学习文档(5)
Redis应用
目录
Redis应用
Redis 除了做缓存,还能做什么?
Redis 可以做消息队列么?
Redis 可以做搜索引擎么?
如何基于 Redis 实现延时任务?
Redis 除了做缓存,还能做什么?
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:分布式锁详解 。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜
Redis 可以做消息队列么?
实际项目中使用 Redis 来做消息队列的非常少,毕竟有更成熟的消息队列中间件可以用。
先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。
通过 RPUSH/LPOP 或者 LPUSH/RPOP即可实现简易版消息队列:
# 生产者生产消息
> RPUSH myList msg1 msg2
(integer) 2
> RPUSH myList msg3
(integer) 3
# 消费者消费消息
> LPOP myList
"msg1"不过,通过 RPUSH/LPOP 或者 LPUSH/RPOP这样的方式存在性能问题,我们需要不断轮询去调用 RPOP 或 LPOP 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
# 超时时间为 10s
# 如果有数据立刻返回,否则最多等待10秒
BRPOP myList 10
nullList 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。
Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。
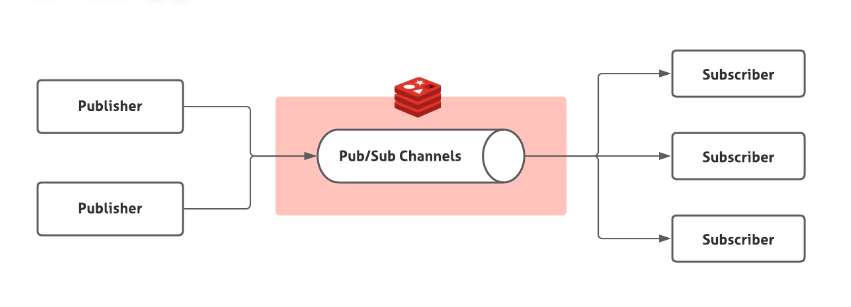
Redis 发布订阅 (pub/sub) 功能
pub/sub 中引入了一个概念叫 channel(频道),发布订阅机制的实现就是基于这个 channel 来做的。
pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
- 发布者通过
PUBLISH投递消息给指定 channel。 - 订阅者通过
SUBSCRIBE订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
我们这里启动 3 个 Redis 客户端来简单演示一下:

pub/sub 实现消息队列演示
pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
为此,Redis 5.0 新增加的一个数据结构 Stream 来做消息队列。Stream 支持:
- 发布 / 订阅模式
- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
- 消息持久化( RDB 和 AOF)
- ACK 机制(通过确认机制来告知已经成功处理了消息)
- 阻塞式获取消息
Stream 的结构如下:
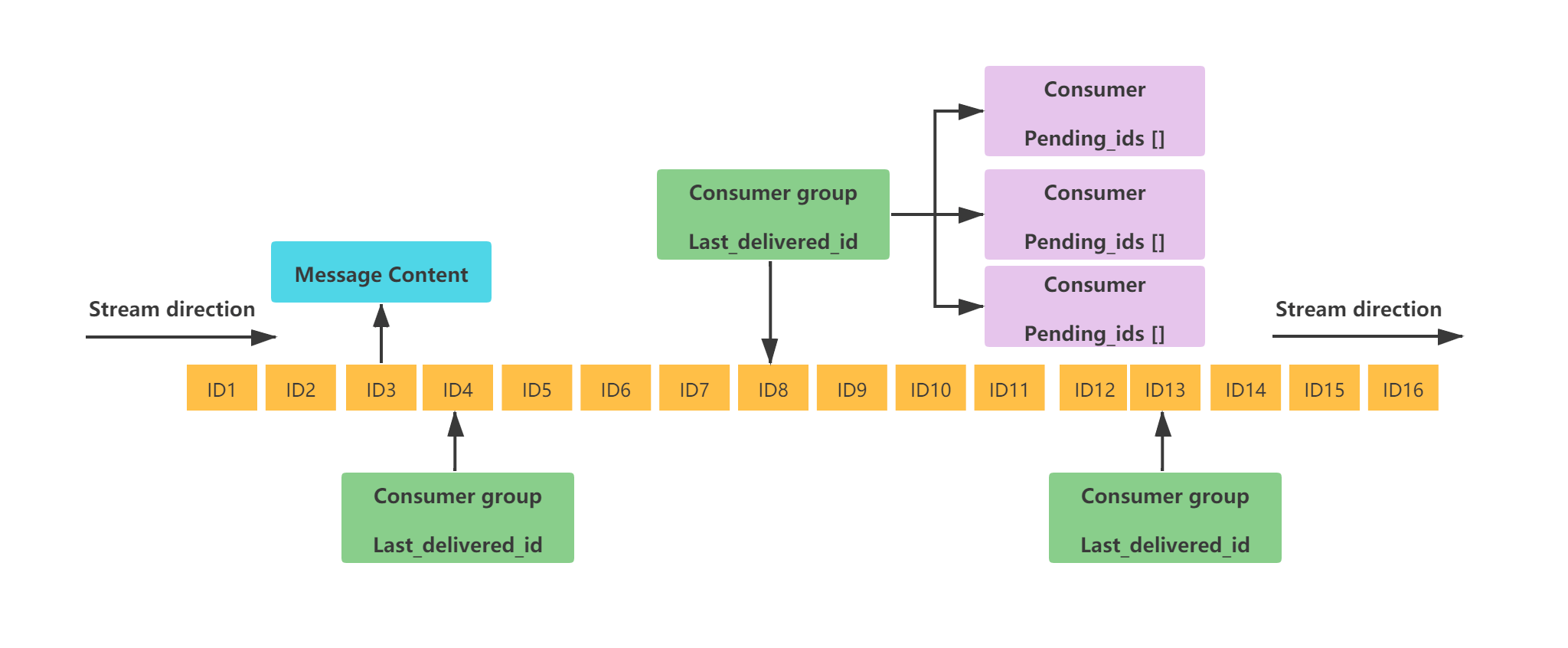
这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
这里再对图中涉及到的一些概念,进行简单解释:
Consumer Group:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费last_delivered_id:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。pending_ids:记录已经被客户端消费但没有 ack 的消息的 ID。
下面是Stream 用作消息队列时常用的命令:
XADD:向流中添加新的消息。XREAD:从流中读取消息。XREADGROUP:从消费组中读取消息。XRANGE:根据消息 ID 范围读取流中的消息。XREVRANGE:与XRANGE类似,但以相反顺序返回结果。XDEL:从流中删除消息。XTRIM:修剪流的长度,可以指定修建策略(MAXLEN/MINID)。XLEN:获取流的长度。XGROUP CREATE:创建消费者组。XGROUP DESTROY: 删除消费者组XGROUP DELCONSUMER:从消费者组中删除一个消费者。XGROUP SETID:为消费者组设置新的最后递送消息 IDXACK:确认消费组中的消息已被处理。XPENDING:查询消费组中挂起(未确认)的消息。XCLAIM:将挂起的消息从一个消费者转移到另一个消费者。XINFO:获取流(XINFO STREAM)、消费组(XINFO GROUPS)或消费者(XINFO CONSUMERS)的详细信息
Stream 使用起来相对要麻烦一些,这里就不演示了。
总的来说,Stream 已经可以满足一个消息队列的基本要求了。不过,Stream 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 Stream,这是目前相对最优的 Redis 消息队列实现。
Redis 可以做搜索引擎么?
Redis 是可以实现全文搜索引擎功能的,需要借助 RediSearch ,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
- 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
- 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
对于比较复杂或者数据规模较大的搜索场景还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
- 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
- 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
- 聚合功能较弱:Elasticsearch 提供了丰富的聚合功能,而 RediSearch 的聚合功能相对较弱,只支持简单的聚合操作。
- 生态较差:Elasticsearch 可以轻松和常见的一些系统/软件集成比如 Hadoop、Spark、Kibana,而 RedisSearch 则不具备该优势。
Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合的场景,而 RediSearch 适用于快速数据存储、缓存和简单查询的场景。
如何基于 Redis 实现延时任务?
类似的问题:
- 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
- 红包 24 小时未被查收自动退还,如何用 Redis 实现?
基于 Redis 实现延时任务的功能无非就下面两种方案:
- Redis 过期事件监听
- Redisson 内置的延时队列
Redis 过期事件监听的存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
Redisson 内置的延时队列具备下面这些优势:
- 减少了丢消息的可能:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
- 消息不存在重复消费问题:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
相关文章:
学习文档(5)
Redis应用 目录 Redis应用 Redis 除了做缓存,还能做什么? Redis 可以做消息队列么? Redis 可以做搜索引擎么? 如何基于 Redis 实现延时任务? Redis 除了做缓存,还能做什么? 分布式锁&…...

node.js下载安装以及环境配置超详细教程【Windows版本】
node安装以及环境变量配置 Step1:选择版本进行安装Step2:安装Node.jsStep3:环境配置Step4:检查node.js是否成功安装Step5:npm修改下载镜像 Step1:选择版本进行安装 Node.js 安装包及源码下载地址为 Node.…...

08_实现 reactive
目录 编写 reactive 的函数签名处理对象的其他行为拦截 in 操作符拦截 for...in 循环delete 操作符 处理边界新旧值发生变化时才触发依赖的情况处理从原型上继承属性的情况处理一个对象已经是代理对象的情况处理一个原始对象已经被代理过一次之后的情况 浅响应与深响应代理数组…...

finereport 中台 帆软 编码解码
帆软用的 post 方式编码不是用的 dict,而是二次 url 编码,需要二次解析 import time import urllib.parse import json# 原始字符串 encoded_string data "__parameters__%7B%22MANUFACTURER%22%3A%22%22%2C%22CATEGORY%22%3A%22%22%2C%22HHPN_L…...

Day15-数据库服务全面优化与PT工具应用
Day15-数据库服务全面优化与PT工具应用 1、数据库服务优化讲解1.2 数据库服务系统层面的优化1.3 数据库服务软件版本选择1.4 数据库服务结构参数优化1.4.1 数据库连接层优化1.4.2 数据库服务层优化1.4.3 数据库引擎层优化1.4.4 数据库复制相关优化1.4.5 数据库其他相关优化 1.5…...

开源限流组件分析(二):uber-go/ratelimit
文章目录 本系列漏桶限流算法uber的漏桶算法使用mutex版本数据结构获取令牌松弛量 atomic版本数据结构获取令牌测试漏桶的松弛量 总结 本系列 开源限流组件分析(一):juju/ratelimit开源限流组件分析(二):u…...

探索 SVG 创作新维度:svgwrite 库揭秘
文章目录 **探索 SVG 创作新维度:svgwrite 库揭秘**背景介绍库简介安装指南基础函数使用实战场景常见问题与解决方案总结 探索 SVG 创作新维度:svgwrite 库揭秘 背景介绍 在数字艺术和网页设计领域,SVG(Scalable Vector Graphic…...

为什么要做PFAS测试?PFAS检测项目详细介绍
PFAS测试之所以重要,主要归因于PFAS(全氟和多氟化合物)的广泛存在、持久性、生物累积性和潜在的毒性。这些特性使得PFAS在环境和人体中可能长期存在,并对生态系统和人类健康构成威胁。以下是对PFAS检测项目的详细介绍以及进行PFAS…...

稀土阻燃协效剂的应用
稀土阻燃协效剂是一类利用稀土元素(如铈、镧、钕、铕等)具有的独特性质,来增强材料阻燃性能的化学物质。在聚合物材料燃烧时可催化酯花成碳,迅速在高分子表面形成致密连续的碳层,隔绝聚合物材料内部的可燃性气体与氮气…...

Java的异常处理
常见异常 ① 运行时异常 a、ClassNotFoundException b、FileNotFoundException c、IOException ② 编译时异常 a、ArrayIndexOutOfBoundsException b、NullPointerException c、ClassCastException d、InputFormatException e、InputMismatchException f、ArithmeticException …...

免费域名邮箱申请和使用教程:有哪些步骤?
免费域名邮箱设置指南?如何免费注册烽火域名邮箱? 对于个人和企业而言,拥有一个专属的域名邮箱不仅能提升专业形象,还能增强品牌识别度。烽火将详细介绍如何申请和使用免费域名邮箱,帮助您轻松拥有一个专属的电子邮件…...

Linux之实战命令45:swapon应用实例(七十九)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...

提升数据处理效率:TDengine S3 的最佳实践与应用
在当今数据驱动的时代,如何高效地存储与处理海量数据成为了企业面临的一大挑战。为了解决这一问题,我们在 TDengine 3.2.2.0 首次发布了企业级功能 S3 存储。这一功能经历多个版本的迭代与完善后,逐渐发展成为一个全面和高效的解决方案。 S3…...

高级算法设计与分析 学习笔记13 线性规划
注意是线性规划不是动态规划哦 好家伙,这不是凸优化吗? 凸优化标准形式: 先改成统一最大化(凸优化那边怎么是统一最小化?) 原来的x2正负无所谓,但我希望每个x都是有限制的,所以把它改…...
2024年11月软考中项应试技巧与机考注意事项!
软考中项的备考技巧 重点来了!这部分是我辛苦总结出来的备考技巧,都是我当年备考时逐渐整合出来的,绝对够用,赶紧跟我一起掌握吧! 1.基础知识 在学习时建议大家先跟着班课老师结合教材过一遍基础知识。强调跟着班课…...

网络编程中容易踩的坑罗列,谨记!
1、TCP没考虑粘包分包 TCP是面向连接的可靠协议,TCP是流式协议,创建TCP套接字的类型为SOCK_STREAM int sockfd socket(AF_INET, SOCK_STREAM, 0);很多同学面试时对书上的话背诵如流,在实际TCP编程中却没有处理粘包和分包的代码,以…...

SD-WAN:推动企业网络优化与发展
近年来,软件定义广域网(SD-WAN)逐渐成为众多企业的首选网络解决方案。这背后的原因是什么?接下来我们将深入探讨这一趋势。 在快速发展的通信技术领域,企业对高效、灵活且可扩展的网络架构需求愈发迫切。随着数据流量的…...

[MyBatis-Plus]扩展功能详解
代码生成 使用MP的步骤是非常固定的几步操作 基于插件, 可以快速的生成基础性的代码 安装插件安装完成后重启IEDA连接数据库 mp是数据库的名字?serverTimezoneUTC 是修复mysql时区, 不加会报错 生成代码 TablePrefix选项是用于去除表名的前缀, 比如根据tb_user表生成实体类U…...
)
循序渐进丨MogDB 5.0 远程访问 MogDB/Oracle 数据库的简便方法(使用@符号)
概述 早期的 MogDB 就提供了Postgres_fdw、Oracle_fdw、MySQL_fdw3个插件,用于远程访问 MogDB/Oracle/MySQL数据库。 旧的版本中,访问远程数据库的表,需要显式创建外部表,而在 MogDB 5.0当中,这种用法得到了简化&…...

大模型训练触达「瓶颈」,基座模型厂商还有必要坚持预训练吗?
进入2024年来,中国大模型行业从狂奔进入到了“长跑阶段”。无论是在技术侧,还是在产业侧,行业内都产生了更多新的思考。 从技术发展上看,在算力受限的情况下,中国基座模型的研发能力在全球范围内处在什么身位、如何追赶…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...

如何3步掌握MultiFunPlayer:专业设备同步工具快速入门指南
如何3步掌握MultiFunPlayer:专业设备同步工具快速入门指南 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer MultiFunPlayer是一款专…...

Win11Debloat:一键打造纯净高效的Windows 11终极优化指南
Win11Debloat:一键打造纯净高效的Windows 11终极优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and…...

在Node.js后端服务中集成Taotoken实现AI功能调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现AI功能调用 将大模型能力集成到后端服务是现代应用开发的常见需求。对于Node.js开发者而言&a…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

ElevenLabs匈牙利语音API响应延迟飙升300%?内网穿透+CDN缓存+匈牙利语音素预加载三阶优化方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利文语音API响应延迟飙升300%的现象复现与根因定位 近期多位开发者反馈,ElevenLabs API 在处理匈牙利语(hu-HU)文本转语音请求时,平均端到…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

Go语言SDK开发实战:为AI编程助手Cursor构建高效API客户端
1. 项目概述:一个为AI编程助手Cursor定制的Go语言SDK如果你和我一样,日常重度依赖Cursor这类AI编程助手来提升开发效率,同时又是个Go语言的忠实拥趸,那你肯定遇到过这样的场景:想用Go写个脚本,自动化处理一…...

Arm Neoverse CMN-700性能监控与优化实践
1. Arm Neoverse CMN-700性能监控体系解析在现代多核处理器架构中,性能监控单元(PMU)如同系统的"听诊器",能够实时捕捉微架构层面的各种行为指标。Arm Neoverse CMN-700作为面向基础设施级应用的互联架构,其PMU设计尤其强调对Mesh网…...