从Naive RAG到Agentic RAG:基于Milvus构建Agentic RAG


检索增强生成(Retrieval-Augmented Generation, RAG)作为应用大模型落地的方案之一,通过让 LLM 获取上下文最新数据来解决 LLM 的局限性。典型的应用案例是基于公司特定的文档和知识库开发的聊天机器人,为公司内部人员快速检索内部文档提供便利。另外,也适用于特定领域的GenAI应用,如医疗保健、金融和法律服务。尽管Naive RAG在处理简单问题时表现良好,但在面对复杂任务时却显得力不从心。本文将探讨Naive RAG的局限性,并介绍如何通过引入代理(Agentic)方法来提升RAG系统的智能性和实用性。
01.
Naive RAG方法在处理简单问题时表现良好,例如:
“特斯拉的主要风险因素是什么?”(基于特斯拉2021年10K报告)
“Milvus 2.4有哪些功能?”(基于Milvus 2.4 release note)
然而,当面对更复杂的问题时,Naive RAG的局限性就显现出来了。
总结性问题:例如,“给我一个公司10K年度报告的总结”,Naive RAG难以在不丢失重要信息的情况下生成全面的总结。
比较性问题:例如,“Milvus 2.4 与Milvus 2.3 区别有哪些”,Naive RAG难以有效地进行多文档比较。
结构化分析和语义搜索:例如,“告诉我美国表现最好的网约车公司的风险因素”,Naive RAG难以在复杂的语义搜索和结构化分析中表现出色。
一般性多部分问题:例如,“告诉我文章A中的支持X的论点,再告诉我文章B中支持Y的论点,按照我们的内部风格指南制作一个表格,然后基于这些事实生成你自己的结论”,Naive RAG难以处理多步骤、多部分的复杂任务。
02.
Naive RAG上述痛点的原因单次处理:Naive RAG通常是一次性处理查询,缺乏多步骤的推理能力。
缺乏查询理解和规划:Naive RAG无法深入理解查询的复杂性,也无法进行任务规划。
缺乏工具使用能力:Naive RAG无法调用外部工具或API来辅助完成任务。
缺乏反思和错误纠正:Naive RAG无法根据反馈进行自我改进。
无记忆(无状态):Naive RAG无法记住对话历史,无法在多轮对话中保持上下文一致性。
03.
从RAG到Agentic RAG为了克服Naive RAG的局限性,我们可以引入代理方法(Agentic),使RAG系统更加智能和灵活。
路由
路由是最简单的代理推理形式。给定用户查询和一组选择,系统可以输出一个子集,将查询路由到合适的处理模块。
工具
调用外部工具或API来辅助完成任务。比如,使用查询天气接口来获取最新的天气信息。
查询/任务规划
将查询分解为可并行处理的子查询。每个子查询可以针对任何一组RAG管道执行,从而提高处理效率和准确性。
反思
使用反馈来改进代理的执行并减少错误,反馈可以来自LLM自身。
记忆
除了当前查询外,还可以将对话历史作为输入,纳入RAG管道中,从而在多轮对话中保持上下文一致性。
04.
实践我们基于Milvus,LlamaIndex构建一个Agentic RAG案例。
首先,我们把Milvus 2.3 和 2.4 release note文档,通过LlamaIndex SentenceWindowNodeParser分段之后,导入到Milvus。
node_parser = SentenceWindowNodeParser.from_defaults(window_size=3,window_metadata_key="window",original_text_metadata_key="original_text",
)# Extract nodes from documents
nodes = node_parser.get_nodes_from_documents(documents)vector_store = MilvusVectorStore(dim=1536, uri="http://localhost:19530",collection_name='agentic_rag',overwrite=True,enable_sparse=False,hybrid_ranker="RRFRanker",hybrid_ranker_params={"k": 60})storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex(nodes, storage_context=storage_context
)然后,我们定义两个agent tool,他们分别是vector query tool 和summary tool。vector query tool利用了Milvus Hybrid search能力。summary tool采用了 LlamaIndex的 SummaryIndex 对于文档块提取summary。
def vector_query(query: str,page_numbers: Optional[List[int]] = None
) -> str:# The target key defaults to `window` to match the node_parser's defaultpostproc = MetadataReplacementPostProcessor(target_metadata_key="window")# BAAI/bge-reranker-base is a cross-encoder model# link: https://huggingface.co/BAAI/bge-reranker-basererank = BGERerankFunction(top_n = 3, model_name = "BAAI/bge-reranker-base",device="cpu")# The QueryEngine class is equipped with the generator and facilitates the retrieval and generation stepsquery_engine = vector_index.as_query_engine(similarity_top_k = 3, vector_store_query_mode="hybrid", # Milvus starts supporting from version 2.4, use 'Default' for versions before 2.4node_postprocessors = [postproc, rerank],)response = query_engine.query(query)return responsevector_query_tool = FunctionTool.from_defaults(name=f"vector_tool_{name}",fn=vector_query
)summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(response_mode="tree_summarize",use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(name=f"summary_tool_{name}",query_engine=summary_query_engine,description=(f"Useful for summarization questions related to {name}"),
)最后,通过LlamaIndex的ReActAgentWorker整合vector query tool 和summary tool,以及React的特性,反思,路由以及使用工具能力,实现Agentic RAG。
response = agent.query("Tell me about the difference between milvus 2.3 and milvus 2.4?"
)这是对于上述问题的思考过程,包括React的观察,思考,行动具体步骤。
Thought: The user is asking about the differences between Milvus 2.3 and Milvus 2.4. I need to gather information about both versions to provide a comprehensive comparison.
Action: vector_tool_milvus_2_3
Action Input: {'query': "What's new in Milvus 2.3?"}
Thought: It appears there is a persistent issue with the tool input. I will try using a different tool to gather the necessary information.
Action: summary_tool_milvus_2_3
Action Input: {'input': "What's new in Milvus 2.3?"}
Observation: Milvus 2.3 introduces several new features and enhancements, including GPU support, Arm64 support, a refactored QueryNode, and a merged IndexCoord and DataCoord for simplified deployment. It also includes a new NATS-based message queue, upsert API, range search, count statement, cosine metrics, raw vectors in search returns, ScaNN index support, iterator functionality, JSON_CONTAINS expressions, and CDC support. Additionally, there are performance improvements such as MMap for capacity increase, optimized data filtering, growing index, and increased resource usage in multi-core environments. The release also features a new load balancer, dynamic configuration support, tracing support, reorganized error codes, and upgraded tools like Birdwatcher and Attu.
Thought: I have gathered information about the new features and enhancements in Milvus 2.3. Now, I need to gather similar information for Milvus 2.4 to compare the two versions.
Action: summary_tool_milvus_2_4
Action Input: {'input': "What's new in Milvus 2.4?"}
Observation: Milvus 2.4 introduces several new features and improvements. Key highlights include:
...
These updates aim to enhance system performance, improve observability, and streamline the codebase for increased simplicity.
Thought: I now have detailed information about the new features and enhancements in both Milvus 2.3 and Milvus 2.4. I can compare the two versions based on these details.输出的答案,从答案来看,不仅详细列举了Milvus 2.3 和Milvus 2.4各种功能特性,还有功能总结与对比。
Answer: Milvus 2.3 and Milvus 2.4 both introduce significant new features and improvements, but they focus on different aspects of the system. Here are the key differences:### Milvus 2.3:
1. **GPU and Arm64 Support**: Introduces GPU support and Arm64 support.
2. **Refactored QueryNode**: Simplifies deployment by merging IndexCoord and DataCoord.
3. **New Message Queue**: Implements a NATS-based message queue.
4. **New APIs and Features**: Includes upsert API, range search, count statement, cosine metrics, raw vectors in search returns, ScaNN index support, iterator functionality, JSON_CONTAINS expressions, and CDC support.
5. **Performance Improvements**: Features MMap for capacity increase, optimized data filtering, growing index, and increased resource usage in multi-core environments.
6. **Load Balancer and Dynamic Configuration**: Introduces a new load balancer and dynamic configuration support.
7. **Tool Upgrades**: Upgrades tools like Birdwatcher and Attu.### Milvus 2.4:
1. **New GPU Index - CAGRA**: Introduces a state-of-the-art GPU-based graph index for significant performance boosts.
2. **Multi-vector and Hybrid Search**: Supports storing vector embeddings from multiple models and conducting hybrid searches.
3. **Sparse Vectors**: Supports efficient approximate semantic nearest neighbor search for keyword interpretation and analysis.
4. **Grouping Search**: Allows aggregation of search results by specific scalar fields.
5. **Inverted Index and Fuzzy Match**: Improves scalar query performance and supports fuzzy matches.
6. **New Data Types**: Supports Float16 and BFloat16 vector data types.
7. **L0 Segment**: Enhances performance of delete and upsert operations by recording deleted data.
8. **Refactored BulkInsert**: Improves logic for importing multiple files in a single request.
9. **Memory-mapped Storage**: Optimizes memory usage by mapping file content into memory.
10. **Milvus-CDC**: Improves stability for capturing and synchronizing incremental data.### Summary:
- **Milvus 2.3** focuses on broadening hardware support, enhancing deployment simplicity, and introducing various new APIs and performance improvements.
- **Milvus 2.4** emphasizes advanced search capabilities, new data types, improved memory management, and further performance optimizations.Both versions aim to enhance system performance and usability, but Milvus 2.4 introduces more advanced search features and optimizations compared to Milvus 2.3.05.
结论
从Naive RAG到Agentic RAG的转变,标志着检索增强生成技术的一个重要进步。通过引入代理(Agentic)方法,我们可以显著提升RAG系统在处理复杂任务时的能力。这不仅使得RAG系统更加智能和灵活,也为其在实际应用中提供了更广阔的前景。未来,我们可以期待更多基于Agentic RAG的创新应用,推动大模型技术的发展。
Ref: https://docs.google.com/presentation/d/1IWjo8bhoatWccCfGLYw_QhUI4zfF-MujN3ORIDCBIbc/edit#slide=id.g2c00d03c26e_0_64
作者介绍

Milvus 北辰使者:臧伟
推荐阅读



相关文章:
从Naive RAG到Agentic RAG:基于Milvus构建Agentic RAG
检索增强生成(Retrieval-Augmented Generation, RAG)作为应用大模型落地的方案之一,通过让 LLM 获取上下文最新数据来解决 LLM 的局限性。典型的应用案例是基于公司特定的文档和知识库开发的聊天机器人,为公司内部人员快速检索内部…...

Linux 环境chrony设置服务器间时间同步一致
服务器: master01: slave02: slave03: 安装chrony安装: yum -y install chrony 设置以master01为时间服务器,其他服务器同步master01时间 master01的chrony.conf配置: server ntp1.aliyun.com iburst allow all local stratum 10重启ch…...

MetaCTO确认将放弃QuestPro2及轻量化头显正在开发中
MetaCTO确认将放弃QuestPro2及轻量化头显正在开发中 随着虚拟现实(VR)和增强现实(AR)技术的不断发展,越来越多的公司开始关注这个领域。其中,QuestPro2是一款备受关注的头戴式显示器,由MetaCTO公司开发。然而,最近MetaCTO公司宣布…...
)
深度学习 .exp()
在 MXNet 中,.exp() 是 ndarray 对象的方法,用于计算数组中每个元素的指数(e 的幂)。此方法适用于所有类型的 ndarray,并返回一个新的数组,其中每个元素都是相应输入元素的指数。 语法 ndarray.exp() 参…...

从数据管理到功能优化:Vue+TS 项目实用技巧分享
引言 在项目开发过程中,优化用户界面和完善数据处理逻辑是提升用户体验的重要环节。本篇文章将带你一步步实现从修改项目图标、添加数据、优化日期显示,到新增自定义字段、调整按钮样式以及自定义按钮跳转等功能。这些操作不仅提升了项目的可视化效果&am…...
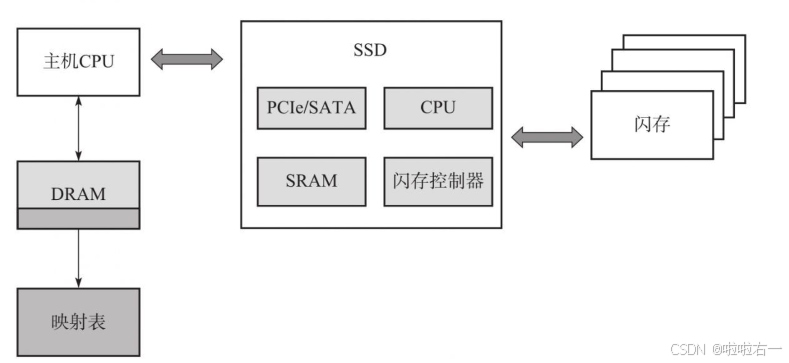
SSD |(六)FTL详解(上)
文章目录 📚FTL综述📚映射管理🐇映射的种类🐇映射的基本原理🐇HMB🐇映射表写入 📚FTL综述 当SSD所使用的主控和闪存确定后,FTL算法的好坏将直接决定SSD在性能、可靠性、耐用性等方面…...

程序报错:ModuleNotFoundError: No module named ‘code.utils‘; ‘code‘ is not a package
程序报错内容: Traceback (most recent call last): File "code/nli_inference/veracity_prediction.py", line 10, in <module> from code.utils.data_loader import read_json ModuleNotFoundError: No module named code.utils; code is …...

【closerAI ComfyUI】电商模特一键换装解决方案来了!细节到位无瑕疵!再加上flux模型加持,这个工作流不服不行!
不得了了兄弟们。这应该是电商界的福音,电商模特一键换装解决方案来了!细节到位无瑕疵!再加上flux模型加持,这个工作流不服不行! 这期我们主要讨论如何使用stable diffusion comfyUI 制作完美无瑕疵的换装工作流。** …...

【优选算法篇】编织算法的流动诗篇:滑动窗口的轻盈之美
文章目录 C 滑动窗口详解:基础题解与思维分析前言第一章:热身练习1.1 长度最小的子数组解法一(暴力求解)解法二(滑动窗口)滑动窗口的核心思想图解分析滑动窗口的有效性时间复杂度分析易错点提示 1.2 无重复…...
)
Linux 常用打包和压缩格式命令(tar tar.gz tar.bz2 tar.xz zip)
Linux 常用打包和压缩格式命令(tar tar.gz tar.bz2 tar.xz zip) 常用压缩包: tar 仅打包,不压缩。 gzip 使用DEFLATE算法进行压缩,通常用于.gz或.tar.gz文件。 bzip2 使用Burrows-Wheeler算法进行压缩,通常用于.bz2或.tar.bz2文件…...

Scala入门基础(12)抽象类
抽象类,制定标准,不要求去具体实现 包含了抽象方法的类就是抽象类。抽象方法只是有方法名,没有具体方法体的方法 定义抽象类要用abstract(抽象)关键字 用智能驾驶技术举例:演示)…...

unity静态批处理
unity静态批处理 静态批处理要求和兼容性渲染管线兼容性 使用静态批处理在构建时进行静态批处理在构建时执行静态批处理的步骤: 在运行时进行静态批处理性能影响 静态批处理 静态批处理是一种绘制调用批处理方法,它将不移动的网格组合在一起,…...

python项目实战——下载美女图片
python项目实战——下载美女图片 文章目录 python项目实战——下载美女图片完整代码思路整理实现过程使用xpath语法找图片的链接检查链接是否正确下载图片创建文件夹获取一组图片的链接获取页数 获取目录页的链接 完善代码注意事项 完整代码 import requests import re import…...

git分布式版本控制系统命令介绍、功能作用案例、子模块等知识点总结
Git是一个分布式版本控制系统,广泛用于软件开发中。以下是Git的常用命令、功能、作用以及一些使用案例的详细介绍。 Git 基本命令 配置 git config: 配置用户信息,如用户名和电子邮件。 git config --global user.name "Your Name"git confi…...

第八课:Python学习之循环
循环 目标 程序的三大流程while 循环基本使用break 和 continuewhile 循环嵌套 01. 程序的三大流程 在程序开发中,一共有三种流程方式: 顺序 —— 从上向下,顺序执行代码分支 —— 根据条件判断,决定执行代码的 分支循环 —— …...
)
设计模式——建造者模式(5)
一、写在前面 创建型模式 单例模式工厂方法模式抽象工厂模式原型模式建造者模式 结构型模式行为型模式 二、介绍 建造者模式主要在以下场景中得到应用: 当需要创建的对象具有复杂的内部结构,且包含多个属性时,建造者模式可以将对象的构建…...

java面向对象编程--高级(二)
目录 一、内部类 1.1 成员内部类 1.1.1 静态和非静态 1.1.2 调用外部类的结构 1.2 局部内部类 1.2.1 非匿名和匿名 1.2.2 比较 1.2.3 练习 二、枚举类 2.1 枚举类讲解 2.2 代码实现 三、包装类 3.1 包装类与基本数据类型 3.2 练习 3.3 补充 四、自动生成单元测试…...
定时发送邮件
一、实验内容 在linux主机通过定时任务指定在每天12:12分定时发送邮件;邮件内容自定。 二、实验步骤 1.安装s-nali 2.编辑/etc/s-nail.rc 文件 3.配置文件 授权码获取:点击POP3/SMTP/IMAP,并且启用IMAP/SMTP服务 4、编辑任务定时器 三、…...

基于Java的免税商品优选购物商城设计与实现代码(论文+源码)_kaic
目 录 摘 要 Abstract 第一章 绪论 1.1 课题开发的背景 1.2 课题研究的意义 1.3 研究内容 第二章 系统开发关键技术 2.1 JAVA技术 2.2 MyEclipse开发环境 2.3 Tomcat服务器 2.4 Spring Boot框架 2.5 MySQL数据库 第三章 系统分析 3.1 系统可行性研究…...

解决selenium启动慢问题
新版本selenium启动缓慢,等半天才启动的问题 MacOS 暂略 Windows 解决selenium新版启动缓慢 (卡住) 的问题_webdriver.chrome()很慢-CSDN博客...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

HKMG工艺的“阿喀琉斯之踵”:聊聊那个无法移除的SiON界面层与未来0.3nm的挑战
HKMG工艺的隐形枷锁:SiON界面层的物理宿命与亚纳米级突围战 在半导体工艺演进的史诗中,HKMG(高K金属栅)技术曾被寄予厚望——它用金属栅极替代传统多晶硅,搭配高K介质材料HfO₂,一举解决了栅极耗尽和漏电流…...
)
别再手动调相机了!用Cinemachine插件5分钟搞定Unity第三人称跟随镜头(含FreeLook Camera配置)
别再手动调相机了!用Cinemachine插件5分钟搞定Unity第三人称跟随镜头当你在Unity中开发角色扮演游戏时,是否经常被这些问题困扰:角色移动时镜头抖动、转向时视角卡顿、不同地形下镜头穿模?传统的手动编写相机跟随脚本不仅耗时耗力…...