RetinaNet 分类头和回归头的网络结构分析
RetinaNet 是由 Facebook AI Research(FAIR)在 2017 年提出的一种高效的一阶段(one-stage)目标检测算法。相比于两阶段(two-stage)方法,RetinaNet 通过引入 Focal Loss 解决了类别不平衡问题,从而在保持高检测速度的同时,实现了与两阶段方法相媲美的检测精度。
本文将深入解析 RetinaNet 的分类头和回归头的网络结构,并详细说明每一层的输入输出尺寸。
RetinaNet 总体架构概述
RetinaNet 主要由以下几个部分组成:
- 主干网络(Backbone):通常使用 ResNet(如 ResNet-50 或 ResNet-101)作为特征提取器。
- 特征金字塔网络(Feature Pyramid Network, FPN):在主干网络的不同层级生成多尺度的特征图。
- 分类头(Classification Head):用于对每个锚框(anchor)进行类别预测。
- 回归头(Regression Head):用于对每个锚框进行边界框回归(位置调整)。
下图展示了 RetinaNet 的整体架构、分类头和回归头的结构(图来自于B站up:霹雳吧啦Wz):


特征金字塔网络(FPN)
在深入讨论分类头和回归头之前,首先简要介绍 FPN 的输出。FPN 从主干网络的不同层级提取特征,并生成多个尺度的特征图,通常标记为 P3 到 P7,对应不同的下采样率(stride):
- P3: 下采样率 8,尺寸为 ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 )
- P4: 下采样率 16,尺寸为 ( H 16 × W 16 × 256 \frac{H}{16} \times \frac{W}{16} \times 256 16H×16W×256 )
- P5: 下采样率 32,尺寸为 ( H 32 × W 32 × 256 \frac{H}{32} \times \frac{W}{32} \times 256 32H×32W×256 )
- P6: 下采样率 64,尺寸为 ( H 64 × W 64 × 256 \frac{H}{64} \times \frac{W}{64} \times 256 64H×64W×256)
- P7: 下采样率 128,尺寸为 ( H 128 × W 128 × 256 \frac{H}{128} \times \frac{W}{128} \times 256 128H×128W×256)
其中,( H ) 和 ( W ) 分别为输入图像的高度和宽度。
分类头和回归头的网络结构
RetinaNet 的分类头和回归头结构基本相同,均由多个卷积层堆叠而成,但在最后的输出层有所不同。以下将分别详细介绍这两个头部的结构及其每一层的输入输出尺寸。
分类头(Classification Head)
分类头的任务是对每个锚框进行类别预测。其结构如下:
-
共享卷积层(Shared Convolutional Layers):
- 层 1: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 2: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 3: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 4: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
每一层后均接 ReLU 激活函数。
-
分类卷积层(Classification Convolutional Layer):
- 3x3 卷积,输入通道数 256,输出通道数 ( K × C K \times C K×C ),步幅 1,填充 1
其中:
- ( K ) 为每个位置的锚框数量(通常为 9)。
- ( C ) 为类别数量(不包括背景类)。
-
输出层:
- 最终输出通过 sigmoid 激活函数,生成每个锚框对应的类别概率。
输入输出尺寸示例(以 P3 为例,假设输入尺寸为 ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ):
| 层级 | 输入尺寸 | 卷积参数 | 输出尺寸 |
|---|---|---|---|
| 共享层 1 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 2 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 3 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 4 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 分类卷积层 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, ( K × C K \times C K×C ) 通道 | ( H 8 × W 8 × ( K × C ) \frac{H}{8} \times \frac{W}{8} \times (K \times C) 8H×8W×(K×C) ) |
| Sigmoid | 同上 | - | - |
回归头(Regression Head)
回归头的任务是对每个锚框进行边界框回归,预测边界框的偏移量。其结构与分类头基本相同,唯一区别在于最后的输出层。
-
共享卷积层(Shared Convolutional Layers):
- 层 1: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 2: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 3: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
- 层 4: 3x3 卷积,输入通道数 256,输出通道数 256,步幅 1,填充 1
每一层后均接 ReLU 激活函数。
-
回归卷积层(Regression Convolutional Layer):
- 3x3 卷积,输入通道数 256,输出通道数 ( K × 4 K \times 4 K×4 ),步幅 1,填充 1
其中:
- ( K ) 为每个位置的锚框数量(通常为 9)。
- 4 对应边界框的四个偏移量(中心点偏移量 ( t x , t y t_x, t_y tx,ty ),宽度和高度的对数尺度偏移量 ( t w , t h t_w, t_h tw,th )。
-
输出层:
- 最终输出通常不经过激活函数,直接输出回归偏移量。
输入输出尺寸示例(以 P3 为例,假设输入尺寸为 ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ):
| 层级 | 输入尺寸 | 卷积参数 | 输出尺寸 |
|---|---|---|---|
| 共享层 1 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 2 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 3 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 共享层 4 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, 256 通道 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) |
| ReLU | 同上 | - | - |
| 回归卷积层 | ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 ) | 3x3, stride=1, padding=1, ( K × 4 K \times 4 K×4 ) 通道 | ( H 8 × W 8 × ( K × 4 ) \frac{H}{8} \times \frac{W}{8} \times (K \times 4) 8H×8W×(K×4) ) |
| 无激活函数 | 同上 | - | - |
注:在此示例中,假设类别数量 ( C = 80 ),则分类卷积层输出通道数为 ( 9 × 80 = 720 9 \times 80 = 720 9×80=720)。
具体示例:以 P3 特征层为例
假设输入图像尺寸为 ( 512 × 512 512 \times 512 512×512 ),则 P3 的尺寸为 ( 64 × 64 × 256 64 \times 64 \times 256 64×64×256 )(即 ( 512 8 × 512 8 × 256 \frac{512}{8} \times \frac{512}{8} \times 256 8512×8512×256 ))。
分类头的层级尺寸
| 层级 | 输入尺寸 | 卷积参数 | 输出尺寸 |
|---|---|---|---|
| 共享层 1 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 2 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 3 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 4 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 分类卷积层 | 64 × 64 × 256 | 3x3, stride=1, padding=1, ( 9 × C 9 \times C 9×C ) 通道 | 64 × 64 × ( 9C ) |
| Sigmoid | 64 × 64 × ( 9C ) | - | - |
回归头的层级尺寸
| 层级 | 输入尺寸 | 卷积参数 | 输出尺寸 |
|---|---|---|---|
| 共享层 1 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 2 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 3 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 共享层 4 | 64 × 64 × 256 | 3x3, stride=1, padding=1, 256 通道 | 64 × 64 × 256 |
| ReLU | 64 × 64 × 256 | - | - |
| 回归卷积层 | 64 × 64 × 256 | 3x3, stride=1, padding=1, ( 9 × 4 9 \times 4 9×4 ) 通道 | 64 × 64 × 36 |
| 无激活函数 | 64 × 64 × 36 | - | - |
注:在此示例中,假设类别数量 ( C = 80 ),则分类卷积层输出通道数为 ( 9 × 80 = 720 9 \times 80 = 720 9×80=720)。
多尺度特征图的处理
RetinaNet 使用 FPN 生成多个尺度的特征图(P3-P7),每个特征图都会通过独立的分类头和回归头进行处理。因此,对于每个特征图,分类头和回归头的网络结构和层级尺寸类似,只是输入特征图的尺寸不同。
以 P4(下采样率 16,尺寸 ( H 16 × W 16 × 256 \frac{H}{16} \times \frac{W}{16} \times 256 16H×16W×256 ))为例,其分类头和回归头的每一层输入输出尺寸将是 ( H 16 × W 16 × 256 \frac{H}{16} \times \frac{W}{16} \times 256 16H×16W×256 ),最终输出为 ( H 16 × W 16 × ( 9 C ) \frac{H}{16} \times \frac{W}{16} \times (9C) 16H×16W×(9C) )(分类)和 ( H 16 × W 16 × 36 \frac{H}{16} \times \frac{W}{16} \times 36 16H×16W×36 )(回归)。
总结
RetinaNet 的分类头和回归头采用了相同的共享卷积层结构,具体如下:
- 共享卷积层:4 个 3x3 卷积层,每层 256 个通道,步幅 1,填充 1,后接 ReLU 激活。
- 输出卷积层:
- 分类头:1 个 3x3 卷积层,输出通道数为 ( K × C K \times C K×C )(通常为 9×类别数),后接 sigmoid 激活函数。
- 回归头:1 个 3x3 卷积层,输出通道数为 ( K × 4 K \times 4 K×4 )(9×4),不经过激活函数。
每个特征图(P3-P7)都会独立地通过分类头和回归头进行处理,从而实现多尺度的目标检测。
疑问
我在思考检测头的结构时,曾经问过一个现在看来可笑的问题:我觉得检测头的输出应该是 1 × 1 × 9 C 1\times1\times9C 1×1×9C,这样9C个通道,就是9C个数值,代表了每一种框被分类为每一类的概率,可为什么检测头的输出是 ( H 8 × W 8 × 256 \frac{H}{8} \times \frac{W}{8} \times 256 8H×8W×256 )呢?
Answer: 如果分类头的输出是 1 × 1 × 9 C 1\times1\times9C 1×1×9C,这意味着整个特征图只生成一个锚框的分类概率,这与 RetinaNet 的设计理念不符。RetinaNet 需要在图像的每一个空间位置上预测多个锚框,以便覆盖不同的位置和尺度的目标。所以实际上,该层特征图的尺寸是 H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W ,一共有 H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W这么多个像素,每个像素都要预测9个anchor属于某一类别的概率。(我的疑问完全是因为自己格局小了)
相关文章:
RetinaNet 分类头和回归头的网络结构分析
RetinaNet 是由 Facebook AI Research(FAIR)在 2017 年提出的一种高效的一阶段(one-stage)目标检测算法。相比于两阶段(two-stage)方法,RetinaNet 通过引入 Focal Loss 解决了类别不平衡问题&am…...

app测试有哪些内容?广东深圳软件测试机构推荐
随着智能手机的普及,手机应用app越来越多,因此,企业为了更好的保证用户留存率,开发完app之后必须进行app测试。一个成功的app,软件测试是必不可少的一步,那么app测试需要进行哪些测试内容呢?深圳又有哪些靠…...

新乡医学院第一附属医院启动巨额医疗设备整体维保招标
鉴于项目本身金额巨大,又恰逢省委巡视组进驻期间,该项目备受瞩目,在业内和省内医疗圈引起了极大轰动。全国影响力最大、实力最强的企业全部参与其中,民营企业上海柯渡医疗、上海昆亚医疗以其创新的服务模式和高效的管理机制备受关注;央企通用技术集团凯思轩达医疗科技凭借雄厚的…...

Linux——综合实用操作
目录 IP与主机 ping命令 wget命令 curl命令 端口:设备与外界通讯交流的出入口 进程管理 Linux top命令Windows 任务管理器 磁盘信息监控 df iostat 网络状态监控 sar -n DEV命令 环境变量 上传,下载 压缩 解压tar,zipÿ…...

一个Idea:爆改 T480
爆改 T480 准备大改 T480,家里有一台闲置很久的 T480,不舍得扔,打算升级一下。看了几位up主的视频后,决定动手改造。 计划如下 网卡:加装4G网卡硬盘:更换为 1T 的 NVMe 2280 固态硬盘内存:升…...

网络编程(21)——通过beast库快速实现http服务器
目录 二十一、day21 1. 头文件和作用域重命名 2. reponse时调用的一些函数 3. http_connection a. 构造函数 b. start() c. process_request() d. create_response() e. create_post_response() f. write_response() 4. Server 5. 主函数 6. 测试 1)测…...

Logback
Logback 简介 SpringBoot 内置日志框架 用来自定义控制台日志输出样式、生成日志文件 使用 由于是内置所以不需要引入,稍加配置就可以直接使用。 内置源头查看 配置application.yml # 日志配置 logging:level:com.ruoyi: logging.levelorg.springframework: war…...
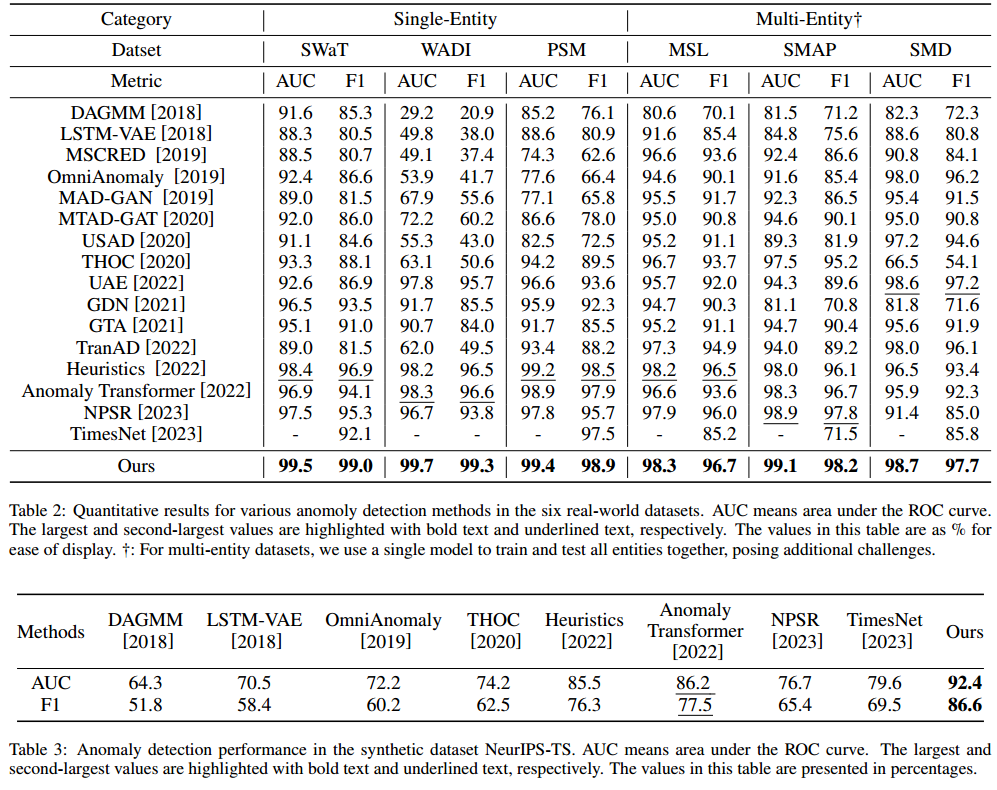
Sub - Adjacent Transformer — 对AT的有趣改进
出处:IJCAI 2024 未开源,链接貌似是:jackyue1994/Sub-Adjacent-Transformer (github.com) 贡献:1. 提出:基于 “次邻域” 及 “注意力贡献” 的注意力学习机制,以增强异常、正常的区分;2. 首次…...

『Mysql集群』Mysql高可用集群之主从复制 (一)
Mysql主从复制模式 主从复制有一主一从、主主复制、一主多从、多主一从等多种模式. 我们可以根据它们的优缺点选择适合自身企业情况的主从复制模式进行搭建 . 一主一从 主主复制 (互为主从模式): 实现Mysql多活部署 一主多从: 提高整个集群的读能力 多主一从: 提高整个集群的…...
的函数)
PHP获取图片属性(size, width, 和 height)的函数
在PHP中,要获取图片的尺寸(宽度和高度),你可以使用 getimagesize() 函数。这个函数不仅返回图片的宽度和高度,还返回图片的类型和MIME类型等信息。 以下是 getimagesize() 函数的基本用法: <?php /…...

MySQL启动失败解决方案
目录 引言 一、查看/启动mysql服务的两种方式 方法一: 方法二: 二、修改mysql服务启动路径的地址 三、"my.ini"文件的使用 设置my.ini文件的路径 给出一个使用my.ini文件的小例子 引言 造成启动闪退\失败的原因我仅仅以个人查询的一下博…...

Spring Boot中使用MyBatis-Plus和MyBatis拦截器来实现对带有特定注解的字段进行AES加密。
1. 添加依赖 首先,在pom.xml文件中添加必要的依赖项: xml 深色版本 <dependencies> <!-- Spring Boot Starter Web --> <dependency> <groupId>org.springframework.boot</groupId> <artifac…...
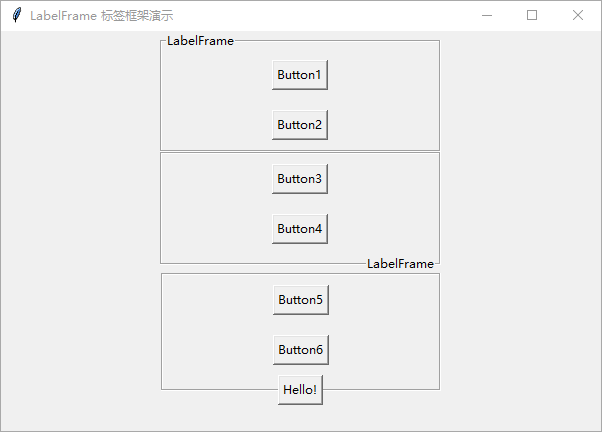
Python GUI 编程:tkinter 初学者入门指南——框架、标签框架
在本文中,将介绍 tkinter Frame 框架小部件、 LabelFrame 标签框架小部件的使用方法。 Frame 框架 Frame 框架在窗体上建立一个矩形区域,作为一个容器,用于组织分组排列其他小部件。 要创建框架,请使用以下构造函数。 frame …...

Mac 远程 Windows 等桌面操作系统工具 Microsoft Remote Desktop for Mac 下载安装详细使用教程
最近需要在 Mac 上远程连接控制我的 windows 电脑系统,经过一番尝试对于 win 来说还是微软自家推出的 Microsoft Remote Desktop for Mac 最最好用,没有之一 简介 Microsoft Remote Desktop是一款由微软公司开发的远程桌面连接工具,可以让用…...

初级网络工程师之从入门到入狱(四)
本文是我在学习过程中记录学习的点点滴滴,目的是为了学完之后巩固一下顺便也和大家分享一下,日后忘记了也可以方便快速的复习。 网络工程师从入门到入狱 前言一、Wlan应用实战1.1、拓扑图详解1.2、LSW11.3、AC11.4、抓包1.5、Tunnel隧道模式解析1.6、AP、…...

MinIO配置与使用
在数字化时代,数据存储与管理变得尤为重要,尤其是对于非结构化数据如日志文件的处理。MinIO,作为一个高性能、可扩展的分布式对象存储系统,以其对Amazon S3的全面兼容性和轻量级设计,成为了众多企业和开发者存储大量数…...

【漏洞复现】SpringBlade menu/list SQL注入漏洞
》》》产品描述《《《 致远互联智能协同是一个信息窗口与工作界面,进行所有信息的分类组合和聚合推送呈现。通过面向角色化、业务化、多终端的多维信息空间设计,为不同组织提供协同门户,打破组织内信息壁垒,构建统一协同沟通的平台。 》》》漏洞描述《《《 致远互联 FE协作办公…...

物联网智能项目(含案例说明)
物联网(Internet of Things,简称IoT)智能项目是指利用物联网技术将各种物理设备、传感器、软件、网络等连接起来,实现设备之间的互联互通,并通过数据采集、传输、处理和分析,实现智能化管理和控制的项目。以…...
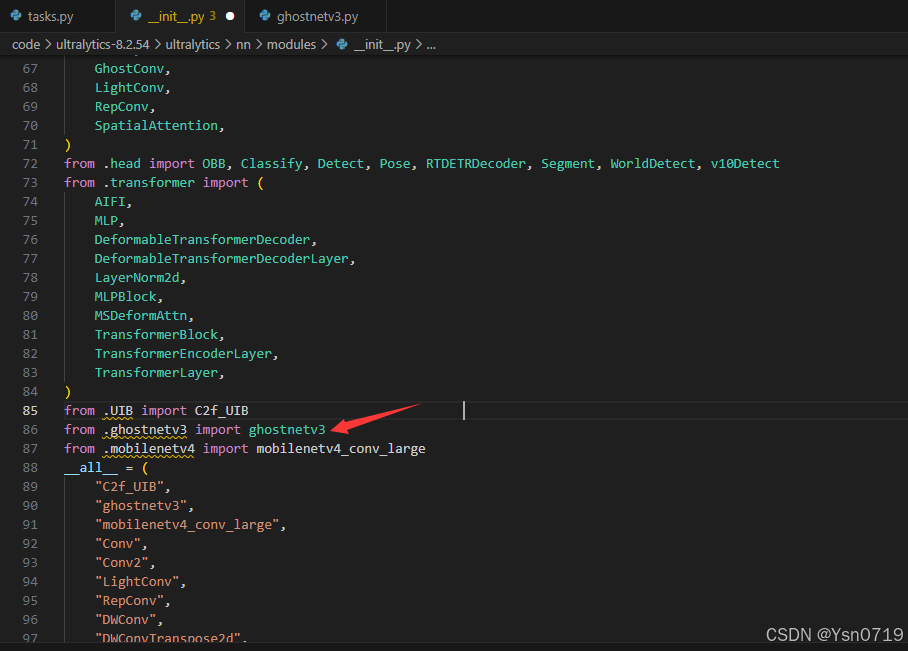
【YOLOv8改进】 YOLOv8 更换骨干网络之GhostNetV3步骤详解
这里yolov8源码版本是 ultralytics-8.2.54 GhostNetV3 源码下载 https://codeload.github.com/huawei-noah/Efficient-AI-Backbones 将ghostnetv3.py文件复制一份到源码./ultralytics-8.2.54/ultralytics/nn/modules路径下 我根据mobilenetv4的教程,修改了ghostne…...
成绩查询小程序,家长查分超方便~
这都马上2025年了,我不相信还有老师不知道怎么发成绩,如果你不知道,那么这篇文章不要错过,推荐给大家我用了7年的发成绩工具 易查分,新版本更新之后,发成绩只需要一分钟的时间即可生成一个成绩查询系统。 …...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...
)
Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践)
更多请点击: https://codechina.net 第一章:Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践) Lindy效应在自动化系统设计中揭示了一个关键洞察:越久经考验的实践,其未来预期寿命越长。Lindy多步…...