LaMI-DETR:基于GPT丰富优化的开放词汇目标检测 | ECCV‘24
现有的方法通过利用视觉-语言模型(
VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测,然而出现了两个主要挑战:(1)概念表示不足,CLIP文本空间中的类别名称缺乏文本和视觉知识。(2)对基础类别的过拟合倾向,在从VLMs到检测器的转移过程中,开放词汇知识偏向于基础类别。为了解决这些挑战,论文提出了语言模型指令(
LaMI)策略,该策略利用视觉概念之间的关系,并将其应用于一种简单而有效的类似DETR的检测器,称为LaMI-DETR。LaMI利用GPT构建视觉概念,并使用T5研究类别之间的视觉相似性。类别之间的这些关系改善了概念表示,避免了对基础类别的过拟合。全面的实验验证了该方法在相同严格设置下的优越性能,不依赖于外部训练资源。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction

- 论文地址:https://arxiv.org/abs/2407.11335
- 论文代码:https://github.com/eternaldolphin/LaMI-DETR
Introduction
开放词汇目标检测(OVOD)旨在识别和定位来自广泛类别的物体,包括在推理过程中的基础类别和新类别,即使仅在有限的基础类别上进行训练。现有的开放词汇目标检测研究主要集中在检测器内部复杂模块的开发,这些模块旨在有效地将视觉-语言模型(VLMs)固有的零样本和少样本学习能力用于目标检测的上下文。
然而,大多数现有方法中存在两个挑战:(1)概念表示。大多数现有方法使用来自CLIP文本编码器的名称嵌入来表示概念。然而,这种概念表示方法在捕捉类别之间的文本和视觉语义相似性方面存在局限性,这种相似性有助于区分视觉上容易混淆的类别并探索潜在的新对象;(2)对基础类别的过拟合。尽管VLMs在新类别上表现良好,但开放词汇检测器的优化仅使用基础检测数据,导致检测器对基础类别的过拟合。因此,新对象容易被视为背景或基础类别。

首先,是概念表示的问题。CLIP文本空间中的类别名称在文本深度和视觉信息方面都存在不足。(1) 与语言模型相比,VLM的文本编码器缺乏文本语义知识。如图1a所示,仅依赖于来自CLIP的名称表示会集中于字母组成的相似性,忽视了语言背后的层次性和常识理解。这种方法对分类聚类不利,因为它未能考虑类别之间的概念关系。(2) 基于抽象类别名称或定义的现有概念表示未能考虑视觉特征。图1b展示了这个问题,尽管海狮和儒艮在视觉上相似,但它们被分配到了不同的聚类中。仅用类别名称表示概念忽视了语言所提供的丰富视觉语境,这可能有助于发现潜在的新对象。
其次,是对基础类别的过拟合问题。为充分利用VLM的开放词汇能力,采用一个冻结的CLIP图像编码器作为主干网络,并利用来自CLIP文本编码器的类别嵌入作为分类权重。论文认为,检测器训练应发挥两个主要功能:首先,区分前景和背景;其次,保持CLIP的开放词汇分类能力。然而,仅在基础类别注释上进行训练,而不结合额外策略,往往导致过拟合:新对象常常被错误分类为背景或基础类别。
探索类别之间关系是解决上述挑战的关键。通过培养对这些关系的细致理解,可以开发一种结合文本和视觉语义的概念表示方法。这种方法还可以识别视觉上相似的类别,引导模型更专注于学习通用的前景特征,从而防止对基础类别的过拟合。因此,论文提出了LaMI-DETR(Frozen CLIP-based DETR with Language Model Instruction),这是一种简单但有效的基于DETR的检测器,利用语言模型的见解提取类别间关系来解决上述挑战。
为了解决概念表示的问题,首先采用Instructor Embedding,一种T5语言模型,重新评估类别的相似性。与CLIP文本编码器相比,语言模型展现出更为细致的语义空间。如图1b所示,“fireweed”(火绒草)和“fireboat”(消防船)被分类到不同的簇中,更加贴近人类的识别方式。接下来,引入GPT-3.5为每个类别生成视觉描述。这包括对形状、颜色和大小等方面的详细描述,有效地将这些类别转换为视觉概念。图1c显示,在相似的视觉描述下,海狮和儒艮现在被归为同一簇。
为了减轻过拟合问题,根据T5的视觉描述嵌入将视觉概念聚类成组。这个聚类结果使得在每次迭代中能够识别和抽样与真实类别在视觉上不同的负类。这放宽了分类的优化,集中模型的注意力于推导更为通用的前景特征,而不是过拟合到基础类别。因此,这种方法通过减少对基础类别的过训练增强了模型的泛化能力,同时保留了CLIP图像骨干的分类能力。
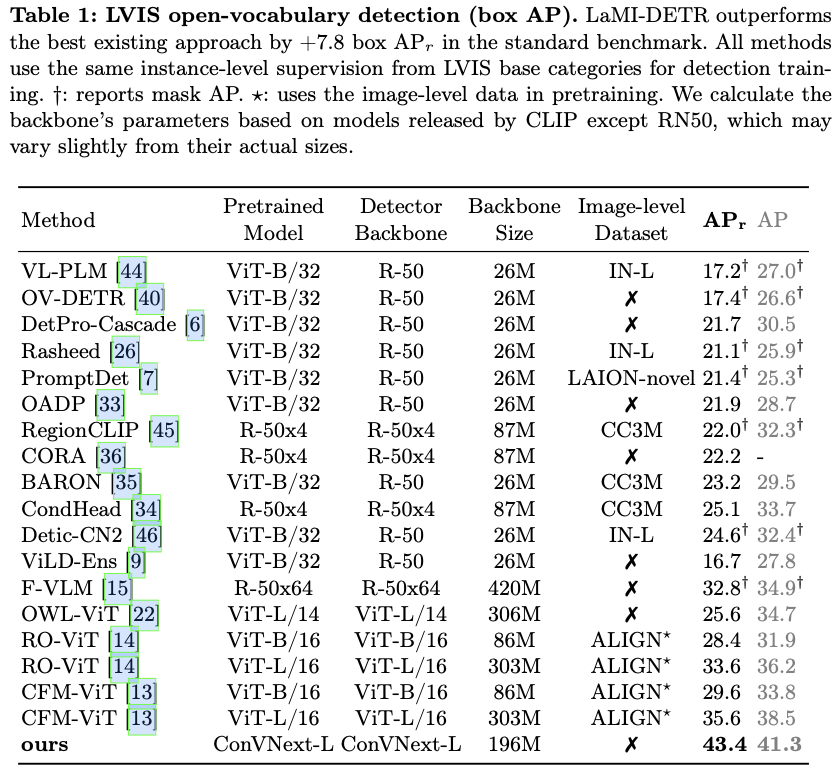
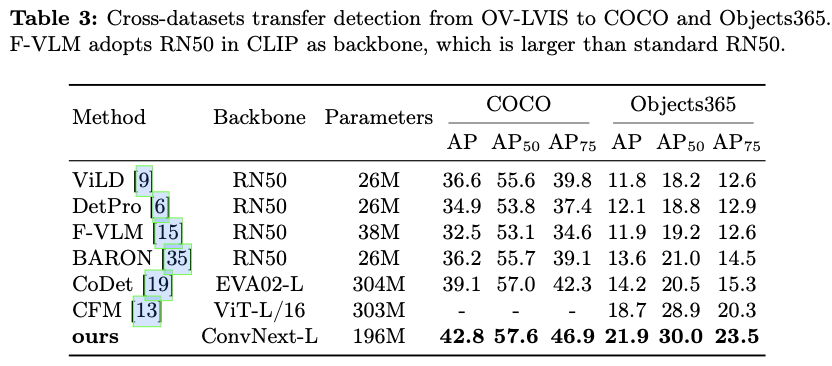
总之,论文提出了一种新颖的方法LaMI,以增强OVOD中的基础到新类别的泛化能力。LaMI利用大型语言模型提取类别之间的关系,并利用这些信息抽样简单的负类,以避免对基础类别的过拟合,同时优化概念表示,以实现视觉上相似类别之间的有效分类。论文提出了一个简单但有效的端到端LaMI-DETR框架,能够有效地将开放词汇知识从预训练的VLM转移到检测器上。通过在大词汇OVOD基准上进行严格测试,展示了LaMI-DETR框架的优越性,包括在OV-LVIS上提升 + 7.8 +7.8 +7.8 AP r _\textrm{r} r 和在VG-dedup上提升 + 2.9 +2.9 +2.9 AP r _\textrm{r} r (与OWL进行公平比较)。
Method
Preliminaries
给定一个输入的图像 I ∈ R H × W × 3 \mathbf{I} \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3 到开放词汇对象检测器,通常会生成两个主要输出:(1)分类,其中为图像中第 j th j^{\text{th}} jth 预测对象分配一个类别标签 c j ∈ C test c_j \in \mathcal{C}_{\text{test}} cj∈Ctest , C test \mathcal{C}_{\text{test}} Ctest 表示在推理过程中针对的类别集合。(2)定位,包括确定边界框坐标 b j ∈ R 4 \mathbf{b}_j \in \mathbb{R}^4 bj∈R4 ,以识别第 j th j^{\text{th}} jth 预测对象的位置。遵循OVR-CNN建立的框架,定义了一个检测数据集 D det \mathcal{D}_{\text{det}} Ddet ,该数据集包含边界框坐标、类别标签及对应的图像,用于处理类别词汇 C det \mathcal{C}_{\text{det}} Cdet 。
遵循OVOD的惯例,将 C test \mathcal{C}_{\text{test}} Ctest 和 C det \mathcal{C}_{\text{det}} Cdet 的类别空间分别表示为 C \mathcal{C} C 和 C B \mathcal{C}_{\text{B}} CB 。通常情况下, C B ⊂ C \mathcal{C}_{\text{B}} \subset \mathcal{C} CB⊂C 。 C B \mathcal{C}_{\text{B}} CB 中的类别被称为基础类别,而仅出现在 C test \mathcal{C}_{\text{test}} Ctest 中的类别则被称为新类别。新类别的集合表示为 C N = C ∖ C B ≠ ∅ \mathcal{C}_{\text{N}} = \mathcal{C} \setminus \mathcal{C}_{\text{B}} \neq \varnothing CN=C∖CB=∅ 。对于每个类别 c ∈ C c \in \mathcal{C} c∈C ,利用CLIP编码其文本嵌入 t c ∈ R d t_c \in \mathbb{R}^d tc∈Rd ,并定义 T cls = { t c } c = 1 C \mathcal{T}_{\texttt{cls}} = \{t_c\}_{c=1}^C Tcls={tc}c=1C ( C C C 是类别词汇的大小)。
Architecture of LaMI-DETR
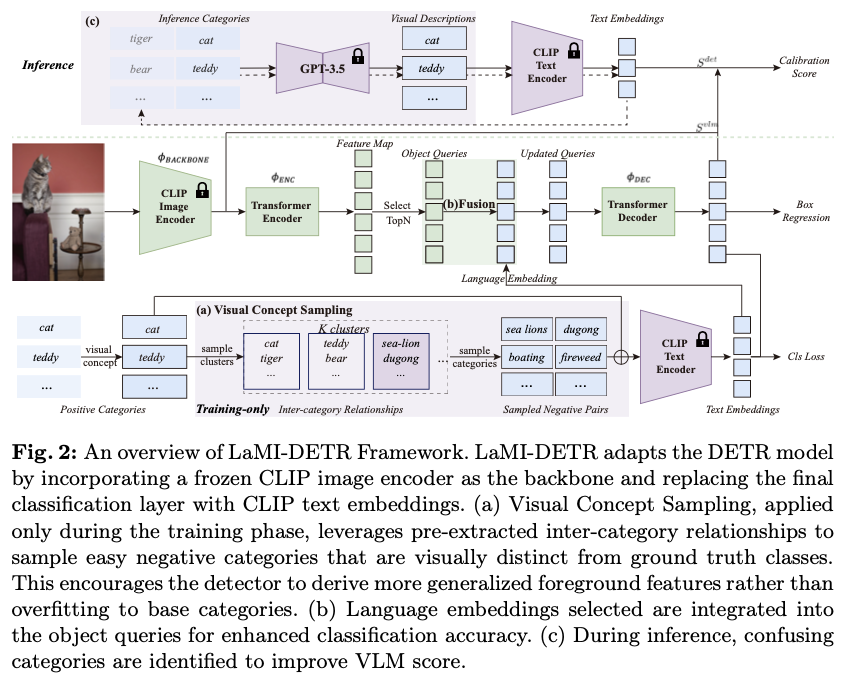
LaMI-DETR的整体框架如图2所示。给定一个图像输入,使用预训练的CLIP图像编码器中的ConvNext主干网络 ( Φ backbone ) \left(\Phi_{\texttt{backbone}}\right) (Φbackbone) 获取空间特征图,该主干在训练期间保持不变。然后,特征图依次经过一系列操作:一个Transformer编码器 ( Φ enc ) \left(\Phi_{\texttt{enc}}\right) (Φenc) 来完善特征图;一个Transformer解码器 ( Φ dec ) \left(\Phi_{\texttt{dec}}\right) (Φdec) ,生成一组查询特征 { f j } j = 1 N \left\{f_j\right\}_{j=1}^{N} {fj}j=1N 。查询特征随后由边界框模块 ( Φ bbox ) \left(\Phi_{\texttt{bbox}}\right) (Φbbox) 处理,以推断对象的位置,记作 { b j } j = 1 N \left\{\mathbf{b}_j\right\}_{j=1}^{N} {bj}j=1N 。
遵循F-VLM的推理流程,并使用VLM分数 S v l m S^{vlm} Svlm 来校准检测分数 S d e t S^{det} Sdet 。
S j v l m = T cls ⋅ Φ pooling ( b j ) S c c a l = { S c v l m α ⋅ S c d e t ( 1 − α ) if c ∈ C B S c v l m β ⋅ S c d e t ( 1 − β ) if c ∈ C N \begin{align} & S_j^{vlm} = \mathcal{T}_\texttt{cls}\cdot\Phi_\text{pooling}\left(b_j\right) \\ &S_c^{cal} = \begin{cases} {S^{vlm}_c}^\alpha \cdot {S^{det}_c}^{(1-\alpha)} & \text{if } c \in \mathcal{C}_B \\ {S^{vlm}_c}^\beta \cdot {S^{det}_c}^{(1-\beta)} & \text{if } c \in \mathcal{C}_N \end{cases} \end{align} Sjvlm=Tcls⋅Φpooling(bj)Sccal={Scvlmα⋅Scdet(1−α)Scvlmβ⋅Scdet(1−β)if c∈CBif c∈CN
CORA和EdaDet框架也在DETR中使用一个被冻结的CLIP图像编码器来提取图像特征。然而,LaMI-DETR在以下几个方面与这两种方法显著不同。
- 在使用的主干网络数量方面,
LaMI-DETR和CORA均采用单个主干。而EdaDet则使用两个主干:一个可学习的主干和一个被冻结的CLIP图像编码器。 CORA和EdaDet都采用了一种将分类和回归任务解耦的架构。虽然这种方法解决了无法召回新类别的问题,但它需要额外的后处理步骤,如NMS,从而破坏了DETR原有的端到端结构。CORA和EdaDet在训练过程中都需要RoI-Align操作。在CORA中,DETR仅预测物体性,necessitating在锚点预匹配过程中对CLIP特征图进行RoI-Align,以确定提议的具体类别。EdaDet基于每个提议的分类分数(通过池化操作获得)最小化交叉熵损失。因此,CORA和EdaDet在推理过程中需要多次池化操作。相比之下,LaMI-DETR简化了这一过程,仅在推理阶段需要一次池化操作。
Language Model Instruction
与仅依赖VLMs的视觉-语言对齐的先前方法不同,论文旨在通过增强概念表示和研究类间关系来改善开放词汇检测器。
根据图1中识别出的问题,采用视觉描述来建立视觉概念,从而完善概念表示。此外,利用具有丰富文本语义知识的T5来测量视觉概念之间的相似性关系,从而提取类间关系。
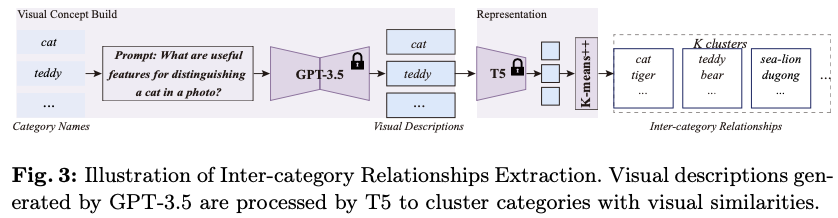
如图3所示,给定一个类别名称 c ∈ C c \in \mathcal{C} c∈C ,使用描述的方法提取其细粒度视觉特征描述符 d d d 。将 D \mathcal{D} D 定义为 C \mathcal{C} C 中类别的视觉描述空间。这些视觉描述 d ∈ D d \in \mathcal{D} d∈D 随后被送入T5模型,以获得视觉描述嵌入 e ∈ E e \in \mathcal{E} e∈E 。因此,构建了一个开放的视觉概念集合 D \mathcal{D} D 及其对应的嵌入 E \mathcal{E} E 。为了识别视觉上相似的概念,将视觉描述嵌入 E \mathcal{E} E 聚类为 K K K 个聚类中心。归类在同一聚类中心下的概念被认为具有相似的视觉特征。提取的类间关系随后在视觉概念采样中应用,如图2a所示。
如图2b所示,在Transformer编码器之后,特征图 { f i } i = 1 M \{f_i\}_{i=1}^{M} {fi}i=1M 上的每个像素被解释为一个对象查询,每个查询直接预测一个边界框。为了选择得分最高的 N N N 个边界框作为区域提议,该过程可以概括如下:
{ q j } j = 1 N = Top N ( { T cls ⋅ f i } i = 1 M ) . \begin{align} \{q_j\}_{j=1}^{N} = \text{Top}_N(\{\mathcal{T}_\texttt{cls} \cdot f_i\}_{i=1}^M). \end{align} {qj}j=1N=TopN({Tcls⋅fi}i=1M).
在LaMI-DETR中,将每个查询 { q j } j = 1 N \{q_j\}_{j=1}^{N} {qj}j=1N 与其最近的文本嵌入进行融合,得到:
KaTeX parse error: Undefined control sequence: \label at position 16: \begin{align} \̲l̲a̲b̲e̲l̲{eqn:embedding_…
其中 ⊕ \oplus ⊕ 表示逐元素相加。
一方面,视觉描述被输入到T5模型以聚类视觉上相似的类别,如前所述。另一方面,视觉描述 d j ∈ D d_j \in \mathcal{D} dj∈D 被转发到CLIP模型的文本编码器以更新分类权重,记作 T cls = { t c ′ } c = 1 C \mathcal{T}_{\text{cls}} = \{t'_c\}_{c=1}^{C} Tcls={tc′}c=1C ,其中 t c ′ t'_c tc′ 表示在CLIP文本编码器空间中 d d d 的文本嵌入。
因此,用于语言嵌入融合过程的文本嵌入会相应地更新:
KaTeX parse error: Undefined control sequence: \label at position 16: \begin{align} \̲l̲a̲b̲e̲l̲{eqn:embedding_…
由于相似的视觉概念通常共享共同的特征,因此可以为这些类别生成几乎相同的视觉描述符。这种相似性在推理过程中给区分相似的视觉概念带来了挑战。
为了在推理过程中区分容易混淆的类别,首先基于 T cls \mathcal{T}_{\text{cls}} Tcls 在CLIP文本编码器语义空间中为每个类别 c ∈ C c \in \mathcal{C} c∈C 识别出最相似的类别 c conf ∈ C c^{\text{conf}} \in \mathcal{C} cconf∈C 。然后,修改用于生成类别 c c c 的视觉描述 d ′ ∈ D ′ d' \in \mathcal{D}' d′∈D′ 的提示,将 c c c 与 c conf c^{\text{conf}} cconf 区分开来的特征。
设 t ′ ′ t'' t′′ 为 d ′ d' d′ 在CLIP文本编码器空间中的文本嵌入。如图2c所示,推理流程如下:
KaTeX parse error: Undefined control sequence: \label at position 16: \begin{align} \̲l̲a̲b̲e̲l̲{eqn:confusing_…
为了解决开放词汇检测数据集中不完整标注所带来的挑战,采用联邦损失,最初是为长尾数据集引入的。这种方法随机选择一组类别,以计算每个小批量的检测损失,有效地最小化了某些类别中缺失标注相关的问题。
给定类别出现频率 p = [ p 1 , p 2 , … , p C ] p = [p_1, p_2, \ldots, p_C] p=[p1,p2,…,pC] ,其中 p c p_c pc 表示第 c th c^{\text{th}} cth 视觉概念在训练数据中的出现频率, C C C 代表类别的总数。根据概率分布 p p p 随机抽取 C fed C_{\text{fed}} Cfed 个样本。选择第 c th c^{\text{th}} cth 样本 x c x_c xc 的可能性与其对应的权重 p c p_c pc 成正比。该方法有助于将由语言模型提取的视觉相似性知识转移到检测器,从而减少过拟合问题:
KaTeX parse error: Undefined control sequence: \label at position 16: \begin{align} \̲l̲a̲b̲e̲l̲{eqn:federated_…
结合联邦损失,分类权重被重新表述为 T cls = { t c ′ ′ } c = 1 C fed \mathcal{T}_{\text{cls}} = \{t''_c\}_{c=1}^{C_{\text{fed}}} Tcls={tc′′}c=1Cfed ,其中 C fed \mathcal{C}_{\text{fed}} Cfed 表示每次迭代中参与损失计算的类别,而 C fed C_{\text{fed}} Cfed 是 C fed \mathcal{C}_{\text{fed}} Cfed 的数量。
利用一个具有强大开放词汇能力的冻结CLIP作为LaMI-DETR的主干。然而,由于检测数据集中类别的有限性,经过训练后对基本类别的过拟合是不可避免的。为了减少对基本类别的过度训练,根据视觉概念聚类的结果抽取简单的负类别。
在LaMI-DETR中,设包含真实类别的聚类在给定迭代中记作 K G \mathcal{K}_G KG 。将 K G \mathcal{K}_G KG 中的所有类别称为 C g \mathcal{C}_g Cg 。具体而言,在当前迭代中排除 C g \mathcal{C}_g Cg 的抽样。为此,将 C g \mathcal{C}_g Cg 中类别的出现频率设置为零。这种方法使得由语言模型提取的视觉相似性知识能够转移到检测器,从而缓解过拟合问题:
KaTeX parse error: Undefined control sequence: \label at position 16: \begin{align} \̲l̲a̲b̲e̲l̲{eqn:concept_sa…
其中 p c c a l p_c^{cal} pccal 表示在语言模型校准后类别 c c c 的出现频率,确保在这一迭代中不会抽样视觉上相似的类别。此过程如图2a所示。
视觉概念描述与DetCLIP中采用的概念丰富不同。LaMI中使用的视觉描述更加强调对象自身固有的视觉属性。在DetCLIP中,类别标签被补充了定义,这些定义可能包括在图片中不存在的概念,以严格描述一个类别。
Implementation Details
训练是在 8 8 8 块40G A100 GPU上进行的,总批量大小为 32 32 32 。对于OV-LVIS设置,训练模型 12 12 12 个周期。在VG-dedup基准中,为了与OWL-ViT进行公平比较,在随机抽样的 1 / 3 1/3 1/3 Object365 数据集上预训练LaMI-DETR 12 12 12 个周期。随后,LaMI-DETR在VG dedup数据集上进行额外的 12 12 12 个周期的微调。
检测器使用来自OpenCLIP的ConVNext-Large作为其主干网络,在整个训练过程中保持不变。LaMI-DETR基于DINO,采用了 900 900 900 个查询,具体参数如detrex所述。严格遵循detrex中详细描述的原始训练配置,除了采用指数移动平均(EMA)策略以增强训练稳定性。为了平衡训练样本的分布,使用默认超参数应用重复因子抽样。在联邦损失方面,类别数量 C fed C_{\text{fed}} Cfed 在OV-LVIS和VG dedup数据集中分别设置为 100 100 100 和 700 700 700 。
为了探索更广泛的视觉概念以实现更有效的聚类,从LVIS、Object365、VisualGenome、Open Images和ImageNet-21K中汇编了一个全面的类别集合。通过使用WordNet的上位词过滤掉冗余概念,最终形成了一个包含 26 , 410 26,410 26,410 个独特概念的视觉概念字典。在视觉概念分组阶段,该字典被聚类为 K K K 个中心,其中OV-LVIS的 K K K 值为 128 128 128 ,VG dedup的 K K K 值为 256 256 256 。
Experiments

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

相关文章:
LaMI-DETR:基于GPT丰富优化的开放词汇目标检测 | ECCV‘24
现有的方法通过利用视觉-语言模型(VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测,然而出现了两个主要挑战:(1)概念表示不足,CLIP文本空间中的类别名称缺乏…...

AI大模型是否有助于攻克重大疾病?
AI大模型在攻克重大疾病方面展现出了巨大的潜力,特别是在疾病预测、药物研发、个性化医疗等领域有着广泛应用。具体来说,AI大模型能够帮助以下几方面: 1、疾病预测与诊断:AI大模型通过分析海量的医学数据,可以提高重大…...

【渗透测试】-红日靶场-获取web服务器权限
拓扑图: 前置环境配置: Win 7 默认密码:hongrisec201 内网ip:192.168.52.143 打开虚拟网络编辑器 添加网络->VMent1->仅主机模式->子网ip:192.168.145.0 添加网卡: 虚拟机->设置-> 添加->网络适配器 保存&a…...

python 深度学习 项目调试 图像分割 segment-anything
起因, 目的: 项目来源: https://github.com/facebookresearch/segment-anything项目目的: 图像分割。 提前图片中的某个目标。facebook 出品, 居然有 47.3k star! 思考一些问题 我可以用这个项目来做什么?给一个图片, 进行分割࿰…...
:支付和订单处理)
【GO实战课】第六讲:电子商务网站(6):支付和订单处理
1. 简介 本课程将探讨电子商务网站的支付和订单处理功能,以及使用GO语言实现。在本课程中,我们将介绍如何设计一个可扩展、可靠和高性能的支付和订单处理系统,并演示如何使用GO语言编写相关代码。 本课程的目标是帮助学生理解电子商务网站的支付和订单处理功能,并提供一个…...

专题十三_记忆化搜索_算法专题详细总结
目录 1. 斐波那契数(easy) 那么这里就画出它的决策树 : 解法一:递归暴搜 解法二:记忆化搜索 解法三:动态规划 1.暴力解法(暴搜) 2.对优化解法的优化:把已经计算过的…...
)
已发布金融国家标准目录(截止2024年3月)
已发布金融国家标准目录2024年3月序号标准编号标准名称...

【论文#快速算法】Fast Intermode Decision in H.264/AVC Video Coding
目录 摘要1.前言2.帧间模式决策概览2.1 H.264/AVC中的帧间模式决策2.2 发现和动机 3.同质性和平稳性的确定3.1 同质性区域的确定3.2 稳定性区域的决定3.3 整体算法 4.实验结果4.1 IPPP序列的测试4.2 IBBP序列测试 5.结论 《Fast Intermode Decision in H.264/AVC Video Coding》…...

Git核心概念图例与最常用内容操作(reset、diff、restore、stash、reflog、cherry-pick)
文章目录 简介前置概念.git目录objects目录refs目录HEAD文件 resetreflog 与 reset --hardrevert(撤销指定提交)stashdiff工作区与暂存区差异暂存区与HEAD差异工作区与HEAD差异其他比较 restore、checkout(代码撤回)merge、rebase、cherry-pick 简介 本文将介绍Git几个核心概念…...

【人工智能在医疗企业个人中的应用】
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

IPv4头部和IPv6头部
IPv4和IPv6是互联网协议(IP)中的两个主要版本,它们在数据包头部(Header)结构上存在显著差异。以下是IPv4头部和IPv6头部的主要结构和区别: IPv4头部结构 IPv4(Internet Protocol Version 4&…...

从零开始手把手带你训练LLM保姆级教程,草履虫都能学会!零基础看完这篇就足够了~
导读 ChatGPT面世以来,各种大模型相继出现。那么大模型到底是如何训练的呢,在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程,包括模型预训练(Pretrain)、Tokenizer 训练、指令微调࿰…...

strcat函数追加字符串
char * strcat ( char * destination, const char * source ); dest:目标字符串,即要将源字符串追加到其末尾的字符串。src:源字符串,即要追加到目标字符串末尾的字符串 使用strcat函数给目标字符串追加字符时,首先要…...

每月洞察:App Store 和 Google Play 的主要更新
Google Play 和 App Store 的算法不断发展,定期更新和变化会显着影响其功能。对于开发人员和营销人员来说,跟上这些变化至关重要,因为它们会直接影响应用发现和排名。 本文将深入探讨 Google Play 和 App Store 的最新更新,解释它…...

【python openai function2json小工具】
两种方法 一种openai-swarm中提供的、一种langchain实现的 一、openai工具函数调用 import inspectdef merge_chunk(final_response: dict, delta: dict) -> None:delta.pop("role", None)merge_fields(final_response, delta)tool_calls delta.get("tool_…...
和super().__init__()的解释)
super()和super().__init__()的解释
一、super 1.基本概念 在python继承当中,super()函数主要用在子类中调用父类的方法。它返回一个特殊对象,这个对象会帮我们调用父类方法 class Parent:def __init__(self, name):self.name namedef say_hello(self):print(f"Hello, Im {self.nam…...

【C++】—— 多态(下)
【C】—— 多态(下) 4 多态的原理 4.1 虚函数表指针4.2 多态的原理4.3 动态绑定和静态绑定 4.4 虚函数表 4 多态的原理 4.1 虚函数表指针 我们以一道题来引入多态的原理 下面编译为 32 位程序的运行结果是什么() A、编译报错 B…...

idea 2023 配置 web service
前言 能在网上查到的资料,都是比较老的,搞了一上午才配置好了环境 因此记录一下,服务你我他 我的环境: java 1.8,Idea2023.1 配置web service 服务端 直接新建一个java新项目 下载插件 添加框架支持 启动项目 配置web service 客户端 新建项目,下载三个插件的步骤和上面服务…...

MYSQL数据库SQL+DQL
关于MySQL数据库中的SQL和DQL,以下是一些关键信息: SQL概述 SQL(Structured Query Language,结构化查询语言)是用于操作关系型数据库的编程语言。它定义了一套操作关系型数据库的统一标准。SQL语句可以单行或多行书写…...
Java中的异常Throwable
原文链接https://javaguide.cn/java/basis/java-basic-questions-03.html#%E5%BC%82%E5%B8%B8 Java 异常类层次结构图 Exception 和 Error 的区别 在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类: Excep…...

通过curl命令直接调用Taotoken大模型API的排错指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调用Taotoken大模型API的排错指南 对于需要在无SDK环境下进行快速测试、调试或集成的开发者而言,直接…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...

迪拜塔幕墙设计
迪拜塔幕墙设计 【作 者】:罗永增 【关键词】:迪拜塔,幕墙,设计,系统。 前言:...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...

Docker Compose编排微服务
Docker Compose编排微服务 引言 Docker Compose是Docker官方提供的容器编排工具,用于定义和运行多容器Docker应用。通过Compose,可以使用YAML文件定义服务、网络、数据卷等资源,然后通过简单的命令启动和停止整个应用。Docker Compose特别适合…...