缓存框架JetCache源码解析-缓存定时刷新
作为一个缓存框架,JetCache支持多级缓存,也就是本地缓存和远程缓存,但是不管是使用着两者中的哪一个或者两者都进行使用,缓存的实时性一直都是我们需要考虑的问题,通常我们为了尽可能地保证缓存的实时性,都会去采用一些策略,比如更新数据库时同时删除缓存,又或者是使用缓存双删等策略,而在JetCache中,它还支持定时地去刷新缓存,又进一步地能够保证缓存的实时性
功能使用
编程式
QuickConfig idQc = QuickConfig.newBuilder(":user:cache:id:").cacheType(CacheType.BOTH).expire(Duration.ofHours(2)).refreshPolicy(RefreshPolicy.newPolicy(1,TimeUnit.HOURS)).syncLocal(true).build();
idUserCache = cacheManager.getOrCreateCache(idQc);在编程式的方式中,通过refreshPolicy属性配置,指定缓存刷新的时间间隔,比如上面定义的是每隔1小时刷新一次缓存
声明式
@Cached(name = ":user:cache:id:", cacheType = CacheType.BOTH, key = "#userId", cacheNullValue = true)
@CacheRefresh(refresh = 60, timeUnit = TimeUnit.MINUTES)
public User findById(Long userId) {return userMapper.findById(userId);
}声明式的方式JetCache中提供的是CacheRefresh注解,在该注解中的refresh属性中可以配置缓存的刷新时间
源码解析
RefreshCache的继承体系
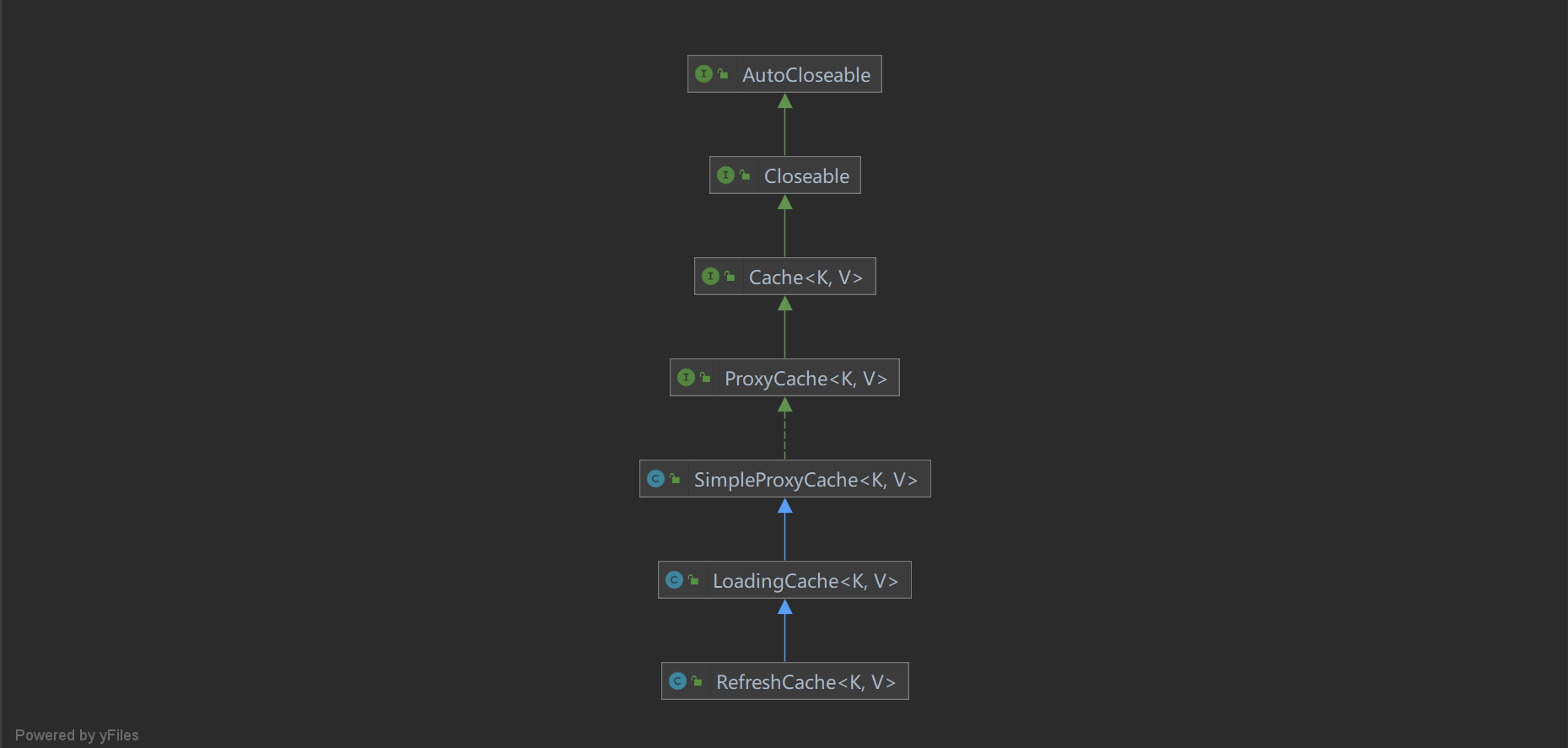
- Cache:Cache实例的顶级接口,定义了Cache实例常用的一些api,例如get,put等等
- ProxyCache:继承于Cache接口,通过名字可以知道ProxyCache就是用于代理某一个Cache实例的,而它也提供了一个getTargetCache方法,该方法可以返回这个被代理的Cache实例
- SimpleProxyCache:它是ProxyCache接口的一个实现,里面有一个Cache实例的成员变量,这个Cache实例其实就是被代理的Cache实例,而SimpleProxyCache中的方法也很简单,都是实现Cache接口以及ProxyCache接口的方法,在实现的方法中调用成员变量Cache实例的同名方法而已,其实就是一个代理模式
- LoadingCache:通过名字可以知道这个Cache具有加载数据的功能,所谓的加载数据就是从某一处数据源(比如数据库,es等)进行数据加载然后再放到整个被代理的Cache实例中
- RefreshCache:缓存定时刷新的核心实现,在里面实现了通过定时器去进行缓存的刷新
缓存定时刷新任务RefreshTask
/*** 缓存刷新任务,以key为维度,每一个key对应一个RefreshTask* 这个任务主要做的事:以key为维度,每隔一段时间(配置的refreshMillis)执行一次,通过loader加载出数据更新到缓存中* 如果使用的是多级缓存,那么就会先loader数据到远程缓存中,然后再更新到本地缓存中*/
class RefreshTask implements Runnable {private Object taskId;/*** 目标刷新的key*/private K key;/*** loader*/private CacheLoader<K, V> loader;/*** 上一次访问时间*/private long lastAccessTime;private ScheduledFuture future;RefreshTask(Object taskId, K key, CacheLoader<K, V> loader) {this.taskId = taskId;this.key = key;this.loader = loader;}private void cancel() {logger.debug("cancel refresh: {}", key);future.cancel(false);taskMap.remove(taskId);}/*** 通过loader加载出数据,如果有必要则还需把加载出的数据放到Cache中*/private void load() throws Throwable {CacheLoader<K, V> l = loader == null ? config.getLoader() : loader;if (l != null) {// 获取到一个ProxyLoader,这个ProxyLoader会去对loader进行代理,在原来loader加载数据的功能上增加了其他功能l = CacheUtil.createProxyLoader(cache, l, eventConsumer);// 加载数据V v = l.load(key);// 条件成立:说明加载出来的数据需要更新到Cache中if (needUpdate(v, l)) {// 假如这个被代理的cache是一个多级缓存,那么此时本地缓存和远程缓存都会被更新到了cache.PUT(key, v);}}}/*** 该方法的作用是:如果目标key已经到达了缓存刷新时间则会使用loader去进行加载这个key的数据,加载出来的数据会放入到缓存中,* 在使用loader加载数据的过程中,会以key为维度去加一把分布式锁,目的就是为了防止多个机器节点同时进行loader,因为只需要一台机器实例去loader数据到远程缓存即可* 如果抢到分布式锁成功,那么就会把加载到的数据放到Cache缓存实例中,如果抢不到分布式锁,则说明已经有其他机器loader数据到远程缓存中了,这时候就不用loader数据了,* 但是还需要注意的是如果这时候使用的是多级缓存,则还需要更新本地缓存,所以就会从远程缓存中获取到数据然后更新本地缓存** @param concreteCache 远程缓存Cache实例* @param currentTime 当前时间,用于判断key是否到达刷新时间了*/private void externalLoad(final Cache concreteCache, final long currentTime) throws Throwable {byte[] newKey = ((AbstractExternalCache) concreteCache).buildKey(key);byte[] lockKey = combine(newKey, LOCK_KEY_SUFFIX);// 获取到刷新缓存时加锁的过期时间long loadTimeOut = RefreshCache.this.config.getRefreshPolicy().getRefreshLockTimeoutMillis();// 刷新缓存的时间间隔long refreshMillis = config.getRefreshPolicy().getRefreshMillis();byte[] timestampKey = combine(newKey, TIMESTAMP_KEY_SUFFIX);// 从缓存中获取到这个key上一次的刷新时间CacheGetResult refreshTimeResult = concreteCache.GET(timestampKey);// 是否应该对这个key进行刷新boolean shouldLoad = false;// 如果这个key存在,并且这个key已经到达了下一次的刷新时间,那么就需要对它进行刷新if (refreshTimeResult.isSuccess()) {shouldLoad = currentTime >= Long.parseLong(refreshTimeResult.getValue().toString()) + refreshMillis;}// 如果这个key并不存在,那么也应该对它进行刷新else if (refreshTimeResult.getResultCode() == CacheResultCode.NOT_EXISTS) {shouldLoad = true;}// 条件成立:不需要对这个key进行刷新if (!shouldLoad) {// 如果是多级缓存,那么此时从最后一级缓存中获取数据刷新到前面层级的缓存中if (multiLevelCache) {refreshUpperCaches(key);}return;}// 抢到分布式锁之后会去执行这个runnable// runnable做的事情:通过loader加载出数据,如果有必要则还需把加载出的数据放到Cache实例中Runnable r = () -> {try {// 通过loader加载出数据,如果有必要则还需把加载出的数据放到缓存中load();// 更新这个key最近的一次刷新时间concreteCache.put(timestampKey, String.valueOf(System.currentTimeMillis()));} catch (Throwable e) {throw new CacheException("refresh error", e);}};// 尝试去获取锁,如果获取到锁就执行rboolean lockSuccess = concreteCache.tryLockAndRun(lockKey, loadTimeOut, TimeUnit.MILLISECONDS, r);// 获取锁失败,说明有其他线程获取到锁了,也就说明其他线程正在加载数据到远程缓存中if (!lockSuccess && multiLevelCache) {// 如果被代理的Cache实例是多级缓存的话还需要从远程缓存中获取到数据,然后把数据刷新到上层的本地缓存// 延迟执行,因为此时其他线程还在加载数据到远程缓存中JetCacheExecutor.heavyIOExecutor().schedule(() -> refreshUpperCaches(key), (long) (0.2 * refreshMillis), TimeUnit.MILLISECONDS);}}/*** 从最后一级缓存中获取数据刷新到前面层级的缓存中** @param key key*/private void refreshUpperCaches(K key) {MultiLevelCache<K, V> targetCache = (MultiLevelCache<K, V>) getTargetCache();Cache[] caches = targetCache.caches();int len = caches.length;// 从最后一级缓存中获取到这个key的缓存数据CacheGetResult cacheGetResult = caches[len - 1].GET(key);if (!cacheGetResult.isSuccess()) {return;}// 刷新前面层级的缓存for (int i = 0; i < len - 1; i++) {caches[i].PUT(key, cacheGetResult.getValue());}}@Overridepublic void run() {try {if (config.getRefreshPolicy() == null || (loader == null && !hasLoader())) {cancel();return;}long now = System.currentTimeMillis();// 获取到停止缓存刷新的时间间隔long stopRefreshAfterLastAccessMillis = config.getRefreshPolicy().getStopRefreshAfterLastAccessMillis();if (stopRefreshAfterLastAccessMillis > 0) {// 条件成立:上一次访问这个key的时间 + 停止缓存刷新的时间间隔 < 当前时间// 也就是说这个key距离上一次访问已经有一段时间了,这时候可能意味着这个key并不是一个频繁被访问的key,所以此时可以把它的缓存刷新定时任务取消掉if (lastAccessTime + stopRefreshAfterLastAccessMillis < now) {logger.debug("cancel refresh: {}", key);// 取消这个key的缓存刷新定时任务cancel();return;}}logger.debug("refresh key: {}", key);// 获取到被代理的Cache实例,如果被代理的Cache实例是多级缓存的Cache实例,那么就返回最后一级缓存的Cache实例Cache concreteCache = concreteCache();// 如果这个Cache实例是远程缓存实例,那么就执行externalLoadif (concreteCache instanceof AbstractExternalCache) {// 在externalLoad方法中会使用loader加载数据到远程缓存中externalLoad(concreteCache, now);}// 如果这个Cache实例不是远程缓存实例,那么就直接load数据到本地缓存中else {load();}} catch (Throwable e) {logger.error("refresh error: key=" + key, e);}}
}RefreshTask实现了Runnable接口,也就是说它是运行在子线程中的,而每一个RefreshTask任务都只会服务于一个key,也就是说当我们访问了某一个key的数据,那么这个key就会创建出对应的RefreshTask去对它进行定时的刷新
(1)run
public void run() {try {if (config.getRefreshPolicy() == null || (loader == null && !hasLoader())) {cancel();return;}long now = System.currentTimeMillis();// 获取到停止缓存刷新的时间间隔long stopRefreshAfterLastAccessMillis = config.getRefreshPolicy().getStopRefreshAfterLastAccessMillis();if (stopRefreshAfterLastAccessMillis > 0) {// 条件成立:上一次访问这个key的时间 + 停止缓存刷新的时间间隔 < 当前时间// 也就是说这个key距离上一次访问已经有一段时间了,这时候可能意味着这个key并不是一个频繁被访问的key,所以此时可以把它的缓存刷新定时任务取消掉if (lastAccessTime + stopRefreshAfterLastAccessMillis < now) {logger.debug("cancel refresh: {}", key);// 取消这个key的缓存刷新定时任务cancel();return;}}logger.debug("refresh key: {}", key);// 获取到被代理的Cache实例,如果被代理的Cache实例是多级缓存的Cache实例,那么就返回最后一级缓存的Cache实例Cache concreteCache = concreteCache();// 如果这个Cache实例是远程缓存实例,那么就执行externalLoadif (concreteCache instanceof AbstractExternalCache) {// 在externalLoad方法中会使用loader加载数据到远程缓存中externalLoad(concreteCache, now);}// 如果这个Cache实例不是远程缓存实例,那么就直接load数据到本地缓存中else {load();}} catch (Throwable e) {logger.error("refresh error: key=" + key, e);}
}首先会去获取stopRefreshAfterLastAccessMillis这个配置值,这个配置值表示停止缓存刷新的时间间隔,也就是说如果一个key的上一次访问时间距离当前时间已经超过了这个时间值了,那么就可以停止掉这个key的缓存刷新定时任务了,接着就会去通过loader加载器去加载数据了,但是加载的时候需要去判断当前被代理的Cache是否有使用远程缓存,如果没有使用远程缓存就会执行load方法
/*** 通过loader加载出数据,如果有必要则还需把加载出的数据放到Cache中*/
private void load() throws Throwable {CacheLoader<K, V> l = loader == null ? config.getLoader() : loader;if (l != null) {// 获取到一个ProxyLoader,这个ProxyLoader会去对loader进行代理,在原来loader加载数据的功能上增加了其他功能l = CacheUtil.createProxyLoader(cache, l, eventConsumer);// 加载数据V v = l.load(key);// 条件成立:说明加载出来的数据需要更新到Cache中if (needUpdate(v, l)) {// 假如这个被代理的cache是一个多级缓存,那么此时本地缓存和远程缓存都会被更新到了cache.PUT(key, v);}}
}protected boolean needUpdate(V loadedValue, CacheLoader<K, V> loader) {if (loadedValue == null && !config.isCacheNullValue()) {return false;}// 是否禁止缓存的更新,默认不禁止if (loader.vetoCacheUpdate()) {return false;}return true;
}load方法很简单,其实就是调用loader的load方法去加载数据,然后再把加载数据的数据交给needUpdate方法,在needUpdate方法中会判断是否设置缓存null值的配置,如果加载出来的数据为null,并且设置了允许缓存null值,那么就会进一步再判断loader的vetoCacheUpdate方法,该方法表示加载出来的时候是否允许更新到缓存中,默认为false,表示允许更新到缓存中,最后再把加载的数据放到被代理的Cache实例中
(2)externalLoad
/*** 该方法的作用是:如果目标key已经到达了缓存刷新时间则会使用loader去进行加载这个key的数据,加载出来的数据会放入到缓存中,* 在使用loader加载数据的过程中,会以key为维度去加一把分布式锁,目的就是为了防止多个机器节点同时进行loader,因为只需要一台机器实例去loader数据到远程缓存即可* 如果抢到分布式锁成功,那么就会把加载到的数据放到Cache缓存实例中,如果抢不到分布式锁,则说明已经有其他机器loader数据到远程缓存中了,这时候就不用loader数据了,* 但是还需要注意的是如果这时候使用的是多级缓存,则还需要更新本地缓存,所以就会从远程缓存中获取到数据然后更新本地缓存** @param concreteCache 远程缓存Cache实例* @param currentTime 当前时间,用于判断key是否到达刷新时间了*/
private void externalLoad(final Cache concreteCache, final long currentTime) throws Throwable {byte[] newKey = ((AbstractExternalCache) concreteCache).buildKey(key);byte[] lockKey = combine(newKey, LOCK_KEY_SUFFIX);// 获取到刷新缓存时加锁的过期时间long loadTimeOut = RefreshCache.this.config.getRefreshPolicy().getRefreshLockTimeoutMillis();// 刷新缓存的时间间隔long refreshMillis = config.getRefreshPolicy().getRefreshMillis();byte[] timestampKey = combine(newKey, TIMESTAMP_KEY_SUFFIX);// 从缓存中获取到这个key上一次的刷新时间CacheGetResult refreshTimeResult = concreteCache.GET(timestampKey);// 是否应该对这个key进行刷新boolean shouldLoad = false;// 如果这个key存在,并且这个key已经到达了下一次的刷新时间,那么就需要对它进行刷新if (refreshTimeResult.isSuccess()) {shouldLoad = currentTime >= Long.parseLong(refreshTimeResult.getValue().toString()) + refreshMillis;}// 如果这个key并不存在,那么也应该对它进行刷新else if (refreshTimeResult.getResultCode() == CacheResultCode.NOT_EXISTS) {shouldLoad = true;}// 条件成立:不需要对这个key进行刷新if (!shouldLoad) {// 如果是多级缓存,那么此时从最后一级缓存中获取数据刷新到前面层级的缓存中if (multiLevelCache) {refreshUpperCaches(key);}return;}// 抢到分布式锁之后会去执行这个runnable// runnable做的事情:通过loader加载出数据,如果有必要则还需把加载出的数据放到Cache实例中Runnable r = () -> {try {// 通过loader加载出数据,如果有必要则还需把加载出的数据放到缓存中load();// 更新这个key最近的一次刷新时间concreteCache.put(timestampKey, String.valueOf(System.currentTimeMillis()));} catch (Throwable e) {throw new CacheException("refresh error", e);}};// 尝试去获取锁,如果获取到锁就执行rboolean lockSuccess = concreteCache.tryLockAndRun(lockKey, loadTimeOut, TimeUnit.MILLISECONDS, r);// 获取锁失败,说明有其他线程获取到锁了,也就说明其他线程正在加载数据到远程缓存中if (!lockSuccess && multiLevelCache) {// 如果被代理的Cache实例是多级缓存的话还需要从远程缓存中获取到数据,然后把数据刷新到上层的本地缓存// 延迟执行,因为此时其他线程还在加载数据到远程缓存中JetCacheExecutor.heavyIOExecutor().schedule(() -> refreshUpperCaches(key), (long) (0.2 * refreshMillis), TimeUnit.MILLISECONDS);}
}当使用了远程缓存时,就会执行externalLoad方法去加载数据,那么为什么使用了远程缓存之后就需要单独使用externalLoad方法去加载而不是load方法呢?原因就是我们部署的服务如果是有多个节点的话,对于每一个节点来说,相同的key它们都会去起一个RefreshTask子线程去从数据库中加载数据然后put到远程缓存中,但是这个操作需要每一个节点都执行吗?显然不需要,只需要其中一个节点把数据库的数据加载到远程缓存中,然后其他节点在这个过程中阻塞等待缓存结果即可
首先会判断这个key是否到达了刷新时间了,如果还没到达刷新时间,那么就把远程缓存的数据刷新到上层缓存(通常是本地缓存)即可,反之如果key到达了刷新时间了,那么就会去尝试获取锁(因为上面也说到了,只需要一个节点执行就行了),如果获取锁成功了,那么就执行load方法从数据库中加载数据到被代理的Cache实例中(如果这个被代理的Cache实例是一个多级缓存,那么它的本地缓存和远程缓存都会被刷新了),如果没有抢到锁,说明已经有其他节点抢到锁去加载数据了,如果这时候是多级缓存,那么此时就会延迟五分之一的刷新时间再去从远程缓存刷新数据到本地缓存中,那么为什么要延迟执行呢?这是因为如果抢不到锁就立刻去从远程缓存获取数据的话,这时候加载数据的节点可能还没有加载完成,也就是说远程缓存这时候还是旧的数据,所以JetCache这里就适当地做了一下延迟,但是这样还会导致另一个问题,那就是这个延迟不就会导致节点间本地缓存不一致了吗?单单从这个缓存定时刷新机制来看是会导致这个问题的,但是JetCache为了保证多节点间的本地缓存尽可能一致性,还有一个缓存更新通知机制作为兜底,有了这个缓存更新通知机制,上述的问题也就能够解决了
RefreshTask任务的添加
上面讲了整个RefreshTask任务的执行流程,那么它是在那里被添加的呢?
private ConcurrentHashMap<Object, RefreshTask> taskMap = new ConcurrentHashMap<>();在RefreshCache中有一个map,key可以理解为就是key值,value存放的这个key对应的RefreshTask任务
@Override
public V get(K key) throws CacheInvokeException {// 如果配置缓存刷新策略,并且也有设置了对应的loaderif (config.getRefreshPolicy() != null && hasLoader()) {// 给这个key添加一个缓存刷新的定时任务addOrUpdateRefreshTask(key, null);}return super.get(key);
}@Override
public Map<K, V> getAll(Set<? extends K> keys) throws CacheInvokeException {// 如果配置缓存刷新策略,并且也有设置了对应的loaderif (config.getRefreshPolicy() != null && hasLoader()) {// 给每一个key都添加一个缓存刷新的定时任务for (K key : keys) {addOrUpdateRefreshTask(key, null);}}return super.getAll(keys);
}而在RefreshCache中,会去重写get和getAll这个两个方法,当我们每次去访问一个key对应的缓存数据的时候,如果这个key在taskMap中没有对应的RefreshTask,那么就会调用addOrUpdateRefreshTask方法创建一个
/*** 给指定的key添加一个缓存刷新定时任务RefreshTask,如果这个key已经存在对应的RefreshTask,那么就更新一下这个RefreshTask的访问时间* @param key key* @param loader loader*/
protected void addOrUpdateRefreshTask(K key, CacheLoader<K, V> loader) {// 获取配置的缓存刷新策略RefreshPolicy refreshPolicy = config.getRefreshPolicy();// 如果没有配置缓存刷新策略,那么直接returnif (refreshPolicy == null) {return;}// 获取缓存刷新的时间间隔long refreshMillis = refreshPolicy.getRefreshMillis();if (refreshMillis > 0) {// 根据key获取到对应的taskIdObject taskId = getTaskId(key);// 根据taskId从taskMap中获取一个缓存刷新任务RefreshTask,如果taskMap中没有则创建一个RefreshTask refreshTask = taskMap.computeIfAbsent(taskId, tid -> {logger.debug("add refresh task. interval={}, key={}", refreshMillis, key);// 创建一个RefreshTaskRefreshTask task = new RefreshTask(taskId, key, loader);task.lastAccessTime = System.currentTimeMillis();ScheduledFuture<?> future = JetCacheExecutor.heavyIOExecutor().scheduleWithFixedDelay(task, refreshMillis, refreshMillis, TimeUnit.MILLISECONDS);task.future = future;return task;});// 更新这个key的访问时间为当前的最新时间refreshTask.lastAccessTime = System.currentTimeMillis();}
}如果这个key在taskMap中已经存在对应的RefreshTask了,那么就取出这个RefreshTask,更新一下它的lastAccessTime即可,在执行这个RefreshTask任务的时候,如果配置了stopRefreshAfterLastAccessMillis的话,就会通过去比较lastAccessTime来决定是否还需要定时更新这个key,如果不需要,则会把这个RefreshTask任务取消掉,然后再从taskMap移除
总结
当我们去访问每一个key的时候,JetCache都会对这个key生成一个RefreshTask任务,然后会把这个RefreshTask任务交给定时任务调度器。在执行RefreshTask任务的过程中,主要就是分为两种情况,一种是当前使用了远程缓存,一种是没有使用远程缓存,如果使用了远程缓存,那么此时会先去获取锁,只有获取锁成功了,才会去从数据库中加载数据然后刷新到远程缓存中,如果没有抢到锁,但是又使用了多级缓存(本地缓存+远程缓存),那么这时候就会延迟一段时间才会去把远程缓存的时候刷新到本地缓存,延迟的原因是因为抢到锁的节点这时候可能还没有完成数据的加载到远程缓存中,而正是因为这个延迟,就会有可能导致多节点间本地缓存数据不一致的情况,针对这种情况,JetCache则是通过缓存更新通知机制去进行兜底
相关文章:
缓存框架JetCache源码解析-缓存定时刷新
作为一个缓存框架,JetCache支持多级缓存,也就是本地缓存和远程缓存,但是不管是使用着两者中的哪一个或者两者都进行使用,缓存的实时性一直都是我们需要考虑的问题,通常我们为了尽可能地保证缓存的实时性,都…...

docker配置mysql8报错 ERROR 2002 (HY000)
通过docker启动的mysql,发现navicat无法连接,后来进入容器内部也是无法连接,产生以下错误 root9f3b90339a14:/var/run/mysqld# mysql -u root -p Enter password: ERROR 2002 (HY000): Cant connect to local MySQL server through socket …...

【Linux】为什么环境变量具有全局性?共享?写时拷贝优化?
环境变量表具有全局性的原因: 环境变量表之所以具有全局性的特征,主要是因为它们是在进程上下文中维护的,并且在大多数操作系统中,当一个进程创建另一个进程(即父进程创建子进程)时,子进程会继承…...

如何在Linux中找到MySQL的安装目录
前言 发布时间:2024-10-22 在日常管理和维护数据库的过程中,了解MySQL的确切安装位置对于执行配置更改、更新或者进行故障排查是非常重要的。本文将向您介绍几种在Linux环境下定位MySQL安装路径的方法。 通过命令行工具快速定位 使用 which 命令 首…...

机器人备件用在哪些领域
机器人备件,作为机器人技术的重要组成部分,被广泛应用于多个领域,以提高生产效率、降低成本、增强产品质量,并推动相关行业的智能化发展。以下是一些主要的应用领域: 制造业: 机器人备件在制造业中的应用最…...

基于单片机优先级的信号状态机设计
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、背景知识二、使用步骤1.定义相应状态和信号列表2.获取最高优先级信号3.通用状态机实现4.灯的控制函数 总结 前言 在嵌入式系统中,设备控制的灵…...

数字电路week3
数字电路学习 九.补充 1.Verilog和fpga verilog是一种描述电路的语言,出现于上世纪80年代 非:~与: &,或: |,异或: ^ fpga:一种可编程逻辑器件 FPGA 由大量的逻辑单元、查找表(LUTs)、触发…...

如何在 Linux 中对 USB 驱动器进行分区
如何在 Linux 中对 USB 驱动器进行分区 一、说明 为了在 Linux 上访问 USB 驱动器,它需要有一个或多个分区。由于 USB 驱动器通常相对较小,仅用于临时存储或轻松传输文件,因此绝大多数用户会选择只配置一个跨越整个 USB 磁盘的分区。但是&a…...

【STM32+HAL】STM32CubeMX学习目录
一、基础配置篇 【STM32HAL】微秒级延时函数汇总-CSDN博客 【STM32HAL】CUBEMX初始化配置 【STM32HAL】定时器功能小记-CSDN博客 【STM32HAL】PWM呼吸灯实现 【STM32HAL】DACDMA输出波形实现-CSDN博客 【STM32HAL】ADCDMA采集(单通道多通道)-CSDN博客 【STM32HAL】三重A…...

PPT自动化:Python如何修改PPT文字和样式!
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 文章内容 📒📝 使用 Python 修改 PPT 文本内容📝 遍历所有幻灯片和文本框📝 设置和修改文本样式📝 复制和保留文本样式⚓️ 相关链接 ⚓️📖 介绍 📖 在日常工作中,PPT 的文字内容和样式修改似乎是一项永无止境的…...

4:Java的介绍与基础4:for语句
4.1for循环 for循环也是一个非常重要的东西,再代码中是一个循环的作用,在python的文章中也介绍过了for循环的使用方法,其实在Java中也是一样的逻辑,但是有着不一样的表达,现在我们来讲一下关于for循环的东西。 因为循…...

R语言机器学习算法实战系列(十二)线性判别分析分类算法 (Linear Discriminant Analysis)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍LDA的原理LDA的步骤教程下载数据加载R包导入数据数据预处理数据描述数据切割构建模型预测测试数据评估模型模型准确性混淆矩阵模型评估指标ROC CurvePRC Curve保存模型总结优点:缺…...
)
[LeetCode] 50. Pow(x, n)
题目描述: 实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn )。 示例 1: 输入:x 2.00000, n 10 输出:1024.00000示例 2: 输入:x 2.10000, n 3 输出…...
)
Vue学习笔记(七、事件修饰符 .stop .capture .self .once .prevent)
先看一段基本的代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><title>VueBaseCode</title><script src"./lib/vue.js"></script><style>.inner {width:…...

web网站搭建(静态)
准备工作: 关闭防火墙: [rootlocalhost ~]# systemctl disable --now firewalld 修改enforce为permissive [rootlocalhost ~]# setenforce 0 [rootlocalhost ~]# geten getenforce getent [rootlocalhost ~]# getenforce Permissive 重启服务 [rootloca…...

高效特征选择策略:提升Python机器学习模型性能的方法
高效特征选择策略:提升Python机器学习模型性能的方法 目录 🔍 特征选择的重要性📊 相关性分析🔄 递归特征消除 (RFE)🌳 基于模型的特征选择 1. 🔍 特征选择的重要性 特征选择在机器学习中至关重要&#…...

2024年TI杯E题-三子棋游戏装置方案分享-jdk123团队-第四弹 第一题
#1024程序员节|征文# 往期回顾 前期准备 摄像头bug解决 手搓机械臂 视觉模块的封装 第一问: 需要将一颗黑棋,放入棋盘中的五号位置。 理想思路:依据摄像头,依据机械臂及其传感器。建立机械臂的逆运动学方程。然后完…...

优化多表联表查询的常见方法归纳
目录 一、使用mybatis的嵌套查询 二、添加表冗余字段,减少联表查询需求 三、分表预处理,前端再匹配 一、使用mybatis的嵌套查询 【场景说明】 前端需要展示一张列表,其中的字段来源于多张表,如何进行查询优化? 【…...

Java毕业设计 基于SpringBoot发卡平台
Java毕业设计 基于SpringBoot发卡平台 这篇博文将介绍一个基于SpringBoot发卡平台,适合用于Java毕业设计。 功能介绍 首页 图片轮播 商品介绍 商品详情 提交订单 文章教程 文章详情 查询订单 查看订单卡密 客服 后台管理 登录 个人信息 修改密码 管…...

VRoid Studio 介绍 3D 模型编辑器
VRoid Studio 是由日本公司 pixiv 开发的一款免费 3D 模型创建软件,专门设计用于轻松制作 3D 虚拟角色。它的主要特点是用户友好,允许没有 3D 建模经验的用户创建高质量的 3D 人物角色,尤其是针对虚拟主播(Vtuber)、动…...
)
Docker构建速度太慢?试试替换Debian基础镜像的APT源为阿里云(附多版本Dockerfile写法)
加速Docker构建:Debian基础镜像APT源优化全指南 每次等待Docker镜像构建完成时,看着缓慢下载的进度条,是不是感觉时间仿佛被拉长了?特别是在国内网络环境下,从官方Debian源拉取软件包的速度简直让人抓狂。我曾经的一个…...

终极QMC音频解密方案:qmc-decoder如何3分钟转换100首加密音乐
终极QMC音频解密方案:qmc-decoder如何3分钟转换100首加密音乐 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 在数字音乐版权保护的浪潮中,QQ音乐QM…...

3大核心技术解析:猫抓cat-catch如何实现浏览器媒体资源精准捕获
3大核心技术解析:猫抓cat-catch如何实现浏览器媒体资源精准捕获 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch是一款专为技术爱好者和开发者设计的浏览器扩展工具…...

如何用SlopeCraft实现Minecraft地图艺术创作:5个实用技巧
如何用SlopeCraft实现Minecraft地图艺术创作:5个实用技巧 【免费下载链接】SlopeCraft Map Pixel Art Generator for Minecraft 项目地址: https://gitcode.com/gh_mirrors/sl/SlopeCraft 在Minecraft的方块世界中,将现实图像转化为立体地形艺术曾…...

比迪丽LoRA模型Ubuntu部署教程:3步完成环境配置与启动
比迪丽LoRA模型Ubuntu部署教程:3步完成环境配置与启动 想在自己的Ubuntu服务器上体验比迪丽LoRA模型,生成风格独特的AI图像,但被复杂的部署步骤劝退?别担心,这篇教程就是为你准备的。我们绕开那些繁琐的源码编译和环境…...

搞懂 SAP Fiori 中的 RFC 连接:把后端系统、系统别名与 Launchpad 运行链路一次讲透
在很多 SAP Fiori 项目里,团队把注意力都放在 SAPUI5、OData、Fiori Elements、语义对象导航这些能力上,却常常在集成经典应用时踩坑。真正到了项目上线阶段,用户不会关心应用是 SAPUI5、Web Dynpro ABAP,还是 SAP GUI for HTML 实现的,他们只会问一句:为什么在 SAP Fior…...

3大突破!GenUI重构Flutter界面开发范式
3大突破!GenUI重构Flutter界面开发范式 【免费下载链接】genui 项目地址: https://gitcode.com/gh_mirrors/genui1/genui GenUI是一个革命性的Flutter库,它通过AI驱动的动态界面生成技术,彻底改变了传统UI开发流程。作为连接自然语言…...

别再只盯着YOLOv5了!聊聊FPN、PANet这些‘特征融合’老将如何帮你搞定小目标检测
小目标检测实战:FPN与PANet如何突破YOLO系列的性能瓶颈 在工业质检项目中,我们团队曾遇到一个典型问题:使用YOLOv5s模型检测电路板元件时,虽然大尺寸的电容电阻识别准确率超过95%,但0402封装的微型贴片元件(…...
)
Vue3实战:5分钟搞定全局WebSocket封装(含心跳检测与断线重连)
Vue3全局WebSocket封装实战:心跳检测与断线重连的最佳实践 WebSocket在现代Web应用中扮演着越来越重要的角色,特别是在需要实时数据更新的场景中。Vue3作为当前最流行的前端框架之一,与WebSocket的结合能够为开发者提供强大的实时交互能力。本…...

掌握通达信数据接口:量化分析从入门到精通
掌握通达信数据接口:量化分析从入门到精通 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 解决量化数据获取难题:MOOTDX的技术方案与实战应用 如何突破量化分析的数据获取…...