AI金融攻防赛:YOLO理论学习及赛题进阶思路(DataWhale组队学习)

引言
大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年10月学习赛的AI金融攻防赛学习总结文档。本文主要讲解如何在金融场景凭证篡改检测中应用YOLO算法。我们将从模型概述、数据准备、训练流程以及模型评估等多个方面,详细介绍如何搭建一个高效的目标检测模型。希望我的经验能对大家有所帮助!💕💕😊
一、物体检测与YOLO算法介绍
1. 什么是物体检测?
物体检测是计算机视觉中的一个重要任务,它不仅需要识别图像中的对象类别,还要确定对象在图像中的位置,并以边界框的形式标注出来(类别+位置)。物体检测的应用场景包括自动驾驶、视频监控、工业检测、金融凭证核验等领域。
物体检测的一般步骤:
- 输入:一张图像或视频帧,对其进行缩放。
- 特征提取:通过卷积神经网络(CNN)提取视觉特征,为检测提供基础。
- 候选区域生成:部分算法会生成可能含有目标的区域(如R-CNN)。
- 分类与边界框回归:判断区域内物体的类别并回归出精确的边界框坐标。
- 非极大值抑制(NMS):去除重复的边界框,保留最高置信度的框。

2. YOLO算法概述
YOLO(You Only Look Once)是一种高效的实时目标检测算法,将检测任务视为一个单一的回归问题。与传统的滑动窗口方法不同,YOLO在一次网络评估中即可同时预测多个边界框和类别概率。其设计能够兼顾检测速度和精度,非常适合金融凭证篡改检测这种需要实时处理的任务。

YOLO算法并行预测原理
YOLO(You Only Look Once)算法之所以能够同时预测多个边界框和类别概率,主要是因为它将目标检测任务视为一个单一的回归问题。具体来说,YOLO通过以下几个关键步骤实现这一目标:
-
单一网络评估:YOLO将整个图像输入到一个卷积神经网络(CNN)中,网络在一次前向传播过程中直接输出所有边界框和类别概率。这与传统的滑动窗口方法不同,滑动窗口方法需要多次评估图像的不同区域,而YOLO只需要一次评估。
-
网格划分:YOLO将输入图像划分为一个S×S的网格(例如,7×7)。每个网格单元负责预测在其中心附近的目标。每个网格单元可以预测多个边界框(通常是B个,例如B=2),并且每个边界框都与一个类别概率相关联。
-
边界框预测:每个网格单元预测B个边界框,每个边界框由5个参数组成:边界框的中心坐标(x, y)、边界框的宽度和高度(w, h),以及一个置信度(confidence)。置信度表示该边界框包含目标的概率。
-
类别概率预测:每个网格单元还预测C个类别概率,表示该网格单元中目标属于每个类别的概率。这些类别概率与边界框无关,而是基于网格单元的内容。
相关公式理论:
1. 置信度(Confidence):
- 置信度的计算公式为:
Confidence = Pr(Object) × IOU(pred, truth) \text{Confidence} = \text{Pr(Object)} \times \text{IOU(pred, truth)} Confidence=Pr(Object)×IOU(pred, truth)
- Pr(Object):表示网格单元中存在目标的概率。如果网格单元中没有目标,Pr(Object)为0;如果有目标,Pr(Object)为1。
- IOU(pred, truth):表示预测边界框与真实边界框的交并比(Intersection over Union)。IOU的值范围在0到1之间,值越大表示预测框与真实框的重叠程度越高。
2. 类别概率(Class Probability)
- 类别概率的计算公式为:
Class Probability = Pr(Class i ∣ Object) \text{Class Probability} = \text{Pr(Class}_i | \text{Object)} Class Probability=Pr(Classi∣Object)
- Pr(Class_i | Object):表示在网格单元中存在目标的情况下,目标属于第i类的概率。
- 最终预测:
最终的预测结果是每个边界框的置信度与类别概率的乘积:
Final Prediction = Confidence × Class Probability \text{Final Prediction} = \text{Confidence} \times \text{Class Probability} Final Prediction=Confidence×Class Probability- 举例:
假设我们有一个7×7的网格,每个网格单元预测2个边界框,并且我们有3个类别(例如,人、车、自行车)。- 网格划分:图像被划分为7×7的网格,总共有49个网格单元。
- 边界框预测:每个网格单元预测2个边界框,每个边界框有5个参数(x, y, w, h, confidence)。假设某个网格单元预测的两个边界框为:
- 边界框1:(x1, y1, w1, h1, confidence1)
- 边界框2:(x2, y2, w2, h2, confidence2)
- 类别概率预测:
每个网格单元还预测3个类别概率(人、车、自行车)。假设某个网格单元的类别概率为:
- 人:0.8
- 车:0.1
- 自行车:0.1
- 最终预测:对于每个边界框,最终的预测结果是置信度与类别概率的乘积。例如:
- 边界框1的最终预测:(confidence1 * 0.8, confidence1 * 0.1, confidence1 * 0.1)
- 边界框2的最终预测:(confidence2 * 0.8, confidence2 * 0.1, confidence2 * 0.1)
由此,YOLO能够在一次前向传播中同时预测多个边界框和类别概率,从而实现快速且高效的目标检测。
二、YOLO版本演进与特性
YOLO算法自2015年推出以来经历了多次迭代,每一代都在速度、准确性和易用性方面进行了改进:
| 版本 | 年份 | 主要贡献与特点 |
|---|---|---|
| YOLOv1 | 2015 | 将检测视为回归问题,单次网络预测物体类别与位置。 |
| YOLOv2 | 2016 | 引入批量归一化和高分辨率分类器,支持多达9000个类别的检测。 |
| YOLOv3 | 2018 | 使用Darknet-53骨干网络,提高了多尺度检测能力。 |
| YOLOv4 | 2020 | 融合CSPNet和PANet等技术,提升特征提取效率。 |
| YOLOv5 | 2020 | 用PyTorch实现,更易用,适应不同场景。 |
| YOLOv8 | 2023 | 引入Anchor-Free检测头和新损失函数,提升性能与灵活性。 |
| YOLOv10 | 2024 | 取消NMS操作,优化组件,实现最高性能。 |
三、YOLO数据集格式与标注
YOLO算法的标注格式主要使用.txt文件记录图像中的物体信息。每一行代表一个物体的类别及其边界框坐标,格式如下:
class_index x_center y_center width height
- class_index:类别索引,对应于类别列表中的整数。
- x_center, y_center:物体中心的x和y坐标,归一化到[0, 1]范围。
- width, height:物体边界框的宽度和高度,同样归一化处理。
示例配置文件 (YOLO.yaml):
path: ../dataset/ # 数据集根目录
train: images/train/ # 训练集路径
val: images/val/ # 验证集路径# 类别数量和名称
nc: 2 # 类别数量
names: ["0", "1"] # 类别名称
本此比赛的baseline中则是这个data.yaml的文件:

ok,看完Yolo的基本介绍后,我们根据本次比赛的baseLine代码来提出Yolo的训练过程吧!
四、金融检测YOLO模型的训练与评估流程
为了提升模型在金融场景中的应用效果,我们可以采取以下优化措施:
- 增加训练数据:整合更多高质量数据集,提升模型的泛化能力。
- 使用不同的预训练权重:在已有模型上微调,提升精度。
- 模型部署:将训练好的模型部署到云端或本地服务器,实时检测凭证篡改行为。
作者将在下面整理本次比赛代码流程:
1.安装必要的库
pip install ultralytics opencv-python-headless albumentations pandas numpy
2.导入依赖库
import os
import cv2
import shutil
import numpy as np
import pandas as pd
import albumentations as A
from ultralytics import YOLOprint('依赖库导入成功!')
3.定义图像增强和处理函数
# 绘制多边形到二值 mask 上
def polygon_to_mask(polygon, img_height, img_width):mask = np.zeros((img_height, img_width), dtype=np.uint8)polygon = np.array([polygon], dtype=np.int32)cv2.fillPoly(mask, polygon, 1)return mask# 增强图像并生成 mask
def augment_image(img, polygons):mask = np.zeros(img.shape[:2], dtype=np.uint8)for polygon in polygons:polygon_mask = polygon_to_mask(polygon, img.shape[0], img.shape[1])mask = np.maximum(mask, polygon_mask)transform = A.Compose([A.HorizontalFlip(p=0.5),A.VerticalFlip(p=0.5),A.RandomRotate90(p=0.5),A.RandomBrightnessContrast(p=0.2),], is_check_shapes=False)augmented = transform(image=img, mask=mask)return augmented['image'], augmented['mask']# 归一化多边形坐标
def normalize_polygon(polygon, img_width, img_height):return [(x / img_width, y / img_height) for x, y in polygon]print('图像增强和归一化函数定义成功!')
4. 处理训练集和验证集
# 加载数据集(假设已有一个包含路径和多边形数据的DataFrame:training_anno)
training_anno = pd.read_csv('annotations.csv') # 替换为你的注释文件路径# 处理训练数据集
for _, row in training_anno.iloc[:14000].iterrows():shutil.copy(row['Path'], 'yolo_seg_dataset/train/')img = cv2.imread(row['Path'])img_height, img_width = img.shape[:2]# 数据增强img, mask = augment_image(img, row['Polygons'])# 保存标签文件txt_filename = os.path.join('yolo_seg_dataset/train/', row['Path'].split('/')[-1][:-4] + '.txt')with open(txt_filename, 'w') as f:for polygon in row['Polygons']:normalized_polygon = normalize_polygon(polygon, img_width, img_height)normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])f.write(f'0 {normalized_coords}\n')print('训练集处理完成!')# 处理验证集
for _, row in training_anno.iloc[14000:17000].iterrows():shutil.copy(row['Path'], 'yolo_seg_dataset/valid/')img = cv2.imread(row['Path'])img_height, img_width = img.shape[:2]mask = np.zeros(img.shape[:2], dtype=np.uint8)for polygon in row['Polygons']:polygon_mask = polygon_to_mask(polygon, img.shape[0], img.shape[1])mask = np.maximum(mask, polygon_mask)txt_filename = os.path.join('yolo_seg_dataset/valid/', row['Path'].split('/')[-1][:-4] + '.txt')with open(txt_filename, 'w') as f:for polygon in row['Polygons']:normalized_polygon = normalize_polygon(polygon, img_width, img_height)normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])f.write(f'0 {normalized_coords}\n')print('验证集处理完成!')
5.创建配置文件
# 创建数据集的配置文件 data.yaml
with open('yolo_seg_dataset/data.yaml', 'w') as f:data_root = os.path.abspath('yolo_seg_dataset/')f.write(f'''
path: {data_root}
train: train
val: validnames:0: alter
''')print('配置文件创建成功!')
6.训练模型
print('开始模型训练!')# 加载 YOLOv8 分割模型并进行训练
model = YOLO("yolov8l-seg.pt") # 使用较大的 YOLOv8-L 分割模型
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=50, imgsz=640) # 设置训练轮数为50print('模型训练完成!')
7.保存和验证结果
# 保存训练结果
results.save("yolo_seg_results/")
# 打印训练结果摘要
print(results)
- 安装依赖:安装必要的 Python 包,如
ultralytics、opencv、albumentations等。 - 定义增强函数:通过 Albumentations 进行图像增强,并生成 mask。
- 处理数据集:将训练集和验证集中的图像及其标签进行增强和格式化。
- 创建配置文件:定义数据集路径和类别名称。
- 训练模型:加载 YOLOv8 分割模型,使用增强后的数据集进行训练,并保存结果。
相信看完以上代码后,读者对这个流程有了自己的理解;我们再来了解一下实例分割的概念与原理吧!
五、YOLO实例分割原理
1.实例分割的概念

实例分割(Instance Segmentation)是一种计算机视觉任务,它**不仅需要识别图像中的每个物体,还需要精确地分割出每个物体的像素级边界。**与物体检测(Object Detection)不同,物体检测只需要识别出图像中物体的边界框(Bounding Box),而实例分割则需要进一步将每个物体的像素精确地分割出来。
上图中面积区域是实例分割的结果,框选区域是目标识别的结果;
2.实例分割与物体识别的区别
-
物体检测(Object Detection):
- 任务:识别图像中物体的类别和位置。
- 输出:每个物体的边界框(Bounding Box)和类别标签。
- 示例:YOLO、Faster R-CNN。
-
实例分割(Instance Segmentation):
- 任务:识别图像中每个物体的类别,并精确地分割出每个物体的像素级边界。
- 输出:每个物体的像素级掩码(Mask)和类别标签。
- 示例:Mask R-CNN、YOLOv8。
3.YOLO实例分割
YOLOv8通过扩展其基本的目标检测框架,实现了实例分割功能。以下是YOLOv8实现实例分割的关键步骤和原理:
-
多任务损失函数:
- 边界框损失:评估预测框与真实框之间的差异。
- 分类损失:预测类别与真实类别的误差。
- 分割损失:预测掩码与真实掩码的差异。
- DFL损失:用于优化预测框的边缘精度。
-
特征提取:
- YOLOv8使用卷积神经网络(CNN)提取图像特征。这些特征图(
feats)包含了图像的高级语义信息。
- YOLOv8使用卷积神经网络(CNN)提取图像特征。这些特征图(
-
原型掩码生成:
- 在特征提取之后,YOLOv8生成一组原型掩码(
proto)。这些原型掩码是基于特征图生成的,用于表示不同物体的潜在掩码形状。
- 在特征提取之后,YOLOv8生成一组原型掩码(
-
预测掩码生成:
- 基于原型掩码和特征图,YOLOv8生成预测掩码(
pred_masks)。这些预测掩码是每个物体的像素级掩码。
- 基于原型掩码和特征图,YOLOv8生成预测掩码(
-
掩码组合:
- 最终的实例掩码是通过组合预测掩码和原型掩码生成的。这个过程考虑了不同目标之间的掩码重叠情况,并对重叠区域进行处理。
-
损失计算与优化:
- 在训练过程中,YOLOv8使用多任务损失函数来优化模型的参数。通过最小化边界框损失、分类损失、分割损失和DFL损失,模型能够同时学习物体检测和实例分割任务。
示例
假设我们有一张包含多个物体的图像,例如一张包含汽车、行人和自行车的街道图像。

-
物体检测:
- YOLOv8首先识别出图像中的每个物体,并生成它们的边界框。例如,它会识别出汽车、行人和自行车的边界框。
-
实例分割:
- 在物体检测的基础上,YOLOv8进一步生成每个物体的像素级掩码。例如,它会生成汽车、行人和自行车的像素级掩码,精确地分割出每个物体的像素。
代码如下:
import cv2from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colorsmodel = YOLO("yolo11n-seg.pt") # segmentation model
names = model.model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))out = cv2.VideoWriter("instance-segmentation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))while True:ret, im0 = cap.read()if not ret:print("Video frame is empty or video processing has been successfully completed.")breakresults = model.predict(im0)annotator = Annotator(im0, line_width=2)if results[0].masks is not None:clss = results[0].boxes.cls.cpu().tolist()masks = results[0].masks.xyfor mask, cls in zip(masks, clss):color = colors(int(cls), True)txt_color = annotator.get_txt_color(color)annotator.seg_bbox(mask=mask, mask_color=color, label=names[int(cls)], txt_color=txt_color)out.write(im0)cv2.imshow("instance-segmentation", im0)if cv2.waitKey(1) & 0xFF == ord("q"):breakout.release()
cap.release()
cv2.destroyAllWindows()
通过这种方式,YOLOv8不仅能够识别图像中的物体,还能够精确地分割出每个物体的像素级边界,从而实现实例分割任务。
OK! 今天就学习到这里了!😉
七、总结
通过本次AI金融攻防赛的学习和实践,我们深入了解了凭证篡改检测这一关键问题,并成功构建了一个基于YOLOv8l的检测模型。通过数据标注、模型训练和评估,我们验证了YOLO在金融凭证检测任务中的高效性和可靠性。OK,初步解析到此结束!更多内容看后续;希望这篇博客能为您的项目提供帮助!🚀
相关链接
- 项目地址:Git地址
- 活动地址:AI核身之金融场景凭证篡改检测
- 相关文档:专栏地址
- 作者主页:GISer Liu-CSDN博客

如果觉得我的文章对您有帮助,记得三连+关注哦!🌟
相关文章:
AI金融攻防赛:YOLO理论学习及赛题进阶思路(DataWhale组队学习)
引言 大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年10月学习赛的AI金融攻防赛学习总结文档。本文主要讲解如何在金融场景凭证篡改检测中应用YOLO算法。我们将从模型概述、数据准备、训练流程以及模…...

Spring Security 基础配置详解(附Demo)
目录 前言1. 基本知识2. Demo3. 实战 前言 基本的Java知识推荐阅读: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目】实战CRUD的功能整理(持续更新) 1. 基本知识 HttpSecurity 是 Spri…...
代码随想录打卡Day1
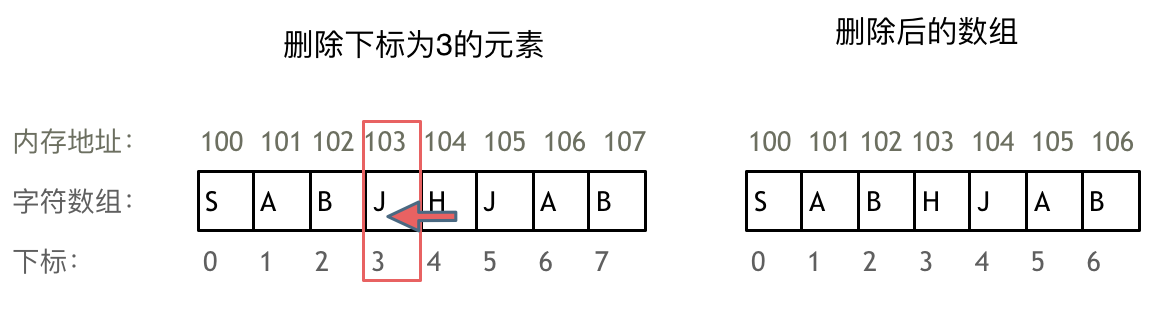
文章目录 day011 数组理论基础2 二分查找法3 移除元素4 平方数 day01 Java JDK是17.0.11 1 数组理论基础 数组是存放在连续内存空间上的相同类型数据的集合。 数组下标都是从0开始的。 数组内存空间的地址是连续的。 因为数组在内存空间的地址是连续的,所以我们…...

Vue快速创建工程+Element Plus
创建Vue工程 执行命令 npm init vuelatest 执行这两个绿色的命令 执行这个命令启动 npm run dev Element 打开网站https://element-plus.org/zh-CN/ npm install element-plus --save 然后在vscode中打开你的项目工程 // main.ts import { createApp } from vue import Ele…...

汽车管理系统——主界面制作
目录 主界面需要有什么?然后要做什么?添加两个主菜单(声明)下一步应该干什么?能够跳转到文件有哪几个动作?动作如何声明?为什么用选择声明指针,不选择直接声明这个对象? …...

C++ 右值引用深入理解:特性、优化与底层
目录 一、左右值的概念及右值的种类 二、左值引用与右值引用 左值引用给右值取别名: 右值引用给左值取别名: 三、引用的意义及左值引用的场景 四、移动构造: 右值引用在底层里的实现: 一、左右值的概念及右值的种类 在 C …...

C# 文件操作
文章目录 文件系统FileInfo和DirectoryInfo类完成一个文件的拷贝判断一个文件是否存在FileInfo和DirectoryInfo的属性列表FileInfo和DirectoryInfo的方法列表读写文件文件系统 下面的类用于浏览文件系统和执行操作,比如移动,复制和删除文件。 System.MarshalByRefObject 这个…...

FFmpeg 4.3 音视频-多路H265监控录放C++开发三 :安装QT5.14.2, 并将QT集成 到 VS2019中。
一,安装QT, 重点:在安装QT的时候要安装msvc201x版本的组件, 二 , 安装 qt-vs-tools Index of /development_releases/vsaddin/2.8.1 三,需要安装过 windows10 SDK,一般我们在安装vs2019的时候就…...

Linux 累加计算递归算法汇编实现
1...n可以使用公式计算,同时也是递归实现的很好例子,其c实现代码为 int f(int i) {i && (if(i-1));return i; } 其终止条件为0,此时i && (if(i-1))表达式不成立,不计算if(i-1)直接返回0&…...

明日周刊-第23期
十月已过半,气温也转凉了,大家注意保温哦。冬吃萝卜,夏吃姜,在快要到来的冬季大家可以选择多吃点萝卜。 配图是本周末去商场抓娃娃的时候拍的照片,现在抓娃娃单次普遍都控制在1块钱以下了,还记得多年前的抓…...

kubernets(二)
集群操作 查看集群信息 kubectl get查看各组件信息 格式:kubectl get 资源类型 【资源名】 【选项】 events #查看集群中的所有日志信息 -o wide # 显示资源详细信息,包括节点、地址... -o yaml/json #将当前资源对象输出至 yaml/json 格式文…...

《YOLO 标注工具全览》
《YOLO 标注工具全览》 一、YOLO 标注工具的重要性二、常见的 YOLO 标注工具介绍(一)LabelImg(二)Yolo_Label(三)在线标注工具 Make Sense(四)Ybat - YOLO BBox Annotation Tool&…...

财富思维学习
四大象限: 人类财富创造史经历的五个阶段: 1、黄色(土地)财务阶段:拥有土地和劳动力是财富的要求 2、蓝色(海)财富阶段:谁拥有贸易的通道谁就拥有财富(如港口ÿ…...
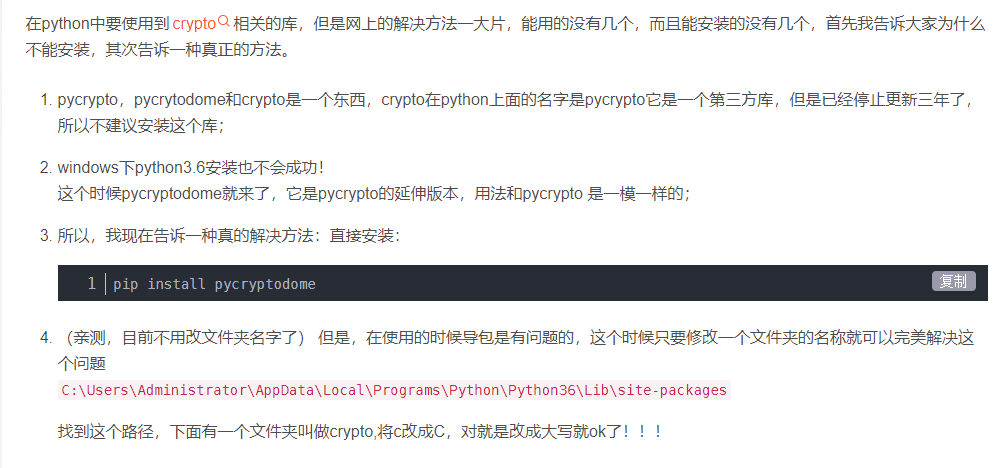
python爬虫加解密分析及实现
第一种: 1、找到加密的接口地址,通过加密的接口地址全局搜索 2、通过打断点的方式,操作页面,跑到断点处时,即可找到加密串,如图二; 3、找到用的是哪种加密方式,如: cr…...

用Java做智能客服,基于私有知识库
构建Java智能客服系统的整体思路 使用Java构建智能客服系统的整体思路是: 首先将客服QA文档以Word形式导入到系统中,通过向量化处理存入知识库。 当用户提出问题时,系统会根据问题内容从知识库中检索相关的上下文信息,并结合大…...
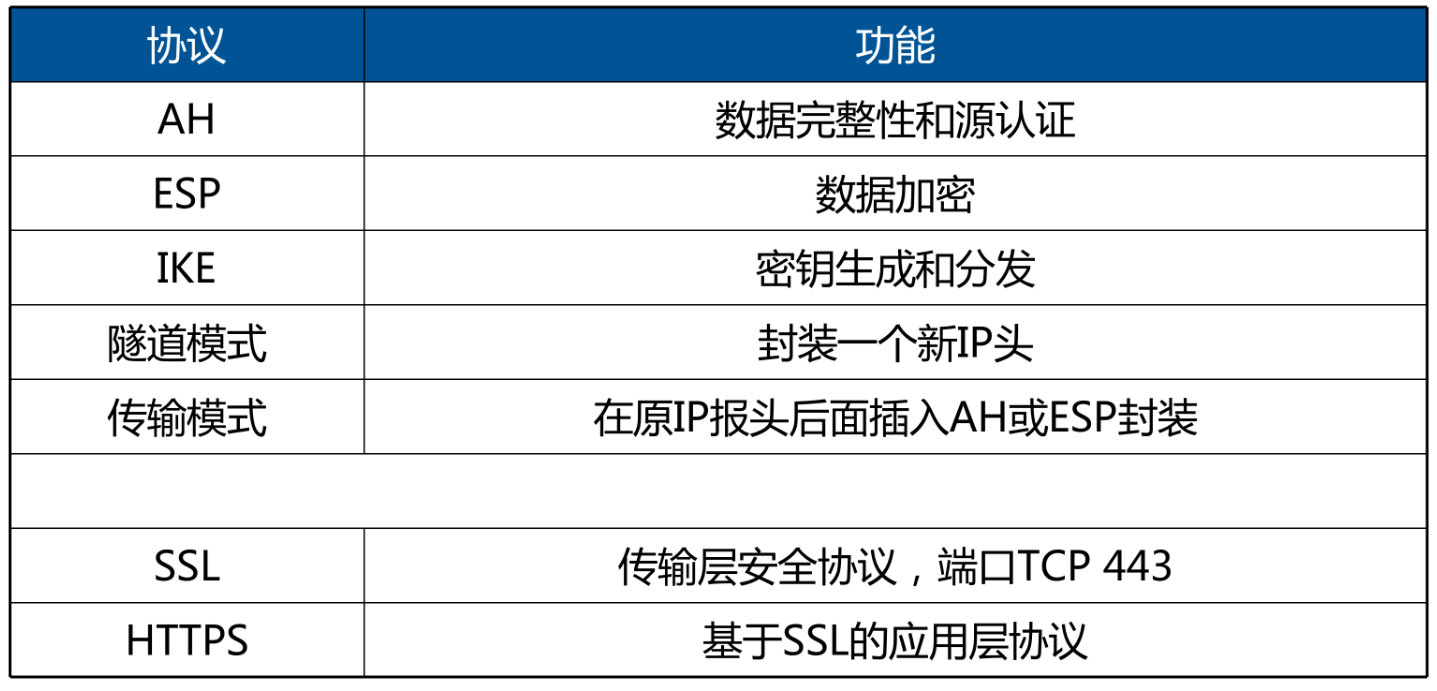
软考(网工)——网络安全
文章目录 🕐网络安全基础1️⃣网络安全威胁类型2️⃣网络攻击类型 🕑现代加密技术1️⃣私钥密码/对称密码体制2️⃣对称加密算法总结3️⃣公钥密码/非对称密码4️⃣混合密码5️⃣国产加密算法 - SM 系列6️⃣认证7️⃣基于公钥的认证 🕒Hash …...

如何给手机换ip地址
在当今数字化时代,IP地址作为设备在网络中的唯一标识,扮演着举足轻重的角色。然而,有时出于隐私保护、网络访问需求或其他特定原因,我们可能需要更改手机的IP地址。本文将详细介绍几种实用的方法,帮助您轻松实现手机IP…...

kafkamanager安装
一.下载kafkamanager2.0 https://download.csdn.net/download/cyw8998/89892482 二.修改配置文件 解压缩 unzip kafka-manager-2.0.0.0.zip vim application.conf /opt/module/kafka-manager-2.0.0.0/conf/application.conf 添加以下内容:(连接zooke…...

笔记本电脑U口保护分享
在前司时候,经常遇到各种硬件类的问题,但是之前没时间分享,现在来给大家分享一下,常见的问题及如何保护。 1.接口接触不良。这个一般发生于使用时间长了,可以用细砂纸,轻轻摩擦后再进行尝试。 2.接口失灵…...

OpenCV高级图形用户界面(20)更改窗口的标题函数setWindowTitle()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在OpenCV中,cv::setWindowTitle函数用于更改窗口的标题。这使得您可以在程序运行时动态地更改窗口的标题文本。 函数原型 void cv::…...

嵌入式裸机开发中的轻量级定时调度方案
1. SmartTimer:裸机环境下的轻量级定时调度方案在嵌入式开发中,定时任务管理是个永恒的话题。我最近在做一个空气质量监测项目时,发现传统的裸机编程方式在处理多个定时任务时显得力不从心。硬件定时器资源有限,软件标志位管理又容…...

springboot基于Hadoop的健康饮食推荐系统的设计与实现_5578bn9k_yh025
前言 随着人们生活水平的提高和健康意识的增强,越来越多的人开始关注自己的饮食习惯和健康状况。然而,传统饮食推荐方式往往缺乏个性化与数据支撑,难以满足用户多样化需求。SpringBoot基于Hadoop的健康饮食推荐系统应运而生,旨在为…...
投)
记录复现多模态大模型论文OPERA的一周工作()投
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

终极模组管理器:XXMI启动器让多游戏模组管理变得简单高效 [特殊字符]
终极模组管理器:XXMI启动器让多游戏模组管理变得简单高效 🚀 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否曾经为《原神》《星穹铁道》《鸣潮》等…...

选择AutoCAD许可管理工具的七大关键评估维度
智能选择AutoCAD许可管理工具的七大关键维度你正在为AutoCAD许可证管理找工具,这是个门槛高的活,就是不光是没门路我帮你梳理出七大关键评估维度,帮你少踩坑,多省钱。许可方式匹配是否够精细?AutoCAD的许可机制越细化&…...

知识图谱嵌入评估实战:从MRR到HITS@n的指标解析与应用
1. 知识图谱嵌入评估指标入门指南 第一次接触知识图谱嵌入评估时,我被各种缩写搞得晕头转向。MRR、MR、HITSn这些指标就像天书一样,直到我在实际项目中踩了几个坑才真正理解它们的意义。现在我就用最直白的语言,带你快速掌握这些核心指标。 …...

GDB调试利器:gdb-stl-views解析STL容器内部数据
1. 为什么需要gdb-stl-views 调试C程序时,STL容器是我们最常打交道的对象之一。但当你用GDB的print命令查看一个std::vector时,看到的可能是一堆让人头晕的内部实现细节,比如_M_impl、_M_start这类晦涩的成员变量。这就像你想看一本书的目录&…...

【计算机网络八股】【欧弟求职】TCP相关
TCP 必须能讲清: 三次握手 / 四次挥手(状态流转)拥塞控制: slow startcongestion avoidancefast retransmit / fast recovery 滑动窗口重传机制(RTO / dup ack)TIME_WAIT 为什么存在高并发下 TIME_WAIT 堆积…...

ESP32无人机飞控C++工具库UAV_utils详解
1. UAV_utils 库概述UAV_utils 是一个面向无人机(Unmanned Aerial Vehicle)固件开发的轻量级 C 工具库,专为基于 ESP32 平台的飞控系统设计。其核心定位并非替代成熟飞控框架(如 PX4 或 ArduPilot),而是为嵌…...
)
pymilvus操作milvus向量数据库笔记(二)
文章目录表结构迁移通过代码迁移内容有点多,拆出来一篇。表结构迁移 导出schema太难看了。 通过代码迁移...