集成学习:投票法、提升法、袋装法
集成学习:投票法、提升法、袋装法
目录
- 🗳️ 投票法 (Voting)
- 🚀 提升法 (Boosting)
- 🛍️ 袋装法 (Bagging)
1. 🗳️ 投票法 (Voting)
投票法是一种强大的集成学习策略,它通过将多个模型的预测结果进行组合,旨在提升整体模型的性能。这种方法可以分为简单投票和加权投票两种形式。在简单投票中,每个模型对分类结果的投票权重相同,而在加权投票中,则根据模型的表现为每个模型分配不同的权重。通过集成多个模型,投票法能够有效降低单一模型的偏差,提高预测的准确性。
投票法的实现
以下是投票法的基本实现,通过 scikit-learn 库的 VotingClassifier 进行组合:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义基学习器
clf1 = LogisticRegression(solver='liblinear')
clf2 = DecisionTreeClassifier()
clf3 = SVC(probability=True)# 创建投票分类器
voting_clf = VotingClassifier(estimators=[('lr', clf1), ('dt', clf2), ('svc', clf3)], voting='soft')# 训练模型
voting_clf.fit(X_train, y_train)# 预测并评估
y_pred = voting_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)print(f'Voting Classifier Accuracy: {accuracy:.2f}')
投票法的优势
投票法的主要优势在于它能够结合不同模型的强项,减少单个模型可能产生的错误。此外,在存在噪声数据时,投票法也能够有效提高稳定性。通过集成多种算法,投票法能够适应不同的决策边界,达到更为理想的分类效果。简单投票的实现易于理解,而加权投票则能更好地利用各个模型的特长。通过这种组合,模型的泛化能力得到提升,特别是在复杂的数据集上。
2. 🚀 提升法 (Boosting)
提升法是一种通过逐步训练多个弱分类器来构建强分类器的技术。它的核心思想是将关注点放在那些被先前分类器错误分类的样本上。通过这种方式,提升法能够逐步减少模型的偏差,提高整体预测的准确性。常见的提升算法包括 AdaBoost 和 XGBoost 等。
提升法的实现
以下是使用 AdaBoost 的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建基础学习器
base_estimator = DecisionTreeClassifier(max_depth=1)# 创建 AdaBoost 分类器
ada_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50)# 训练模型
ada_clf.fit(X_train, y_train)# 预测并评估
y_pred = ada_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)print(f'AdaBoost Classifier Accuracy: {accuracy:.2f}')
提升法的优势
提升法的最大优势在于其强大的预测能力,尤其是在面对复杂的数据模式时。通过将多个弱分类器的结果结合,提升法能够形成一个高度准确的强分类器。此外,提升法对异常值和噪声的鲁棒性较强,能够有效降低过拟合的风险。由于其逐步学习的特性,提升法还能够为每个样本分配不同的权重,从而更有效地学习复杂的决策边界。使用提升法时,选择合适的基础学习器和参数设置至关重要,这将直接影响模型的性能。
3. 🛍️ 袋装法 (Bagging)
袋装法是一种通过对训练数据进行重采样的技术,旨在提升模型的稳定性和准确性。袋装法通过在多个子集上训练多个模型,最终将它们的预测结果进行组合,以减少方差并提高整体性能。随机森林是袋装法的经典应用,结合了决策树的优势和袋装法的灵活性。
袋装法的实现
以下是使用随机森林实现袋装法的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_clf.fit(X_train, y_train)# 预测并评估
y_pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)print(f'Random Forest Classifier Accuracy: {accuracy:.2f}')
袋装法的优势
袋装法的核心优势在于其通过重采样减少方差,进而提高模型的稳定性。这种方法能够有效防止过拟合,尤其是在数据量较小或特征较多的情况下。随机森林作为袋装法的代表,结合了多棵决策树的预测结果,通常能获得优于单一模型的效果。此外,袋装法的并行性使得其在训练速度上也具有一定优势,尤其在数据集较大时,能够显著减少训练时间。
通过对多个模型的集成,袋装法能够充分发挥每个模型的长处,从而形成更为稳定和高效的预测系统。由于其结构的简单性和易于实现的特点,袋装法被广泛应用于各类机器学习任务中,成为数据科学家和工程师的常用工具。
相关文章:

集成学习:投票法、提升法、袋装法
集成学习:投票法、提升法、袋装法 目录 🗳️ 投票法 (Voting)🚀 提升法 (Boosting)🛍️ 袋装法 (Bagging) 1. 🗳️ 投票法 (Voting) 投票法是一种强大的集成学习策略,它通过将多个模型的预测结果进行组合…...

波浪理论、江恩理论、价值投资的结合
结合波浪理论、江恩理论和价值投资,需要理解这三种方法的核心原理和应用方式。下面详细解析如何将它们融合在一起,形成一个更全面的投资策略: 1. 基本概述 波浪理论:由艾略特提出,通过分析市场波动的五个上升浪和三个…...
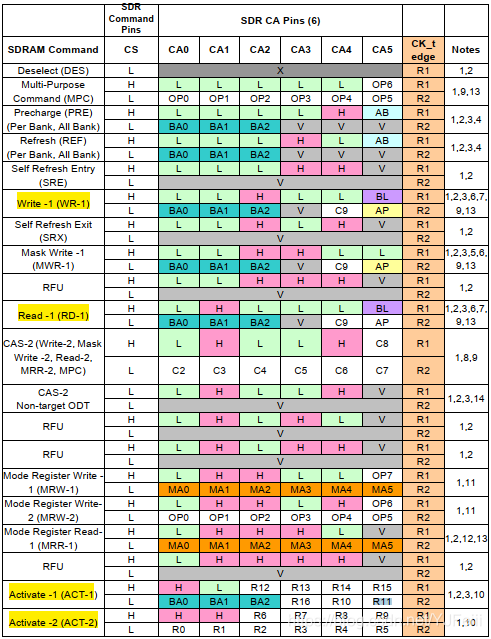
LRDDR4芯片学习(三)——命令和时序
ddr command: activate commandrefresh commandprecharge commandwrite/read commandburst write/read commandMRR/MRW command 一、Activate命令 在读写命令之前,必须要发送Activate命令,由ACTIVATE-1、ACTIVATE-2命令组成。ACTIVATE命令中包含了BA[…...

【趣学C语言和数据结构100例】
【趣学C语言和数据结构100例】 问题描述 61.假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,可共享相同的后缀存储空间,例如,loading 和 being 的存储映像如下图所示,设 strl 和 str2 分别指向两个单词所在单链表的头结点,链表结点结构为 data next。请设计…...
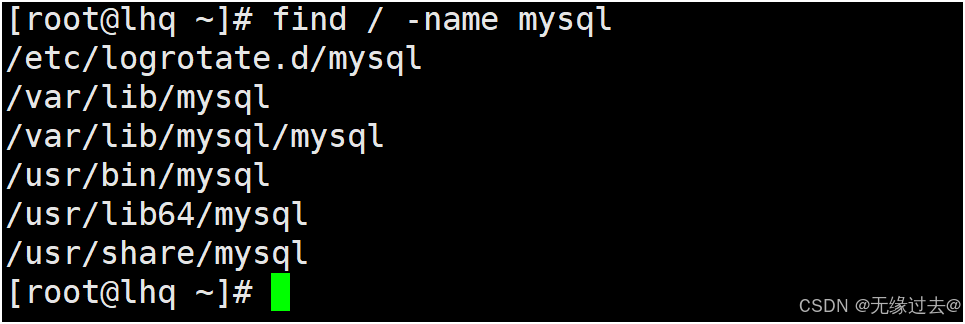
linux卸载数据库(最为完整的卸载方式)
1.首先检查是否安装了MySQL组件 我们可以看到有五个与mysql相关的组件 2.卸载前关闭MySQL服务 systemctl stop mysqld systemctl status mysqld 3.收集MySQL对应的文件夹信息 whereis mysql 4.卸载删除MySQL各类组件 #例如 rpm -ev --nodeps mysql-community-libs-5.7.…...
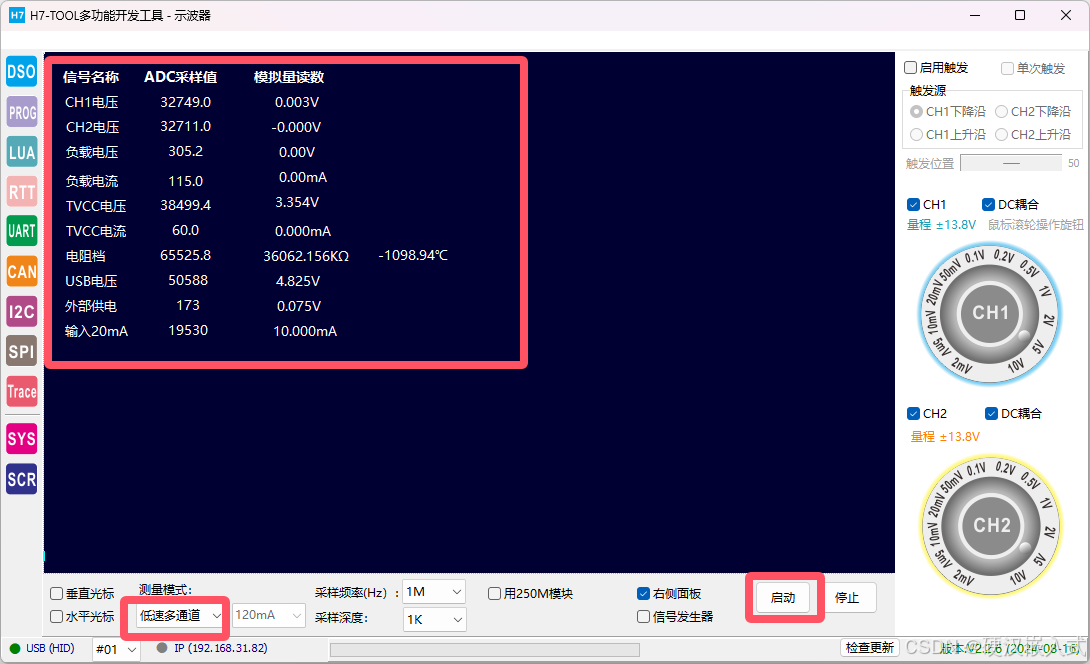
H7-TOOL的LUA小程序教程第15期:电压,电流,NTC热敏电阻以及4-20mA输入(2024-10-21,已经发布)
LUA脚本的好处是用户可以根据自己注册的一批API(当前TOOL已经提供了几百个函数供大家使用),实现各种小程序,不再限制Flash里面已经下载的程序,就跟手机安装APP差不多,所以在H7-TOOL里面被广泛使用ÿ…...

使用梧桐数据库进行销售趋势分析和预测
在当今竞争激烈的商业环境中,企业需要深入了解销售数据,以便做出明智的决策。销售趋势分析和预测是帮助企业把握市场动态、优化库存管理、制定营销策略的重要工具。本文将介绍如何使用SQL来创建销售数据库的表结构,插入示例数据,并…...
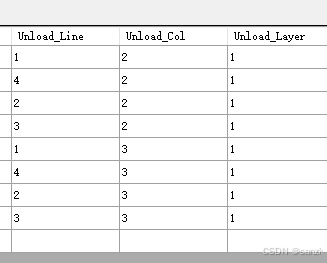
SQLITE排序
最终实现的效果:先查询第一层2列开始的1、4、2、3排,再查询第三列、四列...,然后第二层... 入库 排序优先级:层>列>排(1>2,4>3) 最终排的优先级 1>4>2>3 ORDER BY rack.rackLayer,rack.rackColumn, CASE rack.rackRowW…...

python的文件操作
文件操作 1.打开文件 2.读取文件内容 3.写入文件内容 4.关闭文件 要打开文件,可以使用open()函数并指定文件路径和模式。 file open("example.txt", "r") # 打开了一个名为"example.txt"的文件,并将其赋值给变量file。第…...

群晖通过 Docker 安装 MySQL
1. 打开 Docker 应用,并在注册表搜索 MySQL 2. 下载 MySQL 镜像,并选择版本 3. 在 Docker 文件夹中创建 MySQL,并创建子文件夹 4. 设置权限 5. 选择 MySQL 映像运行,创建容器 6. 配置 MySQL 容器 6.1 使用高权限执行容器 6.2 启…...

同程旅行面经
前言 一面 2024-10-11 实习项目架构,技术栈是怎么样的,自己实现了哪些功能?(文件上传,更新记录记忆,动态表格)写了多少行代码?(2~3k)项目有上线了吗&#x…...
)
【贪心算法】(第八篇)
目录 分发饼⼲(easy) 题目解析 讲解算法原理 编写代码 最优除法(medium) 题目解析 讲解算法原理 编写代码 分发饼⼲(easy) 题目解析 1.题目链接:. - 力扣(LeetCode…...
)
立即调用的函数表达式(IIFE)
立即调用的函数表达式(IIFE),它会立即执行并返回一个空对象 解析 Plugins: (() > { return {}; })():1、解析 () > { return {}; } 是一个箭头函数,它定义了一个返回空对象的函数。 在定义之后,() 表示立即调用…...

YOLOv11改进-卷积-引入小波卷积WTConv 解决多尺度小目标问题
本篇文章将介绍一个新的改进机制——WTConv(小波卷积),并阐述如何将其应用于YOLOv11中,显著提升模型性能。YOLOv11模型相比较于前几个模型在检测精度和速度上有显著提升,但其仍然受卷积核感受野大小的限制。因此&#…...

flask 接口还在执行中,前端接收到接口请求超时,解决方案
在 Flask 中,当某个接口执行时间较长而导致前端请求超时时,需要考虑以下解决方案: 1. 优化接口的响应时间 如果可能,先优化接口中的代码逻辑,减少处理时间。对于查询操作,可以考虑数据库索引优化、缓存机制等手段。2. 增加请求超时时间 如果接口确实需要较长时间完成,前…...

探索 Python 中的 XML 转换利器:xml2dict
文章目录 **探索 Python 中的 XML 转换利器:xml2dict**一、背景介绍二、xml2dict 是什么?三、如何安装 xml2dict?四、基本用法五、实际应用场景六、常见问题及解决方案七、总结 探索 Python 中的 XML 转换利器:xml2dict 一、背景…...

dbt-codegen: dbt自动生成模板代码
dbt项目采用工程化思维,数据模型分层实现,支持描述模型文档和测试,非常适合大型数据工程项目。但也需要用户编写大量yaml描述文件,这个过程非常容易出错且无聊。主要表现: 手工为dbt模型编写yaml文件,这过…...
springboot057洗衣店订单管理系统(论文+源码)_kaic
基于springboot的洗衣店订单管理系统 摘要 随着信息互联网信息的飞速发展,无纸化作业变成了一种趋势,针对这个问题开发一个专门适应洗衣店业务新的交流形式的网站。本文介绍了洗衣店订单管理系统的开发全过程。通过分析企业对于洗衣店订单管理系统的需求…...
数据库在 Spring Boot 中使用 Flyway)
南大通用(GBase 8s)数据库在 Spring Boot 中使用 Flyway
db-migration:Flyway、Liquibase 扩展支持达梦(DM)数据库、南大通用(GBase 8s)数据库,并支持 Flowable 工作流。 已支持 达梦数据库(DM 8)。默认支持 flowable 工作流。南大通用数…...

CMakeLists.txt 编写规则
目录 1. 注释 1.1 注释行 1.2 注释块 2. CMakeLists.txt的编写 2.1 同意目录下的源文件 2.2 SET指令 2.3 file和aux_source_directory 2.4 包含头文件 2.5 生成动态库和静态库 2.6 链接库文件 2.7 message指令 2.8 移除操作 2.9 find_library和find_package 3. 常…...

AI应用安全新挑战:基于模糊测试的提示词注入漏洞自动化检测
1. 项目概述:当AI提示词成为攻击目标最近在跟几个做AI应用安全的朋友聊天,大家不约而同地提到了一个词:“提示词攻击”。听起来有点抽象,对吧?简单来说,就是有人不直接黑你的系统,而是通过精心构…...

IO-Link技术解析:工业自动化通信与LTC2874/LT3669芯片应用
1. IO-Link技术概述:工业自动化的神经末梢在工业4.0的浪潮中,设备间的实时通信如同工厂的神经系统。IO-Link作为这个系统中的"神经末梢",实现了控制层与现场设备间的最后一米连接。这项技术最早由PROFIBUS用户组织在2009年推出&…...

基于Laravel的BeikeShop开源电商平台:从架构解析到生产部署实战
1. 项目概述:为什么选择BeikeShop作为你的开源电商起点?如果你正在寻找一个能让你完全掌控代码和数据,同时又不想从零开始造轮子的电商解决方案,那么BeikeShop绝对值得你花时间深入了解。作为一个基于Laravel 10构建的、100%开源的…...
【Pixel专属Gemini Edge推理引擎】:本地运行LLM不联网、零延迟、功耗降低47%——实测数据首次公开
更多请点击: https://intelliparadigm.com 第一章:Gemini Edge推理引擎的Pixel专属定位与技术边界 Gemini Edge 是 Google 为 Pixel 系列设备深度定制的端侧推理引擎,其核心设计目标并非通用模型部署,而是围绕 Pixel 的硬件协同栈…...

GeoJSON.io:3分钟创建专业地图,地理数据可视化从未如此简单
GeoJSON.io:3分钟创建专业地图,地理数据可视化从未如此简单 【免费下载链接】geojson.io A quick, simple tool for creating, viewing, and sharing spatial data 项目地址: https://gitcode.com/gh_mirrors/ge/geojson.io 你是否曾经需要在地图…...

爱搜索 GEO 营销系统实效展示与能力验证
在当前的数字营销环境中,许多企业发现传统的 SEO 手段在应对 AI 驱动的搜索场景时显得力不从心。当潜在客户向大模型提问“哪家装修公司更靠谱”或“推荐几家铝板输送机厂家”时,如果品牌未能出现在 AI 生成的答案中,就意味着失去了最精准的流…...

DuckyClaw工具链解析:智能家居硬件安全与固件提取实战
1. 项目概述:从“DuckyClaw”看智能家居的硬件安全研究最近在翻看一些开源硬件项目时,一个名为“DuckyClaw”的仓库引起了我的注意。这个项目托管在涂鸦智能(Tuya)的官方GitHub组织下,名字本身就很有意思——“鸭子爪”…...

极域电子教室破解终极指南:如何快速解除课堂控制实现学习自由
极域电子教室破解终极指南:如何快速解除课堂控制实现学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为极域电子教室的全屏控制而烦恼吗?你是…...

开源网络过滤工具librefang:DNS与代理混合部署实战指南
1. 项目概述:一个开源网络过滤与内容管理工具最近在折腾家庭网络和自建服务时,经常遇到一个核心需求:如何在不依赖商业方案或复杂硬件的前提下,对网络流量进行透明、高效且可定制的内容过滤与管理。无论是想给孩子一个更纯净的上网…...
)
【Oracle数据库指南】第35篇:Oracle特殊对象——簇与索引组织表(IOT)
上一篇【第34篇】Oracle索引管理与优化详解 下一篇【第36篇】Oracle用户与权限管理详解(完整版)(明日更新,敬请期待) 摘要 除了普通堆组织表(Heap-Organized Table)之外,Oracle还提…...