点跟踪论文—RAFT: Recurrent All-Pairs Field Transforms for Optical Flow-递归的全对场光流变换
点目标跟踪论文—RAFT: Recurrent All-Pairs Field Transforms for Optical Flow-递归的全对场光流变换
读论文RAFT密集光流跟踪的笔记
RAFT是一种新的光流深度网络结构,由于需要基于点去做目标的跟踪,因此也是阅读了像素级别跟踪的一篇ECCV 2020的经典论文 ——RAFT,递归的全对场光流变换,使用密集的光流来对小而快速的物体进行跟踪。
- 作者:Zachary Teed and Jia Deng
- 发表:ECCV 2020 best paper
论文的难点与核心点
- 不像之前的coarse-to-fine类的方法,RAFT在计算时始终保持同一分辨率,而coarse-to-fine则是对多尺度预测,逐步细化的方式
- update operator是轻量的和循环的,而其他的算法则只能是循环几次,无法长时间循环。
- 一个新的update operator,由卷积GRU组成,可look up 生成的4D相关信息。
是论文的难点也是自己理解不太好的地方。
背景信息
密集光流估计为每个像素分配一个二维光流向量,描述其在时间间隔内的水平和垂直位移。在稀疏光流中,该向量只分配给与边角等强特征相对应的像素。
水平梯度 Iₓ 和垂直梯度 Iᵧ 可用索贝尔算子近似,时间梯度 Iₜ 已知,因为我们有 t 和 t+1 时间的图像。方程有两个未知数 u 和 v,分别是时间 dt 上的水平位移和垂直位移。单个方程中的两个未知数使其成为一个未决问题,人们曾多次尝试求解 u 和 v。RAFT 是一种估算 u 和 v 的深度学习方法,但它实际上比根据两个框架预测流量更复杂。它是为精确估计光流场而精心设计的。

取得的成果:
在KITTI上,RAFT取得了5.10%的F1-all误差,比已公布的最佳结果 (6.10%)降低了16%。在Sintel(final pass)上,RAFT获得了2.855 EPE误差,比已发布的最佳结果(4.098像素)减少了30%的误差。此外,RAFT具有很强的跨数据集泛化能力,以及在推理时间、训练速度和参数量方面具有很高效率。
a new end-to-end trainable model for optical flow

摘要与整体概括
摘要
摘要的核心总结:
-
RAFT 逐像素提取特征,为所有像素对构建多尺度4D相关体,并通过循环单元在
相关体上进行查找,以迭代更新光流场。 -
是一种新的光流深度网络架构。

在学习完成论文之后总结来说:其中的两个关键的词包含了光流跟踪最重要的两个过程信息。
-
correlation: 是我们计算像素之间的全相关性和进行保持高分辨率不变的基础上进行多尺度金字塔构建的一个核心。
-
lookup:是作者们为了简化一定的计算和损失,所提出的一种在coor上寻找特征点的一种方法。(难理解要结合看代码)。
整体概括
给定一对连续的RGB图像作为输入,估计稠密位移场(dense displacement field),位移场将中的每个像素映射到中的对应坐标。算法框架如下图所示:

我们讲述这篇论文从整体到细节首先要明确的是,学习的重点是整篇论文实现的一个思想。我们给出总结的整体的步骤和框架,结合整体的结构不断的细化。论文中给出了我们一定的总结。

REFT主要包括以下的三个部分组成。
- 特征提取编码器与内容提取编码器。
- 一个相关层得出4d的一个相关体。
- 一个用来更新的操作符从相关体中更新光流的信息。
我们对这个过程进行总结在详细的进行描述。
-
先是一个网络 Net1(
特征提取编码器)提取两张输入 I1,I2的特征,还有另一个网络 Net2(内容提取编码器) 再提取一次 I1 的特征,然后通过一个correlation layer接收 Net1的输出并建立两张图片的相似度向量矩阵。最后作者使用了自然语言处理中GRU的思想,把相似度向量,每一次迭代预测出的光流,以及 Net2的输出三者作为输入去迭代着更新光流。 -
RAFT由三部分组成:
-
(1)一个feature encoder提取两张输入图片 I1,I2在每个像素点上的特征。这里我们假设 I1,I2的尺寸是 H×W ,那么经过feature encoder之后得到的特征维度就是 H×W×D ;此外还有一个 context encoder提取 I1的特征,也就是图片的左下角。
-
(2)一个 correlation layer负责把 I1,I2 的特征向量通过点乘的方式连接起来,那么最终输出的是一个 H×W×H×W的4d向量,此向量表示 I1每一个像素点与所有 I2像素点的相关度。然后作者也考虑到这样的表示可能比较稀疏,因此在这个输出之后做了四层的池化,并将每一层池化的输出连接起来做成了一个具有多尺度特征的相似性变量。
-
(3)一个update operator,通过使用一个look up方法(查看 4D Correlation Voulumes的值)迭代着去更新光流。当然第三点需要下面的详细介绍。
The feature encoder extracts per-pixel features. The correlation layer
computes visual similarity between pixels. The update operator mimics the steps of an iterative optimization algorithm.

因为我们已经进行了整体的概括了,有了一定的印象,我们按照论文的结构展开
Approach
方法部分是官方的一个整体的介绍。

给一组连续的RGB图像 I1 I2 we estimate a dense displacement
field (f1, f2)去估计一个密集的位移场 f1,f2.每一个光流(u,v)要map I2.同时总结了三个核心的部分
- 特征提取
- 相似度计算
- 迭代更新
( u ′ , v ′ ) = ( u + f 1 ( u ) , v + f 2 ( v ) ) \left(u^{\prime}, v^{\prime}\right)=\left(u+f^{1}(u), v+f^{2}(v)\right) (u′,v′)=(u+f1(u),v+f2(v))
分辨率描述
在建立完成相关量之后也就是完成8倍的下采样操作通过backebone网络提取出来特征图之后。作者给出了一副描述图
对于I1中的特征向量,我们取其与I2中所有对的内积,生成一个4D W×H×W×H体 (I2中的每个像素生成一个2D 响应图)。使用卷积核大小为1、2、4、8的平均池化对相关体池化。

这组相关性张量同时包含了大位移和小位移的信息;但是也保持前两个维度(维度),因此保存了高分辨率的信息,从而可以恢复小的快速移动物体的运动。
这里自己直观的解读一下的话其实就是,每一个点我们代表的是一个像素的分辨率,我们只对最后的两个维度进行下采样的操作。导致每幅图的最后的两个维度发生变换,内部的每一组包含的像素点发生变换,但我们外部的尺寸保持不变使得内部像素点的分辨率其实也是保持不变的会一直维持在8倍的分辨率上。
保持高分辨率从而就克服了coarse-to-fine类的方法—有粗到细使用不同的分辨率进行采样。
Feature Extraction

核心总结:
- 使用卷积网络进行特征的提取
- 最终通过2倍4倍完成8倍的下采样操作 D=256
- 由6个残差块组成。整个特征提取只进行一次。
- 唯一的区别是特征编码器使用实例标准化,而上下文编码器使用批量标准化。

backbone主干网络细节
相比于其他的复杂的神经网络来说,这里的backbone部分相对比较简单,很大的程度上参考了RestNet50这种结构。

layer层使用的和YOLO中常用的botteneck模块类似,这里我们称为残差块,在代码中每两个残差块为一组。1不进行下采样 2 3在第一个卷积的部分进行下采样的操作。(下采样连接)
对于两幅图 I1和 I2都需要提取特征,该网络称之为 Feature Encoder
Computing Visual Similarity
Computing Visual Similarity计算视觉相似度

通过在所有输入图像对之间构造一个correlation volume(下称为相关性张量)来计算视觉相似性 -印象中代码里面最终对应的是coor
给定抽取得到图像特征: 通过对所有的特征向量对进行点积得到 相关性张量。记相关性张量为 C
g θ ( I 1 ) ∈ R H × W × D and g θ ( I 2 ) ∈ R H × W × D g_{\theta}\left(I_{1}\right) \in \mathbb{R}^{H \times W \times D} \text { and } g_{\theta}\left(I_{2}\right) \in \mathbb{R}^{H \times W \times D} gθ(I1)∈RH×W×D and gθ(I2)∈RH×W×D
C ( g θ ( I 1 ) , g θ ( I 2 ) ) ∈ R H × W × H × W , C i j k l = ∑ h g θ ( I 1 ) i j h ⋅ g θ ( I 2 ) k l h \mathbf{C}\left(g_{\theta}\left(I_{1}\right), g_{\theta}\left(I_{2}\right)\right) \in \mathbb{R}^{H \times W \times H \times W}, \quad C_{i j k l}=\sum_{h} g_{\theta}\left(I_{1}\right)_{i j h} \cdot g_{\theta}\left(I_{2}\right)_{k l h} C(gθ(I1),gθ(I2))∈RH×W×H×W,Cijkl=h∑gθ(I1)ijh⋅gθ(I2)klh
Correlation Layer模块
这里我们得到了 I1对 I2上的多尺度4D Correlation Voulumes.

我们这个模块单独的分离出来,方便进行简单的说明。
我们从最终的一个公式中其实也是可以看出来的,4d向量空间最终融合的是通道数h嘛。
如果我们不看下面的代码来看这一个过程信息。
@staticmethoddef corr(fmap1, fmap2):batch, dim, ht, wd = fmap1.shapefmap1 = fmap1.view(batch, dim, ht*wd) # 展平一个维度fmap2 = fmap2.view(batch, dim, ht*wd) corr = torch.matmul(fmap1.transpose(1,2), fmap2) #转置相乘corr = corr.view(batch, ht, wd, 1, ht, wd)return corr / torch.sqrt(torch.tensor(dim).float()) # coor 互相关运算得到的矩阵
代码是将h和w展平之后来进行操作的。—转置相乘。最后在进行展开合并维度相关的信息。
我们如果按照3通道图片自己来想这一个过程的话,其实就是三个通道的图像相同位置的像素同时做一个点积的操作。在依次的相加得到一个值
我们每一个像素值要做i2的大小 H x W然后i1中有 H x W个像素需要做相关性运算从而就是这个结果了。

从这两个图也可以看出下面会有一个保持分辨率的情况下进行构建金字塔的过程。
Correlation pyramid模块
我们得到 H×W 的向量之后,作者觉得这样比较稀疏,因为 I1不可能与 I2所有的像素点相关,所以作者又将这个向量进行了四层池化。
这样一个相关信息张量C是非常大的, 因此在C的最后两个维度上进行汇合来降低维度大小,每个的维度为保持前两个维度不变, 这种相关信息张量可以保证同时捕捉到较大和较小的像素位移。
这组相关性张量同时包含了大位移和小位移的信息;但是也保持前两个维度(维度),因此保存了高分辨率的信息,从而可以恢复小的快速移动物体的运动。

这个叠加在代码中是放在一个out_pyramid = []变量中来进行返回实现的。
self.corr_pyramid.append(corr) # 后两个维度下采样构建金字塔self.corr_pyramid.append(corr) # 后两个维度下采样构建金字塔for i in range(self.num_levels-1):corr = F.avg_pool2d(corr, 2, stride=2) # 2倍平均池化self.corr_pyramid.append(corr)
Look up模块
Look up的部分个人感觉是最难理解的一个部分(原因在于它描述的过程比较抽象。)具体的更多细节的实现还是参考代码中的具体过程。
We define a lookup operator LC which generates a feature map by indexing from the correlation pyramid.—我们定义了一个查找算子 LC,它通过从相关金字塔进行索引来生成特征图。
上一步构建了四层的Correlation Pyramid,这里要根据像素去查找这个Correlation Pyramid中的对应特征。如果对I1中的每个点的向量都要去I2中所有向量找对应点的话,需要的cost太大了,所以论文中设置了一个lookup的参数,即只对该位置附近位置的点做判断

N ( x ′ ) r = { x ′ + d x ∣ d x ∈ Z 2 , ∥ d x ∥ 1 ≤ r } \mathcal{N}\left(\mathbf{x}^{\prime}\right)_{r}=\left\{\mathbf{x}^{\prime}+\mathbf{d x} \mid \mathbf{d x} \in \mathbb{Z}^{2},\|\mathbf{d x}\|_{1} \leq r\right\} N(x′)r={x′+dx∣dx∈Z2,∥dx∥1≤r}


r超参数是超参数,有点类似于圆的半径,dx是整数,通过这个公式把x’附近的值拿到,同时这个操作会在每一层的金字塔上取值,最后将这些得到的值串联成一个向量。这个向量也就是Lookup的输出。总结一下就是光流建立了I的像素点到I2像素点的映射,然后使用对应的I2点的坐标,在对应的相似性向量的金字塔上采样得到一个输出向量。那么大胆猜测一下,对于快速移动的物体,r设置的偏大一些,效果应该更好;对于移动较慢的无题,r设置的应该偏小一些。
我自己在粗略的看代码的时候也是感觉这个Look up模型更像是一个采样的模块。是在相似性向量的金字塔通过这种邻近范围的方式查找符合计算条件的点(输入后面GRU模块进行计算,应该也是因为维度过高导致计算量过大的原因吧。)
代码中是通过grid_sample()函数之间完成这一个过程的。这个r类似半径但实际上是一个线性的间隔值
bilinear_sampler
F.grid_sample()
for i in range(self.num_levels):corr = self.corr_pyramid[i]dx = torch.linspace(-r, r, 2*r+1, device=coords.device) # (2r+1) x方向的相对位置查找范围 -r,-r+1,...,r 从-r到r的线性间隔的值,并且包括端点。2*r+1是生成这些值的数量dy = torch.linspace(-r, r, 2*r+1, device=coords.device) # # (2r+1) y方向的相对位置查找范围delta = torch.stack(torch.meshgrid(dy, dx), axis=-1) # 查找窗 (2r+1,2r+1,2) 一维张量dy和dx的笛卡尔积torch.meshgrid返回的两个二维张量堆叠起来,形成一个三维张量。axis=-1参数指定了堆叠的轴,这里是最后一个轴(dy_i, dx_i)对表示二维空间中的一个位移向量centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**i # 某尺度下的坐标delta_lvl = delta.view(1, 2*r+1, 2*r+1, 2)coords_lvl = centroid_lvl + delta_lvl # 可以形象理解为:对于 bhw 这么多待查找的点,每一个点需要搜索 (2r+1)*(2r+1) 邻域范围内的其他点,每个点包含 x 和 y 两个坐标值corr = bilinear_sampler(corr, coords_lvl) # 在查找表上搜索每个点的邻域特征,获得相关性图corr = corr.view(batch, h1, w1, -1)out_pyramid.append(corr)out = torch.cat(out_pyramid, dim=-1)return out.permute(0, 3, 1, 2).contiguous().float()
这里我们返回的corr变量其实也就是经过采样之后的一个变量值。作为下一部分的一个输出。
corr = corr_fn(coords1) # 核心index correlation volume 从相关性查找表中获取当前坐标的对应特征
Efficient Computation for High Resolution Images(可选)
具体的公式含义细节我自己也不太明白不做过多的解读了。
原因在于这一个部分,对应代码中的CUDA变成部分对应C++模块是以是一个在训练中可以选择的计算方式,自己不太会CUDA的这一个部分

我自己读论文的话,其实他的思想就是将下采样的操作融合进相关性的计算里面以减少参数量来实现简化计算。从O(n2)到O(mn)
C i j k l m = 1 2 2 m ∑ p 2 m ∑ q 2 m ⟨ g i , j ( 1 ) , g 2 m k + p , 2 m l + q ( 2 ) ⟩ = ⟨ g i , j ( 1 ) , 1 2 2 m ( ∑ p 2 m ∑ q 2 m g 2 m k + p , 2 m l + q ( 2 ) ) ⟩ \mathbf{C}_{i j k l}^{m}=\frac{1}{2^{2 m}} \sum_{p}^{2^{m}} \sum_{q}^{2^{m}}\left\langle g_{i, j}^{(1)}, g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right\rangle=\left\langle g_{i, j}^{(1)}, \frac{1}{2^{2 m}}\left(\sum_{p}^{2^{m}} \sum_{q}^{2^{m}} g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right)\right\rangle Cijklm=22m1p∑2mq∑2m⟨gi,j(1),g2mk+p,2ml+q(2)⟩=⟨gi,j(1),22m1(p∑2mq∑2mg2mk+p,2ml+q(2))⟩

Iterative Updates
Our update operator estimates a sequence of flow estimates {f1, …, fN} from an initial starting point f0 = 0

看出初始化的光流为0
# 初始化光流的坐标信息,coords0 为初始时刻的坐标,coords1 为当前迭代的坐标,此处两坐标数值相等coords0, coords1 = self.initialize_flow(image1)flow = coords1 - coords0 # 初始值为0
输入:当前光流,以及从金字塔中提取的对应的相关特征,context。所以输入是相关特征,光流以及上下文特征。
with autocast(enabled=self.args.mixed_precision):net, up_mask, delta_flow = self.update_block(net, inp, corr, flow)# F(t+1) = F(t) + \Delta(t)coords1 = coords1 + delta_flow

带有卷积的GRU模块(update block模块)
更新算子的核心组件是一个基于GRU的gated activation unit,其中的全连接层使用卷积替换:
其中 x t 是前面定义的光流、相关特征、context特征的拼接。论文还实验了一个可分离的ConvGRU单元,其中用两个GRU替换3×3卷积: 一个用1×5卷积,一个用5×1卷积,以便在不显著增加模型大小的情况下增加感受野。

整体结果的一个定义。
self.args = argsself.encoder = BasicMotionEncoder(args)self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)self.flow_head = FlowHead(hidden_dim, hidden_dim=256)

对应更为细节的具体描述需要断点调试前向传播的部分在文章中就不过多的进行展开说明了。
def __init__(self, hidden_dim=128, input_dim=192+128):super(SepConvGRU, self).__init__()self.convz1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))self.convr1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))self.convq1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))self.convz2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))self.convr2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))self.convq2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))def forward(self, h, x):# horizontalhx = torch.cat([h, x], dim=1)z = torch.sigmoid(self.convz1(hx))r = torch.sigmoid(self.convr1(hx))q = torch.tanh(self.convq1(torch.cat([r*h, x], dim=1))) h = (1-z) * h + z * q
其中的全连接层使用卷积替换
光流预测
self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
光流头通过两个全连接层进行输出。
将GRU输出的隐藏状态经过两个卷积层来预测光流的更新 Δf 。输出的光流的分辨率是输入图像的1/8。
在训练和评估过程中,对预测的光流场进行上采样,以匹配ground-truth的分辨率。
class FlowHead(nn.Module):def __init__(self, input_dim=128, hidden_dim=256):super(FlowHead, self).__init__()self.conv1 = nn.Conv2d(input_dim, hidden_dim, 3, padding=1)self.conv2 = nn.Conv2d(hidden_dim, 2, 3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):return self.conv2(self.relu(self.conv1(x)))
上采样
RAFT 的作者对双线性和凸上采样进行了实验,发现凸上采样可以显着提高性能。

凸上采样将每个精细像素估计为其相邻 3x3 粗像素网格的凸组合

L = ∑ i = 1 N γ N − i ∥ f g t − f i ∥ 1 \mathcal{L}=\sum_{i=1}^{N} \gamma^{N-i}\left\|\mathbf{f}_{g t}-\mathbf{f}_{i}\right\|_{1} L=i=1∑NγN−i∥fgt−fi∥1
相关文章:
点跟踪论文—RAFT: Recurrent All-Pairs Field Transforms for Optical Flow-递归的全对场光流变换
点目标跟踪论文—RAFT: Recurrent All-Pairs Field Transforms for Optical Flow-递归的全对场光流变换 读论文RAFT密集光流跟踪的笔记 RAFT是一种新的光流深度网络结构,由于需要基于点去做目标的跟踪,因此也是阅读了像素级别跟踪的一篇ECCV 2020的经典…...

jmeter学习(6)逻辑控制器-循环
循环执行 1、循环读取csv文件的值 2、foreach 读取变量,变量数字后缀有序递增,通过counter实现 ${__V(typeId${typeIdNum})} beansell断言 String typeIdNum vars.get("typeIdNum"); String response prev.getResponseDataAsString(); …...

unity学习笔记-安装与部署
unity学习笔记-安装与部署 unity & visual studio下载unityvisual studio 创建工程项目内的布局介绍初始化项目各目录介绍1. 场景视图(Scene)2. 游戏视图(Game)3. 层次结构视图(Hierarchy)4. 检查器视图…...

Django+MySQL接口开发完全指南
前言 本文将详细介绍如何使用Django结合MySQL数据库开发RESTful API接口。我们将从环境搭建开始,一步步实现一个完整的接口项目。 环境准备 首先需要安装以下组件: Python 3.8Django 4.2MySQL 8.0mysqlclientdjangorestframework 安装命令 # 创建虚…...

CentOS7上下载安装 Docker Compose
Docker Compose简要介绍(想直接看安装步骤的请跳转到[必要的安装步骤]) Docker Compose 是一个用于定义和管理多容器 Docker 应用的工具,它可以通过一个简单的 YAML 文件(docker-compose.yml)来配置应用程序的服务、网…...

虚拟机的 NAT 模式 或 Bridged 模式能够被外界IPping通
如果虚拟机使用的是 NAT 模式 或 Bridged 模式,通常可以让外部网络(例如互联网)访问虚拟机。NAT 和 Bridged 模式的不同之处在于它们如何将虚拟机连接到宿主机和外部网络。以下是这两种模式的详细说明: 1. NAT 模式 在 NAT 模式…...

C# 使用Dll的几种方法举例
使用 DLL(动态链接库)是 C# 开发中常见的任务之一。DLL 文件包含可以在运行时加载的代码和数据,允许程序共享功能和资源,降低程序的内存占用并促进代码的复用。本篇文章将深入探讨 C# 中使用 DLL 的多种方法,并提供相关…...

什么是不同类型的微服务测试?
大家好,我是锋哥。今天分享关于【什么是不同类型的微服务测试?】面试题?希望对大家有帮助; 什么是不同类型的微服务测试? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 微服务架构中的测试可以分为多种类…...
)
Docker 拉取镜像时配置可用镜像源(包含国内可用镜像源)
在/etc/docker/daemon.json中写入如下内容(如果文件不存在请新建该文件): { "registry-mirrors":["https://registry.docker-cn.com"] } 重新加载 json 配置文件: sudo systemctl daemon-reload重启 docker 服务: sud…...

International Symposium on Artificial Intelligence Innovations
计算机科学(Computer Science): 算法、自动化软件工程、生物信息学和科学计算、计算机辅助设计、计算机动画、计算机体系结构、计算机建模、计算机网络、计算机安全、计算机图形学与图像处理、数据库与数据挖掘、数据压缩、数据加密、数字信号…...

Golang笔记_day10
Go面试题(三) 1、什么是channel,为什么它可以做到线程安全 在Go语言中,channel是一种类型,它可以用来在协程之间传递数据通过共享内存来通信: 通过共享内存来通信是指多个线程或进程直接访问相同的内存区域…...

mlir learn
https://github.com/j2kun/mlir-tutorial 学习这个项目 https://www.jeremykun.com/2023/08/10/mlir-getting-started/ get start 用我的mac编译一下试试看 然后遇到架构不对的问题 因为他的提交默认是x86 https://github.com/j2kun/mlir-tutorial/pull/1/commits/5a267e269d57…...
)
Windows安装RabbitMQ 4.0.2(图文教程)
本章教程,主要记录在Windows 10上RabbitMQ 4.0.2的安装过程。 一、下载安装包 1、官方下载(速度不稳定) Erlang:https://github.com/erlang/otp/releases/download/OTP-26.0/otp_win64_26.0.exe RabbitMQ 4.0.2:https://github.com/rabbitmq/rabbitmq-server/releases/do…...
分布式系统中为什么需要使用消息队列
本文转载自 linkedkeeper.com 消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。 当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ&#…...

Linux环境配置(学生适用)
1.挑选最便宜的云服务器 如腾讯云服务器,华为云服务器,百度云服务器等等…… 2.找到你的云服务器实例,然后找到你的公网IP。 3.云服务器实例 ---更多 --- 重置root密码 (一定要重置) 4. 下载并安装 xshell 或者其他登陆软件 xshel…...

麦禾软件:Mac用户找免费开源工具的最佳选择
抖知书老师推荐: 麦禾软件已经成为众多Mac用户的必备平台,尤其对于那些经常寻找免费、开源、正版软件的用户来说,绝对是一个福音。随着科技的不断进步和用户需求的提升,安全、便捷的软件下载体验成为用户选择平台的核心标准。而…...
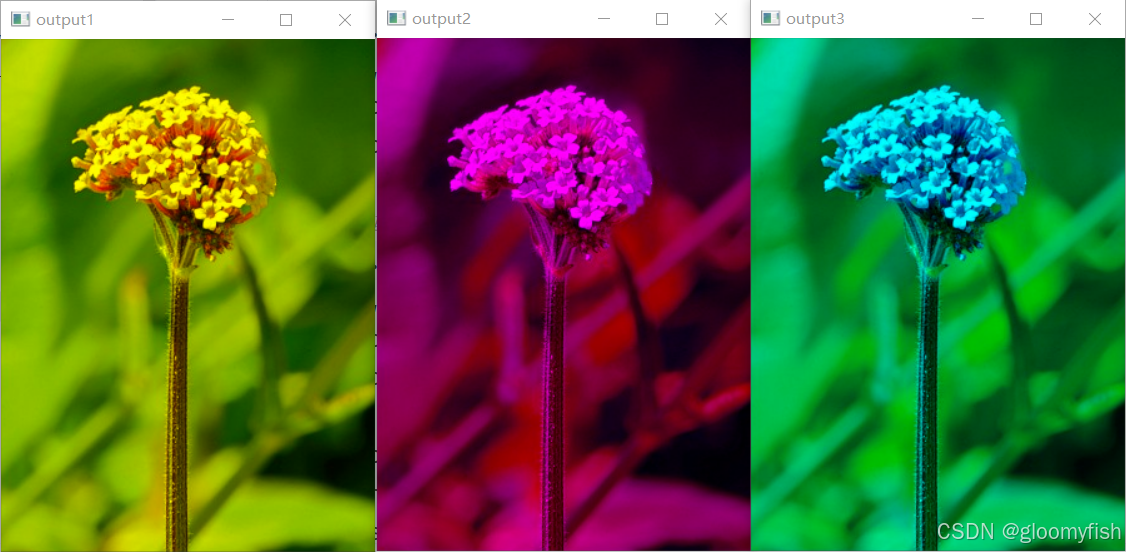
OpenCV4.8 开发实战系列专栏之 08 - 通道分离与合并
大家好,欢迎大家学习OpenCV4.8 开发实战专栏,长期更新,不断分享源码。 专栏代码全部基于C 与Python双语演示,专栏答疑群 请联系微信 OpenCVXueTang_Asst 本文关键知识点: OpenCV中默认imread函数加载图像文件&#…...
iOS 18.1 RC 版本发布,修复iPhone16随机重启、浏览视频卡顿等bug
今日,苹果发布 iOS 18.1 RC 版本升级,内部版本号为 22B82。 iOS 18.1 RC 也就是 iOS 18.1 准正式版,如果没有大的 Bug,这将是 iOS 18.1 正式版发布前最后一次更新,正式版预计下周向消费者推送。 该 RC 版除了为海外用…...

安装buildkit,并使用buildkit构建containerd镜像
背景 因为K8s抛弃Docker了,所以就只装了个containerd,这样就需要一个单独的镜像构建工具了,就用了buildkit,这也是Docker公司扶持的,他们公司的人出来搞的开源工具,官网在 https://github.com/moby/buildkit 简介 服务端为buildkitd,负责和runc或containerd后端连接干活,目前…...

maven jar包二进制文件 invalid stream header: EFBFBDEF 的错误
背景: 将jasper模板文件导入jar包后,生成文件报错 org.springframework.core.io.Resource resource new ClassPathResource("/template/XXXX.jasper");jasperPrint JasperFillManager.fillReport(resource.getInputStream(), paramentMap, …...

PS抠头发太费劲?几种简单方法轻松搞定
作为一名从事平面设计5年的老选手,抠头发绝对是PS修图中最让人头疼的环节——要么抠不干净留杂边,要么太用力丢失细碎发丝,尤其是面对杂色背景、飘逸长发、逆光发丝时,更是让人束手无策。今天就给大家分享3种超实用的PS抠头发丝方…...

借助PD协议分析仪洞悉Type-C充电握手全流程
1. 为什么需要PD协议分析仪? Type-C接口如今已经成为手机、笔记本等设备的标配,但很多用户都遇到过这样的尴尬:买了个第三方充电器,插上设备后要么完全没反应,要么只能以5V慢充。这背后往往是因为PD(Power …...

Agent 工程化系列 · 第 05 篇_FunctionCall底层到底怎么实现
Agent 工程化系列 第 05 篇 Function Call 底层到底怎么实现?模型不是在调用函数,而是在生成调用意图。开篇定位 前面第 04 篇,我们讲清楚了 Function Call 是什么: 它不是让大模型“真的去执行函数”,而是让模型在合…...

2026年十大主流需求管理工具深度测评:哪款更适合你的研发团队?
在软件研发日益复杂化、团队协作边界不断拓展的今天,需求管理不仅是产品经理的基本功,更是整个产品生命周期管理的“神经中枢”。你是否经历过这些问题:版本上线后,发现遗漏了某个关键需求?需求记录散落在 Excel、微信…...

5分钟免费解锁Cursor Pro:终极AI编程助手无限使用方案
5分钟免费解锁Cursor Pro:终极AI编程助手无限使用方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

嵌入式开发中的编程规范实践与行业标准解析
1. 编程规范的本质与价值在嵌入式汽车电子领域干了十五年,我见过太多因为代码不规范导致的惨痛教训。有一次,某车企的ECU控制模块在零下30度环境突然死机,排查三周后发现是未初始化的指针在低温环境下产生了非预期行为——这种问题本可以通过…...

[技术解析] 边缘结构模型MSM:破解时依性混杂的因果推断利器
1. 边缘结构模型MSM:因果推断的"时光机" 想象你是一名医生,正在研究某种降压药的长期疗效。患者A连续服药3个月后血压稳定,患者B服药1个月后自行停药导致血压反弹。传统统计方法会简单对比两组结果,但忽略了一个关键问…...

基于STC89C51单片机的多波形信号发生器设计与Proteus仿真
基于STC89C51单片机的多波形信号发生器设计与Proteus仿真 摘 要 随着电子技术和集成电路的飞速发展,信号发生器作为电子测量领域的基础设备,其性能和智能化水平不断提升。本设计以STC89C51单片机为控制核心,设计了一款多波形信号发生器。系统…...
)
AI应用开发面试题总结(非八股文)
前端请求超过 3 秒,怎么分析原因? 1.看前端和网络 F12开发者模式去查看network,首先判断是前端问题还是后端问题 通过查看接口 Waiting 时间进行判断是后端响应时间太长还是说前端渲染问题 2.给后端接口添加日志进一步定位后端问题 3.如果…...

我让 AI 学会了“拆“App——Antigravity 逆向分析能力搭建手记
你能想象吗?对着 AI 说一句"帮我分析这个 APK",它就自己打开 IDA、拆解代码、Hook 运行时、提取密钥、还原源码……全程不用你碰一下鼠标。先说结论我给 AI 编程助手 Antigravity 装上了 4 把"瑞士军刀",让它从一个只会写…...