浅谈AGI时代的“数据枢纽”——向量数据库
一、前言
人工智能的关键,不只是构建好算力、算法、模型,更重要的是做好数据的清洗、处理、挖掘等问题。一定程度上,智能时代,企业数据处理能力有多强,决定了业务发展的天花板有多高。
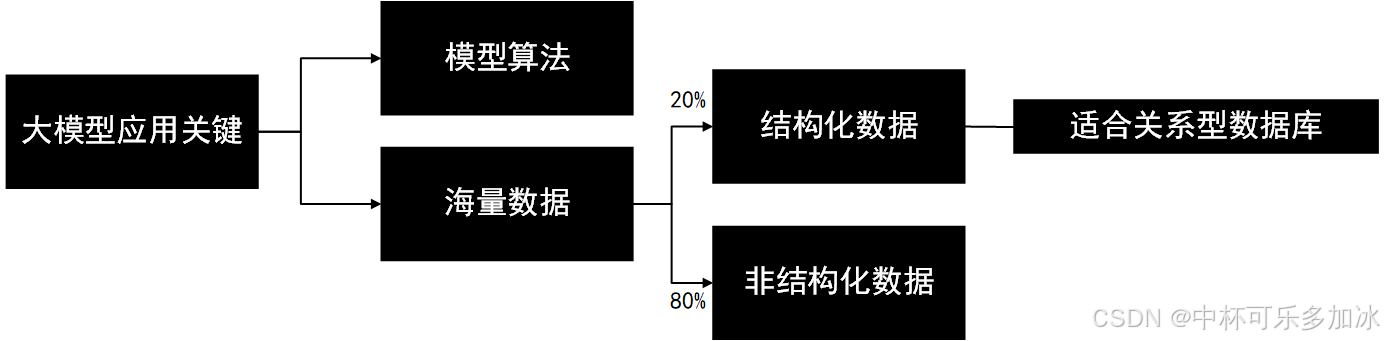
在企业数智化转型过程中,文本、图片、视频等多模态的、非结构化数据的使用需求不断增加,而在复杂的企业数据处理中,适合关系型数据库的,结构化数据仅有20%,其余80%是文本、图像、视频、文档等非结构化数据。
而能力再强大的 LLM 也只能取代人部分学习和推理能力,无法取代存储和访问数据的能力;参数再多的 LLM 也不能仅凭基于通用数据的训练就能精确表达企业内部海量且丰富的数据。而处理这类数据,才是私有化场景的主要需求。
- 一方面,企业很难把自己具有核心竞争力的数据放到大模型中去训练;
- 另一方面,企业的业务数据变化速度快,且实时性强,因此私有化部署后的大模型、在数据层上也很难做到秒、天级别的更新。

二、向量数据库概述
AI 的全流程其实都是围绕着向量的数学运算,向量是基于不同特征或属性来描述对象的数据表示。每个向量代表一个单独的数据点,例如一个词或一张图片,由描述其许多特性的值的集合组成。这些变量有时被称为“特征”或“维度”。例如,一张图片可以表示为像素值的向量,整个句子也可以表示为单词嵌入的向量。一些常用的数据向量如下:
- 图像向量,通过深度学习模型提取的图像特征向量,这些特征向量捕捉了图像的重要信息,如颜色、形状、纹理等,可以用于图像识别、检索等任务;
- 文本向量,通过词嵌入技术如Word2Vec、BERT等生成的文本特征向量,这些向量包含了文本的语义信息,可以用于文本分类、情感分析等任务;、
- 语音向量,通过声学模型从声音信号中提取的特征向量,这些向量捕捉了声音的重要特性,如音调、节奏、音色等,可以用于语音识别、声纹识别等任务。
而向量数据库是一种用于存储和检索以及分析大规模向量数据的数据库系统,其使用专门的数据结构和算法来处理向量之间的相似性计算和查询,通过构建索引结构,快速找到最相似的向量,满足各种应用场景中的查询需求。
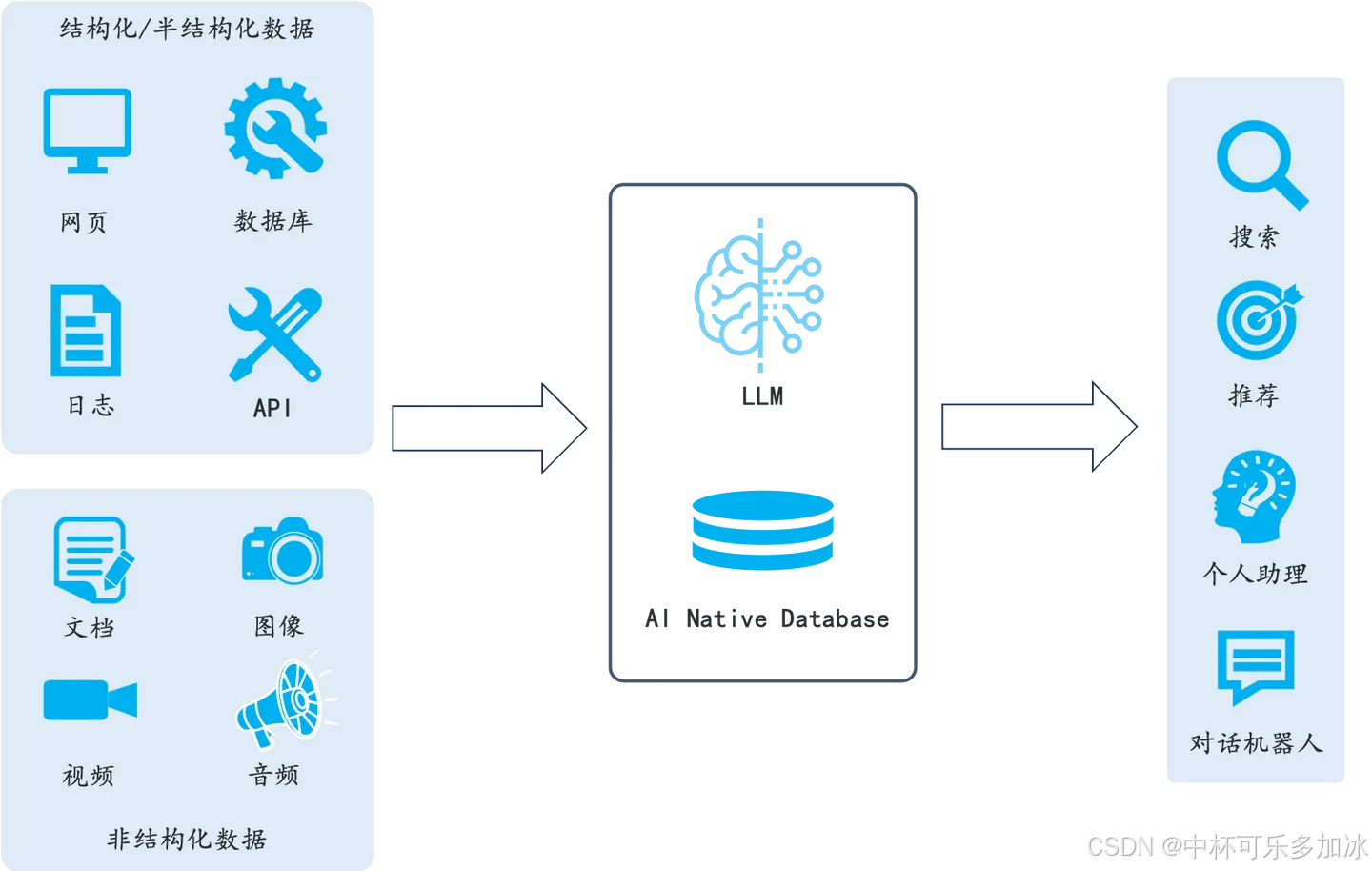
向量数据库不是一款单纯的向量数据库,而是一种为支持整个AI工作流程而设计的综合性数据库系统。其提供向量搜索、全文搜索和结构化数据检索,可以支撑大模型对于复杂数据的获取需求,能够配合大模型共同支撑起企业门户业务需求的基础软件产品。
区别于传统数据库,向量数据库主要有以下特点:
- 能够处理半/非结构化的数据:传统数据库主要处理结构化数据,如数值、字符串、时间等。而向量数据库则专注于处理向量数据,这些向量数据通常由多个数值组成,能够表示图像、音频、文本等复杂数据的特征或属性
- 远超传统关系型数据库的规模:传统的关系型数据库管理1亿条数据已经是拥有很大的业务流量,而向量数据库则专注于处理向量数据,使用向量空间模型来存储数据,这些向量在多维空间中相互关联。向量数据库可以把复杂的非结构化数据,处理成多维逻辑的坐标值,与大模型进行连接,数据处理效率比传统方式提升10倍
- 查询方式不同:传统数据库查询通常为精确查询,结果一般为查到或者未查到,而向量数据库不仅支持全文检索,还能将全文检索与结构化数据检索相结合,提供更为丰富和灵活的查询方式。这种结合能力使得向量数据库能够更好地服务于AI应用,满足复杂多样的查询需求。
三、向量数据库工作原理
3.1、大模型的幻觉问题
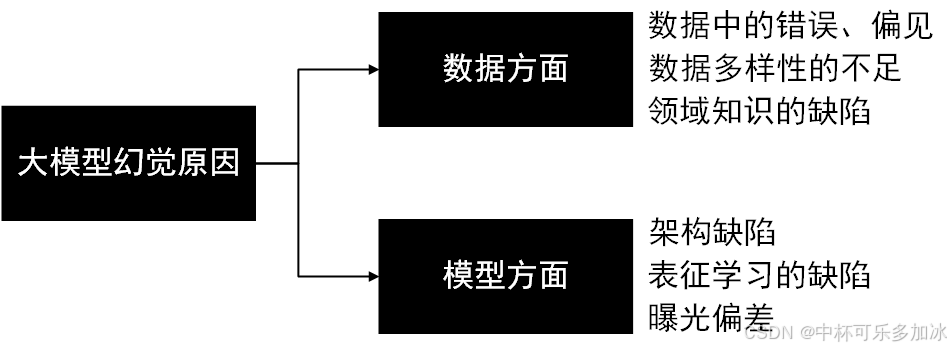
大模型的幻觉问题,尤其是在自然语言处理(NLP)和生成式人工智能(AI)领域,是一个日益受到关注的重要议题。随着深度学习技术的进步,特别是大型预训练语言模型(如GPT系列、BERT等)的兴起,模型能够生成高度连贯、自然的语言文本,极大地推动了AI在内容创作、对话系统、问答系统等方面的应用。然而,这种能力也伴随着潜在的“幻觉”风险,即模型可能生成不符合事实、逻辑错误或完全虚构的内容。幻觉问题的具体表现如下:
Intrinsic幻觉:
定义:这类幻觉指的是模型生成的内容与用户的具体指令或上下文环境存在不匹配或矛盾。例如,用户请求模型根据某个特定主题编写一篇文章,但模型最终生成的内容却偏离了这个主题,或者在文章中出现了与主题无关的信息。
影响:Intrinsic幻觉降低了模型的准确性和可用性,因为用户期望得到的是符合其需求和上下文的内容。
Extrinsic幻觉:
定义:这类幻觉指的是模型生成的内容与现实世界中的事实不符,或是完全基于虚构的信息。这可能是因为模型在训练过程中没有接触到足够广泛和准确的知识库,导致其在生成文本时无法区分真实与虚构。
影响:Extrinsic幻觉可能误导用户,传播错误信息,甚至在某些敏感领域(如医疗、法律)造成严重后果。
为了应对这一问题,业界提出了包括Fine-tuning(微调)、Prompt Engineering(提示工程)、RAG(Retrieval-Augmented Generation,增强检索生成)以及综合方案等多种解决方案。

- Fine-tuning是一种通过特定领域数据对预训练模型进行针对性优化的方法。其核心在于利用特定任务的数据集对预训练好的大模型进行进一步训练,以提升模型在特定任务上的性能。通过微调,模型能够学习并适应特定领域的语言模式和知识,从而减少生成无根据或错误内容的风险。此外,微调过程中超参数的调整也至关重要,如学习率、批次大小和训练轮次等,这些参数需要根据特定任务和数据集进行精细调整,以确保模型训练的有效性和性能。
- Prompt Engineering是一种通过精心设计提示词(Prompt)来引导模型生成更加准确和符合期望内容的方法。提示词是用户向模型发出的指令,其质量直接影响到模型生成结果的准确性和相关性。高质量的提示词应该具体、丰富且少歧义,能够清晰地描述任务要求和期望输出。通过不断优化和调整提示词,可以引导模型生成更加准确和有用的内容,从而减少幻觉问题的发生。
- RAG技术是一种结合检索和生成的技术方法,旨在通过外部知识源来增强模型的生成能力。在生成文本时,模型首先从一个大规模的知识库或文档集合中进行检索,获取与当前生成任务相关的信息,然后利用这些检索到的信息来辅助生成更加准确、全面和有依据的文本。这种方法能够有效减少模型生成无根据或错误内容的风险,提高生成内容的质量和可靠性。同时,RAG技术还具有可解释性强、易于定制等优点,能够根据不同领域和任务的需求进行灵活调整。
- 综合方案通常结合上述多种方法,通过数据清洗、数据增强、网络架构调整、正则化和约束、集成学习等多种手段来提高模型的鲁棒性和准确性
3.2、向量数据库与RAG
RAG,全称为"Retrieval-Augmented Generation",即“检索增强的生成”,是一种结合了检索(Retrieval)和生成(Generation)的深度学习模型,LLM在回答问题或生成文本时,RAG会先从大量文档中检索出相关的信息,然后基于这些信息生成回答或文本,从而提高预测质量。这种模型主要用于自然语言处理(NLP)任务,尤其是在需要理解和生成文本的场景中。
RAG模型的核心原理可以分为以下几个步骤:
检索阶段(Retrieval Phase): 在这个阶段,模型首先接收到用户的查询或问题。然后,模型会从预先存储的文档或数据集中检索出与查询最相关的文档或信息片段。
编码阶段(Encoding Phase): 检索到的文档或信息片段,以及用户的原始查询,会被编码成高维向量。这通常通过使用Transformer架构的编码器来完成,它可以捕捉文本的语义信息。
融合阶段(Fusion Phase): 编码后的向量会进行融合,以便将检索到的信息与用户的查询结合在一起。这一步骤有助于模型更好地理解上下文,并生成与检索到的内容相关的响应。
生成阶段(Generation Phase): 最后,模型使用解码器生成对用户查询的响应。
解码器通常也是基于Transformer架构,它可以根据融合后的向量生成文本。
RAG模型的优势在于它能够结合检索到的外部知识与模型自身的语言生成能力,从而提供更加丰富、准确和相关的回答。这种模型特别适用于需要广泛知识背景的任务,如开放域问答、事实核查等。
文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化(如One-Hot、Word2Vec、GloVe、BERT等embedding技术),然后把向量存到向量数据库里边。用户提出问题后,对问题语句也进行向量化,以余弦相似度或点积等指标,计算在数据库中和问题向量最相似的top k个文档片段,作为上下文输入到大模型中。
三、基于向量数据库的大模型知识库
向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。
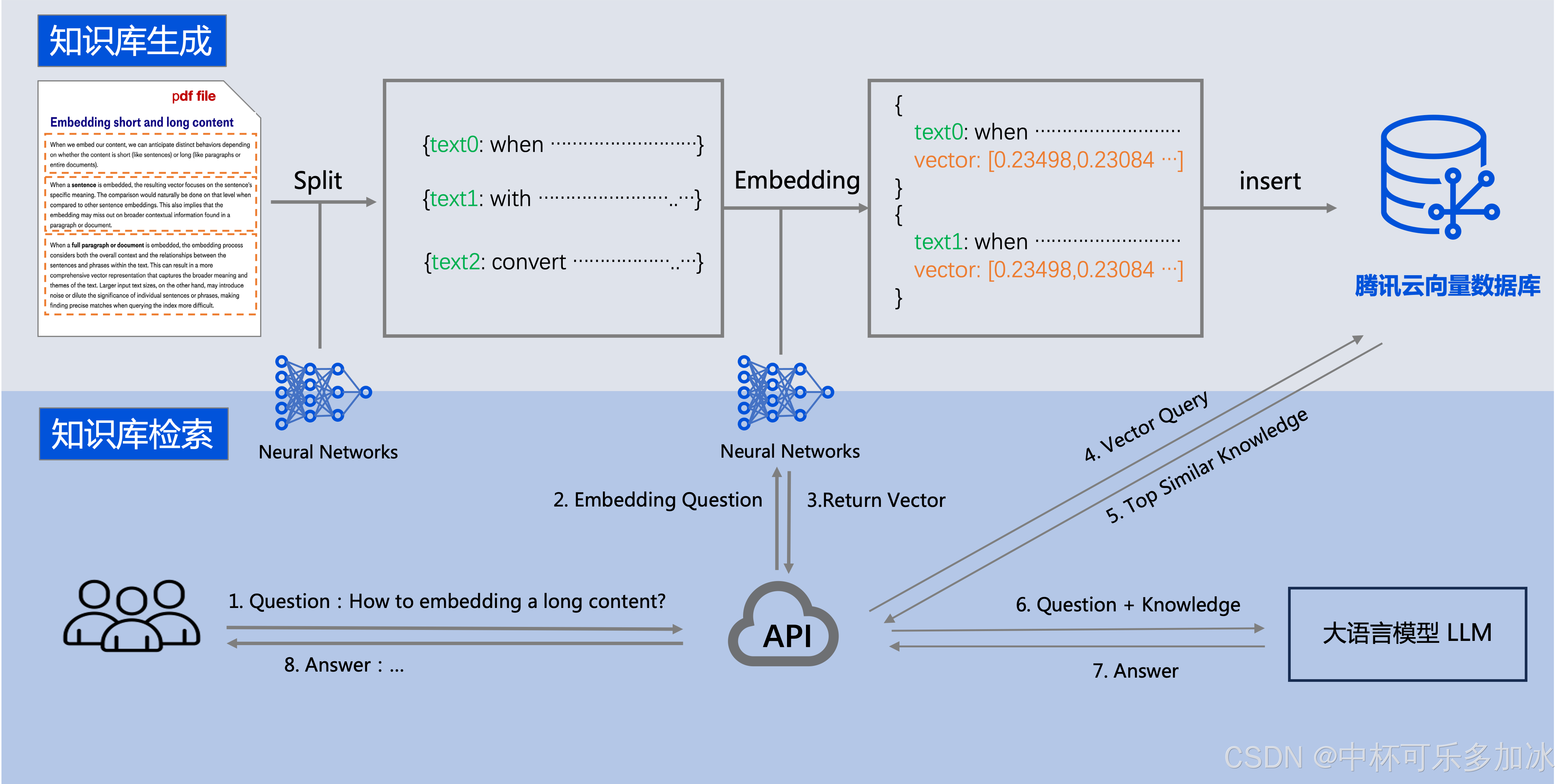
在这些场景中,用户可以通过自然语言提问获取相关信息,例如查询产品信息、控制家居设备等。通过使用向量数据库来存储和检索相关的向量数据,问答系统可以更快速、准确地响应用户的请求,提高用户体验。
相关文章:
浅谈AGI时代的“数据枢纽”——向量数据库
一、前言 人工智能的关键,不只是构建好算力、算法、模型,更重要的是做好数据的清洗、处理、挖掘等问题。一定程度上,智能时代,企业数据处理能力有多强,决定了业务发展的天花板有多高。 在企业数智化转型过程中&#x…...

生成 Excel 表列名称
Excel 大家都用过,它的列名是用字母编号的,A 表示第一列,B 表示第二列,AA 表示第27列,AB 表示第28列等等。 现给定一个数字,如何得到列名称呢。比如输入28,输出 AB。 一开始以为就是一个简单的…...

基于yolov10的烟雾明火检测森林火灾系统python源码+pytorch模型+评估指标曲线+精美GUI界面+数据集
【算法介绍】 基于YOLOv10的烟雾明火检测森林火灾系统是一种先进的火灾预警系统,它结合了深度学习和计算机视觉技术,能够实时检测和分析森林中的烟雾和明火,从而有效预防和控制森林火灾的发生。 该系统主要基于YOLOv10模型进行构建…...

UltraISO(软碟通)制作U盘制作Ubuntu20.04启动盘
目录 一、启动盘制作 1、工具准备 2、打开UltraISO后,点击左上角的文件,在打开的下拉项中,选择打开准备好的Ubuntu系统20.04 LTS镜像文件(ubuntu-20.04-desktop-amd64.iso); 3、然后点击启动->写入硬盘映像 4、在弹出的窗…...

【EtherCAT实践篇一】TwinCAT 3安装、使用
TwinCAT 基于 PC 的开放式控制技术 倍福推出的基于 PC 的控制技术定义了自动化领域的全球标准。在软件方面,1996 年推出的 TwinCAT(The Windows Control and Automation Technology,基于 Windows 的控制和自动化技术)自动化套件是…...
4、CSS3笔记
文章目录 四、CSS3CSS3简介css3概述CSS3私有前缀什么是私有前缀为什么要有私有前缀常见浏览器私有前缀 CSS3基本语法CSS3新增长度单位CSS3新增颜色设置方式CSS3新增选择器CSS3新增盒模型相关属性box-sizing 怪异盒模型resize 调整盒子大小box-shadow 盒子阴影opacity 不透明度 …...

Docker无法拉取镜像解决办法
Docker 无法拉取镜像解决办法 一.现象描述 在docker拉取镜像的时候重复拉取镜像然后超时。 二.解决办法 1.配置国内镜像源地址加速 vi /etc/docker/daemon.json在文件中增加如下内容 { "registry-mirrors": ["https://docker.m.daocloud.io","h…...

Ubuntu 20.04安装Qt 5.15(最新,超详细)
Ubuntu 20.04安装Qt 5.15 1. 准备注册Qt账号安装依赖下载安装工具 2. 安装3. 测试参考 前言 Qt 是一个跨平台的应用程序框架,它支持开发 C 图形用户界面应用程序。Qt 可以用于开发运行在多种操作系统上的应用程序,包括 Windows、Linux、macOS 和各种移动…...

桂林旅游一点通:SpringBoot平台应用
3系统分析 3.1可行性分析 通过对本桂林旅游景点导游平台实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本桂林旅游景点导游平台采用SSM框架,JAVA作…...

【WPF】04 Http消息处理类
这里引入微软官方提供的HttpClient类来实现我们的目的。 首先,介绍一下官方HttpClient类的内容。 HttpClient 类 定义 命名空间: System.Net.Http 程序集: System.Net.Http.dll Source: HttpClient.cs 提供一个类,用于从 URI 标识的资源发送 HTTP 请…...

如何精准设置线程数,提升系统性能的秘密武器!
线程数设定多少更合适? 线程数的设定需要根据任务的类型、系统资源、以及并发需求来进行权衡。设定合适的线程数可以有效提升系统的性能,但设置过多或过少都会影响程序的效率。以下是一些关键因素和计算方法,用于帮助确定最合适的线程数。 …...

正则表达式:从入门到精通
正则表达式(Regular Expression,简称 regex)是一种强大的文本匹配和处理工具。它可以用于搜索、替换、验证和提取文本中的特定模式。本文将带您深入了解正则表达式的各个方面,从基础知识到高级技巧。 1. 基础知识 1.1 什么是正则表达式? 正则表达式是由一系列字符和特殊…...
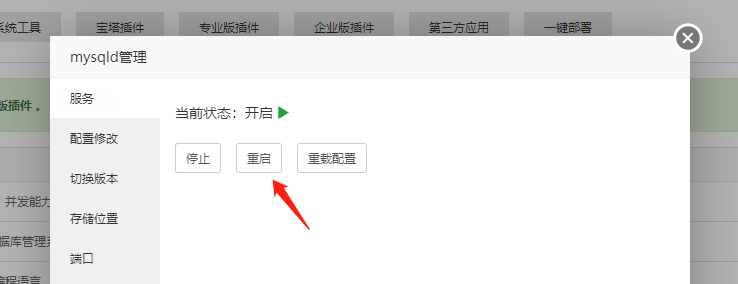
CRMEB标准版Mysql修改sql_mode
数据库配置 1.宝塔控制面板-软件商店-MySql-设置 2.点击配置修改,查找sql-mode或sql_mode (可使用CtrlF快捷查找) 3.复制 NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION 然后替换粘贴,保存 注:MySQL8.0版本的 第三步用…...
linux驱动访问的地址为虚拟地址
在Linux驱动程序中,访问的内存地址通常是虚拟地址。这是因为Linux操作系统采用了虚拟内存管理机制,所有的用户空间和内核空间的内存地址都是虚拟地址。下面是一些关键点,以帮助更好地理解这个概念: 虚拟地址与物理地址࿱…...
基于SpringBoot+Vue+uniapp微信小程序的社区门诊管理系统的详细设计和实现(源码+lw+部署文档+讲解等)
项目运行截图 技术框架 后端采用SpringBoot框架 Spring Boot 是一个用于快速开发基于 Spring 框架的应用程序的开源框架。它采用约定大于配置的理念,提供了一套默认的配置,让开发者可以更专注于业务逻辑而不是配置文件。Spring Boot 通过自动化配置和约…...

使用WPF写一个简单的开关控件
<Window x:Class"WPF练习.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.microsoft.com/expression/blend/2008"xm…...

FPGA采集adc,IP核用法,AD驱动(上半部分)
未完结,明天补全 IP核:集成的一个现有的模块 串口写好后基本不会再修改串口模块内部的一些逻辑,将串口.v文件添加进来,之后通过他的上层的接口去对他进行使用,所以我们打包IP,之后就不用去添加源文件了&a…...

MongoDB 如何做mapreduce
以下是在MongoDB中使用MapReduce的详细步骤和相关说明: 1. MapReduce的概念 MapReduce是一种用于大规模数据处理的编程模型,它由两个主要阶段组成:Map阶段和Reduce阶段。在MongoDB中,MapReduce操作允许在服务器端对数据进行批量…...

Vue是一套构建用户界面的渐进式框架,常用于构建单页面应用
学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技巧(编写中……) 5、面经吐血整理的 面试技…...

c++ 桶排序(看这一篇就够了)
1. 概述 桶排序(Bucket Sort)又称箱排序,是一种比较常用的排序算法。其算法原理是将数组分到有限数量的桶里,再对每个桶分别排好序(可以是递归使用桶排序,也可以是使用其他排序算法将每个桶分别排好序&…...

超越目标空间:多模态多目标优化算法的决策空间评价指标深度解析
1. 为什么我们需要关注决策空间的评价指标? 在传统的多目标优化问题中,我们通常只关注目标空间的性能表现。比如常见的IGD(反转世代距离)和HV(超体积)指标,它们能够很好地衡量解集在目标空间的分…...

STM32堆栈原理与内存管理实践指南
1. 堆栈基础概念解析在嵌入式系统开发中,堆栈(Stack)是最基础也是最重要的内存管理机制之一。简单来说,堆栈就是一块特殊组织方式的内存区域,采用"后进先出"(LIFO)的原则进行数据存取。理解堆栈的工作原理对于STM32开发至关重要&am…...
)
基于雨流计数法的源-荷-储双层协同优化配置研究(Matlab代码实现)
👨🎓个人主页 💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰&a…...

k8s与docker compose的思考
1.稍微复杂2.ip会漂移,各种端口转发性能有所损失。3.占用一定的资源4.master需要高可用5.更适合web无状态docker-compose则比较简单,搭建本地环境就一个配置文件的事情,简直是本地test环境神器。...
引发的UE6.5符号丢失问题全解析,微软/EPIC联合补丁已验证)
C++27模块二进制接口(MBI)引发的UE6.5符号丢失问题全解析,微软/EPIC联合补丁已验证
第一章:C27模块二进制接口(MBI)与UE6.5符号丢失问题的本质溯源C27标准草案中正式引入的模块二进制接口(Module Binary Interface, MBI)旨在终结传统头文件包含机制带来的ODR违规、编译冗余与符号污染问题。MBI通过标准…...

Planify Nextcloud集成:私有云环境下的安全任务同步终极指南
Planify Nextcloud集成:私有云环境下的安全任务同步终极指南 【免费下载链接】planify Task manager with Todoist, Nextcloud & CalDAV support designed for GNOME 项目地址: https://gitcode.com/gh_mirrors/pl/planify Planify是一款专为GNOME设计的…...

Qwen2.5-7B-Instruct法律科技:合同审查要点+修改建议+合规风险等级评估
Qwen2.5-7B-Instruct法律科技:合同审查要点修改建议合规风险等级评估 1. 项目简介:智能法律助手的技术底座 Qwen2.5-7B-Instruct是阿里通义千问推出的旗舰级大模型,专门针对专业级文本交互场景深度优化。相比轻量版的1.5B和3B版本ÿ…...

文献综述怎么写?2026年AI工具盘点,让科研效率飙升!
还在为文献综述焦头烂额?信息爆炸时代,传统方法让你“盲人摸象”,效率低下,甚至因为遗漏关键文献而导致研究方向跑偏,被导师质疑选题深度。别担心!2026年的今天,AI工具已经彻底改变了科研生态。…...

visjs实战:5分钟搞定动态关系图,前端小白也能轻松上手
vis.js实战:5分钟从零构建动态关系图 第一次接触关系图可视化时,我被那些错综复杂却又井然有序的节点连线震撼到了。作为前端开发者,我们经常需要展示组织结构、社交网络或系统架构,而vis.js正是解决这类需求的瑞士军刀。不同于D3…...

Music Tag Web:一站式智能音乐标签管理解决方案
Music Tag Web:一站式智能音乐标签管理解决方案 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/music-tag-we…...