LLAMA2入门(一)-----预训练
Llama 2 是预训练和微调的LLM系列,Llama 2 和 Llama 2-Chat 模型的参数规模达到 70B。Llama 2-Chat 模型专门为对话场景进行了优化。
这是一个系列的文章,会分别从LLAMA2的预训练,微调,安全性等方面进行讲解。
1.数据来源
- 数据集:LLaMA 2 的训练数据来源于公开可用的数据集,并未使用来自 Meta 产品或服务的数据。为了避免隐私泄露,数据集中剔除了来自某些网站的高风险个人信息。
- 数据量:模型共预训练了 2 万亿个 token,比 LLaMA 1 增加了约 40%。同时,数据集上调了最具事实性的来源,以提升模型知识储备,减少幻觉(hallucination)的发生。
- 去重和清洗:数据经过了更严格的清洗和去重处理,旨在提供更干净且更具代表性的数据集。
2.训练细节
模型架构
LLaMA 2 使用了标准的 Transformer 架构(Vaswani et al., 2017),并基于 LLaMA 1 进行了优化,包括使用预归一化(pre-normalization)RMSNorm、SwiGLU 激活函数(Shazeer, 2020)以及旋转位置嵌入(RoPE, Su et al. 2022)。这些优化提升了模型处理长上下文的能力。
(1) 基础架构
- LLaMA 2 使用的是自回归语言模型(Auto-regressive Language Model),这意味着模型是通过预测每个词在给定上下文中的下一个词来进行训练的。
- 标准的 Transformer 架构:模型使用经典的 Transformer 架构 ,最初由 Vaswani 等人提出,这是一种基于自注意力机制的架构,能够处理长距离依赖关系并捕捉句子中的语义结构。
- 归一化层:LLaMA 2 采用了预归一化策略(Pre-normalization),具体使用了 RMSNorm 来替代传统的 LayerNorm。这使得模型的训练更为稳定,尤其是在处理深层网络时。
(2) 改进的激活函数
LLaMA 2 使用了 SwiGLU 激活函数,而不是传统的 ReLU 或 GeLU。SwiGLU 是一种更复杂的非线性激活函数,能够提高模型的表现,特别是在大规模模型中 。
为什么要使用SwiGLU激活函数?
SwiGLU 的公式如下:
S w i G L U ( x ) = ( L i n e a r ( x ) ⋅ S i L U ( L i n e a r ( x ) ) ) SwiGLU(x)=(Linear(x)⋅SiLU(Linear(x))) SwiGLU(x)=(Linear(x)⋅SiLU(Linear(x)))
其中,SiLU(Sigmoid Linear Unit)是一个常用的非线性激活函数,定义为:
S i L U ( x ) = x ⋅ σ ( x ) SiLU(x)=x⋅σ(x) SiLU(x)=x⋅σ(x)
其中 σ ( x ) σ(x) σ(x) 是 Sigmoid 函数 1 1 + e − x \frac{1}{1+e^{−x}} 1+e−x1
因此,SwiGLU 实际上是对输入进行了两次线性变换,并通过 SiLU 将两个结果结合起来,这种组合使得模型可以捕获更丰富的特征表示。
-
SwiGLU有更高的表达能力
SwiGLU 通过双线性变换和 SiLU 非线性结合,提供了更强的表达能力。具体体现在:
- 非线性表现更强:SwiGLU 在输入空间上提供了更复杂的非线性映射,能够捕获数据中更加复杂的模式。相比于传统的 ReLU,它避免了“梯度消失”或“梯度爆炸”的问题,同时也比 GeLU 更能灵活地处理不同输入。
- 激活函数的平滑性:SiLU 是一种平滑的激活函数,这意味着它在小输入值附近表现平稳,输出变化相对缓和。与 ReLU 不同,SiLU 不会像 ReLU 那样在负数部分输出恒为零,这有助于模型更好地处理负值输入,从而提高训练稳定性。
-
计算效率更高
虽然 SwiGLU 包含了两次线性变换,但由于它与 SiLU 激活函数结合,SwiGLU 可以充分利用并行计算硬件(如 GPU 和 TPU)来高效执行。因此,它相比于一些复杂的非线性函数(如 ReLU 或 Tanh)在计算开销上并没有显著增加,同时提升了模型的性能。
-
更好的梯度流动
SwiGLU 结合了 SiLU 的平滑性和双线性变换的组合,使得它能够在梯度反向传播时提供更好的梯度流动,这尤其在深层网络中表现出色。在 LLaMA 2 这样的大规模 Transformer 模型中,模型层数很多,使用 SwiGLU 可以有效地缓解梯度消失问题,确保模型能够在训练过程中更好地学习到深层次的特征。
(3)位置嵌入
旋转位置嵌入(RoPE):LLaMA 2 使用了旋转位置嵌入(Rotary Positional Embeddings, RoPE),这是一种改进的相对位置编码方式,能够处理更长的上下文信息,并提高模型在长文本上的性能 。
-
位置编码的重要性
Transformer 模型本质上是不具备顺序感的,因为它们并没有卷积或递归结构,而是通过自注意力机制(Self-Attention)在序列中的所有词之间计算注意力权重。因此,在处理语言任务时,必须显式地告诉模型每个词在序列中的位置,以便模型能够理解句子中的词序。
传统的 Transformer 使用绝对位置编码(Absolute Positional Encoding),这意味着每个位置(token)的信息是通过一个固定的向量表示,该向量在训练开始时被注入到输入中。然而,绝对位置编码无法很好地建模词与词之间的相对位置关系,特别是当序列长度增加时,绝对位置编码的表现会下降。
-
RoPE的核心思想
旋转位置嵌入(RoPE) 通过引入旋转操作来嵌入相对位置信息。它通过对输入的查询和键(Query 和 Key)向量进行逐元素的旋转变换,将位置信息嵌入到自注意力机制的计算中,从而保留了序列中词之间的相对位置。
RoPE 的核心思想是将每个 token 的查询和键向量按照其位置进行旋转,而这种旋转是连续的,能够保持词与词之间的相对距离信息。这意味着,相比于绝对位置编码,RoPE 不需要依赖固定的位置编码表格,而是通过对向量进行旋转操作来隐式地表示相对位置。
RoPE 的数学定义如下:
旋转变换
给定二维向量 [ x 1 , x 2 ] [x1,x2] [x1,x2],我们可以定义它的旋转变换为:
[ x 1 ′ x 2 ′ ] = [ cos ( θ ) − sin ( θ ) sin ( θ ) cos ( θ ) ] [ x 1 x 2 ] \begin{bmatrix} x'_1 \\ x'_2 \end{bmatrix} =\begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} [x1′x2′]=[cos(θ)sin(θ)−sin(θ)cos(θ)][x1x2]
在 RoPE 中,这种旋转操作会应用到高维向量的每对相邻维度上(如第 1 维和第 2 维,第 3 维和第 4 维),每对维度的旋转角度由位置和频率确定。具体来说,RoPE 对每个位置 ppp 以逐维不同的频率来进行旋转变换,确保较低维度捕捉较短距离的依赖,较高维度捕捉较长距离的依赖。
相对位置优势
这种基于旋转的位置编码能够隐式地表示相对位置。RoPE 的一个关键优势在于,经过旋转编码后,两个位置 p p p 和 p + k p+k p+k 的旋转向量之间的差异只取决于相对位置 k k k,而不是绝对位置。这意味着即使文本序列长度增加,RoPE 也能保持相对位置的关系,使其更具泛化能力,特别是在长文本处理上表现优异。
-
RoPE的具体实现步骤
RoPE 的实现涉及以下几个步骤:
- 输入处理:输入的查询向量 q q q 和键向量 k 是没有位置信息的高维向量。
- 位置嵌入:对每个位置 p p p 的查询和键向量,按照位置 p p p 对查询 q q q 和键 k k k 的偶数维和奇数维进行不同的旋转嵌入。
- 自注意力机制计算:经过旋转嵌入后,查询和键向量会进入自注意力机制进行打分计算,这个过程中,自然地引入了位置相关性和相对位置偏置。
- 输出生成:自注意力机制根据注意力权重生成新的向量表示,传递到后续的 Transformer 层。
-
RoPE 相比传统位置编码的优势
1. 处理长序列的能力
RoPE 的设计使其可以扩展到更长的序列而不会丢失位置信息。传统的绝对位置编码在序列长度超过训练时的长度后,模型的表现会显著下降,因为位置编码无法很好地泛化。而 RoPE 通过旋转方式嵌入相对位置,具备良好的泛化能力,适用于长序列文本处理。
2. 相对位置建模
RoPE 的另一个显著优势是相对位置编码。对于许多 NLP 任务,词与词之间的相对距离往往比绝对位置更为重要。例如,在机器翻译或长文本生成任务中,模型必须理解词语之间的相对关系,而不仅仅是它们的固定位置。
3. 计算效率
RoPE 的旋转计算相对简单,能够高效地并行化计算。相较于需要额外层次处理的相对位置编码方案(如 Transformer-XL 中的相对位置编码),RoPE 在引入相对位置偏置的同时,保持了自注意力机制的计算效率。
-
具体使用例子
给定一个查询向量 qqq 或键向量 kkk,我们通过以下旋转公式将位置信息嵌入:
RoPE ( q 2 i , q 2 i + 1 ) = [ cos ( θ p ) − sin ( θ p ) sin ( θ p ) cos ( θ p ) ] [ q 2 i q 2 i + 1 ] \text{RoPE}(q_{2i}, q_{2i+1}) = \begin{bmatrix} \cos(\theta_p) & -\sin(\theta_p) \\ \sin(\theta_p) & \cos(\theta_p) \end{bmatrix} \begin{bmatrix} q_{2i} \\ q_{2i+1} \end{bmatrix} RoPE(q2i,q2i+1)=[cos(θp)sin(θp)−sin(θp)cos(θp)][q2iq2i+1]
这里:- q 2 i q_{2i} q2i和 q 2 i + 1 q_{2i+1} q2i+1分别是查询向量 q q q 的第 2 i 2i 2i 和第 2 i + 1 2i+1 2i+1 维。
- θ p = p ⋅ θ \theta_{p}=p·\theta θp=p⋅θ是与位置 p p p 相关的旋转角度,通常设定为与维度相关的常数(如 θ = 1000 0 − 2 i d \theta=10000^{\frac{-2i}{d}} θ=10000d−2i,其中 d d d是查询向量的维度)
- 这个变换将每对相邻维度 ( 2 i , 2 i + 1 ) (2i,2i+1) (2i,2i+1)旋转一个与位置 p p p 相关的角度。
注意力机制的改进
引入了分组查询注意力机制(Grouped-Query Attention, GQA),特别是用于处理参数规模较大的模型(例如 34B 和 70B)。这一改进提升了推理的可扩展性,降低了注意力计算时的内存消耗。
查询注意力机制(Grouped-Query Attention, GQA) 是 LLaMA 2 模型中引入的一种优化注意力计算的机制,特别是在处理大规模模型(如 34B 和 70B 参数模型)时,GQA 大幅减少了注意力计算的内存开销,并提高了模型的推理效率。
为了理解 GQA,首先需要了解传统的多头自注意力机制(Multi-Head Self-Attention, MHA),然后我们会介绍 GQA 是如何改进 MHA 的。
回顾多头自注意力机制(MHA)
在传统的多头自注意力机制中,自注意力计算分为多个“头”(attention heads)。每个注意力头会为输入序列生成查询(Query, Q)、键(Key, K)和值(Value, V),并分别进行自注意力计算。具体流程如下:
-
线性投影:每个输入向量(token embedding)会通过线性投影生成对应的 Q、K、V 向量。这意味着每个注意力头有自己独立的线性投影矩阵。
-
注意力计算:每个头都会独立地进行注意力计算,计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dkQKT)V
其中 Q Q Q 是查询, K K K 是键, V V V 是值, d k d_k dk 是键向量的维度。 -
多头组合:所有注意力头的输出会被拼接起来,经过一个线性变换后,生成最后的输出。
传统的 MHA 通过引入多个注意力头,允许模型在不同的子空间中学习不同的注意力模式。然而,MHA 的一个缺点是,当模型参数增加时(如 34B 或 70B 参数模型),每个头都有独立的 Q、K、V 线性投影矩阵,这会显著增加内存和计算开销。
传统多头注意力机制的代码:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MultiHeadSelfAttention(nn.Module):def __init__(self, embed_size, num_heads):super(MultiHeadSelfAttention, self).__init__()self.embed_size = embed_sizeself.num_heads = num_headsself.head_dim = embed_size // num_headsassert self.head_dim * num_heads == embed_size, "Embedding size needs to be divisible by heads"# 为每个头独立生成 Q、K、Vself.query = nn.Linear(embed_size, embed_size, bias=False)self.key = nn.Linear(embed_size, embed_size, bias=False)self.value = nn.Linear(embed_size, embed_size, bias=False)# 最后的全连接层self.fc_out = nn.Linear(embed_size, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 对每个输入进行线性变换得到 Q、K、Vqueries = self.query(query)keys = self.key(keys)values = self.value(values)# 将维度 (N, seq_length, embed_size) -> (N, num_heads, seq_length, head_dim)queries = queries.view(N, query_len, self.num_heads, self.head_dim).transpose(1, 2)keys = keys.view(N, key_len, self.num_heads, self.head_dim).transpose(1, 2)values = values.view(N, value_len, self.num_heads, self.head_dim).transpose(1, 2)# 注意力得分计算: QK^T / sqrt(d_k)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.head_dim ** (1 / 2)), dim=3)# 使用注意力权重加权 Vout = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.embed_size)return self.fc_out(out)
查询注意力机制(Grouped-Query Attention, GQA)
Grouped-Query Attention (GQA) 通过对查询(Q)的投影进行分组优化,大幅减少了计算和内存的使用。具体来说,GQA 保留了多个注意力头的设计,但共享查询的投影矩阵,而不是为每个头都独立投影查询向量。GQA 的核心思想是将多个注意力头分成几组,每组内的所有注意力头共享同一个查询投影矩阵。
GQA 的主要改进点:
共享查询投影:在 GQA 中,多个注意力头会共享一个查询投影矩阵,而不再为每个头都单独分配一个查询投影矩阵。这样减少了查询投影的计算复杂度和内存需求。
- 例如,如果有 64 个注意力头,GQA 可能将这些头分为 4 组,每组 16 个头。组内的所有 16 个头共享同一个查询投影矩阵,而键和值仍然各自独立。
保持多头注意力的灵活性:尽管查询投影被分组共享,键(K)和值(V)的投影仍然是独立的。这意味着每个注意力头仍然可以在不同的子空间中捕捉不同的注意力模式,而不会丧失多头注意力机制的多样性。
GQA 的工作原理
查询投影分组:多个注意力头被分成几组(例如每组 8 或 16 个头),组内的所有注意力头共享同一个查询投影矩阵。这减少了模型中查询投影的总量。
键和值的独立投影:每个头仍然会独立生成键和值向量,从而保留每个头独立关注不同信息的能力。
自注意力计算:GQA 使用共享的查询投影矩阵来计算查询向量 QQQ,然后与独立的键和值一起进行标准的自注意力计算。尽管查询投影被共享,但每个头的键和值是不同的,因此每个头的注意力分数仍然可以有自己的模式。
多头组合:与传统 MHA 类似,所有注意力头的输出会被拼接起来,经过线性变换后生成最终的输出。
GQA 的优点
相比于传统的 MHA,GQA 在大规模模型中具有以下几个显著优点:
1. 减少内存占用
- 由于查询投影矩阵被分组共享,GQA 显著减少了查询投影矩阵的总量。这在处理大规模模型(如 LLaMA 2 的 34B 和 70B 参数模型)时,能有效降低内存占用。
2. 提高推理效率
- 通过减少查询投影的计算,GQA 可以加速推理过程,尤其是在大型模型中。传统的 MHA 随着注意力头的增加,计算量线性增长,而 GQA 通过共享查询投影减少了计算量,提升了推理效率。
3. 更好的可扩展性
- GQA 尤其适用于大规模模型。在大模型中,MHA 的计算和内存瓶颈会变得更加明显,而 GQA 通过减少查询的独立投影,可以更好地扩展模型参数,同时保持较高的计算效率。
4. 保持多头的灵活性
- 尽管 GQA 共享了查询的投影,但仍然保留了多头注意力机制的多样性。每个头的键和值投影仍然是独立的,因此 GQA 不会牺牲模型在不同子空间中学习不同模式的能力。
查询注意力机制(GQA)的代码
class GroupedQueryAttention(nn.Module):def __init__(self, embed_size, num_heads, num_groups):super(GroupedQueryAttention, self).__init__()self.embed_size = embed_sizeself.num_heads = num_headsself.num_groups = num_groups # 分组数self.head_dim = embed_size // num_headsassert self.head_dim * num_heads == embed_size, "Embedding size needs to be divisible by heads"assert num_heads % num_groups == 0, "Number of heads must be divisible by the number of groups"# 共享查询的投影矩阵self.shared_query = nn.Linear(embed_size, embed_size // num_groups, bias=False) # 每组共享# 为每个头单独生成 K 和 Vself.key = nn.Linear(embed_size, embed_size, bias=False)self.value = nn.Linear(embed_size, embed_size, bias=False)# 最后的全连接层self.fc_out = nn.Linear(embed_size, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# 为每个头生成 K 和 Vkeys = self.key(keys)values = self.value(values)# 将每组内的所有头共享查询投影矩阵queries = []group_size = self.num_heads // self.num_groupsfor i in range(self.num_groups):# 对查询进行分组计算q = self.shared_query(query)q = q.repeat(1, 1, group_size) # 共享矩阵复制给组内的所有头queries.append(q)queries = torch.cat(queries, dim=-1) # 将分组后的 Q 拼接起来# 调整维度以适应注意力计算: (N, seq_length, embed_size) -> (N, num_heads, seq_length, head_dim)queries = queries.view(N, query_len, self.num_heads, self.head_dim).transpose(1, 2)keys = keys.view(N, key_len, self.num_heads, self.head_dim).transpose(1, 2)values = values.view(N, value_len, self.num_heads, self.head_dim).transpose(1, 2)# 注意力得分计算: QK^T / sqrt(d_k)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.head_dim ** (1 / 2)), dim=3)# 使用注意力权重加权 Vout = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.embed_size)return self.fc_out(out)
代码解释:
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
该行代码使用了 torch.einsum 来计算注意力得分矩阵,其中 queries 和 keys 是多头自注意力机制中的查询和键张量。
queries 和 keys 的形状为 (N, S, num_heads, head_dim),经过变换,当前它们的形状为:
queries:(N, query_len, num_heads, head_dim),即nqhd:
N:批次大小(batch size)
q:查询序列长度(query length)
h:注意力头的数量(number of heads)
d:每个头的嵌入维度(embedding size per head)
keys`:`(N, key_len, num_heads, head_dim)`,即 `nkhd
N:批次大小k:键的序列长度(key length)h:注意力头的数量d:每个头的嵌入维度
爱因斯坦求和约定
torch.einsum 使用字符串形式的爱因斯坦求和约定,"nqhd,nkhd->nhqk",用来描述张量的运算规则。这个规则可以分为几个部分:
-
输入部分
"nqhd,nkhd"描述了输入张量的维度:
queries的维度是nqhd,即(N, query_len, num_heads, head_dim)。keys的维度是nkhd,即(N, key_len, num_heads, head_dim)。
-
输出部分
"nhqk"描述了输出张量的维度:
n:批次大小。h:注意力头的数量。q:查询序列长度。k:键序列长度。
在这个表达式中,d(head_dim,嵌入维度)被省略掉了,因为 d 是被求和维度。torch.einsum 将在 d 维上进行内积操作,然后输出 (N, num_heads, query_len, key_len) 形状的张量。
注意力得分矩阵
这一步的结果 energy 是一个形状为 (N, num_heads, query_len, key_len) 的张量,它包含每个注意力头中每个查询位置与所有键位置之间的点积结果。该点积值表示查询和键之间的相似度,也就是注意力机制中的原始得分。
接下来,通常会对这个 energy 张量进行 softmax 归一化,以计算注意力权重,从而决定每个查询应该重点关注哪些键值。
传统多头自注意力机制(MHA)与 GQA 的区别
| 特性 | 传统多头自注意力机制(MHA) | 查询注意力机制(GQA) |
|---|---|---|
| 查询(Q)投影矩阵 | 每个注意力头都有独立的查询投影矩阵 | 查询投影矩阵在分组内的所有头中共享,减少了查询投影的计算量 |
| 键(K)和值(V)投影矩阵 | 每个头有独立的键和值投影矩阵 | 每个头仍然有独立的键和值投影矩阵,保持注意力头的灵活性 |
| 内存需求 | 随着注意力头的数量线性增加 | 通过共享查询投影减少内存占用 |
| 计算效率 | 当注意力头数较多时,计算复杂度和内存开销大 | 通过共享查询投影,计算效率更高,尤其是在大模型中 |
| 灵活性 | 每个头都有独立的查询投影,因此具有较大的灵活性 | 查询投影共享在一定程度上减少了灵活性,但仍保持键和值的独立性 |
上下文长度
LLaMA 2 将上下文长度从 2048 token 增加到 4096 token,这使模型能够处理更长的文本段落,特别是在对话场景和长文本总结中表现更好。
3.训练超参数
- 使用了 AdamW 优化器,参数为 β1=0.9、β2=0.95,学习率使用余弦衰减调度,初始预热 2000 步,最终学习率衰减至峰值的 10%。模型使用了权重衰减(weight decay)0.1 和梯度裁剪(gradient clipping)1.0。
- 训练时长和资源:为了减少训练时间,LLaMA 2 采用了 Meta 的研究超级计算集群(RSC),并使用 NVIDIA A100 GPUs。每个 GPU 的功率限制为 350-400W,总共花费 330 万 GPU 小时 进行预训练,碳排放总计 539 吨 CO2,100% 通过 Meta 的可持续性计划进行了抵消 。
4.优化点
更强的泛化能力:LLaMA 2 的设计在处理长上下文、减少幻觉、提升模型推理速度和内存效率等方面做了大量优化。这些优化使得模型在对话生成、文本总结等任务中表现优异,特别是在需要保持上下文一致性的场景下效果更好。
相关文章:
-----预训练)
LLAMA2入门(一)-----预训练
Llama 2 是预训练和微调的LLM系列,Llama 2 和 Llama 2-Chat 模型的参数规模达到 70B。Llama 2-Chat 模型专门为对话场景进行了优化。 这是一个系列的文章,会分别从LLAMA2的预训练,微调,安全性等方面进行讲解。 1.数据来源 数据…...

使用poi-tl动态写入目录更新问题解决
在使用poi-tl动态写完word后,是无法更新目录的,使用poi-tl提供的插件也是不行的,而且很多使用poi手动写入的也是不行,最多就是让你在打开文件时提示你更新目录/更新域,用户体验很差,要点击好几次而且wps还不…...
更改指定窗口的位置函数moveWindow()的使用)
OpenCV高级图形用户界面(9)更改指定窗口的位置函数moveWindow()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将窗口移动到指定的位置。 cv::moveWindow() 函数用于更改指定窗口的位置。你可以使用这个函数来移动窗口到屏幕上的任何位置。 函数原型 void …...

华山论剑之Rust的Trait
华山论剑,群雄荟萃,各显神通。武林中人,各有所长,或剑法飘逸,或掌法刚猛,或轻功绝顶。这就好比Rust中的trait,它定义了一种武功套路,而不同的门派、不同的人,可以将这套武…...

AI 编译器学习笔记之七五 -- pdb 使用方法
1、进入调试状态有2种方法:Python工具PDB调试器的使用方法详解_python_脚本之家 (jb51.net) a) 在重新种设置断点正常执行:遇到代码中插入的pdb.set_trace()或者breakpoint()进入调试状态 b) 不修改命令行:直接使用 python3 -m pdb pdb_demo.…...

15分钟学Go 第8天:控制结构 - 循环
第8天:控制结构 - 循环 在Go语言中,循环是一种基本的控制结构,用于重复执行一段代码。今天我们将深入了解Go语言中的for循环,包括它的各种用法、语法结构、以及如何在实践中有效地应用循环。 1. for 循环的基本概念 for循环是G…...

后端接收参数的几种常用注解
目录 一、RequestParam 二、RequestBody 三、PathVariable 四、RequestHeader 五、RequestAttribute 六、RequestPart 七、Valid 一、RequestParam 1.作用 用于将请求中的 查询参数 或 表单参数 绑定到方法的参数上。支持 GET 和 POST 请求。 2.使用方法 GetMappin…...

如何使用docker在linux中配置C++环境
目录 1. 安装docker 2. 配置C环境 1)启动ubuntu:22.04容器 2)配置编译环境G 3)安装软件 4)测试 1. 如何打包容器生成tar? a. 生成容器镜像 b. 将镜像压缩成tar 2. 如何将容器内部的端口映射至宿主机…...

darknet_ros 使用教程
首先是git clone可能会因为到没有权限的问题(SSH),此时输入 git clone --recursive https://github.com/leggedrobotics/darknet_ros.git 下载成功之后 catkin_make -DCMAKE_BUILD_TYPERelease catkin失败原因(在CMakefile中&…...

第九课 Vue中的v-bind指令拓展
Vue中的v-bind指令 示例拓展 1)切换样式 <style>.test{width: 100px;height: 100px;border: 3px solid #000;}.bg{background: red;}</style><div id"app"><input type"button" value"点击切换样式" click&qu…...
消息)
DOIP协议介绍2-Diagnostic power mode information request (0x4003)消息
DOIP(Diagnostic communication over Internet Protocol)是基于以太网的通讯协议,用于对UDS协议的数据进行传输,规范于ISO13400标准。DOIP的Type:Diagnostic power mode information request(0x4003&#x…...

Eclipse 软件:配置 JDBC、连接 MySQL 数据库、导入 jar 包
目录 一、配置 JDBC (一)作用 (二)官网下载 1. 下载链接 2. 下载 3. 补充:压缩包分类与用途 (三)eclipse 导入 JDBC 的 jar 包 (四)加载数据库驱动 (五…...

二叉树中的最长交错路径
题目链接 二叉树中的最长交错路径 题目描述 注意点 每棵树最多有 50000 个节点每个节点的值在 [1, 100] 之间起点无需是根节点 解答思路 要找到最长交错路径,首先想到的是深度优先遍历因为起点无需是根节点,所以对于任意一个节点,其可以…...
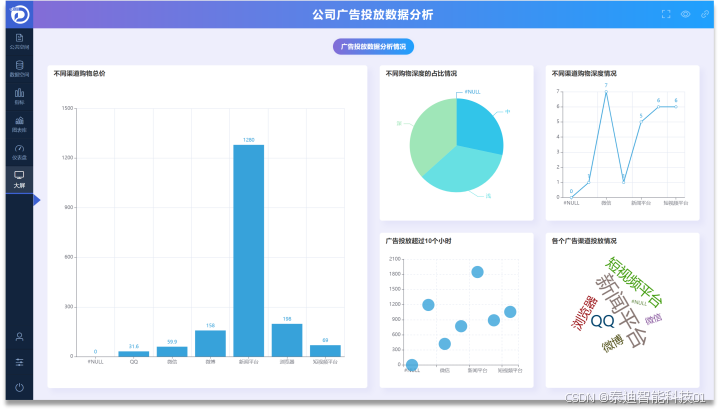
高校企业数据可视化平台功能介绍/特色功能
数据可视化平台是一款适用于高校教学和各领域企业的零门槛可视化工具,能够解决高校数据分析与可视化类课程教学、实训问题。平台采用B/S结构,用户不需要下载客户端,可通过浏览器进行访问。 数据可视化平台提供多种指标设计,学…...

RHCE第三次笔记SSH
第三章 远程连接服务器 1、远程连接服务器简介 (1)什么是远程连接服务器 远程连接服务器通过文字或图形接口方式来远程登录系统,让你在远程终端前登录 linux 主机以取得可操作主机接口(shell ),而登录后…...

JAVA基础-包装类
文章目录 包装类1 概述2 Integer类2.1 Integer类构造方法2.2 Integer类成员方法 3 基本类型与字符串之间的转换3.1 基本类型转换为String3.2 String转换成基本类型 4 底层原理 第六章:算法小题练习一:练习二:练习三:练习四&#x…...
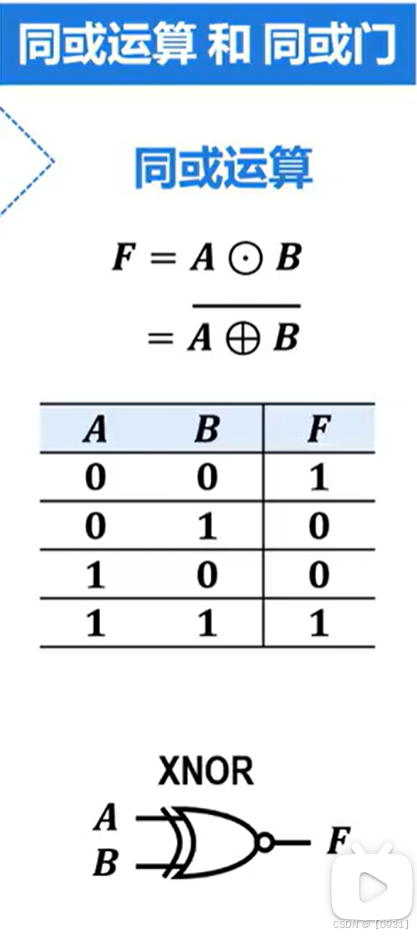
复合逻辑运算与复合逻辑门
或非门(NOR gate) 是一种基本的逻辑门,它结合了“或”(OR)和“非”(NOT)操作。或非门的输出是输入信号的否定,只有在所有输入都为零时,输出才为一。 与非运算࿰…...
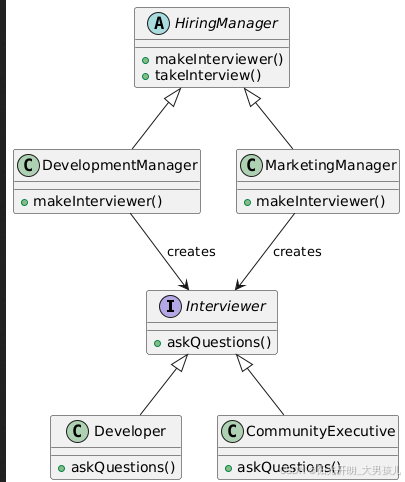
工厂模式~
现实世界中的例子 考虑一个招聘经理的情况。一个人不可能为每一个职位都进行面试。根据职位空缺,她必须决定并将面试步骤委托给不同的人。 用简单的话来说 它提供了一种将实例化逻辑委托给子类的方法。 维基百科的解释 在基于类的编程中,工厂方法模式是…...
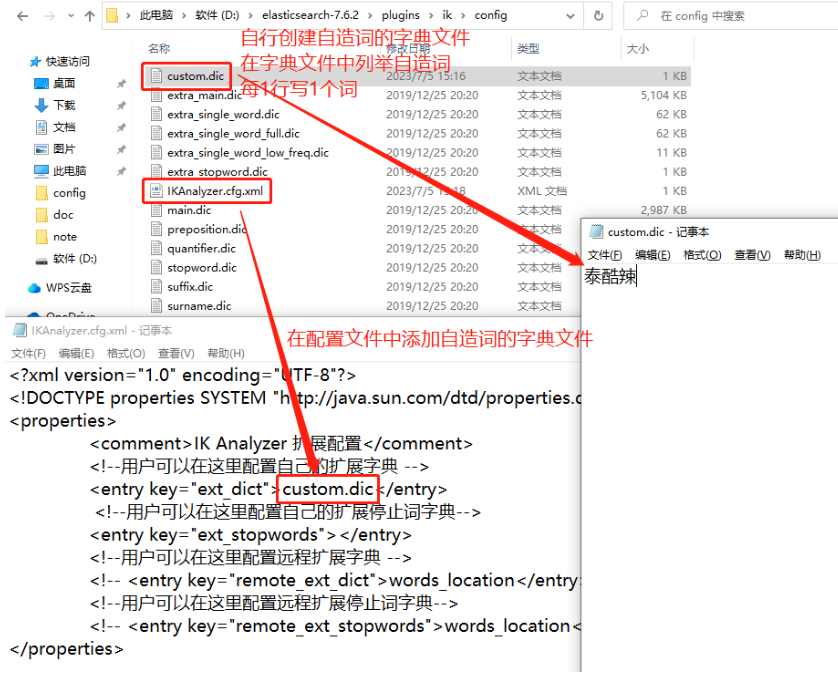
Elasticsearch基本使用及介绍
Elasticsearch 1. 关于各种数据库的使用 关于MySQL:是关系型数据库,能清楚的表示数据之间的关系,并且,是基于磁盘存储的,可以使用相对较低的成本存储大量的数据 关于Redis:是基于K-V结构的在内存中读写数…...
10. PH47代码框架文件组织
通过之前章节对PH47体系的介绍,读者对PH47能建立起了初步的概念及掌握各主要构成部分的使用开发方法。从本章节开始,就将对PH47代码的二次开发内容进行具体讲述。 本部分就将对PH47框架当中代码文件的组织方式及功能作用进行介绍,对于将来熟…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...