【力扣 | SQL题 | 每日3题】力扣2988,569,1132,1158
1 hard + 3mid,难度不是特别大。
1. 力扣2988:最大部门的经理
1.1 题目:
表: Employees
+-------------+---------+ | Column Name | Type | +-------------+---------+ | emp_id | int | | emp_name | varchar | | dep_id | int | | position | varchar | +-------------+---------+ emp_id 是这张表具有唯一值的列。 这张表包括 emp_id, emp_name, dep_id,和 position。
查询 最大部门 的 经理 的 名字。当拥有相同数量的员工时,可能会有多个最大部门。
返回 按照 dep_id 升序 排列的结果表格。
结果表格的格式如下例所示。
示例 1:
输入: Employees table: +--------+----------+--------+---------------+ | emp_id | emp_name | dep_id | position | +--------+----------+--------+---------------+ | 156 | Michael | 107 | Manager | | 112 | Lucas | 107 | Consultant | | 8 | Isabella | 101 | Manager | | 160 | Joseph | 100 | Manager | | 80 | Aiden | 100 | Engineer | | 190 | Skylar | 100 | Freelancer | | 196 | Stella | 101 | Coordinator | | 167 | Audrey | 100 | Consultant | | 97 | Nathan | 101 | Supervisor | | 128 | Ian | 101 | Administrator | | 81 | Ethan | 107 | Administrator | +--------+----------+--------+---------------+ 输出 +--------------+--------+ | manager_name | dep_id | +--------------+--------+ | Joseph | 100 | | Isabella | 101 | +--------------+--------+ 解释 - 部门 ID 为 100 和 101 的每个部门都有 4 名员工,而部门 107 有 3 名员工。由于部门 100 和 101 都拥有相同数量的员工,它们各自的经理将被包括在内。 输出表格按 dep_id 升序排列。
1.2 思路:
不像中等题,有点像中等难度的简单题。
1.3 题解:
-- 先找出最大部门的部门id
with tep as (select dep_idfrom Employeesgroup by dep_idhaving count(*) >= all(select count(*)from Employeesgroup by dep_id)
)
-- 然后在最大部门中取寻找Manager即可。
select emp_name manager_name, dep_id
from Employees
where dep_id in (select * from tep
)
and position = 'Manager'
order by dep_id2. 力扣569:员工薪水中位数
2.1 题目:
表: Employee
+--------------+---------+ | Column Name | Type | +--------------+---------+ | id | int | | company | varchar | | salary | int | +--------------+---------+ id 是该表的主键列(具有唯一值的列)。 该表的每一行表示公司和一名员工的工资。
编写解决方案,找出每个公司的工资中位数。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +----+---------+--------+ | id | company | salary | +----+---------+--------+ | 1 | A | 2341 | | 2 | A | 341 | | 3 | A | 15 | | 4 | A | 15314 | | 5 | A | 451 | | 6 | A | 513 | | 7 | B | 15 | | 8 | B | 13 | | 9 | B | 1154 | | 10 | B | 1345 | | 11 | B | 1221 | | 12 | B | 234 | | 13 | C | 2345 | | 14 | C | 2645 | | 15 | C | 2645 | | 16 | C | 2652 | | 17 | C | 65 | +----+---------+--------+ 输出: +----+---------+--------+ | id | company | salary | +----+---------+--------+ | 5 | A | 451 | | 6 | A | 513 | | 12 | B | 234 | | 9 | B | 1154 | | 14 | C | 2645 | +----+---------+--------+
进阶: 你能在不使用任何内置函数或窗口函数的情况下解决它吗?
2.2 思路:
看注释。
分为两种情况,结果union all。
2.3 题解:
-- 先给每个人排一个排名
with tep1 as (select id, company, salary , row_number() over (partition by company order by salary) ranksfrom Employee
), tep2 as (-- 找到员工个数为奇数的公司select companyfrom tep1group by companyhaving count(*) % 2 = 1
)
-- union all讨论两种情况
-- 如果在员工个数是奇数的公司,则选出ranks排名ceil(count(*) / 2)的人
select id, company, salary
from tep1 t1
where company in (select * from tep2
) and ranks = (select ceil(count(*) / 2) from tep1 t2 where t1.company = t2.company)union all-- 如果在员工个数是偶数的公司,则需要选出两个人选
-- 排名count(*) / 2和count(*) / 2 +1
select id, company, salary
from tep1 t3
where company not in (select * from tep2
)
and ranks = (select count(*) / 2 from tep1 t4 where t3.company = t4.company)
or ranks = (select count(*) / 2 +1 from tep1 t4 where t3.company = t4.company)3. 力扣1132:报告的记录2
3.1 题目:
动作表: Actions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| post_id | int |
| action_date | date |
| action | enum |
| extra | varchar |
+---------------+---------+
这张表可能存在重复的行。
action 列的类型是 ENUM,可能的值为 ('view', 'like', 'reaction', 'comment', 'report', 'share')。
extra 列拥有一些可选信息,例如:报告理由(a reason for report)或反应类型(a type of reaction)等。
移除表: Removals
+---------------+---------+ | Column Name | Type | +---------------+---------+ | post_id | int | | remove_date | date | +---------------+---------+ 这张表的主键是 post_id(具有唯一值的列)。 这张表的每一行表示一个被移除的帖子,原因可能是由于被举报或被管理员审查。
编写解决方案,统计在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比,四舍五入到小数点后 2 位。
结果的格式如下。
示例 1:
输入: Actions table: +---------+---------+-------------+--------+--------+ | user_id | post_id | action_date | action | extra | +---------+---------+-------------+--------+--------+ | 1 | 1 | 2019-07-01 | view | null | | 1 | 1 | 2019-07-01 | like | null | | 1 | 1 | 2019-07-01 | share | null | | 2 | 2 | 2019-07-04 | view | null | | 2 | 2 | 2019-07-04 | report | spam | | 3 | 4 | 2019-07-04 | view | null | | 3 | 4 | 2019-07-04 | report | spam | | 4 | 3 | 2019-07-02 | view | null | | 4 | 3 | 2019-07-02 | report | spam | | 5 | 2 | 2019-07-03 | view | null | | 5 | 2 | 2019-07-03 | report | racism | | 5 | 5 | 2019-07-03 | view | null | | 5 | 5 | 2019-07-03 | report | racism | +---------+---------+-------------+--------+--------+ Removals table: +---------+-------------+ | post_id | remove_date | +---------+-------------+ | 2 | 2019-07-20 | | 3 | 2019-07-18 | +---------+-------------+ 输出: +-----------------------+ | average_daily_percent | +-----------------------+ | 75.00 | +-----------------------+ 解释: 2019-07-04 的垃圾广告移除率是 50%,因为有两张帖子被报告为垃圾广告,但只有一个得到移除。 2019-07-02 的垃圾广告移除率是 100%,因为有一张帖子被举报为垃圾广告并得到移除。 其余几天没有收到垃圾广告的举报,因此平均值为:(50 + 100) / 2 = 75% 注意,输出仅需要一个平均值即可,我们并不关注移除操作的日期。
3.2 思路:
看注释。
3.3 题解:
-- 先找出哪些post_id是垃圾信息
with tep as (select distinct post_id, action_datefrom Actionswhere extra = 'spam'
), tep1 as (-- 以action_date分组-- 然后在tep表中找到action_date当天的垃圾信息-- 并且where过滤掉没有被移除的记录-- 剩下来的都是当天的而且在之后被移除的记录select (select count(*)from (select post_id from tep t2 where t1.action_date = t2.action_date) twhere t.post_id in (select post_id from Removals)) / count(*) * 100 percfrom tep t1group by action_date
)-- 再求平均值
select round(avg(perc), 2) average_daily_percent
from tep14. 力扣1158:市场分析1
4.1 题目:
表: Users
+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | join_date | date | | favorite_brand | varchar | +----------------+---------+ user_id 是此表主键(具有唯一值的列)。 表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。
表: Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | item_id | int | | buyer_id | int | | seller_id | int | +---------------+---------+ order_id 是此表主键(具有唯一值的列)。 item_id 是 Items 表的外键(reference 列)。 (buyer_id,seller_id)是 User 表的外键。
表:Items
+---------------+---------+ | Column Name | Type | +---------------+---------+ | item_id | int | | item_brand | varchar | +---------------+---------+ item_id 是此表的主键(具有唯一值的列)。
编写解决方案找出每个用户的注册日期和在 2019 年作为买家的订单总数。
以 任意顺序 返回结果表。
查询结果格式如下。
示例 1:
输入: Users 表: +---------+------------+----------------+ | user_id | join_date | favorite_brand | +---------+------------+----------------+ | 1 | 2018-01-01 | Lenovo | | 2 | 2018-02-09 | Samsung | | 3 | 2018-01-19 | LG | | 4 | 2018-05-21 | HP | +---------+------------+----------------+ Orders 表: +----------+------------+---------+----------+-----------+ | order_id | order_date | item_id | buyer_id | seller_id | +----------+------------+---------+----------+-----------+ | 1 | 2019-08-01 | 4 | 1 | 2 | | 2 | 2018-08-02 | 2 | 1 | 3 | | 3 | 2019-08-03 | 3 | 2 | 3 | | 4 | 2018-08-04 | 1 | 4 | 2 | | 5 | 2018-08-04 | 1 | 3 | 4 | | 6 | 2019-08-05 | 2 | 2 | 4 | +----------+------------+---------+----------+-----------+ Items 表: +---------+------------+ | item_id | item_brand | +---------+------------+ | 1 | Samsung | | 2 | Lenovo | | 3 | LG | | 4 | HP | +---------+------------+ 输出: +-----------+------------+----------------+ | buyer_id | join_date | orders_in_2019 | +-----------+------------+----------------+ | 1 | 2018-01-01 | 1 | | 2 | 2018-02-09 | 2 | | 3 | 2018-01-19 | 0 | | 4 | 2018-05-21 | 0 | +-----------+------------+----------------+
4.2 思路:
经典的左外连接题。
4.3 题解:
-- 先过滤掉order_date除2019年的记录
with tep as (select *from Orderswhere substring(order_date, 1, 4) = '2019'
)-- 左外连接,以user_id分组
-- 按理来说group是没有join_date字段的,在select语句是不能使用的
-- 但是由于一个组内的join_date都相等,所以可以用-- if函数是将左外连接除去内连接的部分的记录
-- 然后将这部分的记录特殊判断,个数作为0,否则作为1,是不符合题意的。
select user_id buyer_id, join_date
,if(buyer_id is null, 0, count(*)) orders_in_2019
from Users t1
left join tep t2
on t1.user_id = t2.buyer_id
group by user_id相关文章:

【力扣 | SQL题 | 每日3题】力扣2988,569,1132,1158
1 hard 3mid,难度不是特别大。 1. 力扣2988:最大部门的经理 1.1 题目: 表: Employees ---------------------- | Column Name | Type | ---------------------- | emp_id | int | | emp_name | varchar | | de…...

移动网络知识
一、3G网络 TD-SCDMA(时分同步码分多址接入)、WCDMA(宽带码分多址)和CDMA2000三种不同的3G移动通信标准 TD-SCDMA(时分同步码分多址接入):中国自主开发的一种3G标准主要用于国内市场ÿ…...

CentOS系统Nginx的安装部署
CentOS系统Nginx的安装部署 安装包准备 在服务器上准备好nginx的安装包 nginx安装包下载地址为:https://nginx.org/en/download.html 解压 tar -zxvf nginx-1.26.1.tar.gz执行命令安装 # 第一步 cd nginx-1.26.1# 第二步 ./configure# 第三步 make# 第四步 mak…...

Leetcode 最长公共前缀
java solution class Solution {public String longestCommonPrefix(String[] strs) {if(strs null || strs.length 0) {return "";}//用第一个字符串作为模板,利用indexOf()方法匹配,由右至左逐渐缩短第一个字符串的长度String prefix strs[0];for(int i 1; i …...

[C#][winform]基于yolov5的驾驶员抽烟打电话安全带检测系统C#源码+onnx模型+评估指标曲线+精美GUI界面
【重要说明】 该系统以opencvsharp作图像处理,onnxruntime做推理引擎,使用CPU进行推理,适合有显卡或者没有显卡windows x64系统均可,不支持macOS和Linux系统,不支持x86的windows操作系统。由于采用CPU推理,要比GPU慢。…...

【Flutter】基础入门:开发环境搭建
Flutter 是一个强大的跨平台框架,支持在 Android、iOS、Windows、Linux、Web 等多种平台上开发应用。下面将详细介绍如何在各个平台上构建 Flutter 开发环境,并使用相同的项目代码构建出一个可以在多个平台运行的跨平台 Demo。 Flutter 环境配置&#x…...
简介)
AI学习指南深度学习篇-对比学习(Contrastive Learning)简介
AI学习指南深度学习篇 - 对比学习(Contrastive Learning)简介 目录 引言对比学习的背景对比学习的定义对比学习在深度学习中的应用 无监督学习表示学习 详细示例 基本示例先进示例 对比学习的优缺点总结与展望 1. 引言 随着人工智能(AI&am…...
【蓝队技能】【规则开发1】Suricata-C2Webshell隧道
蓝队技能 Suricata-C2&Webshell&隧道 蓝队技能总结前言一、C2规则开发1.1 Sliver1.2 CS 二、内网隧道1.1 frps1.2 nps 三、webshell3.1 蚁剑3.2 冰蝎3.3 哥斯拉 总结 前言 本文聚焦于Suricata规则开发,提供针对Sliver、Cobalt Strike(CS…...
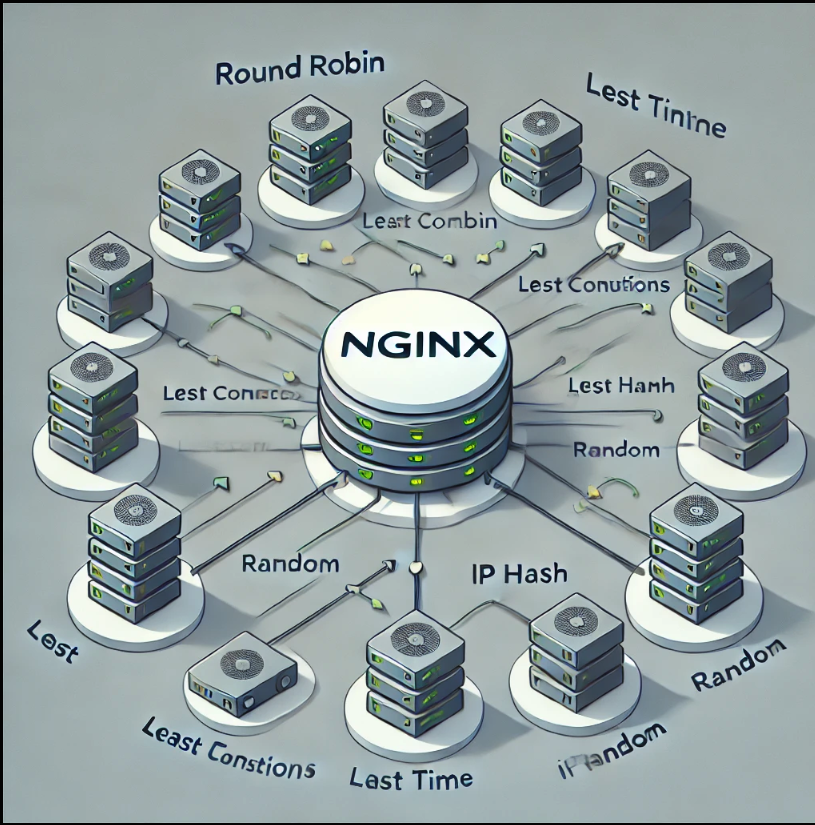
全面了解 NGINX 的负载均衡算法
NGINX 提供多种负载均衡方法,以应对不同的流量分发需求。常用的算法包括:最少连接、最短时间、通用哈希、随机算法和 IP 哈希。这些负载均衡算法都通过独立指令来定义,每种算法都有其独特的应用场景。 以下负载均衡方法(IP 哈希除…...

Java-继承与多态-上篇
关于类与对象,内容较多,我们分为两篇进行讲解: 📚 Java-继承与多态-上篇:———— <就是本篇> 📕 继承的概念与使用 📕 父类成员访问 📕 super关键字 📕 supe…...

通过比较list与vector在简单模拟实现时的不同进一步理解STL的底层
cplusplus.com/reference/list/list/?kwlist 当我们大致阅读完list的cplusplus网站的文档时,我们会发现它提供的接口大致上与我们的vector相同。当然的,在常用接口的简单实现上它们也大体相同,但是它们的构造函数与迭代器的实现却大有不同。…...

软件I2C的代码
I2C的函数 GPIO的配置——scl和sda都配置为开漏输出 void MyI2C_Init(void) {RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB,ENABLE);GPIO_InitTypeDef GPIO_InitStruture;GPIO_InitStruture.GPIO_Mode GPIO_Mode_Out_OD;GPIO_InitStruture.GPIO_PinGPIO_Pin_10 | GPIO_Pin_…...

登录时用户名密码加密传输(包含前后端代码)
页面输入用户名密码登录过程中,如果没有对用户名密码进行加密处理,可能会导致传输过程中数据被窃取,就算使用https协议,在浏览器控制台的Request Payload中也是能直接看到传输的明文,安全感是否还是不足。 大致流程&a…...

ai聊天对话页面-uniapp
流式传输打字机效果,只支持uniapp内使用 ,下载地址 https://download.csdn.net/download/qq_54123885/89899859...

虚拟滚动列表如何实现?
highlight: a11y-dark 虚拟滚动列表,虚拟滚动的关键在于只渲染当前视口内可见的数据项,而不是一次性渲染所有数据项。这可以显著提高性能,尤其是在处理大量数据时。 以下是一个完整的虚拟滚动列表的示例代码: <!DOCTYPE htm…...

07_Linux网络配置与管理:命令与工具指南
本系列文章导航:01_Linux基础操作CentOS7学习笔记-CSDN博客 文章目录 网络配置与管理:命令与工具指南1. ping命令2. ifconfig命令3. ip命令4. route命令5. ip route命令6. nslookup命令7. nmcli命令8. nmtui命令9. RHEL7修改网卡名1. 修改网络(会话)配置…...

首个统一生成和判别任务的条件生成模型框架BiGR:专注于增强生成和表示能力,可执行视觉生成、辨别、编辑等任务
BiGR是一种新型的图像生成模型,它可以生成高质量的图像,同时还能有效地提取图像特征。该方法是通过将图像转换为一系列的二进制代码来工作,这些代码就像是图像的“压缩版”。在训练时会遮住一些代码,然后让模型学习如何根据剩下的…...

【Java知识】Java进阶-服务发现机制SPI
文章目录 SPI概述SPI 工作原理 ServiceLoader代码展示简化的 ServiceLoader 类关键点解释使用示例1. 定义服务接口2. 实现服务提供者3. 配置文件4. 加载服务提供者 总结 SPI使用场景1. 数据库驱动2. 日志框架3. 图像处理4. 加密算法5. 插件系统6. 缓存机制示例代码1. 定义服务接…...

多模态技术的协同表现:从文本生成、语音合成到口型同步综合测评
本文是针对多模态对话系统核心技术栈的使用效果和网络测评整理。 测评内容基于用户体验,侧重于从使用者角度出发,讨论实际操作中的体验感受,如技术的易用性、输出效果如文本的连贯性、语音的自然度、口型同步的准确性等。不涉及具体算法架构…...

Java最全面试题->Java主流框架->Srping面试题
Spring面试题 下边是我自己整理的面试题,基本已经很全面了,想要的可以私信我,我会不定期去更新思维导图 哪里不会点哪里 谈谈你对 Spring 的理解? Spring 是一个开源框架,为简化企业级应用开发而生。Spring 可以是使简单的 JavaBean 实现以前只有 EJB 才能实现的功能。…...

超大规模内容生成技能引擎:模块化架构与工作流实践
1. 项目概述:一个面向超大规模内容生成的技能引擎最近在折腾一些自动化内容生成的项目,发现了一个挺有意思的GitHub仓库,叫smouj/ultra-generator-skill。光看这个名字,你可能会觉得有点抽象——“超生成器技能”?这到…...

WarcraftHelper:5分钟解决魔兽争霸3现代系统兼容性问题
WarcraftHelper:5分钟解决魔兽争霸3现代系统兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在现代电脑上…...

40希尔排序 - 以递减间距进行插入排序
希尔排序 - 以递减间距进行插入排序 040希尔排序:用长距离跳跃打破速度壁垒📰 5W1H 发明者故事 Who(何人)- 发明者是谁? 发明者:唐纳德希尔(Donald L. Shell) 背景:希尔…...

告别背包焦虑!泰坦之旅终极装备管理神器完全指南
告别背包焦虑!泰坦之旅终极装备管理神器完全指南 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》中堆积如山的传奇装备无处存放而烦恼吗&…...
)
别再只会用os.listdir了!Python遍历文件夹的3种高效方法(附性能对比)
别再只会用os.listdir了!Python遍历文件夹的3种高效方法(附性能对比) 当你的Python项目需要处理成千上万的文件时,传统的os.listdir()方法可能会成为性能瓶颈。我曾经在一个图像处理项目中,因为使用了不当的遍历方法&a…...

【LangChain实战】无缝切换:将项目中的OpenAI LLM替换为本地或第三方API模型
1. 为什么需要替换OpenAI LLM? 最近两年大语言模型(LLM)发展迅猛,但很多项目一上来就直接用OpenAI API,这其实存在不少隐患。我在实际项目中就遇到过几个典型问题:首先是API调用不稳定,特别是国…...

利用Taotoken用量看板精细化管理团队大模型API消费
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken用量看板精细化管理团队大模型API消费 对于团队管理者而言,在引入大模型能力后,一个普遍存在的…...

Chat-with-NeRF:三维场景重建与对话式AI的融合实践
1. 项目概述:当NeRF遇见对话式AI最近在三维视觉和AIGC的交叉领域,一个名为“chat-with-nerf”的项目引起了我的注意。简单来说,它实现了一个听起来很科幻的功能:你上传一张或多张照片,系统会基于这些照片重建出一个三维…...

全栈AI应用开发框架Flappy:从智能体到生产级Web应用的快速构建指南
1. 项目概述:从“Flappy”到“Pleisto”的AI应用构建新范式最近在AI应用开发圈子里,一个名为“pleisto/flappy”的项目开始引起不少人的注意。乍一看这个名字,你可能会联想到那个经典的像素小鸟游戏,但此“Flappy”非彼“Flappy”…...

Audacity音频编辑:从新手到专业创作者的免费音频处理方案
Audacity音频编辑:从新手到专业创作者的免费音频处理方案 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 你是否曾经想过编辑一段音频,却因为昂贵的软件而却步?或者想要录制播客…...