Apache Calcite - 基于规则的查询优化
基于规则的查询优化
基于规则的查询优化(Rule-based Query Optimization)是一种通过应用一系列预定义的规则来优化查询计划的技术。这些规则描述了如何转换关系表达式,以提高查询执行的效率。基于规则的优化器并不依赖于统计信息,而是通过模式匹配和规则应用来改进查询计划。
-
规则(Rules): 规则是优化器用来转换关系表达式的基本单位。每条规则定义了一个模式(Pattern)和一个转换(Transformation)。当优化器检测到关系表达式中匹配该模式的部分时,就会应用相应的转换。
-
模式匹配(Pattern Matching): 优化器会遍历关系表达式树,并尝试找到与规则模式匹配的部分。一旦找到匹配的部分,就会应用相应的转换。
-
转换(Transformation): 转换是对匹配模式的关系表达式进行修改的操作。转换后的表达式通常会具有更高的执行效率。
-
优化器(Optimizer): 优化器是应用规则的引擎。Apache Calcite中有多种优化器实现,如HepPlanner(基于规则的优化器)和VolcanoPlanner(基于代价的优化器)。
Calcite中的规则RelOptRule
RelOptRule 是 Apache Calcite 中用于定义查询优化规则的基类。通过继承 RelOptRule,可以创建自定义的优化规则,以便在查询优化过程中应用这些规则。以下是对 RelOptRule 及其常见子类的详细介绍。
- RelOptRule: RelOptRule 是一个抽象类,用于定义查询优化规则。每个规则包含一个模式(Pattern),用于匹配关系表达式树中的特定结构。当优化器检测到关系表达式中匹配该模式的部分时,就会应用相应的转换。
构造函数
- operand:定义规则匹配的模式。
- description:规则的描述,用于调试和日志记录。
protected RelOptRule(RelOptRuleOperand operand, String description)
主要方法
- onMatch(RelOptRuleCall call):当规则的模式匹配成功时调用,用于执行具体的转换逻辑。
- matches(RelOptRuleCall call):检查规则是否适用于当前的匹配上下文,默认实现返回 true。
toString():返回规则的描述信息。
RelOptRule的常用子类简介
- ProjectFilterTransposeRule:ProjectFilterTransposeRule 将 Project 操作下推到 Filter 之后,从而减少不必要的数据传输和处理。
- FilterJoinRule:FilterJoinRule 将 Filter 操作下推到 Join 之前,或者将过滤条件分解并分别应用到连接的两侧。
- JoinCommuteRule:JoinCommuteRule 交换 Join 操作的左右输入,从而可能找到更优的连接顺序。
CoreRules
CoreRules 是 Apache Calcite 提供的一组默认的优化规则集合。这些规则覆盖了常见的查询优化场景,如投影下推、谓词下推、连接重排序等。CoreRules 中的规则大多是通过继承 RelRule 或其子类来实现的。
/** Rule that recognizes an {@link Aggregate}* on top of a {@link Project} and if possible* aggregates through the Project or removes the Project. */public static final AggregateProjectMergeRule AGGREGATE_PROJECT_MERGE =AggregateProjectMergeRule.Config.DEFAULT.toRule();/** Rule that removes constant keys from an {@link Aggregate}. */public static final AggregateProjectPullUpConstantsRuleAGGREGATE_PROJECT_PULL_UP_CONSTANTS =AggregateProjectPullUpConstantsRule.Config.DEFAULT.toRule();/** More general form of {@link #AGGREGATE_PROJECT_PULL_UP_CONSTANTS}* that matches any relational expression. */public static final AggregateProjectPullUpConstantsRuleAGGREGATE_ANY_PULL_UP_CONSTANTS =AggregateProjectPullUpConstantsRule.Config.DEFAULT.withOperandFor(LogicalAggregate.class, RelNode.class).toRule();
HepPlanner
在Apache Calcite中,HepPlanner 是 RelOptPlanner 接口的一个启发式(heuristic)实现。这里的“启发式”具体指的是使用启发式方法来指导查询优化过程,而不是基于全面的成本模型来评估每一个可能的查询计划。启发式方法通常依赖于规则和经验法则(heuristics)来快速找到一个足够好的解决方案,而不是最优解。
启发式方法在计算机科学中通常指的是通过经验法则、直觉或启发式规则来解决问题的方法。这些方法不保证找到最优解,但通常能够在合理的时间内找到一个较好的解决方案。启发式方法在查询优化中尤其重要,因为查询优化问题通常是NP难题,全面搜索所有可能的查询计划是不可行的。
一个基于规则变换的案例
要优化的Sql如下,我们将使用下推规则ProjectFilterTransposeRule来进行优化
"SELECT age FROM your_table WHERE age > 30";
org.apache.calcite.rel.rules.ProjectFilterTransposeRule 规则含义
Rule that pushes a Project past a Filter.
将投影下推到过滤操作之后。这里的“之后”并不是指执行顺序上的“之后”,而是指在查询计划树结构中的位置变化。具体来说,这意味着在查询计划树中,Project 操作会被移动到 Filter 操作的下方(即子节点),从而在逻辑上首先进行投影操作,然后再进行过滤操作。
原查询计划
LogicalProject(a=[$0], b=[$1])LogicalFilter(condition=[=($0, 'b')])LogicalTableScan(table=[[c]])下推后的查询计划
LogicalFilter(condition=[=($0, 'b')])LogicalProject(a=[$0], b=[$1])LogicalTableScan(table=[[c]])Java演示代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.Properties;
import org.apache.calcite.config.Lex;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.plan.hep.HepPlanner;
import org.apache.calcite.plan.hep.HepProgram;
import org.apache.calcite.plan.hep.HepProgramBuilder;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.RelRoot;
import org.apache.calcite.rel.rel2sql.RelToSqlConverter;
import org.apache.calcite.rel.rel2sql.SqlImplementor.Result;
import org.apache.calcite.rel.rules.CoreRules;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.Table;
import org.apache.calcite.schema.impl.AbstractSchema;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.dialect.MysqlSqlDialect;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.pretty.SqlPrettyWriter;
import org.apache.calcite.sql.validate.SqlConformanceEnum;
import org.apache.calcite.tools.FrameworkConfig;
import org.apache.calcite.tools.Frameworks;
import org.apache.calcite.tools.Planner;
import org.junit.Test;/****/
public class OptSqlByRelNode2 {@Testpublic void testSqlToRelNode2() throws Exception{// 1. 设置内存数据库连接Properties info = new Properties();Connection connection = DriverManager.getConnection("jdbc:calcite:", info);CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);// 2. 创建自定义SchemaSchemaPlus rootSchema = calciteConnection.getRootSchema();Schema schema = new AbstractSchema() {};rootSchema.add("MY_SCHEMA", schema);// 3. 添加表到自定义SchemaTable yourTable = new AbstractTable() {@Overridepublic RelDataType getRowType(RelDataTypeFactory typeFactory) {// 如果要动态分析表,那么就自己去创建return typeFactory.builder().add("id", typeFactory.createJavaType(int.class)).add("name", typeFactory.createJavaType(String.class)).add("age", typeFactory.createJavaType(int.class)).build();}};// 3. 添加表到自定义SchemaTable department_table = new AbstractTable() {@Overridepublic RelDataType getRowType(RelDataTypeFactory typeFactory) {// 如果要动态分析表,那么就自己去创建return typeFactory.builder().add("id", typeFactory.createJavaType(int.class)).add("department", typeFactory.createJavaType(String.class)).add("location", typeFactory.createJavaType(String.class)).build();}};rootSchema.getSubSchema("MY_SCHEMA").add("your_table", yourTable);rootSchema.getSubSchema("MY_SCHEMA").add("department_table", department_table);// 4. 配置SQL解析器SqlParser.Config parserConfig = SqlParser.config().withLex(Lex.MYSQL).withConformance(SqlConformanceEnum.MYSQL_5);// 5. 配置框架FrameworkConfig config = Frameworks.newConfigBuilder().parserConfig(parserConfig).defaultSchema(rootSchema.getSubSchema("MY_SCHEMA")) // 使用自定义Schema.build();// 6. 创建Planner实例Planner planner = Frameworks.getPlanner(config);// 7. 解析SQLString sql = "SELECT age FROM your_table WHERE age > 30";
// String sql = "SELECT * FROM your_table where id = 1 and name = 'you_name'";SqlNode sqlNode = planner.parse(sql);// 8. 验证SQLSqlNode validatedSqlNode = planner.validate(sqlNode);// 9. 转换为关系表达式RelRoot relRoot = planner.rel(validatedSqlNode);// 10. 获取RelNodeRelNode rootRelNode = relRoot.rel;// 打印RelNode的信息System.out.println(rootRelNode.explain());// 创建HepProgramHepProgram hepProgram = new HepProgramBuilder()
// .addRuleInstance(CoreRules.FILTER_PROJECT_TRANSPOSE)
// .addRuleInstance(CoreRules.FILTER_INTO_JOIN)
// .addRuleInstance(CoreRules.FILTER_AGGREGATE_TRANSPOSE)
// .addRuleInstance(CoreRules.FILTER_SET_OP_TRANSPOSE).addRuleInstance(CoreRules.PROJECT_FILTER_TRANSPOSE)
// .addRuleInstance(CoreRules.PROJECT_JOIN_TRANSPOSE).build();// 创建HepPlannerHepPlanner hepPlanner = new HepPlanner(hepProgram);// 设置根RelNodehepPlanner.setRoot(rootRelNode);// 进行优化RelNode optimizedRelNode = hepPlanner.findBestExp();// 输出优化后的RelNodeSystem.out.println("优化后的RelNode: \n" + optimizedRelNode.explain());// 10. 使用RelToSqlConverter将优化后的RelNode转换回SQLRelToSqlConverter relToSqlConverter = new RelToSqlConverter(MysqlSqlDialect.DEFAULT);Result result = relToSqlConverter.visitRoot(optimizedRelNode);SqlNode sqlNodeConverted = result.asStatement();// 11. 使用SqlPrettyWriter格式化SQLSqlPrettyWriter writer = new SqlPrettyWriter();String convertedSql = writer.format(sqlNodeConverted);// 输出转换后的SQLSystem.out.println("优化后的SQL: " + convertedSql);// 关闭连接connection.close();}
}
转换后的Sql
SQL: SELECT *
FROM (SELECT "age"FROM "MY_SCHEMA"."your_table") AS "t"
WHERE "age" > 30
变换后的关系表达式
LogicalFilter(condition=[>($0, 30)])LogicalProject(age=[$2])LogicalTableScan(table=[[MY_SCHEMA, your_table]])
总结
使用HepPlanner基于规则对Sql进行优化,最终产生优化后的关系表达式
相关文章:

Apache Calcite - 基于规则的查询优化
基于规则的查询优化 基于规则的查询优化(Rule-based Query Optimization)是一种通过应用一系列预定义的规则来优化查询计划的技术。这些规则描述了如何转换关系表达式,以提高查询执行的效率。基于规则的优化器并不依赖于统计信息,…...

react学习笔记,ReactDOM,react-router-dom
react 学习 1. 下载与安装 下载 npm install -g create-react-app 安装 npx create-react-app xxx 推荐 npm init react-app xxx yarn create react-app xxx 2. 创建 react 元素 indexjs 文件 import React from "react"; import ReactDOM from "react…...

优化UVM环境(八)-整理project_common_pkg文件
书接上回: 优化UVM环境(七)-整理环境,把scoreboard拿出来放在project_common环境里 Prj_cmn_pkg.sv考虑到是后续所有文件的基础,需要引入uvm_pkg并把自身这个pkg import给后续的文件: 这里有3个注意事项&…...

【实战案例】Django框架连接并操作数据库MySQL相关API
本文相关操作基于上次操作基本请求及响应基础之上【实战案例】Django框架基础之上编写第一个Django应用之基本请求和响应 Django框架中默认会连接SQLite数据库,好处是方便无需远程连接,打包项目挪到其他环境安装一下依赖一会就跑起来,但是缺点…...

【其他】无法启动phptudy服务,提示错误2:系统找不到指定的文件
在服务中启动phpstudy服务时,提示“windows 无法启动phpstudy服务 服务(位于本地计算机上) 错误2:系统找不到指定的文件”的错误。导致错误的原因是可执行文件的路径不对,修改成正确的路径就可以了。 下面是错误的路径,会弹出错误窗口&#…...

AI驱动的支持截图或线框图快速生成网页应用的开源项目
Napkins.dev是什么 Napkins.dev是一个创新的开源项目,基于AI技术将用户的截图或线框图快速转换成可运行的网页应用程序。项目背后依托于Meta的Llama 3.1 405B大型语言模型和Llama 3.2 Vision视觉模型,结合Together.ai的推理服务,实现从视觉设…...

es集群索引是黄色
排查 GET /_cat/shards?hindex,shard,prirep,state,unassigned.reason 查询原因 发现node正常 执行重新分配 retry_failedtrue 参数告诉Elasticsearch重试那些因某种原因(如节点故障、资源不足等)而失败的分片分配。这个选项通常用来尝试再次分配那些…...

获取淘宝商品评论的方法分享-调用API接口item_review
在电商领域,商品评论是消费者了解产品、做出购买决策的重要依据。淘宝作为中国最大的电商平台之一,其商品评论系统涵盖了海量的用户反馈数据。为了帮助企业、电商数据分析师、市场研究人员以及普通消费者更高效地获取这些评论数据,淘宝开放平…...

MATLAB人脸考勤系统
MATLAB人脸考勤系统课题介绍 该课题为基于MATLAB平台的人脸识别系统。传统的人脸识别都是直接人头的比对,现实意义不大,没有一定的新意。该课题识别原理为:先采集待识别人员的人脸,进行训练,得到人脸特征值。测试的时…...
Spring篇(事务篇 - 基础介绍)
目录 一、JdbcTemplate(持久化技术) 1. 简介 2. 准备工作 2.1. 引入依赖坐标 2.2. 创建jdbc.properties 2.3. 配置Spring的配置文件 3. 测试 3.1. 在测试类装配 JdbcTemplate 3.2. 测试增删改功能 查询一条数据为实体类对象 查询多条数据为一个…...

qt EventFilter用途详解
一、概述 EventFilter是QObject类的一个事件过滤器,当使用installEventFilter方法为某个对象安装事件过滤器时,该对象的eventFilter函数就会被调用。通过重写eventFilter方法,开发者可以在事件处理过程中进行拦截和处理,实现对事…...
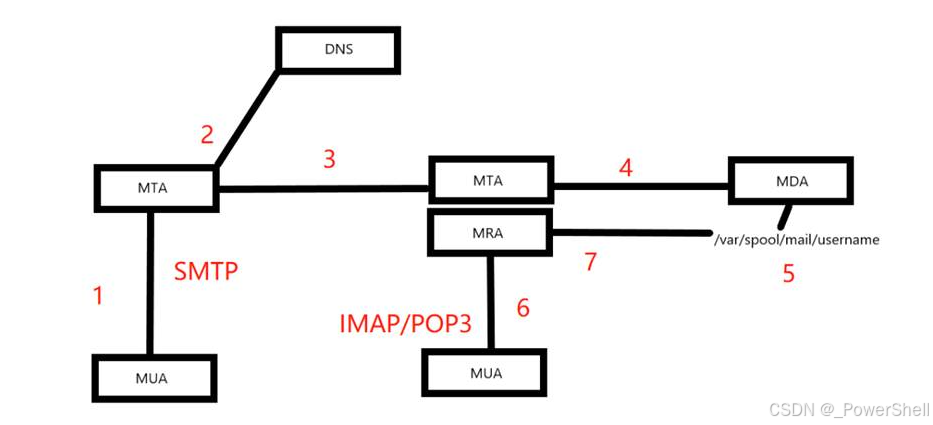
[ 钓鱼实战系列-基础篇-6 ] 一篇文章让你了解邮件服务器机制(SMTP/POP/IMAP)-1
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

wordpress伪静态规则
WordPress 伪静态规则是指将 WordPress 生成的动态 URL 转换为静态 URL 的规则,这样做可以提高网站的搜索引擎优化(SEO)效果,并且使得 URL 更加美观、易于记忆。伪静态规则通常需要在服务器的配置文件中设置,不同的服务器环境配置方法有所不同…...
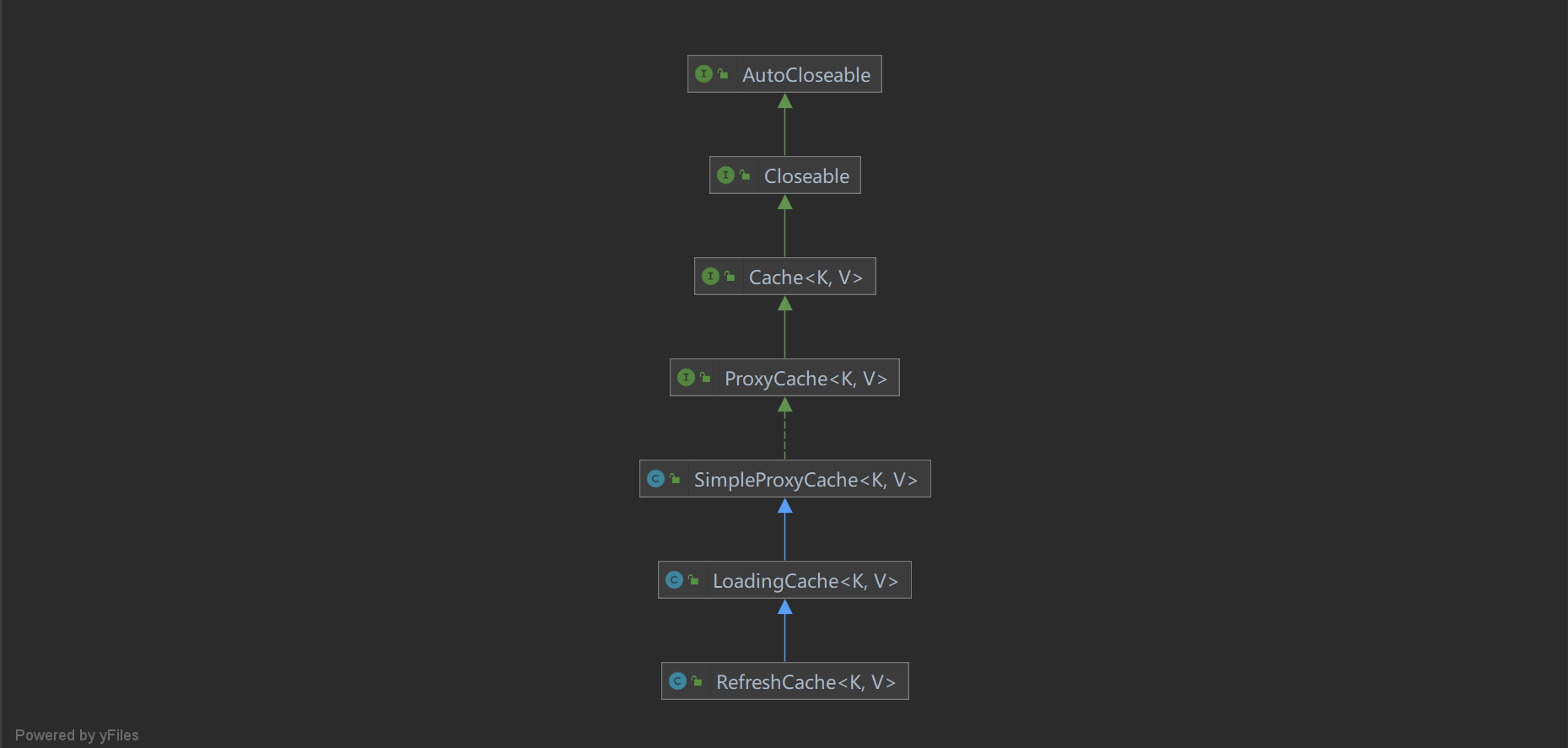
缓存框架JetCache源码解析-缓存定时刷新
作为一个缓存框架,JetCache支持多级缓存,也就是本地缓存和远程缓存,但是不管是使用着两者中的哪一个或者两者都进行使用,缓存的实时性一直都是我们需要考虑的问题,通常我们为了尽可能地保证缓存的实时性,都…...

docker配置mysql8报错 ERROR 2002 (HY000)
通过docker启动的mysql,发现navicat无法连接,后来进入容器内部也是无法连接,产生以下错误 root9f3b90339a14:/var/run/mysqld# mysql -u root -p Enter password: ERROR 2002 (HY000): Cant connect to local MySQL server through socket …...

【Linux】为什么环境变量具有全局性?共享?写时拷贝优化?
环境变量表具有全局性的原因: 环境变量表之所以具有全局性的特征,主要是因为它们是在进程上下文中维护的,并且在大多数操作系统中,当一个进程创建另一个进程(即父进程创建子进程)时,子进程会继承…...

如何在Linux中找到MySQL的安装目录
前言 发布时间:2024-10-22 在日常管理和维护数据库的过程中,了解MySQL的确切安装位置对于执行配置更改、更新或者进行故障排查是非常重要的。本文将向您介绍几种在Linux环境下定位MySQL安装路径的方法。 通过命令行工具快速定位 使用 which 命令 首…...

机器人备件用在哪些领域
机器人备件,作为机器人技术的重要组成部分,被广泛应用于多个领域,以提高生产效率、降低成本、增强产品质量,并推动相关行业的智能化发展。以下是一些主要的应用领域: 制造业: 机器人备件在制造业中的应用最…...

基于单片机优先级的信号状态机设计
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、背景知识二、使用步骤1.定义相应状态和信号列表2.获取最高优先级信号3.通用状态机实现4.灯的控制函数 总结 前言 在嵌入式系统中,设备控制的灵…...

数字电路week3
数字电路学习 九.补充 1.Verilog和fpga verilog是一种描述电路的语言,出现于上世纪80年代 非:~与: &,或: |,异或: ^ fpga:一种可编程逻辑器件 FPGA 由大量的逻辑单元、查找表(LUTs)、触发…...

VisionPro新手避坑指南:从CogPMAlignTool到Blob分析,这10个工具别再乱用了
VisionPro新手避坑指南:10个核心工具的正确打开方式 第一次打开VisionPro的工具栏时,面对数十个名称相似的图标,大多数工程师都会陷入选择困难。更棘手的是,许多工具的参数设置存在微妙的相互影响——一个看似无关的阈值调整可能…...

如何快速入门ROS机器人仿真:WPR系列仿真工具完整指南
如何快速入门ROS机器人仿真:WPR系列仿真工具完整指南 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 想要在虚拟环境中快速学习ROS机器人开发吗?wpr_simulation项目为你提供了一个完美的起点&…...
)
黑群晖/白群晖通用!Docker部署DDNS-Go搞定腾讯云域名解析(保姆级避坑指南)
群晖与腾讯云域名解析终极方案:Docker化DDNS-Go实战指南 当你在群晖NAS上尝试配置腾讯云DDNS服务时,是否遇到过"认证失败"的困扰?这个问题尤其困扰黑群晖用户,但即便是白群晖用户也难免遭遇兼容性难题。本文将带你探索…...

9大网盘下载限速破解终极指南:LinkSwift让你告别龟速下载烦恼
9大网盘下载限速破解终极指南:LinkSwift让你告别龟速下载烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...
)
【Matlab】MATLAB教程:Simulink与MATLAB交互(MATLAB函数模块案例+混合编程仿真)
MATLAB教程:Simulink与MATLAB交互(MATLAB函数模块案例+混合编程仿真) 本教程适配MATLAB R2020a及以上版本,聚焦Simulink与MATLAB交互核心技能,以MATLAB函数模块为核心案例,详解混合编程仿真的全流程,无需深厚编程基础,纯实操导向、案例可直接复刻,适配高校课程设计、…...

《机密计算破局政务金融、截图工具漏洞泄露NTLM哈希、智能体仿冒日增200+:AI安全的三场“攻防战”》
一、全链路机密计算破局:政务/金融敏感数据进入“可信推理”时代当前,大模型落地过程中面临的核心矛盾在于:越是高价值的专业技术领域,其训练数据和实时推理数据的安全级别就越高。在政务场景中,政府规划、财政数据、内…...

自动驾驶汽车保险七大议题:从技术视角看责任转移与系统设计
1. 自动驾驶汽车保险的七个核心议题:从工程师视角看技术与责任的碰撞作为一名在汽车电子和嵌入式系统领域摸爬滚打了十几年的工程师,我亲眼见证了从ABS到自适应巡航,再到今天各种L2辅助驾驶的演进。每当和圈内朋友聊起全自动驾驶,…...

如何用DownKyi实现B站视频自由:5个实用场景与解决方案
如何用DownKyi实现B站视频自由:5个实用场景与解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...

JIT只适合大厂?精益生产中小厂JIT落地技巧,不用大投入也能降库存!
提到精益生产JIT准时化生产,很多中小厂管理者都会陷入一个固有认知:JIT是大厂的专属工具,只有资金充足、供应链完善、管理规范的大厂,才能推行JIT;中小厂规模小、资金有限、供应链不稳定,推行JIT不仅需要大…...

GPU加速时序驱动布局优化技术解析
1. 时序驱动布局优化:GPU加速的创新实践 在超大规模集成电路(VLSI)物理设计中,时序驱动布局(Timing-Driven Placement)一直是决定芯片性能的关键环节。随着工艺节点不断缩小,设计复杂度呈指数级…...