Elasticsearch 入门
ES 概述
ES 是一个开源的高扩展的分布式全文搜索引擎。
倒排索引
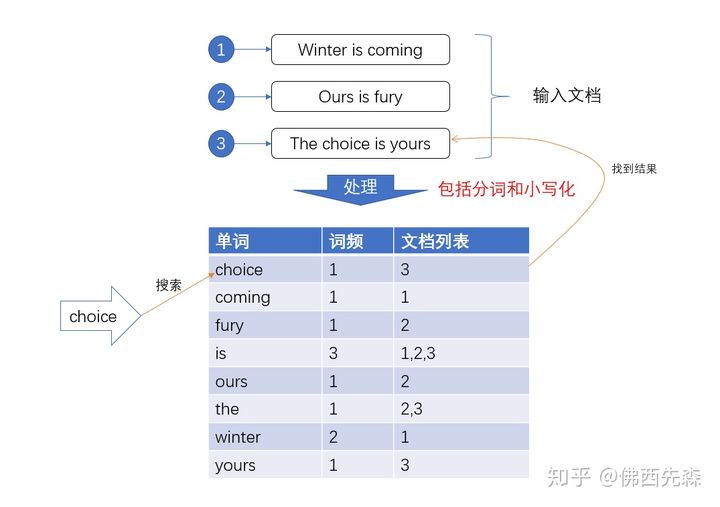
环境准备
Elasticsearch 官方地址:https://www.elastic.co/cn/
下载地址:
注意:9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http
在浏览器中访问:http://localhost:9200
ES VS Mysql
与 MySQL 中概念对比
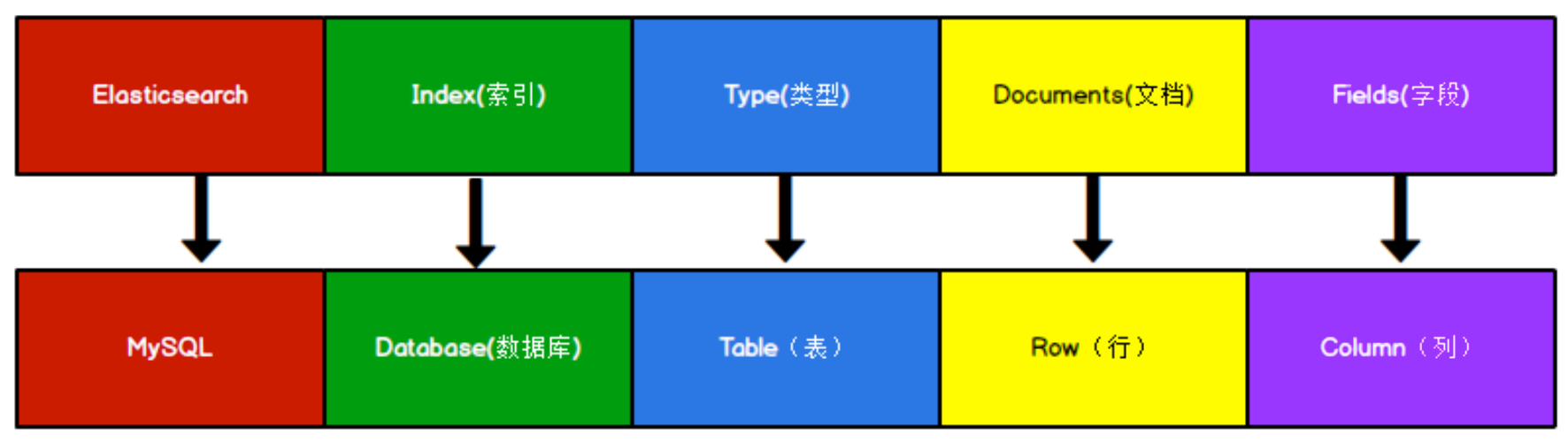
Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
| 版本 | Type |
|---|---|
| 5.x | 支持多个 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义 type (默认类型为:_doc) |
ES 操作
GET,PUT,DELTE,HEAD 操作具有幂等性,POST 操作不具有幂等性。
DSL 其实是 Domain Specific Language 的缩写,中文翻译为领域特定语言。
索引操作
# 创建索引
PUT shopping
{"acknowledged"【响应结果】: true, # true 操作成功"shards_acknowledged"【分片结果】: true, # 分片操作成功"index"【索引名称】: "shopping"
}
注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
# 查看索引
GET shopping
{"shopping"【索引名】: {"aliases"【别名】: {},"mappings"【映射】: {},"settings"【设置】: {"index"【设置 - 索引】: {"creation_date"【设置 - 索引 - 创建时间】: "1614265373911","number_of_shards"【设置 - 索引 - 主分片数量】: "1","number_of_replicas"【设置 - 索引 - 副分片数量】: "1","uuid"【设置 - 索引 - 唯一标识】: "eI5wemRERTumxGCc1bAk2A","version"【设置 - 索引 - 版本】: {"created": "7080099"},"provided_name"【设置 - 索引 - 名称】: "shopping"}}}
}
# 删除索引
DELETE shopping
文档操作
创建文档
# 自动生成 ID
POST shopping/_doc
{"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999
}# 指定 ID(具有幂等性可以使用 PUT 命令)
PUT shopping/_doc/1001
{"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999
}
文档检索
# 全部查询
GET shopping/_doc/_search# 主键查询
GET shopping/_doc/1001
修改文档
# 全量修改
PUT shopping/_doc/1001
{"title": "小米手机2","category": "小米2","images": "http://www.gulixueyuan.com/xm.jpg","price": 4999
}
ES 的 update 只是在ES内部查询出来后,再覆盖。excludes 的字段的数据会丢失。
# 局部修改
POST shopping/_update/1001
{"doc": {"title":"华为手机"}
}
删除文档
DELETE shopping/_doc/9H58aXwBfxge3XJyFrMl
高级查询
条件查询
# 条件查询
# select * from shopping where category='小米'
# match 会把 query 进行分词,多个词之间是 or 关系
GET shopping/_search
{"query": {"match": {"category": "小米"}}
}# 分页查询
# select title,price from shopping where category='小米' order by price desc limit 0,2
GET shopping/_search
{"query": {"match": {"category": "小米"}},"from": 0,"size": 2,"sort": [{"price": {"order": "desc"}}],"_source": ["title","price"]
}
多条件查询:and or
# select * from shopping where category='小米' and price>= 5000
GET shopping/_search
{"query": {"bool": {"must": [{"match": {"category": "小米"}},{# 范围查询"range": {"price": {"gte": 5000}}}]}}
}# select * from shopping where category like '%小米%' or category like '%华为%'
GET shopping/_search
{"query": {"bool": {"should": [{"match": {"category": "小米"}},{"match": {"category": "华为"}}]}}
}# select * from shopping where not category like '%小米%'
GET shopping/_search
{"query": {"bool": {"must_not": [{"match": {"category": "小米"}}]}}
}# select * from shopping where category like '%手机%' or title like '%手机%'
# multi_match 与 match 类似,不同的是它可以在多个字段中查询
GET shopping/_search
{"query": {"multi_match": {"query": "手机","fields": ["category","title"]}}
}# 中文分词
GET _analyze
{"text": ["小米","华为"]
}# 中文分词
GET _analyze
{"text": ["Elasticsearch built-in security"]
}GET _analyze
{"analyzer": "ik_smart","text": ["小米","华为"]
}GET _analyze
{"analyzer": "ik_smart","text":"中华人民共和国国歌"
}GET _analyze
{"analyzer": "ik_max_word","text":"中华人民共和国国歌"
}
IK 分词器
- 下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 解压:拷贝到 Elasticsearch 的 plugins 目录下:文件夹名称为 ik
- 重启:Elasticsearch
聚合查询
# price 平均值
# select avg(price) as price_avg from shopping
GET shopping/_search
{"aggs": {"price_avg": {"avg": {"field": "price"}}},"size": 0
}# price 最小值
# select min(price) as price_min from shopping
# avg,min,max,sum
GET shopping/_search
{"aggs": {"price_min": {"min": {"field": "price"}}},"size": 0
}# 同时返回:count,min,max,avg,sum
GET shopping/_search
{"aggs": {"stats_price": {"stats": {"field": "price"}}},"size": 0
}# select price as key,count(1) as doc_count from shopping group by price
GET shopping/_search
{"aggs": {"category_group": {"terms": {"field": "price"}}},"size": 0
}
映射关系
# name:分词并建倒排索引
# sex:不分词,建倒排索引
# tel:不建倒排索引
PUT user
{"mappings": {"properties": {"name": {"type": "text","index": true},"sex": {"type": "keyword","index": true},"tel": {"type": "text","index": false }}}
}# 查看索引 mapping
GET user/_mapping# 插入测试数据
POST user/_bulk
{"index":{"_id":"1001"}}
{"name":"张三","sex":"男生","tel":"1111"}
{"index":{"_id":"1002"}}
{"name":"李四","sex":"男生","tel":"2222"}
{"index":{"_id":"1003"}}
{"name":"王五","sex":"女生","tel":"3333"}GET user/_search
{"query": {"match": {"name": "张"}}
}GET user/_search
{"query": {"match": {"sex": "男"}}
}GET user/_search
{"query": {"match": {"tel": "1111"}}
}# keyword 可以聚合
GET user/_search
{"aggs": {"sex_group": {"terms": {"field": "sex"}}},"size": 0
}# text 不可以聚合
GET user/_search
{"aggs": {"name_group": {"terms": {"field": "name"}}},"size": 0
}
常见 type 类型
- String 类型
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerica:数值型
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点的高精度类型:sacled_float
- Date:日期类型
- Array:数组类型
- Object:对象
Java API 操作
依赖
<dependencies><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!-- elasticsearch 的客户端 --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.8.0</version></dependency><!-- elasticsearch 依赖 2.x 的 log4j --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.78</version></dependency><!-- junit 单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies>
环境测试
public class EsClient {public static void main(String[] args) throws IOException {// 创建 ES 客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));// 关闭 ES 客户端esClient.close();}
}
索引操作
创建索引
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));CreateIndexRequest request = new CreateIndexRequest("user_v1");CreateIndexResponse response = esClient.indices().create(request, RequestOptions.DEFAULT);System.out.println(response.isAcknowledged());esClient.close();}
查询索引信息
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));GetIndexRequest request = new GetIndexRequest("user_v1");GetIndexResponse response = esClient.indices().get(request, RequestOptions.DEFAULT);System.out.println(response.getMappings());System.out.println(response.getAliases());System.out.println(response.getSettings());esClient.close();}
删除索引信息
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));DeleteIndexRequest request = new DeleteIndexRequest("user_v1");AcknowledgedResponse delete = esClient.indices().delete(request, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged());esClient.close();}
文档操作
创建文档
public class EsDocCreate {public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));IndexRequest request = new IndexRequest("user_v1");request.id("1003");User user = new User("张三", "男生", "1111");request.source(JSON.toJSONString(user), XContentType.JSON);IndexResponse index = esClient.index(request, RequestOptions.DEFAULT);System.out.println(index.getResult());esClient.close();}
局部修改
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));// 局部修改UpdateRequest request = new UpdateRequest("user_v1", "1003");request.doc(XContentType.JSON, "name", "zhangsan");UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);System.out.println(response.getResult());esClient.close();}
根据ID 检索文档
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));GetRequest request = new GetRequest("user_v1", "1003");GetResponse response = esClient.get(request, RequestOptions.DEFAULT);System.out.println(response.getSource());esClient.close();}
文档删除
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));DeleteRequest request = new DeleteRequest("user_v1", "1002");DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);System.out.println(response.getResult());esClient.close();}
批量更新
将操作打包,批量发送给 ES 集群。
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));BulkRequest request = new BulkRequest();// 新增IndexRequest indexRequest = new IndexRequest("user_v1");indexRequest.id("1004");indexRequest.source(JSON.toJSONString(new User("李四", "男生", "4444")), XContentType.JSON);// 新增IndexRequest indexRequest2 = new IndexRequest("user_v1");indexRequest2.id("1005");indexRequest2.source(JSON.toJSONString(new User("王五", "女生", "5555")), XContentType.JSON);// 删除DeleteRequest deleteRequest = new DeleteRequest("user_v1", "1001");request.add(indexRequest);request.add(indexRequest2);request.add(deleteRequest);BulkResponse responses = esClient.bulk(request, RequestOptions.DEFAULT);System.out.println(responses.getItems());esClient.close();}
高级检索
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest request = new SearchRequest("user_v1");// 检索全部数据request.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);for (SearchHit searchHit : response.getHits()) {System.out.println(searchHit.getSourceAsString());}esClient.close();}
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest request = new SearchRequest("shopping");request.source(new SearchSourceBuilder().query(QueryBuilders.matchQuery("category", "小米")).from(0) // 分页.size(10).sort("price", SortOrder.DESC) // 排序);// request.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("category","小米")));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);for (SearchHit searchHit : response.getHits()) {System.out.println(searchHit.getSourceAsString());}esClient.close();}
多条件检索
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));// 构建查询的请求体SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();// andboolQueryBuilder.must(QueryBuilders.matchQuery("category","小米"));// notboolQueryBuilder.mustNot(QueryBuilders.matchQuery("price","5999"));// orboolQueryBuilder.should(QueryBuilders.matchQuery("category","华为"));sourceBuilder.query(boolQueryBuilder);SearchRequest request = new SearchRequest("shopping");request.source(sourceBuilder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);for (SearchHit searchHit : response.getHits()) {System.out.println(searchHit.getSourceAsString());}esClient.close();}
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));// 构建高亮字段HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags("<font color='red'>");highlightBuilder.postTags("</font>");highlightBuilder.field("name");SearchRequest request = new SearchRequest("shopping");request.source(new SearchSourceBuilder().query(QueryBuilders.rangeQuery("price").gt(0) // 范围查询.lt(6000)).highlighter(highlightBuilder));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);for (SearchHit searchHit : response.getHits()) {System.out.println(searchHit.getSourceAsString());}esClient.close();}
聚合
public static void main(String[] args) throws IOException {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest request = new SearchRequest("shopping");request.source(new SearchSourceBuilder().aggregation(AggregationBuilders.max("maxPrice").field("price")));
// request.source(new SearchSourceBuilder().aggregation(AggregationBuilders.min("minPrice").field("price")));
// request.source(new SearchSourceBuilder().aggregation(AggregationBuilders.avg("avgPrice").field("price")));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);if (response.getAggregations().iterator().hasNext()) {ParsedMax parsedMax = (ParsedMax) response.getAggregations().iterator().next();
// ParsedMin parsedMin = (ParsedMin) response.getAggregations().iterator().next();
// ParsedAvg parsedAvg = (ParsedAvg) response.getAggregations().iterator().next();System.out.println(parsedMax.getValue());}System.out.println(response);esClient.close();}
分组聚合
RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest request = new SearchRequest("shopping");request.source(new SearchSourceBuilder().aggregation(AggregationBuilders.terms("price_group").field("price")));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);if (response.getAggregations().iterator().hasNext()) {ParsedLongTerms parsedMax = (ParsedLongTerms) response.getAggregations().iterator().next();for (Terms.Bucket bucket : parsedMax.getBuckets()) {System.out.println(bucket.getKey() + "\t" + bucket.getDocCount());}}esClient.close();
ES 集群
单点服务器的问题:
- 存储容量有限
- 容易出现单点故障,无法实现高可用
- 并发处理能力有限
搭建集群
修改配置文件
node.master:表示节点是否具有成为主节点的资格。
node.data:表示节点是否存储数据。
Node 节点组合:
- 主节点 + 数据节点(master + data)即有称为主节点的资格,又存储数据
- 数据节点(data):不参与选举,只会存储数据
- 客户端节点(client):不会成为主节点,也不会存储数据,主要是针对海量请求的时候,可以进行负载均衡
一个 Mac 上起 3 es 进程
添加如下配置:config/elasticsearch.yml
节点1 配置
# 加入如下配置
# 集群名称
cluster.name: my-application
# 节点名称,每个节点的名称不能重复
node.name: node-01
# 是不是有资格主节点
node.master: true
node.data: true http.port: 9201
transport.tcp.port: 9301# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: truecluster.initial_master_nodes: ["node-01", "node-02", "node-03"]
discovery.seed_hosts: ["127.0.0.1:9301", "127.0.0.1:9302", "127.0.0.1:9303"]
节点2 配置
# 加入如下配置
# 集群名称
cluster.name: my-application
# 节点名称,每个节点的名称不能重复
node.name: node-02
# 是不是有资格主节点
node.master: true
node.data: true http.port: 9202
transport.tcp.port: 9302# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: truecluster.initial_master_nodes: ["node-01", "node-02", "node-03"]
discovery.seed_hosts: ["127.0.0.1:9301", "127.0.0.1:9302", "127.0.0.1:9303"]
节点3 配置
# 加入如下配置
#集群名称
cluster.name: my-application
#节点名称,每个节点的名称不能重复
node.name: node-03
#是不是有资格主节点
node.master: true
node.data: true http.port: 9203
transport.tcp.port: 9303# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: truecluster.initial_master_nodes: ["node-01", "node-02", "node-03"]
discovery.seed_hosts: ["127.0.0.1:9301", "127.0.0.1:9302", "127.0.0.1:9303"]
注意:
- yaml 中数组第一个元素前必须有空格。
- 在启动 ES 节点前,将 data 目录下的数据清空。
// http://127.0.0.1:9201/_cluster/health
{"cluster_name": "my-application","status": "green","timed_out": false,"number_of_nodes": 3,"number_of_data_nodes": 3,"active_primary_shards": 1,"active_shards": 2,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100.0
}http://127.0.0.1:9201/_cat/nodes192.168.3.228 22 79 23 2.61 cdfhilmrstw - node-02
192.168.3.228 19 79 23 2.61 cdfhilmrstw * node-01
192.168.3.228 18 79 17 2.61 cdfhilmrstw - node-03
配置 kibana
配置:config/kibana.yml
# 默认值:http://localhost:9200
elasticsearch.hosts: ["http://localhost:9201", "http://localhost:9202", "http://localhost:9203"]
启动 kibana
bin/kibana
ES 进阶
核心概念
分片
分片:类似数据库中分库分表的概念。
分片的优点
- 可以水平分割/扩展内容容量
- 在分片之上可以进行分布式并行操作,进而提高性能/吞吐量
一个分片就是一个 Lucene 索引。
副本
副本:分片的备份,类似数据库中的从库。
副本的优点
- 防止数据丢失,提供高可用性。一本主分片和副本不会放在同一个节点上。
- 扩展吞吐量,因为搜索可以在所有副本上并行运行。
写流程
新建,删除
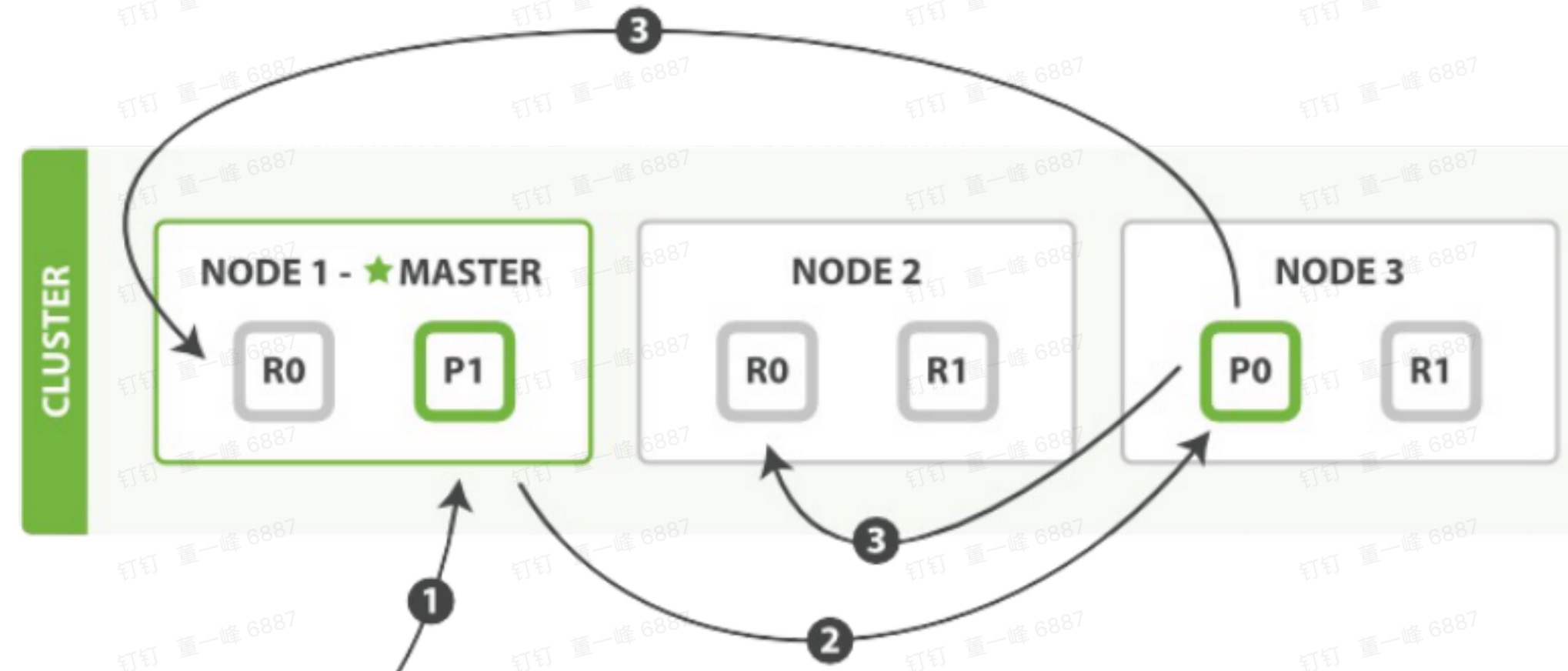
- 客户端向 Node 1 发送新建、索引、删除请求(Node 1 是协调节点)。
- Node 1 根据文档 _id 计算出属于 分片 0,通过集群状态中的内容路由表,获知分片 0 的主分片位于 Node3,于是将请求转发给 Node 3。
- Node 3 在主分片上执行请求(写请求),如果成功,它转发到 Node 1 和 Node 2 的副分片上。当所有的副节点报告成功,Node 3 报告成功给协调节点(Node 1),协调节点在报告给客户端。
路由算法
路由计算公式:shard_num = hash( _routing) % num_primary_shards
默认情况:_routing 值就是文档 id
这就是为什么主分片数在创建索引时定义而且不能修改
局部更新
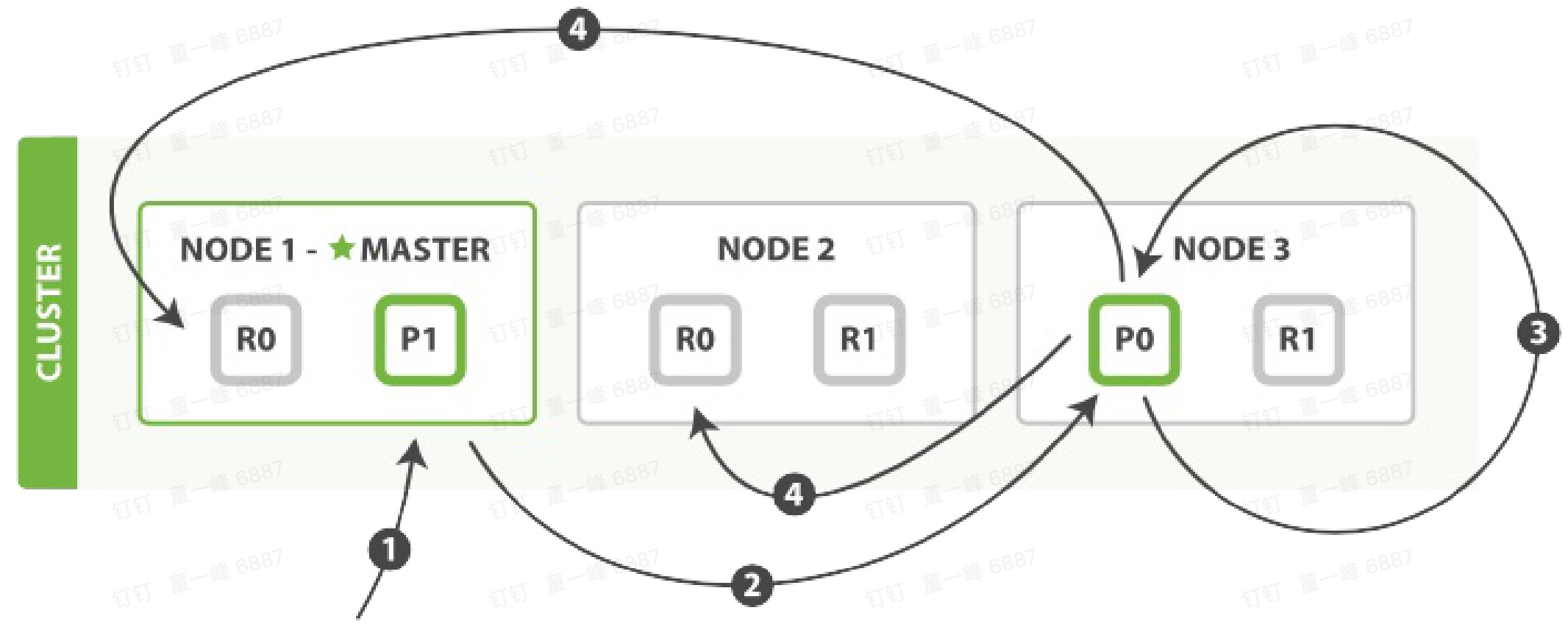
- 客户端向 Node 1 发送一个更新请求。
- 路由到 0 分片上,于是将请求转发给 Node 3(因为Node 3 有 0 主分片)
- Node 3 从主分片上检索出文档,修改 _source 字段的 Json,然后在主分片上重建索引。如果有其他进程修改了文档,它以 retry_on_conflict 设置的次数重复步骤3,都未成功则放弃。
- 如果 Node 3 成功更新了文档,它同时转发(异步,不保证顺序)文档到 Node1 和 Node 2 上的复制分片上重建索引。当所有复制节点报告成功,Node 3 放回成功给请求节点(Node 1),然后返回给客户端。
GET 流程
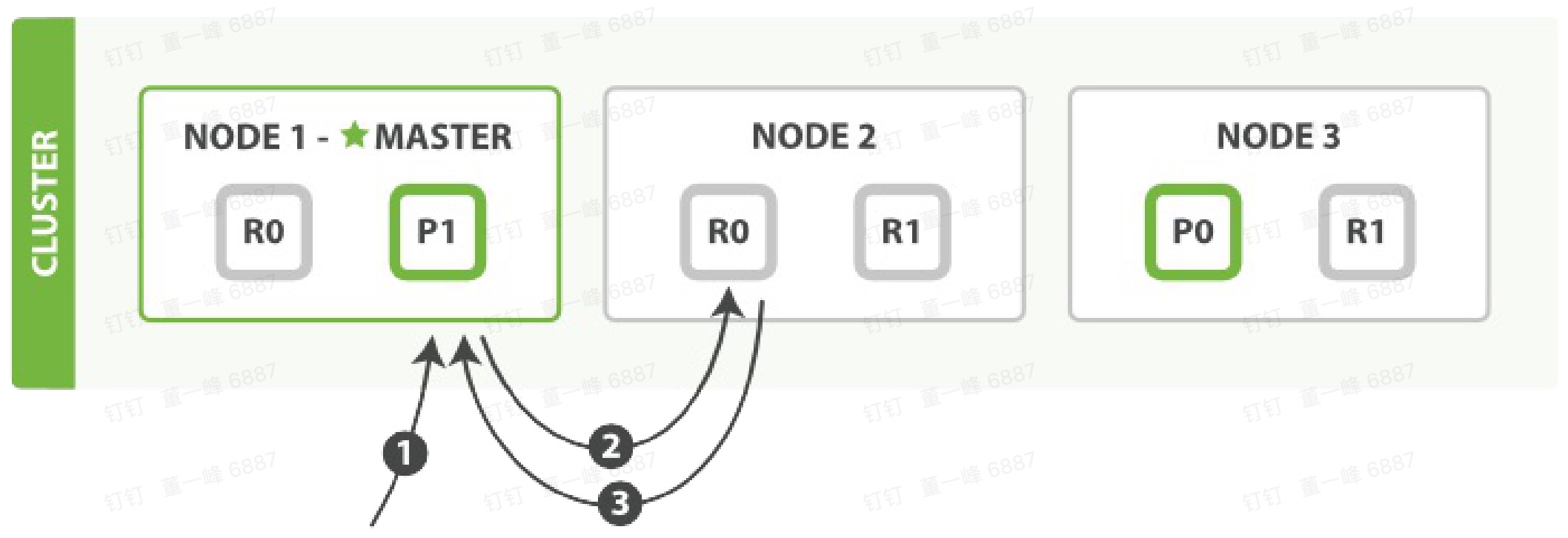
- 客户端向 Node 1 发送 get 请求。
- 路由到 分片 0,分片 0 在 3 个节点上都有。此时它转发给 Node 2.
- Node 2 返回 endangered 给 Node 1,Node 1 返回给客户端。
注意:对于读请求,为了负载平衡,请求节点( Node1 )会为每一个请求选择不同的分片(循环所有分片副本)。
多文档模式
MGet
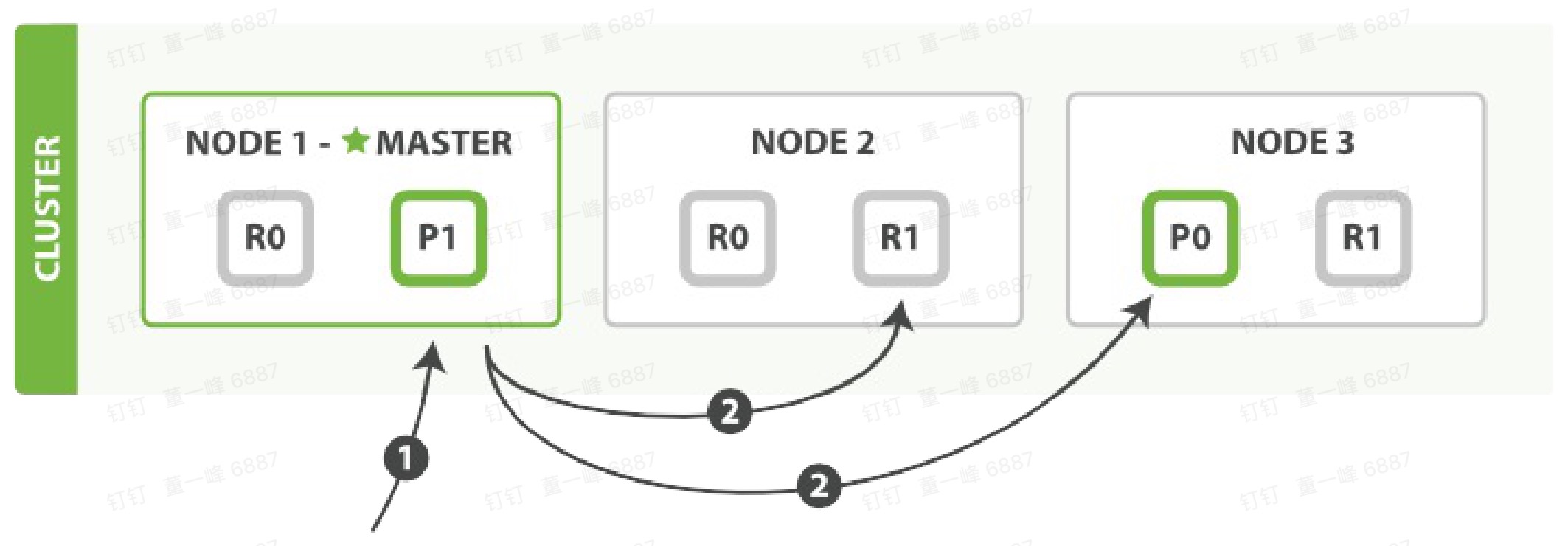
- 客户端向 Node 1发送 mget 请求。
- Node 1,为每个分片构建一个多条数据的检索,然后转发这些请求去所需的主分片或者复制分片上。当所有回复被接收,Node 1 构建响应并返回给客户端。
bulk
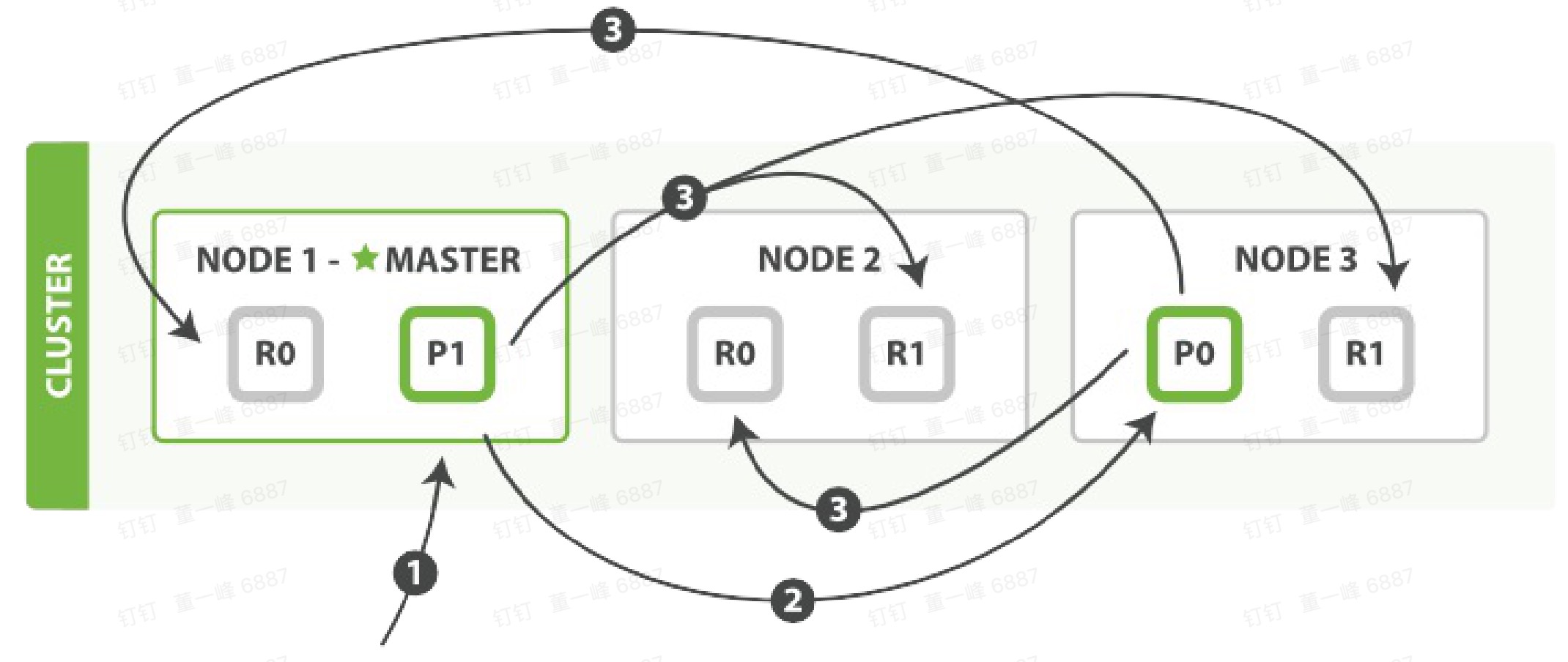
- 客户端向 Node 1发送 bulk 请求。
- Node 1,为每个分片构建批量请求,然后转到这些所需的主分片上。
- 主分片顺序执行操作。当一个操作执行完毕后,主分片转发新文档(或者删除部分)给对应的复制分片,然后执行下一个操作。复制节点报告所有操作完成,节点报告给请求节点(Node 1),Node 1 构建响应并返回给客户端。
Search 流程
query 阶段
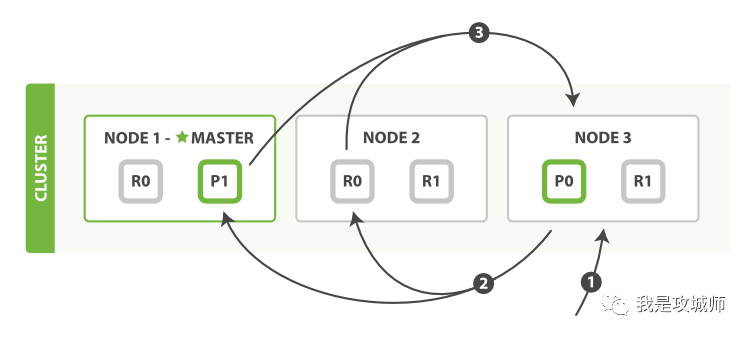
- 客户端发送 search 请求到 Node3(协调节点)
- Node 3 将请求转发到索引的每个主分片或者副分片
- 每个分片在本地执行查询,并使用本地的 Term/Document Frequency 信息进行打分,添加结果到大小为 from + size 的本地有序队列中。
- 每个分片返回各自优先队列中所有的文档 ID 和排序值给协调节点,协调节点合并这些值到自己的优先级队列中,产生一个全局排序后的列表。
注意: 为了避免在协调节点中创建的 number_of_shards * ( from + size ) 优先队列过大,应尽量控制分页深度。
fetch 阶段
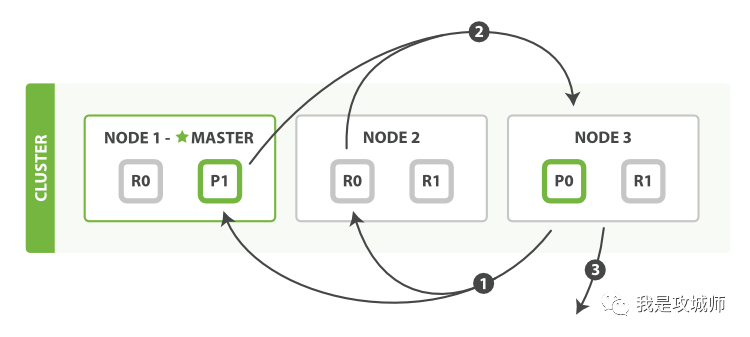
- 协调节点向相关 Node 发送 MGET 请求。
- 分片所在节点向协调节点返回数据。
- 协调节点等待所有文档被取得,然后返回给客户端。
ES 集成
Spring Data 框架集成
Spring Data 是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的
开源框架。
Spring Data Elasticsearch
官方网站: https://spring.io/projects/spring-data-elasticsearch
mvn 依赖
<dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-test</artifactId></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId></dependency></dependencies>
配置文件:application.properties
# es服务地址
elasticsearch.host=127.0.0.1
# es服务端口
elasticsearch.port=9200
# 配置日志级别,开启 debug 日志
logging.level.com.atguigu.es=debug
索引操作
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataIndexTest {// 注入 ElasticsearchRestTemplate@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;@Testpublic void createIndex() {// 创建索引,系统会自动化创建索引System.out.println("创建索引");}@Testpublic void deleteIndex() {elasticsearchRestTemplate.deleteIndex(Product.class);}
}
文档操作
@Repository
public interface ProductDao extends ElasticsearchRepository<Product,Long> {
}@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESProductDaoTest {@AutowiredProductDao productDao;// 新增@Testpublic void save() {Product product = Product.builder().id(1L).title("华为手机").category("手机").price(9999.0).images("https://xavatar.imedao.com/community/201011/1293612628607-20121221.png!240x240.jpg").build();productDao.save(product);}// 修改@Testpublic void update() {Product product = Product.builder().id(1L).title("小米手机").category("手机").price(9999.0).images("https://xavatar.imedao.com/community/201011/1293612628607-20121221.png!240x240.jpg").build();productDao.save(product);}// 根据 Id 查询@Testpublic void findById() {Product product = productDao.findById(1L).get();System.out.println(product);}// 查询全部@Testpublic void findAll() {Iterable<Product> iterable = productDao.findAll();for (Product product : iterable) {System.out.println(product);}}// 删除@Testpublic void delete() {Product product = Product.builder().id(1L).build();productDao.delete(product);}// 批量插入@Testpublic void saveAll() {List<Product> productList = new ArrayList<>();for (int i = 0; i < 10; i++) {Product product = Product.builder().id(Long.valueOf(i)).title(i + "小米手机").category("手机").price(9999.0 + i).images("https://xavatar.imedao.com/community/201011/1293612628607-20121221.png!240x240.jpg").build();productList.add(product);}productDao.saveAll(productList);}// 分页查询@Testpublic void findByPageable() {Sort sort = Sort.by(Sort.Direction.DESC, "id");int page = 0;int size = 5;PageRequest pageRequest = PageRequest.of(page, size, sort);Page<Product> data = productDao.findAll(pageRequest);for (Product product : data.getContent()) {System.out.println(product);}}
}
文档检索
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataEsSearchTest {@AutowiredProductDao productDao;// term 检索@Testpublic void termQuery(){TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> iterable = productDao.search(termQueryBuilder);for (Product product : iterable) {System.out.println(product);}}// term 检索加分页@Testpublic void termQueryByPage(){Sort sort = Sort.by(Sort.Direction.DESC, "id");int page = 0;int size = 5;PageRequest pageRequest = PageRequest.of(page, size, sort);TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> iterable = productDao.search(termQueryBuilder,pageRequest);for (Product product : iterable) {System.out.println(product);}}
}
相关文章:
Elasticsearch 入门
ES 概述 ES 是一个开源的高扩展的分布式全文搜索引擎。 倒排索引 环境准备 Elasticsearch 官方地址:https://www.elastic.co/cn/ 下载地址: 注意:9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 h…...

WebSocket 集成 Spring Boot 的实战指南
🍁 作者:知识浅谈,CSDN签约讲师&博客专家,华为云云享专家,阿里云专家博主,InfoQ签约作者 📌 擅长领域:全栈工程师、爬虫、ACM算法,大数据,深度学习 &…...
无人机集群路径规划:四种优化算法(BKA、CO、PSO、PIO)求解无人机集群路径规划,提供MATLAB代码
一、单个无人机路径规划模型介绍 无人机三维路径规划是指在三维空间中为无人机规划一条合理的飞行路径,使其能够安全、高效地完成任务。路径规划是无人机自主飞行的关键技术之一,它可以通过算法和模型来确定无人机的航迹,以避开障碍物、优化…...

第二届 龙信杯 电子数据取证竞赛部分Writeup
大佬文章: 龙信杯复现(23、24) | BthclsBlog 手机部分 资料:2024年第二届龙信杯 WP_2024龙信杯wp-CSDN博客 1.分析手机检材,请问此手机共通过adb连接过几个设备?[标准格式:3] 2 /data/a…...

偷啥的都有!
好久不做地铁了,昨个儿加班儿太晚,就没骑车回家。早上到了地铁站,想起我前一阵儿下雨时候,把自行车放在了地铁站,结果尾灯被人偷了! 真是偷啥的都有! 2024年10月15日 7:41...

【中文注释】planning_scene_tutorial.cpp
planning_scene_tutorial.cpp #include <rclcpp/rclcpp.hpp>// MoveIt 相关头文件 #include <moveit/robot_model_loader/robot_model_loader.h> #include <moveit/planning_scene/planning_scene.h> #include <moveit/kinematic_constraints/utils.h>…...

【Vue3】 h()函数的用法
目录 介绍 参数 使用案例 1.创建虚拟 DOM 元素 2. 组件的动态渲染 3. 创建功能组件 4.渲染动态属性 5. 使用插槽 6. 创建动态标签 介绍 h() 函数用于辅助创建虚拟 DOM 节点,它是 hypescript 的简称——能生成 HTML (超文本标记语言) 的 JavaScript&#x…...

Flask如何实现前后端分离项目
在现代Web开发中,前后端分离是一种常见的架构模式,其中前端和后端分别独立开发和部署,通过API进行通信。Flask作为后端框架,可以很容易地与前端框架(如React、Vue.js或Angular)配合使用来实现前后端分离。以…...

二维码生成器 1.02.41| 一站式QR码生成器和美化工具
二维码生成器是一个有用的QR码生成器应用程序。可以轻松地为网站链接、文本、WiFi、名片、短信、社交媒体账户等生成QR码。该应用支持更改QR码的颜色、码眼图案和框架,并可以添加徽标和文本,使QR码更加美观。使用此QR码生成器,可以使用设计精…...

腾讯云视立方·直播 SDK 合规使用指南
为帮助使用直播 SDK 的开发运营者(以下简称“您”)在符合个人信息保护相关法律法规、政策及标准的规定下合规接入、使用第三方SDK,深圳市腾讯计算机系统有限公司(以下简称"我们")特制定《直播 SDK 接入使用说…...

在 Spring 中使用 @EhCache 注解作为缓存
文章目录 项目概况项目设置一个简单的 RESTful Web 服务Spring 整合 EhCache第 1 步:更新依赖项以使用 EhCache Spring 注解第 2 步:设置自定义缓存管理器第 3 步:配置 EhCache第 4 步:测试缓存 刷新缓存总结推荐阅读文章 EhCache…...

npm install进度卡在 idealTree:node_global: sill idealTree buildDeps
ping一下源:ping http://registry.npm.taobao.org/ ping不通,原因:原淘宝npm永久停止服务,已更新新域名~~震惊!!! 重新安装:npm config set registry https://registry.npmmirror.c…...

力扣1031. 两个非重叠子数组的最大和
力扣1031. 两个非重叠子数组的最大和 题目解析及思路 题目要求找到两段长分别为firstLen 和 secondLen的子数组,使两段元素和最大 图解见灵神 枚举第二段区间的右端点,在左边剩余部分中找出元素和最大的第一段区间,并用前缀和优化求子数组…...

【Unity实战篇】 接入百度翻译,实现文本自动翻译功能
前言【Unity实战篇】 接入百度自动翻译,实现文本自动翻译功能一、获取百度翻译开发平台的APPID和密钥二、Unity中接入自动翻译功能三、Unity中实现自动翻译文本Text功能总结前言 日常在做项目的过程中,游戏本地化几乎已经成为必不可少的一步。本篇文章将演示怎样在Unity中接入…...

ubuntu samba
参考: 基于Ubuntu22.04的Samba服务器搭建教程(新手保姆级教程)_ubuntu samba-CSDN博客 当时按照这个不行: 主要做了这些修改 1、ufw 打开端口 这些都打开了 Samba服务使用的端口和协议如下1234: Port 137 (UDP) - NetBIOS 名…...

Linux系统和数据库常用的命令2
Linux系统和数据库常用的命令2 1、两台Linux机器ssh免密登录 client端登录server端需要免密,只需把公钥发送到server就可,会在server端生成一个authorized_keys文件 # 108机器上[rootclient ~]# ssh-keygen -t rsa // 非对称算法 Generating public/…...

Golang | Leetcode Golang题解之第468题验证IP地址
题目: 题解: func validIPAddress(queryIP string) string {if sp : strings.Split(queryIP, "."); len(sp) 4 {for _, s : range sp {if len(s) > 1 && s[0] 0 {return "Neither"}if v, err : strconv.Atoi(s); err …...

mermaid 图表相关
1.mermaid图表的代码 1.1 flowchart 流程图代码 flowchart TDA[Christmas] -->|Get money| B(Go shopping)B --> C{Let me think}C -->|One| D[Laptop]C -->|Two| E[iPhone]C -->|Three| F[fa:fa-car Car]1.2 sequece 时序图代码 sequenceDiagramAlice->&…...

Unity接入人工智能
在Unity接入人工智能中,本篇实现了接入百度智能云ai进行npc智能对话,通过http方式,并非插件,适合于所有支持Http链接的Unity版本。对于Chartgpt可以参考本篇内容的实现过程。 1-4节讲解测试,第5节讲解Unity中的实现&a…...

C语言笔记 14
函数原型 函数的先后关系 我们把自己定义的函数isPrime()写在main函数上面 是因为C的编译器自上而下顺序分析你的代码,在看到isPrime的时候,它需要知道isPrime()的样子——也就是isPrime()要几个参数,每个参数的类型如何,返回什么…...

订单簿处理全面解析:从技术原理到实战优化
订单簿处理全面解析:从技术原理到实战优化 【免费下载链接】AXOrderBook A股订单簿工具,使用逐笔行情进行订单簿重建、千档快照发布、各档委托队列展示等,包括python模型和FPGA HLS实现。 项目地址: https://gitcode.com/gh_mirrors/ax/AXO…...
)
用Verilog手搓一个IEEE754浮点加法器:从状态机设计到FPGA上板验证(附完整代码)
从零构建IEEE754浮点加法器:Verilog状态机设计与FPGA实战全解析 1. 浮点运算器的工程实现挑战 在数字信号处理和高性能计算领域,浮点运算器一直是核心组件。与整数运算不同,浮点数的特殊存储格式使得其运算过程复杂得多。IEEE754标准定义了浮…...
)
从医院呼叫器到智能家居:用Multisim 14.2复刻经典八路呼叫器(附完整仿真文件)
从医院呼叫器到智能家居:用Multisim 14.2复刻经典八路呼叫器(附完整仿真文件) 在电子技术发展的历史长河中,经典电路设计往往蕴含着跨越时代的智慧。八路呼叫器作为数字电子技术的经典教学案例,其核心模块——编码、锁…...
)
UniAD高版本环境实战:CUDA11.6+PyTorch1.12避坑全记录(附完整依赖清单)
UniAD高版本环境实战:CUDA11.6PyTorch1.12避坑全记录(附完整依赖清单) 当计算机视觉工程师尝试复现前沿论文时,环境配置往往成为第一道门槛。UniAD作为自动驾驶领域的统一大模型,其官方文档推荐的环境配置(…...

DeepSeek 服务故障,稳定性挑战待解
3 月 29 日晚至 30 日上午,DeepSeek 网页和 App 连崩 10 多个小时。这已不是其首次出问题,随着可能发布的 DeepSeek - V4,系统稳定性成梁文锋亟待解决的难题。事故回顾3 月 29 日 21:35,DeepSeek 网页/APP 服务异常,23…...

提升大语言模型对话体验:text-generation-webui全流程优化指南
提升大语言模型对话体验:text-generation-webui全流程优化指南 【免费下载链接】text-generation-webui A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. 项目地址: https://gitcode.com/G…...

ESP32-IDF开发实战:内置JTAG与OpenOCD高效调试指南
1. 为什么选择ESP32内置JTAG调试? 第一次接触ESP32开发时,你可能会有疑问:市面上这么多调试工具,为什么非要折腾内置JTAG?我刚开始用串口打印调试信息,后来发现这种方法在排查复杂逻辑时效率太低。直到尝试…...

Midscene.js视觉驱动自动化:从认知到实践的AI跨平台控制指南
Midscene.js视觉驱动自动化:从认知到实践的AI跨平台控制指南 【免费下载链接】midscene Let AI be your browser operator. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 一、认知篇:理解Midscene.js的技术革新 1.1 破解传统自动…...

Lingbot-Depth-Pretrain-ViTL-14 实战:Python爬虫获取图像数据并生成深度图
Lingbot-Depth-Pretrain-ViTL-14 实战:Python爬虫获取图像数据并生成深度图 你是不是也遇到过这样的场景:手头有一个很棒的深度估计模型,比如 Lingbot-Depth-Pretrain-ViTL-14,想用它来为自己的项目生成深度图,却发现…...
HyperFusion-DEIM:遥感影像中多路径关注与尺度感知融合的精确物体检测)
(论文速读)HyperFusion-DEIM:遥感影像中多路径关注与尺度感知融合的精确物体检测
论文题目:遥感影像中多路径关注与尺度感知融合的精确物体检测(Multi path attention and scale aware fusion for accurate object detection in remote sensing imagery)期刊:Scientific Reports摘要:在遥感图像中追求…...