【LeetCode HOT 100】详细题解之二分查找篇
【LeetCode HOT 100】详细题解之二分查找篇
- 35 搜索插入位置
- 思路
- 代码(左闭右闭)
- 代码(左闭右开)
- 74 搜索二维矩阵
- 思路
- 代码(左闭右闭)
- 34 在排序数组中查找元素的第一个和最后一个位置
- 思路
- 代码
- 33 搜索旋转排序数组
- 思路
- 代码
- 153 寻找旋转排序数组中的最小值
- 思路
- 代码
- 4 寻找两个正序数组的中位数
- 思路
- 代码
35 搜索插入位置
35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums为 无重复元素 的 升序 排列数组-104 <= target <= 104
思路
一般使用二分查找算法需要满足以下两个条件
- 用于查找的内容有序
- 查找的数量只能是一个,而不是多个
举个例子,在一个有序且无重复元素的数组中,例如nums=[1,3,4,8,15,16,18,28]中查找元素16,这样就可以使用二分查找。
二分查找中,目标元素的查找区间定义十分重要。我们要确定查找的范围。主要有以下两种方式
- [left,right] 左闭右闭 (此时while循环为while(left<=right) )
- [left,right) 左闭右开(此时while循环为while(left<right))
- 这两种方式的实现会在while循环的判断,以及对right的更新上存在一定的区别。在下面会进行详细说明。
用二分查找,查找区间为[left,right] 左闭右闭的操作查找步骤如下:
nums=[1,3,4,8,15,16,18,28]
下标 = 0,1,2,3,4, 5 , 6, 7
-
l = 0, r = nums.length -1 = 7
-
mid = (l+r)/2 = 3
-
比较nums[mid] = 8和target = 16 的大小
-
nums[mid]>target
说明[mid,right]区间内的所有元素都大于target,此时要去[left,mid-1]区间中查找,更新右边界right
right = mid -1;
-
nums[mid]<target (8<16,说明要在[mid+1,right]中找)
说明[left,mid]区间内的所有元素都小于target,此时要去[mid+1,right]区间中查找,更新左边界left
left = mid + 1
-
nums[mid]==target ,直接return mid
-
不断循环1,2,3直到找到为止,若循环完都没有return说明查找元素在数组中不存在
代码(左闭右闭)
class Solution {public int searchInsert(int[] nums, int target) {/**二分查找,查找区间写为[left,right]*/int l = 0,r = nums.length-1;while(l <= r){int mid = l + (r-l)/2;if(nums[mid]>target){ //注意这里,是将r 更新为mid - 1r = mid-1;}else if(nums[mid]<target){l = mid +1;}else if(nums[mid]==target){return mid;}}return l;}
}
代码(左闭右开)
class Solution {public int searchInsert(int[] nums, int target) {/**二分查找,查找区间写为[left,right]*/int l = 0,r = nums.length; //这里r是nums.length,因为查找范围不包括nums[r]while(l < r){ //这里是l<r,因为查找范围为[l,r)int mid = l + (r-l)/2;if(nums[mid]>target){r = mid; //这里r = mid,因为查找范围不包括r}else if(nums[mid]<target){l = mid +1;}else if(nums[mid]==target){return mid;}}return l;}
}
74 搜索二维矩阵
74. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵:
- 每行中的整数从左到右按非严格递增顺序排列。
- 每行的第一个整数大于前一行的最后一个整数。
给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。
示例 1:

输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
示例 2:
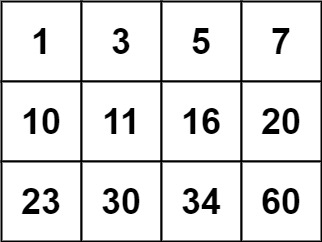
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
思路
挺简单的,遍历每一行,获取每一行的第一个元素和最后一个元素,判断target是否在该行中。若在该行中,则使用二分查找,若不在,则继续遍历下一行。
代码(左闭右闭)
class Solution {public boolean searchMatrix(int[][] matrix, int target) {int m = matrix.length;int n = matrix[0].length;for(int i = 0;i<m;i++){if(target>=matrix[i][0] && target <=matrix[i][n-1]){int l = 0,r = n-1;while(l<=r){int mid = l + (r-l)/2;if(matrix[i][mid]>target){r = mid -1;}else if(matrix[i][mid]<target){l = mid + 1;}else if(matrix[i][mid]==target){return true;}}}}return false;}
}
34 在排序数组中查找元素的第一个和最后一个位置
34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109nums是一个非递减数组-109 <= target <= 109
思路
二分查找的变体。
本题中会存在重复的元素,所以需要用二分查找来找到某个元素在数组中第一次出现的位置。将二分查找算法写成函数lowerBound,该函数会找到target第一次出现的位置。调用两次该方法,第一次查找target,第二次查找target+1,这样就能成功返回目标在数组中的开始位置和结束位置。
我们需要考虑边界情况。如果数组为空,或者所有数都<target,那么会返回nums.length,因此lowerBound返回值为nums.length时,直接返回-1,-1,此外还需要判断lowerBound返回的下标在数组中对应的值是否等于target。
lowerBound如何实现呢,和二分查找的差别在于更新右边界,不管nums[mid] <target还是nums[mid]=target , 都会一直往左找,直到找到该元素第一次出现的位置。
if(numd[mid]<target){
l = mid + 1;
}else{
r = mid - 1; //这里不管nums[mid] <target还是nums[mid]=target , 都会一直往左找,直到找到第一个
}
代码
class Solution {public int[] searchRange(int[] nums, int target) {int start = lowerBound(nums,target);if(start == nums.length || nums[start] !=target){return new int[]{-1,-1};}int end = lowerBound(nums,target+1)-1;return new int[]{start,end};}/**lowerBound返回 [最小的]满足nums[i]>=target的i ,如何实现呢也可以理解为找到target第一次出现的位置。如果数组为空,或者所有数都<target,那么会返回nums.lengthif(numd[mid]<target){l = mid + 1;}else{r = mid - 1; //这里不管nums[mid] <target还是nums[mid]=target , 都会一直往左找,直到找到第一个}*/public int lowerBound(int[] nums,int target){int l = 0,r = nums.length-1;while(l<=r){int mid = l + (r-l)/2;if(nums[mid]>target){r = mid - 1;}else if(nums[mid]<target){l = mid + 1;}else if(nums[mid]==target){r = mid - 1;}}return l;}
}
33 搜索旋转排序数组
33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
示例 3:
输入:nums = [1], target = 0
输出:-1
提示:
1 <= nums.length <= 5000-104 <= nums[i] <= 104nums中的每个值都 独一无二- 题目数据保证
nums在预先未知的某个下标上进行了旋转 -104 <= target <= 104
思路
题目分析
本题是在一个可能经过旋转的有序数组中查找给定目标值的问题。由于数组经过旋转,所以它被分为了两个部分,一部分是有序的,另一部分是无序的。我们需要利用这个特点来进行高效的查找。
二分查找,每次查找一定能有一部分是有序的,一部分是无序的
判断target在哪部分,若在有序的部分则直接二分查找,若在无序的部分就继续切割为有序和无序
解题思路
- 初始化指针
- 首先,定义两个指针
l和r,分别指向数组的首尾位置,表示当前搜索的区间。
- 首先,定义两个指针
- 循环查找
- 进入一个循环,只要
l不超过r,就继续查找。 - 在每次循环中,计算当前区间的中间位置
mid,即mid = l + (r - l)/2。
- 进入一个循环,只要
- 情况判断
- 如果
nums[mid]等于目标值target,说明找到了目标,直接返回mid。 - 如果
nums[mid]不等于目标值,需要判断当前的中间位置处于哪个区间(有序区间还是无序区间)。 - 如果nums[l] <= nums[mid],说明左边[l, mid]是有序区间:
- 如果目标值
target在这个有序区间内(即nums[l] <= target && nums[mid] >= target),那么更新r为mid - 1,继续在有序区间中查找。 - 如果目标值不在这个有序区间内,说明在无序区间中,此时更新
l为mid + 1。
- 如果目标值
- 如果
nums[mid] <= nums[r],说明右边[mid, r]是有序区间:- 如果目标值
target在这个有序区间内(即nums[mid] <= target && nums[r] >= target),那么更新l为mid + 1,继续在有序区间中查找。 - 如果目标值不在这个有序区间内,说明在无序区间中,此时更新
r为mid - 1。
- 如果目标值
- 如果
- 返回结果
- 如果循环结束后还没有找到目标值,说明目标值不在数组中,返回
-1。
- 如果循环结束后还没有找到目标值,说明目标值不在数组中,返回
三、算法复杂度分析
- 时间复杂度:
- 由于每次循环都将搜索区间缩小一半,所以时间复杂度为O(logn) ,其中
n是数组的长度。
- 由于每次循环都将搜索区间缩小一半,所以时间复杂度为O(logn) ,其中
- 空间复杂度:
- 算法只使用了几个额外的变量,不随输入规模增长而增长,所以空间复杂度为O(1) 。
代码
class Solution {public int search(int[] nums, int target) {/**二分查找,每次查找一定能有一部分是有序的,一部分是无序的判断target在哪部分,若在有序的部分则直接二分查找,若在无序的部分就继续切割为有序和无序*/int l = 0,r = nums.length-1;while(l<=r){int mid = l + (r-l)/2;//1.如果当前数等于target,直接返回if(nums[mid]==target){return mid;}else if(nums[l]<=nums[mid]){//2.左边[l,mid]是顺序区间//2.1判断当前元素是否在顺序区间中,若在顺序区间中,更新r为mid-1,继续在顺序区间中查找if(nums[l]<= target && nums[mid]>=target){r = mid - 1;}else{ //不在顺序区间中,在无序区间中l = mid + 1;}}else if(nums[mid]<=nums[r]){//3.右边[mid,r]是顺序区间//3.1 判断当前元素是否在顺序区间中//3.2 若在顺序区间中,更新l 为mid + 1,继续在顺序区间[l,r]中查找if(nums[mid]<=target && nums[r]>=target){l = mid + 1;}else{r = mid - 1; //在无需区间中查找}}}return -1;}
}
153 寻找旋转排序数组中的最小值
153. 寻找旋转排序数组中的最小值
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2] - 若旋转
7次,则可以得到[0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [3,4,5,1,2]
输出:1
解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。
示例 2:
输入:nums = [4,5,6,7,0,1,2]
输出:0
解释:原数组为 [0,1,2,4,5,6,7] ,旋转 3 次得到输入数组。
示例 3:
输入:nums = [11,13,15,17]
输出:11
解释:原数组为 [11,13,15,17] ,旋转 4 次得到输入数组。
提示:
n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums中的所有整数 互不相同nums原来是一个升序排序的数组,并进行了1至n次旋转
思路
实现思路
- 利用二分查找的思想,通过比较中间元素和数组末尾元素的大小关系来确定最小值所在的区间,不断缩小区间范围,直到找到最小值。
- 由于数组经过旋转后被分为了两个部分,一部分是原升序数组的某个子区间,另一部分是旋转后的子区间,最小值就在这两个区间的交界处。通过比较中间元素和末尾元素,可以确定当前中间元素处于哪个子区间,从而缩小查找范围。
具体实现步骤
- 初始化指针
- 定义两个指针
l和r,分别指向数组的首和尾位置,表示当前搜索的区间范围。初始时,l = 0,r = nums.length - 1。
- 定义两个指针
- 进入循环
- 进入一个循环,只要
l小于等于r,就继续查找。
- 进入一个循环,只要
- 计算中间位置
- 在每次循环中,计算当前区间的中间位置
mid,即mid = l + (r - l)/2。
- 在每次循环中,计算当前区间的中间位置
- 情况判断与区间调整
- 如果
nums[mid] <= nums[n - 1]:- 说明
[mid, r]为翻转后的递增区间,此时最小值一定在[l, mid - 1]中,所以将r更新为mid - 1。
- 说明
- 如果nums[mid] > nums[n - 1]:
- 说明
[l, mid]为未翻转的递增区间,那最小值一定在[mid + 1, r]中,所以将l更新为mid + 1。
- 说明
- 如果nums[mid] == nums[n - 1]:
- 说明无法确定最小值在哪个区间,但因为最终要返回
l,所以将r更新为mid - 1,缩小搜索范围。
- 说明无法确定最小值在哪个区间,但因为最终要返回
- 如果
- 返回结果
- 循环结束后,
l指向的位置就是数组中的最小值,返回nums[l]。
- 循环结束后,
算法复杂度分析
- 时间复杂度:
- 由于每次循环都将搜索区间缩小一半,所以时间复杂度为 O(logn),其中
n是数组的长度。
- 由于每次循环都将搜索区间缩小一半,所以时间复杂度为 O(logn),其中
- 空间复杂度:
- 算法只使用了几个额外的变量,不随输入规模增长而增长,所以空间复杂度为 O(1)。
代码
class Solution {public int findMin(int[] nums) {/**[4,5,6,7,0,1,2]使用nums[mid]和nums[n-1]比不停的拿中间的数和最后一个数比较,缩小区间,一共有三种情况nums[mid]<nums[n-1] : 说明[mid,r]为翻转后的递增区间,此时最小值一定在[l,mid-1]中nums[mid]>nums[n-1]: 说明[l,mid]为未翻转的递增区间,那最小值一定在[mid+1,r]中nums[mid]==nums[n-1]:说明最小值为n-1,因为我们要返回l,所以将r更新为mid-1不断缩小区间,最终找到最小值返回*/int l = 0,r = nums.length-1;int n = nums.length;while(l <= r){int mid = l + (r-l)/2;if(nums[mid]<=nums[n-1]){ //r = mid - 1;}else {l = mid + 1;}}return nums[l];}
}
4 寻找两个正序数组的中位数
4. 寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
提示:
nums1.length == mnums2.length == n0 <= m <= 10000 <= n <= 10001 <= m + n <= 2000-106 <= nums1[i], nums2[i] <= 106
思路
解题思路
- 将求两个有序数组的中位数问题转化为求两个数组合并后第
k小的数的问题。 - 利用二分查找的思想,每次排除一定数量的元素,逐步缩小搜索范围,直到找到第
k小的数。
边界情况考虑
- 当其中一个数组到达边界时:
- 如果已经到达数组
nums1的边界,此时要求的第k小的元素即为nums2开始的第k个,直接返回nums2[index2 + k - 1]。 - 同理,如果已经到达数组
nums2的边界,返回nums1[index1 + k - 1]。
- 如果已经到达数组
- 当
k = 1时:- 需要找到两个数组中第 1 小的数,直接返回两个数组开头的最小值。
具体实现步骤
- 求中位数的主方法
- 首先,计算两个数组的长度
m和n。 - 如果合并后的数组大小为奇数,直接求第
(m + n)/2 + 1小的数即可,将结果强制转换为double类型后返回。 - 如果合并后的数组大小为偶数,那么需要求解第
(m + n)/2和第(m + n)/2 + 1小的数,然后取平均并返回。
- 首先,计算两个数组的长度
- 求第
k小的数的辅助方法- 初始化两个数组的指针
index1和index2,分别指向nums1和nums2的起始位置。 - 进入一个循环,在循环中不断缩小搜索范围,直到找到第
k小的数。 - 在每次循环中,首先判断边界情况:
- 如果到达
nums1的边界,返回nums2[index2 + k - 1]。 - 如果到达
nums2的边界,返回nums1[index1 + k - 1]。 - 如果
k = 1,返回两个数组开头的较小值。
- 如果到达
- 正常处理时,为了后续比较的方便,先求出
A[k/2 - 1]和B[k/2 - 1]的下标,但要注意不能直接index + k/2 - 1,可能会越界,应该使用Math.min(index + k/2, array.length) - 1来计算。 - 判断nums1[newIndex1]和nums2[newIndex2]的大小:
- 如果
nums1[newIndex1] > nums2[newIndex2],说明可以排除掉nums2中[index2,...,index2 + k/2 - 1]的部分,更新index2 = index2 + k/2,同时更新k的值为k -= newIndex2 - index2 + 1。 - 如果
nums1[newIndex1] < nums2[newIndex2],可以排除掉nums1中[index1,...,index1 + k/2 - 1]的部分,更新index1 = index1 + k/2,更新k的值为k -= newIndex1 - index1 + 1。
- 如果
- 初始化两个数组的指针
五、算法复杂度分析
- 时间复杂度:
- 由于每次循环都将搜索范围缩小一半,所以时间复杂度为O(logn),其中
m和n分别是两个数组的长度。
- 由于每次循环都将搜索范围缩小一半,所以时间复杂度为O(logn),其中
- 空间复杂度:
- 算法只使用了几个额外的变量,不随输入规模增长而增长,所以空间复杂度为O(1)。
代码
class Solution {public double findMedianSortedArrays(int[] nums1, int[] nums2) {/**使用求两个数组中第k小的数来求解中位数。两种情况1.合并后的数组大小为奇数num,则直接求第 num/2+1 小的数即可2.合并后的数组大小为偶数num,那么需要求解第 num/2 ,和第num/2+1小的数,然后再取平均*/int m = nums1.length,n = nums2.length;if((m+n)%2!=0){int mid = getKthElement(nums1,nums2,(m+n)/2+1);return (double)mid;}else{double mid1 = getKthElement(nums1,nums2,(m+n)/2);double mid2 = getKthElement(nums1,nums2,(m+n)/2+1);return (mid1+mid2)/2;}}/**转换为求两个数组中第k小的数,因为时间复杂度需要为O(log(m+n)),因此考虑二分查找的办法。每次排除都排除k/2个元素。假设有A,B两个数组,现在要求A,B数组合并后的第k小的数求A[k/2-1] B[k/2-1]的值,判断这两个的大小1.若A[K/2-1] > B[k/2-1],说明B[0,...,k/2-1]中的k/2个数一定不会是第k小的数,所以更新B的下标,排除B[0,...,k/2-1]2.反之若A[k/2-1] < B[k/2-1] 说明A[0,...,k/2-1]中的k/2个数一定不会是第k小的数,所以更新A的下标,排除A[0,...,k/2-1]相等的话,排除A和B都行,这里排除A在排除A/B的k/2个元素后,我们现在需要在新的数组中找到第k - k/2 小的元素,因此更新k = k-k/2注意边界条件:1.假如已经到达A/B数组的边界,以A为例,已经到达数组A的边界此时要求的第k小的元素即为B开始的第k个,直接返回B[index + k - 1],反之则返回A[index+k-1]2.假如k=1,需要找到两个数组中第1小的数,直接返回两个数组开头的最小值*/private int getKthElement(int nums1[],int nums2[],int k){int index1 = 0,index2 = 0;while(true){//1.判断边界条件//1.1 到达数组1的边界,返回数组2中第k小的数if(index1==nums1.length){return nums2[index2+k-1];}//1.2 到达数组2的边界,返回数组1中第k小的数if(index2==nums2.length){return nums1[index1+k-1];}//1.3 k==1,需要找到两个数组中第1小的数,直接取两个数组中index较小的数if(k==1){return Math.min(nums1[index1],nums2[index2]);}//2.正常处理// 2.1 为了后续比较的方便,先求出A[k/2-1]和B[k/2-1]的下标// newIndex1 等价于 A的k/2-newIndex2 等价于B的k/2-1// 注意,直接index+k/2-1会越界!!!,所以不能这样。// int newIndex1 = index1 + k/2 - 1;// int newIndex1 = index2 + k/2 -1;int newIndex1 = Math.min(index1+k/2,nums1.length)-1;int newIndex2 = Math.min(index2+k/2,nums2.length)-1;//2.2 判断A[k/2-1]和B[k/2-1]的大小,即判断A[pivot1]和B[pivot2]的大小//2.2.1 nums1[k/2-1] > nums2[index2 + k/2-1],可以排除掉nums2中[index2,...,index2+k/2-1]的部分,更新index2 = index2 + k/2,同时更新k的值if(nums1[newIndex1]>nums2[newIndex2]){//(1)更新k的值k -= newIndex2-index2+1;//(2)排除掉后,更新index2的值index2 = newIndex2+1;}else {//2.2.2 nums1[k/2-1] < nums2[index2 + k/2-1],可以排除掉nums1中[index1,...,index1+k/2-1]的部分,更新index1 = index1 + k/2// 注意这里等于的情况放在哪里都可以。//(1)更新k的值k -= newIndex1 - index1 +1;//(2)排除掉后,更新index1的值index1 = newIndex1 +1;}// (×)2.2.3 更新k,因为已经排除掉了k/2个元素,现在只需要求k-k/2小的值,// k = k - k/2;}}
}
相关文章:
【LeetCode HOT 100】详细题解之二分查找篇
【LeetCode HOT 100】详细题解之二分查找篇 35 搜索插入位置思路代码(左闭右闭)代码(左闭右开) 74 搜索二维矩阵思路代码(左闭右闭) 34 在排序数组中查找元素的第一个和最后一个位置思路代码 33 搜索旋转排序数组思路代码 153 寻找旋转排序数组中的最小值思路代码 4 寻找两个正…...
)(待做))
管理篇(顶级思维模型(31个))(待做)
目录 一、成长进阶模型 二、优势探索模型 三、优势层次模型 四、人生定位模型 五、看懂人性模型 六、如何抉择模型 七、本质思考模型 八、心流模型 九、精力管理模型 十、高效沟通模型 十一、100%传递模型 十二、高效倾听模型 十三、高效表达模型 十四、精准提问模…...

十一、数据库配置
一、Navicat配置 这个软件需要破解 密码是:123456; 新建连接》新建数据库 创建一个表 保存出现名字设置 双击打开 把id设置为自动递增 这里就相当于每一次向数据库添加一个语句,会自动增长id一次 二、数据库的增删改查 1、Vs 建一个控…...

day02 -- docker
1.docker的介绍 Docker 是一个开源的应用容器引擎,基于 Go语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使…...

ecmascript标准
1. 简介 1.1. 概述 ECMAScript(简称ES)是JavaScript编程语言的一个标准化版本。它是为网络开发设计的一种轻量级的脚本语言,主要用于在网页上实现交互性和动态效果。ECMAScript是该语言的标准名称,而JavaScript是其最知名和广泛使用的实现。 1.2. 特点 跨平台性 :ECMAS…...

在Linux命令行中一行执行多个命令
原文地址链接: https://kashima19960.github.io/2024/10/22/Linux/在Linux命令行中一行执行多个命令/,一般有最新的修改都是在我的个人博客里面,所以在当前平台的更新会比较慢,请见谅😃 前言 在shell中一个一个命令行,…...

u盘快速格式化后怎么恢复文件:深入解析与全面指南
U盘,凭借其小巧便携、易于使用的特点,成为了我们日常生活中不可或缺的数据存储工具。然而,有时为了清除病毒、解决文件系统错误或准备存储新数据,我们可能需要对U盘进行快速格式化。但这一操作往往伴随着一个严峻的问题࿱…...

青少年编程能力等级测评CPA C++(二级)试卷(2)
青少年编程能力等级测评CPA C(二级)试卷(2) 一、单项选择题(共20题,每题3.5分,共70分) CP2_2_1.下列C程序段中,对二维数组arr的定义不正确是( &…...

aws 把vpc残留删除干净
最近忘了把vpc 删干净导致又被收了冤大头钱 在删除vpc 的收发现又eni在使用,但是忘了是哪个资源在占用 先用命令行把占用的资源找出来停掉 使用 AWS 命令行界面(CLI)来查看 VPC 的使用情况 列出子网: aws ec2 describe-subnets …...

平衡二叉树最全代码
#include<stdio.h> #include<stdlib.h>typedef struct Node {int val;int height;struct Node *left;struct Node *right; }Node;//创建新结点 Node* newNode(int val) {Node *node (Node*)malloc(sizeof(Node));node->val val;node->height 1;node->l…...

数据库表的创建
运用的环境是pychram python3.11.4 创建一个表需要用到以下语法 注释已经写清楚各种语法的含义,记住缩进是你程序运行的关键,因为程序是看你的缩进来判断你的运行逻辑,像我这个就是缩进不合理导致的报错 那么今天分享就到这里,谢…...

【MySQL 数据库】之--基础知识
1. MySQL 数据库基础概念 数据库: 逻辑上存储和管理数据的集合。MySQL 是一个常用的关系型数据库管理系统。 2. 创建数据库 要创建一个新的数据库,可以使用 CREATE DATABASE 语句。 语法: CREATE DATABASE 数据库名; 示例: CREATE DATABASE my_database; 注意事…...

Flume面试整理-如何处理Flume中的数据丢失
在Apache Flume中,数据丢失是一个可能出现的严重问题,特别是在处理大规模数据时。数据丢失通常会发生在数据从Source(源)到Channel(通道),或从Channel到Sink(汇)传输的过程中。如果不处理得当,Flume的崩溃或网络故障可能会导致丢失的数据无法恢复。以下是几种常见的F…...

文件处理新纪元:微信小程序的‘快递员’与‘整理师’
嗨,我是中二青年阿佑,今天阿佑将带领大家如何通过巧妙的文件处理功能,让用户体验从‘杂乱无章’到‘井井有条’的转变! 文章目录 微信小程序的文件处理文件上传:小程序的“快递服务”文件下载:小程序的“超…...

应付账款优化,自动化管理5要点
优化应付账款流程对企业现金流至关重要。通过自动化、规范采购订单、管理供应商、设计高效流程及保留数字记录,可显著提升效率与精确度。ZohoBooks在线财务记账软件助您简化应付账款处理,确保业务顺畅。 1、自动化您的应付账款流程 通过自动化你的应付账…...

Win安装Redis
目录 1、下载 2、解压文件并修改名称 3、前台简单启动 4、将redis设置成服务后台启动 5、命令启停redis 6、配置文件设置 1、下载 【下载地址】 2、解压文件并修改名称 3、前台简单启动 redis-server.exe redis.windows.conf 4、将redis设置成服务后台启动 redis-server -…...
手把手带你安装U9【win10+sql+U9】,同样适用U9C的安装
一、Win10操作系统设置 1、Windows 10内置账号administrator启用 a、登录到Windows 10系统以后,鼠标右键点击桌面左下角“win图标”,在弹出画面选择“命令提示符(管理员)”或”windows power shell(管理员)”,如下图: b、在”命令提示符(管理员)”或”windows power sh…...

若依前后端框架学习——新建模块(图文详解)
若依框架—新建模块 一、项目地址1、后端启动2、前端启动 二、生成代码1、添加菜单2、创建表结构3、生成代码2、编辑一些基本信息,然后点击提交3、生成代码,压缩包里有前端和后端代码 三、配置后端模块1、新建模块2. 修改pom.xlm2.1 修改第一个pom.xml 2…...

【LaTeX和Word版】写论文时如何调整公式和文字的间距
在撰写论文时,公式和文字段落的间距可能会显得不一致,特别是插入的公式占用单独一行时。这种情况下,可以通过以下两种方法来调整公式和文字段落的间距,使论文排版看起来更加整齐和一致。 1. 使用 LaTeX 调整段落间距 (1) 调整行…...

快乐数--双指针
一:题目 题目链接:. - 力扣(LeetCode) 二:算法原理 三:代码编写 int Sum(int n){int sum 0;while(n){sum pow(n%10,2);n / 10;}return sum;}bool isHappy(int n) {int slow n,fast Sum(n);while(slow …...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

从NLP到RAG:AI标书生成系统的技术架构与落地路径深度剖析
引言2026年2月,国家发改委等八部门联合印发《关于加快招标投标领域人工智能推广应用的实施意见》,明确到2026年底招标文件检测、智能辅助评标、围串标识别等重点场景在部分省市实现全覆盖。同一时期,《招标投标法》修订草案经国务院常务会议原…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

如何快速实现U盘文件自动备份:USBCopyer终极指南
如何快速实现U盘文件自动备份:USBCopyer终极指南 【免费下载链接】USBCopyer 😉 用于在插上U盘后自动按需复制该U盘的文件。”备份&偷U盘文件的神器”(写作USBCopyer,读作USBCopier) 项目地址: https://gitcode.…...