大数据-178 Elasticsearch Query - Java API 索引操作 文档操作
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(正在更新…)
章节内容
上节我们完成了如下的内容:
- 聚合分析
- 指标聚合
- 桶聚合

索引操作
-
创建索引:创建索引是存储数据的第一步。在 Elasticsearch 中,索引相当于关系数据库中的表。创建索引时,你可以指定映射(Mapping),定义字段类型(如 text、keyword、date、geo_point 等)。可以通过 Java API 传递索引设置(Settings)和映射来灵活定义索引的结构。
-
获取索引信息:通过 Java API 可以获取现有索引的详细信息,例如索引的元数据、字段映射、分片数量、副本数量等。这有助于用户分析和优化索引的性能。
-
索引存在性检查:在执行某些操作之前,检查索引是否存在是常见需求。例如,在插入数据前确保索引已经创建,或在删除索引之前确认它的存在性。
-
删除索引:删除不再需要的索引可以节省磁盘空间。需要小心的是,删除索引会清除该索引中的所有数据,操作不可逆,因此通常建议在执行此操作前进行备份。
-
更新索引设置:当集群扩展或数据增长时,你可能需要动态调整索引的分片数量或副本数量。Java API 提供了修改索引设置的功能,可以对现有索引进行优化调整。
文档操作
-
插入文档:文档是 Elasticsearch 中的最小数据存储单元,类似于关系数据库中的行。每个文档以 JSON 格式存储在索引中。通过 Java API,可以向特定索引插入单个文档,并指定文档的 ID(如果不指定,Elasticsearch 会自动生成一个 ID)。
-
获取文档:Java API 可以根据文档 ID 从索引中获取单个文档,返回的结果会包含文档的元数据信息,如 _id、_index、_version 等。获取文档操作通常用于精确查询和显示某个特定数据。
-
更新文档:更新文档时,Elasticsearch 并不会直接修改原始文档,而是通过创建一个新版本的文档来完成。Java API 支持部分更新(Partial Update),即只更新文档中的某些字段,而不必重新提交整个文档。
-
删除文档:删除文档同样基于文档 ID 进行操作。如果文档需要从集群中移除,可以通过 Java API 进行删除操作。此外,删除文档时也可以基于查询条件进行批量删除。
-
批量操作:在处理大量文档时,批量操作(Bulk API)非常重要。Java API 提供了批量插入、更新、删除文档的功能,可以提高大规模数据处理的效率。批量操作通常应用于数据迁移、批量更新、或者从其他系统同步数据到 Elasticsearch。
文件工程
IDEA新建Maven工程,开始对Elasticsearch的学习。
由于重复度很高,这里就跳过了,大家自行创建即可。
导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>study-es</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.3.0</version><exclusions><exclusion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.3.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>compile</scope></dependency><dependency><groupId>org.testng</groupId><artifactId>testng</artifactId><version>6.14.3</version><scope>test</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.11.1</version></dependency></dependencies>
</project>
配置文件
我们要在Resource目录下,新建 log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN"><Appenders><Console name="Console" target="SYSTEM_OUT"><PatternLayout pattern="%d{yyyy-mm-dd HH:mm:ss} [%t] %-5p %c{1}:%L - %msg%n" /></Console></Appenders><Loggers><Root level="info"><AppenderRef ref="Console" /></Root></Loggers>
</Configuration>
创建Client
package icu.wzk;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.After;
import org.junit.Before;import java.io.IOException;public class ElasticsearchTest {RestHighLevelClient client;@Beforepublic void init() throws Exception {RestClientBuilder builder = RestClient.builder(new HttpHost("h121.wzk.icu", 9200, "http"),new HttpHost("h122.wzk.icu", 9200, "http"),new HttpHost("h123.wzk.icu", 9200, "http"));final RestHighLevelClient highLevelClient = new RestHighLevelClient(builder);System.out.println(highLevelClient.cluster().toString());client = highLevelClient;}@Afterpublic void destroy() throws IOException {if (null != client) {client.close();}}}
索引操作
创建索引
JSON方式
@Test
public void createIndex() throws Exception {final CreateIndexRequest indexRequest = new CreateIndexRequest("wzk-icu-es-test");// mapping 信息// mapping 信息String mapping = "{\n" +" \"settings\": {},\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"description\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"name\": {\n" +" \"type\": \"text\"\n" +" },\n" +" \"pic\": {\n" +" \"type\": \"text\",\n" +" \"index\": false\n" +" },\n" +" \"studymodel\": {\n" +" \"type\": \"text\"\n" +" }\n" +" }\n" +" }\n" +"}";indexRequest.source(mapping, XContentType.JSON);// 创建索引CreateIndexResponse indexResponse = client.indices().create(indexRequest, RequestOptions.DEFAULT);boolean acknowledged = indexResponse.isAcknowledged();System.out.println("创建结果: " + acknowledged);
}
执行结果如下图所示,创建成功!

我们通过 Elasticsearch-Head 工具,可以看到如下的内容:

对象方式
@Test
public void createIndex2() throws Exception {CreateIndexRequest createIndexRequest = new CreateIndexRequest("wzk-icu-es-2");createIndexRequest.settings(Settings.builder().put("index.number_of_shards", 5).put("index.number_of_replicas", 1).build());// 指定 mappingXContentBuilder xContentBuilder = XContentFactory.jsonBuilder();xContentBuilder.startObject();xContentBuilder.startObject("properties");xContentBuilder.startObject("description").field("type", "text").field("analyzer", "ik_max_word").endObject();xContentBuilder.startObject("name").field("type", "text").endObject();xContentBuilder.startObject("pic").field("type", "text").field("index", "false").endObject();xContentBuilder.startObject("studymodel").field("type", "text").endObject();xContentBuilder.endObject();xContentBuilder.endObject();// mapping塞进去createIndexRequest.mapping(xContentBuilder);final CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);boolean acknowledged = createIndexResponse.isAcknowledged();System.out.println("创建结果2: " + acknowledged);
}
执行的结果的如下图所示:

Elasticsearch-Head 查看,可以看到刚才创建的ES索引,分片的分布情况如下:

删除索引
@Test
public void deleteIndex() throws Exception {DeleteIndexRequest deleteRequest = new DeleteIndexRequest("wzk-icu-es-test");AcknowledgedResponse deleteResponse = client.indices().delete(deleteRequest, RequestOptions.DEFAULT);boolean acknowledged = deleteResponse.isAcknowledged();System.out.println("删除索引: " + acknowledged);
}
执行结果如下图所示:

对应的Elasticsearch-Head查看,可以看到索引已经移除了:

文档操作
添加文档
@Test
public void addDoc() throws Exception {IndexRequest indexRequest = new IndexRequest("wzk-icu-es-2").id("1");String str = " {\n" +" \"name\": \"spark添加文档\",\n" +" \"description\": \"spark技术栈\",\n" +" \"studymodel\":\"online\",\n" +" \"pic\": \"http://www.baidu.com\"\n" +" }";indexRequest.source(str, XContentType.JSON);// 新增IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println("新增的结果:" + index.status());
}
执行代码的结果如下图所示:

查询文档
@Test
public void getDoc() throws Exception {GetRequest getRequest = new GetRequest("wzk-icu-es-2");getRequest.id("1");GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);Map<String, Object> sourceMap = getResponse.getSourceAsMap();System.out.println("查询结果:" + sourceMap);
}
执行结果如下图:

查询所有
@Test
public void getAllDoc() throws Exception {SearchRequest searchRequest = new SearchRequest();// 指定索引searchRequest.indices("wzk-icu-es-2");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchAllQuery());searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);RestStatus status = searchResponse.status();System.out.println("查询结果状态: " + status);SearchHits hits = searchResponse.getHits();SearchHit[] hits1 = hits.getHits();for (SearchHit sh : hits1) {System.out.println("---");Map<String, Object> map = sh.getSourceAsMap();System.out.println("查询的结果: " + map);}
}
执行的结果如下图所示:

相关文章:
大数据-178 Elasticsearch Query - Java API 索引操作 文档操作
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

PHP(一)从入门到放弃
参考文献:https://www.php.net/manual/zh/introduction.php PHP 是什么? PHP(“PHP: Hypertext Preprocessor”,超文本预处理器的字母缩写)是一种被广泛应用的开放源代码的多用途脚本语言,它可嵌入到 HTML…...

基于深度学习的生物启发的学习系统
基于深度学习的生物启发学习系统(Biologically Inspired Learning Systems)旨在借鉴生物大脑的结构和学习机制,设计出更高效、更灵活的人工智能系统。这类系统融合了生物神经科学的研究成果,通过模仿大脑中的学习模式、记忆过程和…...

10_实现readonly
在某些时候,我们希望定义一些数据是只读的,不允许被修改,从而实现对数据的保护,即为 readonly 只读本质上也是对数据对象的代理,我们同样可以基于之前实现的 createReactiveObject 函数来实现,可以为此函数…...

简单介绍$listeners
$listeners 它可以获取父组件传递过来的所有自定义函数,如下: // 父组件 <template><div class"a"><Child abab"handleAbab" acac"handleAcac"/></div> </template><script> impor…...

架构设计笔记-20-补充知识
知识产权 我国没有专门针对知识产权制定统一的法律(知识产权法),而是在民法通则规定的原则下,根据知识产权的不同类型制定了不同的单项法律及法规,如著作权法、商标法、专利法、计算机软件保护条例等,这些法律、法规共同构成了我…...

scrapy 爬虫学习之【中医药材】爬虫
本项目纯学习使用。 1 scrapy 代码 爬取逻辑非常简单,根据url来处理翻页,然后获取到详情页面的链接,再去爬取详情页面的内容即可,最终数据落地到excel中。 经测试,总计获取 11299条中医药材数据。 import pandas as…...

PDH稳频技术粗谈
PDH(Plesiochronous Digital Hierarchy)是一种传输技术,主要用于数字通信中的传输系统。PDH稳频技术是指在PDH传输系统中,通过稳定频率来实现传输系统的稳定性和可靠性。 PDH传输系统中,时钟同步是非常重要的。传输系…...
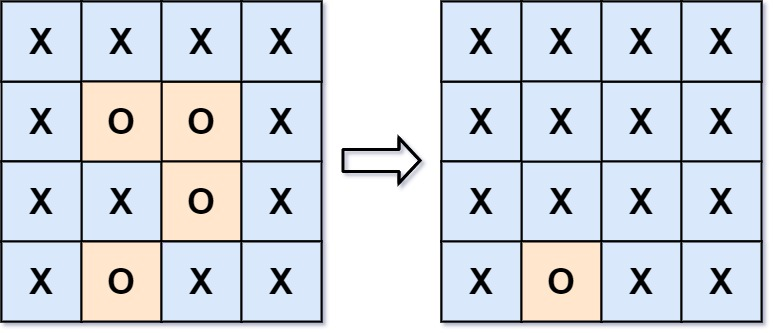
[LeetCode] 130. 被围绕的区域
题目描述: 给你一个 m x n 的矩阵 board ,由若干字符 X 和 O 组成,捕获 所有 被围绕的区域: 连接:一个单元格与水平或垂直方向上相邻的单元格连接。区域:连接所有 O 的单元格来形成一个区域。围绕&#x…...

C语言位运算
目录 1.C语言位运算符表 2.C语言移位运算符详解(配实例作业) 3.C语言&按位与运算符详解 4.C语言|按位或运算符详解 5.C语言^按位异或运算符详解 6.C语言~取反运算符详解 C语言位运算这一章主要介绍C语言位运算符表、C语言移位运算符、C语言&按…...

Go 语言中格式化动词
当然,我很乐意为你提供 Go 语言中所有的格式化动词的完整列表。Go 语言的格式化动词非常丰富,可以满足各种打印和格式化需求。以下是完整的列表: 通用: %v - 以默认格式打印值 %v - 类似 %v,但对结构体会添加字段名 %#…...

CSS3 动画相关属性实例大全(四)(font、height、left、letter-spacing、line-height 属性)
CSS3 动画相关属性实例大全(四) (font、height、left、letter-spacing、line-height 属性) 本文目录: 一、font 属性(所有字体属性) 1.1、font-size属性(指定字体的大小) 1.2、f…...

大模型涌现判定
什么是大模型? 大模型:是“规模足够大,训练足够充分,出现了涌现”的深度学习系统; 大模型技术的革命性:延申了人的器官的功能,带来了生产效率量级提升,展现了AGI的可行路径&#x…...

LeetCode 1456.定长子串中元音的最大数目
题目: 给你字符串 s 和整数 k 。 请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。 英文中的 元音字母 为(a, e, i, o, u)。 思路:定长滑动窗口 入 更新 出 代码: class Solution {pub…...

freeswitch-esl 三方设备实现监听功能
使用场景: A和B在通话中,C想监听A和B通话内容 方法一: 修改拨号计划<extension name="global" continue="true"><condition><action application="info"/>...

【LeetCode】123.买卖股票的最佳时间
清晰明了的思路是解决问题的至上法宝。如何把一个复杂的问题拆成简单的问题,就是我们需要考虑的。 1. 题目 2. 思想 这道题虽然是难题,但是思想比较简单。 题目要求说至多买卖两次,也就是说,也可以买卖一次,这种情况…...

elk部署安装
elk部署 前提准备1、elasticsearch2、kibana3、logstash 前提准备 1、提前装好docker docker-compose相关命令 2、替换docker仓库地址国内镜像源 cd /etc/docker vi daemon.json # 替换内容 {"registry-mirrors": [ "https://docker.1panel.dev", "ht…...

使用 JAX 进行 LLM 分布式监督微调
LLM distributed supervised fine-tuning with JAX — ROCm Blogs (amd.com) 24年1月25日,Douglas Jia 发布在AMD ROCm 博客上的文章。 在这篇文章中,我们回顾了使用 JAX 对基于双向编码器表示(BERT)的大型语言模型(LL…...

【简单版】通过 Window.performance 实现前端页面(性能)监控
1 背景 前端监控系统告警xx接口fetchError 问题:前端监控系统没有更多的错误信息,查询该fetch请求对应的接口日志返回200状态码、无请求异常记录,且后台能查到通过该fetch请求成功发送的数据。那是前端页面的错误还是前端监控系统的问题&…...

微信小程序考试系统(lw+演示+源码+运行)
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了微信小程序考试系统的开发全过程。通过分析微信小程序考试系统管理的不足,创建了一个计算机管理微信小程序考试系统的方案。文章介绍了微信小程序考…...

PyTorch 3.0静态图分布式训练落地实录:从torch.compile到DistributedGraphExecutor的7个关键配置节点
第一章:PyTorch 3.0静态图分布式训练全景概览PyTorch 3.0 引入了原生静态图编译能力(TorchDynamo Inductor 后端深度集成),结合 torch.distributed 的增强型 API,构建出面向大规模集群的高性能分布式训练范式。与传统…...

SQL删除视图会删掉原数据吗_DROP VIEW的安全性分析
DROP VIEW仅删除视图定义而非数据,不影响基表;它不校验下游依赖,删后应用调用会报错;真正删数据的是DROP TABLE或DELETE等操作。DELETE、TRUNCATE 和 DROP VIEW 的作用对象完全不同不会删原表数据。DROP VIEW 只是删掉一个「查询的…...

新鲜出炉!2026简历模板服务商推荐排行 专业评测榜 AI适配/全行业覆盖
一、摘要据中国人力资源开发研究会2026年行业报告显示,国内简历模板服务市场中,仅有30%的服务商能实现ATS系统通过率90%以上,求职者因简历模板不适配、内容不规范导致面试邀约率偏低,平均错失40%的求职机会;企业则因模…...

RAG大模型“外挂“揭秘:3步解锁私有数据问答,秒变“开卷学霸“!
什么是 RAG?一文搞懂大模型时代最火技术 🎯 当AI遇到"失忆症":RAG来拯救 相信用过 ChatGPT 的朋友都遇到过这种尴尬: 你问它最新新闻,它回答"我的知识截止到2023年"你问公司内部政策,它…...
可视化避坑与调参指南)
从.nii文件到发表级配图:一份超详细的fMRI脑区(ROI)可视化避坑与调参指南
从.nii文件到发表级配图:一份超详细的fMRI脑区(ROI)可视化避坑与调参指南 当你终于跑完最后一组统计分析,看着屏幕上那些代表显著脑区的彩色斑点时,可能已经迫不及待想把它们放进论文插图。但现实往往是——直接导出的…...

语雀文档本地化备份工具:轻量级工具实现全流程管理
语雀文档本地化备份工具:轻量级工具实现全流程管理 【免费下载链接】yuque-exporter export yuque to local markdown 项目地址: https://gitcode.com/gh_mirrors/yuq/yuque-exporter 在语雀平台调整服务策略的背景下,如何安全高效地迁移个人创作…...

Halcon卡尺直线检测避坑指南:参数设置与常见错误排查
Halcon卡尺直线检测避坑指南:参数设置与常见错误排查 在工业视觉检测领域,直线边缘的精准定位是许多项目的基础需求。Halcon作为行业标杆工具,其卡尺直线检测功能看似简单,却暗藏诸多参数陷阱。不少开发者在初次接触时࿰…...

一篇文章帮你认识JDBC!!!
一、基础概念1. 什么是 JDBCJDBC(Java DataBase Connectivity):Java 语言操作关系型数据库的一套API(规范 / 接口)。作用:让 Java 程序可以统一连接、操作 MySQL、Oracle、SQL Server 等数据库。2. JDBC 本…...

Qwen-Image镜像实测:RTX4090D+120G内存,图文理解快到飞起
Qwen-Image镜像实测:RTX4090D120G内存,图文理解快到飞起 1. 开箱即用的高性能推理环境 当我第一次启动这个专为RTX 4090D优化的Qwen-Image镜像时,最直观的感受就是"快"。在120GB内存的支持下,大模型加载过程几乎没有任…...

实战指南:基于快马平台与contextmenumanager,为你的数据可视化图表添加专业右键菜单功能
实战指南:基于快马平台与contextmenumanager,为你的数据可视化图表添加专业右键菜单功能 最近在做数据可视化项目时,发现很多用户反馈希望在图表上直接操作,而不是到处找功能按钮。于是研究了一下如何给Chart.js图表添加右键菜单…...