ollama + fastgpt+m3e本地部署
ollama + fastgpt+m3e本地部署
- 开启WSL
- 更新wsl
- 安装ubuntu
- docker下载
- 修改docker镜像源
- 开启WSL integration
- 安装fastgpt
- 先创建一个文件夹来放置一些配置文件
- 用命令下载fastgpt配置文件
- 用命令下载docker的部署文件
- 启动容器
- M3E下载
- ollama下载
- oneapi配置
- 登录oneapi
- 配置ollama渠道
- 配置渠道m3e
- 创建令牌
- 修改config.json
- 重启容器
- FastGTP配置与使用
- 登录
- 新建知识库
- 训练模型
- 因为我这里使用的是本地文件去训练,所以要选择 文本数据集
- 这样就是训练好了,这里之前我踩过一个坑,就是一直在训练然后一条数据都没有,这个一般都是向量模型的问题,向量模型选错了,或者是向量模型没办法访问,所以上面配置渠道的时候一定要测试的原因就是这样的
- 创建应用
- 注意:以上只是最初级的玩法,要知识库好用的话,还得慢慢研究
开启WSL
因为这里使用的win部署,所以要安装wsl,如果是linux系统就没那么麻烦
控制面板->程序->程序和功能

更新wsl
wsl --set-default-version 2
wsl --update --web-download
安装ubuntu
wsl --install -d Ubuntu
docker下载
官网下载:docker官网
修改docker镜像源
因为docker下载的镜像源默认是国外的地址,所以下载比较慢,换成国内的镜像源下载会比较快一点
{"registry-mirrors": ["https://docker.m.daocloud.io","https://docker.1panel.live","https://hub.rat.dev"]
}

开启WSL integration

安装fastgpt
先创建一个文件夹来放置一些配置文件
mkdir fastgpt
cd fastgpt
用命令下载fastgpt配置文件
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
用命令下载docker的部署文件
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
这里如果是测试的话就用简单模型就好了,其他的高级玩法后面再慢慢摸索
启动容器
docker-compose up -d
M3E下载
#查看网络
docker network ls
# GPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --gpus all --name m3e --network fastgpt_fastgpt(这里你们的网络名称可能不是这个,如果不是这个就按照你们查到的网络去填) stawky/m3e-large-api
# CPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --name m3e --network fastgpt_fastgpt stawky/m3e-large-api
ollama下载
ollama下载这里就不做说明了,因为现在ollama下载比较简单,需要的话,我再出博客讲解
oneapi配置
模型的处理我们只要用的是oneapi来处理模型
登录oneapi
本机地址:http://localhost:3001/
oneapi登录账号:root 默认密码:123456或者1234
配置ollama渠道

base url那里的ip要换成本地ip
模型那里选择的模型要选择你本地ollama下载的模型
密钥可以随便填
添加完渠道,记得要点一下测试,测试通过了才能正常使用
配置渠道m3e

base url要像我这样填写才行,不然回出问题
模型要选m3e
密钥填:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
这里提交之后也要点测试,看能不能通
创建令牌

这里记得选无限额度和永不过期

这里复制令牌放置docker-compose.yml文件中
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。- DEFAULT_ROOT_PSW=1234# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。- OPENAI_BASE_URL=http://oneapi:3000/v1# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)- CHAT_API_KEY=sk-apETi4q0ohZoqLynBfA5CcAc716b44CcB9E7F3B0716d8c5f

修改config.json
首先是加入ollama的本地模型
"llmModels": [{"model": "qwen2.5:7b", // 模型名(对应OneAPI中渠道的模型名)"name": "qwen2.5:7b", // 模型别名"avatar": "/imgs/model/openai.svg", // 模型的logo"maxContext": 125000, // 最大上下文"maxResponse": 16000, // 最大回复"quoteMaxToken": 120000, // 最大引用内容"maxTemperature": 1.2, // 最大温度"charsPointsPrice": 0, // n积分/1k token(商业版)"censor": false, // 是否开启敏感校验(商业版)"vision": true, // 是否支持图片输入"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型"customExtractPrompt": "", // 自定义内容提取提示词"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)},
像我用的是qwen2.5,你们可以根据自己的模型进行选择
然后加入向量模型vectorModels
"vectorModels": [{"model": "m3e", // 模型名(与OneAPI对应)"name": "m3e", // 模型展示名"avatar": "/imgs/model/openai.svg", // logo"charsPointsPrice": 0, // n积分/1k token"defaultToken": 700, // 默认文本分割时候的 token"maxToken": 3000, // 最大 token"weight": 100, // 优先训练权重"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)"queryConfig": {} // 参训时的额外参数},
重启容器
docker-compose down
docker-compose up -d
FastGTP配置与使用
登录
本机地址:http://localhost:3000
账号:root 密码:1234

新建知识库


这里选用通用知识库
索引模型也就是向量模型
文件处理模型就是用来做回答的模型
训练模型

因为我这里使用的是本地文件去训练,所以要选择 文本数据集

这里是分割数据的模型,用自动模式就好了

这样就是训练好了,这里之前我踩过一个坑,就是一直在训练然后一条数据都没有,这个一般都是向量模型的问题,向量模型选错了,或者是向量模型没办法访问,所以上面配置渠道的时候一定要测试的原因就是这样的
创建应用

这里测试的话就用简单应用就好了

这里选择模型,选择完之后就可以用了

注意:以上只是最初级的玩法,要知识库好用的话,还得慢慢研究
相关文章:
ollama + fastgpt+m3e本地部署
ollama fastgptm3e本地部署 开启WSL更新wsl安装ubuntu docker下载修改docker镜像源开启WSL integration 安装fastgpt先创建一个文件夹来放置一些配置文件用命令下载fastgpt配置文件用命令下载docker的部署文件 启动容器M3E下载ollama下载oneapi配置登录oneapi配置ollama渠道配…...

Linux执行source /etc/profile命令报错:权限不够问(已解决)
1.问题 明明以root账号登录Linux系统,在终端执行命令source /etc/profile时 显示权限不够 如下图: 2.问题原因 可能在编辑 /etc/profile 这个文件时不小心把开头的 井号 ‘#’ 给删除了 如图: 这里一定要有# 3.解决办法 进入/etc/pro…...

Windows 11开发全解析
Windows 11开发全解析 一、搭建开发环境 在开始Windows 11开发之前,搭建一个高效的开发环境是至关重要的。Windows 11提供了多种工具和框架,可以帮助开发者快速搭建起一个强大的开发环境。 1. Visual Studio 2024 Visual Studio 2024是微软为Windows…...
如何进行数学家式的学习思考?
如何进行数学家式的学习思考? 学生阶段的数学学习是非常重要的,对这一点很少有人质疑。一提起数学学习,一些学生、家长甚至一些教师认为,学生的数学学习往往侧重于掌握基本概念、公式和解题技巧,通过做题来巩固知识和提…...
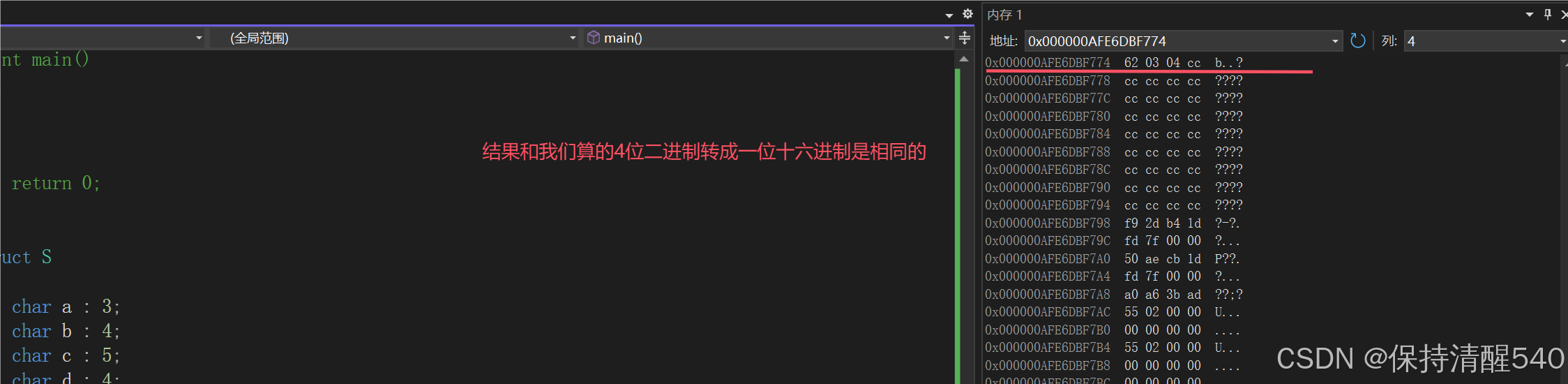
自定义类型--结构体
目录 1. 结构体类型的声明 1.1结构的声明 1.2 结构体变量的创建和初始化 1.3不完全结构体 1.4结构的⾃引⽤ 2 结构体的内存对齐 2.1offsetof 2.2 对⻬规则 2.3 为什么存在内存对⻬? 2.4修改默认对⻬数 3. 结构体传参 4 结构体实现位段 4.1什么是位段 4.2 位段的内…...

笔试练习day7
目录 OR59 字符串中找出连续最长的数字串题目解析解法(双指针遍历)代码 NC109 岛屿数量题目解析解法代码(dfs)dfs的实现 拼三角题目解析解法(枚举)代码 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 &…...

python 爬虫 入门 一、基础工具
目录 一,网页开发者工具的使用 二、通过python发送请求 (一)、get (二)、带参数的get (三)、post 后续:数据解析 一,网页开发者工具的使用 我们可以用 requests 库…...

金融衍生品中的风险对冲策略分析
金融衍生品是现代金融市场中不可或缺的一部分,它们通过标的资产的价格波动为投资者提供了多样的风险管理工具。随着市场的不确定性和复杂性增加,风险对冲成为企业和个人投资者的首要任务。本文将深入探讨金融衍生品中的常见风险对冲策略,分析…...

linux下建立软链接
深度学习训练中经常会遇到数据量庞大或者工程中模型报错太多导致磁盘空间不够,但是又不想修改原来在代码中写的路径,这个时候制作软连接很有作用,把占用量大的目录移到别的空闲磁盘,然后在原来的目录做一个软连接指向那个移到的空…...

MySql数据库left join中添加子查询
user表查询出数据列表(多条,如id)左连接到order表中的order_agent_id字段,并通过 order_agent_id分组,求和user_order_partner,使用COALESCE()聚合函数对未获取到和值的进行默认赋值,防止查询不…...

redis--过期策略和内存淘汰策略
redis过期策略 1、惰性删除 当客户端尝试访问某个键时,Redis会先检查该键是否设置了过期时间,并判断是否过期。 如果键已过期,则Redis会立即将其删除。这就是惰性删除。 总结:该策略可以最大化的节省CPU资源,却对内存非…...

qt QTableview 左侧 序号 倒序
本文主要在QTableview插入数据的基础上,使左边序号实现倒序,实现如下图所示。 解决办法: QTableview左侧是QHeaderView类构成的,重写QHeaderView的paintSection, 重写序号的文字内容,进而 实现QTableview …...

隧道代理IP如何帮助企业采集数据?
在数字化时代,数据已成为企业决策的重要基石。无论是市场调研、竞品分析,还是用户行为研究,高质量的数据采集都是企业成功的关键。然而,面对复杂的网络环境和日益严格的反爬虫机制,如何高效、稳定地采集数据成为了一个…...

Spring Boot知识管理系统:技术与方法论
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常适…...

SpringBoot1~~~
目录 快速入门 依赖管理和自动配置 修改自动仲裁/默认版本号 starter场景启动器 自动配置 修改默认扫描包结构 修改默认配置 读取application.properties文件 按需加载原则 容器功能 Configuration Import 编辑 Conditional ImportResource 配置绑定Configur…...

兼容多家品牌手机的多协议取电快充芯片
随着智能手机的普及和功能不断的增强,电池续航能力成为了用户关注的焦点,为了解决这各问题各大手机厂商推出了手机快充技术,快充协议是快充技术的核心,每家品牌手机都有自己的独家快充协议,如FCP/SCP协议是华为手机的独…...

Java和Python的不同
1. 语法差异 Java: - Java是一种强类型语言,要求在编译时明确变量的数据类型。 - Java代码块由大括号 {} 包围,如方法体、循环和条件语句。 - Java使用分号 ; 作为语句的结束符。 public class HelloWorld {public static void main(String[] args) {S…...

Moshang摩熵医药数据库
摩熵医药数据库是摩熵数科信息公司旗下的一个核心产品,专注于为医药行业提供全面的数据支持和决策服务。该医药数据库整合了中、美、欧、日等全球七十多个主流国家的数10万数据信息源,其中收载的50亿数据体系的覆盖了生物医药全生命周期数据和精细化工全…...
基于web的酒店客房管理系统【附源码】
基于web的酒店客房管理系统(源码L文说明文档) 目录 4 系统设计 4.1 系统概述 4.2系统结构 4.3.数据库设计 4.3.1数据库实体 4.3.2数据库设计表 5系统详细实现 5.1 用户信息管理 5.2 会员信息管理 5.3 客房信息管理 5.…...

潜水定位通信系统的功能和使用方法_鼎跃安全
潜水定位通信系统是保障潜水安全与作业高效的关键设备。它利用先进的声呐、无线电等技术,可精准定位潜水员位置。在水下能实现潜水员之间以及与水面的双向通信,确保信息及时传递。具备高可靠性和稳定性,即使在复杂水环境中也能正常运行。 一、…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...