数据分箱:如何确定分箱的最优数量?
选择最优分箱可以考虑以下几种方法:
一、基于业务理解
- 分析业务背景:从业务角度出发,某些特征可能有自然的分组或区间划分。例如,年龄可以根据不同的人生阶段进行分箱,收入可以根据常见的收入等级划分。
- 优点:符合业务逻辑,结果易于解释和理解。
- 缺点:可能不够精确地优化模型性能。
二、基于数据分布观察
- 绘制直方图:对于连续特征,可以绘制其直方图,观察数据的分布情况。如果数据呈现明显的多峰分布,可以考虑在峰值处进行分箱。
- 例如,使用
matplotlib库绘制直方图:
import matplotlib.pyplot as plt import pandas as pddata = pd.DataFrame({'loanAmnt': [100, 200, 300, 400, 500]}) plt.hist(data['loanAmnt'], bins=10) plt.show() - 例如,使用
- 使用核密度估计:核密度估计可以更平滑地展示数据的分布,可以帮助确定合适的分箱点。
- 例如,使用
seaborn库绘制核密度图:
import seaborn as sns import pandas as pddata = pd.DataFrame({'loanAmnt': [100, 200, 300, 400, 500]}) sns.kdeplot(data['loanAmnt']) - 例如,使用
三、基于模型性能评估
- 交叉验证:使用不同数量的分箱对数据进行处理,然后在多个数据集上进行交叉验证,评估模型的性能。选择性能最佳的分箱数量。
- 示例代码:
from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression import pandas as pddata = pd.DataFrame({'loanAmnt': [100, 200, 300, 400, 500], 'target': [0, 1, 0, 1, 0]})for num_bins in range(2, 10):data['loanAmnt_bin'] = pd.qcut(data['loanAmnt'], q=num_bins)X = pd.get_dummies(data[['loanAmnt_bin']])y = data['target']model = LogisticRegression()scores = cross_val_score(model, X, y, cv=5)print(f"Number of bins: {num_bins}, Mean score: {np.mean(scores)}") - 信息价值(Information Value,IV)和基尼系数(Gini Coefficient):在信用评分等领域,可以计算特征的信息价值或基尼系数来确定分箱的效果。通常,较高的信息价值或较低的基尼系数表示更好的分箱效果。
- 例如,假设存在一个计算信息价值的函数
calculate_information_value:
from some_library import calculate_information_valuedata = pd.DataFrame({'loanAmnt': [100, 200, 300, 400, 500], 'target': [0, 1, 0, 1, 0]})for num_bins in range(2, 10):data['loanAmnt_bin'] = pd.qcut(data['loanAmnt'], q=num_bins)iv = calculate_information_value(data['loanAmnt_bin'], data['target'])print(f"Number of bins: {num_bins}, Information Value: {iv}") - 例如,假设存在一个计算信息价值的函数
四、自动化方法
- 使用基于决策树的分箱方法:一些算法,如卡方分箱(ChiMerge),可以自动确定最佳的分箱数量和区间。这些方法基于统计检验来合并相似的区间,直到满足一定的停止条件。
- 例如,可以使用
pandas和scipy.stats库实现简单的卡方分箱:
import pandas as pd from scipy.stats import chi2_contingencydef chimerge(data, feature, target, max_bins=10):bins = pd.cut(data[feature], bins=10)while len(bins.categories) > max_bins:pvalues = []for i in range(len(bins.categories) - 1):bin1 = data[target][bins.categories[i].left <= data[feature] < bins.categories[i].right]bin2 = data[target][bins.categories[i + 1].left <= data[feature] < bins.categories[i + 1].right]contingency_table = pd.crosstab(bin1, bin2)_, pvalue, _, _ = chi2_contingency(contingency_table)pvalues.append(pvalue)min_pvalue_idx = pvalues.index(min(pvalues))if min(pvalues) >= 0.05:breakbins = pd.cut(data[feature], bins=list(bins.categories[:min_pvalue_idx]) + list(bins.categories[min_pvalue_idx + 2:]))return binsdata = pd.DataFrame({'loanAmnt': [100, 200, 300, 400, 500], 'target': [0, 1, 0, 1, 0]}) bins = chimerge(data, 'loanAmnt', 'target') data['loanAmnt_bin'] = bins - 例如,可以使用
选择最优分箱通常需要综合考虑多个因素,包括业务需求、数据分布和模型性能。可以尝试多种方法,并根据具体情况选择最合适的分箱策略。
相关文章:

数据分箱:如何确定分箱的最优数量?
选择最优分箱可以考虑以下几种方法: 一、基于业务理解 分析业务背景:从业务角度出发,某些特征可能有自然的分组或区间划分。例如,年龄可以根据不同的人生阶段进行分箱,收入可以根据常见的收入等级划分。 优点&#x…...

机器学习核心功能:分类、回归、聚类与降维
机器学习核心功能:分类、回归、聚类与降维 机器学习领域的基本功能类型通常按照学习模式、预测目标和算法适用性来分类。这些类型包括监督学习、无监督学习、半监督学习和强化学习,它们可以进一步细化为特定的任务,如分类、回归、聚类和降维…...

Python爬虫-eBay商品排名数据
前言 本文是该专栏的第39篇,后面会持续分享python爬虫干货知识,记得关注。 本文以eBay为例,通过搜索目标”关键词“,获取相关搜索”关键词“的商品排名数据。废话不多说,具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。接下来,跟着笔者直接往下看正文详…...
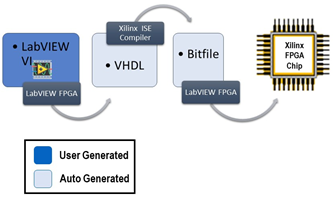
LabVIEW提高开发效率技巧----图像处理加速
在现代工业和科研中,图像处理技术被广泛应用于质量检测、自动化控制、机器人导航等领域。然而,随着图像数据量的增加,传统的CPU处理方式可能难以满足实时性和高效处理的需求。LabVIEW通过结合NI Vision模块和FPGA硬件平台,可以显著…...
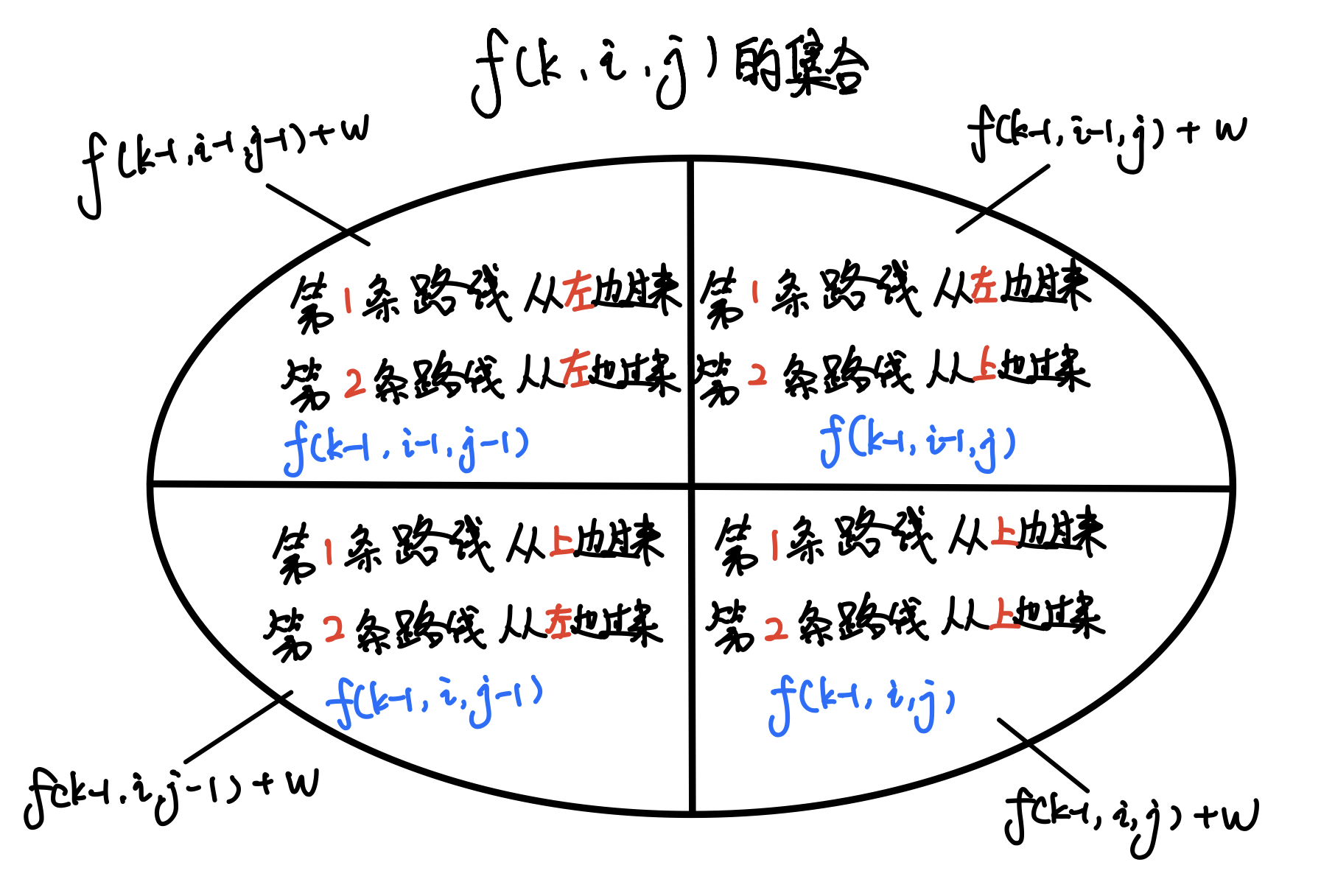
AcWing1027
题目重述: 题目的核心是找到一条路径的最大权值总和,但路径要从起点 (1, 1) 走到终点 (n, n)。由于两条路径分别经过不同的格子,我们可以巧妙地将问题简化为两次同时出发的路径问题。这种映射的设计让我们能够更方便地处理两条路径重叠在同一…...

23 Shell Script服务脚本
Linux 服务脚本 一、Linux 开机自动启动服务 linux开机服务原理: ①linux系统启动首先加载kernel ②初始操作系统 ③login验证程序等待用户登陆 初始化操作系统 kernel加载/sbin/init创建用户空间的第一个程序 该程序完成操作系统的初…...

三周精通FastAPI:3 查询参数
查询参数 FastAPI官网手册:https://fastapi.tiangolo.com/zh/tutorial/query-params/ 上节内容:https://skywalk.blog.csdn.net/article/details/143046422 声明的参数不是路径参数时,路径操作函数会把该参数自动解释为**查询**参数。 from…...

大语言模型学习指南:入门、应用与深入
0x00 学习路径概述 本文将学习路径划分为三个部分:入门篇、应用篇、深入篇。每个章节针对不同的学习需求,帮助你从基础知识入手,逐步掌握大语言模型(LLM)的使用、应用开发以及技术原理等内容。 学习目标 入门篇&…...

【Linux-进程间通信】匿名管道+4种情况+5种特征
匿名管道 匿名管道(Anonymous Pipes)是Unix和类Unix操作系统中的一种通信机制,用于在两个进程之间传递数据。匿名管道通常用于命令行工具之间的数据传递; 匿名管道的工作原理是创建一个临时文件,该文件被称为管道文件…...

Perl打印9x9乘法口诀
本章教程主要介绍如何用Perl打印9x9乘法口诀。 一、程序代码 1、写法① use strict; # 启用严格模式,帮助捕捉变量声明等错误 use warnings; # 启用警告,帮助发现潜在问题# 遍历 1 到 9 的数字 for my $i (1..9) {# 对于每个 $i,遍历 1…...

Android--第一个android程序
写在前边 ※安卓开发工具常用模拟器汇总Android开发者必备工具-常见Android模拟器(MuMu、夜神、蓝叠、逍遥、雷电、Genymotion...)_安卓模拟器-CSDN博客 ※一般游戏模拟器运行速度相对较快,本文选择逍遥模拟器_以下是Android Studio连接模拟器实现(先从以上博文中…...

MySQL的并行复制原理
1. 并行复制的概念 并行复制(Parallel Replication)是一种通过同时处理多个复制任务来加速数据复制的技术。它与并发复制的区别在于,并行复制更多关注的是数据块或事务之间的并行执行,而不是单纯的任务并发。在数据库主从复制中&…...

2023年五一杯数学建模C题双碳目标下低碳建筑研究求解全过程论文及程序
2023年五一杯数学建模 C题 双碳目标下低碳建筑研究 原题再现: “双碳”即碳达峰与碳中和的简称,我国力争2030年前实现碳达峰,2060年前实现碳中和。“双碳”战略倡导绿色、环保、低碳的生活方式。我国加快降低碳排放步伐,大力推进…...

信息安全工程师(57)网络安全漏洞扫描技术与应用
一、网络安全漏洞扫描技术概述 网络安全漏洞扫描技术是一种可以自动检测计算机系统和网络设备中存在的漏洞和弱点的技术。它通过使用特定的方法和工具,模拟攻击者的攻击方式,从而检测存在的漏洞和弱点。这种技术可以帮助组织及时发现并修补漏洞ÿ…...

练习题 - Scrapy爬虫框架 Spider Middleware 爬虫页中间件
在 web 爬虫开发中,Scrapy 是一个非常强大且灵活的框架,它可以帮助开发者轻松地从网页中提取数据。Scrapy 的下载器中间件(Downloader Middleware)是 Scrapy 处理下载请求和响应的一个重要组件。通过使用和编写下载器中间件,开发者可以自定义请求的处理过程,增加请求头信…...
)
探索C++的工具箱:双向链表容器类list(1)
引言 在C中,std::list 是一个标准库提供的容器类,属于C STL(标准模板库)。std::list 是一种独特而强大的容器,它使用双向链表结构来管理元素。无论是在处理动态数据集合,还是在需要频繁进行插入和删除操作时…...

大厂高频算法考点--单调栈
什么是单调栈: 单调栈就是借助一个栈,在仅仅使用当前栈的条件下,时间复杂度是N(n),将每个节点最有离这他最近的大于或者是小于的数据返回,将已知数组的元素放到栈里。再自我实现的代码里面我们使用数组实现…...

Unity使用Git及GitHub进行项目管理
git: 工作区,暂存区(存放临时要存放的内容),代码仓库区1.初始化 git init 此时展开隐藏项目,会出现.git文件夹 2.减小项目体积 touch .gitignore命令 创建.gitignore文件夹 gitignore文件夹的内容 gitignore中添加一下内容 # This .gitignore file should be place…...

如何将本地 Node.js 服务部署到宝塔面板:完整的部署指南
文章简介: 将本地开发的 Node.js 项目部署到线上服务器是开发者常见的工作流程之一。在这篇文章中,我将详细介绍如何将本地的 Node.js 服务通过宝塔面板(BT 面板)上线。宝塔面板是一个强大的服务器管理工具,具有简洁的…...

SpringBoot项目启动报错:命令行太长解决
文章目录 SpringBoot项目启动报错:命令行太长解决1. 第一种方法1. 第二种方法1-1 旧版本Idea1-2 新版本Idea 3. 重新启动SpringBoot项目即可解决 SpringBoot项目启动报错:命令行太长解决 报错信息: 1. 第一种方法 1. 第二种方法 找到项目…...
)
在VMware虚拟机里用CentOS 7.5手把手搭建OpenVPN 2.4.12服务器(附完整证书生成与防火墙配置)
在虚拟化环境中构建安全通信通道的技术实践 虚拟化技术为现代IT基础设施提供了灵活性和隔离性,而在这类环境中建立安全的通信通道则是许多开发者和运维人员的刚需。本文将聚焦于如何在VMware虚拟化平台上,基于CentOS 7.5系统构建一套完整的加密通信解决…...
)
从B站视频到毕业设计:三相四桥臂的三种主流控制方案到底怎么选?(MPC/3D-SVPWM/载波调制深度对比)
三相四桥臂逆变器控制方案深度对比:从理论到工程实践的选择指南 在电力电子领域,三相四桥臂逆变器的控制策略选择一直是工程师和研究者面临的关键挑战。不同于传统的三相三桥臂结构,第四桥臂的引入虽然解决了不平衡负载下的中性点电流问题&a…...

2026届最火的五大AI辅助论文网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 有着自动剖析研究领域热点能力的AI开题报告工具,是依托自然语言处理与知识图谱技…...

5个AI Skill实测:影视内容创作全流程自动化
为什么AI助手的能力上限取决于你装了什么Skill养虾必装的5个Skill,影视博主效率翻倍你的小龙虾(OpenClaw/CodeBuddy/Windsurf)装了几个Skill?很多人养虾只用来写代码、查资料,但其实用小龙虾做内容创作、数据分析、批量…...
)
【基于Python技术的智慧中医商业项目】后端应用Articles代码实现(三)
前后端分离场景中,序列化字段映射一旦写错,常见表现是接口返回字段缺失、层级字段解析失败、列表页展示异常;过滤器规则不稳定时,表现为列表查询条件无效、批量筛选失控、后台与接口筛选口径不一致。 本文围绕文章应用模块的 serializes.py 与 filters.py 拆解,聚焦序列化…...

OpenSC2K完整开发路线图:打造终极开源城市模拟体验的三大核心方向
OpenSC2K完整开发路线图:打造终极开源城市模拟体验的三大核心方向 【免费下载链接】OpenSC2K OpenSC2K - An Open Source remake of Sim City 2000 by Maxis 项目地址: https://gitcode.com/gh_mirrors/op/OpenSC2K OpenSC2K是一款基于经典游戏《模拟城市200…...
)
Halcon 9点标定保姆级教程:从螺丝批头点到机械手精准定位(附源码)
Halcon 9点标定实战指南:从硬件准备到误差优化的全流程解析 在工业自动化领域,视觉引导的机械手定位精度直接影响生产质量。许多工程师第一次接触Halcon标定时,往往被理论公式和算法流程所困扰,却忽略了现场实施中最关键的实操细节…...

深入操作系统原理:Qwen3.5-9B-AWQ-4bit解读进程调度与内存管理
深入操作系统原理:Qwen3.5-9B-AWQ-4bit解读进程调度与内存管理 1. 操作系统教学的新助手 计算机操作系统课程向来以抽象难懂著称。学生们常常被进程状态转换、死锁条件、页面置换算法等概念困扰,而传统教学方式又难以直观展示这些动态过程。这正是Qwen…...

mac上安装openclaw从入门到删除
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录安装拉取最新版本拉取对应版本卸载1、卸载openclaw2、卸载openclaw CLI3、确认是否删除参考来源保姆级!Mac 安装小龙虾 OpenClaw 全教程OpenClaw 卸载教程…...

AI入门必看|一文搞懂人工智能是什么,小白也能秒懂
前言:随着ChatGPT、自动驾驶、AI绘画的普及,人工智能已经从“高大上的科技概念”走进了我们的日常生活,但很多小白面对“人工智能”四个字,还是会感到迷茫——它到底是什么?能做什么?和我们普通人有什么关系…...