MedMamba代码解释及用于糖尿病视网膜病变分类
MedMamba原理和用于糖尿病视网膜病变检测尝试
1.MedMamba原理

MedMamba发表于2024.9.28,是构建在Vision Mamba基础之上,融合了卷积神经网的架构,结构如下图:
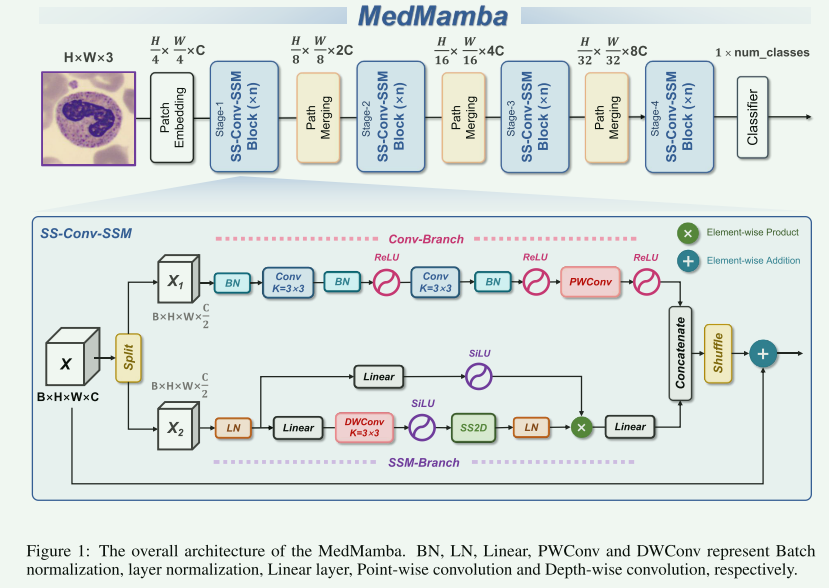
原理简述就是图片输入后按通道输入后切分为两部分,一部分走二维分组卷积提取局部特征,一部分利用Vision Mamba中的SS2D模块提取所谓的全局特征,两个分支的输出通过通道维度的拼接后,经过channel shuffle增加信息融合。
2.代码解释
模型代码就在源码的MedMamba.py文件下,对涉及到的代码我进行了详细注释:
-
mamba部分
基本上是使用Vision Mamaba的SS2D:
class SS2D(nn.Module):def __init__(self,d_model,d_state=16,# d_state="auto", # 20240109d_conv=3,expand=2,dt_rank="auto",dt_min=0.001,dt_max=0.1,dt_init="random",dt_scale=1.0,dt_init_floor=1e-4,dropout=0.,conv_bias=True,bias=False,device=None,dtype=None,**kwargs,):# 设置设备和数据类型的关键参数factory_kwargs = {"device": device, "dtype": dtype}super().__init__()self.d_model = d_model # 模型维度self.d_state = d_state # 状态维度# self.d_state = math.ceil(self.d_model / 6) if d_state == "auto" else d_model # 20240109self.d_conv = d_conv # 卷积核的大小self.expand = expand # 扩展因子self.d_inner = int(self.expand * self.d_model) # 内部维度,等于模型维度乘以扩展因子# 时间步长的秩,默认为模型维度除以16self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank# 输入投影层,将模型维度投影到内部维度的两倍,用于后续操作self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias, **factory_kwargs)# 深度卷积层,输入和输出通道数相同,组数等于内部维度,用于空间特征提取self.conv2d = nn.Conv2d(in_channels=self.d_inner,out_channels=self.d_inner,groups=self.d_inner,bias=conv_bias,kernel_size=d_conv,padding=(d_conv - 1) // 2, # 保证输出的空间维度与输入相同**factory_kwargs,)self.act = nn.SiLU() # 激活函数使用 SiLU# 定义多个线性投影层,将内部维度投影到不同大小的向量,用于时间步长和状态self.x_proj = (nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs), nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs), nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs), nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False, **factory_kwargs), )# 将四个线性投影层的权重合并为一个参数,方便计算self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K=4, N, inner)# 删除单独的投影层以节省内存del self.x_proj# 初始化时间步长的线性投影,定义四组时间步长投影参数self.dt_projs = (self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),self.dt_init(self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs),)# 将时间步长的权重和偏置参数合并为可训练参数self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K=4, inner, rank)self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K=4, inner)del self.dt_projs# 初始化 S4D 的 A 参数,用于状态更新计算self.A_logs = self.A_log_init(self.d_state, self.d_inner, copies=4, merge=True) # (K=4, D, N)# 初始化 D 参数,用于跳跃连接的计算self.Ds = self.D_init(self.d_inner, copies=4, merge=True) # (K=4, D, N)# 选择核心的前向计算函数版本,默认为 forward_corev0# self.selective_scan = selective_scan_fnself.forward_core = self.forward_corev0# 输出层的层归一化,归一化到内部维度self.out_norm = nn.LayerNorm(self.d_inner)# 输出投影层,将内部维度投影回原始模型维度self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias, **factory_kwargs)# 设置 dropout 层,如果 dropout 参数大于 0,则应用随机失活以防止过拟合self.dropout = nn.Dropout(dropout) if dropout > 0. else None@staticmethoddef dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4, **factory_kwargs):dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)# 初始化用于时间步长计算的线性投影层# Initialize special dt projection to preserve variance at initialization# 特殊初始化方法,用于保持初始化时的方差不变dt_init_std = dt_rank**-0.5 * dt_scaleif dt_init == "constant": # 初始化为常数nn.init.constant_(dt_proj.weight, dt_init_std)elif dt_init == "random": # 初始化为均匀随机数nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)else:raise NotImplementedError# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max# 初始化偏置,以便在使用 F.softplus 时,结果处于 dt_min 和 dt_max 之间dt = torch.exp(torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))+ math.log(dt_min)).clamp(min=dt_init_floor)# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759# softplus 的逆操作,确保偏置初始化在合适范围内inv_dt = dt + torch.log(-torch.expm1(-dt))with torch.no_grad():dt_proj.bias.copy_(inv_dt) # 设置偏置参数# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinitdt_proj.bias._no_reinit = True # 将该偏置标记为不重新初始化return dt_proj
-
SS_Conv_SSM
这部分就是论文提出的创新点,图片中的结构
class SS_Conv_SSM(nn.Module):def __init__(self,hidden_dim: int = 0,drop_path: float = 0,norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),attn_drop_rate: float = 0,d_state: int = 16,**kwargs,):super().__init__()# 初始化第一个归一化层,归一化的维度是隐藏维度的一半self.ln_1 = norm_layer(hidden_dim//2)# 初始化自注意力模块 SS2D,输入维度为隐藏维度的一半self.self_attention = SS2D(d_model=hidden_dim//2,dropout=attn_drop_rate,d_state=d_state,**kwargs)# DropPath 层,用于随机丢弃路径,提高模型的泛化能力self.drop_path = DropPath(drop_path)# 定义卷积模块,由多个卷积层和批量归一化层组成,用于特征提取self.conv33conv33conv11 = nn.Sequential(nn.BatchNorm2d(hidden_dim // 2),nn.Conv2d(in_channels=hidden_dim//2,out_channels=hidden_dim//2,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(hidden_dim//2),nn.ReLU(),nn.Conv2d(in_channels=hidden_dim // 2, out_channels=hidden_dim // 2, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(hidden_dim // 2),nn.ReLU(),nn.Conv2d(in_channels=hidden_dim // 2, out_channels=hidden_dim // 2, kernel_size=1, stride=1),nn.ReLU())# 注释掉的最终卷积层,可能用于进一步调整输出维度# self.finalconv11 = nn.Conv2d(in_channels=hidden_dim, out_channels=hidden_dim, kernel_size=1, stride=1)def forward(self, input: torch.Tensor):# 将输入张量沿最后一个维度分割为左右两部分input_left, input_right = input.chunk(2,dim=-1)# 对右侧输入进行归一化和自注意力操作,之后应用 DropPath 随机丢弃x = self.drop_path(self.self_attention(self.ln_1(input_right)))# 将左侧输入从 (batch_size, height, width, channels)# 转换为 (batch_size, channels, height, width) 以适应卷积操作input_left = input_left.permute(0,3,1,2).contiguous()input_left = self.conv33conv33conv11(input_left)# 将卷积后的左侧输入转换回原来的形状 (batch_size, height, width, channels)input_left = input_left.permute(0,2,3,1).contiguous()# 将左侧和右侧的输出在最后一个维度上拼接起来output = torch.cat((input_left,x),dim=-1)# 对拼接后的输出进行通道混洗,增加特征的融合output = channel_shuffle(output,groups=2)# 返回最终的输出,增加残差连接,将输入与输出相加return output+input -
VSSLayer
有以上结构堆叠构成网络结构
class VSSLayer(nn.Module):""" A basic Swin Transformer layer for one stage.Args:dim (int): Number of input channels.depth (int): Number of blocks.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self, dim, depth, attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False, d_state=16,**kwargs,):super().__init__()# 设置输入通道数self.dim = dim# 是否使用检查点self.use_checkpoint = use_checkpoint# 创建 SS_Conv_SSM 块列表,数量为 depthself.blocks = nn.ModuleList([SS_Conv_SSM(hidden_dim=dim, # 隐藏层维度等于输入维度# 处理随机深度的丢弃率drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer, # 使用的归一化层attn_drop_rate=attn_drop, # 注意力丢弃率d_state=d_state, # 状态维度)for i in range(depth)]) # 重复 depth 次构建块# 初始化权重 (暂时没有真正初始化,可能在后续被重写)# 确保这一初始化应用于模型 (在 VSSM 中被覆盖)if True: # is this really applied? Yes, but been overriden later in VSSM!# 对每个模块的参数进行初始化def _init_weights(module: nn.Module):for name, p in module.named_parameters():if name in ["out_proj.weight"]:# 克隆并分离参数 p,用于保持随机数种子一致p = p.clone().detach_() # fake init, just to keep the seed ....# 使用 Kaiming 均匀初始化方法nn.init.kaiming_uniform_(p, a=math.sqrt(5))# 应用初始化函数到整个模型self.apply(_init_weights)# 如果提供了下采样层,则使用该层,否则设置为 Noneif downsample is not None:self.downsample = downsample(dim=dim, norm_layer=norm_layer)else:self.downsample = Nonedef forward(self, x):# 逐块应用 SS_Conv_SSM 模块for blk in self.blocks:# 如果使用检查点,则通过检查点执行前向传播,节省内存if self.use_checkpoint:x = checkpoint.checkpoint(blk, x)else:# 否则直接进行前向传播x = blk(x)# 如果存在下采样层,则应用下采样层if self.downsample is not None:x = self.downsample(x)# 返回最终的输出张量return x -
最终的网络模型类
class VSSM(nn.Module):def __init__(self, patch_size=4, in_chans=3, num_classes=1000, depths=[2, 2, 4, 2], depths_decoder=[2, 9, 2, 2],dims=[96,192,384,768], dims_decoder=[768, 384, 192, 96], d_state=16, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, patch_norm=True,use_checkpoint=False, **kwargs):super().__init__()self.num_classes = num_classes # 设置分类的类别数目self.num_layers = len(depths) # 设置层的数量,即编码器层的数量# 如果 dims 是一个整数,则自动扩展为一个包含每一层维度的列表if isinstance(dims, int):dims = [int(dims * 2 ** i_layer) for i_layer in range(self.num_layers)]self.embed_dim = dims[0] # 嵌入维度等于第一层的维度self.num_features = dims[-1] # 特征维度等于最后一层的维度self.dims = dims # 记录每一层的维度# 初始化补丁嵌入模块,将输入图像分割成补丁并进行线性投影self.patch_embed = PatchEmbed2D(patch_size=patch_size, in_chans=in_chans, embed_dim=self.embed_dim,norm_layer=norm_layer if patch_norm else None)# WASTED absolute position embedding ======================# 是否使用绝对位置编码,默认情况下不使用self.ape = False# self.ape = False# drop_rate = 0.0# 如果使用绝对位置编码,则初始化位置编码参数if self.ape:self.patches_resolution = self.patch_embed.patches_resolution# 创建位置编码的可训练参数,并进行截断正态分布初始化self.absolute_pos_embed = nn.Parameter(torch.zeros(1, *self.patches_resolution, self.embed_dim))trunc_normal_(self.absolute_pos_embed, std=.02)# 位置编码的 Dropout 层self.pos_drop = nn.Dropout(p=drop_rate)# 使用线性函数生成每层的随机深度丢弃率dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # 随机深度衰减规则# 解码器部分的随机深度衰减dpr_decoder = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths_decoder))][::-1]# 初始化编码器的层列表self.layers = nn.ModuleList()for i_layer in range(self.num_layers): # 创建每一层的 VSSLayerlayer = VSSLayer(dim=dims[i_layer], # 输入维度depth=depths[i_layer], # 当前层包含的块数量d_state=math.ceil(dims[0] / 6) if d_state is None else d_state, # 状态维度drop=drop_rate, # Dropout率attn_drop=attn_drop_rate, # 注意力 Dropout率# 当前层的随机深度丢弃率drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],# 归一化层类型norm_layer=norm_layer,# 下采样层,最后一层不进行下采样downsample=PatchMerging2D if (i_layer < self.num_layers - 1) else None,# 是否使用检查点技术节省内存use_checkpoint=use_checkpoint,)# 将层添加到层列表中self.layers.append(layer)# self.norm = norm_layer(self.num_features)# 平均池化层,用于将特征池化为单个值self.avgpool = nn.AdaptiveAvgPool2d(1)# 分类头部,使用线性层将特征映射到类别数目self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()# 初始化模型权重self.apply(self._init_weights)# 对模型中的卷积层进行 Kaiming 正态分布初始化for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')def _init_weights(self, m: nn.Module):"""out_proj.weight which is previously initilized in SS_Conv_SSM, would be cleared in nn.Linearno fc.weight found in the any of the model parametersno nn.Embedding found in the any of the model parametersso the thing is, SS_Conv_SSM initialization is uselessConv2D is not intialized !!!"""# 对线性层和归一化层进行权重初始化if isinstance(m, nn.Linear):# 对线性层的权重使用截断正态分布初始化trunc_normal_(m.weight, std=.02)# 如果存在偏置,则将其初始化为 0if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):# 对 LayerNorm 层的偏置和权重初始化nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):# 返回不需要权重衰减的参数名return {'absolute_pos_embed'}@torch.jit.ignoredef no_weight_decay_keywords(self):# 返回不需要权重衰减的关键字return {'relative_position_bias_table'}def forward_backbone(self, x):# 使用补丁嵌入模块处理输入张量x = self.patch_embed(x)if self.ape:# 如果使用绝对位置编码,则将位置编码加到输入特征上x = x + self.absolute_pos_embed# 位置编码之后应用 Dropoutx = self.pos_drop(x)# 逐层通过编码器层for layer in self.layers:x = layer(x)return xdef forward(self, x):# 通过骨干网络提取特征x = self.forward_backbone(x)# 变换维度以适应池化操x = x.permute(0,3,1,2)# 使用自适应平均池化将特征降维x = self.avgpool(x)# 展平成一个向量x = torch.flatten(x,start_dim=1)# 通过分类头进行最终的类别预测x = self.head(x)return x作者在原文中尝试了大中小三个不同的参数版本
medmamba_t = VSSM(depths=[2, 2, 4, 2],dims=[96,192,384,768],num_classes=6).to("cuda") medmamba_s = VSSM(depths=[2, 2, 8, 2],dims=[96,192,384,768],num_classes=6).to("cuda") medmamba_b = VSSM(depths=[2, 2, 12, 2],dims=[128,256,512,1024],num_classes=6).to("cuda")总体论文原理比较简单,但是论文实验做得很扎实,感兴趣查看原文。
3.在糖尿病视网膜数据上实验一下效果
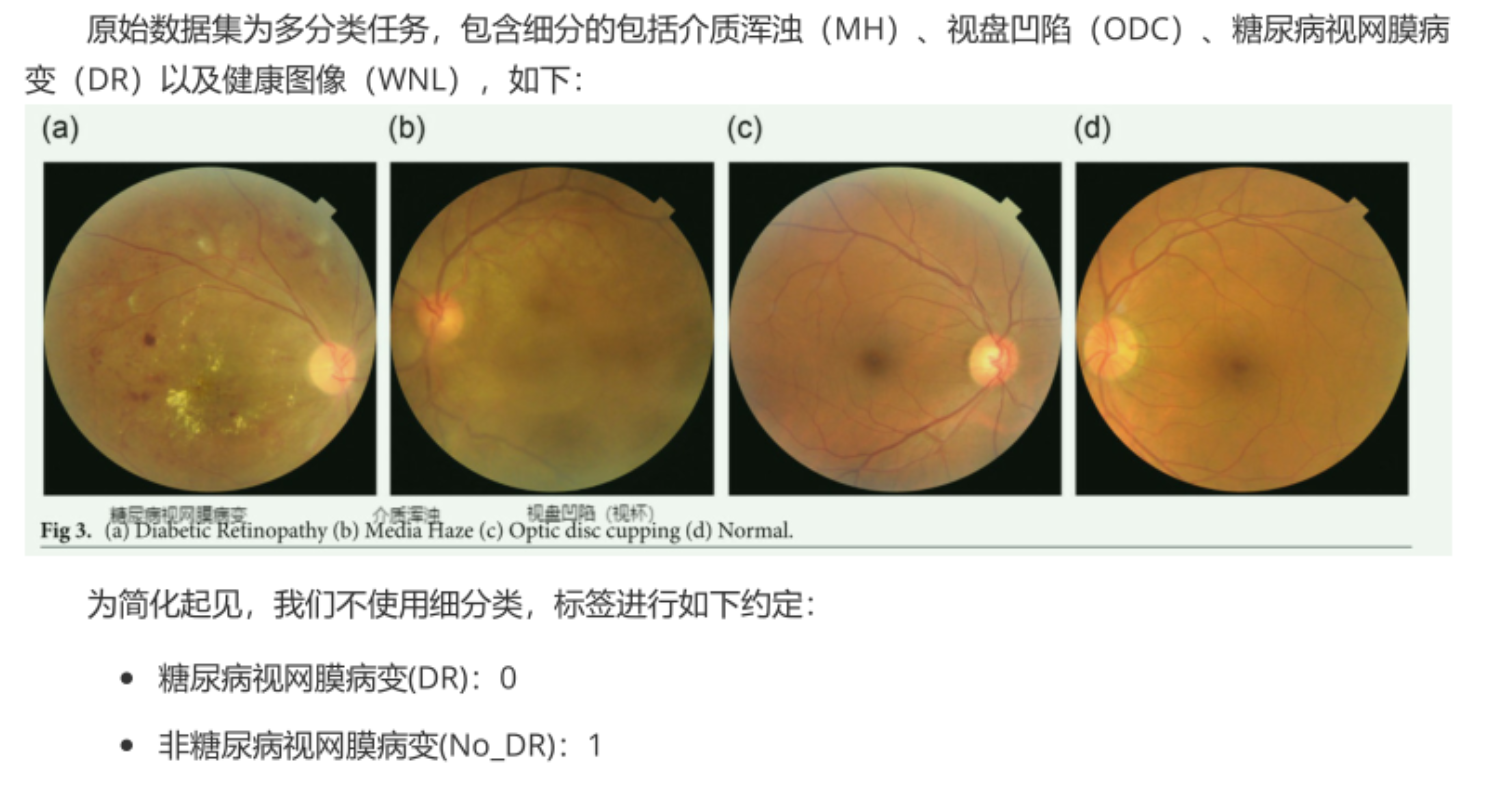
数据集情况
采用开源的retino_data糖尿病视网膜病变数据集:
环境安装
这部分主要是vision mamba的环境安装不要出错,参考官方Github会有问题:
-
Python 3.10.13
conda create -n vim python=3.10.13
-
torch 2.1.1 + cu118
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
-
Requirements: vim_requirements.txt
pip install -r vim/vim_requirements.txt
wget https://github.com/Dao-AILab/causal-conv1d/releases/download/v1.1.3.post1/causal_conv1d-1.1.3.post1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
wget https://github.com/state-spaces/mamba/releases/download/v1.1.1/mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
-
pip install causal_conv1d-1.1.3.post1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
-
pip install mamba_ssm-1.1.1+cu118torch2.1cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
-
然后用官方项目里的mamba_ssm替换安装在conda环境里的mamba_ssm
-
用conda env list 查看刚才安装的mamba环境的路径,我的mamba环境在/home/aic/anaconda3/envs/vim
-
用官方项目里的mamba_ssm替换安装在conda环境里的mamba_ssm
cp -rf mamba-1p1p1/mamba_ssm /home/aic/anaconda3/envs/vim/lib/python3.10/site-packages
-
代码编写
编写一个检查数据集均值和方差的代码,不用Imagenet的:
# -*- coding: utf-8 -*-
# 作者: cskywit
# 文件名: mean_std.py
# 创建时间: 2024-10-07
# 文件描述:计算数据集的均值和方差# 导入必要的库
from torchvision.datasets import ImageFolder
import torch
from torchvision import transforms# 定义函数get_mean_and_std,用于计算训练数据集的均值和标准差
def get_mean_and_std(train_data):# 创建DataLoader,用于批量加载数据train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)# 初始化均值和标准差mean = torch.zeros(3)std = torch.zeros(3)# 遍历数据集中的每个批次for X, _ in train_loader:# 遍历RGB三个通道for d in range(3):# 计算每个通道的均值和标准差mean[d] += X[:, d, :, :].mean()std[d] += X[:, d, :, :].std()# 计算最终的均值和标准差mean.div_(len(train_data))std.div_(len(train_data))# 返回均值和标准差列表return list(mean.numpy()), list(std.numpy())# 判断是否为主程序
if __name__ == '__main__':root_path = '/home/aic/deep_learning_data/retino_data/train'# 使用ImageFolder加载训练数据集train_dataset = ImageFolder(root=root_path, transform=transforms.ToTensor())# 打印训练数据集的均值和标准差print(get_mean_and_std(train_dataset))# ([0.41586006, 0.22244255, 0.07565845],# [0.23795983, 0.13206834, 0.05284985])
然后编写train
# -*- coding: utf-8 -*-
# 作者: cskywit
# 文件名: train_DR.py
# 创建时间: 2024-10-10
# 文件描述:
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdmfrom MedMamba import VSSM as medmamba # import model
import warnings
import os,syswarnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0"# 设置随机因子
def seed_everything(seed=42):os.environ['PYHTONHASHSEED'] = str(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.deterministic = Truedef main():# 设置随机因子seed_everything()# 一些超参数设定num_classes = 2BATCH_SIZE = 64num_of_workers = min([os.cpu_count(), BATCH_SIZE if BATCH_SIZE > 1 else 0, 8]) # number of workersdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")epochs = 300best_acc = 0.0save_path = './{}.pth'.format('bestmodel')# 数据预处理transform = transforms.Compose([transforms.RandomRotation(10),transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])])transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])])# 加载数据集root_path = '/home/aic/deep_learning_data/retino_data'train_path = os.path.join(root_path, 'train')valid_path = os.path.join(root_path, 'valid')test_path = os.path.join(root_path, 'test')dataset_train = datasets.ImageFolder(train_path, transform=transform)dataset_valid = datasets.ImageFolder(valid_path, transform=transform_test)dataset_test = datasets.ImageFolder(test_path, transform=transform_test)class_labels = {0: 'Diabetic Retinopathy', 1: 'No Diabetic Retinopathy'}val_num = len(dataset_valid)train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE,num_workers=num_of_workers,shuffle=True,drop_last=True)valid_loader = torch.utils.data.DataLoader(dataset_valid,batch_size=BATCH_SIZE,num_workers=num_of_workers,shuffle=False,drop_last=True)test_loader = torch.utils.data.DataLoader(dataset_test,batch_size=BATCH_SIZE,shuffle=False)print('Using {} dataloader workers every process'.format(num_of_workers))# 模型定义net = medmamba(num_classes=num_classes).to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0001)train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(valid_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
感觉Mamaba系列的通病了吧,显存占用不算高,GPU利用率超高:
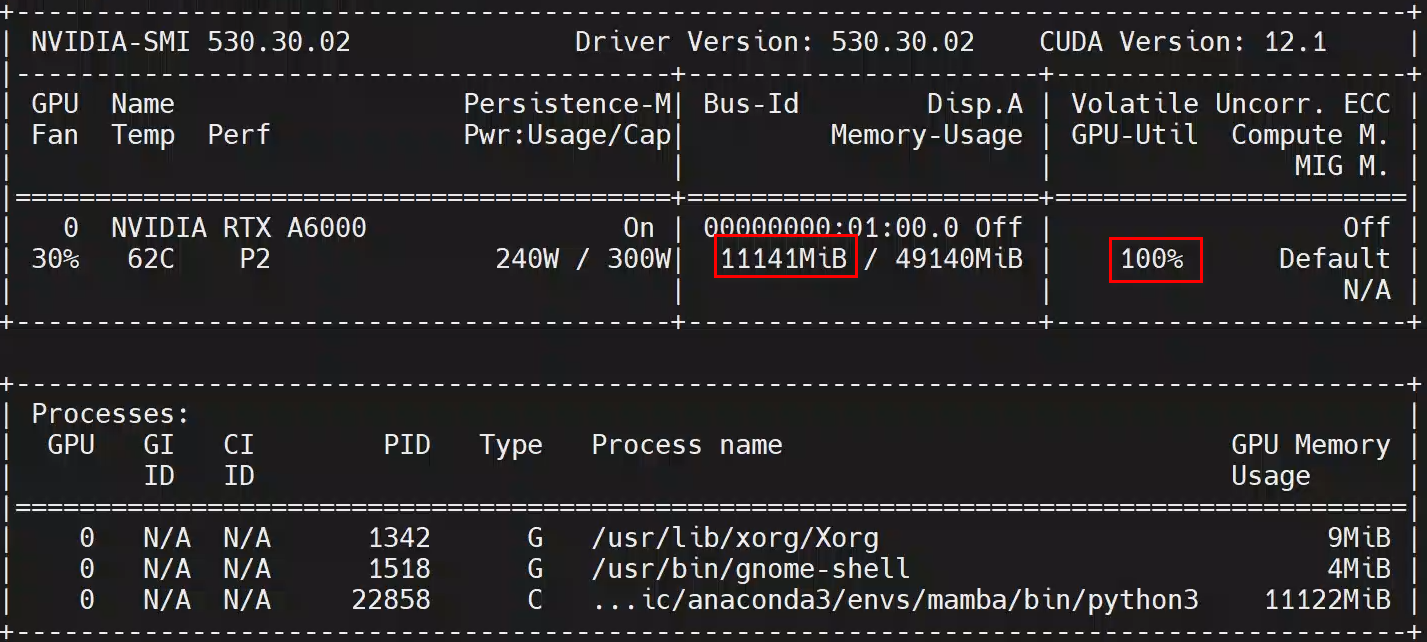
可能是没有用任何的训练调参技巧,经过几个epoch后,验证集准确率很快提升到了92.3%,然后就没有继续上升了。
相关文章:
MedMamba代码解释及用于糖尿病视网膜病变分类
MedMamba原理和用于糖尿病视网膜病变检测尝试 1.MedMamba原理 MedMamba发表于2024.9.28,是构建在Vision Mamba基础之上,融合了卷积神经网的架构,结构如下图: 原理简述就是图片输入后按通道输入后切分为两部分,一部分走…...

单点登录的要点
单点登录(SSO)是一种身份验证服务,它允许用户使用一组凭据登录一次,然后在多个应用程序中访问其他应用程序而无需重新进行身份验证。这样,用户只需一次登录即可访问整个应用生态系统,提高了用户体验并简化了…...

linux线程 | 一点通你的互斥锁 | 同步与互斥
前言:本篇文章主要讲述linux线程的互斥的知识。 讲解流程为先讲解锁的工作原理, 再自己封装一下锁并且使用一下。 做完这些就要输出一堆理论性的东西, 但博主会总结两条结论!!最后就是讲一下死锁。 那么, 废…...

全栈开发小项目
用到的技术栈: nodejswebpackknockoutmongodbPM2rabbitmq 以下是一个综合指南,展示如何将 Node.js、Webpack、Knockout.js、MongoDB、PM2 和 RabbitMQ 集成到一个项目中。 我们将在这一项目中添加 RabbitMQ,用于处理消息队列。这对于任务分…...

批处理一键创建扫描仪桌面打开快捷方式图标 简单直接有效 扫描文档图片的应急策略
办公生活中,我们在安装完多功能一体机的打印驱动之后,找不到扫描文件的地方,如果驱动程序安装正确,我们可以用系统自带的扫描仪程序调用这种打印机或复印机的扫描程序即可,它在电脑系统中的位置一般是:C:\W…...

【服务器知识】Tomcat简单入门
文章目录 概述Apache Tomcat 介绍主要特性版本历史使用场景 核心架构Valve机制详细说明请求处理过程 Tomcat安装Windows系统下Tomcat的安装与配置:步骤1:安装JDK步骤2:下载Tomcat步骤3:解压Tomcat步骤4:配置环境变量&a…...

【前端】Matter:过滤与高级碰撞检测
在物理引擎中,控制物体的碰撞行为是物理模拟的核心之一。Matter.js 提供了强大的碰撞检测机制和碰撞过滤功能,让开发者可以控制哪些物体能够相互碰撞,如何处理复杂的碰撞情况。本文将详细介绍 碰撞过滤 (Collision Filtering) 与 高级碰撞检测…...

wps图标没有坐标轴标题怎么办?wps表格不能用enter下怎么办?
目录 wps图标没有坐标轴标题怎么办 一、在WPS PPT中添加坐标轴标题 二、在WPS Excel中添加坐标轴标题 wps表格不能用enter下怎么办 一、检查并修改设置 二、检查单元格保护状态 三、使用快捷键实现换行 wps图标没有坐标轴标题怎么办 一、在WPS PPT中添加坐标轴标题 插入…...

在ESP-IDF环境中如何进行多文件中的数据流转-FreeRTOS实时操作系统_流缓存区“xMessageBuffer”
一、建立三个源文件和对应的头文件 建立文件名,如图所示 图 1-1 二、包含相应的头文件 main.h 图 2-1 mess_send.h mess_rece.h和这个中类似,不明白的大家看我最后面的源码分享 图2-2 三、声明消息缓存区的句柄 大家注意,在main.c中定义的是全局变…...

ConcurrentLinkedQueue适合什么样的使用场景?
ConcurrentLinkedQueue 是 Java 中一种无界线程安全的队列,适合多线程环境中的高并发场景。以下是一些它特别适合的使用场景: 1. 高频读操作,低频写操作 ConcurrentLinkedQueue 对于实际应用中读操作相对频繁,写操作较少的场景非…...

C语言 | Leetcode C语言题解之第480题滑动窗口中位数
题目: 题解: struct Heap {int* heap;int heapSize;int realSize;bool (*cmp)(int, int); };void init(struct Heap* obj, int n, bool (*cmp)(int, int)) {obj->heap malloc(sizeof(int) * (n 1));obj->heapSize 0;obj->cmp cmp; }bool c…...
LabVIEW开发如何实现降维打击
在LabVIEW开发中实现“降维打击”可以理解为利用软件优势和高效工具来解决复杂的问题,将多维度、多层次的技术简化为容易操作和管理的单一维度,达到出其不意的效果。以下是几种关键策略: 1. 模块化设计与封装 将复杂系统分解为若干模块&…...

docker 文件目录迁移
文章参考 du -hs /var/lib/docker/ 命令查看磁盘使用情况。 du -hs /var/lib/docker/docker system df命令,类似于Linux上的df命令,用于查看Docker的磁盘使用情况: rootnn0:~$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 7 2 122.2…...

Markdown 标题
Markdown 标题 Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成格式化的HTML代码。Markdown 的语法简洁明了,广泛用于撰写文档、博客文章、笔记等。本文将详细介绍 Markdown 的标题语法及其在文档中的应用。 Markdown 标题语法 在…...

【动手学电机驱动】TI InstaSPIN-FOC(5)Lab04 力矩控制
TI InstaSPIN-FOC(1)电机驱动和控制测试平台 TI InstaSPIN-FOC(2)Lab01 闪灯实验 TI InstaSPIN-FOC(3)Lab03a 测量电压电流漂移量 TI InstaSPIN-FOC(4)Lab02b 电机参数辨识 TI Insta…...

Mysql的CommunicationsException
一、报错内容 com.mysql.cj.jdbc.exceptions.CommunicationsException: The last packet successfully received from the server was 1,500,378 milliseconds ago. The last packet sent successfully to the server was 1,500,378 milliseconds ago. is longer than the s…...
---- 重用目的的继承)
C++学习笔记----9、发现继承的技巧(二)---- 重用目的的继承
现在你对继承的基本语法已经比较熟悉了,是时候探索继承是c语言中重要属性的一个主要原因了。继承是一个装备允许你平衡既有代码。本节会举出基于代码重用目的的继承的例子。 1、WeatherPrediction类 假想你有一个任务,写一个程序来发出简单的天气预报&a…...

锐评 Nodejs 设计模式 - 创建与结构型
本系列文章的思想,都融入了 让 Java 再次伟大 这个全新设计的脚手架产品中,欢迎大家使用。 单例模式与模块系统 Node 的单例模式既特殊又简单——凡是从模块中导出的实例天生就是单例。 // database.js function Database(connect, account, password)…...

【RoadRunner】自动驾驶模拟3D场景构建 | 软件简介与视角控制
💯 欢迎光临清流君的博客小天地,这里是我分享技术与心得的温馨角落 💯 🔥 个人主页:【清流君】🔥 📚 系列专栏: 运动控制 | 决策规划 | 机器人数值优化 📚 🌟始终保持好奇心&…...

15分钟学Go 第4天:Go的基本语法
第4天:基本语法 在这一部分,将讨论Go语言的基本语法,了解其程序结构和基础语句。这将为我们后续的学习打下坚实的基础。 1. Go语言程序结构 Go语言程序的结构相对简单,主要包括: 包声明导入语句函数语句 1.1 包声…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...