机器学习西瓜书
绪论
1.1绪论1.2课程定位
科学:是什么,为什么;
技术:怎么做;
工程:做的多快好省;
应用:
1.3机器学习
经典定义:利用经验改善系统自身的性能
1.4典型的机器学习过程

1.5计算学习理论
机器学习有坚实的理论基础,由Leslie Valiant的计算学习理论 现在有一个数据样本x,现在对x进行一个f(x)的判断,y是真实的结果,,我们让两个数的差小于一个非常小的数字即可
现在有一个数据样本x,现在对x进行一个f(x)的判断,y是真实的结果,,我们让两个数的差小于一个非常小的数字即可
提出了两个问题,第一个问题,为什么不追求绝对的等于0 ,第二,为什么是一个概率而不是每次绝对能拿到这关乎到机器学习的根本
p ?= NP
1.6基本术语
数据集;训练,测试
示例(instance),样例(example)
样本(sample)
属性(attribute),特征(feature);属性值属性空间,样本空间,输入空间
特征向量(feature vector)
标记空间,输出空间

example是有结果,instance则是没有结果的,这是这两个的区别;
样本这是一个比较模糊的概念,对sample代称的理解需要结合上下文,有可能是指某一个example,也可能是某一个dataset
我们把每一个属性叫做一个轴,比如西瓜就是一个三维空间,任何一个西瓜都是空间直角坐标系 的一个点,这就是一个特征向量,这个空间就是属性空间,同时也叫做样本空间,因为所有样本都是在这个空间里面,输出空间同理y/n
对于输出,如果是个别的点,比如yes/no就是01两点二分类,大中小3点多分类,如果是一个范围,那就是回归
监督学习,有时候又把它叫做有导师的学习,Supervised learning.无监督学习有时候叫舞蹈式学习,它指的是什么呢?你在数据里面拿到样例的这个结果部分,我们没有拿到这个部分,我们没有这个部分就是无监督学习,有这个部分就是监督学习.也就是说拿到的数据里面没有期望结果是无监督学习
你可能认为无监督学习没什么用,无监督学习就是你给我一堆西瓜,这个好的坏的都不告诉我,那我这能做什么。可能能做的是把这些西瓜分成很多堆,这边有一堆,那边有一堆,分类回归非监督学习的典型任务有哪些呢?类似于离散类别的做聚类,我们把数据分成若干个离散个类别,也有可能我们处理连续的就是在做密度轨迹估计,我判断一下什么样的东西更多,什么样的东西更少
1.7假设空间


1.8归纳偏好
 奥卡姆剃刀:若非必要勿增实体
奥卡姆剃刀:若非必要勿增实体
简单的来说呢,就是当我们发现有很多的假说,很多的东西都能够完美的解释我们的观察,这时候我们就选最简单的。机器学习里面我们看到的训练样本,如果有多个模型都能很好地解释这个现象,我们就找最简单的这个模型啊,这就是基本思路
1.9NFL定理

NFL定理的重要前提:所有“问题”出现的机会相同、或所有问题同等重要
实际情形并非如此;我们通常只关注自己正在试图解决的问题。脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义!具体问题,具体分析!
模型评估与选择
2.1泛化能力2.2过拟合和欠拟合
泛化误差:在“未来”样本上的误差
经验误差:在训练集上的误差,亦称“训练误差” 泛化误差越小越好?经验误差是否越小越好?
NO!因为会出现“过拟合”(overfiting)

在多项式时间下,P和M P确实会不等,但是如果在单项式时间下,只求最小环境下的最优解,那么就有可能实现P和nP在一定时间状态下是对等的。可以理解为 确定一个模型就是最优模型,这件事比NP问题还要复杂,所以确定不了。
2.3三大问题
 根据已有的性能指标设计方法设计一个针对你的具体业务的性能指标
根据已有的性能指标设计方法设计一个针对你的具体业务的性能指标
2.4 评估方法
关键:怎么获得“测试集”(test set)?测试集应该与训练集“互斥”
常见方法:留出法(hold-out)
交叉验证法(cross validation) 自助法(bootstrap)  这里面其实有个非常根本的问题,大家要理解这种hold dot测试它的缺陷是什么呢,我们要去理解,假设这是完整的数据,我们认为它假设有100个样本,在这,我们训练出来一个模型,我们把这个模型叫做M100,我们希望判断它未来的性能怎么样,我们把它叫做error100,这个东西我们得不到,这个东西我们是能得到的,但这个东西我们得不到,我们现在在做一件什么事呢,我们把它一切假设这是80,这是20,我们做的是什么呢,M80,你要注意,我现在做的是M80,已经不是M100,然后呢,我用它对它的测试来对error80做一个估计,并且以后我说我用这个东西来监视他,你有没有看到这里面就有问题了,如果你这个测试数据用得太多,其实你测的这个模型,已经不是我最后真正用的这个模型了,明白吗,我最后用的应该是,拿着100个样本训练出来的模型,结果呢你弄了个80个样本训练出来模型,你告诉我80个样本训练出来模型就好了,你这个算法在这上面好,但是这个是不是一定的呢,有可能80个他好了,90个,另外一个算法更好,所以我们是在用这个模型在近视,它这个的近视能力肯定是随着这个值的变小,近视能力差,我最希望的是这个你就是到100,这个是真正的就是他了,所以这个不能太小,这个不能太小,这个越小对他的逼近能力就越差,那另一方面我们要测出这个东西来,这个东西测的准不准,其实和你这部分数据有关系,这个越小,这个应该测得越不准,那我实际上是希望这个要大一点,这个才能测得更准一点,但是你看这个我也希望要大,这个也希望要大,所以这是个不可调和的矛盾,那所以这个问题我们怎么办呢,一般来说我们只能用一个大家经验上的做法,你用20%或者1/3的数据来做测试几,其他的用来做训练机再小了,比如说你用一半来做训练集了,这个时候,可能你觉得这个和这个差别已经很大了,另外呢我们在这样做了之后,假设我们现在有两个算法,L1和L2在这上面做了之后,我们发现ALE小于L2,这时候我们怎么办呢,我们就take a l e算法,我们认为L1算法在这上面是好的,那是不是我就直接把这个模型就给用户就算了呢,不是的,当你确定了之后,你应该把所有的数据合起来,再来用LE训练一下,把这时候得到的这个模型给用户,所以我们这个画数据之后,训练测试的过程,实际上只是在起一个选择的作用,选定了之后,你应该把整个数据合起来,再训练一下模型,再提交给用户。
这里面其实有个非常根本的问题,大家要理解这种hold dot测试它的缺陷是什么呢,我们要去理解,假设这是完整的数据,我们认为它假设有100个样本,在这,我们训练出来一个模型,我们把这个模型叫做M100,我们希望判断它未来的性能怎么样,我们把它叫做error100,这个东西我们得不到,这个东西我们是能得到的,但这个东西我们得不到,我们现在在做一件什么事呢,我们把它一切假设这是80,这是20,我们做的是什么呢,M80,你要注意,我现在做的是M80,已经不是M100,然后呢,我用它对它的测试来对error80做一个估计,并且以后我说我用这个东西来监视他,你有没有看到这里面就有问题了,如果你这个测试数据用得太多,其实你测的这个模型,已经不是我最后真正用的这个模型了,明白吗,我最后用的应该是,拿着100个样本训练出来的模型,结果呢你弄了个80个样本训练出来模型,你告诉我80个样本训练出来模型就好了,你这个算法在这上面好,但是这个是不是一定的呢,有可能80个他好了,90个,另外一个算法更好,所以我们是在用这个模型在近视,它这个的近视能力肯定是随着这个值的变小,近视能力差,我最希望的是这个你就是到100,这个是真正的就是他了,所以这个不能太小,这个不能太小,这个越小对他的逼近能力就越差,那另一方面我们要测出这个东西来,这个东西测的准不准,其实和你这部分数据有关系,这个越小,这个应该测得越不准,那我实际上是希望这个要大一点,这个才能测得更准一点,但是你看这个我也希望要大,这个也希望要大,所以这是个不可调和的矛盾,那所以这个问题我们怎么办呢,一般来说我们只能用一个大家经验上的做法,你用20%或者1/3的数据来做测试几,其他的用来做训练机再小了,比如说你用一半来做训练集了,这个时候,可能你觉得这个和这个差别已经很大了,另外呢我们在这样做了之后,假设我们现在有两个算法,L1和L2在这上面做了之后,我们发现ALE小于L2,这时候我们怎么办呢,我们就take a l e算法,我们认为L1算法在这上面是好的,那是不是我就直接把这个模型就给用户就算了呢,不是的,当你确定了之后,你应该把所有的数据合起来,再来用LE训练一下,把这时候得到的这个模型给用户,所以我们这个画数据之后,训练测试的过程,实际上只是在起一个选择的作用,选定了之后,你应该把整个数据合起来,再训练一下模型,再提交给用户。

这个折我们在英文里面叫fold,经过上图的验证(Turn food cross validation),这不是留出法,留出法是每次随机取测试集,有的样本可能自始至终都没办法成为测试集中的一个。这当然很好,但是对于极端的例子,比如1个男生和99个女生的集合,留一法就明显的错误了 
叫bootstrap something,那他是在做什么事呢?我们想象一个盒子,这个盒子里面我现在放了十个球,你每次摸一个球copy一下,再把这个球放回去,下次再取一个球,那就有的球会多次出现,有的球根本没取到。但是不管怎么说,你原来有十个球,我现在还可以取十个球出来,只不过有的是重复的嘛,有的样本出现了好几次。但是以这种方式,你原来是假设是100个数据做模型,我现在就能采样出一个数据集来,用100个样本做模型,同时呢这个里面没有出现的数据,我就可以留出来做测试。那这个没有出现的数据大概会有多少呢?我们可以做这么一个估计,非常简单的估计M个样本,我们取M4,那么它不出现的可能性,每一次M个球啊,每一次每取一次他都没有被取到,是一减N分之一,我们取了M个球,取了M次,那就是这么数,那如果这个M非常大的时候,它就是1/1,那这个是0.368,也就是说大概有36.8%的数据,在取出来的这个集合里面没有出现。那现在我们就能用这个没有出现的这部分来做测试集,那这样一个测试叫什么呢?叫out of a bag estimation,这专门有个名字啊,就是叫包外估计。所以当你看到有的东西说我用了out of bag estimation的时候,你就应该知道他用的测试方法是这样一种测试方法。原来的100个我闭着眼睛可重复采样,取100个,训练了100个做的模型,然后呢用原来的这个没取到的这些来测试,测出来的结果啊,这也是一种很好的一种技术,在特定的场合他还很有用。那我们说说它的缺陷,最重大的缺陷就是它改变了训练数据的分布,对吧?我们应该是用这样的一个训练数据的分布,结果呢他在这个用这样来做训练数据了,就本来我们这十个样本,这十个球应该同等重要,结果你这个做的模型认为,这个中这个球和这个球更重要,你的模型在这上面可能得到了一个高估,这是他的问题,训练分布发生变化了。但是有时候如果我们认为训练分布它稍微变一点不太重要的时候啊,那这个挺好,而且有时候数据量不够的时候,用这个也挺好,所以你一定要考虑你使用的场景。bootstrap somebody这个东西非常有用,以后我们还会接触到bootstrap这个词,这个包括在我们讲第八部分讲ensemble methods集成学习方法的时候,这个是个关键的一个技术。而这个东西怎么可重复采样,你们看起来是个很简单的过程,但事实上从统计上来说,概率统计上研究它的性质,它里面有很深刻的一些东西,所以为此,甚至我们非常著名的一位统计学大师Efron为此专门写了一本书,这本书就是《Bootstrap》,就专门在讲这个bootstrap后面的道理。
2.5 调参与验证集
调参数呢我们这里面要区别有两件事儿,有一个叫超参数,我们有时候把算法本身的参数叫超参数,模型的参数呢我们有时候把它叫参数,这个参数是要算法去学的,超参数呢是人去设的
比如说我们说现在有一个算法,就是用多项式函数去逼近数据,那大家知道这个多项式函数有好多种,用这么一个曲线在拟合这个数据。确定的是ABC,那这就是算法要确定模型的参数,这个就是我们直接就把它叫parameter,这个超参数就是SUPERPARAMETER啊,超参数和参数其实本质上它都是一种参数啊
有时候看到一个词叫验证机,叫validation set,这个就是为了把这件事和测试集把它区分开,验证集就是专门用来调参数啊
2.6 性能度量
 对于回归的判断,这里有没有1/2无所谓,
对于回归的判断,这里有没有1/2无所谓,


100个西瓜,预测说10个是好的,10个里面有多少是真的好的,这就是查准率,查全率就是其实是有20个好的,查全率就是50%,我们进一步更新(调和平均)

2.7 比较检验
在某种度量下取得评估结果后,是否可以直接比较以评判优劣?NO
因为:
- ·测试性能不等于泛化性能
- ·测试性能随着测试集的变化而变化
- ·很多机器学习算法本身有一定的随机性
机器学习········“概率近似正确”
 第一个评估我们使用了误差、错误率和精度,它们实际上是一个值。我们来看,这是A算法,这是B算法。在进行交叉验证时,我们实际做了多次实验,其中A有一个基线A1,B也有一个基线B1,以此类推。如果这两个算法没有显著区别,本质上是一回事,那么它们的误差应该是一样的,可以通过做减法得到一个值,我们随意加一个字母叫西格玛。这样,你可以假设得到十个西格玛,这十个值应该符合零均值分布,因为两个算法效果相同。这个零均值分布左右可能有一点浮动,比如做十次恰好有五次A比B好,五次B比A好,且每次差距不大,一次好0.1,另一次好0.09。这意味着两者没有显著差异。通过计算这些值的均值加上标准差,可以判断是否属于该分布,这种检验方法在数理统计中被称为成对T检验或Student t检验。
第一个评估我们使用了误差、错误率和精度,它们实际上是一个值。我们来看,这是A算法,这是B算法。在进行交叉验证时,我们实际做了多次实验,其中A有一个基线A1,B也有一个基线B1,以此类推。如果这两个算法没有显著区别,本质上是一回事,那么它们的误差应该是一样的,可以通过做减法得到一个值,我们随意加一个字母叫西格玛。这样,你可以假设得到十个西格玛,这十个值应该符合零均值分布,因为两个算法效果相同。这个零均值分布左右可能有一点浮动,比如做十次恰好有五次A比B好,五次B比A好,且每次差距不大,一次好0.1,另一次好0.09。这意味着两者没有显著差异。通过计算这些值的均值加上标准差,可以判断是否属于该分布,这种检验方法在数理统计中被称为成对T检验或Student t检验。

那么刚才我们讲的这个是基于一个值的,你基于一个值就误差对吧,那我们前面在评估的时候不还有碰到两个值的吗,呃我们得到一个表,我们得到一个表,这边是true positive对吧,那实际上你如果把它当成两个算法呢,这算法一是算法二,那其实可以把那个表就借用过来了,这种叫联列表,那实际上这个地方就不再是叫two positive了,他说的是什么呢,两个都做对了,你认为是对的,他也认为是对的,那这个呢是你认为是NO,他也认为是NO,这个呢是第一个认为是yes,第二个认为NO,这个是第一个认为NO,第二个认为yes,你看这个部分你们是一样的,不一样的就是这个部分对吧,其实这两个分假假设两个分类的话不一样的不就这个部分吗,那这个部分我们想什么情况下它可能就没有显著的区别,你可以想一想,很容易想到这样的例子,假设我们100个样本,这边是49个,两个都说是yes,49个,两个都说是漏,有一个这个说yes是另外一个漏,有一个这个说yes,那个漏,这没有显著区别,那考虑这两者的关系呢就可以用一个假设检验这个McNemar检验,这个mcnemar就是把这个列联表考虑出来之后,就考虑这个副对角线,反对角线上这两个点,然后呢他后面基于一个卡方检验把它用上去。
线性模型
3.1 线性回归

简单基本而且可理解性好
此处缺少一大段解析

这样一个式子,f(x)=wx+b,w是w1w2.x是x1x2....现在我们用;表示列向量,用,表示行向量。如果wb解出来了,原函数就是线性拟合就确定的
3.2 最小二乘解
对他求偏导,然后给导数为0,在上面式子中体现是对w和b求偏导
对这么一个表达求偏导的时候,实际上意味着我们希望找到一个极值点,这个点是它不动了.这个偏导在物理上它表示一个什么含义呢,表示一个变化率。其实当你对偏导求W意味着你希望找到一个点,我们看这个W1直在动,偏导的这个东西等于零的时候它就不动了。它不动意味着什么呢?一种呢是它到了最小值点不动了,还有一种呢是它到了最大值点不动了。但是我们现在假设就是唯一的,你想一想我现在是YFX偏离Y有多远,我这个可以偏离的无限远,就是说你这个模型根本对我不适用嘛,他们两个相等的这一点,接下来强调的必要性。
3.3 多元线性回归

其实就是你从这个议员方程
变成了一个多元方程
那我们最简单的不就是高斯消元法就解它吗
那其实这个解的过程也就类似于高斯消元法啊
没有那么多玄奥的东西
但是我们要记住一个表达
我们可以把这个B吸收到W里面去
你看我们现在的是FXWWT转置X加B
这个主要是为了以后我们书写简化
这个也是粗体的
那实际上呢我可以把这个B当作是B乘以一
那如果B乘一
你看你前面这个不是等于W1X1加W2X2
一直加WDXD嘛
那再加上B乘以一
那实际上我把这个X抽出来
那你就得到了一个X一X2XD
再加一这么一个X
而这个W呢就变成了W1等等等等等
我们把它叫做W
那这个表达没有问题吧
那所以以后我们就可以只用讨论
这个Y等于WTX啊
这就是为了一个简化讨论的这么一个表达啊
我们把它变成一个向量的形式好
那现在呢我们就可以用这种方式来解了

对于和
由于两式不满秩无唯一解,所以对他们做一个限定,比如对c做一个约束偏好:c越小越好
机器学习很多时候需要一个偏好不加你就没有办法做出来,具体加这个东西我们把他叫做正则化
3.4 广义线性模型

线性模型稍加优化解决非线性问题,其实是用线性回归来逼近对数的目标

3.5 对率回归


3.6 对率回归求解
 看起来的道理就是让看起来复利让ln内下方更大,正理让上方更大
看起来的道理就是让看起来复利让ln内下方更大,正理让上方更大

就是对于最小二乘法,
变成带入其中,实际上对带入后的式子求w的偏导以导数为0的解得到解这个方法是不行的
我想这个人工智能学院的同学学过优化了啊,这个应该是一个基本的道理,我们什么时候能够通过求梯度为零的点,得到极值,我们这样知道,极值点它应该是梯度是零的,但是梯度是零的点是不是一定是极值点啊,不一定,只有在什么时候才能是凸函数啊,他必须是这种形状的函数,是凸函数,就是简单,大家好,就是这种U型函数,你自己找两个点,它的连线,那这个上面的都在这个上面,这是凸函数,当然我们国内有些书的定义是反过来的,它是以这个曲线的形状这样为突,但这个没关系啊,你把前面取个负号,他就回来了,对讨论他的数学性质没有太大的关系,只有在这样的东西,我们梯度为零的点,它一定是它的极值点,然后上节课我们讲到线性回归的时候,讲到为什么我们能用均方误差最小化,因为当你这条线的时候,它只有两个极值点,极大值点它可以无穷大是吧,你可以取让这个离这个线无限无无限的偏,所以它极值点一定是它的最小值点啊,所以我们能这样做,而现在这个函数大家回去可以做一个习题,这个函数你去讨论一下它的凸性,这个函数是非凸的啊,这个可以做一个协调,你看满不满足这个性质啊,这个这个这个是非凸的,那这个非凸的我们就不能直接这样去解它,那所以我们在解,所以我们在解这个对立回归的时候呢,我们就用到一个极大似然法,极大似然法,这个更具体的人,我们以后会再讲第六章的时候再给大家讲,那么在这呢简单的先告诉一下它的基本思想,其实这个东西非常简单,很容易理解它是一个什么样的东西呢。
3-6.对率回归求解_哔哩哔哩_bilibili一直到最后都是
3.7 线性LDA判别分析
 用一条线分开,那个算法叫linear SVM后面会学。要求实现组内误差尽可能小,组间误差尽可能大
用一条线分开,那个算法叫linear SVM后面会学。要求实现组内误差尽可能小,组间误差尽可能大

类内散度矩阵指的是只考虑同类对象内部他的一个分散程度,实际上就是他的协方差矩阵和第一类他的协方差矩阵

正如上式,w是可以类似约去的,所以真正起作用的是这个w的方向。我们看任何一个线性的东西,你就可以想象在这个矩阵中啊,在这个坐标空间中,它就是这么一个量,大小呢无外乎就是同等放大,大小无关之后,其实就是离这个指向哪边更重要,其实最重要的就是这个指向就是k斜率,而为什么指向重要呢,你想想我们这个点这个点投影到这条线上去,我们本来就是投影到它的延长线上去,所以最重要的就是这个方向,这个方向如果错了,我们算出来的这个东西就不对了,所以方向是最关键的啊,这个是在它的物理含义上,最后我们调解的时候,其实就是在考虑这件事。
接下来我们解最大化广义瑞利商,这是运筹学的课程内容。前面说了w的大小不重要,只有方向重要才可以随意乘一个系数:因为右边的标量只有那慕达,左边的标量就等于那慕达


第一个式子,第二个式子,这两个式子相等对吧好了,这两个相等,我把这边拿掉,对吧,这个是这样的吧,这个东西是个标量,假设它是C没问题,我们就说它等于C好吧,是不是没关系吧,那如果他是C,那这边有个拉姆达,我们又说了,这个W的大小是无所谓的,那这个W的大小既然无所谓,我们乘一下好了,我们把它存起来,使得它等于number,把这两边一把它凑到一起去,实际上你就等于把这个东西啊除到这边来,这个W里面不是有他吗,W大小不是没关系吗,我把这个里面插的这部分存到这里面去,没问题吧,那你得到的就是这个东西等于他了,明白吗啊这个是个简单的从代数上的考虑,那如果你要从几何的角度来考虑呢,其实你考虑这个式子之后啊,如果你们线性代数学得比较好,你可以看到其实这一项是方向,前面这项是决定方向的,而我们刚才又讲到了,在LDA这个广义瑞利商里面,其实最重要的我们要求的我刚才擦掉了,就是要找到这个方向,那所以这个方向最重要就是这一项,而前面这个什么东西是决定它的方向呢,你把这个东西全进来,如果不管W的大小,它就在这里面,所以我们可以得到这个东西等于它,那马上你就可以得到了,把这个东西求个例,这就是我们解出来的W,这就是得到的这个式子是,所以如果直接从标准的推导,我们直接就得到这样的解决方案啊,你可以去这样去解它啊,但是在现实中呢大家直接做的时候呢,通常我们会用一个更快的一个做法,求这个SWSW,我们通常直接做这个奇异值分解,拿原来数据它的协方差矩阵,我们直接取值分解,把这个UV分解出来啊,然后呢SW直接通过这个奇异值分解的结果,把它倒过来,拼过来就得到它啊,这个是我们原始拿到的数据,拿到他的一个散度矩阵,然后我们再来做这件事,然后把SW求出来,这个东西就解出来了,那这个就是整个我们LDA求解的一个过程,非常简单,那基本思路就是,你看我把所有的点投到这条直线上去,那你自己内这一团应该扣得比较紧,我们两者之间应该离得比较远,然后把这个目标一个写在分子上,应该写在分母上,然后把它解出来啊,解的过程用拉格朗日乘子法啊,再观察一下它原来的定义,一比较就出来了。
3.8 线性判别分析LAD的多类推广
 迹tr aq,你的特征值之和主对角线之和。其实这个形式和刚才LDA那个向量单点的样子形式一模一样,把原来的二次型换成G2型,这个就是那这个是用SB和SW来定义,那其实你也可以把st放进去啊,然后同样也可以用ST和SW来做,或者ST和SB来做。所以有多种做法,那么我们看这个最典型的这种,那这种我们怎么来解它呢?你还是得到箭头右端的这个式子,最后得到的必是解
迹tr aq,你的特征值之和主对角线之和。其实这个形式和刚才LDA那个向量单点的样子形式一模一样,把原来的二次型换成G2型,这个就是那这个是用SB和SW来定义,那其实你也可以把st放进去啊,然后同样也可以用ST和SW来做,或者ST和SB来做。所以有多种做法,那么我们看这个最典型的这种,那这种我们怎么来解它呢?你还是得到箭头右端的这个式子,最后得到的必是解
3.9 多分类学习基本思路

最后我怎么决定总输出呢,把它们合起来看,比如说我们投票,现在说你看哪一个最多啊,投C3的最多,我们就决定C3了,因为每一个类它一定是出现的次数是一样多的,也是两两猜的嘛,投C3最多就取C3了,但如果打平了怎么办?我们的很多模型它还提供了一个置信度,我预测的同时其实还一定程度上告诉你的置信度,比如说我们支持向量机,它会有一个这个margin,就可以把这个当做置信度,还有呢比如说对率回归的时候,你大于0.5就是1,但实际上它输出的是0.8,对另外一个输出的是0.7,那我就推0.8,这个那就得到最终结果

那还有一种划分的是one versus rest,对,其余,大家注意有的书里面把这个叫做OVA,他把这个A当做是or就一对全,这个说法是不严格的,你不可能把全部当作反对,因为你自己也在里面了,所以一定是自己和其余,那他这个怎么做呢,你看假设还有这四个类的话,第一个分类器考虑第一类是正类,234是负类,第二个呢考虑二类是正类,134是负类,以此类推,然后来一个新样本之后扔进去,它同样会给你这些预测最后的结果,这时候同样考虑可以投票,如果投票再决定不了,考虑你的置信度。
3.10 类别不平衡
我们怎么样要去考虑这种大类小类不平衡的问题呢,这个问题很重要,如果大类和小类它的代价是相同的,我们不需要做任何处理,大家可以想一个极端情况啊,我们100个样本,99个是正的,一个是负类,那现在我有一个简单的模型,我说我看到的训练样本谁多就是谁,那我来一个样本,我都认为是真的,那这个精度已经是99%了,但是呢他把那一个负类丢掉了,如果正类比负类重要,那丢掉它没有关系,如果我总要犯错误,那我就宁可犯在代价小的这个问题上去,所以如果小类它不重要,那我们不需要做任何处理,如果小类和正类同等重要,我们也不需要做任何处理,我们要做处理的一定是,当小类比大类更重要的时候,这一点大家记住了,不是说任何时候类别不平衡都要处理的,只有说你丢掉的这个小类啊,它的价值很高,这时候我们才要特别处理,这是我们的前提,那如果我们恰恰碰到这种问题,我们的样本两类完全不一样,那比如信用卡检测就是这样的问题,100万个交易里面可能欺诈只有100个,那这时候这100个对我非常重要,你把所有的都说是好的,99.99这个模型对我没意义,那这种情况我该怎么做呢?
如果Y除以一减Y,这个时候alt大家还记得啊,这个叫几率,如果这个几率大于一,我们就预测为正类,其实我们到现在为止,教给大家的二类分类的模型都在做这件事,这个是什么东西啊,我们平时做的其实是隐含的,是在以1/2做一个标准,当你输出大于1/2,就零一之间啊,当你输出大于1/2,我认为你是正的,小于1/2,我认为你是负的,你看这个几率大于一,不就是上面大于下面,把Y倒过来,不就Y大于1/2吗,所以实际上我们做的是,当你的输出在这么一个轴上,我们始终解说你在这边就是正类,在这边就是负类,但是现在的问题是,我们认为正负同样重要的时候,那如果正负不同样重要,而且这个父类比较正类,我们假设这个阵内比较重要,假设这个正类比较少的,假设这个镇内,假设是一比三,那实际上就是镇内比总样本只占1/4,这时候我还应不应该以1/2为标准呢,直觉的大家告诉我,你直观上你觉得应该以什么样为划分标准,有多少,1/4大于1/4,就是正,小于1/4就是负对吧好,我们按这个来想啊,那现在就应该Y大于1/4,那这个是什么呢,Y除以一减Y大于1/3,而这边,所以当两类不平衡的时候,我们应该要做的是这个准则啊,我们实际上可以怎么做呢,把这个东西放过来,我们就是要得到一个算法,这个算法本身是在做以0.5为切分点,他以0.5为切分点,实际上就已经做到了,我以这个东西为切分点,你把这个东西带进去,就能得到这么一个东西,这个其实只是一个基本的思路,实际上我很难很精确地估计这个比例,我们有时候看到这个数据集里面有一个A是100,B是十,那我是不是就把100÷10放上去呢,如果要这样做,必须有一个假设,就是我们拿到的训练集是整个潜在可能的数据拿到的一个无偏采样,这才有可能就是说我们拿到的这个是,我们本来假设,所有的数据都是从这个里面采样出来的,都是从这样里面一个一个采样出来,那但是我们拿到的训练集呢,你可以看到说这部分是正类,这部分是负类,但是如果这部分负类本身很小的时候,那他还能不能保证说,原来你看到的这个就是原来整个数据,它就是这样分布的,这时候就不一定了,所以如果它一致,那就说明他是他的无偏的真实采样,但是这件事情很难保证啊,那我们来解决这样的问题,有几种做法呢,通常有三种典型的做法,我这边给大家讲一讲这个基本思路啊,很简单,第一种呢我叫过采样,我就是让小类增加,增加到和大类一样多,那这时候你就平衡了嘛,就按原来的做法做就好了,第二种做法呢是欠采样,就on商品,我把大类变小,让他和小类一样多,那第三种呢很少的情况下,我们把阈值按这样来移,就像刚才我们不是说,你看我预测的时候是以0.5,那现在呢我要变成1/4,我把这个阈值移动一下,有少数算法可以这样做到,其中支持向量机就是一种,我们来看看这个所谓的过采样啊,假设你看这个是我们的一类的样子,另外呢有一类样本是这样,大小类不一样,那如果我们要用小类和大类一样多,怎么办,大家想到最简单的是copy,但是一旦你copy之后,这个问题就会带来很大的问题,你的OVERFITTING的可能性会大幅度增加,因为如果这个东西有点噪声的话,实际上你让噪声的影响加倍了,甚至加几倍了,那所以最著名的一种做法叫SMOTE,这个是Chawla提出来的,你看他的名字就知道是个印度人,但是是位美国学者啊,在这个圣母大学做教授,他也到南大来访问过几次啊,有一段时间经常来啊,我们也去过,那这个SMOTE怎么做呢,这个是他最著名的工作,我们在中间插值,这就多了一个点了,如果你有很多别的样本,你可以再插,那可以查出很多样本来,这就是SMOTE的基本的想法,然后你这个几个我讲两个的话,我就这样差一个,这再差一个就变成四个了啊,如果更多了,我还有别的插值的办法,这就是过采样,你不能完全的copy,你可以在已经有的数据上稍微加点变化啊,这样呢就会好很多,这个做法基本上是现在处理不平衡问题,过采样里面的最经典的做法,而且你们在大多数的工具包里面都能看到它,欠采样,顾名思义,欠采样要做的呢,就是我们要丢掉一些大类的样本,那我们能不能随机丢掉一些呢,早期有这样的做法,但是这个做法会带来一个很大的问题,因为你不知道你丢掉的是不是关键的东西,比方说如果我们这个分类本来是这个样子的,其实你这个分类边界会是这样,但是一旦你把这个东西丢掉了,它的分类边界马上可能会有一个非常显著的变化,所以随便丢是不太好的,因为你不知道你是不是把关键的大类样本丢掉了,所以有一个很重要的做法叫EasyEnsemble,这个是我们组做出来的啊,也是很多地方在用,但这个做法是什么呢,它是个集成学习的时候,我们做很多的模型,比如说你这个小类啊,总共只有三个,我每次就从这个大类里面找三个做一个模型,这是三对三,这个模型一,然后下次我再找三个这三对三,这是模型二,每一个这样的子模型它都是均衡的,但是通过做很多个这个之后呢,我们最后用一个投票办法结合起来,那里面每一个都是均衡的,那这个做法呢就避免了你可能很有价值的大类被错误的丢掉,而且反过来这个还利用到以后,我们会讲到这个集成学习的好处,反而还使得精度能够提得更高。
常见类别不平衡学习方法:
- 过采样(oversampling) 例如:SMOTE
- 欠采样(undersampling) 例如:EasyEnsemble
- 阈值移动(threshold-moving)
决策树
4.1 决策树基本流程
策略:“分而治之”(divide-and-conquer) 自根至叶的递归过程
在每个中间结点寻找一个“划分”(split or test)属性
三种停止条件:
(1)当前结点包含的样本全属于同一类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分; (3)当前结点包含的样本集合为空,不能划分.
这个节点,第一种状态里面如果全是同类的样本了,我不用往下分了,这是第一种状态是吧;第二种状态你虽然还有不同类的,但是我已经没有更多的属性来用了,这是什么意思呢,你看我们这个决策树啊,是不断的从上往下走下来的,假设我们现在就考虑这个决策树就有两个属性,一个是颜色,一个是敲的声音,我现在现在判断了,说颜色是不是青绿色的,你说yes,下来,我说敲的声音是不是浑浊的,你说yes,下来到了这儿还是没有全分开,这时候我没有办法再往下做,难道我再问一下颜色是什么,那那走到这儿的颜色都是青绿色的,我再问一下声音,走到这儿的声音都是浑浊的,没有办法往下做,所以我必须停,这也就是说属性极为空了,或者在剩下的属性上,它的取值都一样了,也许你还有属性,比如说这个是颜色,这个是声音,这边是什么耕地啊之类,但是这几个样本呢,前面这个划分之后,后面的这个它取值完全是一样的,也没办法往下分了,所以这时候我必须停止明白吧,属性不够用了。
还有一种情况,当前节点包含的样本集合为空,这会什么情况呢,你看啊,我们假设用颜色来划分,颜色是青绿色的,往左走,颜色是浅白色的,往右走,颜色是黑色的,黑色的往右走,浅白色的往中间走,但是很遗憾,我拿到的训练数据集里面,就没有出现过浅白色的西瓜,那按照属性来说,它有可能取这种属性的,但是我训练集里面就没有这样的数据,所以这个数据集是空,这时候我也要停止,那下面我们就无外乎要对这三种情况做处理,第一种情况,如果所有的都同类,那很简单,它是个叶节点,你全是阵内,就是正内,全是父类,就是父类对吧,第二种情况,我到这种情况,我属性没有了,没法往下分了,这时候我该把这些节点当做什么呢,很简单,你谁多我就当做谁,你这个多我就当做是正类,那这种情况怎么办呢,你这是空的,你的这个父节点谁多,我就当作是谁,这是最简单的操作了吧,因为我是从父节点下来的嘛,我没有样本,但是我父节点是有的,那父节点谁多,我就当做是谁,所以这两个操作实际上是什么呢,这个不用说了,这个实际上是我们观察到数据,它是以它的后验概率做一个划分,而这个呢是我们把父节点的概率当做了我以后样本可能来的一个先验概率,基于他在做一个划分,这个道理很简单是吧。

4.2 信息增益划分
4.3 其他属性划分准则
4.4 决策树的剪枝
4.5 预剪枝与后剪枝
4.6 缺失值的处理
支持向量机
5.1 支持向量机基本型

 中间那条线是超平面,下面那边是负的,上面是正的,最关键是找到那几个有圈的样本来,要和两个的在中间,距离都要最大。如果说把正例和负例的距离都变成1就变成了2/w的超平面相对于数据集的间隔。
中间那条线是超平面,下面那边是负的,上面是正的,最关键是找到那几个有圈的样本来,要和两个的在中间,距离都要最大。如果说把正例和负例的距离都变成1就变成了2/w的超平面相对于数据集的间隔。
 指拉格朗日乘子
指拉格朗日乘子
5.2 对偶问题与解的特性
对偶问题的得到的是原来目标函数的下界,希望原函数最好,所以求一个极大

5.3 求解方法
对于上图式子,有另外的方法加快求解
5.4 特征空间映射
如果遇到不明显或复杂的图难以分割,若不存在一个能正确划分两类样本的超平面,怎么办?
我们采用将样本从原始空间映射到一个更高维的特征空间,使样本在这个特征空间内线性可分

 需要详细阐述
需要详细阐述
5.5 核函数
在低维空间中输入,处理的结果恰恰等于高维空间两向量的积,那么k怎么找? 将求高向量行为点积转化为在低维空间中求核函数的值;其中函数起到一个空间的变化
将求高向量行为点积转化为在低维空间中求核函数的值;其中函数起到一个空间的变化
 在甚高维空间变成
在甚高维空间变成,这就是函数fai做的事情;再定义xl的点,可能就跑到x轴上去了。如果距离矩阵可以为0,对应上面这样一个空间那么恰恰能够称为核函数
任何一个核函数,都隐式地定义了一个RKHS(Reproducing Kernel Hilbert Space,再生核希尔伯特空间)
“核函数选择”成为决定支持向量机性能的关键!
缺少6分钟讲解
5.6 软间隔SVM
5.7 正则化
5.8 如何使用SVM?
神经网络
6.1 神经网络模型
"神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应"[T. Kohonen, 1988, Neural Networks 创刊号]
神经网络是一个很大的学科领域,本课程仅讨论神经网络与机器学习的交集,即“神经网络学习”亦称“连接主义(connectionism)”学习
 那第一点我们来看看神经元模型,这就是简单单元,所谓的这个简单单元,到现在为止,我们用到的最多的神经元模型还是在1943年,这个芝加哥大学的这两个人MICHAEL和Pitts提出的模型一直沿用至今,哪怕今天深度学习这么红的年代里面,我们用的最多的还是这个模型,那这个模型非常简单,它刻画的是一个什么现象呢?我们在生物神经系统里面有这么一个现象,一个神经细胞它会接收到来自其他细胞的信号,而这个信号通过这个连接突触增强到达我这个细胞,它传过来的其实是一种电位,当到我这儿的累积电位高于一个阈值,我就激活了,往外传出一个信号,所以你看现在我们把这个花当做一个细胞,从很多别的地方传过来,X这就是别的细胞给它提供的信号,通过这个连接放大放大嘛,就是乘一个W,那么到我这儿之后呢,就变成所有的sigma x和W乘起来,如果它比较大,比这个C塔要大一些,我就激活激活就是产生一个输出,由一个函数F来处理产生输出,所以所谓的这一个神经元模型其实就是这么一个简单的数学函数,X是别的神经元来的信号,W是突出放大,全部加起来sigma比我原来的一个阈值theta高,你就用F来处理一下,产生Y,所以所谓的一个神经元就是这么一个函数,那么我们在所谓的学习以后要学什么呢?就和刚才我们说到线性回归啊,等等线性模型一样,要学的就是这个W还有这个theta,我们线性模型不是WXT转置加乘X加B吗,加B嘛,你和减C塔是一回事了啊,正负号把那个吸收进去就是了,那所以你看他要学的还是W和B诶,你看这一点和线性模型是一样的,其实每一个神经元自己本身,如果你不考虑这个F它就是个线性模型,所以把这个F去掉,它不就是个线性模型吗,那么现在有这个F之后,它能够处理非线性的东西了,那么我们一定知道这个F要做某种变化。
那第一点我们来看看神经元模型,这就是简单单元,所谓的这个简单单元,到现在为止,我们用到的最多的神经元模型还是在1943年,这个芝加哥大学的这两个人MICHAEL和Pitts提出的模型一直沿用至今,哪怕今天深度学习这么红的年代里面,我们用的最多的还是这个模型,那这个模型非常简单,它刻画的是一个什么现象呢?我们在生物神经系统里面有这么一个现象,一个神经细胞它会接收到来自其他细胞的信号,而这个信号通过这个连接突触增强到达我这个细胞,它传过来的其实是一种电位,当到我这儿的累积电位高于一个阈值,我就激活了,往外传出一个信号,所以你看现在我们把这个花当做一个细胞,从很多别的地方传过来,X这就是别的细胞给它提供的信号,通过这个连接放大放大嘛,就是乘一个W,那么到我这儿之后呢,就变成所有的sigma x和W乘起来,如果它比较大,比这个C塔要大一些,我就激活激活就是产生一个输出,由一个函数F来处理产生输出,所以所谓的这一个神经元模型其实就是这么一个简单的数学函数,X是别的神经元来的信号,W是突出放大,全部加起来sigma比我原来的一个阈值theta高,你就用F来处理一下,产生Y,所以所谓的一个神经元就是这么一个函数,那么我们在所谓的学习以后要学什么呢?就和刚才我们说到线性回归啊,等等线性模型一样,要学的就是这个W还有这个theta,我们线性模型不是WXT转置加乘X加B吗,加B嘛,你和减C塔是一回事了啊,正负号把那个吸收进去就是了,那所以你看他要学的还是W和B诶,你看这一点和线性模型是一样的,其实每一个神经元自己本身,如果你不考虑这个F它就是个线性模型,所以把这个F去掉,它不就是个线性模型吗,那么现在有这个F之后,它能够处理非线性的东西了,那么我们一定知道这个F要做某种变化。
sigmoid函数其实是指S型的一类函数,如是最为特点的一个函数,


6.2 万有逼近能力
多层前馈网络有强大的表示能力(”万有逼近性”)
仅需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数
[Hornik et al., 1989]
任何一个输入x输出一个f(x)函数,如果要求在x空间中任何一点都有值,就说是连续函数,可以看到我们的任何计算过程都是做连续函数。故任何函数逼近问题都可以用单隐层前馈网络解决
但是如何设置隐层神经元数是未决问题(open problem),实际常用试错法
很多人认为万有逼近性是神经网络独有的优良属性,但是是错误的,傅里叶变化等等等等也有此性质.
6.3 BP(误差逆传播算法)算法推导





难以概括,提供视频理解5-3.BP算法推导_哔哩哔哩_bilibili
6.4 缓解过拟合

一个抖动的线,中间抽象一条线,虽然平滑掉锯齿
贝叶斯分类器
7.1 贝叶斯决策论
 我们再其中选择一个风险最小的决策,即贝叶斯判定准则。
我们再其中选择一个风险最小的决策,即贝叶斯判定准则。
h*称为贝叶斯最优分类器(Bayes optimal classifier),其总体风险称为 贝叶斯风险(Bayes risk),他反映了学习性能的理论上限
假设我们看到ground truth,因此我们的问题在于无法看到groundtruth的区别是这个条件概率
7.2 生成式和判别式模型
 所谓的生成式模型是先把他的联合概率做出来,在此基础上进一步处理的。
所谓的生成式模型是先把他的联合概率做出来,在此基础上进一步处理的。
为什么叫做生成式呢?我们给出一个数据集,都可以看到有一个数据分布并得到一个采样(独立同分布), 潜在我们叫他假定有一个分布的我们不知道的!!!!!缺少。如果把数据集叫做C(可看作关于类别模型)生成即P(X,C)
总之,两个一个是拿到数据后就事论事只做他;另一个是把原来的分布尽可能还原出来。
7.3 贝叶斯分类器与贝叶斯学习
很难用什么话概述,建议看视频7-3.贝叶斯分类器与贝叶斯学习_哔哩哔哩_bilibili
7.4 极大似然估计
假设有一个高斯分布,中间有(m,seita)这样一点,把D_c这一数据集全部导出,那么每一个x都从这个产生的概率是多少?把每一个X都是独立随机事件且独立同分布,用确立这个模型的产生X的概率,这是若干个X(即X1X2X3....)可以认为是把他们的各自的对应的概率相乘即
.seita有许多选择,故可以参数化(0.1,0.2,0.3......)最后调参至误差min即可
 同学,这里书中的log默认为ln
同学,这里书中的log默认为ln
7.5 朴素贝叶斯分类器
从贝叶斯公式出发,从BYS公式,我们刚才的探讨一个PC,一个PX啊,这个我们都不用去讲了,PX就是你看到的X这个PC呢是类别先验,那你可以认为我也可以把它当作,产生很多数据之后找后验,那我们要估计的就是他,但是这个东西估计呢非常困难,为什么困难呢,大家要注意这个X啊,它涉及到一个feature space,而当我们要估计
的时候,其实是涉及到属性,它的联合展开

现在我们有西瓜青绿根底蜷缩浑浊声音,我们把条件叫做x1x2x3,因此现在衍生出X1|C,X2|C,X3|C,X1X3|C,X1X2|C,X2X3|C,X1X2X3|C这就是蓝字的问题,2的3次方组合爆炸


那么举一个例子,17个数据8个好9个坏 
7.6 拉普拉斯修正
其中有一个问题是对于某些比如青绿蜷缩浊响模糊的西瓜,他是坏的。但是没有模糊的样本?

这个里面有部分没有出现,现在3个口袋来一个球进入A或者B,但是C一直是0,会对结果产生错误预测,于是拉普拉斯就预先在所有口袋放一个球,
实际上这是假定属性值和内容均匀分布,这是我额外有引进的bias
集成学习
8.1 集成学习
集成学习(Ensemble Learning)是一种利用多个模型来提升整体预测性能的技术,而非单一模型。通过结合多种模型的结果,集成学习通常能够获得更好的效果,尤其在竞赛和实际应用中表现突出。
集成学习有两种主要类型:
- 同质集成:所有模型相同,如多个决策树(可称为决策树集成)。
- 异质集成:模型各不相同,比如神经网络和决策树的组合。
每个模型在集成中被称为个体或成分,通常叫“弱学习器”。集成学习广泛应用于各大比赛和工程中。例如,在深度学习中,往往会将神经网络输出的特征传入其他集成模型(如随机森林、XGBoost)来提升性能。这种技术尤其适用于需要高性能的场景,且即使没有创新,使用集成学习往往能获得较好的效果。
8.2 好而不同

现在假设我们要预测的目标有三位,分别是绿色、黄色和绿色。我们有三个模型来完成这项任务。第一个模型在预测最右边的颜色时犯了错误,将绿色误认为黄色;第二个模型则在中间位置犯错,将黄色误认为绿色;而第三个模型在最左边犯了同样的错误,将绿色预测为黄色。每个模型都只正确预测了其中的两位颜色,因此它们各自的准确率为66.6%。然而,如果我们采用一种简单的方法——多数投票(majority voting),即当多数模型对某一位颜色的预测相同时,我们就采纳这个预测作为最终结果。这样,通过结合三个模型的预测,我们可以得到100%准确的结果。这是因为每个模型虽然都有缺陷,但它们的错误并不相同,通过组合这些不同的“声音”,我们可以抵消错误,从而获得比任何一个单独模型更好的结果。
但是,并不是所有情况下集成方法都能提高性能。比如,当三个模型在同一个位置上都犯了相同的错误时,使用多数投票并不会改善结果,反而会保持错误不变。这说明,为了使集成方法有效,个体模型之间需要存在差异性。进一步来看,如果每个模型都犯了多个错误,并且这些错误导致了完全相反的预测结果,那么即使采用多数投票,最终的准确性也可能降到0%,甚至比单个最差的模型还要糟糕。这表明,为了使集成学习有效,不仅需要个体模型之间的差异性,还需要保证每个模型的基本性能,即它们不能太差。
这个例子很好地展示了集成学习的基本原理和条件,即个体模型不仅要具备一定的准确性,还需要具有多样性。这与团队合作类似,当团队成员各有所长,能够互补时,整个团队的表现往往能超越单个成员的能力。


8.3 两类常用集成学习方法

8.4 Boosting
8-4.Boosting_哔哩哔哩_bilibili
Boosting其实是一种框架,之后我会讲更具体的内容。现在大家可以先了解一下它的流程。Boosting家族的算法一般以“boost”结尾,比如常见的AdaBoost,而整个家族的流程是类似的。首先,我们拿到一个初始训练集,假设称之为DataSet1,然后选择一个基础算法,常用的是决策树等算法,这时我们称之为Base Learning Algorithm。集成学习中有同质与异质之分,Boosting侧重同质集成,因其实现更为方便,即使用一个算法多次训练得到多个模型即可。
同质集成的挑战在于如何保持模型间的差异性(diversity),这比异质集成要难。异质集成由于算法不同,模型间天然存在差异,而同质集成则需要通过训练集的不同来实现差异。
在Boosting框架中,首先训练一个基础模型Learner1,用它对训练集预测,记录正确与错误的样本。为每个样本分配权重,错误的样本权重上升,正确的样本权重下降。然后重新采样得到新的训练集DataSet2。这样,第二个训练集将更关注先前分类错误的样本,进而生成Learner2。如此重复T轮,最后将所有Learner加权组合。
Boosting可以用于分类、回归,甚至排序任务。其核心思想是对残差最小化的高效实现,设计之初便是统计学残差最小化过程的计算方法。
8.5 Bagging
8-5.Bagging_哔哩哔哩_bilibili
Bagging是一个相对容易理解的集成学习方法。当我们得到一个数据集后,通过对该数据集生成多个学习器来构建模型。假设我们有100个数据,使用C4.5决策树来训练。如果每次都直接使用相同的数据集,生成的每个决策树模型会非常相似,集成起来效果不佳。因此,我们引入了一种技术:从原始数据集中通过“可重复采样”(bootstrap sampling)来生成多个不同的数据集。可重复采样允许同一个样本被多次选中,而某些样本可能完全未被选中,这样生成的数据集就有了差异性。
通常,约63.2%的样本会被采样进入每个新数据集,剩余的留在外面。基于这些不同的数据集训练出多个模型后,将它们组合在一起——分类任务中投票决定结果,回归任务中取平均值。这种方式让每个模型平等参与,不像Boosting中模型有权重差别。Boosting是一个序列化过程,前面的学习器处理简单问题,后面逐步解决更难的部分,权重不可均等。而Bagging可以平等地组合每个模型,生成出一个集成模型。
Bagging的改进版是随机森林(Random Forest),到今天仍被广泛使用。这两个方法中,Boosting有代表性的XGBoost,Bagging有Random Forest,是集成学习中最重要的代表性算法。
8.6 多样性度量
8-6.多样性度量_哔哩哔哩_bilibili

在集成学习中,“多样性”是一个非常关键的因素。它反映了集成学习中不同分类器的差异程度,而这种差异通常能够增强模型的表现力。然而,多样性如何精确度量,却并不是一个简单的问题。
一种简单的度量方式是通过分类器之间的“列联表”来实现。对于任意两个分类器,我们可以构造一个4项表格,用ABCD四个值分别代表分类器在正类和负类的判断情况。基于这些数据,可以计算两分类器的不同程度,例如用 (B+C)/(A+B+C+D)(B + C) / (A + B + C + D)(B+C)/(A+B+C+D) 来度量分类器判断不同的比率,或通过计算相关系数来量化分类器的相似性和差异性。
实际中,已有很多不同的多样性度量方式,比如不和度量(Disagreement)、Q统计量、卡帕统计量等,特别是卡帕值越小,表明多样性越大。我们甚至可以将这些度量与模型的误差表现结合起来,用图表展示模型误差与多样性的关系。然而,通过不同的度量和分析方式,目前仍未找到最优解。
英国学者Lucy Kuncheva曾总结过,当时多达76种多样性度量方法。尽管定义了如此多的度量方式,依旧无法找到多样性与模型性能之间清晰的关系。学者们通过实验发现,个体性能接近的模型,在多样性更高的情况下,理论上应表现更好,但实践中并不总是如此。2003年和2006年的研究表明,即使引入这些多样性度量,并不总能有效提高集成模型的性能。
这也揭示了一个深层次的问题:多样性如何更准确地刻画和量化。现有的定义可能还不够全面,或许需要从模型结构上去考虑预测结构的差异。目前,这个问题仍然是集成学习领域的“圣杯问题”,即一旦能从数学上刻画出完美的多样性度量方法,集成学习的构建将不再有秘密,集成模型的优化也将变得更加系统化、理论化,从而推动整个机器学习进入新的阶段。
聚类
9.1 聚类
9.2 距离计算
9.3 聚类方法概述
相关文章:
机器学习西瓜书
绪论 1.1绪论1.2课程定位 科学:是什么,为什么; 技术:怎么做; 工程:做的多快好省; 应用: 1.3机器学习 经典定义:利用经验改善系统自身的性能 1.4典型的机器学习过程 1.5计算学习理论 机器学习有坚实的理论基础,由Leslie Valiant的计算学习理论现在有一个数据样本x,现在…...

如何使用 Puppeteer 和 Browserless 运行自动化测试?
Puppeteer:什么是 Puppeteer 及其功能 Puppeteer 是一个 Node.js 库。使用 Puppeteer,您可以在所有基于 Chromium 的浏览器上测试您的网站,包括 Chrome、Microsoft Edge Chrome 和 Chromium。此外,Puppeteer 可用于网页抓取、自动…...

python菜鸟知识
去除空格 str 这是 含 空格 print(f去除两端空格{str.strip()}) print(f去除左端空格{str.lstrip()}) print(f去除右端空格{str.rstrip()}) print(f去除全部空格{str.replace(" ", "")}) 方法返回对象yield yield :.join([ip, port])yield {ranking…...

GPT4o,GPTo1-preview, 拼
兄弟们GPT刚开的 需要上车的扣,工作用 大家一起PIN分摊点压力。 在当今数字化的时代,程序员这一职业已经从幕后走到了前台,成为推动科技进步和社会变革的关键力量。编写代码、解决问题、不断学习新技术,程序员们的日常充满了挑战与…...

论文笔记:Pre-training to Match for Unified Low-shot Relation Extraction
论文来源:ACL 2022 论文地址:https://aclanthology.org/2022.acl-long.397.pdf 论文代码:https://github.com/fc-liu/MCMN (笔记不易,请勿恶意转载抄袭!!!) 目录 A…...

一篇文章带你快速了解linux中关于信号的核心内容
1. 信号概念 信号是操作系统用来通知进程某个特定事件已经发生的一种方式。它们是一种软件中断,可以被发送到进程以对其进行异步通知。 2. 信号处理的三种方式 执行默认动作执行自定义动作忽略 signal() 函数:将信号处理设置为 SIG_IGN,可…...

openEuler、Linux操作系统常见操作-(6)如何登录Linux
如何登录Linux Linux登陆方式主要有如下两种: 。本地登陆 。一个典型的Linux系统将运行六个虚拟控制台和一个图形控制台,openEuler目前暂未支持图形化界面; 可以通过CtrlAltF[1-6]在6个虚拟控制台之间进行切换。 远程登录 。默认情况下openEuler支持远程登录&…...

Python基础语法条件
注释 注释的作用 通过用自己熟悉的语言,在程序中对某些代码进行标注说明,这就是注释的作用,能够大大增强程序的可读性。 注释的分类及语法 注释分为两类:单行注释 和 多行注释。 单行注释 只能注释一行内容,语法如下…...
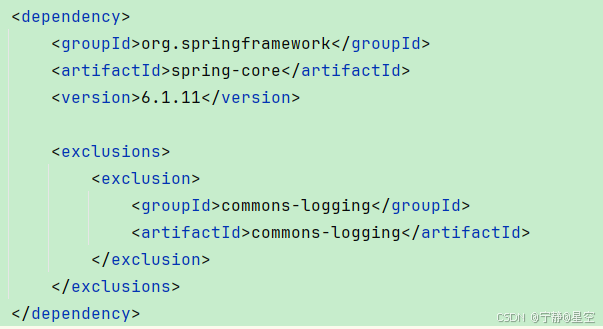
006-MAVEN 的使用
MAVEN 的使用 一、依赖范围二、依赖的传递性三、依赖的原则四、依赖的排除 一、依赖范围 在引入log4j 依赖的时候,有一个scope设置,这个scope设置的值就是对应的依赖范围(因为compile 是默认的依赖范围,所以有时也可以省略)。 Maven 提供了…...

npm使用时报错:Could not retrieve https://npm.taobao.org/mirrors/node/index.json.
在使用npm时报错,报错信息如下: 报错的原因:是原来的淘宝镜像地址过期了 解决办法:修改镜像地址。打开nvm的安装地址 -->settings.txt文件 -->配置下载源 1、将settings.txt文件中的 node_mirror: https://npm.taobao.or…...

软考中级网络工程师——高级配置
文章目录 IS-ISBGP(边境网关协议)-IBGP-EBGP配置BFD(双向转发侦测)与Router-Static联动BFD与OSPF联动BFD与VRRP(虚拟路由器冗余协议)联动VRRP配置(基于网关备份)FW基础配置FW高级配置DHCP路由策略 IS-IS 第一步:每一个路由设置环回口地址 第二部:配置接…...

Leetcode 第 141 场双周赛题解
Leetcode 第 141 场双周赛题解 Leetcode 第 141 场双周赛题解题目1:3314. 构造最小位运算数组 I思路代码复杂度分析 题目2:3315. 构造最小位运算数组 II思路代码复杂度分析 题目3:3316. 从原字符串里进行删除操作的最多次数思路代码复杂度分析…...

Linux性能调优,还可以从这些方面入手
linux是目前最常用的操作系统,下面是一些常见的 Linux 系统调优技巧,在进行系统调优时,需要根据具体的系统负载和应用需求进行调整,并进行充分的测试和监控,以确保系统的稳定性和性能。同时,调优过程中要谨…...

STM32的独立看门狗定时器(IWDG)技术介绍
在嵌入式系统中,确保系统的稳定性和可靠性至关重要。看门狗定时器(Watchdog Timer, WDT) 是一种常用的硬件机制,用于监控系统的运行状态,防止系统因软件故障或意外情况进入不可预期的状态。STM32系列微控制器提供了两种…...
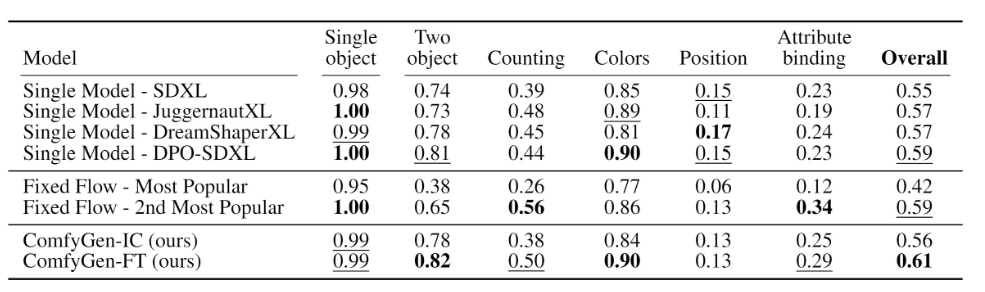
自动化生成工作流?英伟达提出ComfyGen:通过LLM来匹配给定的文本提示与合适的工作流程
ComfyGen的核心在于通过LLM来匹配给定的文本提示与合适的工作流程。该方法从500个来自用户的多样化提示生成图像,随后使用一系列美学预测模型对生成结果进行评分。这些评分与相应的工作流程形成了一个训练集,包含提示、工作流程及其得分的三元组。 然后…...
)
indicatorTree-v10练习(有问题)
目标:设计数据库表表格式,将“indicatorTree-v10.json”导入到数据库,再从数据库读取写为JSON文件。 其他要求:数据库要求为mysql数据库;编程语言暂时限定为C;JSON解析使用本文件夹中的cJSON.c和cJSON.h&am…...

python源码:指定麦克风/音响播放歌曲
前言 我使用pygame实现了指定麦克风/音响播放歌曲的功能,主要目的是解决直播过程的多源声道控制问题。 代码 # 查看自己的音频设备 # 请记住目标音频设备的具体名称 import pygame as mixer import pygame._sdl2 as sdl2mixer.init() # Initialize the mixer, thi…...
基于华为云智慧生活生态链设计的智能鱼缸
一. 引言 1.1 项目背景 随着智能家居技术的发展和人们对高品质生活的追求日益增长,智能鱼缸作为一种结合了科技与自然美的家居装饰品,正逐渐成为智能家居领域的新宠。本项目旨在设计一款基于华为云智慧生活生态链的智能鱼缸,它不仅能够提供…...

OJ-1015图像物体的边界
分析 思路 1.输入读取:读取网格的维度(M,N)和像素值到一个二维数组中。 2.迭代:遍历二维数组中的每个单元格。 3.边界检测:对于每个像素值为1的单元格,检查其八个相邻的单元格。如果任何相邻单元格的像素值为5,则增加边界计数。 4,边界计数调整:由于每…...

RAG 入门实践:从文档拆分到向量数据库与问答构建
本文将使用 Transformers 和 LangChain,选择在 Retrieval -> Chinese 中表现较好的编码模型进行演示,即 chuxin-llm/Chuxin-Embedding。 你还将了解 RecursiveCharacterTextSplitter 的递归工作原理。 一份值得关注的基准测试榜单:MTEB (M…...

MetaTube插件:如何让Jellyfin媒体库实现智能元数据管理
MetaTube插件:如何让Jellyfin媒体库实现智能元数据管理 【免费下载链接】jellyfin-plugin-metatube MetaTube Plugin for Jellyfin/Emby 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metatube 你是否曾经花费数小时手动整理电影库的元数据…...
原理入门:模型辅助理解AI视觉基础)
通义千问1.5-1.8B-Chat-GPTQ-Int4 卷积神经网络(CNN)原理入门:模型辅助理解AI视觉基础
通义千问1.5-1.8B-Chat-GPTQ-Int4 卷积神经网络(CNN)原理入门:模型辅助理解AI视觉基础 你是不是经常看到“AI识别图片”、“自动驾驶看路”、“手机相册自动分类”这些功能,然后好奇它们是怎么做到的?其实,…...

NEURAL MASK 模型调试技巧:使用IDE进行Python代码跟踪与问题定位
NEURAL MASK 模型调试技巧:使用IDE进行Python代码跟踪与问题定位 调试代码,尤其是涉及复杂模型加载和推理的代码,有时候就像在黑暗的房间里找一颗掉落的螺丝钉。你大概知道它就在那儿,但就是看不见摸不着。对于NEURAL MASK这类模…...

3种高效策略:Legacy iOS Kit 旧设备系统降级与越狱终极方案
3种高效策略:Legacy iOS Kit 旧设备系统降级与越狱终极方案 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to downgrade/restore, save SHSH blobs, and jailbreak legacy iOS devices 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit L…...

如何快速诊断dynamic-datasource JVM线程问题:JStack实战指南
如何快速诊断dynamic-datasource JVM线程问题:JStack实战指南 【免费下载链接】dynamic-datasource dynamic datasource for springboot 多数据源 动态数据源 主从分离 读写分离 分布式事务 项目地址: https://gitcode.com/gh_mirrors/dy/dynamic-datasource …...

如何保证代码质量?
一、编码阶段:从源头控制质量1. 统一代码规范(强制执行)核心目标:减少风格差异,提高可读性常见工具:ESLint:代码规范校验Prettier:自动格式化Stylelint:样式规范…...
)
手把手教你搞定VMware VCP-DCV 2024线下考试预约(附北上广考位抢票攻略)
2024年VMware VCP-DCV认证考试抢位全攻略:一线城市实战技巧 凌晨三点,北京中关村某科技公司的运维工程师小李又一次刷新了Pearson VUE页面——这已经是他连续第七天蹲守VCP-DCV 2024的考位。作为晋升技术主管的硬性条件,这张认证对他来说价值…...

Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告
Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告 1. 模型介绍:专为边缘设备设计的智能助手 LFM2.5-1.2B-Thinking是一个专门为设备端部署优化的文本生成模型,它在LFM2架构基础上进行了深度改进。这个模型最大的特点就是…...

OpenClaw安装排错:Qwen3-VL:30B部署常见问题解决
OpenClaw安装排错:Qwen3-VL:30B部署常见问题解决 1. 为什么需要这篇排错指南 上周我在本地部署Qwen3-VL:30B模型时,遇到了至少5个导致部署失败的"坑"。从模型服务无法启动到飞书消息收不到,每个问题都耗费了大量排查时间。这篇文…...

WSL2上跑GraspNet避坑全记录:从CUDA版本冲突到Open3D图形显示,我花了4天踩的坑都在这了
WSL2环境下的GraspNet复现实战:十大典型问题与系统化解决方案 在Windows Subsystem for Linux 2(WSL2)环境中复现GraspNet这类涉及GPU计算与3D渲染的复杂AI项目,开发者往往会遇到各种环境配置、依赖冲突和图形显示问题。本文将基…...