从零开始手把手带你训练LLM保姆级教程,草履虫都能学会!零基础看完这篇就足够了~
导读
ChatGPT面世以来,各种大模型相继出现。那么大模型到底是如何训练的呢,在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程,包括模型预训练(Pretrain)、Tokenizer 训练、指令微调(Instruction Tuning)等环节。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
文章目录
- 1.预训练阶段(Pretraining Stage)
-
- 1.1 Tokenizer Training
- 1.2 Language Model PreTraining
- 1.3 数据集清理
- 1.4 模型效果评测
- 2. 指令微调阶段(Instruction Tuning Stage)
-
- 2.1 Self Instruction
- 2.2 开源数据集整理
- 2.3 模型的评测方法
- CSDN独家福利
1.预训练阶段(Pretraining Stage)
工欲善其事,必先利其器。
当前,不少工作选择在一个较强的基座模型上进行微调,且通常效果不错(如:[alpaca]、[vicuna] 等)。
这种成功的前提在于:预训练模型和下游任务的差距不大,预训练模型中通常已经包含微调任务中所需要的知识。
但在实际情况中,我们通常会遇到一些问题,使得我们无法直接使用一些开源 backbone:
- 语言不匹配: 大多数开源基座对中文的支持都不太友好,例如:[Llama]、[mpt]、[falcon] 等,这些模型在英文上效果都很优秀,但在中文上却差强人意。

- 专业知识不足: 当我们需要一个专业领域的 LLM 时,预训练模型中的知识就尤为重要。由于大多数预训练模型都是在通用训练语料上进行学习,对于一些特殊领域(金融、法律等)中的概念和名词无法具备很好的理解。我们通常需要在训练语料中加入一些领域数据(如:[xuanyuan 2.0]),以帮助模型在指定领域内获得更好的效果。
 轩辕 2.0(金融对话模型)论文中所提及的训练语料分布,其中 Financial Pretraining 为金融语料
轩辕 2.0(金融对话模型)论文中所提及的训练语料分布,其中 Financial Pretraining 为金融语料
基于上述原因,我们在进行 SFT 步骤之前,先来看看预训练任务是如何做的。
1.1 Tokenizer Training
在进行预训练之前,我们需要先选择一个预训练的模型基座。
一个较为普遍的问题是:大部分优秀的语言模型都没有进行充分的中文预训练,
因此,许多工作都尝试将在英语上表现比较优秀的模型用中文语料进行二次预训练,期望其能够将英语上的优秀能力迁移到中文任务中来。
已经有许多优秀的仓库做过这件事情,比如:[Chinese-LLaMA-Alpaca]。
但在进行正式的训练之前,我们还有一步很重要的事情去做:词表扩充。
通俗来讲,tokenizer 的目的就是将一句话进行切词,并将切好词的列表喂给模型进行训练。
例如:
输入句子 >>> 你好世界
切词结果 >>> ['你', '好', '世', '界']通常,tokenizer 有 2 种常用形式:WordPiece 和 BPE。
WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中,
当需要切词的时候就从词表里面查找即可。
 bert-base-chinese tokenizer 可视化
bert-base-chinese tokenizer 可视化
上述图片来自可视化工具 [tokenizer_viewer]。
如上图所示,大名鼎鼎的 BERT 就使用的这种切词法。
当我们输入句子:你好世界,
BERT 就会依次查找词表中对应的字,并将句子切成词的组合。
 BERT 切词测试图
BERT 切词测试图
当遇到词表中不存在的字词时,tokenizer 会将其标记为特殊的字符 [UNK]:
 Out of Vocabulary(OOV)情况
Out of Vocabulary(OOV)情况
Byte Pair Encoder(BPE)
WordPiece 的方式很有效,但当字词数目过于庞大时这个方式就有点难以实现了。
对于一些多语言模型来讲,要想穷举所有语言中的常用词(穷举不全会造成 OOV),
既费人力又费词表大小,为此,人们引入另一种方法:BPE。
BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
对于中文来讲,一个汉字是由 3 个 unicode 编码组成的,
因为平时我们不会拆开来看(毕竟中文汉字是不可拆分的),所以我一开始对这个概念也不太熟悉。
我们来看看 LLaMA 的 tokenizer(BPE)对中文是如何进行 encode 的:

上述图片来自可视化工具 [tokenizer_viewer]。
可以看到,「编码」两个字能够被正常切成 2 个字,
但「待」却被切成了 3 个 token,这里的每个 token 就是 1 个 unicode 编码。
 LLaMA tokenizer 查找结果,「待」不在词表中,「编」「码」在词表中
LLaMA tokenizer 查找结果,「待」不在词表中,「编」「码」在词表中
通过 token 查找功能,我们可以发现「编」「码」在词表中,但「待」不在词表中。
但任何 1 个汉字都是可以由 unicode 表示(只是组合顺序不同),因此「待」就被切成了 3 个 token。

通常在模型训练不够充足的时候,模型会输出一些乱码(不合法的 unicode 序列):
游泳池是杭州西湖的一个游泳池,���
词表扩充
为了降低模型的训练难度,人们通常会考虑在原来的词表上进行「词表扩充」,
也就是将一些常见的汉字 token 手动添加到原来的 tokenizer 中,从而降低模型的训练难度。
我们对比 [Chinese-LLaMA] 和 [LLaMA] 之间的 tokenizer 的区别:
 Chinese LLaMA 和 原始LLaMA 之间 tokenizer 的区别
Chinese LLaMA 和 原始LLaMA 之间 tokenizer 的区别
我们可以发现:Chinese LLaMA 在原始 tokenizer 上新增了17953 个 tokens,且加入 token 的大部分为汉字。
而在 [BELLE] 中也有同样的做法:
在 120w 行中文文本上训练出一个 5w 规模的 token 集合,
并将这部分 token 集合与原来的 LLaMA 词表做合并,
最后再在 3.2B 的中文语料上对这部分新扩展的 token embedding 做二次预训练。
 《Towards Better Instruction Following Language Models for Chinese》 Page-4
《Towards Better Instruction Following Language Models for Chinese》 Page-4
1.2 Language Model PreTraining
在扩充完 tokenizer 后,我们就可以开始正式进行模型的预训练步骤了。
Pretraining 的思路很简单,就是输入一堆文本,让模型做 Next Token Prediction 的任务,这个很好理解。
我们主要来讨论几种预训练过程中所用到的方法:数据源采样、数据预处理、模型结构。
数据源采样
在 [gpt3] 的训练过程中,存在多个训练数据源,论文中提到:对不同的数据源会选择不同采样比例:
 GPT3 Paper Page-9
GPT3 Paper Page-9
通过「数据源」采样的方式,能够缓解模型在训练的时候受到「数据集规模大小」的影响。
从上图中可以看到,相对较大的数据集(Common Crawl)会使用相对较大的采样比例(60%),
这个比例远远小于该数据集在整体数据集中所占的规模(410 / 499 = 82.1%),
因此,CC 数据集最终实际上只被训练了 0.44(0.6 / 0.82 * (300 / 499))个 epoch。
而对于规模比较小的数据集(Wikipedia),则将多被训练几次(3.4 个 epoch)。
这样一来就能使得模型不会太偏向于规模较大的数据集,从而失去对规模小但作用大的数据集上的学习信息。
数据预处理
数据预处理主要指如何将「文档」进行向量化。
通常来讲,在 Finetune 任务中,我们通常会直接使用 truncation 将超过阈值(2048)的文本给截断,
但在 Pretrain 任务中,这种方式显得有些浪费。
以书籍数据为例,一本书的内容肯定远远多余 2048 个 token,但如果采用头部截断的方式,
则每本书永远只能够学习到开头的 2048 tokens 的内容(连序章都不一定能看完)。
因此,最好的方式是将长文章按照 seq_len(2048)作分割,将切割后的向量喂给模型做训练。
模型结构
为了加快模型的训练速度,通常会在 decoder 模型中加入一些 tricks 来缩短模型训练周期。
目前大部分加速 tricks 都集中在 Attention 计算上(如:MQA 和 Flash Attention [falcon] 等);
此外,为了让模型能够在不同长度的样本上都具备较好的推理能力,
通常也会在 Position Embedding 上进行些处理,选用 ALiBi([Bloom])或 RoPE([GLM-130B])等。
1.3 数据集清理
中文预训练数据集可以使用 [悟道],数据集分布如下(主要以百科、博客为主):
 悟道-数据分布图
悟道-数据分布图
但开源数据集可以用于实验,如果想突破性能,则需要我们自己进行数据集构建。
在 [falcon paper] 中提到,
仅使用「清洗后的互联网数据」就能够让模型比在「精心构建的数据集」上有更好的效果,
一些已有的数据集和它们的处理方法如下:
 各种数据源 & 数据清理方法
各种数据源 & 数据清理方法
1.4 模型效果评测
关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC] 等,
可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理。
这种方式可以用来评估模型对「语言模板」的拟合程度,
即给定一段话,预测后面可能出现哪些合法的、通顺的字词。
但仅仅是「生成通顺句子」的能力现在已经很难满足现在人们的需求,
大部分 LLM 都具备生成流畅和通顺语句能力,很难比较哪个好,哪个更好。
为此,我们需要能够评估另外一个大模型的重要能力 —— 知识蕴含能力。
C-Eval
一个很好的中文知识能力测试数据集是 [C-Eval],涵盖1.4w 道选择题,共 52 个学科。
覆盖学科如下:
 c-eval 数据集覆盖学科图
c-eval 数据集覆盖学科图
由于是选择题的形式,我们可以通过将题目写进 prompt 中,
并让模型续写 1 个 token,判断这个续写 token 的答案是不是正确答案即可。
但大部分没有精调过的预训练模型可能无法续写出「A B C D」这样的选项答案,
因此,官方推荐使用 5-shot 的方式来让模型知道如何输出答案:
以下是中国关于会计考试的单项选择题,请选出其中的正确答案。
下列关于税法基本原则的表述中,不正确的是____。
A. 税收法定原则包括税收要件法定原则和税务合法性原则
B. 税收公平原则源于法律上的平等性原则
C. 税收效率原则包含经济效率和行政效率两个方面
D. 税务机关按法定程序依法征税,可以自由做出减征、停征或免征税款的决定
答案:D
甲公司是国内一家领先的新媒体、通信及移动增值服务公司,由于遭受世界金融危机,甲公司经济利润严重下滑,经营面临困境,但为了稳定职工队伍,公司并未进行裁员,而是实行高层管理人员减薪措施。甲公司此举采用的收缩战略方式是____。
A. 转向战略
B. 放弃战略
C. 紧缩与集中战略
D. 稳定战略
答案:C
… # 第 3, 4, 5 道样例题
下列各项中,不能增加企业核心竞争力的是____。
A. 产品差异化
B. 购买生产专利权
C. 创新生产技术
D. 聘用生产外包商
答案:
通过前面的样例后,模型能够知道在「答案:」后面应该输出选项字母。
于是,我们获得模型续写后的第一个 token 的概率分布(logits),
并取出「A B C D」这 4 个字母的概率,通过 softmax 进行归一化:
probs = (torch.nn.functional.softmax( torch.tensor( [ logits[self.tokenizer.encode( "A", bos=False, eos=False)[0]], logits[self.tokenizer.encode( "B", bos=False, eos=False)[0]], logits[self.tokenizer.encode( "C", bos=False, eos=False)[0]], logits[self.tokenizer.encode( "D", bos=False, eos=False)[0]], ] ), dim=0, ).detach().cpu().numpy()
)
pred = {0: "A", 1: "B", 2: "C", 3: "D"}[np.argmax(probs)] # 将概率最大的选项作为模型输出的答案C-Eval 通过这种方式测出了许多模型在中文知识上的效果,
由于是 4 选项问题,所以基线(随机选择)的正确率是 25%。
C-Eval 也再一次证明了 GPT-4 是个多么强大的知识模型:
 各模型在 5-shot 下的得分排名
各模型在 5-shot 下的得分排名
2. 指令微调阶段(Instruction Tuning Stage)
在完成第一阶段的预训练后,就可以开始进到指令微调阶段了。
由于预训练任务的本质在于「续写」,而「续写」的方式并一定能够很好的回答用户的问题。
例如:

因为训练大多来自互联网中的数据,我们无法保证数据中只存在存在规范的「一问一答」格式,
这就会造成预训练模型通常无法直接给出人们想要的答案。
但是,这并不代表预训练模型「无知」,只是需要我们用一些巧妙的「技巧」来引导出答案:

不过,这种需要用户精心设计从而去「套」答案的方式,显然没有那么优雅。
既然模型知道这些知识,只是不符合我们人类的对话习惯,那么我们只要再去教会模型「如何对话」就好了。
这就是 Instruction Tuning 要做的事情,即指令对齐。
OpenAI 在 [instruction-following] 中展示了 GPT-3 和经过指令微调前后模型的区别:
 GPT-3 只是在做续写任务,InstructGPT 则能够回答正确内容
GPT-3 只是在做续写任务,InstructGPT 则能够回答正确内容
2.1 Self Instruction
既然我们需要去「教会模型说人话」,
那么我们就需要去精心编写各式各样人们在对话中可能询问的问题,以及问题的答案。
在 [InstructGPT Paper] 中,使用了 1.3w 的数据来对 GPT-3.5 进行监督学习(下图中左 SFT Data):
 InstructGPT Paper 训练数据集预览
InstructGPT Paper 训练数据集预览
可以观察到,数据集中人工标注(labeler)占大头,
这还仅仅只是 InstructGPT,和 ChatGPT 远远不是一个量级。
非官方消息:ChatGPT 使用了百万量级的数据进行指令微调。
可见,使用人工标注是一件成本巨大的事情,只是找到人不够,需要找到「专业」且「认知一致」的标注团队。
如果这件事从头开始做自然很难(OpenAI 确实厉害),但今天我们已经有了 ChatGPT 了,
我们让 ChatGPT 来教我们自己的模型不就好了吗?
这就是 Self Instruction 的思路,即通过 ChatGPT 的输入输出来蒸馏自己的模型。
一个非常出名的项目是 [stanford_alpaca]。
如果从 ChatGPT 「套」数据,那么我们至少需要「套」哪些数据。
Instruction Tuning 中的「输入」(问题)和「输出」(答案)是训练模型的关键,
答案很好得到,喂给 ChatGPT 问题根据返回结果就能获得,
但「问题」从哪里获得呢?
(靠人想太累了,屏幕前的你不妨试试,看看短时间内能想出多少有价值的问题)
Alpaca 则是使用「种子指令(seed)」,使得 ChatGPT 既生成「问题」又生成「答案」。
由于 Alpaca 是英文项目,为了便于理解,我们使用相同思路的中文项目 [BELLE] 作为例子。
通俗来讲,就是人为的先给一些「训练数据样例」让 ChatGPT 看,
紧接着利用 ChatGPT 的续写功能,让其不断地举一反三出新的训练数据集:
你被要求提供10个多样化的任务指令。这些任务指令将被提供给GPT模型,我们将评估GPT模型完成指令的能力。
以下是你提供指令需要满足的要求:
1.尽量不要在每个指令中重复动词,要最大化指令的多样性。
2.使用指令的语气也应该多样化。例如,将问题与祈使句结合起来。
3.指令类型应该是多样化的,包括各种类型的任务,类别种类例如:brainstorming,open QA,closed QA,rewrite,extract,generation,classification,chat,summarization。
4.GPT语言模型应该能够完成这些指令。例如,不要要求助手创建任何视觉或音频输出。例如,不要要求助手在下午5点叫醒你或设置提醒,因为它无法执行任何操作。例如,指令不应该和音频、视频、图片、链接相关,因为GPT模型无法执行这个操作。
5.指令用中文书写,指令应该是1到2个句子,允许使用祈使句或问句。
6.你应该给指令生成适当的输入,输入字段应包含为指令提供的具体示例,它应该涉及现实数据,不应包含简单的占位符。输入应提供充实的内容,使指令具有挑战性。
7.并非所有指令都需要输入。例如,当指令询问一些常识信息,比如“世界上最高的山峰是什么”,不需要提供具体的上下文。在这种情况下,我们只需在输入字段中放置“<无输入>”。当输入需要提供一些文本素材(例如文章,文章链接)时,就在输入部分直接提供一些样例。当输入需要提供音频、图片、视频或者链接时,则不是满足要求的指令。
8.输出应该是针对指令和输入的恰当回答。
下面是10个任务指令的列表:
1.指令: 在面试中如何回答这个问题?
1.输入:当你在车里独处时,你会想些什么?
1.输出:如果是在晚上,我通常会考虑我今天所取得的进步,如果是在早上,我会思考如何做到最好。我也会尝试练习感恩和活在当下的状态,以避免分心驾驶。
2.指令: 按人口对这些国家进行排名。
2.输入:巴西,中国,美国,日本,加拿大,澳大利亚
2.输出:中国,美国,巴西,日本,加拿大,澳大利亚
3.指令:
如上述例子所示,我们先给出 2 个样例,并让 ChatGPT 进行续写:
 ChatGPT 续写结果
ChatGPT 续写结果
2.2 开源数据集整理
在这一章中,我们将梳理一些开源的 Instruction Tuning 的数据集,
除了直接拿来用以外,我们期望通过分析这些已有数据集,从而学习如何构建一个指令数据集。
Alpaca
[stanford_alpaca] 采用上述的 self instruction 的方式采集了 5200 条指令训练数据集。
数据样例如下:
{"instruction": "Arrange the words in the given sentence to form a grammatically correct sentence.", "input": "quickly the brown fox jumped", "output": "The quick brown fox jumped quickly."
}其中,instruction 代表要求模型做的任务,input 代表用户输入, output 代表喂给模型的 label。
Alpaca 覆盖了多种类型的指令,其数据分布如下:
 Alpaca 数据分布图
Alpaca 数据分布图
包含写作、描述、分类、摘要等多种类型的任务集合。
BELLE
BELLE 开放了好几种规模的数据集,[100万]、[200万]、[350万] 等。
训练数据集样例如下:
{"instruction": "判断给定的文章是否符合语法规则。如果不符合,请提供修改建议。 下面是一篇文章的开头: ‘为了探讨这个主题,本文将提供一系列数据和实例,以证明这一观点。’", "input": "", "output": "这个开头符合语法规则。"
}由于数据量很大,我们无法统计出训练数据集中各任务的真实占比,
但从 [1000条评测集] 数据分布可以推测出,训练数据集中同样包含:摘要、问答、分类等任务。
 BELLE - 评测集分布
BELLE - 评测集分布
我们按照类别对评测数据进行采样,结果如下:

2.3 模型的评测方法
比起预训练(Pretrain)环节里相对明确的评价指标(如PPL、NLL等),
Instruction 环节中的评价指标比较令人头疼。
鉴于语言生成模型的发展速度,BLEU 和 ROUGH 这样的指标已经不再客观。
一种比较流行的方式是像 [FastChat] 中一样,利用 GPT-4 为模型的生成结果打分,
我们也尝试使用同样的 Prompt 对 3 种开源模型:OpenLlama、ChatGLM、BELLE 进行测试。
注意:下面的测试结果仅源自我们自己的实验,不具备任何权威性。
对于每一个问题,我们先获得 ChatGPT 的回复,以及另外 3 种模型的回复,
接着我们将 「ChatGPT 答案 - 候选模型答案」这样的 pair 喂给 GPT-4 打分(满分为 10 分)。
得到的结果如下:
 测试结果 & 测试 prompt
测试结果 & 测试 prompt
我们对每个任务单独进行了统计,并在最后一列求得平均值。
GPT-4 会对每一条测试样本的 2 个答案分别进行打分,并给出打分理由:
 GPT-Review 的结果
GPT-Review 的结果
但是,我们发现,GPT-4 打出的分数和给出理由并不一定正确。
如上图所示,GPT-4 为右边模型的答案打出了更高的分数,给出的理由是:
将「最长时期」改为了「最长时期之一」会更准确。
但事实上,Instruction 中明确设定就是「最长时期」,
这种「给高分」的理由其实是不正确的。
此外,我们还发现,仅仅调换句子顺序也会对最后打分结果产生影响,
针对这个问题,我们考虑「调换句子顺序并求和平均」来缓解。
但不管怎么样,GPT-4 给出的分数或许并没有我们想象中的那么靠谱,
为此,我们通过人工的 Review 的方式对每个答案进行了一次回扫,得到的结果和标准如下:
再次重申:我们只是期望指出 GPT-4 打分可能会和实际产生偏差的问题,这里排名不具备任何权威性。
 人工 Review 结果 & 打分原则
人工 Review 结果 & 打分原则
我们可以看到,
在 GPT-4 打分的结果中,已经有模型的效果甚至超过了 ChatGPT(分数为 1.02),
但再经过人工 Review 后,ChatGPT 的答案是我们认为更合理一些的。
当然,最近陆陆续续的推出了许多新的评测方法,如:[PandaLM],
以及许多比较有影响力的评测集,如:[C-Eval]、[open_llm_leaderboard] 等,
我们或许会在后续的整理中更新。
CSDN独家福利
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

相关文章:
从零开始手把手带你训练LLM保姆级教程,草履虫都能学会!零基础看完这篇就足够了~
导读 ChatGPT面世以来,各种大模型相继出现。那么大模型到底是如何训练的呢,在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程,包括模型预训练(Pretrain)、Tokenizer 训练、指令微调࿰…...

strcat函数追加字符串
char * strcat ( char * destination, const char * source ); dest:目标字符串,即要将源字符串追加到其末尾的字符串。src:源字符串,即要追加到目标字符串末尾的字符串 使用strcat函数给目标字符串追加字符时,首先要…...

每月洞察:App Store 和 Google Play 的主要更新
Google Play 和 App Store 的算法不断发展,定期更新和变化会显着影响其功能。对于开发人员和营销人员来说,跟上这些变化至关重要,因为它们会直接影响应用发现和排名。 本文将深入探讨 Google Play 和 App Store 的最新更新,解释它…...

【python openai function2json小工具】
两种方法 一种openai-swarm中提供的、一种langchain实现的 一、openai工具函数调用 import inspectdef merge_chunk(final_response: dict, delta: dict) -> None:delta.pop("role", None)merge_fields(final_response, delta)tool_calls delta.get("tool_…...
和super().__init__()的解释)
super()和super().__init__()的解释
一、super 1.基本概念 在python继承当中,super()函数主要用在子类中调用父类的方法。它返回一个特殊对象,这个对象会帮我们调用父类方法 class Parent:def __init__(self, name):self.name namedef say_hello(self):print(f"Hello, Im {self.nam…...

【C++】—— 多态(下)
【C】—— 多态(下) 4 多态的原理 4.1 虚函数表指针4.2 多态的原理4.3 动态绑定和静态绑定 4.4 虚函数表 4 多态的原理 4.1 虚函数表指针 我们以一道题来引入多态的原理 下面编译为 32 位程序的运行结果是什么() A、编译报错 B…...

idea 2023 配置 web service
前言 能在网上查到的资料,都是比较老的,搞了一上午才配置好了环境 因此记录一下,服务你我他 我的环境: java 1.8,Idea2023.1 配置web service 服务端 直接新建一个java新项目 下载插件 添加框架支持 启动项目 配置web service 客户端 新建项目,下载三个插件的步骤和上面服务…...

MYSQL数据库SQL+DQL
关于MySQL数据库中的SQL和DQL,以下是一些关键信息: SQL概述 SQL(Structured Query Language,结构化查询语言)是用于操作关系型数据库的编程语言。它定义了一套操作关系型数据库的统一标准。SQL语句可以单行或多行书写…...
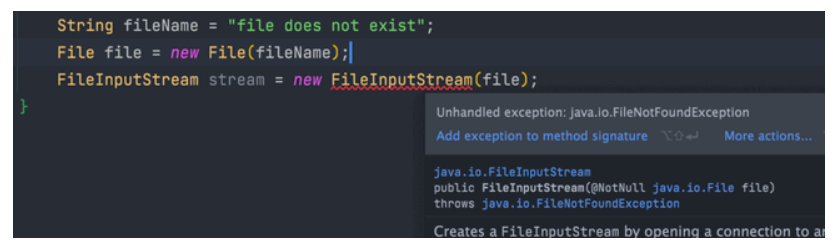
Java中的异常Throwable
原文链接https://javaguide.cn/java/basis/java-basic-questions-03.html#%E5%BC%82%E5%B8%B8 Java 异常类层次结构图 Exception 和 Error 的区别 在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类: Excep…...
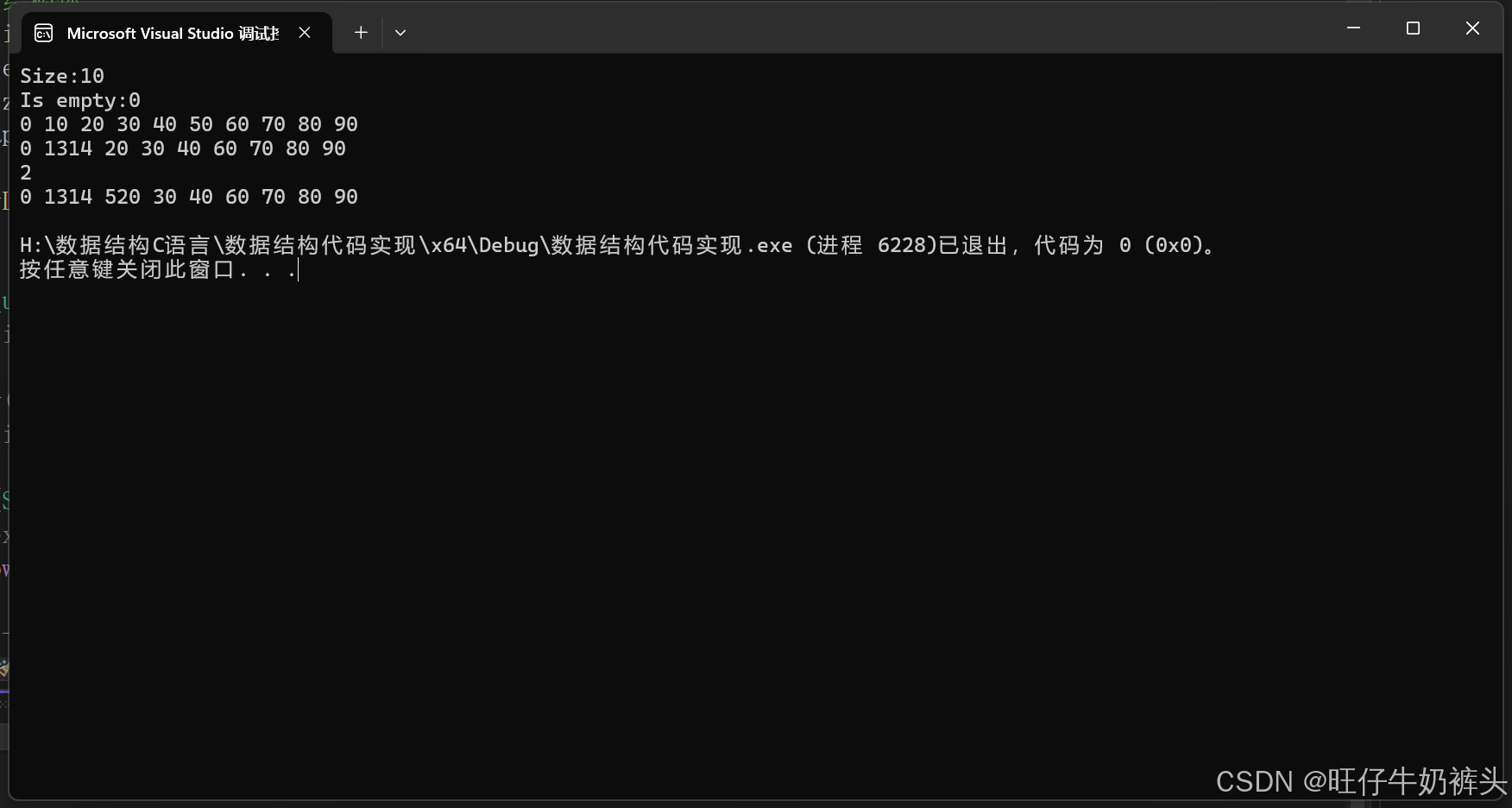
Day4顺序表c++代码实现
代码中实现,顺序表的初始化,插入,查找,删除 废话不多说,直接上 #include<iostream> using namespace std; #define eleType int struct SequentialList {eleType* elements;//指针int size;int capacity;//容量…...

将图片转换成base64格式
1.先创建一个canvas对象,然后给canvas对象设置图片对象的宽高,再调用canvas的getContext获取2d上下文对象,再调用上下文对象的drawImage方法,再通过canvase对象的toDataURL方法,将图片转换成base64格式的字符串 2.将b…...
的慢查询实战)
征服ES(ElasticSearch)的慢查询实战
在 Elasticsearch(ES)中,进行大数据查询时,常常会由于多种因素而导致性能显著下降。接下来,我们将深入探讨几种常见情况及其相应的解决方案。 一、常见问题分析 深分页、大排序 大量数据扫描与多分片上的多次排序会严…...

如何才能从普通程序员转行AI大模型?
人工智能已经成为一个非常火的方向。作为一名普通的程序员,该如何转向AI大模型方向。以程序员为例,看看普通程序员如何开启AI大模型之路。 接下来给大家分享一下程序员转大模型的一些注意点: 作为一名程序员,在考虑转行至大模型领…...

【番外】软件设计师中级笔记关于数据库技术更新笔记问题
提问 由于软件设计师中级笔记中第九章数据库技术基础的笔记内容太多,我应该分几期发布呢?还是一期一次性发布完成。 如果分为一期发布,可能需要给我多一些时间,由于markdown格式有所差异,所以我需要部分进行修改与调…...
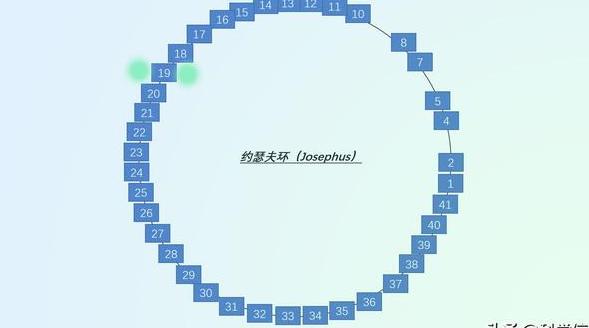
【代码】约瑟夫问题——故事背景
Hello!大家好,我是学霸小羊,今天先来讲讲约瑟夫问题的背景。 在古罗马时期,犹太历史学家约瑟夫斯领导犹太人反对罗马帝国的统治,并与罗马军队进行激烈的战斗。然而,在罗马军队的围困下,约瑟夫与…...

什么是事件冒泡和事件捕获
文章目录 1. 事件传播机制2. 事件冒泡(Event Bubbling)3. 事件捕获(Event Capturing)4. 事件冒泡和事件捕获的区别5. 阻止事件传播总结 事件冒泡和事件捕获是两种处理网页中事件传播的机制,特别是在 JavaScript 中处理…...

高端优质建站公司具备哪些优势?2024高端建站公司哪家好
从某种程度上讲,一个出色的建站公司需具备将无形的品牌价值巧妙转化为直观视觉元素的能力,这一转化过程极为考究,涵盖了设计的精细程度、色彩运用的巧妙以及空间布局的智慧,这些要素均不容忽视。 接下来考察网站的内容策划能力同…...

word删除空白页 | 亲测有效
想要删掉word里面的末尾空白页,但是按了delete之后也没有用 找了很久找到了以下亲测有效的方法 1. 通过鼠标右键在要删除的空白页面处显示段落标记 2. 在字号输入01,按ENTER(回车键) 3.成功删除了!!...

YashanDB学习-服务启停
YashanDB学习-服务启停 1、查看YashanDB 当前实例状态和数据库名称2、使用 yasboot 工具启停YashanDB3、服务器重启后无法通过yasboot命令运维管理数据库4、正常关闭数据库的方式 数据库安装过程中将实例自动切换成OPEN阶段,并创建名为yashandb的数据库。 1、查看Ya…...

在未排序的整数数组找到最小的缺失正整数
🎁👉点击进入文心快码 Baidu Comate 官网,体验智能编码之旅,还有超多福利!🎁 🔍【大厂面试真题】系列,带你攻克大厂面试真题,秒变offer收割机! ❓今日问题&am…...

终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能
终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩《英雄联…...

苹果A17芯片与台积电3nm工艺:技术解析与行业影响
1. 从3nm工艺说起:为什么A17芯片的制造选择如此关键每年秋季的苹果新品发布会,除了新iPhone的设计,最牵动科技圈神经的莫过于那颗全新的A系列仿生芯片。今年,关于iPhone 15系列将搭载A17芯片,并由台积电独家采用其第二…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

如何快速掌握MTKClient:从零开始的联发科设备救砖与调试完整指南
如何快速掌握MTKClient:从零开始的联发科设备救砖与调试完整指南 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 你是否曾经面对变砖的联发科手机束手无策?是否因为…...

AI助手开发实战:从资源索引到生产级系统搭建指南
1. 项目概述:一个为AI助手开发者准备的“藏宝图” 如果你正在开发一个AI助手应用,或者正打算将大语言模型的能力集成到你的产品里,那你大概率会遇到一个经典难题:面对市面上眼花缭乱的模型、API和工具,我到底该怎么选&…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...