CodeActAgent :Executable Code Actions Elicit Better LLM Agents解读
论文地址
https://arxiv.org/pdf/2402.01030.pdf
项目地址
https://github.com/svjack/CodeActAgent-Gradio/blob/main/README.md
代码智能体的优势
选择代码智能体有以下几个关键原因,它们相较于使用类似JSON的字典输出具有显著优势:
1. 代码的高效表达
如同Wang等人(2024)所展示的那样,代码在表达复杂操作序列方面极其高效。相比之下,JSON虽然也能表达操作序列,但其表现形式冗长且复杂。代码能够更加简洁地描述操作步骤,这使得其在处理复杂任务时更加理想。
2. 简洁性
代码操作比JSON简洁得多。例如,需要运行4个并行的5个连续操作流时,在JSON中你需要生成20个JSON块,每个在其独立的步骤中;而在代码中,这只需1步即可完成。这种简洁性不仅减少了操作步骤,还降低了错误发生的概率。
3. 成本效益
平均而言,使用代码操作比使用JSON减少了30%的步骤,相当于生成的tokens减少了30%。由于大语言模型(LLM)的调用通常是智能体系统的主要成本,减少30%的tokens意味着智能体系统的运行成本也减少了约30%。
4. 重用性
代码允许重用常见库中的工具,这进一步简化了开发和维护过程。通过调用已有的库函数或方法,开发者可以更加高效地构建和扩展智能体的功能。
5. 更好的基准测试表现
在基准测试中,代码通常表现更好,这主要有两个原因:
- 代码是一种更直观的表达操作的方式。
- LLM的训练数据中包含大量代码,这可能使得它们在编写代码方面比编写JSON更为流畅。
6. 变量管理的便利性
在代码中存储一个命名变量要容易得多。例如,需要存储一个由工具生成的岩石图像以供以后使用,可以轻松使用“rock_image = image_generation_tool(“A picture of a rock”)”将变量存储在变量字典中的“rock_image”键下。之后,LLM可以通过再次引用“rock_image”来在任何代码块中使用其值。
相比之下,在JSON中你需要进行复杂的操作来创建一个名称来存储这个图像,以便LLM以后知道如何再次访问它。例如,将图像生成工具的任何输出保存为“image_{i}.png”,并相信LLM稍后会理解image_4.png是内存中之前调用工具的输出?或者让LLM也输出一个“output_name”键来选择存储变量的名称,从而使你的操作JSON的结构变得复杂化。
7. 可读性
智能体日志的可读性大大提高。使用代码记录下来的操作步骤更容易理解和调试,这对开发和维护智能体系统非常重要。
如下是原文翻译
摘要
大型语言模型(LLM)代理,能够执行广泛的操作,例如调用工具和控制机器人,在解决现实世界的挑战方面显示出巨大的潜力。通常,LLM代理通过生成JSON或预定义格式的文本来产生行为,这通常受限于有限的操作空间(例如,预定义工具的范围)和有限的灵活性(例如,无法组合多个工具)。本研究提出使用可执行的Python代码将LLM代理的操作整合到一个统一的操作空间(CodeAct)。通过集成Python解释器,CodeAct可以执行代码操作,并通过多轮交互根据新的观察结果动态调整先前的操作或发出新的操作。
我们对17个LLM在APIBank和一个新创建的基准上的广泛分析显示,CodeAct的表现优于广泛使用的替代方案(成功率提高最多可达20%)。CodeAct的出色表现激励我们构建一个开源的LLM代理,该代理通过执行可解释的代码与环境交互,并使用自然语言与用户协作。为此,我们收集了一个包含7千次使用CodeAct的多轮交互的指令调优数据集CodeActInstruct。我们表明,它可以与现有数据一起使用,以改进面向代理的任务中的模型,而不会损害其通用能力。CodeActAgent通过在Llama2和Mistral上的微调,集成了Python解释器,并专门用于使用现有库和自主调试来执行复杂任务(例如,模型训练)。
介绍
大型语言模型(LLMs)已经成为自然语言处理(NLP)领域的关键突破。当它们与允许访问API的动作模块结合时,其动作空间超越了传统的文本处理范畴,使得LLMs具备诸如工具调用和内存管理的能力(Mialon等,2023;Schick等,2023),并能够涉足如机器人控制(Ahn等,2022;Huang等,2023;Ma等,2023)和进行科学实验(Bran等,2023)等现实世界任务。我们探讨:如何有效扩展LLM代理的动作空间,以解决复杂的现实世界问题?现有许多研究已经通过使用文本(Yao等,2022b;Park等,2023等)或JSON(Qin等,2023b;Chase,2022等)来生成动作(例如,图1左上角的工具使用)。然而,这两种方法通常面临受限的动作空间(动作通常为特定任务量身定制)和有限的灵活性(例如,无法在单个动作中组合多个工具)。作为一种替代方法,一些研究(Liang等,2022;Singh等,2023;Wang等,2023a)展示了使用LLMs生成代码来控制机器人或游戏角色的潜力。然而,这些方法通常依赖于预先指定的控制原语和手工设计的提示,更重要的是,它们难以根据新的环境观察和反馈动态调整或发出动作。本研究提出了CodeAct,一个通用框架,允许LLMs生成可执行的Python代码作为动作(图1右上角)。CodeAct旨在处理各种应用,并具备独特的优势:
- 集成了Python解释器,CodeAct可以执行代码动作,并根据多轮交互中接收到的观察结果(例如代码执行结果)动态调整先前的动作或发出新动作。
- 代码动作允许LLM利用现有的软件包。CodeAct可以使用现成的Python包来扩展动作空间,而不是手工制作的特定任务工具(Yuan等,2023;Shen等,2023)。它还允许LLM使用大多数软件中实施的自动反馈(例如错误消息)通过自我调试其生成的代码来改进任务解决(Chen等,2023b;Wang等,2023d)。
- 代码数据在今天的LLM预训练中被广泛使用(Yang等,2024b)。这些模型已经熟悉结构化的编程语言,允许以较低成本采用CodeAct。
- 与预定义格式的JSON和文本相比,代码本质上支持控制和数据流,允许将中间结果存储为变量以供重用,并通过一段代码组合多个工具来执行复杂的逻辑操作(例如,if语句,for循环),从而通过利用其预训练的编程知识解锁LLMs解决复杂任务的潜力。在图1中,使用CodeAct的LLM(右上角)可以通过for循环(即控制流功能)对所有输入应用相同的工具序列(例如,使用数据流功能将一个工具的输出作为输入传递给另一个工具)一次性完成动作;而文本或JSON必须对每个输入采取动作(左上角)。

我们对17个LLM(包括开源和专有)的广泛实验证实了上述CodeAct的优势(3和4)。为了展示优势3,我们的第一个实验(第2.2节)比较了CodeAct与基线模型在涉及原子工具使用(即每次动作仅使用一个工具)的基本任务上的表现,剔除了CodeAct提供的控制和数据流优势。结果表明,对于大多数LLM,CodeAct的表现与基线相当或更好。在我们的第二个实验(优势4)中,CodeAct在复杂任务中的性能提升更加显著。我们策划了一个包含82个人工策划任务的新基准,通常需要在多轮交互中多次调用多个工具(M3ToolEval;第2.3节)。这个基准中的问题通常需要复杂的协调和多工具组合。凭借控制和数据流的优势,CodeAct在解决问题的成功率上比基线提高了多达20%的绝对值,同时所需动作减少了多达30%。随着LLMs能力的提升,这些性能提升更加明显(图1下方)。
CodeAct的出色表现激励我们构建一个能够通过CodeAct有效行动的开源LLM代理,并通过自然语言与人类协作。为此,我们收集了一个包含7千个高质量多轮交互轨迹的指令调优数据集CodeActInstruct(第3.1节)。CodeActInstruct受通用代理框架(包括代理、用户和环境)的启发(图2),并专注于代理与计算机(信息检索、软件包使用、外部内存)和物理世界(机器人规划)之间的交互。在CodeActInstruct上,我们进行了仔细的数据选择,以促进从多轮交互中改进的能力(例如,自我调试)。我们表明,CodeActInstruct可以与常用的指令调优数据一起使用,在不损害其通用能力(例如,基于知识的问答、编程、指令执行)的情况下,提升模型在代理任务中的表现(第3.2节)。我们的模型CodeActAgent通过从LLaMA-2(Touvron等,2023)和Mistral-7B(Jiang等,2023)微调,不仅在使用CodeAct时在领域外代理任务上有所改进,而且在使用预定义格式的文本动作时也有提升(第3.2节)。
CodeAct还可以从多轮交互和现有软件中受益(优势1和2,第2.4节)。如图3所示,设计用于无缝集成Python的CodeActAgent可以使用现有的Python包执行复杂任务(例如,模型训练、数据可视化)。环境中的错误信息进一步使其能够通过多轮交互中的自我调试自主纠正错误。由于LLM在预训练期间广泛的编程知识,这些都无需上下文示范即可实现,减少了适应CodeActAgent到不同任务的人力成本。

CodeAct使LLMs成为更好的代理
在本节中,我们首先描述了CodeAct框架(第2.1节)并提供了支持选择CodeAct的实证证据。由于Python的流行性(在TIOBE指数中排名第一,2024年)和众多的开源包,我们选择Python作为CodeAct的编程语言。我们旨在使用17个现成的LLM来回答几个研究问题(RQs)。在第2.2节中,我们探讨RQ1:LLMs对代码的熟悉程度(由于大量代码预训练数据)是否为CodeAct相较于文本和JSON带来优势?在第2.3节中,我们讨论RQ2:在复杂问题中,CodeAct是否受益于Python固有的控制和数据流特性?最后,作为一个额外的好处,我们在第2.4节和图3中讨论了使用CodeAct如何通过启用多轮交互并允许其访问现有软件进一步增强LLM代理。
2.1 什么是CodeAct?
在图2中,我们首先介绍了一个通用的多轮交互框架,以便LLM代理在现实世界中的使用,该框架考虑了三种角色(Yang等,2024c):代理、用户和环境。我们将交互定义为代理与外部实体(用户或环境)之间的信息交换。在每轮交互中,代理从用户(例如,自然语言指令)或环境(例如,代码执行结果)接收观察(输入),可以选择通过思维链(Wei等,2022)规划其动作,并向用户(以自然语言)或环境发出动作(输出)。CodeAct使用Python代码来整合所有代理-环境交互的动作。在CodeAct中,发给环境的每个动作都是一段Python代码,代理将接收到代码执行的输出(例如,结果、错误)作为观察。我们在附录E中包含了一个CodeAct的示例提示。
2.2 CodeAct显示出作为强大工具使用框架的潜力
在本节中,我们进行了一项控制实验,以了解哪种格式(文本、JSON、CodeAct)更可能引导LLM生成正确的原子工具调用。该实验的性能反映了LLM对相应格式的熟悉程度。我们假设使用CodeAct调用工具对于模型来说是一种更自然的方式,因为它们在训练过程中通常广泛接触代码数据。
实验设置
我们重新利用API-Bank(Li等,2023)并测试LLMs的API调用性能,比较CodeAct、JSON和文本动作。对于每个评估实例,我们指示LLM生成一个Python函数调用、JSON对象或预定义格式的文本表达的原子工具调用。具体示例见表A.6。我们使用API-Bank的一级指令和提供的工具集。为了评估API调用,我们遵循其正确性指标,将模型生成的API执行输出与真实API输出进行匹配。

结果
我们在表2中展示了结果。对于大多数LLM,即使在控制和数据流优势被剔除的原子动作(最简单的工具使用场景)中,CodeAct也实现了相当或更好的性能。与闭源LLM相比,CodeAct在开源模型中的改进更加显著。此外,代码数据通常比专用的JSON或文本工具调用格式更易于用于微调开源LLM。尽管对于开源模型,JSON通常表现较差,但在闭源LLM中表现良好,表明这些闭源模型可能已经进行了针对性微调,以增强其JSON能力。这些结果表明,对于提高工具使用能力,优化CodeAct是比替代方案更好的路径,因为开源LLM由于在预训练期间广泛接触代码数据,已经展现了良好的初始CodeAct能力。

2.3 CodeAct通过更少的交互完成更多工作
在本节中,我们研究LLM代理是否能够在需要复杂工具使用模式的问题中受益于代码的控制和数据流特性。
M3ToolEval
如表A.7所示,据我们所知,现有的工具使用基准中没有包含需要多工具组合同时支持不同动作格式评估的复杂任务。因此,我们策划了一个名为M3ToolEval的基准,以填补这一空白,评估LLMs在解决通常需要多轮交互中多次调用多工具的复杂任务中的能力。它包含82个人工策划的实例,涵盖任务包括网页浏览、金融、旅行行程规划、科学和信息处理。每个领域配有一组独特的手工制作工具。我们有意保持提示简单(示例见附录F),并避免提供任何示范,以测试LLM在零次提示情况下使用工具的能力,类似于一个没有少次提示知识的新手用户会如何使用模型。

实验设置
我们允许模型生成能够实现控制和数据流(例如,if语句,for循环)的功能性Python代码。我们遵循表A.6中描述的JSON和文本的动作格式。在每轮中,模型可以发出一个动作或提出一个答案,通过与真实解决方案的精确匹配进行验证。当达到最多10轮交互或提交正确解决方案时,交互将终止,类似于(Wang等,2023e)。
评估指标
我们通过计算模型提出的答案与真实解决方案匹配的百分比来衡量成功率。我们还包括平均轮数指标:所有评估实例的平均轮数。
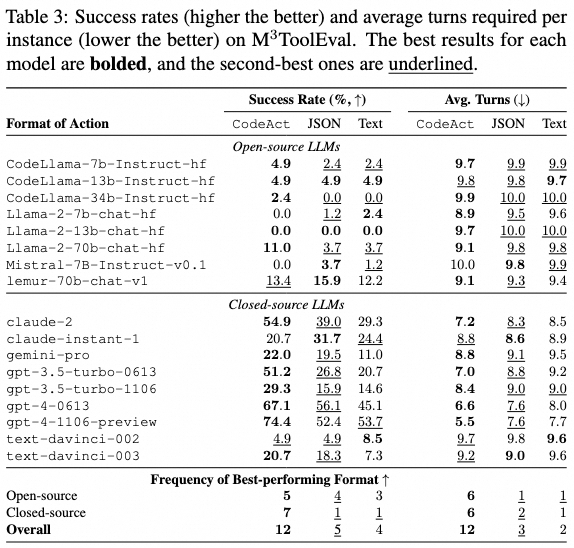
M3ToolEval上的量化结果
我们在表3中包含了完整的结果,并在图1中展示了部分结果用于可视化。CodeAct通常具有更高的任务成功率(在17个评估LLM中有12个),与第2.2节中的趋势类似。此外,使用CodeAct需要更少的平均轮数(在17个评估LLM中有12个)。例如,最佳模型gpt-4-1106-preview相比于次佳动作格式(文本)实现了20.7%的绝对提升,同时平均减少了2.1轮交互。然而,在CodeAct的绝对性能方面,开源和闭源LLM之间仍存在显著差距,最佳开源模型实现了13.4%,而最佳闭源模型gpt-4-1106-preview实现了74.4%。这可能是由于开源模型的任务解决能力较弱,且在没有示范的情况下无法遵循复杂指令,表明需要紧急改进开源LLM以在零次提示设置下进行实际的现实世界任务。
2.4 CodeAct从多轮交互和现有软件包中受益
在图3中,我们展示了一个LLM代理如何与Python集成(即我们在第3.2节训练的CodeActAgent)并使用现有软件在多轮交互中执行复杂任务。由于在预训练期间广泛学习Python知识,LLM代理可以自动导入正确的Python库来解决任务,而无需用户提供工具或示范。如图3所示,CodeActAgent可以使用Pandas下载和处理表格数据,用Scikit-Learn进行机器学习训练-测试数据拆分和回归模型训练,以及用Matplotlib进行数据可视化。此外,使用交互式Python解释器进行代码执行,可以自动生成错误消息,帮助LLM代理在多轮交互中“自我调试”其动作,并最终正确完成用户的请求。
3. 提升开源LLM代理的CodeAct能力
CodeAct所取得的令人鼓舞的结果促使我们构建一个能够通过CodeAct与环境交互并使用语言与人类沟通的开源LLM代理。为了提升开源LLM的CodeAct能力,在第3.1节中,我们介绍了CodeActInstruct,一个包含代理-环境交互轨迹的指令微调数据集。我们在第3.1节中讨论了数据选择程序,以促进从交互行为中改进。此外,我们展示了CodeAct可以与现有的代理-用户对话数据一起使用(第3.1节),以平衡生成的LLM的对话能力。我们的模型CodeActAgent在LLaMA-2(Touvron等,2023)和Mistral-7B(Jiang等,2023)的基础上,通过混合CodeActInstruct和通用对话数据进行微调,提升了CodeAct性能,同时不影响LLM在多样任务上的整体表现(第3.2节)。
3.1 CodeActInstruct:代理-环境交互
我们考虑了代理-环境交互中的四个主要用例,并重新利用五个不同领域的现有数据集生成轨迹:
- 信息检索:我们使用HotpotQA(Yang等,2018)的训练子集生成信息检索轨迹,LLM使用维基百科搜索API(作为Python函数提供)搜索信息来回答问题。
- 软件包(工具)使用:我们使用APPS(Hendrycks等,2021a)中的代码生成问题训练集和MATH(Hendrycks等,2021b)中的数学问题。代码生成任务已经涉及导入包和/或通过定义新的Python函数创建新工具。对于MATH,我们提供导入Python包(例如sympy用于符号数学)解决问题的上下文示例。
- 外部内存:我们重新利用WikiTableQuestion(Pasupat & Liang,2015)的训练子集,并将其修改为需要访问外部内存的两种表格推理任务:(1)基于SQL的任务,需要LLM通过sqlite3包与SQL数据库交互,通过SQL执行回答问题;(2)基于Pandas的任务,需要模型与Pandas表格交互以执行数据操作(例如,选择,过滤)。指令示例见附录G.3.1。
- 机器人规划:我们使用ALFWorld(Shridhar等,2020),一个仅文本的具身环境模拟器,生成使用机器人控制API(重新作为Python函数)完成家务任务的轨迹。遵循MINT(Wang等,2023e),我们提供一个上下文示例,鼓励使用for循环和if语句代码块来自动化重复操作(例如,通过访问不同位置搜索物品)。
数据下采样
我们通过保留最具挑战性的实例来下采样每个数据集,旨在使轨迹生成更高效和成本效益更高。此外,这还有助于去除现有LLM已经能解决的简单实例。过滤后的数据集统计见表A.9。有关下采样过程的详细信息请参阅附录G.1。
数据重新利用以实现多轮交互
一些数据集(APPS,MATH,WikiTableQuestions)最初是单轮问题,每个指令期望一个解决方案,而在现实的代理使用情况下,我们通常需要多轮交互来完成每个任务(图1顶部)。遵循MINT(Wang等,2023e),我们通过允许LLM在提交一个解决方案进行评估之前与环境进行多轮交互,将单轮问题重新利用为多轮问题。具体对于代码生成问题,我们提供一个上下文示例,以指导LLM在提交解决方案之前在提供的测试用例上测试其解决方案。将使用原始数据的指标评估提交的解决方案以确定其正确性。示例见附录G.3。
轨迹生成
我们使用MINT的评估框架(Wang等,2023e)为上述数据集生成交互轨迹,并确定每个轨迹的正确性。我们在下采样数据上运行OpenAI的gpt-3.5-turbo-0613,Anthropic的claude-1-instant和claude-2,代码生成除外,因为代码生成需要更长的上下文,我们使用GPT-3.5的长上下文版本(gpt-3.5-turbo-0613-16k)。在这些模型都无法解决的一部分问题上,我们使用gpt-4-0613生成轨迹。
增强代理从交互中改进的能力
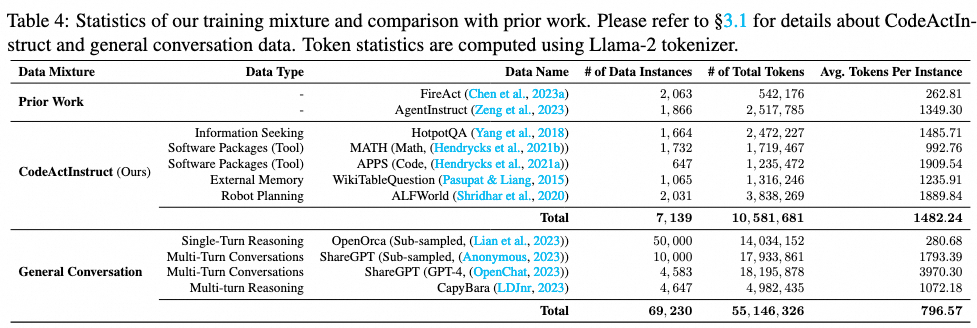
我们从CodeActInstruct生成的所有轨迹中选择一个高质量子集,促进代理基于先前观察改进下一个动作的能力(例如,从代码执行错误消息中自我调试,图2中的计划能力)。为此,我们选择性保留了那些模型最初遇到错误但在后续交互中纠正这些错误的轨迹。对于这些实例,LLM通常在初始错误后进行自我反思,从而主动提高其未来动作。其他筛选细节在附录G.2中讨论。我们保留了gpt-4-0613生成的411个轨迹以及gpt-3.5和claude生成的6728个轨迹。最终数据集CodeActInstruct的统计见表4。
与先前工作的比较
与主要关注使用文本作为动作的先前工作AgentInstruct(Zeng等,2023)和FireAct(Chen等,2023a)相比,CodeActInstruct使得模型在实际应用中更具实用性,因为使用CodeAct的模型可以直接与Python解释器和开源工具包交互(图3),减少了解析动作和创建工具的开发工作。CodeActInstruct按照通用代理框架系统地构建(图2),涵盖了多样的领域(例如,相比于仅考虑QA任务和搜索API的FireAct),包含优质数据(例如,促进代理的自我调试能力)且规模更大(相比AgentInstruct和FireAct分别多3.8倍和3.5倍的数据轨迹以及5倍和19倍的tokens,见表4)。正如我们在表5中经验性展示的那样,CodeActInstruct生成的模型(相同主干)相比AgentInstruct和FireAct分别实现了24%和119%的相对提升。
CodeActInstruct可以与现有的代理-用户对话数据一起使用
我们使用一个集中于单轮思维链(CoT)推理的OpenOrca子集(Lian等,2023),两个包含人类和LLM之间多轮对话的ShareGPT(匿名,2023;OpenChat,2023)数据源以及一个集中于多轮对话推理的CapyBara(LDJnr,2023)。统计和下采样细节见表4和附录C。
3.2 CodeActAgent
我们在混合了CodeActInstruct和通用对话数据(表4)的基础上,对Llama-2 7B(Touvron等,2023)和Mistral 7B(Jiang等,2023)进行微调,获得了CodeActAgent。
训练设置
我们对Llama-2使用长度为4096 tokens的序列,对Mistral使用长度为16384 tokens的序列,进行全参数监督微调。更多细节请参阅附录D。
评估设置
我们使用MINT(Wang等,2023e)评估LLMs在各种代理任务中使用CodeAct的表现。CodeActAgent的一些训练领域与MINT的评估重叠(即MINT包括ALFWorld和MATH),因此我们分别报告MINT在域内和域外的性能。除非另有说明,我们在交互轮数k=5的情况下测量MINT任务的成功率。我们还使用MiniWob++(计算机任务,Kim等,2023)和ScienceWorld(基于文本的小学科学课程模拟器,Wang等,2022a)中的文本动作评估域外代理任务,以测试CodeActAgent是否能适应不同的动作格式。最后,我们包括一组通用LLM评估任务来评估总体能力:用于知识问答的MMLU(Hendrycks等,2020),用于单轮代码生成的HumanEval(Chen等,2021),用于单轮无工具数学推理的GSM8K(Cobbe等,2021),和用于指令遵循的MTBench(Zheng等,2023)。
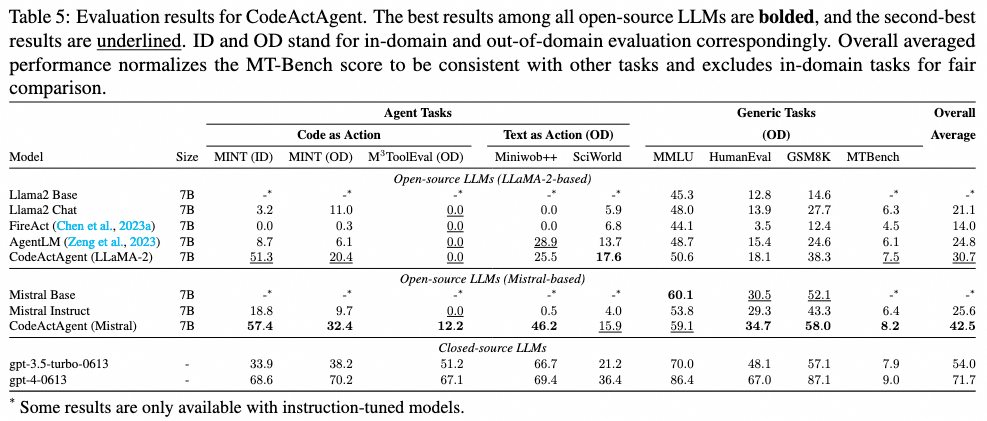
CodeActAgent在CodeAct任务中表现优异
如表5所示,CodeActAgent(两种变体)在MINT的域内和域外子集上都优于所有评估的开源LLM。在M3ToolEval中,我们发现CodeActAgent(Mistral)优于类似规模的开源LLM(7B和13B),甚至达到了70B模型的相似性能(表3)。令人惊讶的是,Llama-2变体没有观察到改进。我们在附录H中讨论了潜在原因。
CodeActAgent能够适应文本动作
在域外文本动作评估中,CodeActAgent(LLaMA2, 7B)尽管从未针对文本动作进行优化,却达到了与明确针对文本动作调整的AgentLM-7B(Zeng等,2023)相当的性能。
CodeActAgent在通用LLM任务上保持或提升了性能
在表5中,我们发现CodeActAgent(两种变体)在我们测试的通用LLM任务上表现更佳,除了CodeActAgent(Mistral, 7B)在MMLU上略有下降。
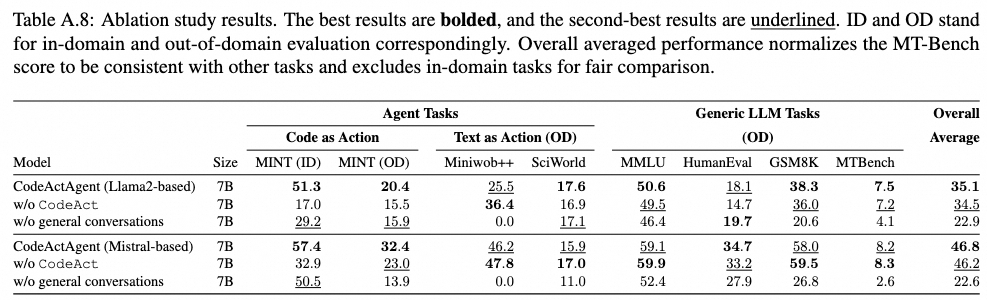
消融研究
表A.8展示了消融实验,以确定CodeActInstruct和通用对话的重要性。CodeActInstruct和通用对话都对代理任务有贡献,而通用对话对于保持通用任务的性能至关重要。
4. 相关工作
4.1 LLM代理中的动作模块
如(Wang等,2023b)所述,基于LLM的自主代理通常围绕四个组件构建:定制化配置文件(Park等,2023;Qian等,2023)、长期记忆能力(Zhu等,2023;Fischer,2023)、推理和规划算法(Wei等,2022;Chen等,2023d)以及最关键的动作模块。动作模块是促使LLM代理能够有效与外部实体(包括人类(Lee等,2022)和工具(Qin等,2023a)在环境中(Wang等,2023e;Yang等,2024a))交互的关键组件。在本研究中,我们解决了为LLM代理标准化动作空间这一关键问题。我们在附录A中进一步讨论了CodeAct与使用代码生成进行问题解决的相关研究之间的差异。我们注意到一项并行研究TaskWeaver(Qiao等,2023)同样支持使用代码。我们在附录B中讨论了其主要区别。
4.2 提升LLM代理
提升LLM代理的两种主要方法是提示工程和指令微调,具体详见(Wang等,2023b)的综述。对于提示工程(Liu等,2023a),已经引入了许多策略以改进思维链推理(Wei等,2022),包括基于自一致性的推理(Wang等,2022b;Chen等,2023d)和基于树的方法(Yao等,2023a)。此外,可以通过战略性地提示LLM来反思之前的计划(Yao等,2023b;Wang等,2023f;Zhang等,2023),使其通过试错法改进初始动作。与提示工程相比,指令微调本质上增强了LLM的能力(Chung等,2022),特别是在其代理能力方面(Zeng等,2023;Chen等,2023a)。为了有效训练,人类注释者可以为特定的代理任务策划专家示范,例如网页浏览(Yao等,2022a;Nakano等,2021)。为了最小化人类注释的工作量,先前的研究使用更强大的LLM创建合成数据集,将代理能力蒸馏到本地模型中,专注于工具使用(Qin等,2023b)、交互(Chen等,2023c)和社交技能(Liu等,2023b)。CodeActInstruct与后者方法一致,使用更强大的LLM创建数据集。
5. 结论
本文介绍了CodeAct,使用可执行的Python代码作为LLM代理的动作,这在复杂场景中相较于使用文本或JSON动作具有优势。我们收集了专注于CodeAct的多轮交互轨迹CodeActInstruct,用于指令微调,并训练了CodeActAgent。该代理专为与Python的无缝集成而设计,能够利用现有的Python包执行复杂任务(例如模型训练),并通过自我调试自动纠正错误。
致谢
我们感谢匿名评审员的建议和意见。本研究基于美国DARPA ECOLE项目No. HR00112390060、DARPA ITM项目No. FA8650-23-C-7316和KAIROS项目No. FA8750-19-2-1004的支持。本文所包含的观点和结论是作者的观点和结论,不应被解释为必然代表DARPA或美国政府的官方政策,无论是明示还是默示。尽管有任何版权注释,美国政府有权为政府目的复制和分发重印件。本研究使用了国家超级计算应用中心的Delta系统,通过高级网络基础设施协调生态系统:服务与支持(ACCESS,Boerner等,2023)项目的分配CIS230256,该项目由国家科学基金会资助,资助号#2138259, #2138286, #2138307, #2137603, 和#2138296。
影响声明
本文展示的研究目标是推进基于LLM的自主代理,能够通过自然语言与人类沟通,并通过在环境中执行任务来协助人类用户。在本节中,我们讨论了与我们的工作及其目标相关的潜在社会影响、局限性和未来工作。
CodeActAgent是一个自主代理的初始原型,仍然存在一些实际局限性。例如,它可能会受到LLM中常见的幻觉影响(例如,想象变量的内容而不实际打印出来),这表明需要后续对齐(Ouyang等,2022)以进一步改进。
尽管是一个原型,CodeActAgent已经展示了有限的自我改进能力(例如,通过自我调试错误消息来改进其动作)和与环境交互的能力。未来的工作可能会基于CodeActAgent,通过让它们在特定环境中进行广泛的交互,并迭代地增强其自我改进能力,从过去的错误中学习来开发更好的代理。这样的算法产生的更强大的代理,可能对解决广泛的现实世界问题(例如,定理证明,药物发现)有益。如(Eloundou等,2023)中广泛讨论的那样,一个完全自主的代理可能会改变当前的劳动力市场格局,并影响现有工人的工作。
此外,由于CodeAct直接授予代理在沙盒环境中自由执行代码的权限,在最坏的情况下(例如,在科幻电影中),这样的代理可能突破沙盒限制,通过网络攻击对世界造成伤害,这强调了未来工作需要设计更好的安全机制来保护自主代理(Tang等,2024)。
相关文章:
CodeActAgent :Executable Code Actions Elicit Better LLM Agents解读
论文地址 https://arxiv.org/pdf/2402.01030.pdf 项目地址 https://github.com/svjack/CodeActAgent-Gradio/blob/main/README.md 代码智能体的优势 选择代码智能体有以下几个关键原因,它们相较于使用类似JSON的字典输出具有显著优势: 1. 代码的高…...

中小型医院网站开发:Spring Boot入门
2 相关技术简介 2.1 Java技术 Java是一种非常常用的编程语言,在全球编程语言排行版上总是前三。在方兴未艾的计算机技术发展历程中,Java的身影无处不在,并且拥有旺盛的生命力。Java的跨平台能力十分强大,只需一次编译,…...

Java读取PDF后做知识库问答_SpringAI实现
核心思路: 简单来说,就是把PDF文件读取并向量化,然后放到向量存储里面,再通过大模型,来实现问答。 RAG(检索增强生成)介绍: 检索增强生成&#x…...
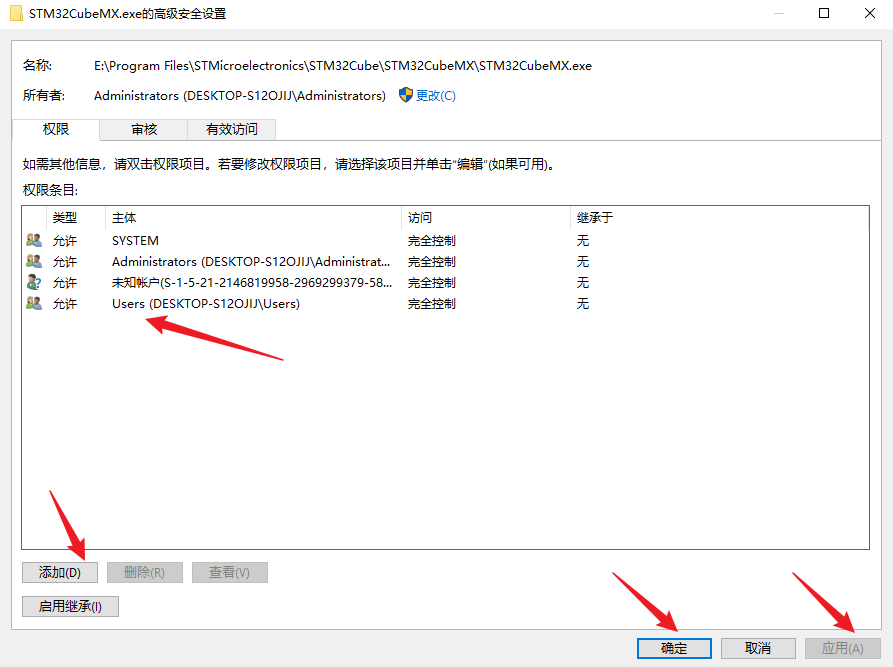
打开exe程序显示没有适当的访问权限
打开exe程序显示没有适当的访问权限 打开.exe可执行程序,显示Windows 无法访问指定设备、路径或文件。你可能没有适当的权限访问该项目。 解决方法 鼠标选中该文件或文件夹,右键单击选择属性,在弹出的属性选项卡中切换到安全选项卡…...

Python异步编程:使用`create_task`并发执行协程
Python异步编程:使用create_task并发执行协程 1. 什么是create_task?2. 为什么需要create_task?3. 如何使用create_task?3.1 基本用法3.2 任务的返回值 4. 注意事项5. 总结 在Python的异步编程中,asyncio库为我们提供了…...
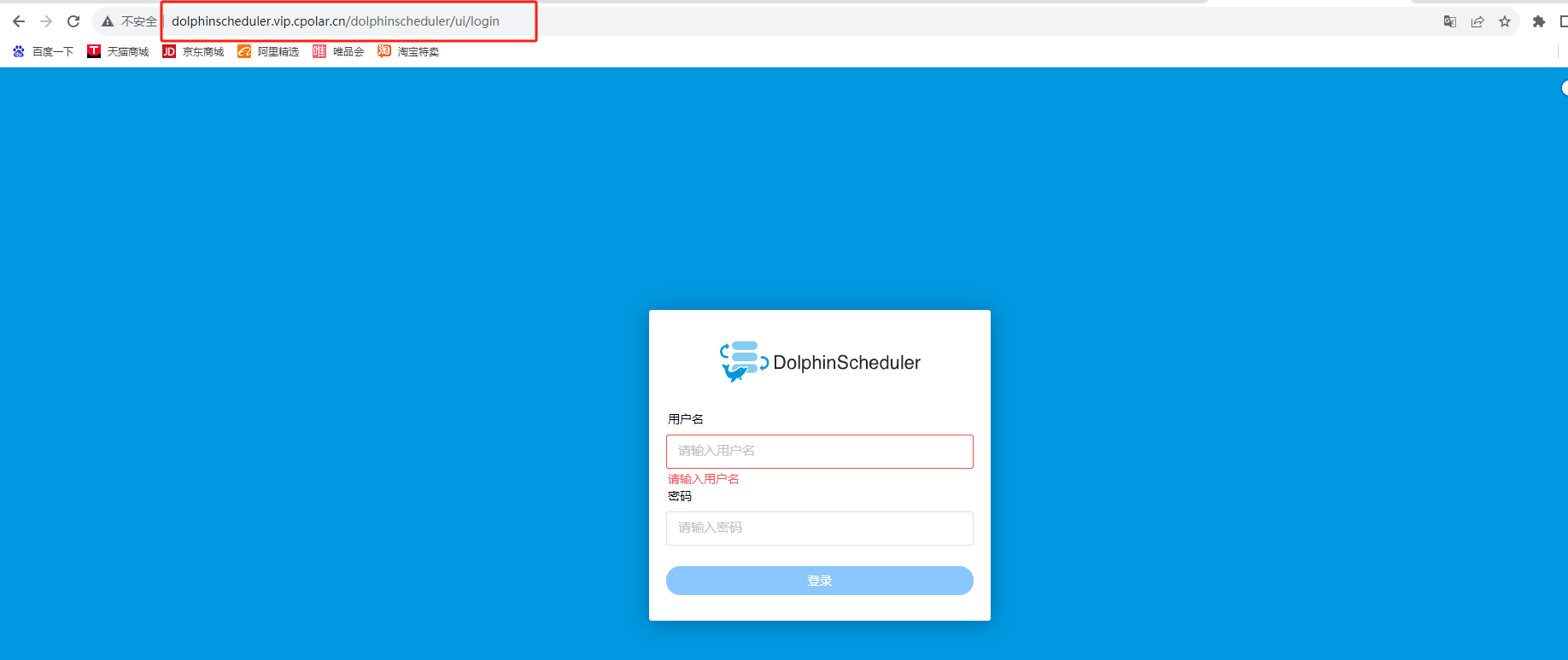
从零开始搭建你的DolphinScheduler分布式任务调度平台实战指南
文章目录 前言1. 安装部署DolphinScheduler1.1 启动服务 2. 登录DolphinScheduler界面3. 安装内网穿透工具4. 配置Dolphin Scheduler公网地址5. 固定DolphinScheduler公网地址 前言 本篇教程和大家分享一下DolphinScheduler的安装部署及如何实现公网远程访问,结合内…...

第五课:Python学习之if语句
判断(if)语句 目标 开发中的应用场景if 语句体验if 语句进阶综合应用 01. 开发中的应用场景 生活中的判断几乎是无所不在的,我们每天都在做各种各样的选择,如果这样?如果那样?…… 程序中的判断 # 定义…...
群晖前面加了雷池社区版,安装失败,然后无法识别出用户真实访问IP
有nas的相信对公网都不模式,在现在基础上传带宽能有100兆的时代,有公网代表着家里有一个小服务器,像百度网盘,优酷这种在线服务都能部署为私有化服务。但现在运营商几乎不可能提供公网ip,要么自己买个云服务器做内网穿…...
秋招-三语言题解)
【秋招笔试】10.13拼多多(已改编)秋招-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 🍒 本专栏已收集…...
)
50个JAVA常见代码大全:学完这篇从Java小白到架构师(附带讲解)
基础语法 1. Hello World public class HelloWorld {public static void main(String[] args) {System.out.println("Hello, World!");} }讲解 这是一个典型的Java程序,它定义了一个名为HelloWorld的类,该类包含一个main方法——Java应用程序的入口点。System.o…...

Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.0 SP1升级到SP3操作方法(x64)
1、首先安装时候选择升级SQLEXPRADV_x64_CHS.exe。 2、接着安装SQLServer2008R2SP1-KB2528583-x64-sp1补丁后10.50.2500.0。 3、接着安装升级SQLEXPRWT_x64_CHS.exe。 4、继续安装SP3:SQLServer2008R2SP3-KB2979597-x64-CHS。 5、最后安装SP3补丁:SQ…...

Centos7安装Git及配置Github
Background Git 是一个开源的分布式版本控制系统,由 Linus Torvalds(Linux 内核的创始人)在 2005 年创建。它被设计用来快速有效地处理从小到大的项目版本管理。Git 目前是全世界最流行的版本控制系统,广泛应用于软件开发中。 1、…...

MobileNet v3(相比于MobileNet v2)
概述: 更新Block(bneck) 使用NAS搜索参数 (Neural Architecture Search) 重新设计耗时层结构 更准确,更高效 以及表中数据展示 更新Block 1.加入SE模块 2.更新了激活函数 首先通过一个1*1的卷积层来进行一个升维处理&#…...

短视频剪辑入门指南:这四大软件值得推荐!
要在众多的短视频作品中脱颖而出并不容易,这就要求制作者不仅要具备良好的创意,还需要掌握一定的剪辑技巧。这里给大家推荐几个好用的短视频剪辑工具! 福昕视频剪辑 直达链接:www.pdf365.cn/foxit-clip/ 操作教程:立…...
网络编程(22)——通过beast库快速实现websocket服务器
目录 二十二、day22 1. websocket简述 2. 基于TCP长连接实现sebsocket a. Connection b. ConnectionMgr c. WebServer d. 编译的小问题 3. 测试 4. 基于http实现的websocket 二十二、day22 因为http受限于请求-响应模式,客户端发起请求,服务器…...

从视频截取每一帧作为图像
查看视频有多少帧 import cv2def count_frames_per_second(video_path):cap cv2.VideoCapture(video_path)if not cap.isOpened():print("Error: Could not open video")return None# Get frames per secondfps cap.get(cv2.CAP_PROP_FPS)# Get total number of f…...

终端 数据表格
// // Created by HongDaYu on 17 十月 2024. //#ifndef HDYSDK_UTIL_H #define HDYSDK_UTIL_H#include <cstdint> #include <string> #include <list> #include <iomanip> #include <memory>class dataGrid { private:std::list<const char*…...

2.4.ReactOS系统运行级别降低IRQL级别KfLowerIrql 函数
2.4.ReactOS系统运行级别降低IRQL级别KfLowerIrql 函数 2.4.ReactOS系统运行级别降低IRQL级别KfLowerIrql 函数 文章目录 2.4.ReactOS系统运行级别降低IRQL级别KfLowerIrql 函数KfLowerIrql 函数 KfLowerIrql 函数 /*******************************************************…...

数字后端实现静态时序分析STA Timing Signoff之min period violation
今天给大家分享一个在高性能数字IC后端实现timing signoff阶段经常遇到的min period violation。大部分时候出现memory min period问题基本上都是需要返工重新生成memory的。这是非常致命的错误,希望大家在做静态时序分析时一定要查看min period violation。 什么是…...

phpstorm+phpstudy 配置xdebug(无需开启浏览器扩展)
今天又被xdebug折磨了,忘记了以前咋配置了现在百度发现好多都是各种浏览器扩展而且也没有真正的用到项目上的都是测试的地址怎么样的 我就简单写一下自己实战吧 不支持workerman swoole hyperf等这种服务框架 如果你会请教教我 工具版本phpstudy8.1.xphpstorm2021.x…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...