RabbitMQ进阶_可靠性
文章目录
- 一、 发送者的可靠性
- 1.1、 生产者重试机制
- 1.2、 生产者确认机制
- 1.2.1、确认机制理论
- 1.2.2、确认机制实现
- 1.2.2.1、定义ReturnCallback
- 1.2.2.2、定义ConfirmCallback
- 二、 MQ的可靠性
- 2.1、 数据持久化
- 2.1.1、 交换机持久化
- 2.1.2、 队列持久化
- 2.1.3、 消息持久化
- 2.2、 LazyQueue
- 三、 消费者的可靠性
- 3.1、 消费者确认机制
- 3.2、 失败重试机制
- 3.3、 失败处理策略
- 3.4、 业务幂等性
- 3.4.1、 唯一消息ID
- 3.4.2、 业务判断
- 3.5、 兜底方案
消息从发送者发送消息,到消费者处理消息,需要经过的流程是这样的:

消息从生产者到消费者的每一步都可能导致消息丢失:
1.发送消息时丢失
- 生产者发送消息时连接MQ失败。
- 生产者发送消息到达MQ后未找到
Exchange。 - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue。 - 消息到达MQ后,处理消息的进程发生异常。
2.MQ导致消息丢失
- 消息到达MQ,保存到队列后,尚未消费就突然宕机。
3.消费者处理消息时
- 消息接收后尚未处理突然宕机。
- 消息接收后处理过程中抛出异常。
综上,我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手:
- 确保生产者一定把消息发送到MQ。
- 确保MQ不会将消息弄丢。
- 确保消费者一定要处理消息。
一、 发送者的可靠性
1.1、 生产者重试机制
生产者发送消息时,出现了网络故障,导致与MQ的连接中断。为了解决这个问题,SpringAMQP提供了消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试,可以在配置文件中添加如下配置:
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled: true # 开启超时重试机制initial-interval: 1000ms # 失败后的初始等待时间multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multipliermax-attempts: 3 # 最大重试次数
当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,无法执行后面逻辑。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
1.2、 生产者确认机制
1.2.1、确认机制理论
一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。不过,在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
- MQ内部处理消息的进程发生了异常。
- 生产者发送消息到达MQ后未找到
Exchange。 - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由。
针对上述情况,RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执:

总结如下:
- 当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功(图中的exchange2,一般情况下路由失败都是由开发人员编码导致的,所以一般不用开启此机制)。
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功(图中queue1)。
- 持久消息投递到了MQ,并且入队完成持久化(保存到磁盘,图中queue2),返回ACK ,告知投递成功。
- 其它情况都会返回NACK,告知投递失败(实际开发中,如果业务场景对可靠性有较高要求,只关注返回nack的情况即可,可以采取重新发送等方式)。
其中ack和nack属于Publisher Confirm机制,ack是投递成功,nack是投递失败。而return则属于Publisher Return机制。
默认两种机制都是关闭状态,需要通过配置文件来开启。
1.2.2、确认机制实现
开启生产者确认:
spring:rabbitmq:publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型publisher-returns: true # 开启publisher return机制
这里publisher-confirm-type有三种模式可选:
none:关闭confirm机制。simple:同步阻塞等待MQ的回执。correlated:MQ异步回调返回回执。
一般我们推荐使用correlated回调机制。
1.2.2.1、定义ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置:
@Slf4j
@AllArgsConstructor
@Configuration
public class MqConfig {private final RabbitTemplate rabbitTemplate;@PostConstructpublic void init(){rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {@Overridepublic void returnedMessage(ReturnedMessage returned) {log.error("触发return callback,");log.debug("exchange: {}", returned.getExchange());log.debug("routingKey: {}", returned.getRoutingKey());log.debug("message: {}", returned.getMessage());log.debug("replyCode: {}", returned.getReplyCode());log.debug("replyText: {}", returned.getReplyText());}});}
}
1.2.2.2、定义ConfirmCallback
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数CorrelationData:

CorrelationData中包含两个核心的东西:
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
将来MQ的回执就会通过这个Future来返回,我们可以提前给CorrelationData中的Future添加回调函数来处理消息回执:

@Test
void testPublisherConfirm() {// 1.创建CorrelationDataCorrelationData cd = new CorrelationData();// 2.给Future添加ConfirmCallbackcd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {@Overridepublic void onFailure(Throwable ex) {// 2.1.Future发生异常时的处理逻辑,基本不会触发log.error("send message fail", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {// 2.2.Future接收到回执的处理逻辑,参数中的result就是回执内容if(result.isAck()){ // result.isAck(),boolean类型,true代表ack回执,false 代表 nack回执log.debug("发送消息成功,收到 ack!");}else{ // result.getReason(),String类型,返回nack时的异常描述log.error("发送消息失败,收到 nack, reason : {}", result.getReason());}}});// 3.发送消息rabbitTemplate.convertAndSend("hmall.direct", "q", "hello", cd);
}
注意:开启生产者确认比较消耗MQ性能,一般不建议开启。
- 路由失败:一般是因为RoutingKey错误导致,往往是编程导致。
- 交换机名称错误:同样是编程错误导致。
- MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
二、 MQ的可靠性
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟消息。这样就会导致两个问题:
- 一旦MQ宕机,内存中的消息就会丢失。
- 内存空间有限,当消费者故障或者处理过慢时,会导致消息积压,引发MQ阻塞。
针对以上两种问题,可以分别采用数据持久化和LazyQueue的解决办法。
2.1、 数据持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,可以配置数据持久化(这个是MQ3.6之前使用的方式),包括:
- 交换机持久化
- 队列持久化
- 消息持久化
我们以控制台界面为例来说明。
2.1.1、 交换机持久化
在控制台的Exchanges页面,添加交换机时可以配置交换机的Durability参数:

2.1.2、 队列持久化
在控制台的Queues页面,添加队列时,同样可以配置队列的Durability参数:

2.1.3、 消息持久化
在控制台发送消息的时候,可以添加很多参数,而消息的持久化是要配置一个properties:delivery_mode

注意:使用spring发送消息到MQ时,这几个持久化都是默认的。
在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
2.2、 LazyQueue
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
- 消费者宕机或出现网络故障。
- 消息发送量激增,超过了消费者处理速度。
- 消费者处理业务发生阻塞。
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为称为PageOut。 PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存。
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)。
- 支持数百万条的消息存储。
而在3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。如果版本较老,可以:
@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg){log.info("接收到 lazy.queue的消息:{}", msg);
}
三、 消费者的可靠性
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
- 消息投递的过程中出现了网络故障。
- 消费者接收到消息后突然宕机。
- 消费者接收到消息后,因处理不当导致异常。
- …
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态。
3.1、 消费者确认机制
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制。即:当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息。
- nack:消息处理失败,RabbitMQ需要再次投递消息。
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息。
一般reject方式用的较少,除非是消息格式有问题,那就是开发问题了。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack。
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用。manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活。auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack.。当业务出现异常时,根据异常判断返回不同结果:- 如果是业务异常,会自动返回
nack。 - 如果是消息处理或校验异常,自动返回
reject。
- 如果是业务异常,会自动返回
通过下面的配置可以修改SpringAMQP的ACK处理方式:
spring:rabbitmq:listener:simple:acknowledge-mode: none # 不做处理
3.2、 失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力。
当然,上述极端情况发生的概率还是非常低的,不过不怕一万就怕万一。为了应对上述情况,Spring又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000ms # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
重启consumer服务,重复之前的测试。可以发现:
- 消费者在失败后消息没有重新回到MQ无限重新投递,而是在本地重试了3次。
- 本地重试3次以后,抛出了
AmqpRejectAndDontRequeueException异常。查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是reject。
结论:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试。
- 重试达到最大次数后,Spring会返回reject,消息会被丢弃。
3.3、 失败处理策略
在之前的测试中,本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。因此Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式 。ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队 。RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机 。
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
其实后面这部分在实际业务开发中还是很有用的。在实际工作中存在kafka to ES的场景,有时会出现同一作业并行跑的异常,这时就需要保证
业务幂等性了,这种场景下用的是唯一ID的解决方案。另外也有定时任务跑批作业的场景,有时由于数据异常等原因导致本批次失败,就需要由调度作业跑下一次,是采用业务逻辑保证业务幂等性的。
兜底方案在实际开发中也有用到,有时业务数据来源非联机,中间经过数据组处理后才回到我们系统,有时会存在数据准确度的延迟问题,这时也需要有“补偿作业”主动联机获取数据,并更新到我们系统中。
3.4、 业务幂等性
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。例如:
- 根据id删除数据
- 查询数据
- 新增数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
- 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况。
- 退款业务。重复退款对商家而言会有经济损失。
然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
- 页面卡顿时频繁刷新导致表单重复提交。
- 服务间调用的重试。
- MQ消息的重复投递。
我们在用户支付成功后会发送MQ消息到交易服务,修改订单状态为已支付,就可能出现消息重复投递的情况。如果消费者不做判断,很有可能导致消息被消费多次,出现业务故障。举例:
- 假如用户刚刚支付完成,并且投递消息到交易服务,交易服务更改订单为已支付状态。
- 由于某种原因,例如网络故障导致生产者没有得到确认,隔了一段时间后重新投递给交易服务。
- 但是,在新投递的消息被消费之前,用户选择了退款,将订单状态改为了已退款状态。
- 退款完成后,新投递的消息才被消费,那么订单状态会被再次改为已支付。业务异常。
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
- 唯一消息ID
- 业务状态判断
3.4.1、 唯一消息ID
这个思路非常简单:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
我们该如何给消息添加唯一ID呢?其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可。以Jackson的消息转换器为例:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jjmc.setCreateMessageIds(true);return jjmc;
}
3.4.2、 业务判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。例如我们当前案例中,处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理。
可以用下面的SQL来解释业务判断的实现逻辑:
UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1
在where条件中除了判断id以外,还加上了status必须为1的条件。如果条件不符(说明订单已支付),则SQL匹配不到数据,根本不会执行。
3.5、 兜底方案
虽然我们利用各种机制尽可能增加了消息的可靠性,但也不好说能保证消息100%的可靠。万一真的MQ通知失败该怎么办呢?有没有其它兜底方案,能够确保订单的支付状态一致呢?
其实思想很简单:既然MQ通知不一定发送到交易服务,那么交易服务就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致。

图中黄色线圈起来的部分就是MQ通知失败后的兜底处理方案,由交易服务自己主动去查询支付状态。不过需要注意的是,交易服务并不知道用户会在什么时候支付,如果查询的时机不正确(比如查询的时候用户正在支付中),可能查询到的支付状态也不正确。那么问题来了,我们到底该在什么时间主动查询支付状态呢?
这个时间是无法确定的,因此,通常我们采取的措施就是利用定时任务定期查询,例如每隔20秒就查询一次,并判断支付状态。如果发现订单已经支付,则立刻更新订单状态为已支付即可。
综上,支付服务与交易服务之间的订单状态一致性是如何保证的?
- 首先,支付服务会在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递的可靠性
- 最后,我们还在交易服务设置了定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
相关文章:
RabbitMQ进阶_可靠性
文章目录 一、 发送者的可靠性1.1、 生产者重试机制1.2、 生产者确认机制1.2.1、确认机制理论1.2.2、确认机制实现1.2.2.1、定义ReturnCallback1.2.2.2、定义ConfirmCallback 二、 MQ的可靠性2.1、 数据持久化2.1.1、 交换机持久化2.1.2、 队列持久化2.1.3、 消息持久化 2.2、 …...

JavaScript字符串的常用方法有哪些?
1.1操作方法 归纳为增删查改 1.1.1增 这里不是直接增添内容,而是创建字符串的一个副本,再进行操作 处理用以及${}进行字符串拼接外,还可以通过concat 1.1.1.1concat 用于将一个或多个字符串拼接为一个新字符串(浅拷贝&#…...

jmeter发送post请求
在jmeter中,有两种常用的请求方式,get和post.它们两者的区别在于get请求的参数一般是放在路径中,可以使用用户自定义变量和函数助手等方式进行参数化,而post请求的参数不能随url发送,而是作为请求体提交给服务器。而在…...

图文深入理解Oracle Total Recall
List item 题记:本文图文深入理解Oracle Total Recall技术。 1. Oracle Total Recall 概述 Oracle Total Recall(也称为 Flashback Data Archive - 闪回数据归档)提供了一种用于跟踪数据库更改的机制,可自动跟踪数据库历史更改…...

腾讯云控制台URL刷新URL预热 使用接口刷新
如图所示的俩个控制台功能,调用腾讯云的接口执行这俩个动作 (代码可以优化)nodejs框架是express, 这里粘贴调用成功的代码示例,做个记录。 app.get(/PurgeUrlsCache, async function (req, res, next) {// Depends on tencentclo…...

构建后端为etcd的CoreDNS的容器集群(二)、下载最新的etcd容器镜像
在尝试获取etcd的容器的最新版本镜像时,使用latest作为tag取到的并非最新版本,本文尝试用实际最新版本的版本号进行pull,从而取到想的最新版etcd容器镜像。 一、用latest作为tag尝试下载最新etcd的镜像 1、下载镜像 [rootlocalhost opt]# …...

libaom-all-intra参数说明
part_sf.less_rectangular_check_level 1; 这个设置可能控制编码器在分割画面时使用非矩形分区的检查级别。part_sf.ml_prune_partition 1; 这个设置可能用于基于机器学习(ML)的分区修剪,以减少不必要的计算。part_sf.prune_ext_partition_…...

应用假死?
有个客户10月18日应用接口都访问慢,nginx层面error显示连接拒绝,当时实施同学重启了java应用运行正常,但今天又卡死了,后台登录也登录不上去,看日志没异常,最终找到了数据库层面。 查看数据库相关日志&…...
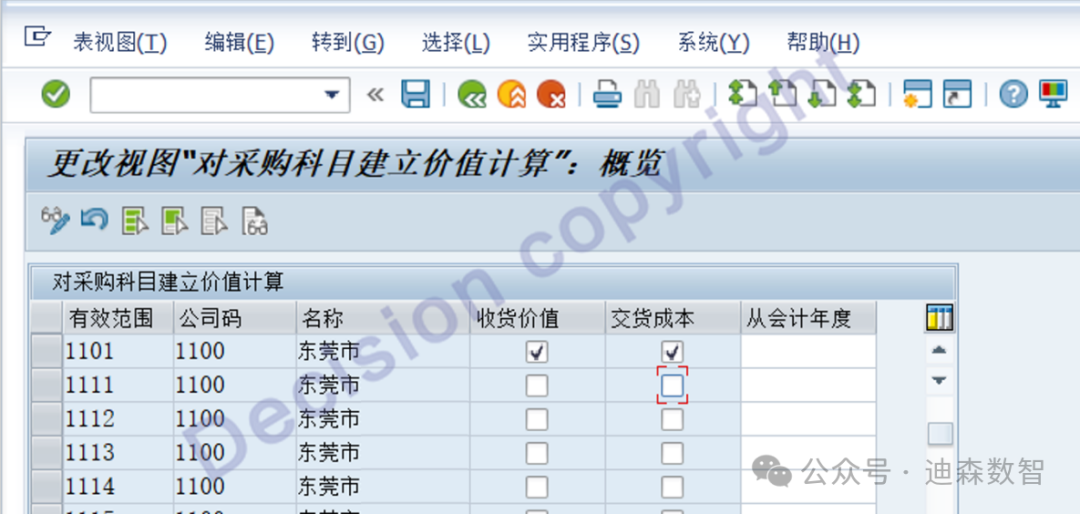
SAP MM+FI - 物料管理模块与财务会计模块的集成配置
01 采购费用过账配置表 为了方便项目实施过程中采购费用过账配置,迪森资深专家根据丰富经验总结得出采购费用过账配置表,以供大家参考: 02 材料采购订单入库及结算 2.1采购订单入库 假设:入库数量1000PC,价格 10 元…...

初阶数据结构【3】--单链表(比顺序表还好的一种数据结构!!!)
本章概述 前情回顾单链表实现单链表彩蛋时刻!!! 前情回顾 咱们在上一章博客点击:《顺序表》的末尾,提出了一个问题,讲出了顺序表的缺点——有点浪费空间。所以,为了解决这个问题,我…...

mysql迁移到达梦的修改点
字段是达梦关键字的,达梦会给转成大写,如果不要转则需要使用双引号引起来。关键字参考:D:\dmdbms\doc\DM8_SQL语言使用手册.pdf 例如:RowCount Level Content Password Locked 中文乱码问题,需要在应用程序所在服务器的…...
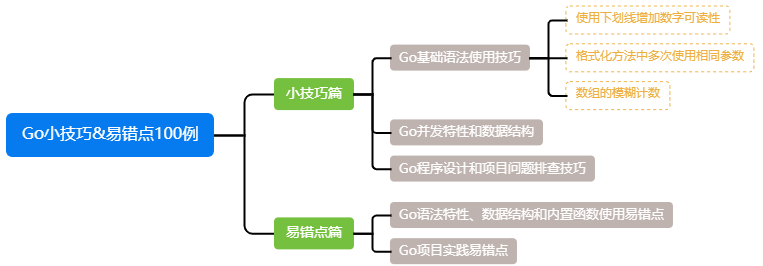
Go小技巧易错点100例(十八)
正文: 使用下划线增加数字可读性 有时候我们代码里会定义很长的数字,虽然计算机程序能支持很大的数据的计算,但是对我们来说,可读性是一个需要考虑的点,特别是1后面全是0的时候。 但是这个问题在Go语言中是可以通过…...

【python】极简教程8-字符串
第八章:字符串 8.1 字符串即序列 字符串是一系列字符的有序集合,可以使用索引访问字符串中的各个字符,索引从 0 开始。 示例代码: fruit = banana letter = fruit[1] print(letter) # 输出: a8.2 len 函数 len 函数返回字符串的长度(字符数)。...

UEFI EDK2框架学习 (四)——UEFI图形化
一、修改protocol.c #include <Uefi.h> #include <Library/UefiLib.h> #include <Library/UefiBootServicesTableLib.h> #include <stdio.h>EFI_STATUS EFIAPI UefiMain(IN EFI_HANDLE ImageHandle,IN EFI_SYSTEM_TABLE *SystemTable ) {EFI_STATUS S…...

【C++】— 一篇文章让你认识STL
文章目录 🌵1.什么是STL?🌵2.STL的版本🌵3.STL的六大组件🌵4.STL的重要性🌵5. 如何学习STL🌵6. 学习STL的三种境界 🌵1.什么是STL? STL是Standard Template Library的简称…...

mysql--索引
目录 1、长什么样 2、硬件理解 3、软件理解 4、进一步认识 5、索引的理解 6、为什么不选择其他数据结果? 7、聚簇索引和非聚簇索引 8、索引操作 (1)主键索引创建 第一种方式 第二种方式 第三种方式 主键索引的特点 (…...
【linux】线程 (三)
13. 常见锁概念 (一)了解死锁 死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程占有的,且不释放的资源,而处于的一种永久等待状态 (二)死锁四个必要条件 互斥条件…...

c++日常积累
在 C 中,可以直接将 int 类型的值赋值给 bool 类型。C 会自动进行类型转换,任何非零的 int 值都会被转换为 true,而 0 会被转换为 false。 QDialog 有一个 finished(int) 信号,该信号在对话框关闭时发出,并传递一个整…...

字节流写入文件
一、创建输出流对象表示的文件三种方式 方法一: FileOutputStream fos new FileOutputStream("fos.txt",true);//最简便方法二: FileOutputStream fos new FileOutputStream(new File("fos.txt"));方法三; File f ne…...

Torch模型导入
冻结param的3种方式 for param in net.lstm.parameters():param.requires_grad Truenet.lstm.requires_grad True # 无效net.lstm.state_dict()[weight_ih_l0].requires_gradFalsenet.lstm.weight_ih_l0.requires_grad False# dir(net.lstm) to validate attributes …...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...