决策树和集成学习的概念以及部分推导
一、决策树
1、概述
决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
决策树的建立过程:
- 特征选择:选择有较强分类能力的特征
- 决策树生成:根据选择的特征生成决策树
- 决策树也容易过拟合,需要采用剪枝的方式来缓解过拟合
2、ID3决策树
(一)、信息熵
(1)、概述
熵:信息论中代表随机变量不确定度的度量
熵越大,数据的不确定性越高,信息就越多
熵越小,数据的不确定性越低
(2)、计算
一般计算时是计算目标值的信息熵。
H ( x ) = − ∑ i = 0 m P ( x i ) l o g 2 P ( x i ) 其 中 P ( x i ) 表 示 的 是 数 据 中 类 别 出 现 的 概 率 , H ( x ) 表 示 信 息 的 信 息 熵 值 H(x) = -\sum_{i=0}^mP(x_i)log_2P(x_i)\\ 其中P(x_i)表示的是数据中类别出现的概率,H(x)表示信息的信息熵值 H(x)=−i=0∑mP(xi)log2P(xi)其中P(xi)表示的是数据中类别出现的概率,H(x)表示信息的信息熵值
例一:α为(ABCDEFGH),计算其信息熵
H ( α ) = − ∑ i = 0 m P ( x i ) l o g 2 P ( x i ) = ( − 1 8 l o g 2 1 8 ) ∗ 8 = 3 H(α) = -\sum_{i=0}^mP(x_i)log_2P(x_i)=(-\frac{1}{8}log_2\frac{1}{8})*8=3 H(α)=−i=0∑mP(xi)log2P(xi)=(−81log281)∗8=3
例二:α为(AAAABBCD),计算其信息熵
H ( α ) = − ∑ i = 0 m P ( x i ) l o g 2 P ( x i ) = ( − 1 2 l o g 2 1 2 ) + ( − 1 4 l o g 2 1 4 ) + ( − 1 8 l o g 2 1 8 ) = 1 2 ∗ 1 + 1 4 ∗ 2 + 1 8 ∗ 3 ∗ 2 = 1.75 H(α) = -\sum_{i=0}^mP(x_i)log_2P(x_i)=(-\frac{1}{2}log_2\frac{1}{2})+(-\frac{1}{4}log_2\frac{1}{4})+(-\frac{1}{8}log_2\frac{1}{8})=\frac{1}{2}*1+\frac{1}{4}*2+\frac{1}{8}*3*2=1.75 H(α)=−i=0∑mP(xi)log2P(xi)=(−21log221)+(−41log241)+(−81log281)=21∗1+41∗2+81∗3∗2=1.75
(二)、信息增益
(1)、概述
特征a对训练集D的信息增益Gain(D,a)或者g(D,a),定义为集合D的熵H(D)与特征a给定条件下的熵H(D|a)之差。
特征a而使得对数据D的分类不确定性减少的程度。
(2)、计算
G a i n ( D , a ) = H ( D ) − H ( D ∣ a ) 信 息 增 益 = 熵 − 条 件 熵 Gain(D,a)=H(D)-H(D|a)\\ 信息增益=熵-条件熵 Gain(D,a)=H(D)−H(D∣a)信息增益=熵−条件熵
那么问题来了,条件熵该怎么计算呢:
H ( D ∣ a ) = ∑ i = 0 n D i D H ( D i ) = ∑ i = 0 n D i D ∑ j = 0 m c i j D i l o g 2 c i j D i H(D|a)=\sum_{i=0}^n\frac{D^i}{D}H(D^i)=\sum_{i=0}^n\frac{D^i}{D}\sum_{j=0}^m\frac{c^{ij}}{D^i}log_2\frac{c^{ij}}{D^i} H(D∣a)=i=0∑nDDiH(Di)=i=0∑nDDij=0∑mDicijlog2Dicij
通俗的来说就是先求某一项特征中每一项的概率,再分别乘上该项在特征中的占比,求出该特征所有的项再求和,就获得了条件熵。
例一:已知有六个样本,根据特征a可以分为α和β两部分。α部分对应值为A,A,A,B;β部分对应值为B,B。
条 件 为 α 的 熵 为 : − 3 4 l o g 2 3 4 − 1 4 l o g 2 1 4 = 0.81 条 件 为 β 的 熵 为 : − 2 2 l o g 2 2 2 = 0 条 件 熵 : α 部 分 占 比 4 6 , β 部 分 占 比 2 6 4 6 ∗ 0.81 + 2 6 ∗ 0 = 0.54 熵 为 : − 3 6 l o g 2 3 6 − 3 6 l o g 2 3 6 = 1 信 息 增 益 : 熵 − 条 件 熵 : 1.0 − 0.54 = 0.46 条件为α的熵为:-\frac{3}{4}log_2\frac{3}{4}-\frac{1}{4}log_2\frac{1}{4}=0.81\\ 条件为β的熵为:-\frac{2}{2}log_2\frac{2}{2}=0\\ 条件熵:α部分占比\frac{4}{6},β部分占比\frac{2}{6}\\ \frac{4}{6}*0.81+\frac{2}{6}*0=0.54\\ 熵为:-\frac{3}{6}log_2\frac{3}{6}-\frac{3}{6}log_2\frac{3}{6}=1\\ 信息增益:熵-条件熵:1.0-0.54=0.46 条件为α的熵为:−43log243−41log241=0.81条件为β的熵为:−22log222=0条件熵:α部分占比64,β部分占比6264∗0.81+62∗0=0.54熵为:−63log263−63log263=1信息增益:熵−条件熵:1.0−0.54=0.46
(三)、总结
ID3决策树构建流程
- 计算每个特征的信息增益
- 使用信息增益最大的特征将数据分为子集
- 使用这个信息增益最大的特征作为当前决策树的节点
- 对剩下的特征重复上述操作,直到结束或者达到条件
3、C4.5决策树
(一)、信息增益率
(1)、概述
特征的信息增益除以特征的内在信息,相当于对信息增益进行修正,增加一个惩罚系数。特征取值个数较多时,惩罚系数较小,反正较大。
惩罚系数为数据集D以特征a作为随机变量的熵的倒数。
(2)、计算
G a i n _ R a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) G a i n _ R a t i o ( D , a ) 就 是 信 息 增 益 率 I V ( a ) = − ∑ i = 1 n D i D l o g 2 ( D i D ) I V ( a ) 为 特 征 熵 Gain\_Ratio(D,a)=\frac{Gain(D,a)}{IV(a)}\\ Gain\_Ratio(D,a)就是信息增益率\\ IV(a)=-\sum_{i=1}^n\frac{D^i}{D}log_2(\frac{D^i}{D})\\ IV(a)为特征熵 Gain_Ratio(D,a)=IV(a)Gain(D,a)Gain_Ratio(D,a)就是信息增益率IV(a)=−i=1∑nDDilog2(DDi)IV(a)为特征熵
例如:
| 特征b | 特征a | 目标值 |
|---|---|---|
| 1 | α | A |
| 2 | α | A |
| 3 | β | B |
| 4 | α | A |
| 5 | β | B |
| 6 | α | B |
特 征 a 的 信 息 增 益 率 : 信 息 增 益 : ( − 3 6 l o g 2 3 6 − 3 6 l o g 2 3 6 ) − ( 4 6 ∗ ( − 3 4 l o g 2 3 4 − 1 4 l o g 2 1 4 ) − 2 6 ∗ ( 0 ) ) = 1 − 0.54 = 0.46 I V 信 息 熵 : − 4 6 l o g 2 4 6 − 2 6 l o g 2 2 6 = 0.92 信 息 增 益 率 : 信 息 增 益 / 信 息 熵 = 0.46 / 0.96 = 0.5 特 征 b 的 信 息 增 益 率 : 信 息 增 益 : − 3 6 l o g 2 3 6 − 3 6 l o g 2 3 6 − 6 ∗ 0 = 1 I V 信 息 熵 : − 1 6 l o g 2 1 6 ∗ 6 = 0.58 信 息 增 益 率 : 信 息 增 益 / 信 息 熵 = 1 / 2.58 = 0.39 特征a的信息增益率:\\ 信息增益:(-\frac{3}{6}log_2\frac{3}{6}-\frac{3}{6}log_2\frac{3}{6})-(\frac{4}{6}*(-\frac{3}{4}log_2\frac{3}{4}-\frac{1}{4}log_2\frac{1}{4})-\frac{2}{6}*(0))=1-0.54=0.46\\ IV信息熵:-\frac{4}{6}log_2\frac{4}{6}-\frac{2}{6}log_2\frac{2}{6}=0.92\\ 信息增益率:信息增益/信息熵=0.46/0.96=0.5\\ 特征b的信息增益率:\\ 信息增益:-\frac{3}{6}log_2\frac{3}{6}-\frac{3}{6}log_2\frac{3}{6}-6*0=1\\ IV信息熵:-\frac{1}{6}log_2\frac{1}{6}*6=0.58\\ 信息增益率:信息增益/信息熵=1/2.58=0.39 特征a的信息增益率:信息增益:(−63log263−63log263)−(64∗(−43log243−41log241)−62∗(0))=1−0.54=0.46IV信息熵:−64log264−62log262=0.92信息增益率:信息增益/信息熵=0.46/0.96=0.5特征b的信息增益率:信息增益:−63log263−63log263−6∗0=1IV信息熵:−61log261∗6=0.58信息增益率:信息增益/信息熵=1/2.58=0.39
选择信息增益率更大的作为分裂特征。
(二)、总结
信息增益偏向于选择种类多的特征作为分裂依据,而信息增益率的出现可以很好的缓解ID3树中存在的不足。
信息增益率 = 信息增益 /特征熵。相当于对信息增益进行修正,增加了一个惩罚系数,也就是特征熵的倒数。
4、CART决策树
(一)、概述
classification and regression tree,cart模型是一种决策树模型,它可以做分类,也可以用于回归。cart回归树使用平均误差最小化策略;cart分类生成树采用的是基尼指数最小化的策略。
(二)、基尼值Gini(D)
从数据集D中随机抽取两个样本,其类别标记不一致的概率,Gini(D)值越小,数据集D的纯度越高。
G i n i ( D ) = ∑ k = 1 n ∑ k , ≠ k p k p k , = 1 − ∑ k = 1 p k 2 Gini(D)=\sum_{k=1}^n\sum_{k^,≠k}p_kp_k^,=1-\sum_{k=1}p_k^2 Gini(D)=k=1∑nk,=k∑pkpk,=1−k=1∑pk2
(三)、基尼指数(Gini_index(D))
选择使划分后基尼系数最小的属性作为最优化分属性。
G i n i i n d e x ( D , a ) = ∑ i = 1 n D i D G i n i ( D i ) Gini_index(D,a)=\sum_{i=1}^n\frac{D^i}{D}Gini(D^i) Giniindex(D,a)=i=1∑nDDiGini(Di)
5、ID3、C4.5、CART对比
| 名称 | 提出时间 | 分支方式 | 特点 |
|---|---|---|---|
| ID3 | 1975 | 信息增益 | 1.ID3只能对离散属性的数据集构成决策树 2.倾向于选择取值较多的属性 |
| C4.5 | 1993 | 信息增益率 | 1.缓解了ID3分支过程中总喜欢偏向选择值较多的属性 2.可处理连续数值型属性,也增加了对缺失值的处理方法 3.只适合于能够驻留于内存的数据集,大数据集无能为力 |
| CART | 1984 | 基尼指数 | 1.可以进行分类和回归,可处理离散属性,也可以处理连续属性 2.采用基尼指数,计算量减小 3.一定是二叉树 |
相关API
6、CART回归决策树
(一)、回归树和分类树的区别
CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值
CART 分类树使用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失
分类树使用叶子节点多数类别作为预测类别,回归树则采用叶子节点里均值作为预测输出
(二)、损失函数
L o s s ( y , f ( x ) ) = ( f ( x ) − y ) 2 f ( x ) 为 预 测 值 , y 为 目 标 值 Loss(y,f(x))=(f(x)-y)^2\\ f(x)为预测值,y为目标值 Loss(y,f(x))=(f(x)−y)2f(x)为预测值,y为目标值
(三)、计算
将特征的值排序,取相邻元素的均值作为划分点,,计算每一个划分点的平方损失,比如下例:

x为特征,y为目标值,先将x取相邻元素的均值作为划分点

先以1.5作为分割点,将原本的数据集分为1和2-10,左子树为1,均值为5.56,右子树为2-10,均值为7.5。
计算出该划分点的平方损失为L(1.5)=(5.56-5.56)²+[(5.7-7.5)²+…+(9.05-7.5)²]=15.72
依次遍历分割点得到所有的划分点的平方损失,得到

可以得到在6.5的位置时,平方损失最小,因此以该点作为划分点,将原数据集划分成两份。
对左右子树重复上述的操作,直到叶子节点或者达到目标深度或节点数为止。
(四)、总结
- 选择一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
- 根据所有划分点,将数据集分成两部分:R1、R2
- R1 和 R2 两部分的平方损失相加作为该切分点平方损失
- 取最小的平方损失的划分点,作为当前特征的划分点
- 以此计算其他特征的最优划分点、以及该划分点对应的损失值
- 在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
7、剪枝
(一)、概述
是决策树学习算法应对过拟合的一种手段。
一般是将一棵子树的子节点全部删掉,用 叶子节点去替换子树(实质是后剪枝),甚至可以只保留根节点然后删除所有的叶子。
(二)、方式以及区别
(1)、预剪枝:
在决策树生成的过程中,对每个节点在划分钱先进行评估,如果当前节点不能带来决策树的泛化性能提升,就停止划分,并且将当前节点标记为叶节点。
优点:
- 预剪枝在树生成过程中,在树展开之前就可以判断是否剪枝,降低过拟合风险
- 显著减少计算时间和资源
缺点:
- 有些划分当前虽然不能提升泛化性能,甚至是泛化性能下降,但是在其基础上进行的后续划分可能会使性能提高
- 会给决策树带来欠拟合风险
(2)、后剪枝:
先生成一颗完整的决策树,然后自底而上的对非叶子节点进行考察,如果将当前节点的子树替换为叶节点可以为决策树带来泛化能力的提升,就将该子树替换为叶节点。
优点:
- 保留更多的分支,一般情况下,后剪枝的决策树欠拟合风险很小,泛化性能往往优于预剪枝。
缺点:
- 后剪枝过程使在生成完决策树之后进行的,要自底而上的对树所有非叶子节点考察,再进行剪枝,所以耗费的资源和时间比较大。
二、集成学习
1、概述
集成学习是机器学习的一种思想,通过多个模型的组合形成一个精度更高的模型,参与组合的模型是弱学习器(基学习器)。在训练时,使用训练集依次训练这些弱学习器,对未知样本进行预测时,弱学习器对其进行联合预测。
传统机器学习算法的目标都是找一个最优的分类器尽可能的将训练数据分开。集成学习算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是 生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
2、分类
(一)、Bagging
通过有放回的抽样产生不同的训练集,从而训练出有差异性的弱学习器,然后通过平权投票、多数服从少数的方式来决定预测结果。
(二)、Boosting
Bagging是一种提升的思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,获得预测结果。
Bagging是一组可以将弱学习器升级为强学习器的算法,步骤如下:
- 先从初始训练集训练出一个基学习器
- 根据基学习器的表现对训练样本分布进行调整,让先前学习器做错的训练集在后续样本上获得较大关注
- 基于调整后的样本分布来训练下一个基学习器
- 重复上述三步,直到学习器的数目达到指定的值为止
- 将这T个基学习器加权得到集成学习器
每新加入一个弱学习器,整体能力就会得到提升。
(三)、区别
Bagging:
- 有放回的采样
- 平权投票
- 学习是并行的状态,每个学习器之间没有依赖关系
Boosting:
- 全部数据集,每次重点关注上一个弱学习器预测错误的值
- 加权投票
- 学习是串行的状态,学习有先后的顺序
3、随机森林
(一)、概述
是一种Bagging思想实现的一种学习算法,它采用决策树模型作为每一个基学习器。
(二)、构建
训练:
- 有放回的产生训练样本,具体来说就是每次从原来的N个训练样本中有放回地随机抽取m个样本(包括可能重复样本)。
- 随机挑选n个特征(n小于总特征数),作为当前节点下决策的备选特征,从这些特征中选择最好地划分训练样本的特征。用每个样本集作为训练样本构造决策树。单个决策树在产生样本集和确定特征后,使用CART算法(默认)计算,不剪枝。
预测:
- 得到所需数目的决策树后,平权投票,多数表决出一个树,作为随机森林的决策。
(三)、一些注意事项
-
随机森林对训练样本进行了采样,同时对特征进行采样,充分保证构建的每个数之间的独立性,使投票更准确。
-
随机森林的随机性体现在每棵树的训练样本都是随机的,树中每个节点的分裂样本也是随机选择的,有这两个随机因素,即使每棵决策树都没有剪枝,随机森林也不会出现过拟合的现象。
-
森林中的树的数量一般取值较大,抽取的属性值需要小于总特征数。
思考
- 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
- 为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”,也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
(四)、相关api
导包:
from sklearn.ensemble import RandomForestClassifier
调用:
RandomForestClassifier()
n_estimators:决策树数量,(default = 10)
Criterion:entropy、或者 gini, (default = gini)
max_depth:指定树的最大深度,(default = None 表示树会尽可能的生长)
max_features="auto”, 决策树构建时使用的最大特征数量
- If “auto”, then
max_features=sqrt(n_features). - If “sqrt”, then
max_features=sqrt(n_features)(same as “auto”). - If “log2”, then
max_features=log2(n_features). - If None, then
max_features=n_features.
bootstrap:是否采用有放回抽样,如果为 False 将会使用全部训练样本,(default = True)
min_samples_split: 结点分裂所需最小样本数,(default = 2)
- 如果节点样本数少于min_samples_split,则不会再进行划分.
- 如果样本量不大,不需要设置这个值.
- 如果样本量数量级非常大,则推荐增大这个值.
min_samples_leaf: 叶子节点的最小样本数,(default = 1)
- 如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝.
- 较小的叶子结点样本数量使模型更容易捕捉训练数据中的噪声.
min_impurity_split: 节点划分最小不纯度
- 如果某节点的不纯度(基尼系数,均方差)小于这个阈值,则该节点不再生成子节点,并变为叶子节点.
- 一般不推荐改动默认值1e-7。
4、adaboost
(一)、概述
是一种自适应提升的算法,基于Boosting思想实现的一种集成学习算法,核心思想使通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。弱分类器的性能比随机猜测强就行,就可以构造出一个非常准确的强分类器。
训练时,样本具有权重,并且在训练过程中动态调整,被分错的样本会增加权重,算法会更加关注难分的样本。
构建的树不能过深,否则很容易过拟合。
(二)、构建
权值调整:
AdaBoost算法提高那些被前一轮基分类器错误分类的样本的权值,降低那些被正确分类样本的权值,从而使得那些没被正确分类的样本由于权值的加大而受到后一轮基分类器的更大关注。
**基分类器组合:**采用加权多数表决的方法
分类误差率较小的弱分类器的权值大,在表决中起较大作用
分类误差率较大的弱分类器的权值小,在表决中起较小作用
(三)、算法推导
H ( x ) = s i g n ( ∑ i = 1 m α i h i ( x ) ) α 为 模 型 的 权 重 m 为 弱 学 习 器 的 数 量 h i ( x ) 表 示 第 i 个 弱 学 习 器 H ( x ) 输 出 结 果 大 于 0 就 归 于 正 类 , 小 于 0 就 归 于 负 类 H(x)=sign(\sum_{i=1}^mα_ih_i(x))\\ α为模型的权重\\ m为弱学习器的数量\\ h_i(x)表示第i个弱学习器\\ H(x)输出结果大于0就归于正类,小于0就归于负类 H(x)=sign(i=1∑mαihi(x))α为模型的权重m为弱学习器的数量hi(x)表示第i个弱学习器H(x)输出结果大于0就归于正类,小于0就归于负类
在初始化训练数据时,各项权重相同,开始训练第一个学习器,根据预测结果找一个错误率最小的分裂点计算并更新样本权重和模型权重。根据第一个弱学习器的新权重样本集再次训练第二个弱学习器,重复上诉更新权重动作,直到训练到第m个弱学习器为止。
adaboost模型权重更新公式:
α i = 1 2 I n ( 1 − ϵ i ϵ i ) ϵ i 表 示 第 i 个 弱 学 习 器 的 错 误 率 ϵ i 计 算 : 预 测 错 误 的 权 重 和 α_i=\frac{1}{2}In(\frac{1-\epsilon_i}{\epsilon_i})\\ \epsilon_i表示第i个弱学习器的错误率\\ \epsilon_i计算:预测错误的权重和 αi=21In(ϵi1−ϵi)ϵi表示第i个弱学习器的错误率ϵi计算:预测错误的权重和
adaboost样本权重更新公式:
D i + 1 ( x ) = D i ( x ) Z i ∗ { e − α i , 预 测 值 = 真 实 值 e α i , 预 测 值 ≠ 真 实 值 Z i 为 归 一 化 值 , 是 所 有 样 本 权 重 总 和 D i ( x ) 为 第 i 个 样 本 权 重 α i 为 第 i 个 模 型 的 权 重 D_{i+1}(x)=\frac{D_{i}(x)}{Z_i}* \begin{cases}e^{-α_i},\ \ 预测值=真实值\\e^{α_i},\ \ \ \ 预测值≠真实值\end{cases}\\ Z_i为归一化值,是所有样本权重总和\\ D_i(x)为第i个样本权重\\ α_i为第i个模型的权重 Di+1(x)=ZiDi(x)∗{e−αi, 预测值=真实值eαi, 预测值=真实值Zi为归一化值,是所有样本权重总和Di(x)为第i个样本权重αi为第i个模型的权重
(四)、举例构建过程
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。

- 构建第一个弱学习器
-
初始化工作:初始化 10 个样本的权重,每个样本的权重为:0.1
-
构建第一个基学习器:
-
寻找最优分裂点
- 对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
- 当以 0.5 为分裂点时,有 5 个样本分类错误
- 当以 1.5 为分裂点时,有 4 个样本分类错误
- 当以 2.5 为分裂点时,有 3 个样本分类错误
- 当以 3.5 为分裂点时,有 4 个样本分类错误
- 当以 4.5 为分裂点时,有 5 个样本分类错误
- 当以 5.5 为分裂点时,有 4 个样本分类错误
- 当以 6.5 为分裂点时,有 5 个样本分类错误
- 当以 7.5 为分裂点时,有 4 个样本分类错误
- 当以 8.5 为分裂点时,有 3 个样本分类错误
- 最终,选择以 2.5 作为分裂点,计算得出基学习器错误率为:3/10=0.3
-
计算模型权重:
1/2 * np.log((1-0.3)/0.3)=0.4236 -
更新样本权重:
- 分类正确样本为:1、2、3、4、5、6、10 共 7 个,其计算公式为:e-αt,则正确样本权重变化系数为:e-0.4236 = 0.6547
- 分类错误样本为:7、8、9 共 3 个,其计算公式为:eαt,则错误样本权重变化系数为:e0.4236 = 1.5275
- 样本 1、2、3、4、5、6、10 权重值为:
0.06547 - 样本 7、8、9 的样本权重值为:
0.15275 - 归一化 Zt 值为:
0.06547 * 7 + 0.15275 * 3 = 0.9165 - 样本 1、2、3、4、5、6、10 最终权重值为:
0.07143 - 样本 7、8、9 的样本权重值为:
0.1667
-
此时得到:

-

- 构建第二个弱学习器
-
寻找最优分裂点:
-
对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
-
当以 0.5 为分裂点时,有 5 个样本分类错误,错误率为:0.07143 * 5 = 0.35715
-
当以 1.5 为分裂点时,有 4 个样本分类错误,错误率为:0.07143 * 1 + 0.16667 * 3 = 0.57144
-
当以 2.5 为分裂点时,有 3 个样本分类错误,错误率为:0.16667 * 3 = 0.57144
。。。 。。。
-
当以 8.5 为分裂点时,有 3 个样本分类错误,错误率为:0.07143 * 3 = 0.21429
-
最终,选择以 8.5 作为分裂点,计算得出基学习器错误率为:0.21429
-
-
计算模型权重:
1/2 * np.log((1-0.21429)/0.21429)=0.64963 -
分类正确的样本:1、2、3、7、8、9、10,其权重调整系数为:0.5222
-
分类错误的样本:4、5、6,其权重调整系数为:1.9148
-
分类正确样本权重值:
- 样本 0、1、2、、9 为:0.0373
- 样本 6、7、8 为:0.087
-
分类错误样本权重值:0.1368
-
归一化 Zt 值为:
0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206 -
最终权重:
- 样本 0、1、2、9 为 :0.0455
- 样本 6、7、8 为:0.1060
- 样本 3、4、5 为:0.1667
-
此时得到:


- 构建第三个弱学习器
错误率:0.1820,模型权重:0.7514

- 强学习器

(五)、相关api
导包:
from sklearn.ensemble import AdaBoostClassifier
调用:
mytree = DecisionTreeClassifier(criterion=‘entropy’, max_depth=1, random_state=0)
先构建一颗ID3决策树
myada = AdaBoostClassifier(base_estimator=mytree, n_estimators=500, learning_rate=0.1, random_state=0)
将基学习器设置为上面构建出的决策树,设置500棵,学习率为0.1
5、GBDT
(一)、概述
梯度提升树(Gradient Boosting Decision Tree)是boosting树的一种。
(二)、算法推导
传统提升树使用的是拟合残差,而梯度提升树利用最速下降的近似方法,利用损失函数的负梯度作为树算法的残差近似值。
计算拟合负梯度:
∂ L ( y , f ( x ) ) ∂ f ( x i ) = f ( x i ) − y i − [ ∂ L ( y , f ( x ) ) ∂ f ( x i ) ] = y i − f ( x i ) y i 为 目 标 值 , f ( x i ) 为 预 测 值 \frac{\partial L(y,f(x))}{\partial f(x_i)}=f(x_i)-y_i\\ -[\frac{\partial L(y,f(x))}{\partial f(x_i)}]=y_i-f(x_i)\\ y_i为目标值,f(x_i)为预测值 ∂f(xi)∂L(y,f(x))=f(xi)−yi−[∂f(xi)∂L(y,f(x))]=yi−f(xi)yi为目标值,f(xi)为预测值
计算预测值:
损 失 函 数 : L ( y , f ( x ) ) = 1 2 ∑ i = 1 n ( y i − f ( x i ) ) 2 为 求 最 小 值 , 对 损 失 函 数 求 导 : ∂ L ( y , f ( x ) ) ∂ f ( x i ) = ∑ i = 1 n ( y i − f ( x i ) ) ∗ ( y i − f ( x i ) ) ‘ = ∑ i = 1 n ( y i − f ( x i ) ) ∗ ( − 1 ) = ∑ i = 1 n ( − y i + f ( x i ) ) = 0 整 理 得 到 : f ( x i ) = ∑ i = 1 n y i n y i 为 目 标 值 , f ( x i ) 为 预 测 值 注 意 此 处 的 预 测 值 在 第 一 次 时 都 一 样 , 后 续 被 切 分 点 分 为 左 子 树 和 右 子 树 , 左 子 树 预 测 值 相 同 , 右 子 树 预 测 值 相 同 损失函数:L(y,f(x))=\frac{1}{2}\sum_{i=1}^n(y_i-f(x_i))^2\\ 为求最小值,对损失函数求导:\frac{\partial L(y,f(x))}{\partial f(x_i)}=\sum_{i=1}^n(y_i-f(x_i))*(y_i-f(x_i))^`\\ =\sum_{i=1}^n(y_i-f(x_i))*(-1)\\ =\sum_{i=1}^n(-y_i+f(x_i))=0\\ 整理得到:f(x_i)=\frac{\sum_{i=1}^ny_i}{n}\\ y_i为目标值,f(x_i)为预测值\\ 注意此处的预测值在第一次时都一样,后续被切分点分为左子树和右子树,左子树预测值相同,右子树预测值相同 损失函数:L(y,f(x))=21i=1∑n(yi−f(xi))2为求最小值,对损失函数求导:∂f(xi)∂L(y,f(x))=i=1∑n(yi−f(xi))∗(yi−f(xi))‘=i=1∑n(yi−f(xi))∗(−1)=i=1∑n(−yi+f(xi))=0整理得到:f(xi)=n∑i=1nyiyi为目标值,f(xi)为预测值注意此处的预测值在第一次时都一样,后续被切分点分为左子树和右子树,左子树预测值相同,右子树预测值相同
计算每个切分点的平方损失,找到平方损失的切分点,以此切分,得到第一棵决策树;将负梯度值传递给下一棵树作为目标值,再次重复计算切分点平方损失,找到切分点,得到第二棵决策树。
(三)、举例
原始数据:

利用
f ( x i ) = ∑ i = 1 n y i n ∂ L ( y , f ( x ) ) ∂ f ( x i ) = f ( x i ) − y i − [ ∂ L ( y , f ( x ) ) ∂ f ( x i ) ] = y i − f ( x i ) y i 为 目 标 值 , f ( x i ) 为 预 测 值 f(x_i)=\frac{\sum_{i=1}^ny_i}{n}\\ \frac{\partial L(y,f(x))}{\partial f(x_i)}=f(x_i)-y_i\\ -[\frac{\partial L(y,f(x))}{\partial f(x_i)}]=y_i-f(x_i)\\ y_i为目标值,f(x_i)为预测值 f(xi)=n∑i=1nyi∂f(xi)∂L(y,f(x))=f(xi)−yi−[∂f(xi)∂L(y,f(x))]=yi−f(xi)yi为目标值,f(xi)为预测值
计算样本的负梯度为

当1.5为切分点:拟合负梯度-1.75, -1.61, -1.40, -0.91, … , 1.74
左子树:1个样本 -1.75, 右子树9个样本:-1.61,-1.40,-0.91…
右子树均值为:((-1.61) + (-1.40)+(-0.91)+(-0.51)+(-0.26)+1.59 +1.39 + 1.69 + 1.74 )/9=0.19;
左子树均值为:- 1.75
计算平方损失:左子树0 + 右子树:(-1.61-0.19)2 + (-1.40-0.19)2 + (-0.91-0.19)2 + (-0.51-0.19)2 +(-0.26-0.19)2 + (1.59-0.19)2 + (1.39-0.19)2 + (1.69-0.19)2 + (1.74-0.19)2 =15.72308
按照这个方式依次计算切分点值得到:

得到在6.5处切分最佳,得到左右子树,此时构建第二个弱学习器:

之前的负梯度就是该学习器的目标值,再利用公式计算左右树的预测值(左右树的均值),再次求负梯度和平方损失。

在3.5处作为切分点,得到第二棵决策树,重复以上动作,直到完成次数为止。下面是第二次计算完成,得出在6.5处切割。


第三次切割完成,我们假设三次就结束,以x=6样本为例,最终的学习器中的结果就是:7.31 + (-1.07) + 0.22 + 0.15 = 6.61


-1.07是第一棵决策树输出结果,0.22是第二棵决策树输出结果,0.15是第三棵决策树输出结果,初始值加上这些输出值,得到最后值。
(四)、相关api
导包:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
调用:
estimator = GradientBoostingClassifier()
网格交叉:
estimator = GradientBoostingClassifier()
param = {“n_estimators”: [100, 110, 120, 130], “max_depth”: [2, 3, 4], “random_state”: [9]}
estimator = GridSearchCV(estimator, param_grid=param, cv=3)
6、XGBoost
(一)、概述
eXtreme Gradient Boosting,极端梯度提升树,集成学习的王牌。
构建模型的方式为从最小化训练数据的损失函数
m i n 1 N ∑ i + 1 N L ( y i , y i ^ ) min\frac{1}{N}\sum_{i+1}^NL(y_i,\hat{y_i}) minN1i+1∑NL(yi,yi^)
训练的模型复杂度会较高,很容易过拟合。可以在损失函数中加入正则化项。
m i n 1 N ∑ i + 1 N L ( y i , y i ^ ) + Ω ( f ) min\frac{1}{N}\sum_{i+1}^NL(y_i,\hat{y_i})+\Omega(f) minN1i+1∑NL(yi,yi^)+Ω(f)
提高对未知的测试数据的泛化性能。
总体来说XGBoost是对GBDT的改进,在损失函数中加入了正则化项。
o b j ( ϕ ) = ∑ i n L ( y i , y i ^ ) + ∑ k = 1 K Ω ( f k ) Ω ( f ) = γ T + 1 2 λ ∣ ∣ w ∣ ∣ 2 T 表 示 一 棵 树 的 叶 子 节 点 数 量 , Ω ( f ) 是 模 型 复 杂 度 , o b j ( ϕ ) 是 目 标 函 数 w 表 示 叶 子 节 点 输 出 值 组 成 的 向 量 , ∣ ∣ w ∣ ∣ 是 向 量 的 模 , λ 对 该 项 的 调 节 系 数 obj(\phi)=\sum_i^nL(y_i,\hat{y_i})+\sum_{k=1}^K\Omega(f_k)\\ \Omega(f)=\gamma T+\frac{1}{2}\lambda||w||^2\\ T表示一棵树的叶子节点数量,\Omega(f)是模型复杂度,obj(\phi)是目标函数\\ w表示叶子节点输出值组成的向量,||w||是向量的模,\lambda对该项的调节系数 obj(ϕ)=i∑nL(yi,yi^)+k=1∑KΩ(fk)Ω(f)=γT+21λ∣∣w∣∣2T表示一棵树的叶子节点数量,Ω(f)是模型复杂度,obj(ϕ)是目标函数w表示叶子节点输出值组成的向量,∣∣w∣∣是向量的模,λ对该项的调节系数
(二)、算法推导
o b j ( ϕ ) = ∑ i n L ( y i , y i ^ ) + ∑ k = 1 K Ω ( f k ) Ω ( f ) = γ T + 1 2 λ ∣ ∣ w ∣ ∣ 2 T 表 示 一 棵 树 的 叶 子 节 点 数 量 w 表 示 叶 子 节 点 输 出 值 组 成 的 向 量 , ∣ ∣ w ∣ ∣ 是 向 量 的 模 , λ 对 该 项 的 调 节 系 数 obj(\phi)=\sum_i^nL(y_i,\hat{y_i})+\sum_{k=1}^K\Omega(f_k)\\ \Omega(f)=\gamma T+\frac{1}{2}\lambda||w||^2\\ T表示一棵树的叶子节点数量\\ w表示叶子节点输出值组成的向量,||w||是向量的模,\lambda对该项的调节系数 obj(ϕ)=i∑nL(yi,yi^)+k=1∑KΩ(fk)Ω(f)=γT+21λ∣∣w∣∣2T表示一棵树的叶子节点数量w表示叶子节点输出值组成的向量,∣∣w∣∣是向量的模,λ对该项的调节系数
上述公式经过t次迭代后,目标函数如下:
o b j ( ϕ ) ( t ) = ∑ i n L ( y i , y i ^ ( t ) ) + Ω ( f t ) = ∑ i n L ( y i , y i ^ ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) obj(\phi)^{(t)}=\sum_i^nL(y_i,\hat{y_i}^{(t)})+\Omega(f_t)\\ =\sum_i^nL(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))+\Omega(f_t) obj(ϕ)(t)=i∑nL(yi,yi^(t))+Ω(ft)=i∑nL(yi,yi^(t−1)+ft(xi))+Ω(ft)
由于直接求解目标函数比较困难,所以通过泰勒展开来将目标函数换成一种近似的表示方式
已知二阶泰勒展开:
f ( x + Δ x ) ≈ f ( x ) + f ‘ ( x ) ⋅ Δ x + 1 2 f ‘ ‘ ( x ) ⋅ Δ x 2 f(x+\Delta x)\approx f(x)+f^`(x)·\Delta x+\frac{1}{2}f^{``}(x)·\Delta x^2 f(x+Δx)≈f(x)+f‘(x)⋅Δx+21f‘‘(x)⋅Δx2
于是将目标公式二阶展开:
o b j ( ϕ ) ( t ) ≈ ∑ i n [ L ( y i , y i ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) h i = ∂ y ^ t − 1 L ( y i , y ^ t − 1 ) g i = ∂ y ^ t − 1 2 L ( y i , y ^ t − 1 ) obj(\phi)^{(t)}\approx \sum_i^n[L(y_i,\hat{y_i}^{(t-1)})+g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\\ h_i=\partial_{\hat y^{t-1}}L(y_i,\hat y^{t-1})\\ g_i=\partial_{\hat y^{t-1}}^2L(y_i,\hat y^{t-1}) obj(ϕ)(t)≈i∑n[L(yi,yi^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)hi=∂y^t−1L(yi,y^t−1)gi=∂y^t−12L(yi,y^t−1)
而损失函数是一个常数值,所以我们在下面的计算当中去掉,方便后续数据处理,因此数据修改为:
o b j ( ϕ ) ( t ) = ∑ i n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) obj(\phi)^{(t)}=\sum_i^n[g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t) obj(ϕ)(t)=i∑n[gift(xi)+21hift2(xi)]+Ω(ft)
完整式子为:
o b j ( ϕ ) ( t ) = ∑ i n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + γ T + 1 2 λ ∣ ∣ w ∣ ∣ 2 f t ( x i ) 表 示 样 本 的 预 测 值 , T 是 叶 子 节 点 的 数 量 obj(\phi)^{(t)}=\sum_i^n[g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\gamma T+\frac{1}{2}\lambda||w||^2\\ f_t(x_i)表示样本的预测值,T是叶子节点的数量 obj(ϕ)(t)=i∑n[gift(xi)+21hift2(xi)]+γT+21λ∣∣w∣∣2ft(xi)表示样本的预测值,T是叶子节点的数量
自定义叶子节点集合,然后对上述公式做转换
定 义 I j 为 叶 子 节 点 的 实 例 集 ∑ i n g i f t ( x i ) = ∑ j = 1 T ( ∑ i ∈ I j g i ) w j ∑ i n 1 2 h i f t 2 ( x i ) = ∑ j = 1 T 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 1 2 λ ∣ ∣ w ∣ ∣ 2 = 1 2 λ ∑ j = 1 T w j 2 将 转 换 带 入 后 简 化 得 : o b j ( ϕ ) ( t ) = ∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 ] + γ T 设 定 : G j = ∑ i ∈ I j g i H j = ∑ i ∈ I j h i 得 到 简 化 式 : o b j ( ϕ ) ( t ) = ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T 定义I_j为叶子节点的实例集\\ \sum_i^ng_if_t(x_i)=\sum_{j=1}^T(\sum_{i\in I_j}g_i)w_j\\ \sum_i^n\frac{1}{2}h_if_t^2(x_i)=\sum_{j=1}^T\frac{1}{2}(\sum_{i\in I_j}h_i+\lambda)w_j^2\\ \frac{1}{2}\lambda||w||^2=\frac{1}{2}\lambda \sum_{j=1}^Tw_j^2\\ 将转换带入后简化得:\\ obj(\phi)^{(t)}=\sum_{j=1}^T[(\sum_{i\in I_j}g_i)w_j+\frac{1}{2}(\sum_{i\in I_j}h_i+\lambda)w_j^2]+\gamma T\\ 设定:\\ G_j=\sum_{i\in I_j}g_i\\ H_j=\sum_{i\in I_j}h_i\\ 得到简化式:\\ obj(\phi)^{(t)}=\sum_{j=1}^T[G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2]+\gamma T 定义Ij为叶子节点的实例集i∑ngift(xi)=j=1∑T(i∈Ij∑gi)wji∑n21hift2(xi)=j=1∑T21(i∈Ij∑hi+λ)wj221λ∣∣w∣∣2=21λj=1∑Twj2将转换带入后简化得:obj(ϕ)(t)=j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT设定:Gj=i∈Ij∑giHj=i∈Ij∑hi得到简化式:obj(ϕ)(t)=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
求解到最终的损失函数,此时我们需要求解函数的最小值,因此我们对损失函数进行求导:
对 w j 进 行 求 导 , 并 且 令 其 等 于 0 : 简 化 后 可 得 : w j = − G j H j + λ 将 次 最 优 解 的 值 带 入 原 公 式 : o b j ( ϕ ) ( t ) = ∑ j = 1 T [ G j ( − G j H j + λ ) + 1 2 ( H j + λ ) ( − G j H j + λ ) 2 ] + γ T = ∑ j = 1 T [ − G j 2 H j + λ + 1 2 ( G j 2 H j + λ ) ] + γ T = − 1 2 ∑ j = 1 T ( G j 2 H j + λ ) + γ T 对w_j进行求导,并且令其等于0:\\ 简化后可得:w_j=-\frac{G_j}{H_j+\lambda}\\ 将次最优解的值带入原公式:\\ obj(\phi)^{(t)}=\sum_{j=1}^T[G_j(-\frac{G_j}{H_j+\lambda})+\frac{1}{2}(H_j+\lambda)(-\frac{G_j}{H_j+\lambda})^2]+\gamma T\\ =\sum_{j=1}^T[-\frac{G_j^2}{H_j+\lambda}+\frac{1}{2}(\frac{G_j^2}{H_j+\lambda})]+\gamma T\\ =-\frac{1}{2}\sum_{j=1}^T(\frac{G_j^2}{H_j+\lambda})+\gamma T 对wj进行求导,并且令其等于0:简化后可得:wj=−Hj+λGj将次最优解的值带入原公式:obj(ϕ)(t)=j=1∑T[Gj(−Hj+λGj)+21(Hj+λ)(−Hj+λGj)2]+γT=j=1∑T[−Hj+λGj2+21(Hj+λGj2)]+γT=−21j=1∑T(Hj+λGj2)+γT
此时的公式就是函数的最优解,我们将其称为打分函数,可以从损失函数和树的复杂度两个角度来衡量一棵树的优劣。当我们构建树的时候,我们可以用这个函数来选择树的划分点:
G a i n = o b j L + R − ( o b j L + o b j R ) = [ − 1 2 ( G L + G R ) 2 H L + H R + λ + γ T ] − [ − 1 2 ( G L 2 H L + λ + G R 2 H R + λ ) + γ ( T + 1 ) ] = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ ] − γ Gain=obj_{L+R}-(obj_L+obj_R)\\ =[-\frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}+\gamma T]-[-\frac{1}{2}(\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda})+\gamma (T+1)]\\ =\frac{1}{2}[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]-\gamma Gain=objL+R−(objL+objR)=[−21HL+HR+λ(GL+GR)2+γT]−[−21(HL+λGL2+HR+λGR2)+γ(T+1)]=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
根据上述公式,我们可以得出:
- 对树中的每个叶子节点都尝试进行分裂
- 计算分裂前-分裂后的分数
- 如果Gain>0,则分裂后树的损失更小,考虑此时分裂
- 如果Gain<0,则分裂后的的损失更大,不建议分裂
- 当触发以下条件时,停止分裂:
- 达到最大深度
- 叶子节点数量低于设定阈值
- 所有的节点分裂时都不能降低损失
(三)、相关api
导包:
from xgboost import XGBClassifier
调用:
estimator = XGBClassifier(n_estimators=100, objective=‘multi:softmax’,eval_metric=‘merror’, eta=0.1, use_label_encoder=False, random_state=22)
-
base_score:基础分数,用于模型初始化时的分数估计,默认值为0.5。
-
booster:基分类器的类型。默认值为’gbtree’,表示使用基于树的模型;还可以选择’gblinear’表示使用线性模型;在某些版本中,还支持’dart’表示使用带dropout的树模型来防止过拟合。
-
objective:目标函数,用于指定模型的训练目标。对于二分类问题,默认值为’binary:logistic’(返回概率);对于回归问题,可以使用’reg:linear’或’reg:logistic’;对于多分类问题,可以使用’multi:softmax’或’multi:softprob’。
-
random_state:随机种子,用于保证结果的可复现性
-
eta,也称为learning_rate: 学习率
相关文章:
决策树和集成学习的概念以及部分推导
一、决策树 1、概述 决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果 决策树的建立过程: 特征选择:选择有较强分类能力的特征决策树生成…...
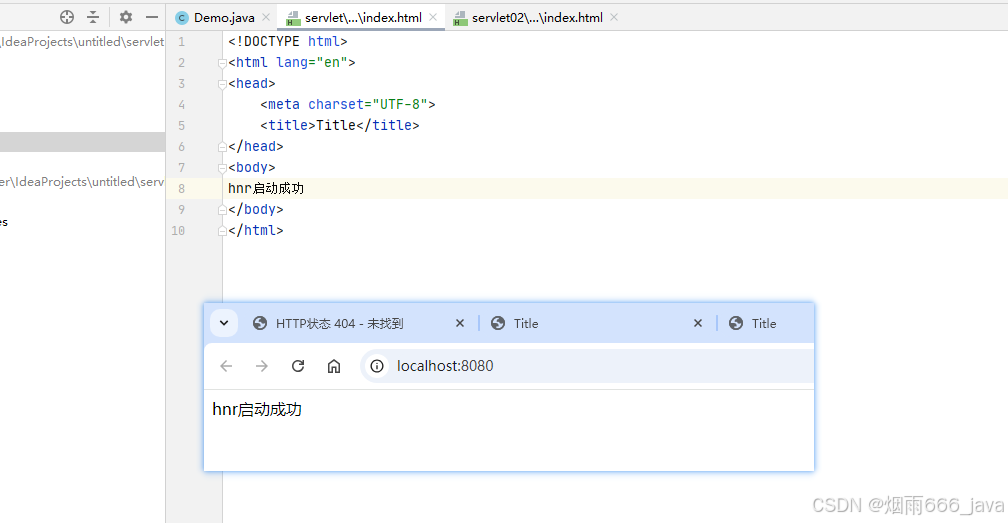
servlet基础与环境搭建(idea版)
文章目录 环境变量配置安包装环境变量配置JDK 配置 静态网页动态网页(idea)给模块添加 web框架新版本 2023 之后的 idea,使用方法二idea 目录介绍建立前端代码启动配置 环境变量配置 tomcat 环境变量 安包装 环境变量配置 JDK 配置 静态网页…...

【10月最新】植物大战僵尸杂交版新僵尸预告(附最新版本下载链接)
【BOSS僵尸】埃德加二世 【新BOSS僵尸】埃德加二世 “埃德加博士的克隆体。驾驶着最新一代小型化机甲,致力于为戴夫博士扫清障碍。” -体型(模型大小)小于原版僵王的头 -血量120000(原版僵王复仇的2倍),免疫…...

网络编程-UDP以及数据库mysql
UDP通信流程 服务端客户端有一个邮箱socket()有一个邮箱socket()绑定地址bind()发送数据sendto接收数据recvfrom关闭close()关闭colse() //服务端 #include "head.h" // ./server 10001 int main(int argc,char *argv[]) {// 1、创建socket套接字// 参数1ÿ…...

ubuntu 20.04 安装ros1
步骤 1:设置系统 首先,确保系统环境是最新的: sudo apt update sudo apt upgrade 步骤 2:设置源和密钥 添加 ROS 软件源: 首先,确保 curl 和 gnupg 已安装: sudo apt install curl gnupg2…...
ShardingSphere-Proxy 数据库中间件MySql分库分表环境搭建
一. ShardingSphere-Proxy简介 1、简介 Apache ShardingSphere 是一款开源分布式数据库生态项目,旨在碎片化的异构数据库上层构建生态,在最大限度的复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力。其核心采用可插…...

Pytest+selenium UI自动化测试实战实例
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 今天来说说pytest吧,经过几周的时间学习,有收获也有疑惑,总之最后还是搞个小项目出来证明自己的努力不没有白费 环境准备 1 …...
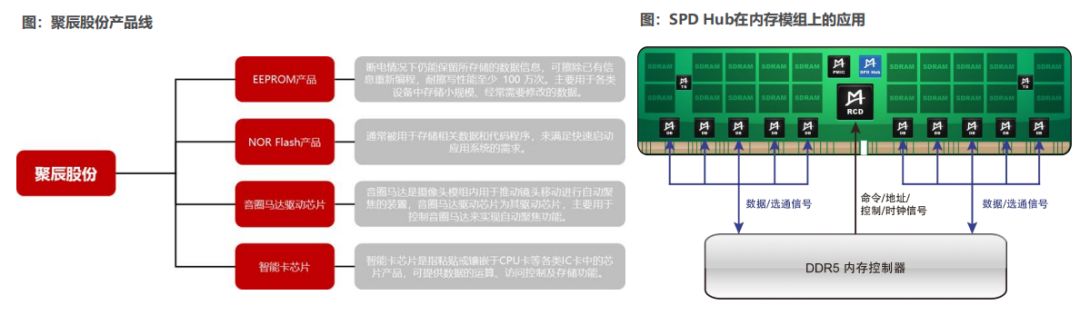
服务器技术研究分析:存储从HBM到CXL
服务器变革:存储从HBM到CXL 在《从云到端,AI产业的新范式(2024)》中揭示,传统服务器价格低至1万美金,而配备8张H100算力卡的DGX H100AI服务器价值高达40万美金(约300万人民币)。 从供…...

下载并安装 WordPress 中文版
下载并安装 WordPress 中文版 1. 安装 LAMP 环境(Linux, Apache, MySQL, PHP)1. 安装 Apache2. 安装 MySQL3. 安装 PHP1. 下载并安装 WordPress 中文版1. 下载 WordPress2. 配置文件权限3 . 创建 MySQL 数据库4 . 配置 WordPress1. 安装 LAMP 环境(Linux, Apache, MySQL, PH…...

从零开始的LeetCode刷题日记:515.在每个树行中找最大值
一.相关链接 题目链接:515.在每个树行中找最大值 二.心得体会 这道题也是层序遍历,只需要记录每一层的最大值即可,反复比较记录最大值。 三.代码 class Solution { public:vector<int> largestValues(TreeNode* root) {vector<…...

C语言 | Leetcode C语言题解之第492题构造矩形
题目: 题解: class Solution { public:vector<int> constructRectangle(int area) {int w sqrt(1.0 * area);while (area % w) {--w;}return {area / w, w};} };...

在FastAPI网站学python:虚拟环境创建和使用
Python虚拟环境(virtual environment)是一个非常重要的工具,它允许开发者为每个项目创建独立的Python环境,隔离您为每个项目安装的软件包,从而避免不同项目之间的依赖冲突。 学习参考FastAPI官网文档:Virt…...
)
安全风险评估(Security Risk Assessment, SRA)
安全风险评估(Security Risk Assessment, SRA)是识别、分析和评价信息安全风险的过程。它帮助组织了解其信息资产面临的潜在威胁,以及这些威胁可能带来的影响。通过风险评估,组织可以制定有效的风险管理策略,以减少或控…...
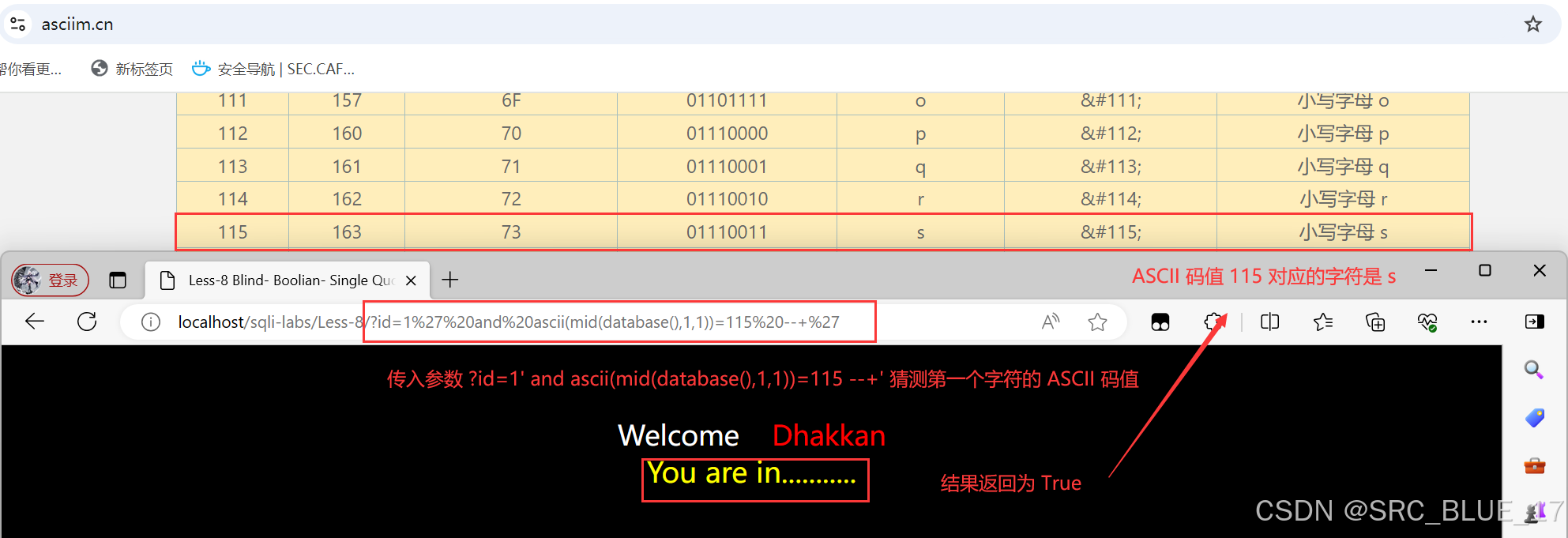
SQL Injection | SQL 注入 —— 布尔盲注
关注这个漏洞的其他相关笔记:SQL 注入漏洞 - 学习手册-CSDN博客 0x01:布尔盲注 —— 理论篇 布尔盲注(Boolean-Based Blind Injection)是一种常见的 SQL 注入技术,它适用于那些 SQL 注入时,查询结果不会直…...
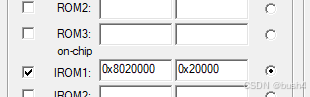
stm32 bootloader写法
bootloader写法: 假设app的起始地址:0x08020000,则bootloader的范围是0x0800,0000~0x0801,FFFF。 #define APP_ADDR 0x08020000 // 应用程序首地址定义 typedef void (*APP_FUNC)(void); // 函数指针类型定义 /*main函数中调用rum_app&#x…...

Unity3D 物体表面水滴效果详解
在游戏开发中,逼真的水滴效果能够显著提升游戏场景的真实感和沉浸感。Unity3D作为一款强大的游戏开发引擎,提供了丰富的工具和技术来实现这种效果。本文将详细介绍如何在Unity3D中实现物体表面的水滴效果,包括技术详解和代码实现。 对惹&…...
若依框架中spring security的完整认证流程,及其如何使用自定义用户表进行登录认证,学会轻松实现二开,嘎嘎赚块乾
1)熟悉之前的SysUser登录流程 过滤器链验证配置 这里security过滤器链增加了前置过滤器链jwtFilter 该过滤器为我们自定义的,每次请求都会经过jwt验证 ok我们按ctrl alt B跳转过去来看下 首先会获取登录用户LoginUser 内部通过header键,获…...

selenium:操作滚动条的方法(8)
selenium支持几种操作滚动条的方法,主要介绍如下: 使用ActionChains 类模拟鼠标滚轮操作 使用函数ActionChains.send_keys发送按键Keys.PAGE_DOWN往下滑动页面,发送按键Keys.PAGE_UP往上滑动页面。 from selenium import webdriver from se…...
Discuz | 起尔开发 传奇开服表游戏公益服发布论坛网站插件
Discuz | 起尔开发 传奇开服表游戏公益服发布论坛网站插件 插件下载:源码 - 起尔开发的插件下载 演示地址:discuz.72jz.com 标黄和非标黄自动分开 在标黄时间内显示在上面置顶,标黄过期后自动显示在下面白色区域。 后台可以设置非标黄默认…...

问:JAVA对象的数据结构长啥样?
Java 对象在内存中的结构是一个复杂且精细的设计,它不仅关乎对象如何存储,还直接影响到垃圾回收(GC)、并发控制等运行时行为。一个典型的 Java 对象主要由三部分组成:对象头(Object Header)、实…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...