零基础读懂Stable Diffusion!
前言
一文搞懂Stable Diffusion是什么,怎么训练和使用,语义信息影响生成图片的过程。>>[][加入极市CV技术交流群,走在计算机视觉的最前沿]
前几个月AIGC可谓是大热了一把,各种高质量的生成图片层出不穷,而其中最重要的开源模型Stable Diffusion也受到了各种技术商业上的热捧,以很快的速度不断的向前迭代着。之前作为一个没有相关知识基础的小白,为了了解相关的技术知识,找了很多文章看,最后还是发现Jay Alammar的这篇文章讲的最为通俗易懂,于是决定简单翻译一下,方便更多人从零开始了解这项强大的技术。
由于原文篇幅较长,所以这里分为三部分进行讲解:
-
第一部分,主要讲“是什么”的问题,包括Stable Diffusion是什么,里面的各个模块是什么
-
第二部分,主要讲“怎么办”的问题,也就是Diffusion怎么训练以及怎么使用的问题。
-
第三部分,主要讲“如何控制”的问题,具体阐述语义信息到底是怎么影响生成图片的过程的。
接下来正式进入第一部分的介绍,谈谈Stable Diffusion是什么,以及里面的一些模块是什么的问题。
本次教程将使用AI绘画工具 Stable Diffusion 进行讲解,如还未安装SD的小伙伴可以扫描免费获取哦~
零基础读懂Stable Diffusion(I):怎么组成
AI图像生成最近所展现出的潜力可谓是让人大开眼界,它能够从一些简单的文字描述开始,变魔法一般的变出高质量的图片。不用说,这已然深刻的拓宽了人类创作艺术的方式。而其中,Stable Diffusion的公布算是一个里程碑事件了,它的开源不仅仅意味着面向大众群体公开了一个极高质量的模型,与此同时这个模型甚至能保持很快的运行速度和较低的显存需求,不可谓不厉害。
用过了Diffusion这个神奇的技术后,你可能会好奇它到底为什么能有如此好的效果,这里将给出一个尽量简单直白的解释。
Stable Diffusion模型确实是多才多艺的,它可以出色的完成很多任务,比如文生图,图生图,特定角色的刻画,甚至超分或者Inpainting,但作为最基础的一篇介绍,这里我们首先就着重讲解最基础的“文生图”模块,也就是txt2img部分。下图是一个基本的文生图展示,输入是“天堂(paradise)、广袤的(cosmic)、海滩(beach)”,可以看到最右边的生成图片很好的符合了输入的要求,图中不仅有蓝天白云,广阔的海滩也一望无际:

最最简单的txt2img示意图,之后我们会不断细化和分解这张图里txt2img的过程
虽然本文暂时还没讲到图生图模块(也就是所谓的img2img),但这个模块的示意图我们也暂时放一下,如下图所示,这次的输入从单纯的“文字”变成了“图片+文字”的形式,生成的结果是由原始图片和文字提示词共同决定的。这次输入是"海盗船(pirate ship)"和上面img2img生成的图片,最后输出的结果也确实把输入图片的帆船变成了海盗船

img2img示意图,输入是"海盗船(pirate ship)",最后输出的结果也确实把输入图片的帆船变成了海盗船
现在,让我们正式开始了解这项技术背后的原理吧。
一、组成模块
Stable Diffusion其实是个比较杂合的系统,里面有着各种各样的模型模块。那首先映入眼帘的问题是,怎么把人类理解的文字转换为机器理解的数学语言,毕竟计算机是不懂英文的嘛。这个时候就需要一个text understander帮忙转化。在生成图像前,下图中蓝蓝的text understander先把文字转换成某种计算机能理解的数学表示:

蓝蓝的text understander(也就是一个文字的encoder编码器)把人类语言转换成计算机能理解的语义内容
我们后续在第三篇中会讲到这个text understander到底是怎么理解文字和怎么训练的,但现在暂时让我略过这一部分内容,我们只要知道这个text understander是个特别的Transformer语言模型就好了。它的输入是人类语言,输出是一系列的向量,这些向量的语义对应着我们输入的文字。
那么现在,有了可以代表语义的向量(就比如下面的蓝色3*5方格),我们就把这个语义向量交给真正的图片生成器了,也即下图中粉粉的Image Generator。

蓝色方格的语义向量被输入到粉色的图片生成器中,正式开始生成图片
这个粉色的图片生成器(Image Generator)可以分解成两个子模块来看
1,图片信息生成器
这个下图中粉色的模块是Stable Diffusion的秘密武器,也是Stable Diffusion和其他diffusion模型最大的区别,很多性能上的提升就来源于此。
首先,最需要明确的一点:图片信息生成器不直接生成图片,而是生成的较低维度的图片信息,也就是所谓的隐空间信息(information of latent space)。这个隐空间信息在下面的流程图中表现为那个粉色的4*3的方格,后续再将下图中这个隐空间信息输入到下图中黄色的Decoder里,就可以成功生成图片了。Stable Diffusion主要引用的论文“latent diffusion”中的latent也是来源于隐变量中的“隐”(latent)。
一般的diffusion模型都是直接生成图片,并不会有先生成隐变量的过程,所以普通的diffusion在这一步上需要生成的信息更多,负荷也更大。因而之前的diffusion模型在速度上和资源利用上都比不过Stable Diffusion。那技术上来说,这个图片隐变量到底是怎么生成的呢?这其实是由一个Unet和一个Schedule算法共同完成的。schedule算法控制生成的进度,unet就具体去一步一步地执行生成的过程。Stable Diffusion中,整个unet的生成迭代过程大概要重复50~100次,隐变量的质量也在这个迭代的过程中不断的变得更好。下图中粉色的Image Information Creator左下角的循环标志也正是象征着这个迭代的过程。
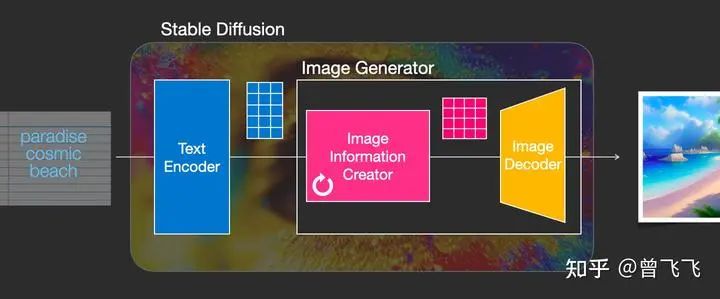
2,图片解码器
图片解码器也就是我们上面说的decoder,它从图片信息生成器(Image Information Creator)中接过图片信息的隐变量,将其升维放大(upscale),还原成一张完整的图片。图片解码器只在最后的阶段起作用,也是我们真正能获得一张图片的最终过程。

上面粗略的聊了一下Stable Diffusion每个模块的功能,下面我们来更具体的了解一下这个系统中输入输出的向量形状,这样的话对Stable Diffusion的工作原理应该能有更直观的认识:
-
Text Encoder (蓝色模块) 功能:将人类语言转换成机器能理解的数学向量 输入:人类语言 输出:语义向量(77,768)
-
Image Information Creator (粉色模块) 功能:结合语义向量,从纯噪声开始逐步去除噪声,生成图片信息隐变量 输入:噪声隐变量(4,64,64)+语义向量(77,768) 输出:去噪的隐变量(4,64,64)
-
Image Decoder 功能:将图片信息隐变量转换为一张真正的图片。输入:去噪的隐变量(4,64,64) 输出:一张真正的图片(3,512,512)
大概流程中的向量形状变化就是这样,至于语义向量的形状为什么是奇怪的(77,768)的形状,我们后面讲到Text Encoder里面的CLIP模型的时候还会讲到,这里就暂且按下不表。
二、扩散(Diffusion)到底是什么意思?
Diffusion模型,翻译成中文也就是扩散模型,那这个扩散到底体现在什么地方呢?这就是我们这第二部分着重要描述的过程。首先我们先用random函数生成一个隐变量大小的纯噪声【下图中左下透明4*4】。而扩散的过程发生在Image Information Creator中,有了初始的纯噪声【下图中左下透明4*4】+语义向量【下图左上蓝色3*5】后,unet会结合语义向量不断的去除纯噪声隐变量中的噪声,重复50~100次左右就完全去除了噪声,同时不断的向隐变量中注入语义信息,我们就得到了一个有语义的隐变量【下图粉色4*4】。别忘了我们还有一个scheduler,它就用来控制unet去噪的强度,以统筹整个去噪的过程。scheduler可以在去噪的不同阶段中动态地调整去噪强度,也可以在某些特殊的任务里,匀速地去除噪声,这都取决于我们一开始的设计。

这个扩散过程是一步一步迭代去噪的,每一步都向隐变量中注入语义信息,不断重复直到去噪完成为止。为了有个直观的认识,我们可以把初始的纯噪声【下图左上透明4*4】和最后的去噪隐变量【下图右上粉色4*4】都通过最后的Image Decoder,看看会出来什么样的图片。不出意料,纯噪声本身没有任何有效信息,解码出来的图片也会是纯噪声,如下图左侧所示。而最后的去噪隐变量由于已经耦合了语义信息,因此最后解码出来的也是一张包含语义信息的有效图片,如下图右侧图片所示。
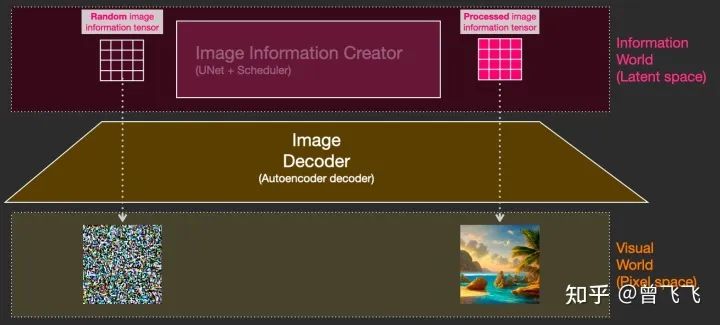
刚才我们也提到过,扩散过程是一个多次迭代的过程。每一步迭代的输入都是一个隐变量,输出也是一个隐变量,只不过输出的这个隐变量噪声更少,并且语义信息更多。下图中4*4的隐变量不断从透明变粉的过程就代表了这个迭代的过程,颜色越粉,迭代次数越多,噪声也就越少。

这个时候我们再偷偷用Image Decoder提前看一下每一步所对应的图片,就会看到我们想要的图片一步一步地脱胎于噪声的全过程:

这是一个神奇的过程,下面的视频展示了迭代去噪的全过程,我们可以看一下视频的展示:
三、总结
至此,我们已经了解了Stable Diffusion是什么,以及其中的种种模块是什么,甚至还简单的窥视了一下它的工作过程。至于为什么Diffusion如何训练、如何控制,鉴于篇幅原因,就容我放到后文中再去细讲了。这里最后再简单做一下总结:
-
第一部分介绍了一些Stable Diffusion中的主要模块——包括一个Text Understander处理语义信息,一个Image Information Creator生成图片的隐变量,一个Image Decoder利用隐变量生成真正的图片。
-
其次还介绍了一下Diffusion生成图片的流程——包括向量形状在系统中经历的一系列变化,以及各个阶段图片隐变量解码后的可视化。
零基础读懂Stable Diffusion(II):怎么训练
一,Diffusion怎么训练
Diffusion模型能够生成高质量图片,其核心原因在于我们现在有着极其强大的计算机视觉模型。只要数据集够大,我们强大的模型就能学习到任何复杂的操作。那具体diffusion里面让unet学习了怎样一个操作呢?简单来说,就是“去噪”。
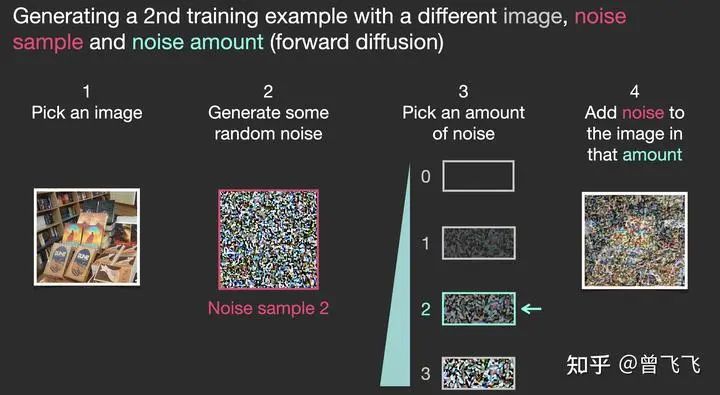
那如何为去噪的任务设计数据集呢?很简单,我们只要向普通的照片里添加噪声,不就有了加噪的图片了嘛。假定我们现在有一张金字塔的图片,我们用random函数生成从强到弱各个强度的噪声,比如下图中0~3共计4个强度的噪声。现在我们选定个某个强度的噪声,比如下图中选了噪声1,并且把这个噪声添加到图片里:

训练集如何制作:1,选张图片 2,生成从强到弱各个强度的噪声 3,从中选个噪声(比如强度1) 4,加到图片里
现在,我们就制作完成了训练集里面的一张图片。按照这样的操作,选一张图片,再选一种强度的噪声混合,我们还可以制作很多训练集。比如下面就选了图书馆的一张照片,混合了强度为2的噪声,创造了一个更模糊一点的训练样本:
上面仅仅作为一个简单的例子,所以噪声只设置了四个档位。实际上我们可以更细腻地划分噪声的等级,将其分为几十个甚至上百个档位,这样就可以创建出成千上万个训练集。比如我们现在噪声设置成100个档位,下面就展示了利用不同的档位结合不同的图片创建6张训练集的过程:
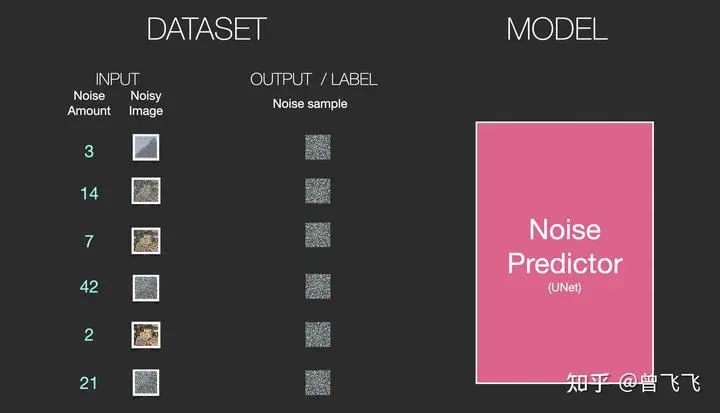
这样的话,一组训练集包括了三样东西:噪声强度(上图数字),加噪后的图片(上图左列图片),以及噪声图(上图右列图片)就可以了。训练的时候我们的unet只要在已知噪声强度的条件下,学习如何从加噪后的图片中计算出噪声图就可以了。注意,我们并不直接输出无噪声的原图,而是让unet去预测原图上所加过的噪声。当需要生成图片的时候,我们用加噪图减掉噪声就能恢复出原图了。
具体的一个训练过程就如下图所示,一共分四步走:
-
从训练集中选取一张加噪过的图片和噪声强度,比如下面的加噪街道图和噪声强度3。
-
输入unet,让unet预测噪声图,比如下图的unet prediction。
-
计算和真正的噪声图之间的误差
-
通过反向传播更新unet的参数。

那完成训练后,我们该如何生成图片呢?
二,Diffusion怎么生成图片
假设我们现在已经按照上面的步骤训练好了一个unet,这就意味着它就可以成功从一个加噪的图片中推断出噪声了。如下图中,知道噪声强度的情况下,给unet输入一张有噪图,unet就输出有噪图上面加过的噪声:
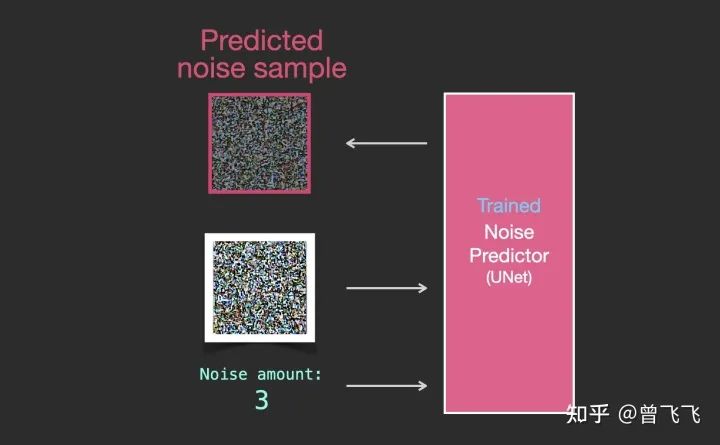
只要知道噪声强度,训练好的unet就可以成功推断出噪声
既然现在噪声图能够被推断出来,我们只要把加噪后的图片减去这个噪声图,就可以轻松得到一张略微去噪的图片了:
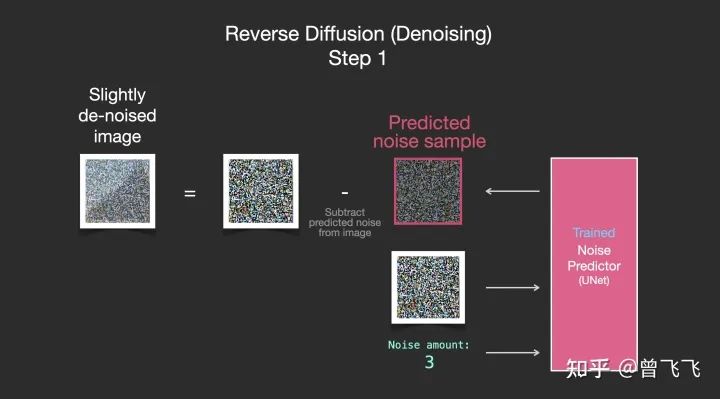
重复这个过程,预测噪声图,再减去噪声图,进行第二步去噪:
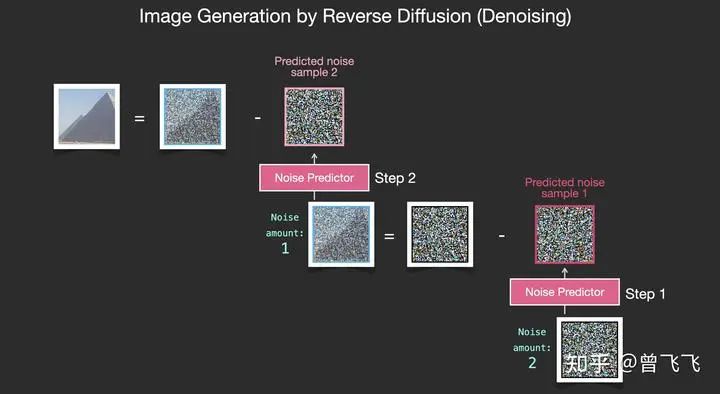
不断地重复这个过程,不断的去除一张噪声图片的噪声,最终我们就可以得到一张很棒的图片。这个图片是接近训练集分布的,它和训练集保有相同的像素规律。比如你用一个艺术家数据集去训练,它就会遵循美学的颜色分布,你用真实世界的训练集去训练,它的结果就会尽量遵循真实世界的规律。现在,你已经了解了Diffusion模型的基本规律了,这不仅仅适用于Stable Diffusion,也适用于OpenAI的Dall-E 2和Google的Imagen。
注意到上面这个过程中我们暂时还没有引入文字和语义向量的控制。也就是说,如果单纯的按照上面的流程走,我们可能能得到一些很炫酷的图片,但我们没有办法去控制最后的结果到底是什么。那如何引入文字控制呢?这就要使用语言模型和Attention机制来引入语义啦。
三、总结
-
Diffusion’s Training: 利用 **“噪声强度、噪声图、加噪后图片”**组成训练集,训练unet,使其学习如何从加噪后的图片推断出所加的噪声。
-
Diffusion’s Inference: 利用训练好的unet,从纯噪声中一步一步去噪,得到合理正常的图片。
零基础读懂Stable Diffusion(III):怎么控制
第二部分中我们着重讲述了如何训练Stable Diffusion中的unet,同时,也了解了在训练好unet之后怎么使用它来去除噪声以及生成图片。然而,还有一个重要的地方我们尚未提及,那就是可控性。我们如何用语言来控制最后生成的结果?答案也很简单——注意力机制。在第一部分中我们讲到,一个unet除了要接收噪声图之外,还要接受我们用Text Encoder预先提取的语义信息。那这个语义信息怎么在生成图片的过程中使用呢?我们直接使用注意力机制在unet内层层耦合即可。下图中每个黄色的小方块都代表一次注意力机制的使用,而每次使用注意力机制,就发生了一次图片信息和语义信息的耦合。每一个unet内部,这样的操作都会发生很多次很多次,直到最后一个unet为止,一直不断重复这耦合的过程。

有人可能就要问了,语义信息是语义信息,图片信息是图片信息,怎么能用attention耦合到一块呢?计算机怎么把这两种完全不同的信息联系到一起的呢?这就要说到我们这篇文章的主角——CLIP模型了。
一,CLIP模型介绍
自从2018年Bert发布以来,Transformer的语言模型就成了主流。Stable Diffusion起初的版本便是用的基于GPT的CLIP模型,而最近的2.x版本换成了更新更好的OpenCLIP。语言模型的选择直接决定了语义信息的优良与否,而语义信息的好坏又会影响到最后图片的多样性和可控性。Google在Imagen论文中做过实验,可以发现不同语言模型对生成结果的影响是相当大的。

那像CLIP这样的语言模型究竟是怎么训练出来的呢?它们是怎么样做到结合人类语言和计算机视觉的呢?接下来我们就来好好了解一下。
首先,要训练一个结合人类语言和计算机视觉的模型,我们就必须有一个结合人类语言和计算机视觉的数据集。CLIP就是在像下面这样的数据集上训练的,只不过图片数据达到了可怕的4亿张而已。事实上,这些数据都是从网上爬取下来的,同时被爬取下来的还有它们的标签或者注释。

CLIP模型包含一个图片Encoder和一个文字Encoder。训练过程可以这么理解:我们先从训练集中随机取出一张图片和一段文字。注意,文字和图片未必是匹配的,CLIP模型的任务就是预测图文是否匹配,从而展开训练。在随机取出文字和图片后,我们再用图片Encoder和文字Encoder分别压缩成两个embedding向量,称之为图片embedding和文字embedding【下图两个蓝色3*1向量】。
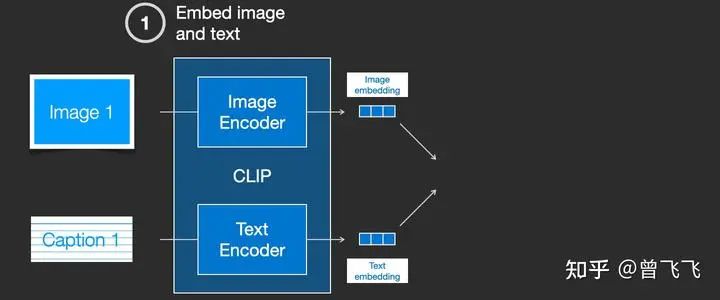
然后我们用余弦相似度来比较两个embedding向量的相似性,以判断我们随机抽取的文字和图片是否匹配。一开始的时候,就算图片和文字配对的很好,但由于我们的两个Encoder刚刚初始化,参数都是混乱的,因此两个embedding向量一定也是混乱的,计算出来的相似度往往会接近于0。这就会出现下图这种状况,明明图文是一对,他们的label是similar,但是余弦相似度算出来的prediction却是not similar:

这个时候,标签(similar)和预测结果(not similar)不匹配,我们就根据这个结果去反向更新两个Encoder的参数:
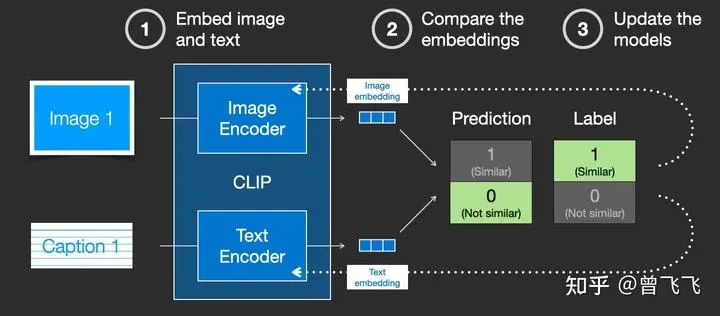
不断地重复这个反向传播的过程,我们就能够训练好两个Encoder。对于配对的图片和文字,这两个Encoder最后就可以输出相似的embedding向量,计算余弦相似度就可以得到接近1的结果。而对于不匹配的图片和文字,这两个Encoder就会输出很不一样的embedding向量,使得余弦相似度计算出来接近0. 这个时候,你给CLIP一张小狗的图片,同时再给出文字描述:“小狗照片”,CLIP模型就会生成两个相似的embedding向量,从而判断出文字和图片是匹配的。这个时候,计算机视觉和人类语言这两个原本不相干的信息就通过CLIP联系到了一块,二者就拥有了统一的数学表示了。你可以将文字通过一个Text Encoder转换成图片信息,也可以将文字通过Image Encoder转换成语言信息,二者就能够相互作用了。这也是Diffusion模型中可以通过文字生图片的秘密所在。
值得注意的是,就像经典的word2vec训练时一样,训练CLIP时不仅仅要选择匹配的图文来训练,还要适当选择完全不匹配的图文给机器识别,作为负样本来平衡正样本的数量。
二,给图片注入语义
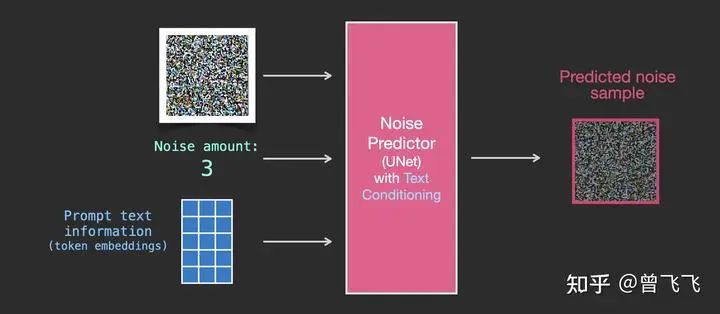
有了训练好的CLIP模型,我们就获得了一个完美的工具,用来联系语义信息和计算机视觉信息了。那如何利用CLIP模型呢?一个很直白的思路就是,对于一段描述文字,我们先用CLIP的Text Encoder去压缩成embedding向量。在unet的去噪过程中,我们就不断地用attention机制给去噪的过程注入这个embedding向量,就可以不断注入语义信息了。
回忆一下,在第二部分中,我们介绍了没有语义信息时unet的输入输出情况。大概就是下图这个样子,输入是噪声强度和加噪图,输出是加噪图上所加的噪声。
现在有了语义的embedding向量,稍作修改之后,我们就有了新的输入输出关系图。语义embedding向量在下图中表示为蓝色3*5的方格:
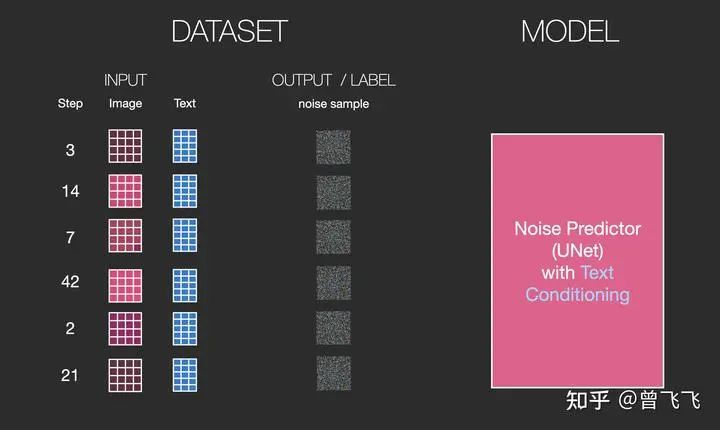
训练的数据集也添加了文字的数据对,现在输入变成了噪声强度+加噪图+文字:
要更清楚的知道语义向量是这么作用于这个过程中的,我们必须更深入的了解一下Unet里面是怎么工作的。
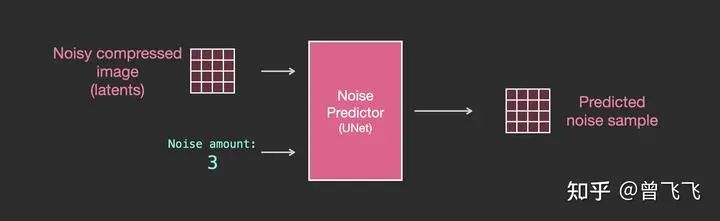
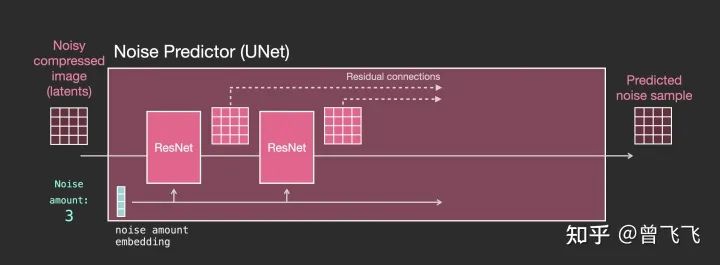
1,没有文字时的Unet
首先,没有文字的时候,unet宏观的工作模式我们已经很清楚了。unet的输入是加噪图和噪声强度,输出是加噪图上所加的噪声:
然后,当我们要更细致的了解unet里面到底是什么样的时候,就可以把上图中代表unet的小粉块放大来看。如下图所示,整个unet内部的流程特点如下
-
整个unet是由一系列Resnet构成的。
-
每一层的输入都是上一层的输出。
-
一些输出用residual connection直接跳跃到后面去,如下图中的虚线,这种residual+skip的操作也是很经典的unet思想。
-
噪声强度被转换成一个embedding向量,输入到每一个子的Resnet里面。这也是噪声强度能控制unet的底层原理所在。
2,有文字时的Unet
了解了没有文字时的unet是怎么工作的之后,接下来我们就要加入文字的处理了。首先,还是看宏观的输入输出,相比上面额外添加了文字embedding作为输入【下图蓝色3*5】:

我们再细看一下粉色的unet模块里到底发生了什么。如下图所示,每个Resnet不再和相邻的Resnet直接连接,而是在中间新增了Attention的模块。CLIP Encoder得到的语义embedding就用这个Attention模块来处理。
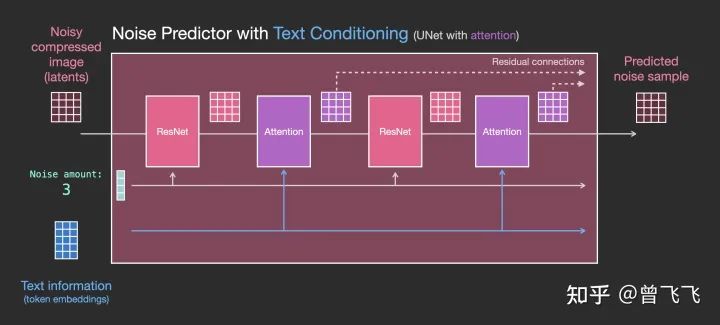
注意到,Resnet模块并不直接以文字作为输入,而是使用了Attention作为后处理模块。现在Unet就可以通过这一方式成功利用CLIP的语义信息了。就此,我们也就能成功完成文生图的任务。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

相关文章:
零基础读懂Stable Diffusion!
前言 一文搞懂Stable Diffusion是什么,怎么训练和使用,语义信息影响生成图片的过程。>>[][加入极市CV技术交流群,走在计算机视觉的最前沿] 前几个月AIGC可谓是大热了一把,各种高质量的生成图片层出不穷,而其中…...

Hash Join 和 Index Join工作原理和性能差异
在数据库查询中,Hash Join 和 Index Join 是两种常见的表连接策略。了解它们的工作原理和性能差异有助于设计高效的数据库查询。我们可以使用 Java 模拟这两种不同的连接方式,并进行性能对比。 1. Hash Join 和 Index Join 的概念: Hash Joi…...

Apifox简介及使用
Apifox 是一款集 API文档管理、接口调试、接口自动化测试 和 Mock 功能于一体的全功能工具,旨在为开发者和测试人员提供一个高效的一站式解决方案。它融合了 Postman、Swagger、JMeter 等工具的优势,能够极大地提升团队协作和 API 开发的效率。 在实际开…...
)
十、IPD 实施细节(产品设计与开发管理)
产品设计与开发管理 产品设计与开发管理是IPD(集成产品开发)实施过程中的核心环节。它确保从概念设计到最终产品的实现能够按照预定的质量、成本、进度目标顺利完成,并与市场需求、技术发展及企业战略保持一致。IPD强调产品设计与开发管理过程中跨职能团队的协作、流程的系…...

MySQL-13.DQL-聚合函数
一.DQL-分组查询 二.聚合函数 -- DQL:分组查询 -- 聚合函数 -- 1.统计该企业员工数量 count select count(id) from tb_emp; select count(job) from tb_emp;select count(A) from tb_emp; select count(*) from tb_emp;-- 2.统计该企业最早入职的员工 min select min(entr…...

为什么跟别人学习如何证明定理要远比使用定理更有意义
目录 背景 为什么跟别人学习 什么是高人,如何判断 高人定义 如何判断一个人的能力? 如何考量一个人的成就? 只知道使用定理的局限性 1. 缺乏灵活性和适应性 2. 无法创新或拓展新方法 3. 容易误用或误解定理 4. 难以推理和分析复杂问…...

Qt在Win,Mac和Linux的开机自启设置
Windows Windows 使用注册表来管理开机自启的应用程序。 void runWithSystem(const QString& name, const QString& path, bool autoRun) {QSetting reg("HKEY_LOCAL_MACHINE\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Run", QSetting::NativeForma…...

spring boot热部署
使用热部署解决了每次都需要重新启动的问题,但不过热部署的在对于改动比较小时速度可能快一些,改动大的话尽量停止 1.使用热部署之前需要在pom.xml文件中导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifa…...

网关与蓝牙网关有什么不同之处?
尽管蓝牙网关也属于网关的一种,但在实际应用和功能特性上,它们之间存在着显著的差异。接下来,我们将深入探讨蓝牙网关的独特之处,并与传统网关进行对比分析。 一、网关与蓝牙网关的共同之处 一对多配对能力:无论是网关…...

JAVA计算双十一多产品实付款优惠券的省钱方案
为了计算双十一期间多产品使用优惠券后的实付款省钱方案,我们需要一个更复杂的逻辑来处理优惠券的应用和叠加规则。以下是一个简化的Java示例,用于展示如何计算多种优惠券应用于多个产品后的实付款金额,并找出最省钱的方案。 首先࿰…...

零售行业的数字化营销转型之路
一方面,市场竞争激烈,电商平台、新兴品牌和跨界对手带来巨大压力。另一方面,消费者需求变化迅速,更加追求个性化、多元化和便捷化的购物体验,同时传统零售企业还面临着高成本压力,如租金、人力和库存等。 然…...

js的for in 和 for of的详解
for...in 和 for...of 是 JavaScript 中的两种循环结构,它们用于不同的场景,适用于不同的数据类型。下面将详细介绍它们的用法、区别以及适用场景。 1. for...in 循环 for...in 用于遍历对象的可枚举属性(包括继承的属性)。 语…...

前端工具函数库
流行的前端工具函数库 lodashlodash-es:用lodash-es代替lodashes-toolkit:https://www.npmjs.com/package/es-toolkitradash:https://github.com/sodiray/radash 补充信息: antd-mobile 已不再依赖 lodash, 淘汰 lo…...

Java程序设计:Spring boot(4)——Freemarker Thymeleaf视图技术集成
1 Freemarker 视图集成 SpringBoot 内部⽀持 Freemarker 视图技术的集成,并提供了⾃动化配置类 FreeMarkerAuto Configuration,借助⾃动化配置可以很⽅便的集成 Freemarker基础到 SpringBoot 环境中。这⾥借助⼊⻔项⽬引⼊ Freemarker 环境配置。 Start…...

JavaScript 第19章:Web Storage
在JavaScript中,Web存储(Web Storage)提供了一种在用户浏览器中持久化数据的方式。这里我们会探讨localStorage、sessionStorage以及IndexedDB,并提供一些简单的示例代码来展示它们的用法。 localStorage localStorage允许你在用…...

[山河2024] week2
官方WP出得很快。对照官的写下私的。大概出入不大,毕竟第2周。后边的才难。 Crypto E&R RSA因子分解题,把q的2进制反转后与p异或。关于异或的题很多,这个还真是头一回见,不过爆破方法还是一样的。 r_q int(bin(q)[2:][::…...

无限可能LangChain——开启大模型世界
什么是大语言模型? 大语言模型是一种人工智能模型,通常使用深度学习技术(如神经网络)来理解和生成人类语言。这些模型拥有非常多的参数,可以达到数十亿甚至更多,使得它们能够处理高度复杂的语言模式。 我…...
URL路径以及Tomcat本身引入的jar包会导致的 SpringMVC项目 404问题、Tomcat调试日志的开启及总结
一、URL路径导致的 SpringMVC项目 404问题 SpringMVC项目的各项代码都没有问题,但是在页面请求时仍然显示404,编译的时候报了下面的问题: org.apache.jasper.servlet.TldScanner.scanJars 至少有一个JAR被扫描用于TLD但尚未包含TLD。 为此记录…...

如何引起Java中的System.in.read()函数的异常
演示的为:关闭标准输入流System.in后再调用System.in.read就会报出IOException import java.io.IOException; import java.io.InputStream;public class Test {public static void main(String[] args) {InputStream in System.in;try {in.close();System.in.read();}catch (…...

深入理解Flutter鸿蒙next版本 中的Widget继承:使用extends获取数据与父类约束
目录 写在前面 什么是Widget继承? 基本概念 StatelessWidget与StatefulWidget build方法 创建自定义Widget 1. 继承StatelessWidget 2. 继承StatefulWidget并访问父类的约束 3. 继承其他自定义Widget并获取数据 写在最后 写在前面 在Flutter中,…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...