尚硅谷大数据Flink1.17实战教程-笔记04【Flink DataStream API】
- 尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】
- 视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据Flink1.17实战教程-笔记01【Flink 概述、Flink 快速上手】
- 尚硅谷大数据Flink1.17实战教程-笔记02【Flink 部署】
- 尚硅谷大数据Flink1.17实战教程-笔记03【Flink 运行时架构】
- 尚硅谷大数据Flink1.17实战教程-笔记04【Flink DataStream API】
- 尚硅谷大数据Flink1.17实战教程-笔记05【】
- 尚硅谷大数据Flink1.17实战教程-笔记06【】
- 尚硅谷大数据Flink1.17实战教程-笔记07【】
- 尚硅谷大数据Flink1.17实战教程-笔记08【】
目录
基础篇
第05章-DataStream API
P033【033_DataStreamAPI_执行环境】24:22
P034【034_DataStreamAPI_源算子_准备工作】06:36
P035【035_DataStreamAPI_源算子_集合&文件&socket】14:40
P036【036_DataStreamAPI_源算子_从Kafka读取】19:50
P037【037_DataStreamAPI_源算子_数据生成器】14:09
P038【038_DataStreamAPI_Flink支持的数据类型】08:49
P039【039_DataStreamAPI_基本转换算子_map】11:48
P040【040_DataStreamAPI_基本转换算子_filter&flatmap】12:45
P041【041_DataStreamAPI_聚合算子_keyby】18:00
P042【042_DataStreamAPI_聚合算子_简单聚合算子】11:53
P043【043_DataStreamAPI_聚合算子_规约聚合reduce】09:34
P044【44_DataStreamAPI_用户自定义函数】24:24
P045【45_DataStreamAPI_分区算子&分区器】25:08
P046【46_DataStreamAPI_分区算子_自定义分区】06:41
P047【47_DataStreamAPI_分流_使用FIlter简单实现】08:50
P048【48_DataStreamAPI_分流_使用侧输出流】26:33
P049【49_DataStreamAPI_合流_union】06:37
P050【50_DataStreamAPI_合流_connect】15:44
P051【51_DataSrreamAPI_合流_connect案例】12:02
基础篇
第05章-DataStream API
P033【033_DataStreamAPI_执行环境】24:22
第5章 DataStream API
DataStream API是Flink的核心层API。一个Flink程序,其实就是对DataStream的各种转换。具体来说,代码基本上都由以下几部分构成:
5.1 执行环境(Execution Environment)
Flink程序可以在各种上下文环境中运行:我们可以在本地JVM中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前Flink的运行环境,从而建立起与Flink框架之间的联系。
5.1.1 创建执行环境
1)getExecutionEnvironment
最简单的方式,就是直接调用getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种方式,用起来简单高效,是最常用的一种创建执行环境的方式。
2)createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU核心数。
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3)createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager主机名
1234, // JobManager进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。

package com.atguigu.env;import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** TODO** @author* @version 1.0*/
public class EnvDemo {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment//.getExecutionEnvironment(); // 自动识别是 远程集群 ,还是idea本地环境.getExecutionEnvironment(conf); // conf对象可以去修改一些参数//.createLocalEnvironment()//.createRemoteEnvironment("hadoop102", 8081,"/xxx")// 流批一体:代码api是同一套,可以指定为 批,也可以指定为 流// 默认 STREAMING// 一般不在代码写死,提交时 参数指定:-Dexecution.runtime-mode=BATCHenv.setRuntimeMode(RuntimeExecutionMode.BATCH);env//.socketTextStream("hadoop102", 7777).readTextFile("input/word.txt").flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1).print();env.execute();//env.executeAsync();/** TODO 关于execute总结(了解)* 1、默认 env.execute()触发一个flink job:* 一个main方法可以调用多个execute,但是没意义,指定到第一个就会阻塞住* 2、env.executeAsync(),异步触发,不阻塞* => 一个main方法里 executeAsync()个数 = 生成的flink job数* 3、思考:* yarn-application 集群,提交一次,集群里会有几个flink job?* =》 取决于 调用了n个 executeAsync()* =》 对应 application集群里,会有n个job* =》 对应 Jobmanager当中,会有 n个 JobMaster*/}
}P034【034_DataStreamAPI_源算子_准备工作】06:36
5.2 源算子(Source)
5.2.1 准备工作
package com.atguigu.bean;import java.util.Objects;/*** TODO** @author* @version 1.0*/
public class WaterSensor {public String id;public Long ts;public Integer vc;// 一定要提供一个 空参 的构造器public WaterSensor() {}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}
}P035【035_DataStreamAPI_源算子_集合&文件&socket】14:40
5.2.2 从集合中读取数据
package com.atguigu.source;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;/*** TODO** @author* @version 1.0*/
public class CollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO 从集合读取数据DataStreamSource<Integer> source = env.fromElements(1, 2, 33); // 从元素读//.fromCollection(Arrays.asList(1, 22, 3)); // 从集合读source.print();env.execute();}
}package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author* @version 1.0*/
public class FileSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从文件读: 新Source架构FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "filesource").print();env.execute();}
}
/*** 新的Source写法:* env.fromSource(Source的实现类,Watermark,名字)*/P036【036_DataStreamAPI_源算子_从Kafka读取】19:50
5.2.5 从Kafka读取数据
package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;/*** TODO** @author* @version 1.0*/
public class KafkaSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从Kafka读:新Source架构KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092") // 指定kafka节点的地址和端口.setGroupId("atguigu") // 指定消费者组的id.setTopics("topic_1") // 指定消费的 Topic.setValueOnlyDeserializer(new SimpleStringSchema()) // 指定 反序列化器,这个是反序列化value.setStartingOffsets(OffsetsInitializer.latest()) // flink消费kafka的策略.build();env//.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkasource").fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource").print();env.execute();}
}
/*** kafka消费者的参数:* auto.reset.offsets* earliest: 如果有offset,从offset继续消费; 如果没有offset,从 最早 消费* latest : 如果有offset,从offset继续消费; 如果没有offset,从 最新 消费** flink的kafkasource,offset消费策略:OffsetsInitializer,默认是 earliest* earliest: 一定从 最早 消费* latest : 一定从 最新 消费*/P037【037_DataStreamAPI_源算子_数据生成器】14:09
5.2.6 从数据生成器读取数据
package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author* @version 1.0*/
public class DataGeneratorDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 如果有n个并行度,最大值设为a// 将数值 均分成 n份,a/n ,比如,最大100,并行度2,每个并行度生成50个// 其中一个是 0-49,另一个50-99env.setParallelism(2);/*** 数据生成器Source,四个参数:* 第一个:GeneratorFunction接口,需要实现,重写map方法,输入类型固定是Long* 第二个:long类型,自动生成的数字序列(从0自增)的最大值(小于),达到这个值就停止了* 第三个:限速策略,比如 每秒生成几条数据* 第四个:返回的类型*/DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:" + value;}},100,RateLimiterStrategy.perSecond(1),Types.STRING);env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator").print();env.execute();}
}P038【038_DataStreamAPI_Flink支持的数据类型】08:49
P039【039_DataStreamAPI_基本转换算子_map】11:48
P040【040_DataStreamAPI_基本转换算子_filter&flatmap】12:45
P041【041_DataStreamAPI_聚合算子_keyby】18:00
P042【042_DataStreamAPI_聚合算子_简单聚合算子】11:53
P043【043_DataStreamAPI_聚合算子_规约聚合reduce】09:34
P044【44_DataStreamAPI_用户自定义函数】24:24
P045【45_DataStreamAPI_分区算子&分区器】25:08
P046【46_DataStreamAPI_分区算子_自定义分区】06:41
P047【47_DataStreamAPI_分流_使用FIlter简单实现】08:50
P048【48_DataStreamAPI_分流_使用侧输出流】26:33
P049【49_DataStreamAPI_合流_union】06:37
P050【50_DataStreamAPI_合流_connect】15:44
P051【51_DataSrreamAPI_合流_connect案例】12:02
相关文章:

尚硅谷大数据Flink1.17实战教程-笔记04【Flink DataStream API】
尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据Flink1.17实战教程-笔记01【Flink 概述、Flink 快速上手】尚硅谷大数据Flink1.17实战教程-笔记02【Flink 部署】尚硅…...

MySQL常见优化策略
MySQL 是一种广泛使用的开源数据库管理系统,性能的优化对于应用程序的效率至关重要。以下是一些常见的 MySQL 优化策略,帮助提高数据库性能和响应速度。🚀 1. 合理的索引设计 使用索引:确保在常用的查询条件(如 WHER…...

gyp ERR stack Error: Command failed: D:\python\python.EXE -c import sys; print
文章目录 1、问题描述 2、解决方案 1、问题描述 网上clone的开源项目在执行npm install的时候报错如下: 2、解决方案 经过多方查证,后来发现是python的版本太高了,我重新配置了个python2.7的环境变量就好了。 …...

代码随想录day6| 242.有效的字母异位词 、349. 两个数组的交集、 202. 快乐数 、 1. 两数之和
代码随想录day6| 242.有效的字母异位词 、349. 两个数组的交集、 202. 快乐数 、 1. 两数之和 242.有效的字母异位词思路步骤 349. 两个数组的交集思路步骤 202. 快乐数思路步骤 1. 两数之和思路步骤 242.有效的字母异位词 思路 使用暴力解法时间复杂度为O(n^2)这道题需要判断…...

《IDE 巧用法宝:使用技巧全解析与优质插件推荐》
在日常撸代码的时候,相信兄弟们在IDEA 中用到不少插件,利用插件,不仅可以提高工具效率,撸起代码来,也格外的娃哈哈…… 一、IntelliJ IDEA 作为一个资深 Java 程序员,除了 IDEA 中默认的插件,我…...

安全见闻---清风
注:本文章源于泷羽SEC,如有侵权请联系我,违规必删 安全见闻1 泷哥语录:安全领域什么都有,不要被表象所迷惑,无论技术也好还是其他方面也好,就是说学习之前,你得理解你要学的是什么…...
)
Python爬虫:urllib_post请求百度翻译(06)
#post的请求 import urllib.request import urllib.parse import jsonurl https://fanyi.baidu.com/sugheaders {user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36}data {kw : spider }#post请…...

GPIO输入和输出
参考视频:2.1 [GPIO]4种输出模式_哔哩哔哩_bilibili 输出:通过写0或者写1,控制引脚输出低电压或高电压。 输入:通过读取引脚是0还是1,判断引脚输入的是高电压还是低电压。 输出 推挽开漏通用通用输出推挽通用输出开漏…...
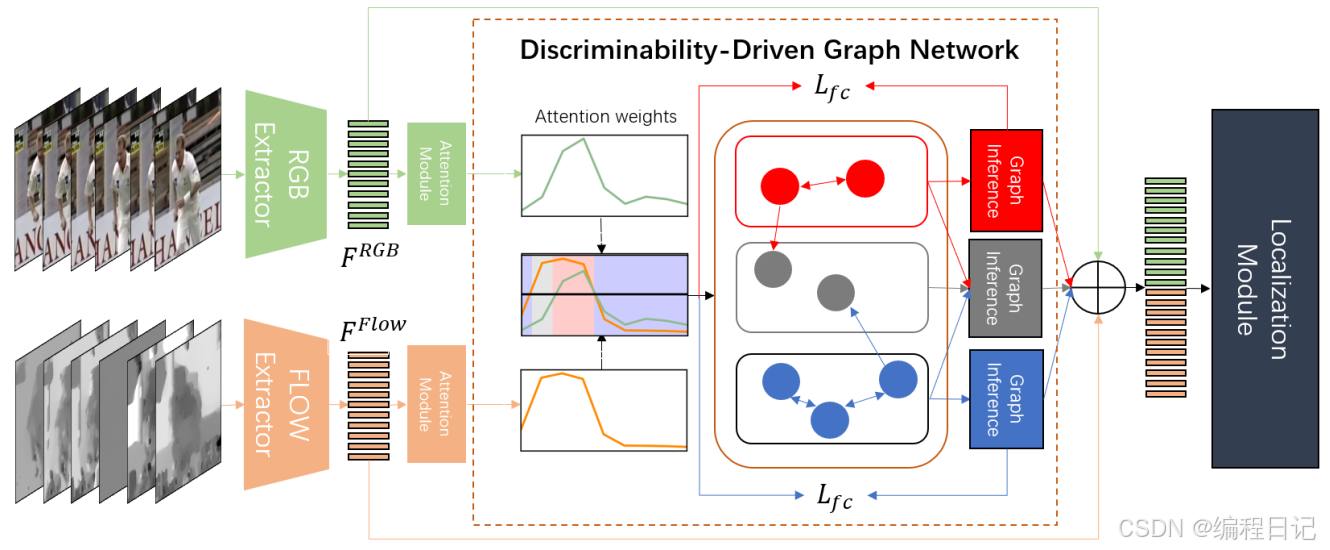
时序动作定位 | DDG-Net:弱监督时间动作定位的判别驱动图网络(ICCV 2023)
"><DDG-Net: Discriminability-Driven Graph Network for Weakly-supervised Temporal Action Localization> 代码:https://github.com/XiaojunTang22/ICCV2023-DDGNet 这篇论文探讨了弱监督时间动作定位(WTAL)任务,指出现有方法在特征提取时依赖于在其他数…...

mapbox没有token/token失效,地图闪烁后变空白,报错Error: A valid Mapbox access token is required to use Mapbox GL JS.
目录 mapbox没有token/token失效,地图闪烁后空白,报错Error: A valid Mapbox access token is required to use Mapbox GL JS. 一、问题描述 二、mapbox去除token验证 1、找到mapbox-gl文件夹 2、找到mapbox-gl.js文件 3、找到对应位置并修改 4、清…...

C#运动控制
在 C# 中实现运动控制主要涉及如何使用编程语言控制运动设备(如电机、伺服电机、传感器等)。以下是一些基本概念和示例,帮助你入门运动控制的编程。 1. 运动控制的基本概念 运动模型:了解运动的基本原理,包括线性运动…...

监控易监测对象及指标之:Kafka中间件JMX监控指标解读
监控易作为一款功能强大的监控软件,旨在为企业提供全方位的IT系统监控服务。其中,针对Kafka中间件的JMX监控是监控易的重要功能之一。本文将详细解读监控易中Kafka的JMX监控指标,帮助企业更好地理解并运用这些数据进行系统性能调优和故障排查…...

PDF文件为什么不能编辑是?是啥原因导致的,有何解决方法
PDF文件格式广泛应用于工作中,但有时候我们可能遇到无法编辑PDF文件的情况。这可能导致工作效率降低,特别是在需要修改文件内容时显得尤为棘手。遇到PDF不能编辑时,可以看看是否以下3个原因导致的。 一、文件受保护 有些PDF文件可能被设置了…...

海螺AI在人类表情刻画中的应用:技术与创新
引言 随着人工智能技术的不断发展,AI在人类表情刻画方面取得了重大突破。海螺AI(Conch AI)作为这一领域的领先技术,因其高度逼真的表情生成和细腻的情感表达能力,受到了广泛关注。本文将探讨海螺AI在人类表情刻画中的…...

【Python实战】几种打包python代码的方法!!!
Python是一种高级编程语言。因此,将Python代码打包成可执行文件(.exe)是一种非常有效的解决方案,能够使用户无需安装Python环境即可直接运行程序,从而提升使用体验。 1、pyinstaller 使用 PyInstaller 打包 Python 代…...

(已开源-ECCV2024)BEV检测模型-LabelDistill,使用真值进行知识蒸馏
项目链接:https://github.com/sanmin0312/LabelDistill (中文版翻译) 文章目录 1. Introduction & Related Work2. Method & Code3. Experiments3.1 Main Results3.2 Ablation Study 1. Introduction & Related Work 2. Method & Code 3. Experim…...

web前端第一次作业
以下为代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><form action"java-api.super-yx.com/register" method"post" enctype"multipart/form-…...

CMake 开发者手册
CMake 开发者手册 CMake 开发者手册一、介绍二、cmake 访问 Windows 注册表2.1 cmake 查询 Windows 注册表2.2 cmake 使用 Windows 注册表查找 3. find_package 查找模块3.1 cmake 查找模块的示例用法3.2 标准变量名称3.3 find_package 一个简单的查找模块示例 六、其他文章推荐…...

Redis入门:在Java程序中高效使用Redis
准备工作 下载windows版的Redis(自行查找网络资源) 解压到指定文件夹 如图所示:Redis的目录结构 redis本质上也是一个数据库,只不过经常被用作缓存 。redis分为服务端和客户端,先启动服务器redis-server,在…...

活着就好20241021
今日提醒:2024年10月21日,星期一,已是开工第247天。早安,摸鱼界的同仁们! 健康警钟:即便工作繁忙,也别忘了关爱自己。起身走走,茶水间、厕所、廊道都是好去处,毕竟&…...

【MYSQL】在Centos7和ubuntu22.04环境下安装
一.MYSQL在Centos7下的安装注意:安装与卸载中,⽤⼾全部切换成为root初期练习,mysql不进⾏⽤⼾管理,全部使⽤root进⾏1.卸载内置环境1-1卸载不要的环境[rootVM-0-3-centos ~]$ ps ajx |grep mariadb # 先检查是否有mariadb存在 131…...

OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级
OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在苹果生态系统中&…...

MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验
MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer …...
)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南) 在电子工程领域,精确测量电容值是一项基础却极具挑战性的任务。无论是研发高频电路的设计师,还是调试精密仪表的工程师,亦或是研究…...

终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能
终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩《英雄联…...

低碳环境下新型电气能源系统优化配置与运行仿真研究
摘要:在“双碳”目标和新能源快速发展的背景下,传统电气能源系统面临碳排放高、新能源消纳能力不足以及运行调度灵活性较弱等问题。为提高系统低碳运行水平,本文以风电、光伏、储能、可控负荷和智慧电网为主要研究对象,开展低碳环…...

终极AI分层工具:3分钟让单张图片变专业PSD文件
终极AI分层工具:3分钟让单张图片变专业PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 还在为复杂的插画分层工作头疼吗?L…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...