爬虫基础---python爬虫系列2
爬虫基础
文章目录
- 爬虫基础
- 爬虫简介
- 爬虫的用途
- 爬虫的合法性
- 规避风险
- 看懂协议
- 反爬机制
- 反反爬策略
- 认识HTTP
- HTTP协议--HyperText Transfer Protocol
- HTML--HyperText Markup Language
- HTTPS
- 如何查看网站是什么协议呢
- 使用端口号
- URL组成部分详解
- 常用的请求- Request Method
- 常见的请求头参数
- User-Agent 浏览器名
- Referer
- Cookie 身份证
- 常见的响应状态码 - Response Code
- 分析网页
- 静态网页 - 源代码
- 动态网站(异步加载) - 抓包
- 抓包工具
- Elements
- Network
- Requests----get
- 基于www.hao123.com做一个网页采集器
- Requests---post
- 基于百度翻译,实现文本翻译
- 基于豆瓣电影,获取华语评分前十电影(失败,原因:该产品程序员对网页做出了调整,跟着课做不出来)
- 数据解析
- 正则表达式
- 匹配单个字符
- 匹配多个字符
- 示例一 ------以中间部分内容
- 示例二 ------以开头^
- 示例三 ----以结尾判定$
- 贪婪匹配与非贪婪匹配*?+
- 正则表达式的应用案例
- 匹配手机号 1[3-9]\d{9}
- 匹配邮箱 \w+@[0-9a-z]+.[a-z]+
- 匹配网址 (https:|http:\ftp:)//\S+
- 匹配身份证号 \d{17}[xX\d]
- 正则表达式re模块
- 最低级的字符串处理函数match
- 中级字符串处理函数search
- 高级字符串处理函数findall 也是常用的函数
- 字符串替换函数sub
- 案例 小说筛选器
- 字符串分割函数split
- 换行加注释
- 正则表达式预处理compile
- 正则表达式的转义字符与原生字符
- 案例 美元$与正则表达式取结尾\$
- 案例 以反斜杠作为标识符
- 案例 匹配网页的标题
- 正则表达式xPath模块(XML Path Language)
- xPath节点
- xPath语法
- 谓语
- 选取未知节点
- 选取若干路径
- 数据解析
- xPath-lxml库的使用
- lxml库
- lxml库-读取本地xml文件
- 使用HTML的方式读入文件
- 定位元素
- 按标签顺序定位元素
- 按照包含的元素定位
- /与//的区别
- python案例---下载人生格言
- python案例---下载美女图片
- 案例总结
- BS4--beautifulsoup4库
- BS4语法
- 对象的种类
- 获取标签
- 获取标签的名称
- 获取标签的属性/属性值
- 改变标签的属性值
- 获取标签的文本内容
- 获取注释部分的内容
- 遍历文档树
- 搜索文档树
- CSS选择器
爬虫简介
就是通过代码,模拟浏览器上网,获取互联网的数据过程
爬虫的用途
- 爬取网页上的文字、图片、视频、音频等
- 自动填写表单,打卡等
爬虫的合法性
- 在法律中不被禁止
- 具有一定风险
- 不能干扰被访问网站的正常运营----不能高并发式访问网站,就是不能1秒内向网上发送上万次请求,可能导致服务器崩溃
- 不能抓取受法律保护的特定信息和数据
规避风险
- 尽量不高并发访问
- 设计敏感内容时及时停止爬取或传播
- 阅读robots.txt协议,这上面会说那些数据不能爬取
- 如何找一个网站的这个协议呢
- 只需要在那个网址后面加上斜杠和这个名称就好了
- 比如https://www.bilibili.com/robots.txt
- 就可以看到哪些数据不该访问
- 如何找一个网站的这个协议呢
看懂协议
user-agent 用户代理
Baiduspider 百度爬虫
Disallow 禁止访问一切内容
反爬机制
通过技术手段防止爬虫程序对网站数据进行爬取
- 对疑似爬虫的ip进行限制
反反爬策略
破解反爬机制,获取相关数据
- 定时切换ip,继续获取数据
认识HTTP
HTTP协议–HyperText Transfer Protocol
意思就是超文本发送和接收协议。现在可以传输二进制码流,也就是音频图片等等
HTML–HyperText Markup Language
这是一个页面,HTTP所要呈现的页面,服务器端口是80、
一些小网站啥的,浏览器会显示不安全
HTTPS
是加密版的HTTP,比HTTP多一个SSL层,服务器端口是443。因为是加密过的所以更安全
比如京东啥的,浏览器会显示一个锁,在网址前面
如何查看网站是什么协议呢
只需要看看网址前缀是什么
使用端口号
在浏览器中的网址后面,加上冒号,再加上80或者443,就能显示页面了
URL组成部分详解
URL是Uniform Resource Locator的简写,统一资源定位符。
一个URL由以下几部分组,对于 scheme://host:port/path/?query-string=xxx#anchor 来说
scheme:代表的是访问的协议,一般为http或者https以及ftp等
就是网址前面的http啥的
host:主机名,域名,比如www.baidu.com
就是网址后面紧挨着的域名
port:端口号。当你访问一个网站的时候,浏览器默认使用80端口
这个端口号浏览器默认添加,一般看不见,放在域名后面,与域名连在一起比如说www.baidu.com:80
path:查找路径。比如:sz.58.com/chuzu/ 后面的/chuzu就是path
这个是你点开初始页面的某个项目,这个例子是点开了58租房的一个出租的页面,可以把初始页面类比成一个大文件夹,然后你点开哪一个页面就是点开哪一个小文件夹
有时候,这个类似文件夹的路径是虚拟的
query-string:查询字符串,比如:www.baidu.com/s?wd=python,后面的wd=python就是查询字符串
这个wd后面的python就是用户想要搜索的信息,比如去qq音乐里面搜一个歌手,你在搜索框里面填写歌手名,实际上是写在了wd的后面,然后后端再根据信息返回给你
anchor:锚点,前端用来做页面定位的。现在一些前后端分离项目,也用锚点来做
因为一个页面有很多板块,为了使页面更美观,我们会把一些信息分类,一类一类的去展示,这些板块标上号,就可以排版了,比如#1是目录,#2是歌手大全等等
常用的请求- Request Method
就是你打开一个网站时,你向服务器发送请求的方式,常用的有两种,一个是GET 一个是POST
一共是8种请求方式,其他6种与爬虫关系不大
一般来说,GET请求,我们不会向服务器发送数据,不会占用服务器的资源,几乎没影响

而POST请求是需要让服务器特意接收我们的信息,给我们预留空间,会对服务器产生一定的影响
这种都是我们要登录了,给服务器提醒,或者给服务器上传数据

出来这种信息,需要我们登录一下,就会出现这个文件了
常见的请求头参数
在http协议中,向服务器发送请求时,数据分为3种
第一种是放在链接url里面,
第二种是把数据放在参数体body里面,在post请求中有一部分就在body里面
第三个就是把数据放在请求头里面
User-Agent 浏览器名
就是服务器想知道你这个请求是哪个浏览器发送的

这里面一般有你请求的浏览器版本信息,还有你电脑配置的信息
我们以后写爬虫时,不填写这个信息,人家就会默认你是Python,人家后台用最简单的判断就能实现反爬技术,人家就会给你一些假数据或者直接拒绝你的请求
为了防止这样,我们要模拟自己是一个浏览器,自己填写User-Agent,所以要经常设置这个值,来伪装我们的爬虫
Referer
表明当前请求是从哪个url过来的,意思就是,我们的想要获取的页面,是从哪里来访问的
比如,我现在想登录淘宝网,那么登录界面就应该从主页点击而来

这里的referer表明我们是从京东主页过来的,也就是从京东主页发送请求而来到这个页面
有时候,人家也会检查你的referer来判断你来到当前页面是否合法,如果不合法就给你反爬
应对这个反爬机制,就需要我们自己指定一下referer,找指定页面
Cookie 身份证
一般是我们填写账号和密码后,服务器会给你一个特定的cookie,
服务器通过检查你的cookie来判断你的身份,
有cookie之后,再访问服务器就不需要登录了,就是身份证

一些反爬较强的网站会检测你是否有cookie,登录或者不登录都会检查cookie
没用cookie就会拒绝访问
这些参数如何设置,请听下回分晓
常见的响应状态码 - Response Code
就是我们向服务器发送请求,服务器会返回一个状态响应码

返回
-
200:请求正常,服务器正常的返回数据。
-
301:永久重定向。比如在访问www.jingdong.com的时候会重定向到www.id.com.
- 就是你访问的是旧网址,人家不用了,给你指向新的地址
-
302临时重定向:比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录页面。
- 就像知乎一样,知道你没登录就强制跳转到登录页面,哪怕你再访问知乎主页,还是会被传回登录页面,这个传送就是临时重定向

-
400/404:请求的url在服务器上找不到。换句话说就是请求链接url错误。
-
403:服务器拒绝访问,权限不够,或者是被反爬了
-
500:服务器内部错误。可能是服务器出现bug了,或者宕机了。 这个与咱们无关
分析网页
网页分为两类:静态网页和动态网页
静态网页 - 源代码
就是计算机向服务器发送请求,服务器一次性把所有内容打包发送给我们
像是4399啊或者一些工具网站啊,就是那种一次性展示所有的固定信息的网站
我们可以选择源代码的方式获取数据
动态网站(异步加载) - 抓包
就是计算机向服务器请求数据,服务器第一次只给框架,等计算机接收完之后再次请求,服务器才把真正的数据发送过来。然后计算机开始填充内容,进行拼接
相当于一次请求分了好几步才给你整个页面
这种方式,源代码中一般只有框架,不是我们想要的,所以我们通过抓包的形式,去找数据包

找到的数据包,是json文件,需要进一步拆分

像这种信息比较全的,就是服务器第二次向浏览器发送的数据包了
然后就是浏览器自己拼接了
抓包工具
Elements
帮助分析网页结构,有的数据是ajax请求的,也就是二次请求,就是异步加载的数据包,不在源代码里面
Network
查看整个网页发送的所以网络请求
Requests----get
获取静态网页并保存在本地文件中
用浏览器打开这个文件,就可以访问这个网页了
基于www.hao123.com做一个网页采集器
下面是作业:基于www.hao123.com做一个网页采集器
# https://www.baidu.com/s? 这个网址问号?后面的都是数据了
# tn=50000021_hao_pg
# &ie=utf-8&sc=UWd1pgw-pA7EnHc1FMfqnHTzPH64PjTYn1TzPiuW5y99U1Dznzu9m1Ykn1TvnW04njms
# &ssl_sample=normal
# &srcqid=8885165236642971965
# &H123Tmp=nunew7
# &word=%E5%91%A8%E6%9D%B0%E4%BC%A6# tn: 50000021_hao_pg
# ie: utf-8
# sc: UWd1pgw-pA7EnHc1FMfqnHTzPH64PjTYn1TzPiuW5y99U1Dznzu9m1Ykn1TvnW04njms
# ssl_sample: normal
# srcqid: 8885165236642971965
# H123Tmp: nunew7
# word: 周杰伦
上面是自己先搜索任意一个关键字,得到的网址
然后打开network找包头,就是这些data数据tn,ie等等,然后发现word就是我们填充关键字的地方import requests 导入这个模块keyword = input('请输入要查询的内容:') 索取关键字
url = f'https://www.baidu.com/s?word={keyword}' 只需要给个网站域名www..com,再给个关键字就好了qingqiu_header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'} 这是从自己的浏览器复制过来的请求头,
这里要把请求头以字典(键值对)的格式赋值给我们的请求头results = requests.get(url=url,headers = qingqiu_header ) 通过查看浏览器的network任意一个文件发现是get的获取方式,就用get发送请求,参数把我们的网址填进去,然后再把请求头填进去,模拟浏览器请求
如果不写请求头,将返回乱码print(results) -- 200 正常访问
print(results.url) -- 查看我们输入的网址 https://www.baidu.com/s?word=%E5%91%A8%E6%9D%B0%E4%BC%A6
print(results.request) ---返回请求的类型,比如get/post
print(results.request.headers) --- 查看请求头,也就是user-agent,如果我们填写了请求头,这个结果和请求头是一样的如果没有填写请求头,就会返回默认值{'User-Agent': 'python-requests/2.32.3', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}发现默认是python,直接反爬,让我们得到乱码print(results.text) 这里是显示一下你获取的数据,以text的格式with open(keyword + '.html','w',encoding='utf-8') as f: 这里是把数据储存在本地文件里面,你用浏览器可以打开这个文件f.write(results.text)print(f'已下载成功……{keyword}') 告诉用户,你已经成功把网页保存起来了步骤:
- 搜索任意关键词
- 获取网址 www…com
- 找请求头user-agent
- 找关键词对应的接口
- 把关键词和网址以及请求头作为参数使用requests模块
- 检查状态响应码是不是200
- 以text的格式查看返回的内容是真实有效
- 以只写的形式创建文件,把网页写进去,就保存好了
Requests—post
首先知道什么是异步获取,判断是post请求

然后点开负载,也就是data数据

不难发现,只有一个数据,这个数据就是我们输入的文本
也就是以后我们填写关键词的地方
然后就是筛选数据

这是在data值下的第0位元素中v的值
基于百度翻译,实现文本翻译
# https://www.hao123.com/
import pprint 格式化模块
import requests 请求模块keyword = input('请输入要查询的单词:')
url = 'https://fanyi.baidu.com/sug'headersss = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'}data = {'kw':f'{keyword}'}ret = requests.post(url=url,headers=headersss,data=data) 就比get多了个data参数# pprint.pprint(ret.json()) 先用这里找数据ret_json = ret.json() 超文本转json字典格式
print(str(ret_json['data'][0]['v'])) 最后打印找到的数据基于豆瓣电影,获取华语评分前十电影(失败,原因:该产品程序员对网页做出了调整,跟着课做不出来)
数据解析
- 正则表达式
- xPath
- BS4
正则表达式
概念: 根据某种方法从字符串中找到想要匹配的数据 , 就是给你篇文章让你找个词,圈出来这个词在哪些地方
优点:速度快,准确度高
缺点:新手入门难度大
匹配单个字符
- 单个字符点 ” . “ ,可以匹配任意单字符 1,2,3,4,5,6,7,我,@,空格
- 两个点 ” … “ ,可以两两匹配字符,就是 12,34,56,78
- ” \d “,可以匹配单个数字,就是值匹配字符串里面的数字
- ” \d\d “,就是匹配两个相邻的数字,比如,相约1980年,匹配19,80 几个斜杠d,就是匹配几个数字
- ” \D “,匹配非数字内容,单个字符
- ” \w “,匹配数字,字母和下划线
- ” \W “,就是跟小w取反,非数字非字母非下划线
- ” \s “,匹配空格、换行符、制表符等等看不见的东西
- “ \S ”,取反
- “ [] ”,组合匹配,将文本与方括号内的的任意字符匹配,只要有一个字符能匹配上就行
- [a-z] 匹配所有的小写字母
- [a-zA-Z] 匹配所有的大小写字母
- [a-zA-Z0-9] 匹配所有的字母和数字
- [a-zA-Z0-9_@$] 匹配括号里面全部的内容,字母数字和你输入的特殊符号
- 理论上这个匹配规则可以取代上面所有的"\什么东西"
匹配多个字符
示例一 ------以中间部分内容
电话:123456
电话:1122334455
电话:123
电话:
- 电话:\d 匹配前三行到数字1的位置
- 电话:\d* 匹配全部,数字可以是0个
- 电话:\d+ 匹配前三个,至少一个数字的
- 电话:\d? 匹配0或者1个
- 电话:\d{6} 匹配前两个,至少6位数电话的前6位
- 电话:\d{6,} 匹配前两个,至少6位数的电话
- 电话:\d{6,8} 匹配前两个,位数是6到8的电话
示例二 ------以开头^
112233
123aaa
ab123
- ^\d 匹配以数字开头的字符串 , 前两个的第一位数字
- ^\d+ 以数字开头的字符串,只匹配数字部分,第一个的全部,第二个的数字部分
示例三 ----以结尾判定$
123.@qq.com
www.222.com
666.cn
-
com$ 匹配前两个的com部分
-
.*com$ 匹配前两个全部
-
在 Python 的正则表达式中,
.*是一个常用的模式,具体含义如下:.: 匹配任意字符(除了换行符\n)。*: 表示匹配前面的字符(在这里是.)0 次或多次。
因此,
.*的整体含义是:匹配任意数量的任意字符,包括零个字符,直到遇到不符合匹配条件的字符(如果有的话)。
-
-
^www.*com$ 组合一下,就是以www开头,以com结尾的第二个了
贪婪匹配与非贪婪匹配*?+
对于123456来说
- \d* 默认尽量匹配最多,最少是0个,也就是123456
- \d*? 按照*最少的数量匹配,也就是不匹配
- \d+ 至少匹配一个,默认是尽可能多,也就是123456
- \d+? 也就是按照+的最少数量匹配,1,2,3,4,5,6
对于网页的源代码来说,比如
<h1>这是标题<h1>
- <.*> 匹配全部<h1>这是标题<h1> 贪婪模式
- <.*?> 匹配<h1> 非贪婪模式
正则表达式的应用案例
匹配手机号 1[3-9]\d{9}
首先是数字1开头
第二位一般是3到9的其中一个
然后是剩下的9个数字
匹配邮箱 \w+@[0-9a-z]+.[a-z]+
对于112233@168.com来说
使用\w+ 贪婪匹配字符串,这里就分割成了112233,168,com三个字符串
再加上一个@,成为\w+@,限定字符串是以@结尾的
接着就是域名了,比如QQ邮箱就是@qq.com,还有@168.com等等,一般是数字和小写字母[0-9a-z]
再跟着一个+,就是贪婪匹配数组和小写字母的字符串的最大长度,
最后是那个com,用小写字母匹配,再贪婪一下,就好了
匹配网址 (https:|http:\ftp:)//\S+
首先是常见的网址开头,有三个https和http以及ftp
因为这三个头都有可能,所以想要全部匹配,需要用到圆括号括起来,再用一个竖“|”表示或,就可以了
去除开头剩下的内容不为空就可以了,用\S,贪婪一下
匹配身份证号 \d{17}[xX\d]
一般是17位数字,加上最后一位,可能是x也可能是数字
正则表达式re模块
一个负责处理字符串内容的模块,也就是网站中超多的源代码,超文本等等
这也是python内置的模块,不需要下载,直接导入就可以了
因为要在正则表达式中频繁使用转义字符,在python解释器中更期望两个反斜杠的用法
比如,在字符串中使用反斜杠要注意转义的问题,这里使用\d{4}会报错,使用\\d{4}就没事了
最低级的字符串处理函数match
这个函数只能完全匹配字符串才能提取内容
这个函数的返回值不能直接使用,需要配合group函数,才能把match识别的信息提取出来
把需要提取的信息用正则表达式括起来,group(1)对应的就是第一个括号提取的内容,group(2)对应的就是第二个括号了,剩下的一次类推
还有一种方法可以一次性提取所有括号的内容,也就是groups(),这个函数会把提取的内容放到一个元组里面,可以以数组的形式打印出来
text = '姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日'# match 函数只能从起始位置匹配整个字符串,最麻烦的一种,一旦“姓名”改成“1姓名”就识别不出来了t1 = re.match('姓名',text)
print(t1)
# 如果直接打印match的返回值,就会显示所有内容,如,<re.Match object; span=(0, 3), match='姓名'>
# 如果这个字符串里面没找到macth第一个参数的字符串,就会返回“NoneType”
# 这里还要进一步筛选,使用group函数,返回match识别的内容
print(t1.group()) # 姓名# 这里可以用正则表达式,对字符串进行划分
# 如
t2 = re.match('姓名:.*出生日期:\\d{4}',text)
print(t2.group()) # 姓名:小明 出生日期:2000t2 = re.match('姓名:.*出生日期:\\d{4}.*毕业年龄:\\d{4}',text)
print(t2.group()) # 姓名:小明 出生日期:2000年1月1日 毕业年龄:2024t2 = re.match('姓名:.*出生日期:(\\d{4}).*毕业年龄:(\\d{4}).*',text)
print(t2.group(1)) # 给想要提取的信息加上圆括号,再使用group函数,从左往右,从1开始,打印匹配的内容
# t2.group(1) 就是2000
# t2.group(2) 就是2024
print(t2.groups()) # 也可以把这些内容以元组的形式打印出来 ('2000', '2024')
print(t2.groups()[0]) # 这里就是打印元组的第0个元素 2000
中级字符串处理函数search
这个函数比较高级,不需要完全匹配字符串,它可以自己去找对应的位置,如果找不到则返回NoneType
这些函数找不到对应内容基本上都是返回这个语句NoneType
这个函数,只能返回第一个匹配的内容,意思就是处理多个相同内容时,这个语句只能返回一次内容
text2 = '姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日'
t1 = re.search('出生日期:(\\d{4}).*年龄:(\\d{4})',text2)
print(t1.group(1),t1.group(2),t1.groups())# search中使用groups也是放到元组里面
# 扫描整个字符串返回第一个与之匹配的内容,意思就是处理多个相同内容时,这个语句只能返回一次内容
高级字符串处理函数findall 也是常用的函数
这个函数可以一次性扫描整个字符串,并把匹配的内容打印出来,如果有多个匹配的内容就以列表的形式打印出来
# re.findall 直接打印会放到一个列表里面,想要提取出来,只需要和使用数组一样,加个方括号就好了
text3 = '姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日'
t3 = re.findall('出生日期:(\\d{4}).*年龄:(\\d{4})',text3) # 如果要识别的内容有多个,就会先放到列表里面,再放到元组里面,想要提取内容需要再使用方括号
print(t3) [('2000', '2024')]text4 = """
姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日
姓名:小李 出生日期:2001年2月1日 毕业年龄:2024年7月1日
姓名:小张 出生日期:2002年2月2日 毕业年龄:2024年8月1日
"""t4 = re.findall('出生日期:(\\d{4}).*年龄:(\\d{4})',text4)
print(t4) # 对于多个相同内容的字符串就会把一行里面的内容放到一个元组里面去,有几组内容就有几个元组 [('2000', '2024'), ('2001', '2024'), ('2002', '2024')]t5 = re.findall('出生日期:(.*?) 毕业',text4) # 使用非贪婪模式,避免匹配的内容不理想
print(t5) ['2000年1月1日', '2001年2月1日', '2002年2月2日']
当然现在的编译器比较智能了,这个贪婪与非贪婪有的时候没啥区别,为了严谨一些,还是自己区分一下吧
字符串替换函数sub
这个的使用原理和replace函数是一样的,但是sub可以使用正则表达式,在处理问题的时候更加灵活
第一个参数是正则表达式,第二个是要替换的内容,第三个是参考文本
不会改变原来的内容,只是在原来的基础上更改后保存在新的变量中
# re.sub() 替换函数
text5 = '0566-12345678'
t6 = re.sub('^\\d{4}','0333',text5) # 第一个参数是正则表达式,第二个是要替换的内容,第三个是参考文本
print(t6,text5) # 并不会对原来的文本进行替换,只是把替换后的内容放到新变量里面text6 = '0566-123123123'.replace('0566','0333')
print(text6) # 他们的效果一样,但是sub更灵活,当内容不一样时,还是正则表达式通用
案例 小说筛选器
text = """
<div class="noveContent">
<p>1945年四月,山城。</p>
<p>宋孝安,果党军统内勤处第三科科长,中校军衔,因为信佛又极为擅长布局、算无遗策,被称之为‘军统小诸葛’。</p>
<p>此时他神情紧张,听着戴老板办公室时不时传出来的呵斥声,让他额头上的汗珠没断过。</p>
<p>手上拿着佛珠,不停地转动着:“明诚长官,你可把我害惨了啊。”</p>
<p>此时他不祈祷能够升官发财,只求不被枪毙。</p>
<p>戴笠,军事委员会调查统计局副局长,军衔少将,实际上是军统的实际控制人,此时他非常生气,看着眼前的陈汉文,一手叉腰一手拿着手绢指着对方:“谁让你跑到沪上杀人的?76号总部被你炸上了天,李士群死了,丁默邨被你刺成重伤,如果不是他运气好,现在也被你送上天了,你想怎么样?我有没有和你说过,我们和76号不是敌人,在陕北的共党才是,还有新四军……”</p>
<p>陈汉文坐在沙发上,旁边戴笠的训斥就当没听到,看到水烧开后,他端起来开始泡茶。</p>
<p>陈汉文,字明诚,少将衔,军统总务处处长。</p>
"""
t7 = re.sub('<.*?>',' ',text)
print(t7) # 完成了字符串的替换,这里是把网页的格式字符全部替换为空
字符串分割函数split
第一个参数是想要分割的标识符,像是逗号句号或者空格
第二个参数是需要处理的文本
# re.split() 字符串分割 按照设计的正则表达式的格式,把字符串分割后放在列表里面
text4 = '你好 python 工程师'
t9 = re.split(' ',text4)
print(t9) # ['你好', 'python', '工程师']text4 = '你好,python.工程师'
t9 = re.split('[,.]',text4) # 使用正则表达式更灵活 上面的那个也可以是t9 = re.split('[ ]',text4)
print(t9) # ['你好', 'python', '工程师']
换行加注释
注意在多行语句组合一句话的时候,需要用三个”“”双引号“”“
# 换行加注释
text2 = '姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日'
t10 = re.findall("""
出生日期:(\\d{4}) # 现在就可以添加注释了
.*年龄:(\\d{4}) # 比如解释说明,这里提取的是毕业年龄
""",text2,re.VERBOSE) # re.VERBOSE 可以忽略#和换行符以及中间的内容
print(t10)
findall的第三个参数re.VERBOSE,意思是告诉程序,在正则表达式里面换行了,而且可能还有注释
re.VERBOSE标志通常与re模块中的re.compile()、re.search()、re.match()、re.finditer()等函数一起使用。- 这样可以很方便地写出复杂的正则表达式,同时在其中添加注释和换行,使其更加清晰。
正则表达式预处理compile
正则表达式的预处理,因为对于字符串的处理可能高达上万次,那么我们就需要考虑一下预处理
把正则表达式提前处理成被执行的格式,如果不预处理,每次遇到字符串都要重新编译,预处理提高效率
# 预编译re.compile
text5 = '姓名:小明 出生日期:2000年1月1日 毕业年龄:2024年6月1日'
tt = re.compile('出生日期:(\\d{4}).*年龄:(\\d{4})') # 正则表达式预处理格式放在tt里面
t11 = re.findall(tt,text5) # 按照tt的格式,对text5处理
print(t11)
正则表达式的转义字符与原生字符
对于一个语句中,如果含有转义字符,比如“\d”,“\n”等等
我们想要直接打印就会出现问题
text = 'hello\nihao\didi'
print(text)
如果你是在python解释器pycharm中,复制这段话,就会发现"\n"跟其他的字符不太一样
你尝试打印一下
hello
ihao\didi
就是这种结果,可能程序还会报错,因为\d是字符串插入数字的标识符
\n 没了
因为\n有自己的意思,是换行符,也是在字符串中出现,
现在你不想转义,就想打印hello\nihao\didi这句话
-
要么在已有的反斜杠前面或者后面再加一个反斜杠,组成两个反斜杠
-
要么就是在字符串前面加一个小写的r,比如,text = r’hello\nihao\didi’
- 这个小写的r原型是raw意思是原生,就是告诉程序别转义
案例 美元$与正则表达式取结尾$
This apple is available for $5 and $7
如果直接放在正则表达式里面,想要提取5美元和7美元这个价格
很明显我们需要的是$这个标识符,还有"\d+"
解决方式有两个:
- ”\$\d+“
- r"$\d+"
案例 以反斜杠作为标识符
abc123\water
在这里,我们想要提取反斜杠前面的123这个数值
需要用到反斜杠作为标识符,我们想要的是”(\d+)\“
可惜的是,你使用字符串函数,并把这个内容作为正则表达式,会报错
第二个反斜杠会和后面的引号结合,此时你想再用一个反斜杠,很抱歉又错了,在程序预编译的时候会处理掉一个反斜杠
程序又会把这个反斜杠和引号结合
所以只能再加两个反斜杠,也就是4个反斜杠在预编译的时候,每两个反斜杠消去一个,最后真正执行的时候,还剩两个,程序就能识别了
text = 'hello\water'
t1 = re.findall("(\d+)\\\\",text)
print(text)
上面这些话证明了使用反斜杠来转转义字符很麻烦,我们只需要
t1 = re.findall(r"(\d+)\\",text)
使用r固定这个字符串,不让程序在预处理的时候消去反斜杠就可以了,
案例 匹配网页的标题
首先,拿到两个源代码,分析一下,发现标题从=后面开始,A站前面结束
我们直接放到正则表达式里面,然后把想要提取的部分弄成(.*?)
text1 = '<meta name="keywords" content="【AC独家】千星绪~又谁在月牙下做一曲新谣,舞蹈·偶像,宅舞,楚殅南w,A站,AcFun,ACG,弹幕">'
text2 = '<meta name="keywords" content="戴眼镜的可以吗......(今日开心视频:1541),娱乐,搞笑,表情笑笑坊,A站,AcFun,ACG,弹幕">'
t1 = re.findall('<meta name="keywords" content="(.*?),A站,AcFun,ACG,弹幕">',text1)
t2 = re.findall('<meta name="keywords" content="(.*?),A站,AcFun,ACG,弹幕">',text2)
print(t1,t2)
这个案例是想要讲带有表情的网址,比如B站的 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili这个表情
有时候也会在正则表达式里面出现,如果正则表达式里面有这些括号什么的,也需要反转义字符
正则表达式xPath模块(XML Path Language)
这个模块主要是处理网页(XML和HTML)源代码里面的内容,因为大部分的信息都是放在源代码的元素和属性中
像是字符串、图片、音频等等
xPath节点
在源代码中有七种类型的节点:
- 元素
- 属性
- 文本
- 命名空间
- 处理指令
- 注释
- 文档(根)节点
XML文档被xPath看成节点树,也是从根出发,用Tab对齐来控制子节点父节点,这些节点之间的关系
xPath语法
| 表达式 | 描述 |
|---|---|
| nodename | 直接写这个节点的名字,就是选它所有的子节点 |
| / | 一个斜杠,从根节点选取 |
| // | 两个斜杠,就是从整个源代码中任意位置匹配节点(相对简单一些,不用找头节点) |
| . | 一个点,意味着选取当前节点 |
| … | 两个点,选取当前节点的父节点 |
| @ | 选取属性 |
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| //book | 选取所有 book子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为lang 的所有属性。 |
谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于bookstore 元素的子元素的book元素 |
| //title[@lang] | 选取所有拥有名为lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为eng的lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore元素的所有book元素,且其中的price 元素的值须大于35.00。 |
| /bookstore/book[price>35.00]/title | 选取bookstore元素中的book元素的所有title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
| 通配符 | 描述 |
|---|---|
| /bookstore/* | 选取bookstore元素的所有子元素 |
| @* | 选取文档所有元素 |
| //title[@*] | 选取所有带有属性title的元素 |
选取若干路径
使用“|”可以一次访问多个对象
| 路径表达式 | 结果 |
|---|---|
| //book/title|//book/price | 选取book元素的所有title和price元素 |
| //title|//price | 选取文档中所有title和price元素 |
| /bookstore/book/title|//price | 选取属于bookstore元素的book元素的所有title元素,以及整个文档中所有的price元素 |
数据解析
xPath-lxml库的使用
lxml库
- Ixml 是 一个HIML/XML的解析器,主要的功能是解析和提取HTML/XML 数据
- Ixml和正则一样,也是用C语言实现的,是一款高性能的 Python HIML/XMI解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
- lxml python 官方文档:http://lxml.de/index.html
lxml库-读取本地xml文件
- 我们可以利用他来解析IIML代码,并且在解析HIML代码的时候,如果HIML代码不规范,他会自动的进行补全。
- from lxml import etree
- 这是导入模块
- xml= etree.parse(xPath test1.html’)
- 这里是把本地文件读入xml或者html,直接打印是一颗etree树
- parse对文档的语法极为严格,少一点就会报错
- print(etree.tostring(xml).decode('unicode ))
- etree.tostring(xml) 这里是把树拿出来了,但是以字节byte的形式打开的
- 所以还要etree.tostring(xml).decode( )再加一个函数,意思是以字符串的形式打开
使用HTML的方式读入文件
使用HTML读文件的时候,对文件比较友好,可以抛弃parse了
定位元素

-
定位“xPath练习”
/head/title/text()
意思是找到节点head再找title节点,找到title节点之后再访问title节点里面的文本信息
-
定位”百里守约“
/body/div/p/text()
-
定位”李清照“
/body//div[@class=“song”]//p/text()
定位body节点,找属性值位class=“song”的div节点,再访问下面的所有p节点,打印p节点的文本部分
有多个对象的时候,会得到一个列表,这里的李清照排在第一位,可以使用列表的形式得到信息
假如,我们用对象result来接收这个列表,打印李清照就是result[0]
如果是倒数第3个也可以是result[-3]
-
定位属性”song“
这里是获取节点的属性值
有时候,一些信息是包在属性里面,我们就需要得到他们
//body//div/@class
这个操作就是,先找body节点,下面的div节点的属性class的值,也就是等号后面引号包起来的东西
按标签顺序定位元素
这里的李清照是第一个p节点
可以使用,//body//div[@class=“song”]/p[1]/text() (从1开始)
last元素,指最后一个标签,比如上面的最后一个是苏轼,那么p[last]就是苏轼
按照包含的元素定位
上面的图片中,在body节点下面有两个div标签,这里的第二个div标签还包含一个a节点
所以每个div标签还能根据包含的子节点来定位,定位第一个div,//div[p]
定位第二个div节点,//div[p and a] ,意思就是这个div下面有两个子节点a和p
/与//的区别
单个/,意思就是从当前位置查找,就是你需要先找到一个确定的节点,才能使用/
单/,不太好用,需要写的特别具体,就像文件操作里面的绝对路径一样,需要从盘开始定位
双//,就是从任意位置查找,这里我们一般给了属性值,就只能找到一个节点,也就是我们想要的东西,这里就是文件操作的相对路径,写的东西比较少
python案例—下载人生格言
python项目实战-xPath下载人生格言-CSDN博客
python案例—下载美女图片
python项目实战——下载美女图片-CSDN博客
案例总结
写完这两个案例之后,感觉使用xPath语法提取内容,特别简单
就是确定内容都在源代码里面,把这个源代码转换成etree树,以节点树的方式,去获取信息
然后就是固定的几步:
- 使用requests模块得到源代码
- 使用etree.HTML函数,把源代码转换成节点树
- 使用xPath语法提取内容
掌握了这个语法之后,感觉一些比较基础的网址的任何内容都可以爬取了
比如,我为了查看自己在CSDN上发表的博客的浏览量,写了python实现csdn文章浏览量日志-CSDN博客
觉得只是查看,没意思,就加了一个获取时间的库,写成日志,记录我每次查看的时间和得到的数据,
这里还能改一改,比如,把查看的博客名称也记录在本地文件中,格式就是“博客名称+浏览量+记录时间”
回头看看,之前那个豆瓣电影,也能爬取了,,,暂且先不做了,继续往下开搞!
BS4–beautifulsoup4库
和lxml库一样,都是对HTML/XML的解释器,主要功能也是提取数据
lxml是局部遍历,beautiful soup是基于HTMl DOM(document object model),也就是整个文件解析DOM树
因为是对全部内容解析,所以性能要更低一点
BS4语法
导入库
from bs4 import BeautifulSoup
实例化
soup = BeautifulSoup(html,‘html.parser’) 第一个参数是html的文档,第二个是解析方式
解析方式有两种:html.parser和lxml,区别就是对字符的补全方式不同
一般使用第一个解析方式
soup库自带一个整理格式的函数,soup.prettify()这个函数就跟之前的pprint一样,但是这个是以html的格式显示
对象的种类
- Tag:
Tag 通俗点讲就是 HTML 中的一个个标签。我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.tag。但是注意,它查找的是在所有内容中的第一个符合要求的标签。 - NavigableString:
如果拿到标签后,还想获取标签中的内容。那么可以通过tag.string获取标签中的文字。 - BeautifulSoup:
BeautifulSoup 对象表示的是一个文档的全部内容,大部分时候,可以把它当作Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法. - Comment:
Tag,NavigableString,BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象,容易让人担心的内容是文档的注释部分Comment 对象是一个特殊类型的NavigableString 对象
这个Conmment就是针对注释部分的类型
获取标签
print(soup.a) 就可以拿到整个a标签的全部内容,包括属性和文本部分
soup.a的类型就是bs4.element.Tag
获取标签的名称
print(soup.a.name) 打印出来就是a
获取标签的属性/属性值
print(soup.a.attrs) 打印出来的就是一个字典,包含是所有的属性{’属性名‘:’属性值‘,’属性名‘:’属性值‘,’属性名‘:’属性值‘}
想要打印具体的属性值
print(soup.a[‘href’]) 打印的就是a标签的href属性的值
还有另一种方式,print(soup.a.get(‘href’)) 和上面那个一样
改变标签的属性值
soup.a[‘href’] = ‘hello’
print(soup.a)
获取标签的文本内容
print(soup.a.string) 就相当于lxml里面的//a/text()
print(soup.a.text)
print(soup.a.get_text())
这三个都是一样的效果,他们的type都是bs4.element.NavigableString
获取注释部分的内容
<b>
<!–Hey,How are you?–>
<b>
上面这个以!感叹号开头的标签是一个注释
# 导入库
from bs4.element import Comment
print(soup.b.string) # Hey,How are you?
print(ytype(soup.b.string)) # 类型是bs4.element.Comment
遍历文档树
- contents和children :
contents:返回所有子节点的列表 就是以列表的形式打印节点
children:返回所有子节点的迭代器 打印子节点,默认不显示换行符,可以使用repr的方式显示出来 - strings 和 stripped_.strings
strings:如果tag中包含多个字符串 ,可以使用 .strings 来循环获取
stripped_strings:输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容
body_tag = soup.body
print(body_tag.contents) 打印列表
for tag in body_tag.children: 循环得到子节点print(tag) 打印子节点print(repr(tag)) 显示换行符的方式打印子节点 ,与上一条语句有一个就行
for tag in body_tag.strings:print(tag)
# 直接打印,不显示换行符,有很多空白
# 使用repr函数,显示换行符,减少空白
# 但是不想要换行符,也不想要空白
for tag in body_tag.stripped_.strings:print(tag)# 可以去除换行符也没有空行
搜索文档树
- find和find_all方法:
搜索文档树,一般用得比较多的就是两个方法,一个是find,一个是find_all。
find方法是找到第一个满足条件的标签后就立即返回,只返回一个元素。
find_all方法是把所有满足条件的标签都选到,然后返回。
- find
tr = soup.find('tr')
print(tr)
# 会把第一个tr标签包含的所有内容全部打印出来
-
find_all
trs = soup.findall('tr') print(trs) # 返回的是一个列表,包含的是所有的tr标签 # 使用for循环可以打印出来 for tr in trs:print(tr)print('--'*30) # 分隔符
- 获取id='nr’的标签,有两种写法
- 直接写属性
trs = soup.find_all('tr',id='nr')
for tr in trs:print(tr)print('**'*30)
在获取tr标签的基础上,多了一个条件id=nr
- 以字典的形式把属性以键值对的形式填入
trs = soup.find_all('tr',attrs={'id':'nr'})
for tr in trs:print(tr)print('**'*30)
他们的效果是一样的
- 获取有两个特定属性的标签
tds = soup.find_all('td',class_="odd",align="center") # 因为class是python的一个关键字,这里不想作为关键字使用,需要额外在后面加一个下划线
for td in tds:print(td) # 直接打印td,得到的是所有的td标签
for td in tds:print(td.text) # 加个后缀就可以得到文本部分了 # 根上面一样,也有两种写法
tds = soup.find_all('td',attrs={'class'='odd','align':'center'}) # 跟上面的效果是一样的
- 获取所有属性值target=‘"_blank"的a标签的href的属性
a_list = soup.find_all('a',target=‘"_blank")
for a in a_list:print(a) # 直接打印,得到的是a的整个标签页
for a in a_list:print(a['href']) # 这里是只打印a标签的href的值
for a in a_list:print(a.get('href')) # 这里跟上面的效果一样
- 获取多个内容,这里是从小说网页上爬取小说的作者,名称,链接,日期等信息,以列表的形式打印
trs = soup.find_all('tr',id = 'nr') # 这里是获取了一本小说的整个标签
info = [] # 创建空列表,放小说的基本信息
# 下面就是从获取的整个标签里面摘除想要的信息
for tr in trs:tds=tr.find_all('td') # 这里是进一步取出标签信息link = tds[0],a['href'] # 获取a标签的href属性值name = tds[0].a.string # 获取a的文本部分author = tds[2].text #获取第3个标签的文本部分date = tds[4].text # 获取第5个标签的文本部分info.append([link,name,author,date]) # 把信息存入列表print(info)
上面的代码展示了获取信息的多种方式,比如,string,get,text等等
CSS选择器
使用该选择器,需要使用soup.select方法
-
查找所有的tr标签
print(soup.select(‘tr’))
-
查找类名是odd的标签,这里的类就是class,也就是class=‘odd’
print(soup.select(‘.odd’)) 意思就是class=’odd‘,但是可以简写成’.'+‘odd’
-
查找所有id是center的标签
print(soup.select(‘#center’)) 意思就是id=‘center’ ,这里也是简写’#'+‘center’
-
组合查找
-
p标签下面包含属性值为id=link2的标签
print(soup.select(‘p #link2’)) 先写一个p,说明想要的是p标签,后空一格,说明要找下面的值,即id=link2
如果不加空格,说明这个属性值是p的,就会按照既是p标签还有属性值的p,就不再是p标签下面的某标签的属性值
-
p标签下面的所有a标签
print(soup.select(‘p a’))
-
-
查找属性值 target = "_blank"的 a 标签
print(soup.select(‘a[target=“_blank”]’))
-
获取属性值及文本内容
获取a标签的所有文本内容,及href的属性值
a = soup.select('a') for i in a:print(i.text)print(i.get('href'))
这些文本操作都差不多,都是筛选信息的
相关文章:
爬虫基础---python爬虫系列2
爬虫基础 文章目录 爬虫基础爬虫简介爬虫的用途爬虫的合法性规避风险看懂协议反爬机制反反爬策略 认识HTTPHTTP协议--HyperText Transfer ProtocolHTML--HyperText Markup LanguageHTTPS如何查看网站是什么协议呢使用端口号 URL组成部分详解常用的请求- Request Method常见的请…...

jmeter在beanshell中使用props.put()方法的注意事项
在jmeter中,通常使用beanshell去处理一些属性的设置和获取的操作,而这些操作也是有一定的规则的。 1. 设置属性时,在属性名上要加双引号,这代表它不是一个需要用var去声明的变量 这种设置属性的方式才是有效可行的,在…...

息肉检测数据集 yolov5 yolov8适用于目标检测训练已经调整为yolo格式可直接训练yolo网络
息肉检测数据集 yolov5 yolov8格式 息肉检测数据集介绍 数据集概述 名称:息肉检测数据集(基于某公开的分割数据集调整)用途:适用于目标检测任务,特别是内窥镜图像中的息肉检测格式:YOLO格式(边…...

通过API进行Milvus实例配置
更新Milvus各个组件的配置参数。 调试 您可以在OpenAPI Explorer中直接运行该接口,免去您计算签名的困扰。运行成功后,OpenAPI Explorer可以自动生成SDK代码示例。 编辑调试 授权信息 下表是API对应的授权信息,可以在RAM权限策略语句的…...

Excelize 开源基础库 2.9.0 版本正式发布
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准。可以使用它来读取、写入由 Excel、WPS、OpenOffice 等办公软件创建的电子表格文档。支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式…...

人脸识别-特征算法
文章目录 一、LBPH算法1.基本原理2.实现步骤3.代码实现 二、Eigenfaces算法1.特点2.代码实习 三、FisherFaces算法1.算法原理2.算法特点3.代码实现 四、总结 人脸识别特征识别器是数字信息发展中的一种生物特征识别技术,其核心在于通过特定的算法和技术手段…...

C++【内存管理】(超详细讲解C++内存管理以及new与delete的使用和原理)
文章目录 1.C/C内存分布2.C语言中动态内存管理方式3.C内存管理方式3.1 new/delete操作内置类型3. 2new/delete操作自定义类型 4. operator new与operator delete函数(重点)5. new和delete的实现原理5.1 内置类型5.2 自定义类型5.2.1 自定义类型调用new[]…...

elementUi el-table 表头高度异常问题
1、现象 在同一个页面通过状态切换不同table时,当从有合并标头行的table切换到无合并表头的table时,无合并表头的table的表头的高度异常了,如下图 切换后 2、解决 给每个el-table 加上一个唯一的key <el-table key"1"></…...

kubekey的应用
随着 Kubernetes 社区的不断发展,即将迎来 Kubernetes 1.30 版本的迭代。在早先的 1.24 版本中,社区作出一个重要决策:不再默认集成 Docker 作为容器运行时,即取消了对 Docker 的默认支持。这就像咱们家厨房换了个新灶头ÿ…...
如何识别并分类转录因子的家族
愿武艺晴小朋友一定得每天都开心 当我们有了差异表达的转录因子列表以后,接下来可能就想知道这些转录因子的家族分布情况是怎样的?有没有1-2个Family在其中起主要作用,占比较多。 基于这种需求,可以按以下几步来实现: 1)从AnimalTFDB4转录因子数据库中,根据需要…...

【C++11】可变模板参数详解
个人主页:chian-ocean 文章专栏 C 可变模板参数详解 1. 引言 C模板是现代C编程中一个非常强大且灵活的工具。在C11标准中,引入了可变模板参数(variadic templates),它为模板编程带来了革命性改变。它的出现允许我们…...
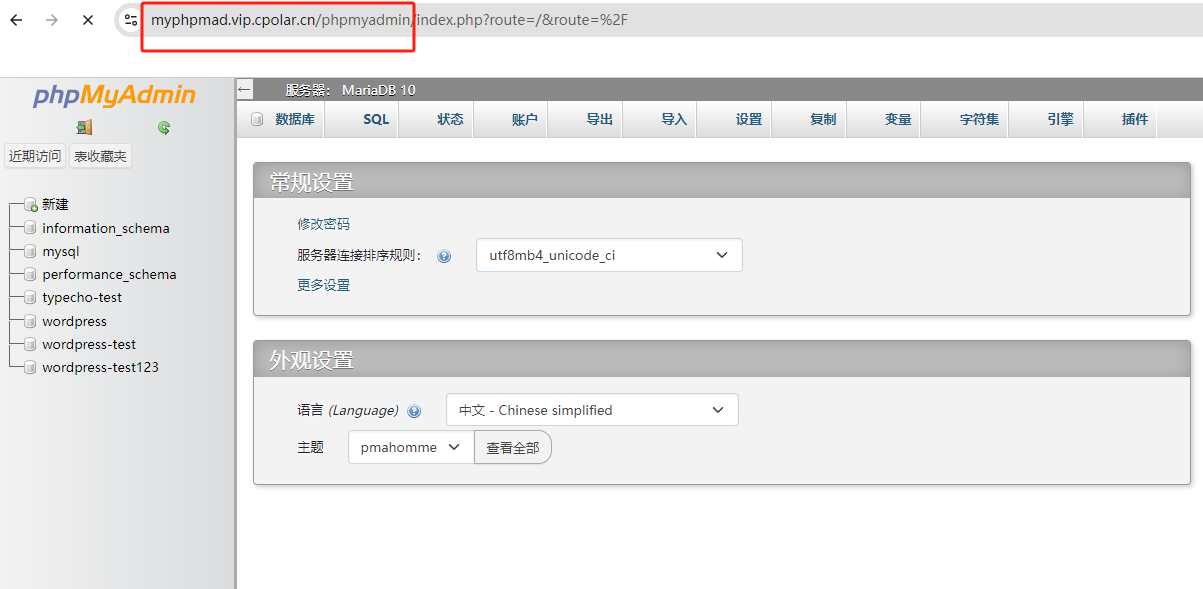
本地群晖NAS安装phpMyAdmin管理MySQ数据库实战指南
文章目录 前言1. 安装MySQL2. 安装phpMyAdmin3. 修改User表4. 本地测试连接MySQL5. 安装cpolar内网穿透6. 配置MySQL公网访问地址7. 配置MySQL固定公网地址8. 配置phpMyAdmin公网地址9. 配置phpmyadmin固定公网地址 前言 本文主要介绍如何在群晖NAS安装MySQL与数据库管理软件p…...

QTableWidget 接口详情
Qt Widgets->C Classes->QTableWidget Qt 5.12版本QTableWidget接口详情(机翻) QTableWidget类提供了一个带有默认模型的基于项的表视图。 属性 列数columnCount : int 行数rowCount : int 细节描述 QTableWidget类提供了一个带有默认模型的基…...

GESP CCF python四级编程等级考试认证真题 2024年9月
一、单选题(每题 2 分,共 30 分) 第 1 题 据有关资料,山东大学于1972年研制成功DJL-1计算机,并于1973年投入运行,其综合性能居当时全国第三位。DJL-1计算机运算控制部分所使用的磁心存储元件由磁心颗粒组成…...

oracle数据库名实例名服务名
Oracle数据库是一个复杂的系统,它包含多个组件,包括数据库服务器、实例和服务。 数据库名(DB_NAME):这是数据库的内部名称,通常在创建数据库时指定,并在整个数据库生命周期内保持不变。 实例名…...

python+appium+雷电模拟器安卓自动化及踩坑
一、环境安装 环境:window11 1.1 安装Android SDK AndroidDevTools - Android开发工具 Android SDK下载 Android Studio下载 Gradle下载 SDK Tools下载 这里面任选一个就可以,最终下载完主要要安装操作安卓的工具adb,安装这个步骤的前提是要…...

Python第七八次作业
1.输入一个大于0的正整数n,如果n 1 ,则返回1, 如果n是偶数,则返回 n // 2 ,如果n是奇数,则返回 3n 1,将所有的返回值存放到一个列表中,注意:n是第一个元素,其他的元素根…...
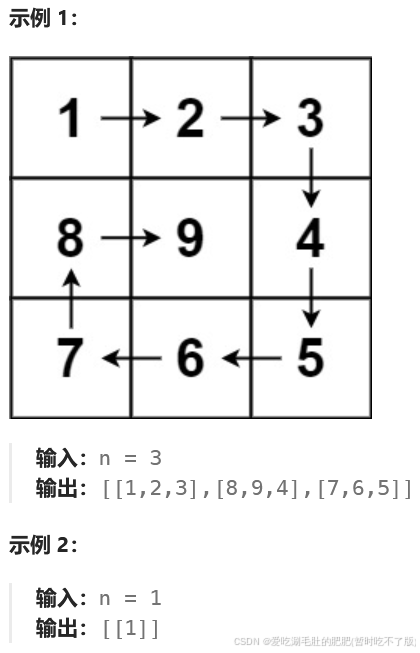
Leetcode——数组:螺旋矩阵59.螺旋矩阵
题目 思路 对于每层,从左上方开始以顺时针的顺序填入所有元素。假设当前层的左上角位于 (top,left),右下角位于 (bottom,right),按照如下顺序填入当前层的元素。 从左到右填入上侧元素,依次为 (top,left) 到 (top,right)。 从上到…...

C++类与对象-继承和多态(超全整理)
前言 前面讲类与对象上中下时,所讲的都是在单个类中相关的语法(初始化列表、this指针、静态成员、常函数和常对象......)或者使两个不同的类产生联系的语法(友元)。而本文虽然也是类与对象的内容,但和之前的…...

3.3 Thymeleaf语法
文章目录 引言Thymeleaf标签显示标签链接地址标签条件判断标签元素遍历标签 Thymeleaf表达式变量表达式选择变量表达式消息表达式链接表达式 Thymeleaf内置对象上下文对象上下文变量上下文区域请求对象响应对象会话对象日期对象 实战演练创建控制器创建模板页面 结语 引言 Thy…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

Visual C++运行库一键安装指南:彻底解决Windows应用依赖问题
Visual C运行库一键安装指南:彻底解决Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时弹出"缺少…...