超详细的总结!最新大模型算法岗面试题(含答案)来了!
大模型应该是目前当之无愧的最有影响力的AI技术,它正在革新各个行业,包括自然语言处理、机器翻译、内容创作和客户服务等,正成为未来商业环境的重要组成部分。
截至目前大模型已超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关岗位和面试也开始越来越卷了。

年前,我们技术群组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂同学、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、入门大模型算法岗该如何准备、面试常考点、面经等热门话题进行了热烈的讨论。
我今天给大家分享一些梳理的面试题,内容较长,喜欢记得收藏、关注、点赞。
一、基础篇
目前主流的开源模型体系有哪些?
- Transformer体系:由Google提出的Transformer模型及其变体,如BERT、GPT等。
- PyTorch Lightning:一个基于PyTorch的轻量级深度学习框架,用于快速原型设计和实验。
- TensorFlow Model Garden:TensorFlow官方提供的一系列预训练模型和模型架构。
- Hugging Face Transformers:一个流行的开源库,提供了大量预训练模型和工具,用于NLP任务。
prefix LM 和 causal LM 区别是什么?
- prefix LM(前缀语言模型):在输入序列的开头添加一个可学习的任务相关的前缀,然后使用这个前缀和输入序列一起生成输出。这种方法可以引导模型生成适应特定任务的输出。
- causal LM(因果语言模型):也称为自回归语言模型,它根据之前生成的 token 预测下一个 token。在生成文本时,模型只能根据已经生成的部分生成后续部分,不能访问未来的信息。
涌现能力是啥原因?
涌现能力(Emergent Ability)是指模型在训练过程中突然表现出的新的、之前未曾预料到的能力。这种现象通常发生在大型模型中,原因是大型模型具有更高的表示能力和更多的参数,可以更好地捕捉数据中的模式和关联。随着模型规模的增加,它们能够自动学习到更复杂、更抽象的概念和规律,从而展现出涌现能力。
大模型LLM的架构介绍?
大模型LLM(Large Language Models)通常采用基于Transformer的架构。Transformer模型由多个编码器或解码器层组成,每个层包含多头自注意力机制和前馈神经网络。这些层可以并行处理输入序列中的所有位置,捕获长距离依赖关系。大模型通常具有数十亿甚至数千亿个参数,可以处理大量的文本数据,并在各种NLP任务中表现出色。
前馈神经网络(Feedforward Neural Network)是一种最基础的神经网络类型,它的信息流动是单向的,从输入层经过一个或多个隐藏层,最终到达输出层。在前馈神经网络中,神经元之间的连接不会形成闭环,这意味着信号在前向传播过程中不会回溯。
前馈神经网络的基本组成单元是神经元,每个神经元都会对输入信号进行加权求和,然后通过一个激活函数产生输出。激活函数通常是非线性的,它决定了神经元的输出是否应该被激活,从而允许网络学习复杂和非线性的函数。
前馈神经网络在模式识别、函数逼近、分类、回归等多个领域都有应用。例如,在图像识别任务中,网络的输入层节点可能对应于图像的像素值,而输出层节点可能代表不同类别的概率分布。
训练前馈神经网络通常涉及反向传播(Backpropagation)算法,这是一种有效的学习算法,通过计算输出层的误差,并将这些误差信号沿网络反向传播,以调整连接权重。通过多次迭代这个过程,网络可以逐渐学习如何减少输出误差,从而实现对输入数据的正确分类或回归。
在设计和训练前馈神经网络时,需要考虑多个因素,包括网络的层数、每层的神经元数目、激活函数的选择、学习速率、正则化策略等,这些都对网络的性能有重要影响。
你比较关注哪些主流的开源大模型?
- GPT系列:由OpenAI开发的生成式预训练模型,如GPT-3。
- BERT系列:由Google开发的转换式预训练模型,如BERT、RoBERTa等。
- T5系列:由Google开发的基于Transformer的编码器-解码器模型,如T5、mT5等。
目前大模型模型结构都有哪些?
- Transformer:基于自注意力机制的模型,包括编码器、解码器和编码器-解码器结构。
- GPT系列:基于自注意力机制的生成式预训练模型,采用解码器结构。
- BERT系列:基于自注意力机制的转换式预训练模型,采用编码器结构。
- T5系列:基于Transformer的编码器-解码器模型。
prefix LM 和 causal LM、encoder-decoder 区别及各自有什么优缺点?
- prefix LM:通过在输入序列前添加可学习的任务相关前缀,引导模型生成适应特定任务的输出。优点是可以减少对预训练模型参数的修改,降低过拟合风险;缺点是可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息。
- causal LM:根据之前生成的 token 预测下一个 token,可以生成连贯的文本。优点是可以生成灵活的文本,适应各种生成任务;缺点是无法访问未来的信息,可能生成不一致或有误的内容。
- encoder-decoder:由编码器和解码器组成,编码器将输入序列编码为固定长度的向量,解码器根据编码器的输出生成输出序列。优点是可以处理输入和输出序列不同长度的任务,如机器翻译;缺点是模型结构较为复杂,训练和推理计算量较大。
模型幻觉是什么?业内解决方案是什么?
模型幻觉是指模型在生成文本时产生的不准确、无关或虚构的信息。这通常发生在模型在缺乏足够信息的情况下进行推理或生成时。业内的解决方案包括:
- 使用更多的数据和更高质量的训练数据来提高模型的泛化和准确性。
- 引入外部知识源,如知识库或事实检查工具,以提供额外的信息和支持。
- 强化模型的推理能力和逻辑推理,使其能够更好地处理复杂问题和避免幻觉。
大模型的Tokenizer的实现方法及原理?
大模型的Tokenizer通常使用字节对编码(Byte-Pair Encoding,BPE)算法。BPE算法通过迭代地将最频繁出现的字节对合并成新的符号,来构建一个词汇表。在训练过程中,模型会学习这些符号的嵌入表示。Tokenizer将输入文本分割成符号序列,然后将其转换为模型可以处理的数字表示。这种方法可以有效地处理大量文本数据,并减少词汇表的规模。
ChatGLM3 的词表实现方法?
ChatGLM3使用了一种改进的词表实现方法。它首先使用字节对编码(BPE)算法构建一个基本的词表,然后在训练过程中通过不断更新词表来引入新的词汇。具体来说,ChatGLM3在训练过程中会根据输入数据动态地合并出现频率较高的字节对,从而形成新的词汇。这样可以有效地处理大量文本数据,并减少词汇表的规模。同时,ChatGLM3还使用了一种特殊的词表分割方法,将词表分为多个片段,并在训练过程中逐步更新这些片段,以提高模型的泛化能力和适应性。
GPT3、LLAMA、ChatGLM 的Layer Normalization 的区别是什么?各自的优缺点是什么?
- GPT3:采用了Post-Layer Normalization(后标准化)的结构,即先进行自注意力或前馈神经网络的计算,然后进行Layer Normalization。这种结构有助于稳定训练过程,提高模型性能。
- LLAMA:采用了Pre-Layer Normalization(前标准化)的结构,即先进行Layer Normalization,然后进行自注意力或前馈神经网络的计算。这种结构有助于提高模型的泛化能力和鲁棒性。
- ChatGLM:采用了Post-Layer Normalization的结构,类似于GPT3。这种结构可以提高模型的性能和稳定性。
大模型常用的激活函数有哪些?
- ReLU(Rectified Linear Unit):一种简单的激活函数,可以解决梯度消失问题,加快训练速度。
- GeLU(Gaussian Error Linear Unit):一种改进的ReLU函数,可以提供更好的性能和泛化能力。
- Swish:一种自门控激活函数,可以提供非线性变换,并具有平滑和非单调的特性。
Multi-query Attention 与 Grouped-query Attention 是否了解?区别是什么?
- Multi-query Attention和Grouped-query Attention是两种不同的注意力机制变种,用于改进和扩展传统的自注意力机制。
- Multi-query Attention:在Multi-query Attention中,每个查询可以与多个键值对进行交互,从而捕捉更多的上下文信息。这种机制可以提高模型的表达能力和性能,特别是在处理长序列或复杂关系时。
- Grouped-query Attention:在Grouped-query Attention中,查询被分成多个组,每个组内的查询与对应的键值对进行交互。这种机制可以减少计算复杂度,提高效率,同时仍然保持较好的性能。
多模态大模型是否有接触?落地案例?
多模态大模型是指可以处理和理解多种模态数据(如文本、图像、声音等)的模型。落地案例,例如:
- OpenAI的DALL-E和GPT-3:DALL-E是一个可以生成图像的模型,而GPT-3可以处理和理解文本。两者结合可以实现基于文本描述生成图像的功能。
- Google的Multimodal Transformer:这是一个可以同时处理文本和图像的模型,用于各种多模态任务,如图像字幕生成、视觉问答等。
二、大模型(LLMs)进阶
1.llama 输入句子长度理论上可以无限长吗?
LLaMA(Large Language Model Adaptation)模型的输入句子长度受到硬件资源和模型设计的限制。理论上,如果硬件资源足够,模型可以处理非常长的输入句子。然而,实际上,由于内存和处理能力的限制,输入句子长度通常是有限制的。在实际应用中,开发者会根据具体需求和硬件配置来确定合适的输入句子长度。
2.什么是 LLMs 复读机问题?
LLMs 复读机问题是指在某些情况下,大型语言模型在生成文本时会重复之前已经生成的内容,导致生成的文本缺乏多样性和创造性。
3.为什么会出现 LLMs 复读机问题?
LLMs 复读机问题可能由多种因素引起,包括模型训练数据中的重复模式、模型在处理长序列时的注意力机制失效、或者模型在生成文本时对过去信息的过度依赖等。
4.如何缓解 LLMs 复读机问题?
- 数据增强:通过增加训练数据的多样性和复杂性,减少重复模式的出现。
- 模型改进:改进模型的结构和注意力机制,使其更好地处理长序列和避免过度依赖过去信息。
- 生成策略:在生成文本时采用多样化的策略,如抽样生成或引入随机性,以增加生成文本的多样性。
5.LLMs 复读机问题
6.llama 系列问题
7.什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型?
BERT 模型通常用于需要理解文本深层语义的任务,如文本分类、命名实体识别等。LLaMA 和 ChatGLM 类大模型则适用于需要生成文本或进行更复杂语言理解的任务,如对话系统、文本生成等。选择哪种模型取决于任务的需求和可用资源。
8.各个专业领域是否需要各自的大模型来服务?
不同的专业领域需要特定的大模型来更好地服务。专业领域的大模型可以针对特定领域的语言和知识进行优化,提供更准确和相关的回答和生成文本。
9.如何让大模型处理更长的文本?
- 使用模型架构,如Transformer,它可以有效地处理长序列。
- 使用内存机制,如外部记忆或缓存,来存储和检索长文本中的信息。
- 使用分块方法,将长文本分割成更小的部分,然后分别处理这些部分。
10.大模型参数微调、训练、推理
如何让大模型输出合规化?
- 过滤不当内容:使用内容过滤器来识别和过滤掉不当的语言或敏感内容。
- 指导性提示:提供明确的提示,指导模型生成符合特定标准和偏好的输出。
- 后处理:对模型的输出进行后处理,例如使用语法检查器和修正工具来提高文本的质量。
- 强化学习:使用强化学习来训练模型,使其偏好生成符合特定标准的输出。
应用模式变更
应用模式变更是指在部署模型时,根据实际应用的需求和环境,对模型的配置、部署策略或使用方式进行调整。例如,一个在云端运行的模型可能需要调整其资源分配以适应不同的负载,或者在边缘设备上运行的模型可能需要减少其内存和计算需求以适应有限的资源。
应用模式变更可能包括: - 资源调整:根据需求增加或减少用于运行模型的计算资源。
- 模型压缩:使用模型压缩技术如剪枝、量化来减少模型大小。
- 动态部署:根据负载动态地扩展或缩小模型服务的实例数量。
- 缓存策略:实施缓存机制来存储常用查询的响应,减少重复计算的次数。
- 性能优化:对模型进行性能分析,并优化其运行效率,例如通过批处理输入数据来提高吞吐量。
举例来说,如果一个大型语言模型在云平台上运行,当用户查询量增加时,可以通过增加服务器的数量或使用更高效的硬件来扩展其能力。相反,如果模型需要在嵌入式设备上运行,可能需要将模型压缩到更小的尺寸,并优化其运行时的内存使用,以确保模型可以在资源有限的设备上顺利运行。
在实际操作中,应用模式变更通常需要综合考虑模型的性能、成本、可扩展性和业务需求,以找到最佳的平衡点。
为了帮助大家更好地把握AI大模型的学习和发展机遇,下面提供一份AI大模型的学习路线图以及相关的学习资源,旨在帮助您快速掌握AI大模型的核心技术和应用场景。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相关文章:
超详细的总结!最新大模型算法岗面试题(含答案)来了!
大模型应该是目前当之无愧的最有影响力的AI技术,它正在革新各个行业,包括自然语言处理、机器翻译、内容创作和客户服务等,正成为未来商业环境的重要组成部分。 截至目前大模型已超过200个,在大模型纵横的时代,不仅大模…...

vmware-17pro全网最细安装教程(图文讲解,不需注册账户)
文章目录 一、下载安装包: 二、安装教程: 三、检查是否安装成功 四、许可证密匙 vmware安装教程 一、下载安装包: 链接:https://pan.baidu.com/s/1yC610SU1-O9Jtk7nUrZuSA?pwdsKBy 提取码:sKBy 二、安装教程&…...
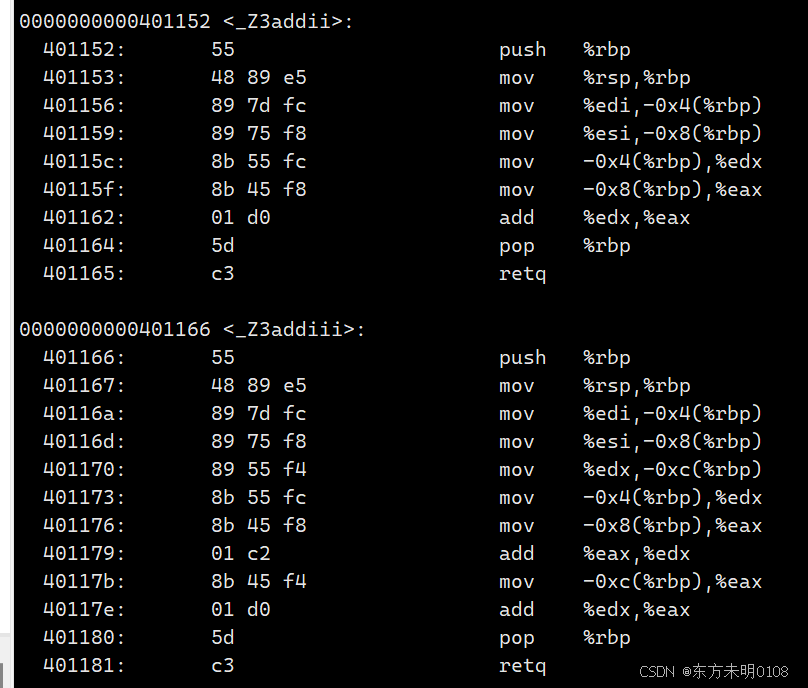
C/C++(二)C++入门基础
这一章会介绍C入门必须掌握的一些基础概念。 一、函数重载 1、什么是函数重载? 函数重载是C相比于C语言的一个重大改进。 即C允许在同一作用域内声明多个功能类似的同名函数,这些函数的参数类型 / 个数 / 类型顺序不同。(注:返回…...

人工智能发展:一场从“被教导”到“自我成长”的奇妙冒险
说到人工智能(AI),大家的第一反应往往是机器人、无人驾驶、或者那个让人害怕的AI会不会取代人类。其实,AI的进化过程简直像一部精彩的电影,有起伏、有高潮、有让人摸不着头脑的时刻。今天,我们就一起来“吃…...

企业级 RAG 全链路优化关键技术
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人: 邢少敏 | 阿里云智能集团高级技术专家 活动: 2024 云栖大会 - AI 搜索企业级 RAG 全链路优化关键技术 在2024云栖大会上,阿里云 AI 搜索研发负责人之一的…...
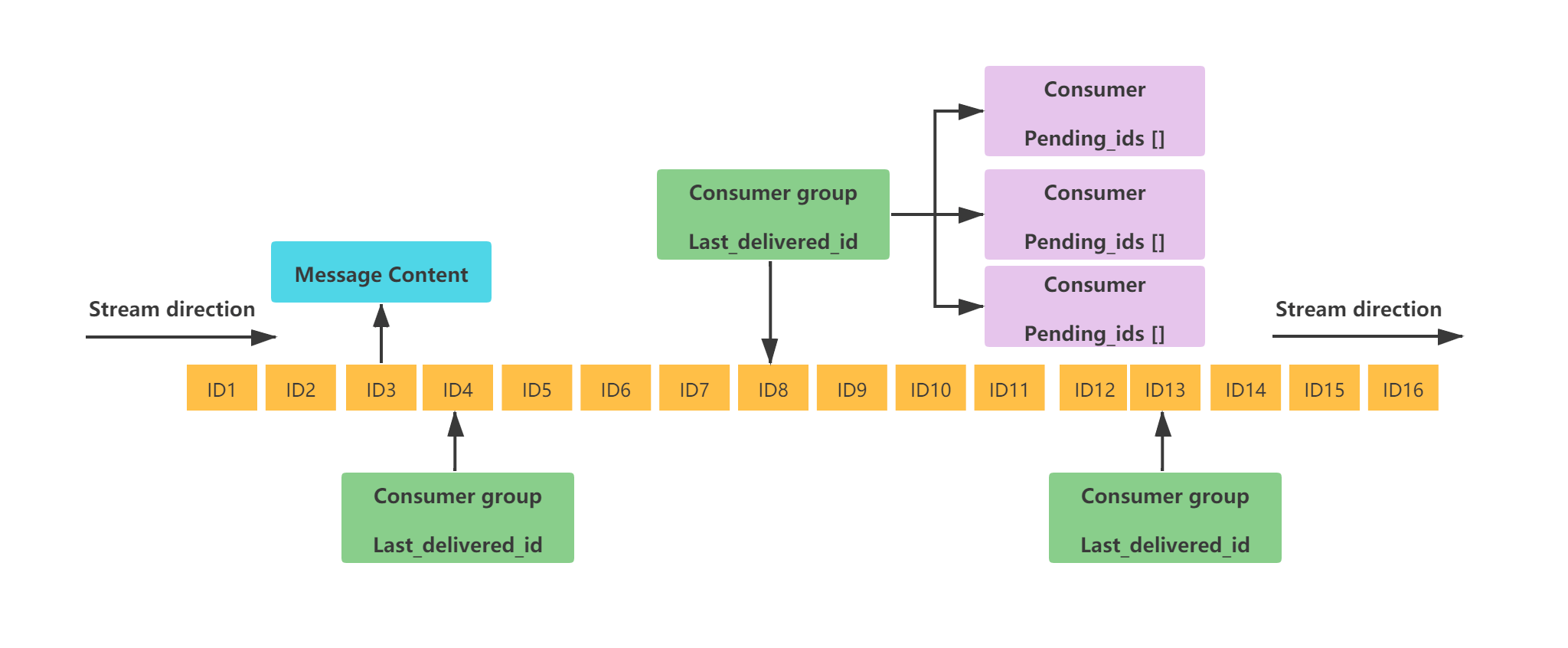
学习文档(5)
Redis应用 目录 Redis应用 Redis 除了做缓存,还能做什么? Redis 可以做消息队列么? Redis 可以做搜索引擎么? 如何基于 Redis 实现延时任务? Redis 除了做缓存,还能做什么? 分布式锁&…...

node.js下载安装以及环境配置超详细教程【Windows版本】
node安装以及环境变量配置 Step1:选择版本进行安装Step2:安装Node.jsStep3:环境配置Step4:检查node.js是否成功安装Step5:npm修改下载镜像 Step1:选择版本进行安装 Node.js 安装包及源码下载地址为 Node.…...

08_实现 reactive
目录 编写 reactive 的函数签名处理对象的其他行为拦截 in 操作符拦截 for...in 循环delete 操作符 处理边界新旧值发生变化时才触发依赖的情况处理从原型上继承属性的情况处理一个对象已经是代理对象的情况处理一个原始对象已经被代理过一次之后的情况 浅响应与深响应代理数组…...

finereport 中台 帆软 编码解码
帆软用的 post 方式编码不是用的 dict,而是二次 url 编码,需要二次解析 import time import urllib.parse import json# 原始字符串 encoded_string data "__parameters__%7B%22MANUFACTURER%22%3A%22%22%2C%22CATEGORY%22%3A%22%22%2C%22HHPN_L…...

Day15-数据库服务全面优化与PT工具应用
Day15-数据库服务全面优化与PT工具应用 1、数据库服务优化讲解1.2 数据库服务系统层面的优化1.3 数据库服务软件版本选择1.4 数据库服务结构参数优化1.4.1 数据库连接层优化1.4.2 数据库服务层优化1.4.3 数据库引擎层优化1.4.4 数据库复制相关优化1.4.5 数据库其他相关优化 1.5…...

开源限流组件分析(二):uber-go/ratelimit
文章目录 本系列漏桶限流算法uber的漏桶算法使用mutex版本数据结构获取令牌松弛量 atomic版本数据结构获取令牌测试漏桶的松弛量 总结 本系列 开源限流组件分析(一):juju/ratelimit开源限流组件分析(二):u…...

探索 SVG 创作新维度:svgwrite 库揭秘
文章目录 **探索 SVG 创作新维度:svgwrite 库揭秘**背景介绍库简介安装指南基础函数使用实战场景常见问题与解决方案总结 探索 SVG 创作新维度:svgwrite 库揭秘 背景介绍 在数字艺术和网页设计领域,SVG(Scalable Vector Graphic…...

为什么要做PFAS测试?PFAS检测项目详细介绍
PFAS测试之所以重要,主要归因于PFAS(全氟和多氟化合物)的广泛存在、持久性、生物累积性和潜在的毒性。这些特性使得PFAS在环境和人体中可能长期存在,并对生态系统和人类健康构成威胁。以下是对PFAS检测项目的详细介绍以及进行PFAS…...

稀土阻燃协效剂的应用
稀土阻燃协效剂是一类利用稀土元素(如铈、镧、钕、铕等)具有的独特性质,来增强材料阻燃性能的化学物质。在聚合物材料燃烧时可催化酯花成碳,迅速在高分子表面形成致密连续的碳层,隔绝聚合物材料内部的可燃性气体与氮气…...

Java的异常处理
常见异常 ① 运行时异常 a、ClassNotFoundException b、FileNotFoundException c、IOException ② 编译时异常 a、ArrayIndexOutOfBoundsException b、NullPointerException c、ClassCastException d、InputFormatException e、InputMismatchException f、ArithmeticException …...

免费域名邮箱申请和使用教程:有哪些步骤?
免费域名邮箱设置指南?如何免费注册烽火域名邮箱? 对于个人和企业而言,拥有一个专属的域名邮箱不仅能提升专业形象,还能增强品牌识别度。烽火将详细介绍如何申请和使用免费域名邮箱,帮助您轻松拥有一个专属的电子邮件…...

Linux之实战命令45:swapon应用实例(七十九)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...

提升数据处理效率:TDengine S3 的最佳实践与应用
在当今数据驱动的时代,如何高效地存储与处理海量数据成为了企业面临的一大挑战。为了解决这一问题,我们在 TDengine 3.2.2.0 首次发布了企业级功能 S3 存储。这一功能经历多个版本的迭代与完善后,逐渐发展成为一个全面和高效的解决方案。 S3…...

高级算法设计与分析 学习笔记13 线性规划
注意是线性规划不是动态规划哦 好家伙,这不是凸优化吗? 凸优化标准形式: 先改成统一最大化(凸优化那边怎么是统一最小化?) 原来的x2正负无所谓,但我希望每个x都是有限制的,所以把它改…...
2024年11月软考中项应试技巧与机考注意事项!
软考中项的备考技巧 重点来了!这部分是我辛苦总结出来的备考技巧,都是我当年备考时逐渐整合出来的,绝对够用,赶紧跟我一起掌握吧! 1.基础知识 在学习时建议大家先跟着班课老师结合教材过一遍基础知识。强调跟着班课…...

原来选对床垫还能改善全家睡眠质量?
选对床垫,改善全家睡眠质量的秘密在快节奏的现代生活中,良好的睡眠质量变得越来越重要。一张合适的床垫不仅能提升个人的睡眠体验,还能改善全家人的睡眠质量。本文将探讨如何选择适合全家人的床垫,并重点介绍美德丽床垫的独特优势…...

RStudio 2026最新版下载:一键直达官网,解锁数据分析新体验
RStudio免费版安装包下载地址:RStudio安装包 RStudio 是 R 语言专用的集成开发环境,简单说就是 R 语言的 “超级工作台”。它不替代 R 语言,而是必须搭配 R 语言使用,负责把 R 语言的能力可视化、流程化、高效化。 RStudio 的核心…...

5分钟掌握猫抓扩展:浏览器视频下载终极指南
5分钟掌握猫抓扩展:浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到精彩的在线视频却无法下载保…...

Flask核心进阶:路由、模板与静态文件实战
在掌握Flask入门知识后,想要开发出更具实用性和美观度的Web应用,就需要深入学习其核心进阶功能,其中路由、模板与静态文件是最基础也是最常用的三个模块,三者协同工作,构成了Flask Web应用的前端展示与请求分发体系。路…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...