【python】NumPy(三):文件读写

目录
前言
NumPy
常见IO函数
save()和load()
savez()
loadtxt()和savetxt()
练习
前言
在数据分析中,我们经常需要从文件中读取数据或者将数据写入文件,常见的文件格式有:文本文件txt、CSV格式文件(用逗号分隔)、二进制文件等。
Numpy可以读写磁盘上的文本数据或者二进制数据。为ndarray对象引入了一个简单的文件格式:npy。用于存储重建ndarray所需的数据、图形、dtype等信息。
NumPy
常见IO函数
在Numpy中,常见的IO函数有:
- loadtxt()和savetxt():处理正常的文本文件和CSV文件。
- load()和save():读写文件数组数据的两个主要函数,默认情况下,是以未压缩的原始二进制格式保存在.npy文件中;
- savez():用于将多个数写入文件。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npz 的文件中
save()和load()
numpy.save(file, arr, allow_pickle=True, fix_imports=<no value>)
想了解更多关于save函数的知识,可以查看:
numpy.save — NumPy v2.1 手册
- file:文件的路径;
- arr:所要保存的数组;
- allow_pickle:bool,可选,允许使用python pickles保存对象数组。默认True。
- fix_imports:bool,可选,不过已经弃用,忽略。
文件拓展名为.npy。
numpy.load(file,mmap_mode=None,allow_pickle=False,fix_imports=True,encoding='ASCII')
- file:所要读取的文件路径;
mmap_mode:None,{‘r+’,'r','w+','c'}可选;一个 内存映射数组保存在磁盘上。但是,可以访问它 并像任何 ndarray 一样进行切片。内存映射特别有用 用于访问大文件的小片段,而无需读取 整个文件复制到内存中。
| ‘r' | 打开现有文件仅供读取 |
| 'r+' | 打开现有文件进行读取和写入 |
| 'w+' | 常见或覆盖现有文件以进行读取和写入。如果shape也必须指定,那么mode='w+' |
| ‘c’ | Copy-on-write:赋值会影响内存中的数据,但更改不会保存到磁盘,磁盘上的文件为只读。 |
- allow_pickle:bool,可选 .
- fix_imports:bool,可选。仅在python3上加载python2生成的picked文件时有用。
- encoding:str,可选。读取python2字符串时使用的编码,仅在以下情况下有用 在 Python 3 中加载 Python 2 生成的 pickle 文件,其中包括 npy/npz 文件。除 'latin1' 以外的值, 不允许使用 'ASCII' 和 'bytes',因为它们会破坏数字 数据。默认值: 'ASCII'。
-
max_header_size:int,可选。标头允许的最大大小。大标头可能不安全 以安全地加载,因此需要显式传递更大的值。 有关详细信息,请参阅。 传递 allow_pickle 时,将忽略此选项。在那种情况下 根据定义,该文件是可信的,并且限制是不必要的。
示例:
# 首先存储数组数据,生成.npy文件
import numpy as np#这里利用相对路径来存储
fileName = './text.npy'
# 生成数组
a = np.arange(24).reshape(2,3,4)
print(a)
#保存到文件中
np.save(fileName,a)当运行完上面的代码,我们可以打开我们在编写代码下的文件夹:

当我们用记事本打开后,会发现是一堆乱码:

我们来利用load()来读取其中的数据:
a = np.load(fileName)
aarray([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])我们可以看到,能够成功读取。
savez()
对于前面的save(),一次只能存储一个数组,那么在numpy中,提供了savez()函数,可以将多个数据保存到一个文件中,生成的文件拓展名是.npz。
savez(file,*args,**kwds)
- file:文件的路径;
- *args:要保存到文件的数组;
- **kwds:关键字,每个数组都会保存到 output 文件及其相应的关键字名称。
示例:
# 将三个数组放到文件中
a = np.arange(20).reshape(2,10)
b = np.arange(10).reshape(2,5)
c = np.arange(40).reshape(5,8)
#要保存到的文件路径
fileName = './texts.npz'
np.savez(fileName,a,b,c)我们可以打开文件查查看,确实生成了texts.npz文件,在打开之后,也是一堆乱码。


同样的,我们需要利用load()函数来读取。
需要注意,如果我们直接接受文件内容,打印出来是这样的:

可以看到,直接打印我们得不到我们想要的数组,因为什么呢?
因为被压缩了,需要根据文件所给的key关键字名称当做索引来进行打印。
all = np.load(fileName)
print(all)
print(all['arr_0'])
print(all['arr_1'])
print(all['arr_2'])NpzFile './texts.npz' with keys: arr_0, arr_1, arr_2
[[ 0 1 2 3 4 5 6 7 8 9][10 11 12 13 14 15 16 17 18 19]]
[[0 1 2 3 4][5 6 7 8 9]]
[[ 0 1 2 3 4 5 6 7][ 8 9 10 11 12 13 14 15][16 17 18 19 20 21 22 23][24 25 26 27 28 29 30 31][32 33 34 35 36 37 38 39]]loadtxt()和savetxt()
这两个函数只能够读写一维或者二维数组的文本文件,同时我们也可以给定分隔符、跳过行数等。
numpy.savetxt(fname,array,fmt='%.18e',delimiter=None,newline='\n', header='', footer='', comments='# ', encoding=None)
- fname:文件路径
- array:要写入文件的数组(可以是一维或者二维数组);
- fmt:写入文件的格式,如:%d、%f、%.18e。默认是%.18e。
- delimiter:分隔符;
- header:将在文件开头写入的字符串;
- footer:在文件末尾写入的字符串;
- comments:附加在header和footer之间的字符串,为注释。
- encoding:所使用的字符集编码。
生成的文件可以是txt文件或者是CSV文件。
numpy.loadtxt(fname,dtype=type’float’>,comments=’#’,delimiter=None, converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0,encoding=‘bytes’)
- fname:所要读取的文件路径;
- dtype:读取后数据的类型;
- comments:跳过文件中指定参数开头的行(相当于注释)
- delimiter:读取文件时的分隔符
- converters:对读取的数据进行预处理;
- skiprows:跳过的行数;
- usecols:指定读取的列;
- encoding:对读取的文件进行预编码。
示例:
现在我们来创建数组保存到文件中。
a = np.arange(12).reshape(3,4)
fileName='./text.txt'
# 默认fmt是%.18e(浮点数,即保留18位小数)
np.savetxt(fileName,a)
可以看到,如果我们没有设置格式,那么默认的格式就是%.18e,输出18位小数。

我们可以来设置一下:
a = np.arange(12).reshape(3,4)
fileName='./text.txt'
# 默认fmt是%.18e(浮点数,即保留18位小数)
np.savetxt(fileName,a,fmt='%d')

可以看到,我们指定输出格式为整数,那么在输出的时候就是整数。
我们来读取一下:
a = np.arange(12).reshape(3,4)
fileName='./text.txt'
# 默认fmt是%.18e(浮点数,即保留18位小数)
np.savetxt(fileName,a,fmt='%d')#读取文件
a = np.loadtxt(fileName,dtype=np.int32)
print(a)
结果:
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]那么如果我们生成的是csv文件,那么会是什么样的?
a = np.arange(12).reshape(3,4)
fileName='./text.csv'
# 默认fmt是%.18e(浮点数,即保留18位小数)
np.savetxt(fileName,a,fmt='%d')
我们来读取一下:
a = np.arange(12).reshape(3,4)
fileName='./text.csv'
# 默认fmt是%.18e(浮点数,即保留18位小数)
np.savetxt(fileName,a,fmt='%d')#读取文件
a = np.loadtxt(fileName,dtype=np.int32)
print(a)[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]那如果我们只想要第二三行,那么我们可以指定一下跳过几行(skiprows=1)
#读取文件
a = np.loadtxt(fileName,dtype=np.int32,skiprows=1)
print(a)[[ 4 5 6 7][ 8 9 10 11]]在此基础上,我们只需要第2、4列,那么我们可以设置一下usecols=(1,3)
#读取文件
a = np.loadtxt(fileName,dtype=np.int32,skiprows=1,usecols=(1,3))
print(a)[[ 5 7][ 9 11]]练习
现在有一个学生成绩单,根据需求,我们要读取出学生的成绩,并计算其总分。;


我们可以打开记事本查看,会发现中间有逗号隔开,所以我们在读取的时候,也需要设置一下分隔符:

#首先我们需要创建一个结构化类型
stu_type = np.dtype([('name',np.str_,2),('Chinese','i2'),('Math','i2'),('English','i2')])
fileName='./成绩单.csv'
#进行读取,跳过第一行
student = np.loadtxt(fileName,skiprows=1,dtype=stu_type,delimiter=',')
print(student)
# 这里我们需要取出各科成绩
Chinese = student['Chinese']
Math = student['Math']
English = student['English']
print(Chinese)
print(Math)
print(English)
# 计算总分
sum = Chinese + Math + English
print('每个同学的总分为:',sum)
averge =sum/3
#设置格式
np.set_printoptions(formatter={'float': '{: 0.3f}'.format})
print('每个同学的平均分为:',averge)[('张三', 90, 86, 99) ('李四', 100, 100, 100) ('王五', 87, 98, 111)('赵六', 89, 99, 98) ('安静', 86, 87, 94) ('安心', 98, 90, 87)('王梓', 87, 88, 89)]
[ 90 100 87 89 86 98 87]
[ 86 100 98 99 87 90 88]
[ 99 100 111 98 94 87 89]
每个同学的总分为: [275 300 296 286 267 275 264]
每个同学的平均分为: [ 91.667 100.000 98.667 95.333 89.000 91.667 88.000]
以上就是本篇所有内容咯~
若有不足,欢迎指正~
后续慢慢改进~~~
相关文章:
【python】NumPy(三):文件读写
目录 前言 NumPy 常见IO函数 save()和load() savez() loadtxt()和savetxt() 练习 前言 在数据分析中,我们经常需要从文件中读取数据或者将数据写入文件,常见的文件格式有:文本文件txt、CSV格式文件(用逗号分隔ÿ…...

硬件产品经理的开店冒险之旅(下篇)
缘起:自己为何想要去寻找职业第二曲线 承接上篇的内容,一名工作13年的普通硬件产品经理将尝试探索第二职业曲线。根本原因不是出于什么高大上的人生追求或者什么职业理想主义,就是限于目前的整体就业形式到了40岁的IT从业人员基本不可能在岗…...
基于GeoScene Pro的开源数据治理与二维制图规范化处理智能工具箱
内容导读 本文描述的是一个基于GeoScene Pro4.0/ArcGIS3.1 Pro平台的开源数据治理与二维制图规范化处理智能工具箱(免费试用,文末有获取方式),旨在解决GIS应用中数据转换、检查、治理和制图数据规范化处理方面的问题。 工具箱结合了Geoscene/ArcGIS Pr…...

CSS 设置网页的背景图片
背景 最近正好在写一个个人博客网站“小石潭记”,需要一张有水,有鱼的图片。正好玩原神遇到了类似场景,于是截图保存,添加到网站里面。以下是效果图: css 写个class,加到整个网页的body上 .bodyBg {ba…...
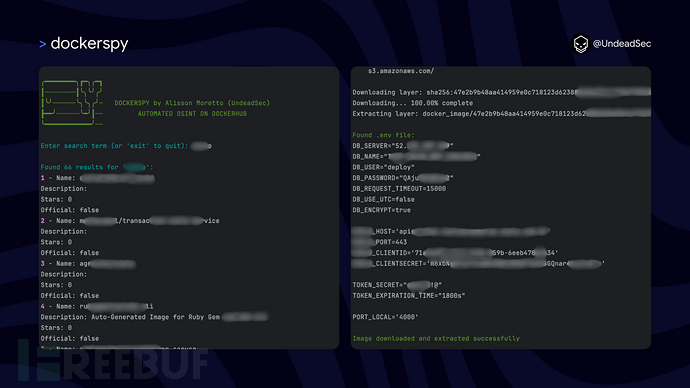
如何使用DockerSpy检测你的Docker镜像是否安全
关于DockerSpy DockerSpy是一款针对Docker镜像的敏感信息检测与安全审计工具,该工具可以帮助广大研究人员在Docker Hub上检测和搜索自己镜像的安全问题,并识别潜在的泄漏内容,例如身份验证密钥等敏感信息。 功能介绍 1、安全审计:…...
数据结构练习题4(链表)
1两两交换链表中的节点 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4]…...

【前端】如何制作自己的网站(7)
以下内容接上文。 结合图片的超链接 将img元素作为内容,放在a元素中。即可为图片添加一个超链接。 例如右边的代码,点击头像就会打开“aboutme.html“。 点击右边的图片试试~ 两个非文本元素——图片与超链接。 从现在开始࿰…...

《数字图像处理基础》学习02-BMP位图文件
目录 一,BMP文件组成 二,使用ultra edit软件查看图像结构 1,ultra edit软件的下载和安装 2,ultra edit打开图像 三,使用matlab显示RGB图像 在之前的文章学习到,计算机只能处理数字图像,因…...

车辆管理系统设计与SpringBoot技术融合
3系统分析 3.1可行性分析 通过对本车辆管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本车辆管理系统采用Spring Boot框架,JAVA作为开发语…...

常见TCP/IP协议基础——计算机网络
目录 前言常见协议基础常见协议-基于TCP的应用层协议常见协议-基于UDP的应用层协议常见协议-网络层协议习题自测1.邮件发送协议2.接收邮件协议端口3.建立连接4.层次对应关系5.FTP服务器端口 前言 本笔记为备考软件设计师时的重点知识点笔记,关于常见TCP/IP协议基础…...

SVM支持向量机python实现
支持向量机(Support Vector Machine, SVM)是一种强大的监督学习算法,主要用于分类和回归任务。SVM的核心思想是找到一个最优的超平面,使得不同类别的数据点能够被尽可能清晰地分开,并且这个超平面与最近的数据点之间有…...

linux查看系统类型
要确定系统是 Ubuntu 还是 CentOS,可以通过查看系统的发行版信息来判断。以下是几种常见的方法: 方法一:使用 cat 命令查看 /etc/os-release 文件 这个文件包含了系统的详细信息,包括发行版名称和版本号。 cat /etc/os-release…...

SpringSecurity 捕获自定义JWT过滤器抛出的异常
自定义过滤器如下: /*** jwt过滤器,验证令牌是否合法** author 朱铭健*/ Slf4j public class JwtAuthenticationFilter extends OncePerRequestFilter {Overrideprotected void doFilterInternal(HttpServletRequest request, HttpServletResponse resp…...

中小型企业网络的设计与实现
资料下载中小型企业网络的设计与实现论文资源-CSDN文库 摘 要 本文规划的是一个公司的网络搭建,网络设计包括了多个部门的网络架构,每个部门通过VLAN进行隔离,确保了网络的安全性和高效。 华为企业网络模拟平台(ENSP)…...

小马识途海外媒体推广有何优势?
互联网让地球变得像一个村子一样,信息可以瞬间变得人尽皆知,商品和服务也同样习惯了跨国合作。中国不少物美价廉的产品在世界各地都很受欢迎,国内小资群体对国外的服饰和美妆更是偏爱有加。小马识途营销顾问认为,中国品牌不出走国…...

Spring Boot知识管理:跨平台集成方案
4系统概要设计 4.1概述 本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示: 图4-1系统工作原理…...

逆向工程基本流程
1 逆向的基本流程 1获取目标app (官网,豌豆荚),尽量不要去华为应用市场,小米应用市场下载–多渠道打包,安装到手机上 2使用抓包工具 抓包分析(charles,fiddler…) 3使用反编译工具 (JADX,JD-GUI。。),把apk反编译成java代码,分析java代码,定位代码位置 4 使用动态分…...

target_include_directories是如何组织头文件的?
target_include_directories(mylib PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}) 这条 CMake 命令用于指定编译目标(在此例中为 mylib 静态库)的头文件搜索路径。具体来说,这条命令的作用包括以下几个方面: 1. 添加包含目录 mylib&…...

【Flutter】Dart:运算符
在 Dart 中,运算符是非常重要的组成部分,它们可以对变量和常量进行多种运算操作。理解和掌握 Dart 中的各种运算符不仅可以帮助你编写更加高效、简洁的代码,还能更好地理解其背后的逻辑和设计。本文将深入探讨 Dart 中的运算符,包…...

ChatGPT01-preivew体验报告:内置思维链和多个llm组合出的COT有啥区别呢?丹田与练气+中学生物理奥赛题测试,名不虚传还是名副其实?
一个月前,o1发布的时候,我写了篇文章介绍 逻辑推理能力堪比博士生,OpenAI发布全新AI模型系列: o1 - 大模型或许进入新阶段,还翻译了官方的介绍 解密OpenAI o1是如何让LLMs获得逻辑推理能力的 - CoT * RL,也…...

位置编码详解
位置编码(Positional Encoding, PE) 是自然语言处理(NLP)中,特别是 Transformer 模型架构里的一个核心概念。它的作用是给序列中的每个词(Token)注入“顺序”或“位置”信息。一、WHY࿱…...

12届蓝桥杯省赛Java B 组Q1~Q4
题目链接: Q1 蓝桥云课:ASC Q2 蓝桥云课:卡片 Q3 蓝桥云课:直线 Q4 蓝桥云课:货物摆放 算法原理: Q1解法:作差 时间复杂度O(1) 思路很简单,只需无脑算出L和A的差值ÿ…...
)
别再让图片拖慢你的多模态模型了:手把手教你用Q-Former和PruMerge压缩视觉Token(附代码)
视觉Token压缩实战:用Q-Former和PruMerge提升多模态模型效率 当你在深夜调试一个多模态问答系统时,突然收到告警——GPU显存爆了。查看日志发现,一张用户上传的4K产品图片生成了超过3万个视觉Token,直接拖垮了整个推理流程。这不是…...

CANoe CAPL文件读写保姆级教程:从记录测试数据到读取配置文件
CANoe CAPL文件读写实战指南:从数据记录到动态配置 在汽车电子测试领域,数据记录和参数配置的自动化程度直接影响着测试效率和可靠性。想象这样一个场景:凌晨三点的耐久性测试实验室,测试工程师需要每隔15分钟手动记录一次总线报文…...
)
别再乱删了!手把手教你用官方工具彻底卸载Autodesk全家桶(3ds Max/CAD)
彻底告别安装失败!Autodesk软件专业卸载与重装全指南 你是否曾经遇到过这样的困扰:明明已经卸载了3ds Max或AutoCAD,重新安装时却频频报错?那些隐藏在系统深处的残留文件就像顽固的污渍,无论你怎么擦洗都挥之不去。本…...

手把手教你:在无外网服务器上用Docker离线搭建Jitsi-Meet视频会议系统
无外网环境下的Jitsi-Meet容器化部署实战指南 在金融、军工等对网络安全要求极高的行业,或是某些特殊的生产环境中,服务器往往被部署在完全隔离的内网中。这种环境下,传统的在线安装方式完全失效,而视频会议系统又是现代企业协作的…...

langchain学习--提示词
langchain提示词学习要点提示词(Prompt)在LangChain中扮演着核心角色,直接影响模型输出的质量和准确性。以下是关键学习方向和实践方法:基础结构设计明确指令:直接说明任务要求,例如"生成一份关于气候…...

06OpenCVSharp角点检测与检测平整度
06OpenCVSharp 角点检测 检测平整度。 代码仅供参考。工厂里检测金属板平整度这事可太常见了。老师傅拿个游标卡尺左量右测,咱们程序猿当然要琢磨怎么用代码搞定。今天说个骚操作——用角点检测判断平面平整度,听着不靠谱?别急,看…...

SQLServer跨平台迁移实战:从Windows备份到Linux还原的完整指南
1. 迁移前的准备工作 跨平台迁移数据库就像搬家前的打包工作,需要提前确认好物品清单和运输工具。我经历过多次SQL Server从Windows到Linux的迁移,发现90%的问题都出在准备阶段。以下是必须检查的关键点: Windows端必备条件: 确保…...

揭秘哈苏HNCS:如何用色彩科学重塑摄影艺术
1. 哈苏HNCS:色彩科学的革命性突破 第一次用哈苏相机拍人像时,我盯着屏幕愣了三秒——模特的肤色就像透过清晨薄雾看到的真实肌肤,连颧骨处细微的红晕过渡都像被阳光自然晕染开的。这种震撼体验背后,是哈苏HNCS自然色彩解决方案在…...