【Kafka】Kafka源码解析之producer过程解读
从本篇开始 打算用三篇文章 分别介绍下Producer生产消费,Consumer消费消息 以及Spring是如何集成Kafka 三部分,致于对于Broker的源码解析,因为是scala语言写的,暂时不打算进行学习分享。
总体介绍

- clients : 保存的是Kafka客户端代码,主要就是生产者和消费者代码
- config:保存Kafka的配置文件,其中比较重要的配置文件是server.properties。
- connect目录:保存Connect组件的源代码。我在开篇词里提到过,Kafka Connect组件是用来实现Kafka与外部系统之间的实时数据传输的。
- core目录:保存Broker端代码。Kafka服务器端代码全部保存在该目录下。
而一条消息的整体流转过程其实就是经过三部分,也就是Producer\Broker\Consumer。
因为是对主要核心流程的分析,所以只会截核心代码。具体后面细节,在说。

producer整体流程
对于Producer来说,其实就是几部分。
- 初始化、发送流程、缓冲区
初始化流程
设置分区器
// 设置分区器this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG,Partitioner.class,Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
设置重试时间,默认100ms,如果配置Kafka可以重试,retries制定重试次数,retryBackoffMs指定重试的间隔
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
获取Key和Value的序列化器
// 序列化器if (keySerializer == null) {this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,Serializer.class);this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);} else {config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);this.keySerializer = keySerializer;}if (valueSerializer == null) {this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,Serializer.class);this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);} else {config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);this.valueSerializer = valueSerializer;}
拦截器
// 设置拦截器List<ProducerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,ProducerInterceptor.class,Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));if (interceptors != null)this.interceptors = interceptors;elsethis.interceptors = new ProducerInterceptors<>(interceptorList);
其他参数
// 设置最大消息为多大,默认是1M 默认是16384this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);// 设置缓存大小 默认是32M 默认是33554432 RecordAccumulator=32MBthis.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);// 设置压缩类型 可以提升性能this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));this.accumulator = new RecordAccumulator(logContext, // 因为是通过缓冲区发送消息的,所以需要消息累计器RecordAccumulator.PartitionerConfig partitionerConfig = new RecordAccumulator.PartitionerConfig(enableAdaptivePartitioning,config.getLong(ProducerConfig.PARTITIONER_AVAILABILITY_TIMEOUT_MS_CONFIG));
初始化元数据
// 初始化集群元数据if (metadata != null) {this.metadata = metadata;} else {this.metadata = new ProducerMetadata(retryBackoffMs,config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),logContext,clusterResourceListeners,Time.SYSTEM);this.metadata.bootstrap(addresses);}
创建Sender线程,其中包含一个重要的网络组件NetWorkClient
// 创建sender线程this.sender = newSender(logContext, kafkaClient, this.metadata);// 线程nameString ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;// 封装起来 设置为守护线程 并启动this.ioThread = new KafkaThread(ioThreadName, this.sender, true);// 线程启动this.ioThread.start();
发送消息流程
发送消息的过程
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {// 执行拦截器逻辑ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);return doSend(interceptedRecord, callback);}
先执行拦截器,可以发现就是遍历拦截器,然后执行对应的onSend()方法。当我们想增加一个拦截器,直接实现对应的接口,重写onSend()方法,然后Kafka就会调用我们的onSend方法。通过提供一个拓展点进行使用。
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {ProducerRecord<K, V> interceptRecord = record;for (ProducerInterceptor<K, V> interceptor : this.interceptors) {try {interceptRecord = interceptor.onSend(interceptRecord);} catch (Exception e) {}}return interceptRecord;}
从Kafka Broker集群获取元数据metadata
// 从broker获取元数据clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
对key和value进行序列化,调用对应的serialize的方法。
byte[] serializedKey;try {// 选择对应的序列化进行操作serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());} catch (ClassCastException cce) {}byte[] serializedValue;try {serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());} catch (ClassCastException cce) {}
// 选择具体的分区int partition = partition(record, serializedKey, serializedValue, cluster);// 消息缓存到RecoredAccumulatorresult = accumulator.append(record.topic(), partition, timestamp, serializedKey,serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);// 消息发送的条件// 缓冲区数据大小达到batch.size 或者linnger.ms达到上限后 唤醒sneder线程。if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());this.sender.wakeup();}
Sender线程
runOnce();long pollTimeout = sendProducerData(currentTimeMs);


缓冲区、

这篇讲解很详细 https://www.cnblogs.com/rwxwsblog/p/14754810.html
生产者核心参数配置
bootstrap.servers:连接Broker配置,一般就是xxxx:9092
key.serializer 和 value.serializer:对key和value进行序列化器,可以自定义,一般就是String方式
buffer.memory:RecordAccumulator 缓冲区总大小,默认32m。
batch.size: 消息会以batch的方式进行发送,这是一批数据的大小 默认是16K
linger.ms:发送消息的时机,如果没有达到batch.size or linger.ms的时间就会发送 默认是0ms 立即发送
acks: 0: 不落盘 1:只有leader落盘 -1(all) : leader和所有从节点持久化成功 默认是-1
max.in.flight.requests.per.connection:允许最多没有返回 ack 的次数,默认为 5
retries: 消息发送失败时,系统重发消息 默认值 2147483647
retry.backoff.ms:两次重试间隔 默认是100ms
enable.idempotence: 开启幂等性 默认true
compression.type: 压缩格式 默认是none
相关文章:
【Kafka】Kafka源码解析之producer过程解读
从本篇开始 打算用三篇文章 分别介绍下Producer生产消费,Consumer消费消息 以及Spring是如何集成Kafka 三部分,致于对于Broker的源码解析,因为是scala语言写的,暂时不打算进行学习分享。 总体介绍 clients : 保存的是Kafka客户端…...

深度学习笔记20_数据增强
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 一、我的环境 1.语言环境:Python 3.9 2.编译器:Pycharm 3.深度学习环境:TensorFlow 2.10.0 二、GPU设置…...

模板变量与php变量对比做判断
${item.create_name}如何与php变量对比 在PHP中,您可以通过将字符串内嵌到双引号中来将模板变量 ${item.create_name} 与PHP变量进行对比。如果您有一个PHP变量 $phpVariable 并且想要检查它是否与 ${item.create_name} 相同,您可以使用 str_replace 函…...

C语言 | Leetcode C语言题解之第485题最大连续1的个数
题目: 题解: int findMaxConsecutiveOnes(int* nums, int numsSize) {int maxCount 0, count 0;for (int i 0; i < numsSize; i) {if (nums[i] 1) {count;} else {maxCount fmax(maxCount, count);count 0;}}maxCount fmax(maxCount, count);…...

C语言复习概要(六)
公主请阅 1. 深入理解数组与指针在C语言中的应用1.1 数组名的理解 2. 使用指针访问数组3. 一维数组传参的本质4. 冒泡排序的实现5. 二级指针6. 指针数组7. 指针数组模拟二维数组8.总结 1. 深入理解数组与指针在C语言中的应用 数组与指针是C语言的核心概念之一,理解…...

PyQt 入门教程(2)搭建开发环境
文章目录 一、搭建开发环境1、安装PyQt5与pyqt5-tools2、配置QtDesigner3、配置Pyuic4、配置Pyrcc 一、搭建开发环境 1、安装PyQt5与pyqt5-tools PyQt5: PyQt的开发库。Pyqt5-tools: 它是一个包含多种工具的工具包,旨在帮助开发者更方便地使…...

Flink Kubernetes Operator
Flink Kubernetes Operator是一个用于在Kubernetes集群上管理Apache Flink应用的工具。 一、基本概念 Flink Kubernetes Operator允许用户通过Kubernetes的原生工具(如kubectl)来管理Flink应用程序及其生命周期。它简化了Flink应用在Kubernetes集群上的…...

【最新华为OD机试E卷-支持在线评测】字符统计及重排(100分)多语言题解-(Python/C/JavaScript/Java/Cpp)
🍭 大家好这里是春秋招笔试突围 ,一枚热爱算法的程序员 💻 ACM金牌🏅️团队 | 大厂实习经历 | 多年算法竞赛经历 ✨ 本系列打算持续跟新华为OD-E/D卷的多语言AC题解 🧩 大部分包含 Python / C / Javascript / Java / Cpp 多语言代码 👏 感谢大家的订阅➕ 和 喜欢�…...

springboot使用GDAL获取tif文件的缩略图并转为base64
springboot使用GDAL获取tif文件的缩略图并转为base64 首先需要安装gdal:https://blog.csdn.net/qq_61950936/article/details/142880279?spm1001.2014.3001.5501 然后是配置pom.xml文件: <!--处理缩略图的--><dependency><groupId>o…...

Pytorch——pip下载安装pytorch慢的解决办法
一、找到需要下载的pytorch链接 运行:pip install torch1.11.0cu113 torchvision0.12.0cu113 torchaudio0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113。然后得到: 我这里为:https://download.pytorch.org/whl/cu113/t…...

uniapp微信小程序调用百度OCR
uniapp编写微信小程序调用百度OCR 公司有一个识别行驶证需求,调用百度ocr识别 使用了image-tools这个插件,因为百度ocr接口用图片的base64 这里只是简单演示,accesstoken获取接口还是要放在服务器端,不然就暴露了自己的百度项目k…...

Vue3+TS项目---实用的复杂类型定义总结
namespace 概念 在TypeScript中,namespace是一种用于组织代码得结构,主要用于将相关得功能(例如类、接口、函数等)组合在一起。它可以帮助避免命名冲突,尤其是在大项目中。 用法 1.定义命名空间 使用namespace关键…...

尚硅谷rabbitmq2024 工作模式路由篇 第11节 答疑
String exchangeName "test_direct"; /! 创建交换机 人图全 channel.exchangeDeclare(exchangeName,BuiltinExchangeType.DIREcT, b: true, b1: false, b2: false, map: null); /1 创建队列 String queue1Name "test_direct_queue1"; String queue2Name &q…...

HTTP vs WebSocket
本文将对比介绍HTTP 和 WebSocket ! 相关文章: 1.HTTP 详解 2.WebSocket 详解 一、HTTP:请求/响应的主流协议 HTTP(超文本传输协议)是用于发送和接收网页数据的标准协议。它最早于1991年由Tim Berners-Lee提出来&…...

R语言医学数据分析实践-数据读写
【图书推荐】《R语言医学数据分析实践》-CSDN博客 《R语言医学数据分析实践 李丹 宋立桓 蔡伟祺 清华大学出版社9787302673484》【摘要 书评 试读】- 京东图书 (jd.com) R语言编程_夏天又到了的博客-CSDN博客 R编程环境的搭建-CSDN博客 在分析公共卫生数据时,数…...

JavaWeb环境下Spring Boot在线考试系统的优化策略
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了基于JavaWeb技术的在线考试系统设计与实现的开发全过程。通过分析基于Java Web技术的在线考试系统设计与实现管理的不足,创建了一个计算机管理基于Ja…...
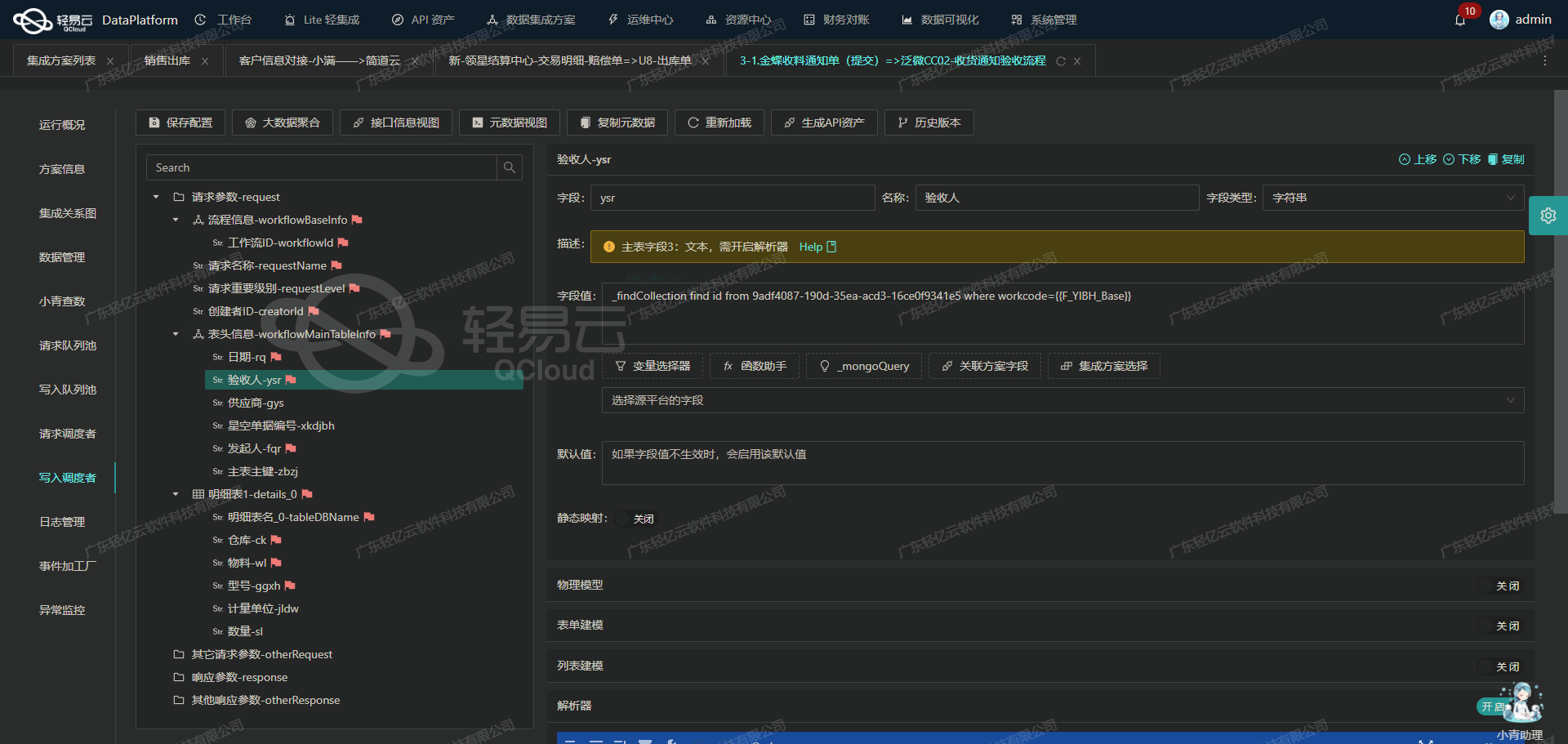
ETL技术在金蝶云星空与旺店通WMS集成中的应用
金蝶云星空数据集成到旺店通WMS的技术案例分享 在数字化转型的背景下,现代企业对系统间的数据集成需求日益增加。本篇文章将以“组装入库>其他入库单-1”方案为例,详细解析如何通过轻易云数据集成平台,实现金蝶云星空与旺店通WMS之间的数…...

【力扣热题100】3194. 最小元素和最大元素的最小平均值【Java】
题目:3194.最小元素和最大元素的最小平均值 你有一个初始为空的浮点数数组 averages。另给你一个包含 n 个整数的数组 nums,其中 n 为偶数。 你需要重复以下步骤 n / 2 次: 从 nums 中移除 最小 的元素 minElement 和 最大 的元素 maxElement…...

机器学习拟合过程
import numpy as np import matplotlib.pyplot as plt# 步骤1: 生成模拟数据 np.random.seed(0) X 2 * np.random.rand(100, 1) y 4 3 * X 2 * X**2 np.random.randn(100, 1)# 步骤2: 定义线性模型 (我们从随机权重开始) w np.random.randn(2, 1) b np.random.randn(1)#…...
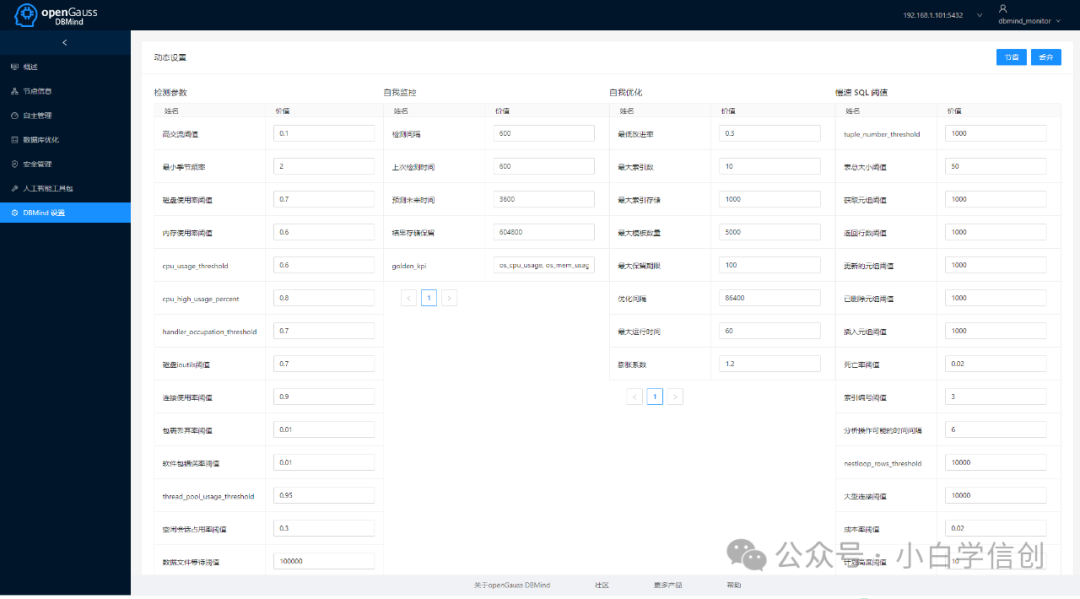
如何快速部署一套智能化openGauss测试环境
一、openGauss介绍 openGauss是一款开源关系型数据库管理系统,采用木兰宽松许可证v2发行,允许用户自由地复制、使用、修改和分发软件。openGauss内核深度融合了华为在数据库领域多年的研发经验,结合企业级场景需求,持续构建竞争力…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南
NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer NBTExplorer是一款面向Minecraft数据管理的…...