Detr论文精读
摘要:
作者提到,该方法将物体检测看做直接的集合预测,在传统的目标检测算法中,会先生成候选区域,然后对每个候选区域进行单独的预测(包括物体的分类和预测框的回归),集合预测就是直接基于原始图像生成一系列预测结果,避免了划分区域。(不知道我这样理解对不对)。这样能够简化流程。该模型基于二分匹配(我的理解是预测结果与真实结果之间的匹配)以及transformer机制(简单来说就是编码和解码过程)对目标进行检测的,并且是并行输出,(看来是直接拿transformer的结果来用啊,改都不改一点)。损失计算是全局损失,对预测集合和真实目标整体计算,(相比二阶段任务而言,损失也简化了好多流程)。最后还介绍了一下优势,在COCO数据集上取的了不错的效果,而且模型简单,泛化能力很强。
嗯嗯...,我来让ai读读文章来概括一下:(nonono,只是补充)。
二分强制匹配是一种特定的匹配机制,确保每个预测的物体都是唯一的,确实是是将预测结果和真实结果进行一对一的匹配,好处是模型被迫在输出的时候对每个物体生成唯一的预测,同一个物体不会被多次预测,(达到比非极大抑制更好的效果,但是如果图片中存在多个同一目标呢?),解决方案是detr中存在多个数量的预测。
基于集合的全局损失:损失关注的是预测集合和真实集合的整体损失,而不是逐个比较。
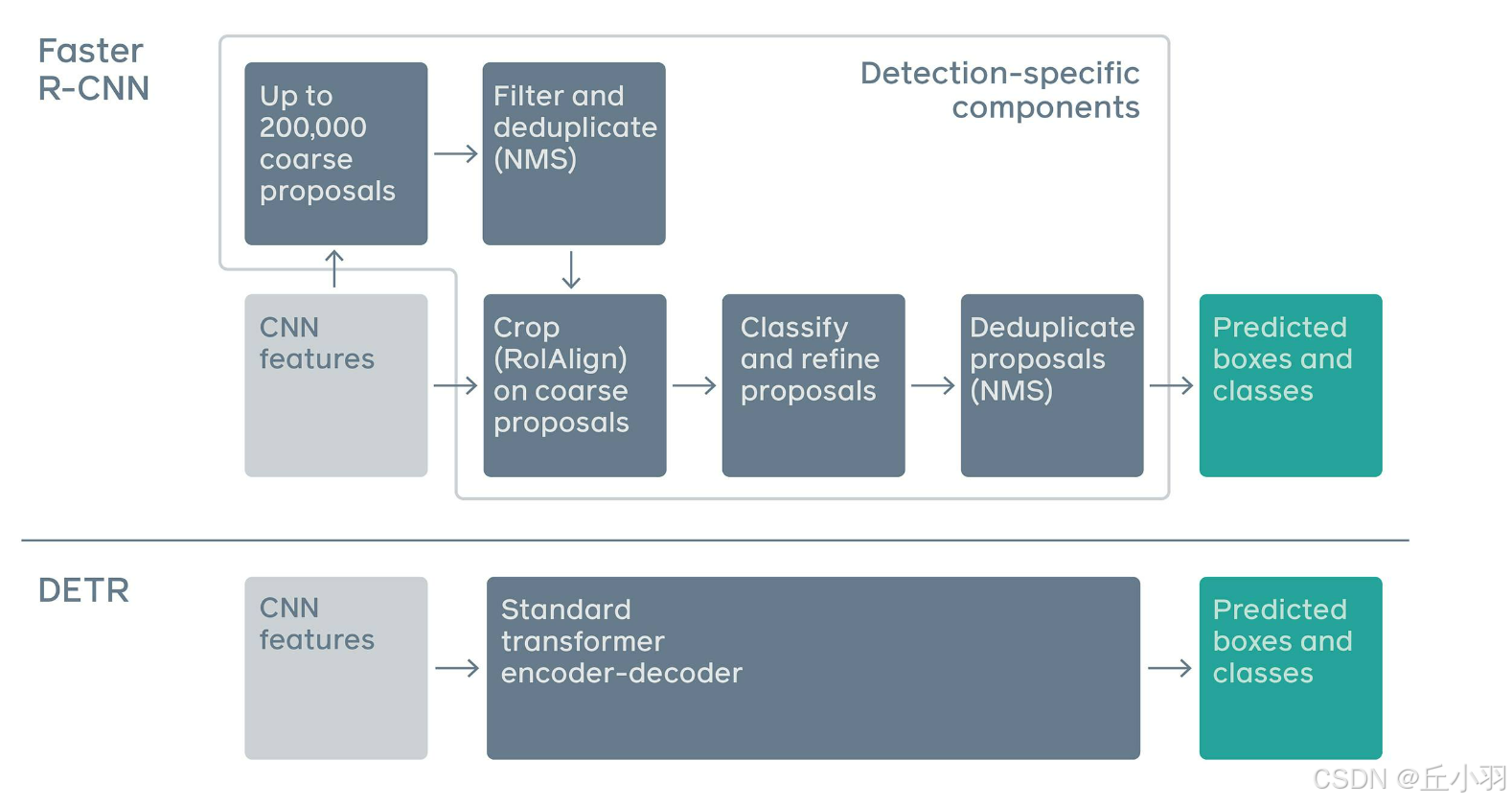
介绍:
第一段没什么很重要的信息,相当于是重复了一遍。第二段:自注意力机制精确的模拟了句子之中元素之间的相互关系,非常适应有限值的集合预测问题(所谓限制是指不能重复预测,看得出作者对非极大抑制方法有点瞧不起)。在这里科普一下自注意力机制:作用是在输入元素的时候,动态的关注其他的元素,计算查询与键之间的相似性,并为其赋予权重。第三段也是重复叙述,第四段,之前的检测器侧重于使用RNN的逻辑回归,我们的匹配机制直接分配预测框给真实框。第四段,重复叙述了优势之后指出对于小目标检测精度一般的问题。后面关于全景分割的部分不看,我们关注的只是目标检测,介绍部分还说,要在下文中寻找影响检测精度的重要因素。
相关工作:
(吐槽一下,内容很冗余,光是看到相关工作部分,我至少听他叙述了四五遍“我们的工作是直接预测,之前还没人做过”,“我们的模型在COCO数据集上表现很好”)。其实这些如果觉得必要,叙述三次就行了,没必要说这么多次。
2.1,这部分没有细讲,就是说传统的检测要避免重复检测,而我们的模型使用的是基于匈牙利算法的二分匹配,有效的避免了后处理,但是匈牙利算法是啥,没有具体叙述,具体数学计算不再赘述,匹配原理大概是这样的: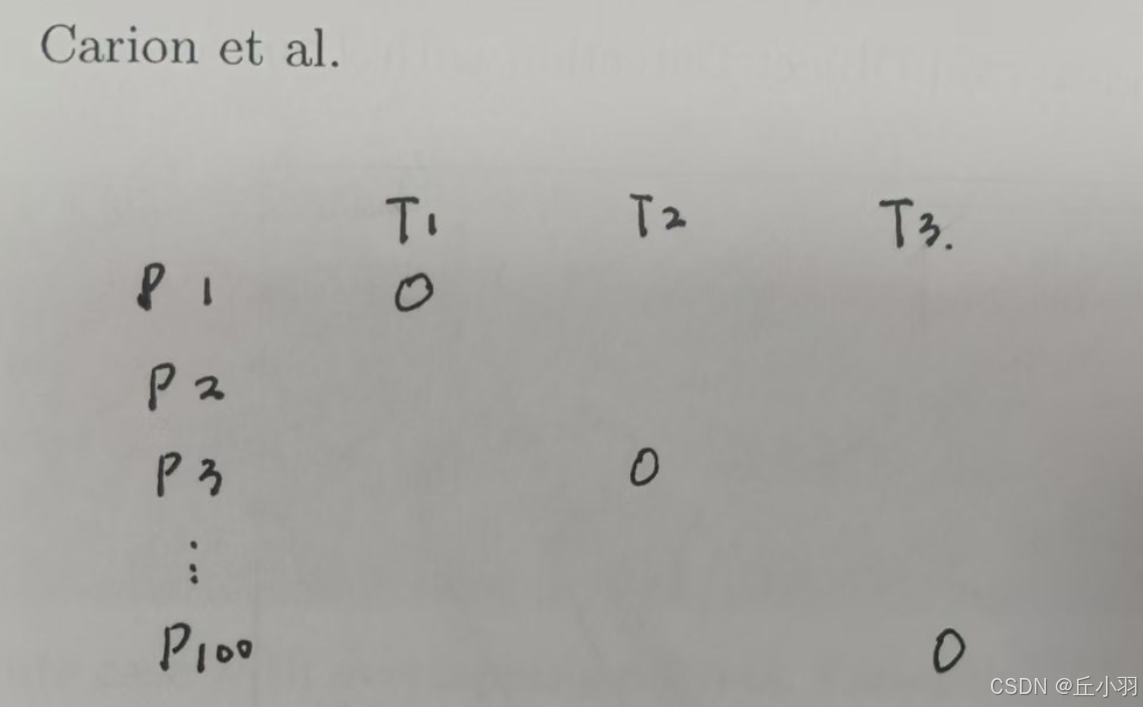
我们预测的目标有100个,但是图像中真实存在的只有3个,对于每一个真实目标,在所有目标框中选择唯一一个与之对应,但是不同真实目标不能选定同一个预测目标,使得损失最小化。
2.2主要是将transformer,其在自然语言处理中的地位,明显的优势是全局计算以及良好的记忆能力,本模型运用了transformer,并在算力成本以及全局计算能力之间折中。这里我再简要介绍一下transformer,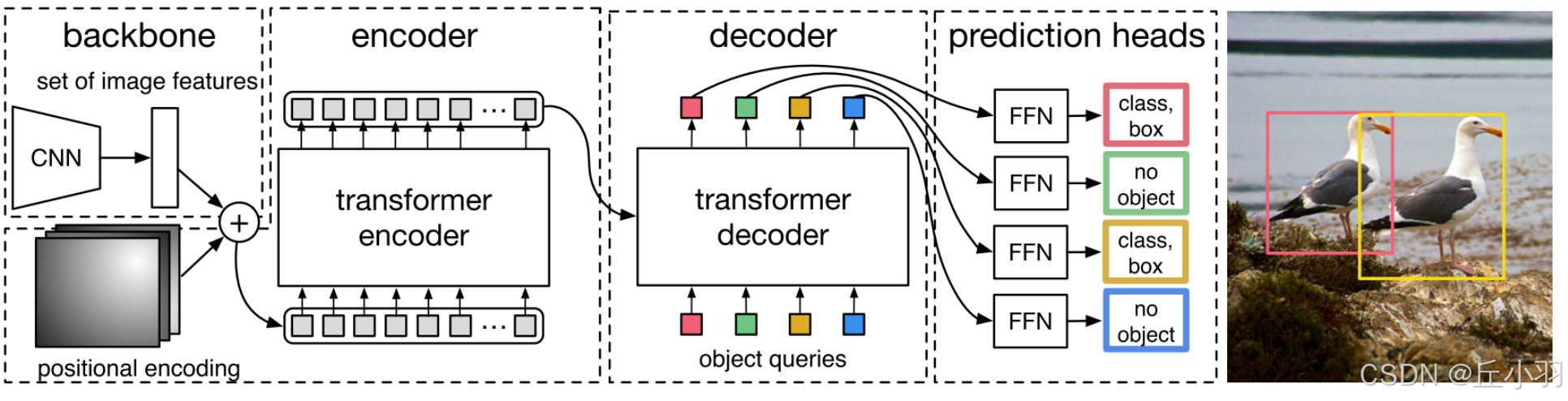
将原始图像提取特征,然后与位置编码相加,再推倒(我喜欢用这个词,虽然不是很合适)成一维,放入encoder模块,得到的结果输出到decoder中,在decode之前初始化100个queries(随机初始化),进行解码,解码结果与真实图像进行二分匹配。
详细讲解一下encoder过程,跟着代码看如下:
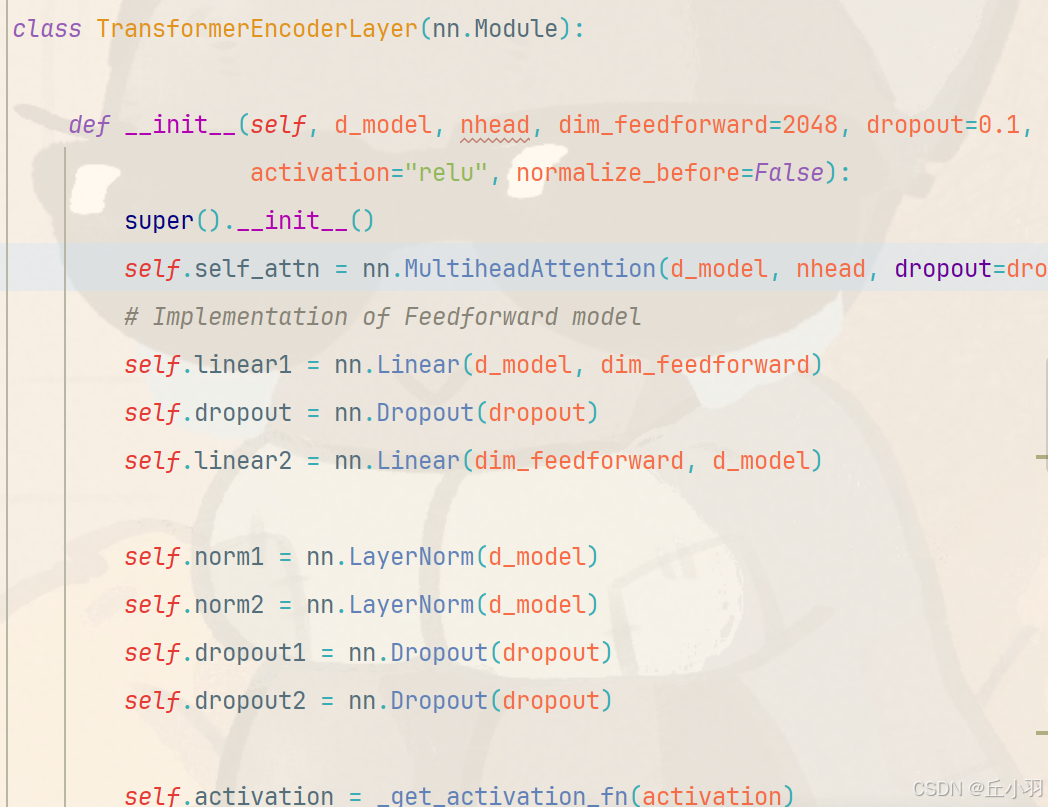
这里头是d_model是512,nhead是8(源码中),首先进入到多头注意力机制函数中......,有点不适合写进博客(上次写博客两万字都卡的要命,原代码内容量大,可能会影响博客原本的布局美感,在此只是截取一段):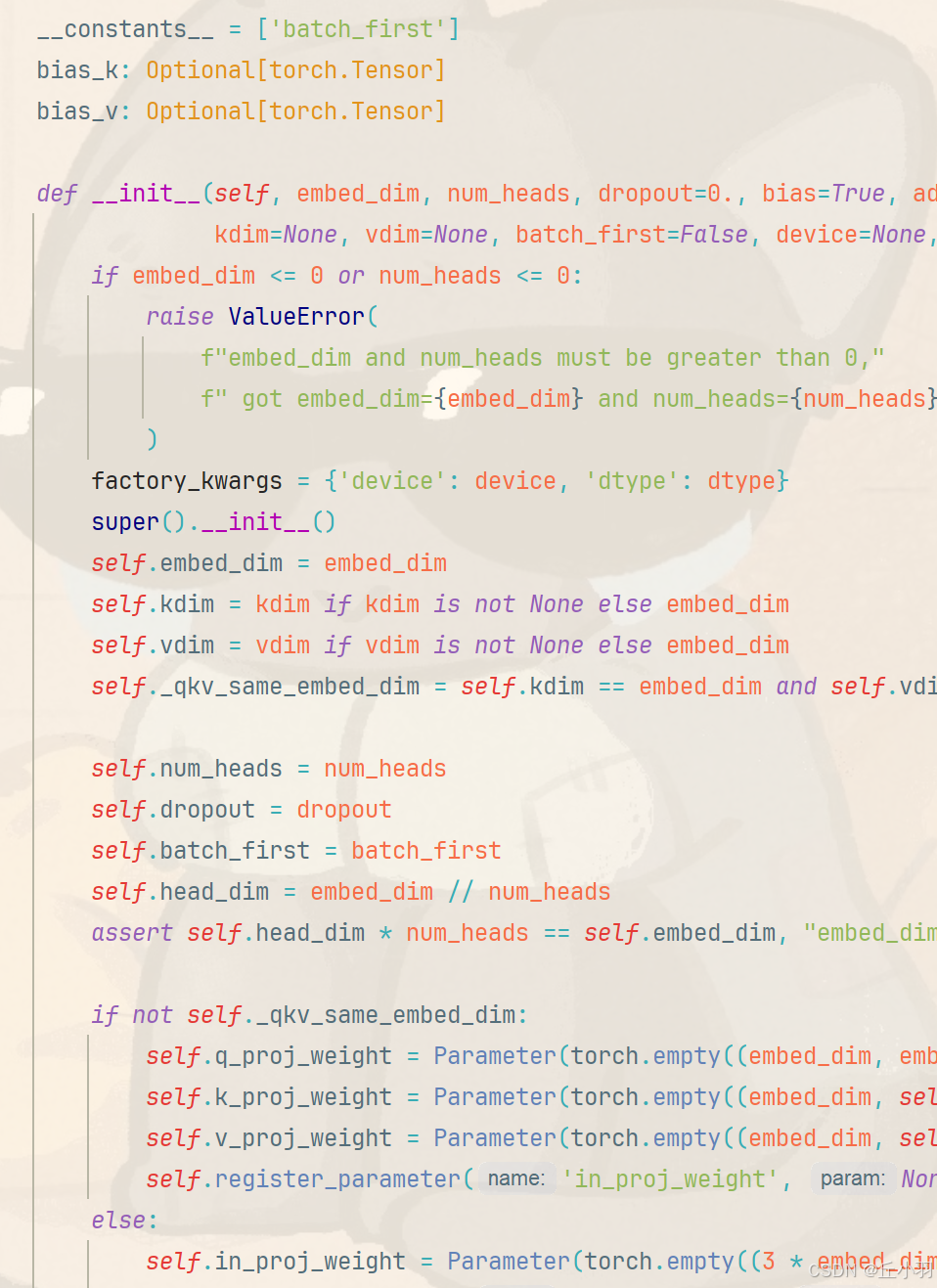
有点丑,直接问AI吧还是:
多头注意力机制先随机初始化三个权重矩阵,对应Q,K,V。使用随机初始化数值,满足Xavier 均匀分布,偏置是可以选择的,在源代码中默认存在偏置。
好像不对,自注意力机制是QKV都是x,也就是代码中的原始输入加上位置编码但是这样也就没有了学习的空间,没有从输入转化为合适的QKV部分(这个非常适合学习)。为了使之具有一定的自由度,我们生成了3个权重矩阵,将其与X相乘得到QKV。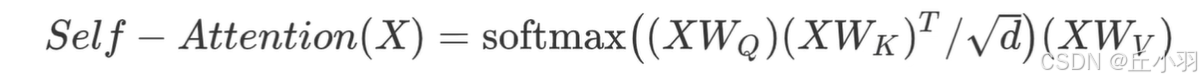
直接看forward过程:
def forward_post(self,src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):q = k = self.with_pos_embed(src, pos)src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src)return srcdef forward_pre(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):src2 = self.norm1(src)q = k = self.with_pos_embed(src2, pos)src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src2 = self.norm2(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))src = src + self.dropout2(src2)return srcdef forward(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):if self.normalize_before:return self.forward_pre(src, src_mask, src_key_padding_mask, pos)return self.forward_post(src, src_mask, src_key_padding_mask, pos)可选择的forward方法有两种,根据初始化在自注意力机制和前馈网络的顺序,分为post和pre,分别表示在自注意力和前馈网络之前进行归一化以及在自注意力和前馈网络之后进行归一化。
以post为例,首先先将位置嵌入,将q,k,v放入自注意力机制中,对于每个q,分别计算其与所有k相乘的结果,激活后乘以对应的v,得到对于每一个序列的output,将所有的output相加得到结果,(也就是输出),当然使用矩阵计算会更加方便。(保持形状相同)。
然后将dropout之后的finnaloutput与原始输入相加,再经过正则化处理。然后经过的一些列操作源码都很清晰的表示出来了,我将从图像输入到经过第一个encoder layer的过程绘制出来如下:(这里是单头的)。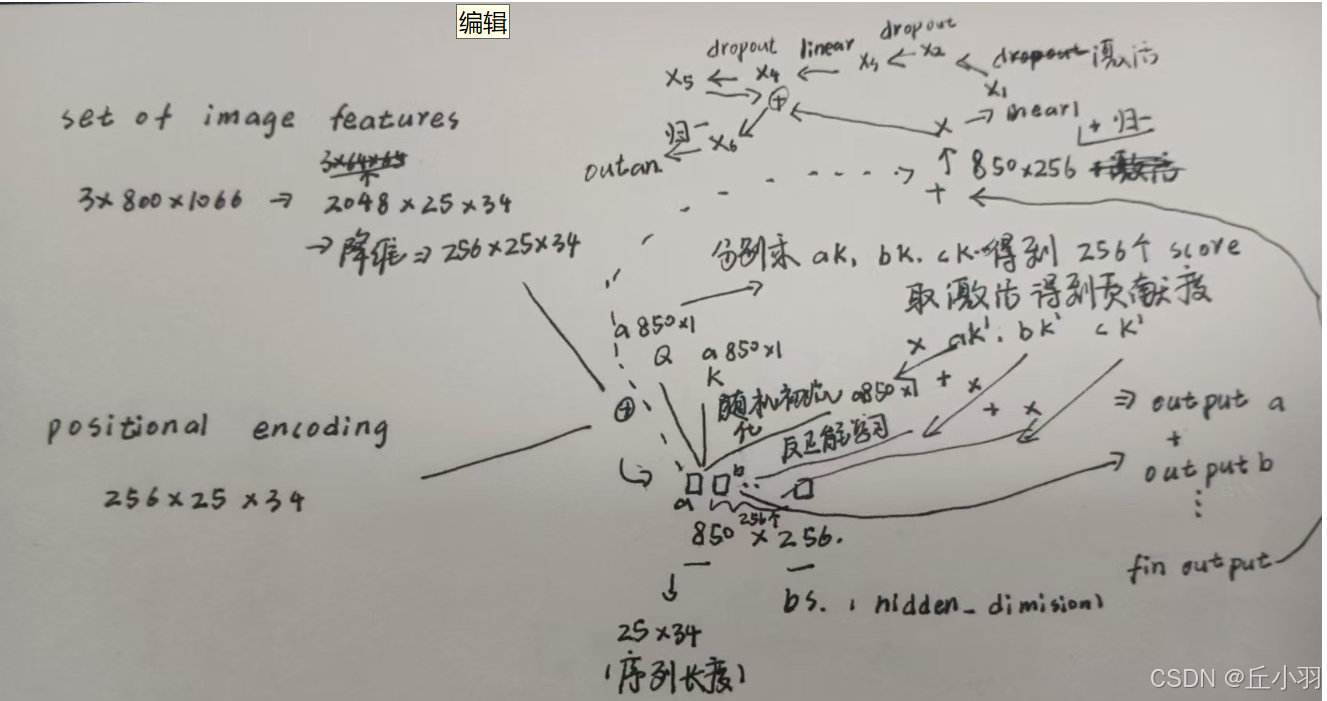 事实上,我们采用的是多头注意力机制,原理如下:
事实上,我们采用的是多头注意力机制,原理如下: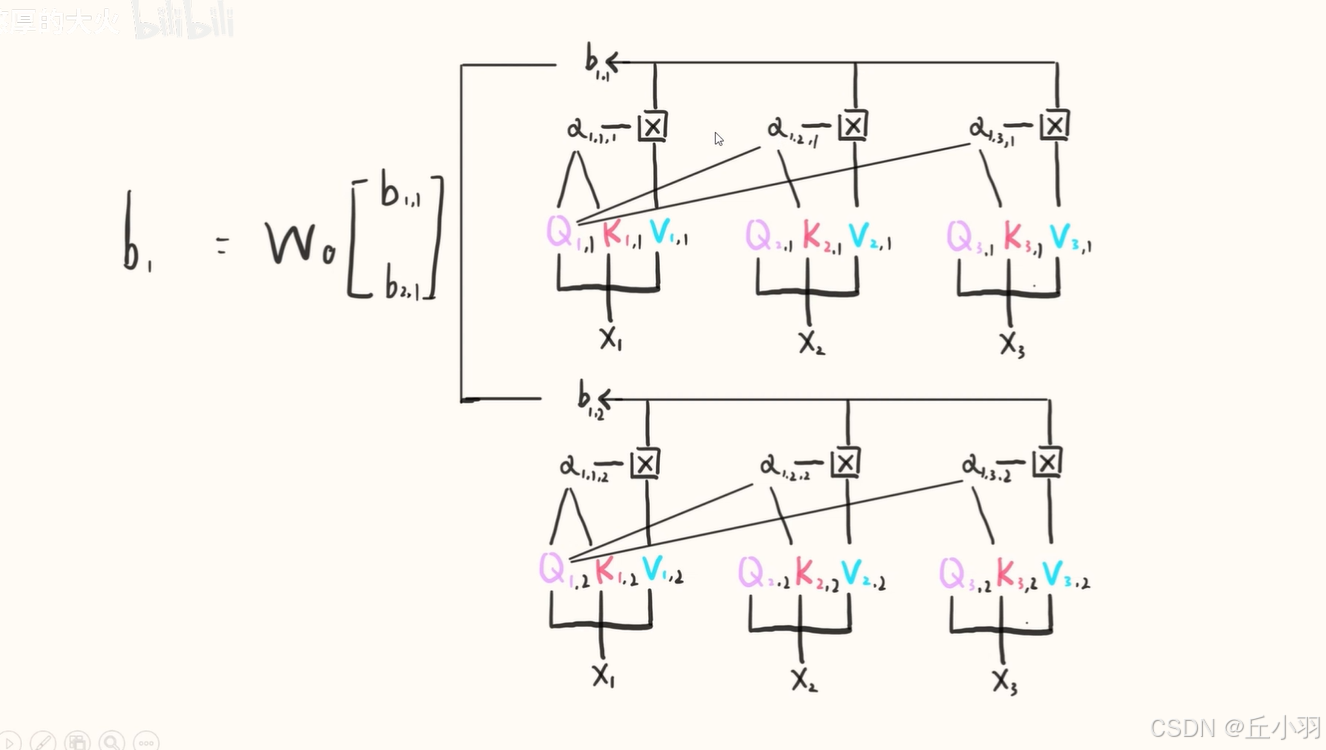
总结而来就是执行多个单头,然后将得到的结果按权重相加,这个权重也是学习来的,从讲故事的角度来说(当然,我认为作者是为了圆自己的说法,没有事实依据的胡扯):每个头会注意到不同的信息。
这里我使用的是forward_post:,在源码中是这样的:
整体是将6个encoder layers层上下接连起来,有意思的是,得到的输出本来就是在最后一个layer层里面归一化过了,但是仍要选择是否要进行进一步的归一化。最后得到输出。
为了清晰明了,作者还将最后一层的输出命名为memory。
编码部分算是过了,然后来看解码部分:
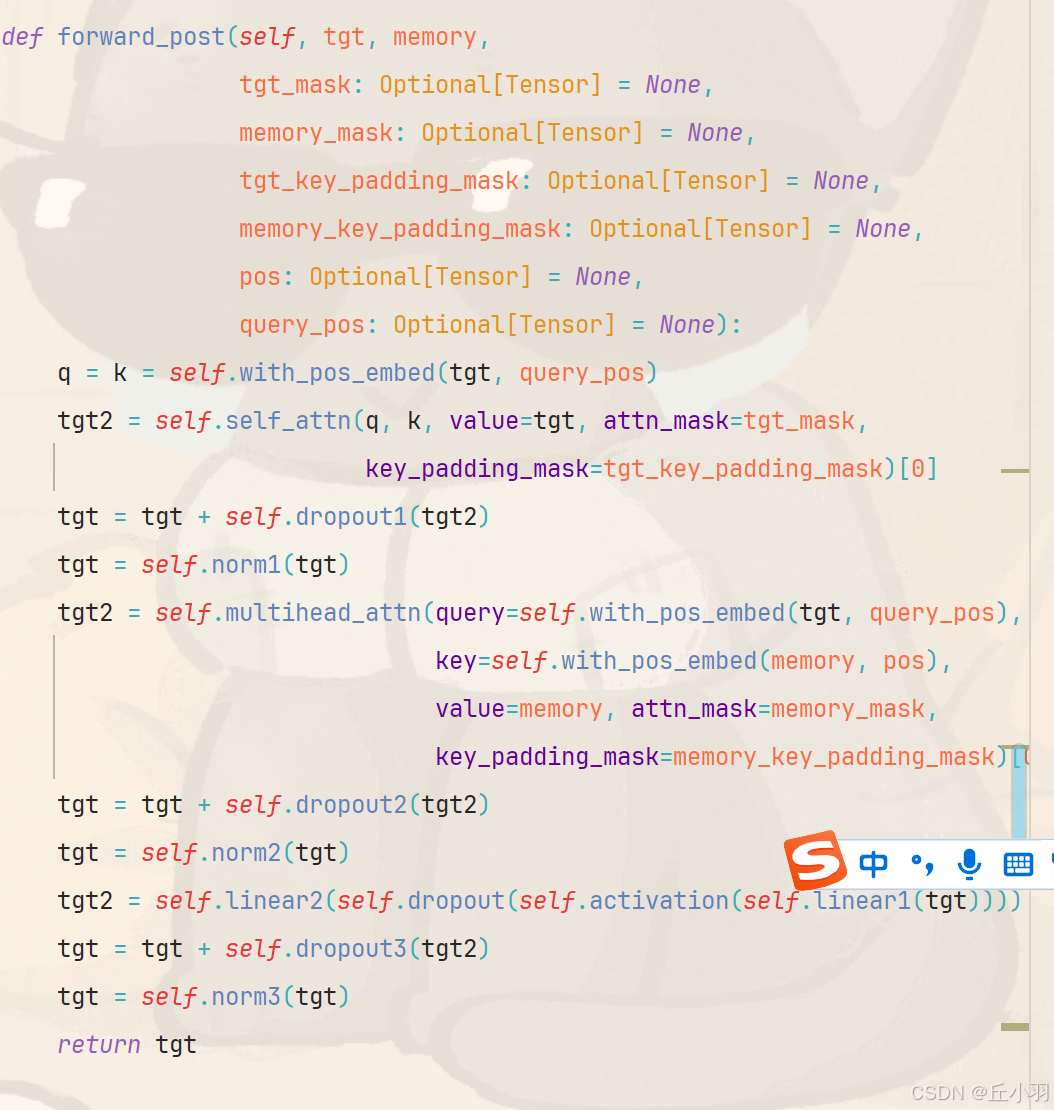
还是以forward_post为例,q和k为原始输入加上位置编码,然后将qk以及不包含位置信息的原始特征输入(其实是随机初始化的tgt),放进自注意力机制中去(代码后面使用了一个multihead_attn)可能会让人觉得自注意力机制不是多头的,其实不然,自注意力机制也是多头的。
自注意力机制得到的结果经过一个残差连接之后,进行归一化,然后再经过一个多头注意力机制模块儿(这个注意力机制中的q为正则化结果再进行一次位置编码,k为encoder得到的输出经过位置编码之后的结果,v为encoder得到的输出)。
多头注意力机制得到的结果进行残差相加...光是叙述不够清晰明了,我还是作图吧。
等下,容我找找tgt在哪。
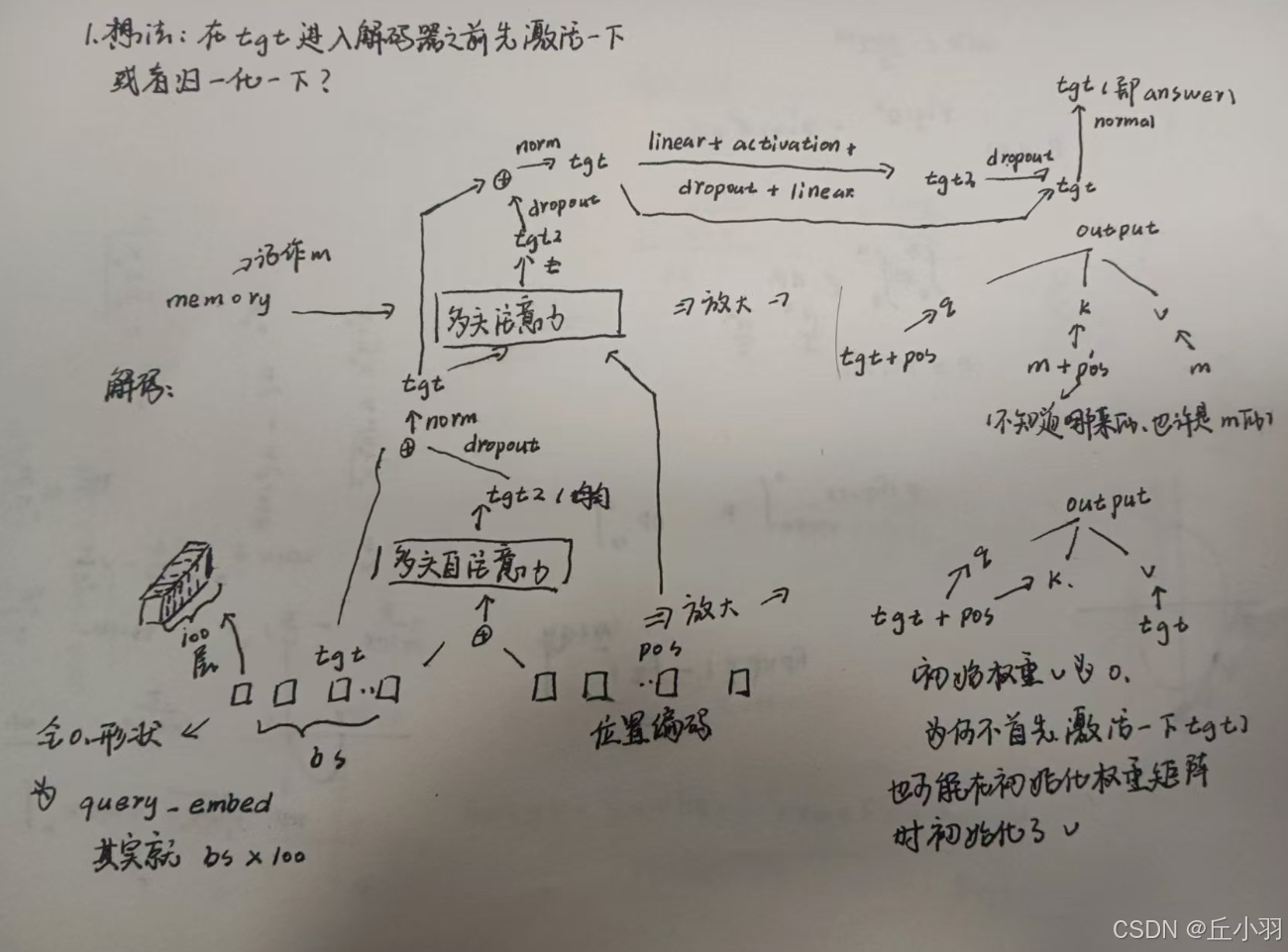
当然,这只是一层的输出,源码中是将每个层的输出都记录下来,得到6个输出后同样将第6层的结果再归一化,且记录下来,总的来说有7个输出。

有源码可知,最后通过一个线性层来预测得到种类:
运用三层感知机来预测边界框:
 。
。
相关文章:
Detr论文精读
摘要: 作者提到,该方法将物体检测看做直接的集合预测,在传统的目标检测算法中,会先生成候选区域,然后对每个候选区域进行单独的预测(包括物体的分类和预测框的回归),集合预测就是直…...

找寻孤独伤感视频素材的热门资源网站推荐
在抖音上,伤感视频总是能够引起观众的共鸣,很多朋友都在寻找可以下载伤感视频素材的地方。作为一名资深的视频剪辑师,今天我来分享几个提供高清无水印伤感素材的网站,如果你也在苦苦寻找这些素材,不妨看看以下推荐&…...

大模型~合集13
我自己的原文哦~ https://blog.51cto.com/whaosoft/12302606 #TextRCNN、TextCNN、RNN 小小搬运工周末也要学习一下~~虽然和世界没关 但还是地铁上看书吧, 大老勿怪 今天来说一下 文本分类必备经典模型 模型 SOTA!模型资源站收录情况 模型来源论文 RAE ht…...

【Next.js 项目实战系列】04-修改 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】03-查看 Issue 修改 Issue 添加修改 Button 本节代码链接 安装 Radix UI 的 Ra…...

【Linux】并行与并发(含时间片)
简单来说 并发:多个进程轮流使用同一个CPU,在逻辑层面上,一段时间内推进完成了多个进程 并行:机器中有多个CPU可以使用,在物理层面上,做到同一时间会有多个进程同时在运行 举个例子:一群人需要…...
)
【Flutter】页面布局:弹性布局(Flex)
在 Flutter 开发中,布局是非常重要的部分。布局系统允许开发者控制和管理界面上的组件如何排列和展示。弹性布局(Flex)是其中一个非常强大且常用的布局组件,它能够在水平方向或垂直方向上灵活调整子组件的空间分配比例。Row 和 Co…...

深入解析 Go 语言接口:多接口实现与接口组合的实际应用
文章目录 一、引言二、一个类型实现多个接口1. 定义多个接口2. 类型实现多个接口3. 使用多个接口 三、接口的组合1. 接口嵌套2. 实现复合接口 四、实际开发中的应用场景1. 多态与模块化设计2. 松耦合系统设计3. 测试与依赖注入4. 事件驱动架构中的应用 五、小结 一、引言 在 G…...

Eclipse——Java开发详解
Eclipse 1、配置JDK2、设置编译版本2.1、全局编译版本2.2、项目编译版本2.3、Web项目编译版本 3、设置工作目录4、创建Java项目5、配置Tomcat6、创建Web项目7、配置Maven8、创建Maven项目8.1、普通Maven项目8.2、Maven Web项目 9、创建SpringBoot项目10、设置字体11、设置代码提…...

练手小项目推荐
以下是一些练手项目推荐,我可以给你一些适合学生毕业设计的小项目建议,既可以锻炼技能,也能完成学术要求。以下是一些可行的毕业设计项目建议: 校园导航APP 功能:为校园内的新生和访客提供导航,标记教室、…...

一图秒懂色彩空间和色彩模型
色彩空间和色彩模型 想必学过图像处理或者摄影的小伙伴都知道这两个词,看了一些博客,发现很少有人把这两个概念说清楚的,大多数都是混在一起,色彩模型和色彩空间的概念混为一谈,很让人疑惑。 这里我们用一张图来解…...

控制Stable Diffusion生成质量的多种方法
在Stable Diffusion绘图中,控制AI生成图像的质量可以通过多种方法来实现。以下是几种常见的方法: 1. 从底模控制(Checkpoint) 使用不同的模型检查点(Checkpoints)可以显著影响生成图像的质量和细节。选择一…...

递归算法笔记
根据b站视频整理的 **视频地址:**https://www.bilibili.com/video/BV1S24y1p7iH/?spm_id_from333.788.videopod.sections&vd_source6335ddc7b30e1f4510569db5f2506f20 最常见的一个递归例子: 斐波那契数列:1,2,3…...

Android——发送彩信
跳转到相册选择图片 btn_jump.setOnClickListener(new View.OnClickListener() {Overridepublic void onClick(View view) {// 跳转到系统相册选择图片并返回Intent intent new Intent(Intent.ACTION_GET_CONTENT);// 设置图片类型为图片类型intent.setType("image/*&quo…...

对比迁移项目的改动
文章目录 对比迁移项目的改动场景背景解决方案 对比迁移项目的改动 场景背景 同源定制化项目,同一套代码扩展出来的项目(从领导口中得知) A项目的有三维地图展示,项目B跑起来却加载不出来,但是本地运行A项目代码&…...

数据结构-复杂度
复杂度 1.数据结构1.1算法 2.算法效率2.1复杂度的概念 3.时间复杂度3.1大O渐进表示法3.2时间复杂度计算示例3.2.1 示例13.2.2 示例23.2.3 示例33.2.4 示例43.2.5 示例5:3.2.6 示例63.2.7 示例7 4.空间复杂度4.1.1 示例14.1.2 示例2 5.常见复杂度对比6.复杂度算法题6…...

无人机之放电速率篇
无人机的放电速率是指电池在一定时间内放出其储存电能的能力,这一参数对无人机的飞行时间、性能以及安全性都有重要影响。 一、放电速率的表示方法 放电速率通常用C数来表示。C数越大,表示放电速率越快。例如,一个2C的电池可以在1/2小时内放…...
免费开源AI助手,颠覆你的数字生活体验
Apt Full作为一款开源且完全免费的软件,除了强大的自然语言处理能力,Apt Full还能够对图像和视频进行一系列复杂的AI增强处理,只需简单几步即可实现专业级的效果。 在图像处理方面,Apt Full提供了一套全面的AI工具,包…...

VMware虚拟机三种网络模式详解
主要内容 1. 桥接模式2. NAT模式VMware Network Adapter VMnet8虚拟网卡的作用 3. 仅主机模式VMware Network Adapter VMnet1虚拟网卡的作用设置虚拟机联通外网 4. 总结 参考资料: 1.Vmware虚拟机三种网络模式详解 VMware虚拟机三种网络模式详解之Bridged࿰…...

【算法篇】动态规划类(4)——子序列(笔记)
目录 一、Leetcode 题目 1. 最长递增子序列 2. 最长连续递增序列 3. 最长重复子数组 4. 最长公共子序列 5. 不相交的线 6. 最大子序和 7. 判断子序列 8. 不同的子序列 9. 两个字符串的删除操作 10. 编辑距离 11. 回文子串 12. 最长回文子序列 二、动态规划总结 …...

【图解版】力扣第162题:寻找峰值
注意 题目只要求找到一个峰值就可以了。nums[-1]和nums[n]这两个位置是负无穷,也就是说,除了数组的位置之外,其它地方都是负无穷。对于所有有效的 i 都有 nums[i] ! nums[i 1] 方法一 遍历整个数组,找到最高的那个点。时间复杂…...

电子系统设计中7种经典电路接口详解与应用
1. 电路接口概述:信号传输的关键桥梁在电子系统设计中,不同模块间的数据交换就像城市间的交通网络,需要标准化的"道路规则"来确保信息高效流通。实际工程中常遇到三大类信号传输问题:时序不同步(如CPU与外设…...

造相-Z-Image本地部署全记录:无需网络,RTX 4090专属优化方案
造相-Z-Image本地部署全记录:无需网络,RTX 4090专属优化方案 你是否曾为部署一个AI绘画模型而焦头烂额?面对复杂的依赖、漫长的网络下载、以及最令人头疼的“爆显存”问题,是不是感觉手头这张强大的RTX 4090显卡有力使不出&#…...

OpenClaw监控方案:百川2-13B-4bits模型运行状态可视化
OpenClaw监控方案:百川2-13B-4bits模型运行状态可视化 1. 为什么需要监控OpenClaw百川模型组合? 去年冬天的一个深夜,我的OpenClaw自动化任务突然卡死。第二天检查时发现是百川2-13B模型显存溢出导致进程崩溃——这种"事后发现"的…...

二叉树中堆的数据结构
堆的概念和结构 如果有一个关键码的集合K {k1 ,k2 ,k3 ,…,kn },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,(i为下标)并满足:ki < k(2i1)且 k…...

视觉障碍辅助:OpenClaw+Phi-3-vision-128k-instruct实时描述周围环境
视觉障碍辅助:OpenClawPhi-3-vision-128k-instruct实时描述周围环境 1. 项目背景与核心需求 去年在帮助一位视障朋友调试智能家居时,我意识到现有环境感知工具存在明显断层——要么是功能单一的"拍照识物"APP,要么是昂贵的企业级…...

什么叫低代码?低代码平台能做什么?国内十大低代码平台盘点
在数字化转型浪潮席卷全球的今天,软件开发效率成为企业竞争的关键因素。低代码(Low-Code)作为一种革命性的开发模式,正以惊人速度改变着传统软件开发的格局,让"人人都是开发者"的愿景逐渐成为现实。本文将深…...

别再被JJWT新版坑了!手把手教你从0.12.x降级到0.11.2解决parseClaimsJws报错
JJWT版本降级实战:从0.12.x回退0.11.2解决parseClaimsJws报错指南 最近在Spring Boot项目中整合JWT时,不少开发者反馈升级到JJWT 0.12.x后突然遭遇parseClaimsJws方法消失的编译错误。这个看似简单的API变动背后,其实是JJWT团队对安全架构的重…...
)
JDK 1.8 vs JDK 17:jvisualvm 安装配置全攻略(附Visual GC插件避坑指南)
JDK 1.8 vs JDK 17:jvisualvm 安装配置全攻略(附Visual GC插件避坑指南) 在Java开发的世界里,JVM性能调优一直是开发者进阶的必修课。而jvisualvm作为Oracle官方提供的免费性能分析工具,可以说是我们窥探JVM内部运行状…...
manga-image-translator:如何让图片中的文字跨越语言障碍?
manga-image-translator:如何让图片中的文字跨越语言障碍? 【免费下载链接】manga-image-translator Translate manga/image 一键翻译各类图片内文字 https://cotrans.touhou.ai/ (no longer working) 项目地址: https://gitcode.com/gh_mirrors/ma/ma…...

GeekDoc
GeekDoc 中文系列教程是一个庞大且组织良好的技术文档集合,它并非单一教程,而是一个开源文档翻译与整理项目,旨在将优秀的技术文档和教程翻译成中文,并按技术领域进行分类。其内容广泛覆盖了信息技术领域的多个核心方向࿰…...