Collection 单列集合 List Set
集合概念
集合是一种特殊类 ,这些类可以存储任意类对象,并且长度可变, 这些集合类都位于java.util中,使用的话必须导包
按照存储结构可以分为两大类 单列集合 Collection 双列集合 Map 两种 区别如下
Collection 单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的的子接口, List Set
`List` 接口 特点是元素有序可重复 它的实现类有 **ArrayList LinkedList**`Set` 接口 特点是元素无序且不可重复它的实现类有 HashSet TreeSet
Map 双列集合类的根接口, 用于存储具有 键(Key) 值(Value) 隐射关系的元素,每个元素都包 含一对键值 ,其中键值不可重复且每个键 最多只能映射到到一个值,在使用Map集合时 可以通过指定的Key找到对应的Value,通一个人的学号找到学生的名字一样没有爸爸接口,只要爷爷接口Mpa 实现类有 HashMap TreeMap
Collection 单列集合根接口
单列集合的父接口,它定义了单例集合(List Set) 通用的一些方法,这样方法可用于操作所有的单列集合 ,,在开发中,往往很少直接使用 Collcetion 接口进行开发基本上都是使用其子接口,子接口主要有 List、Set、Queue和 SortedSeto
常用API
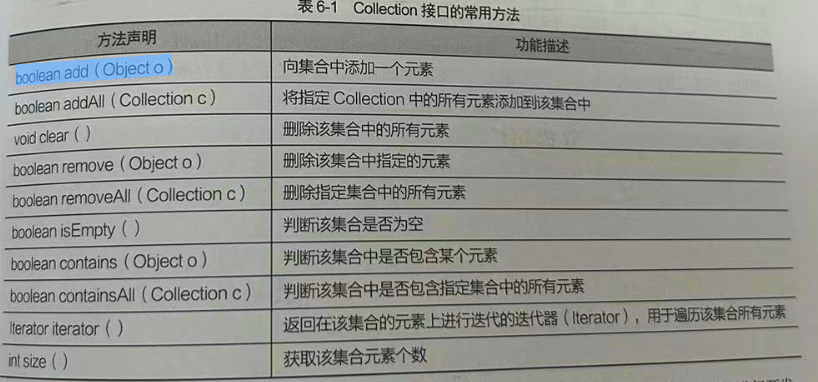
List接口
List接口继承父接口Collection 接口 ,是单列集合的一个重要分支,它允许出现重复的元素,所有元素都是以一种线性的方式存储的,通过索引访问List
集合中的指定元素,它的特点是有序** 即元素 存入和取出的 顺序一致**
List集合常用方法,上方父接口 Collection方法同样可以继承使用
List 的所有实现类都可以通过调用这些方法操作集合元素
| 方法声明 | 功能描述 |
| void add ( int index, Object element ) | 将元素 element 插入在List 集合的index处 |
| boolean addAll ( int index, Collection c ) | 将集合所包含的所有元素插入到List集合的index处 |
| Object get ( int index ) | 返回集合索引inde处的元素 |
| Object remove ( int index ) | 删除集合索引inde处的元素 |
| Object set ( int index, Object element | 将集合索引indx处 元素替换成element对象,并将替换后的元素返回 |
| int indexOf ( Object o ) | 返回对象o在List集合中出现的位置索引 |
| int lastlndexOf ( Object o ) | 返回对象o在List集合中最后一次出现的位置索引 |
| List subList ( int fromlndex, int tolndex ) | 返回从索引 fromindex(包括) 到toindex(不包括) 处所有元素组成的子集合 |
ArrayList实现类 查询 有序可重复
ArrayList是List 接口的一个实现类,它是程序中一种常见的集合,在ArrayList内部封装了一个长度可变的数组对象,当存入的元素
超过数组长度时 ArrayList会在内存中分配一个更大的数组来存储这些元素,因此可以将ArrayList集合看作一个长度灵活可变的数组
它的大部分方法都是继承父类Collection 和List接口的 其中 add()方法 和 get() 分别实现元素的存入和取出
import java.util.ArrayList;public class h {public static void main(String[] args) {ArrayList List = new ArrayList(); // 创建 ArrayList集合 相当于实现了List接口List.add(3);List.add("你好");List.add("世界");// 获取集合中元素的个数 size()方法是 Collection的System.out.println("集合的长度:"+List.size());// 取出并打印指定位置的元素 通过索引查找和数组一样从 0开始// 访问元素索引最好不要超过范围,否则会出现角标越界异常System.out.println("第2个元素是:"+List.get(1));}
}---------------------------------------------输出:集合的长度:3
第2个元素是:你好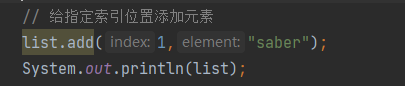
注意 :
由于Aaytist 集合的底层使用一个数组来保存元素,在增加或删除指定位置的元素时,会创建新的数组,效率很低 因此不适合大量的增加删除操作,
因为这种数组的结构允许程序通过索引的方式来访问问元素,所以 ArrayList集合查找元素很方法
LinkedList实现类 增删 有序可重复
LinkedList集合内部维护了一个双向循环表,链表中的每一个元素都使用了引用的方式来记住它的前一个元素或后一个元素,从而可以将所有的元素彼此连接起来,LikedList 集合进行元素的增加删除操作时效率很高,
常用方法
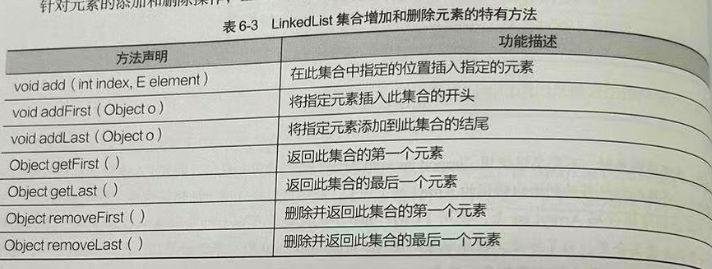
import java.util.LinkedList;public class g {public static void main(String[] args) {LinkedList link = new LinkedList(); // 创建了LinkeduList集合link.add(3);link.add("你好");link.add("世界");System.out.println(link.toString()); //取出并打印该集合的元素转换为字符串输出System.out.println(link); // 同样取出元素直接输出对象// 上面两个的区别在于两个打印语句的结果是相同的,只是输出格式不同。link.add(3,"saber"); // 向该集合中指定位置插入元素link.addFirst("插入"); // 向该集合第一个位置插入元素System.out.println(link.getFirst()); // 取出该集合中的第一个元素 插入link.remove(2); // 删除该集合中指定位置的元素 按照数组索引来 所以是第三个 看清楚System.out.println("会输出"+link);link.removeFirst(); // 删除该集合中的第一个元素System.out.println(link);}
}使用 LinkedList 对元素进行增加和删除操作是非常便捷的----------------------------------------------输出:[3, 你好, 世界]
[3, 你好, 世界]
插入
会输出 [插入, 3, 世界, saber]
[3, 世界, saber]lterator接口 遍历迭代器
接口Iterator 接口也是集合中的一员, 但是它与 Collection Map 有所不同, Collection接口和Map 接口主要是用于存储元素 而
Iteratore 主要用于迭代访问(即遍历) Collection 中的元素,因此 Iteratior对象也称迭代器
代码含义:hasNext()方法用于判断集合中是否还有下一个元素,如果有则返回true,否则返回false。如果返回true,
则可以使用next()方法取出下一个元素,并将其赋值给一个Object类型的变量obj。最后,使用System.out.println()方法将obj打印出来。
整个过程会一直重复,直到集合中的所有元素都被遍历完毕。因此,这段代码的作用是遍历ArrayList集合中的所有元素,并将它们打印出来。注意:通过next()方法获取元素时 必须保证获取元素的存在,否则会抛出 NoSuchElementException 异常 (无搜索元素异常)---------------------------------------------import java.util.ArrayList;
import java.util.Iterator;
public class f {public static void main(String[] args) {ArrayList list = new ArrayList();list.add("张三"); // 存入了集合就必须使用 Object类型接收list.add("李四");list.add("王五");list.add("赵六"); // 每一个集合迭代前都是必须通过下面的代码来获取迭代器Iterator it = list.iterator(); // 获取迭代器对象while (it.hasNext()){ // 判断ArrayList集合 是否存在下一个元素Object obj = it.next(); // 取出ArrayList集合中的元素 赋值给新的对象 objSystem.out.println(obj); // 依次打印出全部的时间}}
}-----------------------------------------------输出:张三
李四
王五
赵六迭代判断删除
使用迭代器对集合中的元素进行迭代时, 如果调用了集合对象的 remover() 方法删除元素,那么继续使用迭代器会出现异常,下面通过案例来演示说明
import java.util.Locale;public class e {public static void main(String[] args) {ArrayList list = new ArrayList();list.add("张三");list.add("李四");list.add("王五");list.add("赵六");Iterator it = list.iterator(); // 获取迭代器对象while (it.hasNext()){ // 判断ArrayList集合 是否存在下一个元素Object obj = it.next(); // 取出ArrayList集合中的元素if ("张三".equals(obj))list.remove(obj); // 删除后就也就不再继续}System.out.println(list); // 删除的是没有张三的集合}
}上述代码会报出错误,原因是迭代器在运行期间删除了元素,导致迭代次数发生了变化,迭代结果不准确,解决方案
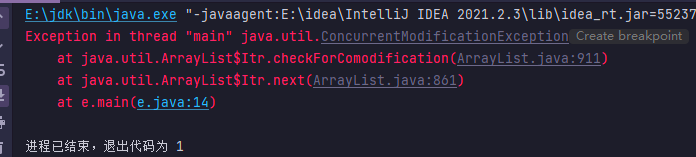
(1) 找到对应的名称字符删除后就使用 breack语句跳出循环不再继续迭代,
while (it.hasNext()){ // 判断ArrayList集合 是否存在下一个元素Object obj = it.next(); // 取出ArrayList集合中的元素if ("张三".equals(obj))list.remove(obj); // 删除后就也就不再继续break;(2) 使用迭代器本身的删除方法去进行删除,删除后所导致的迭代次数变化,对于迭代器本身是可预测的
while (it.hasNext()){ // 判断ArrayList集合 是否存在下一个元素Object obj = it.next(); // 取出ArrayList集合中的元素if ("张三".equals(obj))list.remove(); // 删除后就也就不再继续}foreach 循环
Iterator 虽然可以遍历集合中的元素,但是写法比较繁琐,简化书写提供了 foreach 循环,也称 增强for 循环, 它可以遍历数组或集合中的元素
语法格式:for(容器中元素类型 临时变量: 容器变量){执行语句
}和for循环相比foreach不再需要获得容器的长度,也不再需要根据索引访问,它会根据索引去访问容器的元素
`并且自动遍历容器中的每个元素`import java.util.ArrayList;
public class foreach {public static void main(String[] args) {ArrayList list = new ArrayList();list.add("张三");list.add("李四");list.add("王五");list.add("赵六");for (Object obj:list){// 循环遍历ArrayListSystem.out.println(obj); // 取出}}
}--------------------------------输出:张三
李四
王五
赵六循环局限性
当使用foreach 循环遍历集合和数组时,只能访问集合中的元素,不能对其中的元素进行修改, 下面是一个String 类型的数组,演示 foreach 局限性
public class foreach {static String[] strrs = {"aaa","ddd","ccccc"};public static void main(String[] args) {// foteach 遍历数组for(String str: strrs){str="ddd";}System.out.println("foreach循环修改后的数组"+strrs[0]+","+strrs[1]+","+strrs[2]);// for循环遍历数组for (int i= 0;i<strrs.length;i++){strrs[i]="ddd"; // 修改数据}System.out.println("循环修改后的数组"+strrs[0]+","+strrs[1]+","+strrs[2]);}
}-----------------------------------输出:foreach循环修改后的数组aaa,ddd,ccccc
循环修改后的数组ddd,ddd,dddforeach循环str=“ddd” 只是将临时的变量指向一个新的字符串并不能修改元素,for循环则是可以通过索引的方式对数组中的元素进行修改的
Set接口
Set接口和List接口一样,同样继承Collection 接口,方法和他基本一致, 功能上并没有扩充,反而更加严格,它的List接口不同在于, Set接口元素无序且不重复
实现类
- **HashSet **: 根据对象的散列值来确定元素在集合中存储的位置,具有良好的存取和查找功能
- TreeSet : 以二叉树方式存储元素,它可以实现对元素的排序
HashSet *实现类无序无重复
存储元素不可重复 意味着没有相同的,并且元素无序
import java.util.HashSet;
import java.util.Iterator;public class foreach {static String[] strrs = {"aaa","ddd","ccccc"};public static void main(String[] args) {HashSet set = new HashSet(); // 创建HashSet集合set.add("张三"); // 向集合中添加元素set.add("李四");set.add("王五");set.add("王五"); // 添加重复元素Iterator it = set.iterator(); // 获取迭代器接口while (it.hasNext()){ // while 判断集合是否有元素Object obj = it.next(); // 如果有元素则通过迭代器 next() 获取元素System.out.println(obj); // 打印获取到的元素}}
}-----------------------------------------------输出:李四
张三
王五注意:
取出元素和添加元素并不一致,并且重复添加的元素只出现了一次,它之所以可以确保不出现重复的元素,做了很多工作, add 添加元素时,首先调用存入对象的 hashCode() 方法获得对象的散列值,然后根据元素的散列值计算出特有的存储位置**, 散列值还是看数据类型是否相等的**, 只要数据类型相等,里面数字相等那么就是一样的,如果出现 String 字符串的100 和 int 类型的 100 其实是不同的,因为数据类型不同,并且 equals使用的前提也是相同数据类型比较字符串类型一致,详见String字符串 Random数字运算、
上面是不相同的情况,相同情况则是计算哈希后,进行equals 比较,如果比较存在,则是舍弃 没有则是加入
import java.util.HashSet;
import java.util.Iterator;public class foreach {static String[] strrs = {"aaa","ddd","ccccc"};public static void main(String[] args) {HashSet set = new HashSet(); // 创建HashSet集合set.add("张三"); // 向集合中添加元素set.add("李四");set.add("王五");set.add("王五"); // 添加重复元素set.add("100"); // 两个类型不同set.add(100); // 两个类型不同Iterator it = set.iterator(); // 获取迭代器接口while (it.hasNext()){ // while 判断集合是否有元素Object obj = it.next(); // 如果有元素则通过迭代器 next() 获取元素System.out.println(obj); // 打印获取到的元素}}
}------------------------------------两个内容相同类型不同,散列值也是不同 会保存下来输出:李四
100
张三
100
王五HashSet 存储Class类
将字符串存入HshSet时 String类已经重写了hashCode 和 equals 方法,下面演示存储自定义的Class类 的结果
未改写 hashCode和equals()方法
import java.util.HashSet;
class Student{String id;String name;public Student(String id, String name) { // 创建构造方法this.id = id;this.name = name;}public String toString(){return id+":"+name;}
}
public class foreach {static String[] strrs = {"aaa","ddd","ccccc"};public static void main(String[] args) {HashSet set = new HashSet(); // 创建HashSet集合Student stu1 = new Student("1","杜甫"); // 创建对象传入参数到构造函数中Student stu2 = new Student("2","李白");Student stu3 = new Student("2","李白");set.add(stu1); // 将对象的值传入到集合中 也就是传入 classset.add(stu2);set.add(stu3);System.out.println(set);}
}---------------------------------------------输出:[2:李白, 2:李白, 1:杜甫]**注意:**在Java中,当我们使用System.out.println()方法输出一个对象时,实际上会自动调用该对象的`toString`()方
法来获取其字符串表示形式。因此,在这段代码中,当我们使用System.out.println(set)输出HashSet对象时
实际上会自动调用每个Student对象的toString()方法来获取其字符串表示形式,并将它们拼接成一个字符串输
出。虽然你没有显式调用toString()方法,但它确实被隐式调用了。 所以上面代码我们没有调用实际上啊是自动
调用了----------------------------------------------------------运行结果出现了两个相同的李白2,本来应该被认为是重复元素,不允许输出的,为什么没有去掉是因为在定义
Class类时 没有重写hashCode和equals()方法已改写 hashCode和equals()方法
import java.util.HashSet;class Student{String id;String name;public Student(String id, String name) { // 创建构造方法this.id = id;this.name = name;}public String toString(){ // 重写toSring() 方法return id+":"+name;}public int hashCode(){ // 重写了hashCode()return id.hashCode();}// 重写 eqlals 方法public boolean equals(Object obj){if (this==obj){ // 判断是否是同一个对象return true; // 是的话就是真}if (!(obj instanceof Student)){ // 判断对象是否是Student类型return false;}Student stu = (Student) obj; // 将对象强制转换为 Student 类型boolean b = this.id.equals(stu.id); // 判断id值是否相同return b;}}public class foreach {static String[] strrs = {"aaa","ddd","ccccc"};public static void main(String[] args) {HashSet set = new HashSet(); // 创建HashSet集合Student stu1 = new Student("1","杜甫"); // 创建对象传入参数到构造函数中Student stu2 = new Student("2","李白");Student stu3 = new Student("2","李白");set.add(stu1); // 将对象的值传入到集合中set.add(stu2);set.add(stu3);System.out.println(set);}}----------------------------------------输出:[1:杜甫, 2:李白]**注意:**Student类重写了Object类的hashCode()返回`id`属性的散列值还有`equals` 并且在`equals` 方法比较对象
的id属性值是否相等并返回结果`HashSet`集合添加元素时,因为改写了`hashCode`方法所以`add`添加时
会进行比较发现散列值相同而且**stue.equsls(stu3)** 返回true 集合认为两个参数相等因为重复的被去掉了LinkedHashSet实现类存取有序无重复
HashSet集合存储的元素是无序的,如果想让元素存取顺序一致,那么就使用 LinkedHashSet
它是HashSet 的子类,它和LinkdList一样 使用双向链表来维护内部元素关系
import java.util.Iterator;
import java.util.LinkedHashSet;public class foreach {public static void main(String[] args) {LinkedHashSet set = new LinkedHashSet();set.add("张三"); // 集合添加元素set.add("李四");set.add("王五");set.add("王五"); // 即使出现重复元素 也还是会显示一个Iterator it = set.iterator(); // 迭代器判断while (it.hasNext()){ // 循环判断是否有元素Object obj = it.next();System.out.println(obj);}}}-------------------------------------------------输出:张三
李四
王五TreeSet 实现类有序无重复
为了对集合的元素进行排序,Set 接口提供了另一个可以对HashSet集合中元素排序的类——TreeSet
import java.util.TreeSet;public class foreach {public static void main(String[] args) {TreeSet set = new TreeSet();set.add(1);set.add(1);set.add(3);set.add(5);set.add(6);System.out.println(set);}
}----------------------------------------------输出:[1, 3, 5, 6]元素会自动排序并且没有存在重复TreeSet 集合之所以可以对添加元素排序,是因为元素的类实现了`Comparable`接口
(基本类型的包装类 String类都实现了该接口) `Comparable`强行对实现它的每个类的对象进行整体排序这种排序被称为自然排序Comparable接口的compareTo()方法被称为自然比较方法!什么是comparTo()方法
Comparable接口是Java中的一个接口,用于实现对象之间的比较。其中,compareTo()方法是Comparable接口中的一个方法,用于比较当前对象与另一个对象的大小关系。
compareTo()方法的返回值为int类型,表示当前对象与另一个对象的大小关系。如果当前对象小于另一个对象,则返回负整数;如果当前对象等于另一个对象,则返回0;如果当前对象大于另一个对象,则返回正整数。
compareTo()方法的作用是用于实现对象之间的排序。在Java中,如果一个类实现了Comparable接口,就可以使用Collections.sort()方法或Arrays.sort()方法对该类的对象进行排序。在排序过程中,会调用compareTo()方法来比较对象之间的大小关系,从而实现排序。
需要注意的是,如果一个类实现了Comparable接口,就必须实现compareTo()方法,否则会编译错误。另外,compareTo()方法的实现应该满足一定的规则,例如具有传递性、反对称性等,否则可能会导致排序结果不正确
TreeSet 存储Class类
如果同HashSet()一样存储Class类,TreeSet集合不会去进行排序,Class类对象必须实现 Comparable
接口并重写 compareTo方法实现对象元素的顺序存取 想对添加的元素进行排序就先重写
import java.util.TreeSet;// 定义Student类 **第一步实现了Comparable泛型;**
class Student implements Comparable<Student>{private String id;private String name;public Student(String id, String name) {this.id = id;this.name = name;}// 重写toString字符串方法public String toString(){return id+":"+name;}// **第二步重写 compareTo方法**// 三种compareTo方法的三种情况 public int compareTo(Student o){return 0 ; // 集合中只有一个元素 还是第一个张三// return 1 // 集合怎么存怎么取的顺序
// return -1; // 集合按照存入的元素进行倒序}
}
public class foreach {public static void main(String[] args) {TreeSet set = new TreeSet();set.add(new Student("1","张三")); // 直接打印省去了 stu1 stu2 操作set.add(new Student("2","李白"));set.add(new Student("3","毒品"));System.out.println(set);}
}---------------------------------------------输出:return 0 [1:张三]return 1 [1:张三, 2:李白, 3:毒品]return -1[3:毒品, 2:李白, 1:张三]除了自然排序还有另一种排序方法; 即实现Comparator接口 重写compare()方法 equals()方法
但是由于所有的类默认继承Object 而Object 又存在 equals() 所以自定义比较器类时,不用重写equals方法,只需要重写compare() 方法这种排序称为比较器排序
通过自定义Class类对象 通过比较器存入TreeSet集合
import java.util.Comparator;
import java.util.TreeSet;class Student {private String id;private String name;public Student(String id, String name) {this.id = id;this.name = name;}// 重写toString字符串方法public String toString(){return id+":"+name;}
}
public class foreach {public static void main(String[] args) {// 声明了一个TreeSet集合并通过匿名内部类的方式实现了Comparator接口,TreeSet set = new TreeSet(new Comparator() {@Override// 然后重写了compare()方法并public int compare(Object o1, Object o2) {return -1;}});set.add(new Student("1","张三")); // 直接打印省去了 stu1 stu2 操作set.add(new Student("2","李白"));set.add(new Student("3","毒品"));System.out.println(set);}
}--------------------------------------------输出:[3:毒品, 2:李白, 1:张三]相关文章:
Collection 单列集合 List Set
集合概念 集合是一种特殊类 ,这些类可以存储任意类对象,并且长度可变, 这些集合类都位于java.util中,使用的话必须导包 按照存储结构可以分为两大类 单列集合 Collection 双列集合 Map 两种 区别如下 Collection 单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两…...
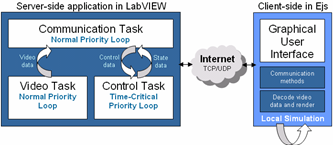
LabVIEW提高开发效率技巧----跨平台开发
在如今的多平台环境下,开发者常常面临不同操作系统的需求,如Windows、Linux和RT(实时)系统等。而LabVIEW作为一种强大的开发工具,提供了支持跨平台开发的能力,但要使其无缝迁移,开发者需要掌握一…...

创建uniCloud新项目并且是新服务空间,运行会报Error: Invalid uni-id config file错误
问题说明 新创建的服务空间,新起的项目,运行查询数据库就会报错,Uncaught (in promise) Error: Invalid uni-id config file,我记得在原来创建项目的时候,是不需要进行配置的,最近创建新项目出现了这个错误…...
)
七、IPD 方法论框架(IPD的组织架构)
IPD的组织架构 在IPD(集成产品开发)方法论中,组织架构是确保跨职能团队高效协作、快速响应市场需求的关键要素之一。IPD的组织架构通常打破传统的职能部门隔离,倡导跨职能团队和矩阵式管理模式,使各职能部门在项目开发中紧密合作,从而提高开发效率,降低沟通成本。 IPD…...
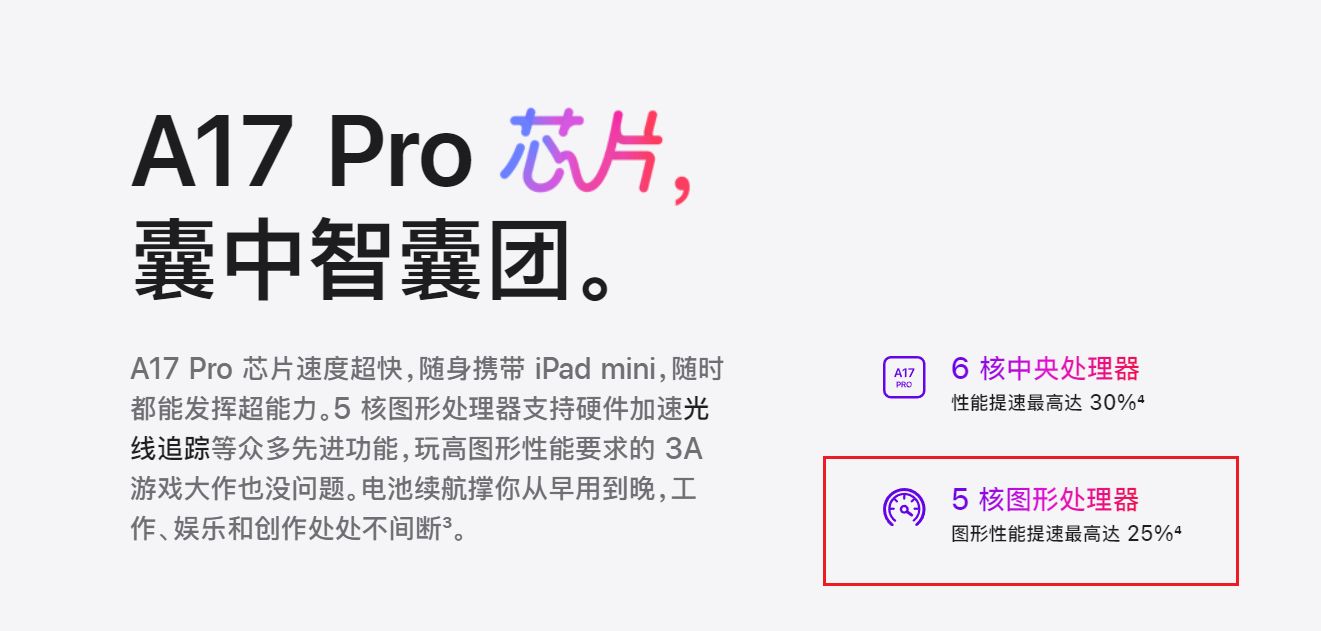
iPad mini 7惨遭暗砍一刀
大屏是工作,小屏才是生活。 iPad mini系列,一直被誉为最适合普罗大众的平板。热爱学习、工作的卷王不多,沉迷游戏、追剧的俗人不少。 对娱乐场景而言,便携性是核心属性。iPad mini不大不小,只有两台手机的大小&#x…...

【计算机网络 - 基础问题】每日 3 题(三十六)
✍个人博客:https://blog.csdn.net/Newin2020?typeblog 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞…...

Docker镜像
Docker是一个开源的容器化平台,它可以帮助开发人员打包应用程序及其依赖项为轻量级、可移植的容器,以实现快速部署和可扩展性。下面是关于Docker的一些基本概念和优势: 容器:Docker使用容器来封装应用程序和其所有依赖项ÿ…...

Golang | Leetcode Golang题解之第478题在圆内随机生成点
题目: 题解: type Solution struct {radius, xCenter, yCenter float64 }func Constructor(radius, xCenter, yCenter float64) Solution {return Solution{radius, xCenter, yCenter} }func (s *Solution) RandPoint() []float64 {r : math.Sqrt(rand.…...

菜鸟笔记006 截图识别文字插件 textOCR
随手可得的截图识别文字插件 textOCR,识别出来的文字可直接输入到illustrator的当前文档中: 执行条件 1、需截图软件支持,推荐笔记截图工具 2、截好图片直接拖入面板即可完成识别 ****后期可完成实现在illustrator选择图片对象完成文字识别。…...

MySQL【知识改变命运】07
MySQL 1:Group by 分组查询1.1:语法:1.2:练习 2:having⼦句3回顾:3:内置函数3.1 :⽇期函数 1:Group by 分组查询 可以根据某列,进行分组查询,比如学校里面的…...

Matlab自学笔记三十八:日期时间序列的创建方法
1.概念 时间序列是指,某一时间段的时间,也就是说,一组日期时间数据组成的序列,例如,1.1~1.10,1点~5点等,在Matlab中,使用向量表示这种时间序列,例如[2025.1.1 2025.1.2 …...

fiber的原理
React Fiber 的主要原理包括动态优先级、可中断的工作、增量渲染和协作式多任务 React Fiber 是 React 16 引入的一种新的协调(reconciliation)引擎,它旨在提高 React 应用的性能和响应性。Fiber 的核心原理主要包括以下几个方面:…...

重塑输电线路运维管理,巡检管理系统守护电网稳定运行
在输电线路巡检管理中,一个高效、直接的巡检系统对于确保电力供应的稳定性和安全性至关重要。巡检系统能够直接对接运维需求,减少繁琐流程,并强化数据分析能力,这无疑为输电线路的运维管理带来了诸多优势。以下是对这些优势的具体…...

各种排序方法总结
目录 1. 冒泡排序 (Bubble Sort 2. 选择排序 (Selection Sort) 3. 插入排序 (Insertion Sort) 4. 快速排序 (Quick Sort) 5. 归并排序 (Merge Sort) 6. 堆排序 (Heap Sort) 排序算法 时间复杂度 空间复杂度 备注冒泡排序 最好情况: O(n) 平均情况: O(n^2) 最坏情况: O(n^…...

【工欲善其事】巧用 PowerShell 自动清除复制 PDF 文本时夹杂的换行符号
文章目录 巧用 PowerShell 自动清除复制 PDF 文本时夹杂的换行符号1 问题描述2 解决方案3 具体步骤4 效果测试5 小结与复盘 巧用 PowerShell 自动清除复制 PDF 文本时夹杂的换行符号 1 问题描述 不知各位是否也为复制过来的文本中夹杂的回车换行符抓狂过?就是在复…...

Maven与Gradle的区别
Maven与Gradle是两种流行的构建工具,广泛用于Java项目的管理和构建。以下是它们的对比,包括官网、Windows 11配置环境、在IDEA中的相同点和不同点,以及它们各自的优缺点。 官网 Maven官网: https://maven.apache.orgGradle官网: https://gr…...

【linux 多进程并发】0202 Linux进程fork之后父子进程间的文件操作有着相同的偏移记录,多进程操作文件的方法
0202 Linux进程资源 专栏内容: postgresql使用入门基础手写数据库toadb并发编程 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 文章目录 020…...

SQLite在安卓中的应用
在 Android 应用程序中,SQLite 是默认的嵌入式数据库解决方案,Android 系统为开发者提供了相应的 API 来管理 SQLite 数据库。通过使用 SQLiteOpenHelper 类和 SQLiteDatabase 类,开发者可以方便地创建、查询、更新和删除数据库中的数据。 以…...

Python数据库操作
前面的章节中学习了使用 Python 读写文件的方法,大家可以用文件方式来存放数据,不过使用文件方式时不容易管理,同时还容易丢失,会带来许多问题。目前主流的方法都是采用数据库软件,通过数据库软件来组织和存放数据&…...

交叉熵损失函数为代表的两层神经网络的反向传播量化求导计算公式
反向传播(back propagation,BP)算法也称误差逆传播,是神经网络训练的核心算法。我们通常说的 BP 神经网络是指应用反向传播算法进行训练的神经网络模型。反向传播算法的工作机制究竟是怎样的呢?我们以一个两层…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...