Flink时间语义和时间窗口
前言
在实际的流计算业务场景中,我们会发现,数据和数据的计算往往都和时间具有相关性。
举几个例子:
- 直播间右上角通常会显示观看直播的人数,并且这个数字每隔一段时间就会更新一次,比如10秒。
- 电商平台的商品列表,会显示商品过去24小时的销量、或者总销量
- 阅读CSDN博客会显示总的阅读量,并且会持续更新
归纳总结可以发现,这些和时间相关的数据计算可以统一用一个计算模型来描述:每隔一段时间,计算过去一段时间内的数据,并输出结果。这个计算模型,就是时间窗口。
时间窗口类型
时间窗口计算模型具备三个重要的属性:
- 时间窗口的计算频次,即 隔多久计算一次
- 时间窗口的大小,即 计算过去多久的数据
- 时间窗口内数据的处理逻辑
举例来说,每隔1分钟计算商品过去24小时的销量。时间窗口的计算频次就是1分钟,时间窗口的大小是24小时,窗口数据的处理逻辑是 对商品销量求和。
Flink 提供了三种时间窗口的类型
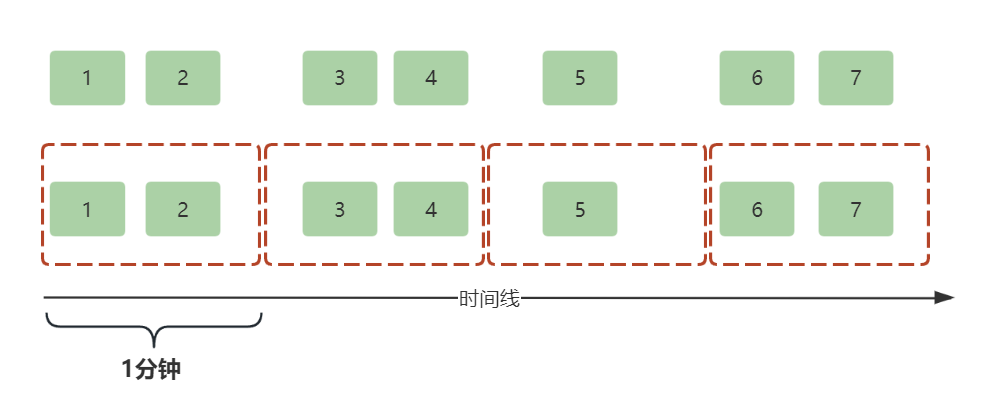
滚动窗口(Tumble Window)
滚动窗口的特点是:时间窗口大小和计算频次相同!
顾名思义,滚动窗口就像一个车轮一样滚滚向前,因为窗口大小和计算频次相同,所以窗口是紧密相连的,窗口内的数据不会重复计算。
举个例子,每隔1分钟计算商品过去1分钟的销量。
如下示例程序,每隔5秒计算过去5秒的订单销售额:
public class TumblingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<Order>() {@Overridepublic void run(SourceContext<Order> sourceContext) throws Exception {while (true) {Threads.sleep(1000);Order order = Order.mock();sourceContext.collectWithTimestamp(order, order.createTime);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).keyBy(i -> i.itemId).window(TumblingEventTimeWindows.of(Duration.ofSeconds(5L))).sum("orderAmount").print();environment.execute();}@Data@NoArgsConstructor@AllArgsConstructorpublic static class Order {public String itemId;public long orderAmount;public long createTime;static Order mock() {return new Order("001", ThreadLocalRandom.current().nextLong(100), System.currentTimeMillis());}}
}
这里采用滚动窗口计算模型,窗口大小和计算频次均是5秒,运行作业后,控制台会每隔5秒输出一次总销售额
1> TumblingWindow.Order(itemId=001, orderAmount=250, createTime=1722344630342)
1> TumblingWindow.Order(itemId=001, orderAmount=270, createTime=1722344635388)
1> TumblingWindow.Order(itemId=001, orderAmount=147, createTime=1722344640407)
1> TumblingWindow.Order(itemId=001, orderAmount=253, createTime=1722344645430)
......
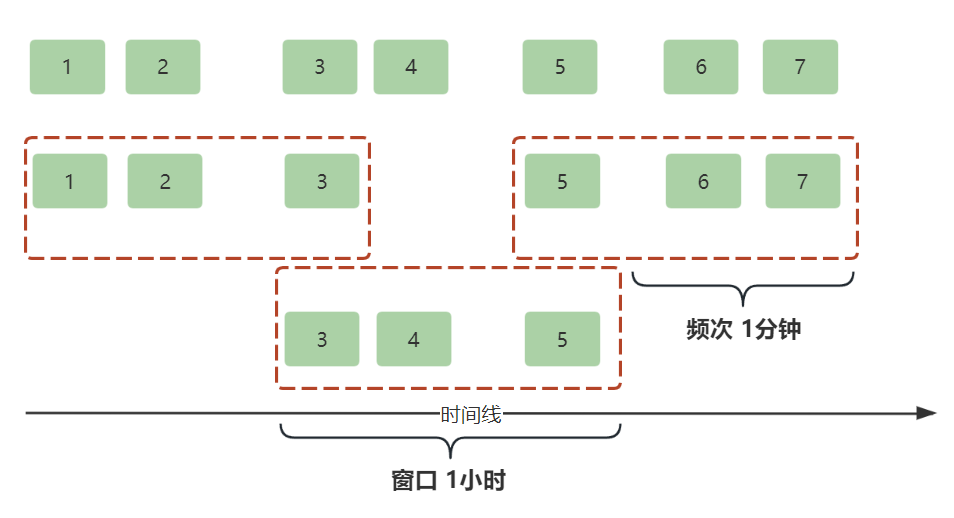
滑动窗口(Sliding Window)
滑动窗口的特点是:时间窗口大小和计算频次不相同,如果窗口大小大于计算频次,就会导致数据被重复计算;如果窗口大小小于计算频次,就会导致数据被漏计算;如果二者相等,那就是滚动窗口了。
举个例子,每隔1分钟计算商品过去1小时的销量。窗口大小为1小时,计算频次为1分钟,因此数据会被重复计算多次。
如下示例程序,每隔1秒计算过去5秒的订单销售额,部分订单会被重复计算多次:
public class SlidingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<TumblingWindow.Order>() {@Overridepublic void run(SourceContext<TumblingWindow.Order> sourceContext) throws Exception {while (true) {Threads.sleep(1000);TumblingWindow.Order order = TumblingWindow.Order.mock();sourceContext.collectWithTimestamp(order, order.createTime);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).keyBy(i -> i.itemId).window(SlidingEventTimeWindows.of(Duration.ofSeconds(5L), Duration.ofSeconds(1L))).sum("orderAmount").print();environment.execute();}
}
作业运行后,控制台每秒会输出一次过去5秒的销售额。
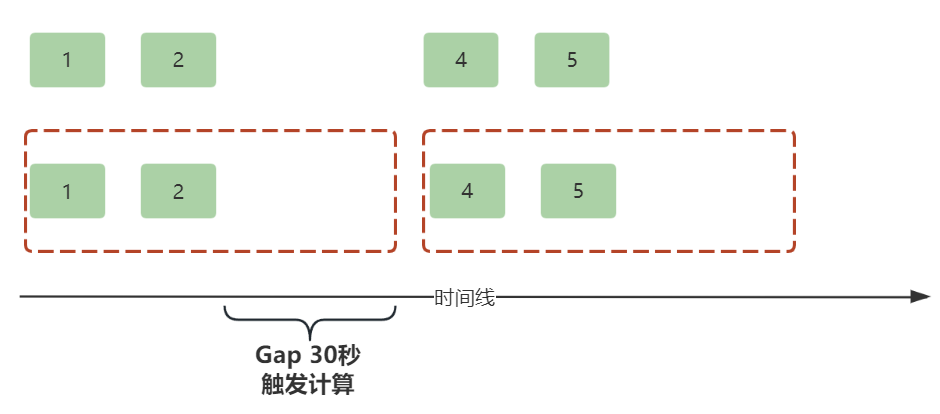
会话窗口(Session Window)
会话窗口的窗口大小和计算频次非常灵活,可以动态改变,每次都不一样。当窗口隔一段时间没有接收到新的数据,Flink就认为会话可以关闭并计算了,等下一次有新的数据进来,就会开启一个新的会话。这里的“隔一段时间”就是值会话窗口的间隔(Gap),这个间隔可以固定设置也可以动态设置。
举个例子,读书类APP都会有的一个功能,就是统计用户的阅读时长。用户必须有持续的动作,APP才会认为用户是真的在阅读,反之用户长时间没有操作,APP会认为用户已经离开,此时不会再统计阅读时长。
如下示例,随机5秒内模拟一次用户行为,会话窗口间隔设置为3秒,超过3秒认为用户离开,关闭窗口并统计用户阅读时长。
public class SessionWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<UserAction>() {@Overridepublic void run(SourceContext<UserAction> ctx) throws Exception {while (true) {UserAction userAction = UserAction.mock();ctx.collectWithTimestamp(userAction, userAction.time);ctx.emitWatermark(new Watermark(System.currentTimeMillis()));// 随机5秒内 用户才会有新的操作Threads.sleep(ThreadLocalRandom.current().nextLong(0L, 5000L));}}@Overridepublic void cancel() {}})// 超过三秒没有收到用户新的动作,认为用户离开,关闭窗口并计算.windowAll(EventTimeSessionWindows.withGap(Duration.ofSeconds(3L))).aggregate(new AggregateFunction<UserAction, UserReadingTime, UserReadingTime>() {@Overridepublic UserReadingTime createAccumulator() {return new UserReadingTime();}@Overridepublic UserReadingTime add(UserAction userAction, UserReadingTime userReadingTime) {// 记录窗口内的用户阅读开始和结束时间userReadingTime.userId = userAction.userId;if (userReadingTime.startTime == 0L) {userReadingTime.startTime = userAction.time;}userReadingTime.endTime = userAction.time;return userReadingTime;}@Overridepublic UserReadingTime getResult(UserReadingTime userReadingTime) {return userReadingTime;}@Overridepublic UserReadingTime merge(UserReadingTime userReadingTime, UserReadingTime acc1) {return null;}}).addSink(new SinkFunction<UserReadingTime>() {@Overridepublic void invoke(UserReadingTime value, Context context) throws Exception {System.err.println("用户" + value.userId + " 阅读了 " + (value.endTime - value.startTime) + " ms");}});environment.execute();}@Data@AllArgsConstructor@NoArgsConstructorpublic static class UserAction {public Long userId;public long time;public static UserAction mock() {return new UserAction(1L, System.currentTimeMillis());}}@Data@AllArgsConstructor@NoArgsConstructorpublic static class UserReadingTime {public Long userId;public long startTime;public long endTime;}
}
运行Flink作业,控制台随机输出用户的阅读时长
用户1 阅读了 3240 ms
用户1 阅读了 9414 ms
用户1 阅读了 138 ms
用户1 阅读了 2960 ms
时间语义
时间语义和时间窗口息息相关。
Flink 提供了三种不同的时间语义,分别是:处理时间、事件时间、摄入时间。
在不同的时间语义下,针对同样的数据,Flink 分配的时间窗口是不一样的。
举个例子,我们要统计某个商品过去1分钟的销量,这是个典型的一分钟大小的时间窗口。用户在 09:00:50 下了一笔订单,中间由于网络延时等原因,Flink 在 09:01:01 才收到这笔订单数据,恰巧此时 Flink 因为自身作业压力宕机崩溃,在 09:02:10 才恢复作业,该笔订单数据随即被 keyBy 分组发送给下游算子处理。
这个例子中的三个时间点,刚好对应了 Flink 的三种时间语义:
- 事件时间:事件发生的时间,通常数据本身会携带一个时间戳,即例子中的 09:00:50
- 摄入时间:Flink 数据源接收数据的subTask算子本地时间,即例子中的 09:01:01
- 处理时间:Flink 算子处理数据的机器本地时间,即例子中的 09:02:10
事件时间
事件时间是最常用的,在事件时间语义下,数据本身通常会携带一个时间戳,Flink 会根据该时间戳为数据分配正确的时间窗口。
因为事件时间是不会改变的,所以在事件时间语义下,Flink 窗口计算的结果始终是一致的,数据是清晰明确的。
但是,事件时间语义 会带来另一个问题。事件的产生是顺序的,但是数据在传输过程中,可能会因为网络拥塞等种种原因,到达 Flink 时乱序了。此时,Flink 如何处理这些乱序数据就是个麻烦事儿了。
举个例子,还是统计商品过去1分钟的销量,Flink 先是接收到事件时间为 09:00:30 的订单数据,此时将其分配到 [09:00,09:01] 窗口缓存起来,接着接收到了 09:01:30 的订单数据,此时 [09:00,09:01] 窗口可以关闭并计算了吗?显然不能,因为数据乱序到达的原因,谁也不能保证 Flink 待会不会收到 09:00 分钟产生的订单。
那怎么办呢?[09:00,09:01] 窗口总不能一直不关闭吧。为了解决这个问题,Flink 引入了 Watermark 机制,这里不做介绍。
使用事件时间对应的窗口分配器是:
- TumblingEventTimeWindows 基于事件时间的滚动窗口
- SlidingEventTimeWindows 基于事件时间的滑动窗口
- EventTimeSessionWindows 基于事件时间的会话窗口
如下示例,每秒生成一个带时间戳的随机数,数据用 Flink 自带的 Tuple2 封装,同时用 TumblingEventTimeWindows 让 Flink 基于事件时间语义来分配 5秒 的滚动窗口。运行 Flink 作业,控制台每隔5秒会输出前5秒的随机数之和。
public class TumblingWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();environment.addSource(new SourceFunction<Tuple2<Long, Long>>() {@Overridepublic void run(SourceContext<Tuple2<Long, Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);// f0是随机数 f1是时间戳Tuple2<Long, Long> tuple2 = new Tuple2<>(ThreadLocalRandom.current().nextLong(100), System.currentTimeMillis());sourceContext.collectWithTimestamp(tuple2, tuple2.f1);sourceContext.emitWatermark(new Watermark(System.currentTimeMillis()));}}@Overridepublic void cancel() {}}).windowAll(TumblingEventTimeWindows.of(Duration.ofSeconds(5L))).sum(0).print();environment.execute();}
}
控制台输出
// subTask任务ID 数字和 时间戳
19> (108,1722432788302)
20> (308,1722432790305)
21> (324,1722432795346)
总结一下,如果业务要按照事件发生的时间计算结果或分析数据,那么只能选事件时间语义。通常情况下,事件时间也确实更有价值。例如,利用Flink分析用户的行为日志,用户具体在什么时间点做了哪些行为,会更有分析价值,至于 Flink 是什么时候处理这些日志的,对业务方来说并不重要。因为事件时间具有不变性,所以基于事件时间统计的结果总是清晰明确的,缺点是数据到达Flink是乱序的,处理迟到数据会给Flink带来一定的压力。
摄入时间
摄入时间是指数据到达 Flink Source 算子的本地机器时间,它为处理数据流提供了一种相对简单而直观的时间参考,算是在 事件时间 和 处理时间 中间做了一个折中。
摄入时间具备一定的优势。一方面,它避免了事件时间的乱序问题,相较于事件时间具备更高的处理效率;另一方面,相较于处理时间而言,它具备不变性,计算产生的结果也会更加准确。
摄入时间适用于那些对时间精度要求不是特别高,但又希望时间能够相对反映数据进入系统先后顺序的场景。
如下示例,使用摄入时间语义计算过去5秒窗口生成的随机数之和。因为用的是摄入时间,所以无须发送 Watermark,数据本身也无须携带时间戳。
public class IngestionTimeFeature {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// 采用摄入时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);environment.addSource(new SourceFunction<Tuple1<Long>>() {@Overridepublic void run(SourceContext<Tuple1<Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);sourceContext.collect(new Tuple1<>(ThreadLocalRandom.current().nextLong(100)));}}@Overridepublic void cancel() {}}).keyBy(IN -> "all").timeWindow(Time.of(5L, TimeUnit.SECONDS)).sum(0).print();environment.execute();}
}
处理时间
处理时间语义是指数据实际被处理的时间,也就是数据到达Window算子时subTask机器的本地时间。
因为 处理时间语义 完全依靠算子的机器本地时间,所以时间窗口在划分数据和触发计算,都只需要依靠本地时间来驱动,性能是最好的,延迟低,适用于对高性能和延迟敏感的业务。
同样的,处理时间语义也有它的劣势。因为采用的是subTask算子的本地时间,所以数据的时间其实是具备不确定性的。举个例子,订单数据在 09:00:01 被算子接收,它会被分配到 [09:00,09:01]窗口,假设此时该subTask作业故障宕机,等到 09:10:00 才恢复,Flink 重新消费这条数据,它又会被分配到 [09:10,09:11] 窗口,产出的数据就会不一致。因此在使用处理时间语义时,要保证业务方能接受这种因为异常情况导致的计算结果不符合预期的场景。
如下示例,采用处理时间语义,因为是采用subTask本地时间,所以同样也不需要发送 Watermark。
public class ProcessTimeFeature {public static void main(String[] args) throws Exception {StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// 采用处理时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);environment.addSource(new SourceFunction<Tuple1<Long>>() {@Overridepublic void run(SourceContext<Tuple1<Long>> sourceContext) throws Exception {while (true) {Threads.sleep(1000);sourceContext.collect(new Tuple1<>(ThreadLocalRandom.current().nextLong(100)));}}@Overridepublic void cancel() {}}).windowAll(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5L))).sum(0).print();environment.execute();}
}
尾巴
Flink 具有丰富的时间语义,包括事件时间、处理时间和摄入时间。事件时间基于数据本身携带的时间戳,处理时间基于系统处理数据的本地时钟,摄入时间则是数据进入 Flink Source算子的时间。
时间窗口是 Flink 处理流式数据的重要方式,Flink 提供了 滚动窗口、滑动窗口、会话窗口 三种窗口类型。滚动窗口有固定大小且不重叠,滑动窗口大小固定且可重叠,会话窗口根据数据间隔来划分。合理选择时间语义和时间窗口,能更准确有效地处理和分析流式数据。
相关文章:
Flink时间语义和时间窗口
前言 在实际的流计算业务场景中,我们会发现,数据和数据的计算往往都和时间具有相关性。 举几个例子: 直播间右上角通常会显示观看直播的人数,并且这个数字每隔一段时间就会更新一次,比如10秒。电商平台的商品列表&a…...

在wpf中登录成功之后怎么设置主页布局及点击不同的菜单跳转到不同的页面,这个是我们做wpf项目必要会的一个功能
通过frame与page实现在mvvm下的页面跳转 在wpf中登录成功之后怎么设置主页布局及点击不同的菜单跳转到不同的页面_哔哩哔哩_bilibili 1、MainWindow代码 <DockPanel><StackPanel DockPanel.Dock"Top" Height"40"><Grid><Grid.ColumnD…...

基于opencv的人脸闭眼识别疲劳监测
1. 项目简介 本项目旨在实现基于眼部特征的眨眼检测,通过监测眼睛开闭状态来计算眨眼次数,从而应用于疲劳监测、注意力检测等场景。使用了面部特征点检测算法,以及眼部特征比率(EAR, Eye Aspect Ratio)来判断眼睛的闭…...

aeo认证需要什么材料
AEO(Authorized Economic Operator)认证,即经认证的经营者认证,是企业信用管理体系的一种高级认证。申请AEO认证时,企业需要准备一系列的材料以证明其符合认证标准。以下是一份详细的AEO认证申请材料清单: …...

【iOS】YYModel
目录 什么是YYModel ? 如何使用YYModel ? 最简单的Model 与网络请求结合 属性为容器类的Model 白名单和黑名单 Model的嵌套 结语 什么是YYModel ? YYModel是一个用于 iOS 和 macOS 开发的高性能的模型框架,主要用于对象和…...

Cadence元件A属性和B属性相互覆盖
最近在使用第三方插件集成到Cadence,协助导出BOM到平台上,方便对BOM进行管理和修改,结果因为属性A和属性B不相同,导致导出的BOM错误。如下图: 本来我们需要导出Q12,结果给我们导出了Q13,或者反之&…...

【火山引擎】语音合成 | HTTP接口 | 一次性合成 | python
目录 一 准备工作 二 HTTP接口(一次性合成-非流式) 1 接口说明 2 身份认证 3 请求方式 三 实践 四 注意事项 火山引擎语音合成TTS(Text-to-Speech)是一种基于云计算的语音合成服务,可以将文本转化为自然、流畅的语音。以下是火山引擎TTS的主要功能和特点: ①多种语音…...

YOLOv11改进-卷积-空间和通道重构卷积SCConv
本篇文章将介绍一个新的改进模块——SCConv(小波空间和通道重构卷积),并阐述如何将其应用于YOLOv11中,显著提升模型性能。为了减少YOLOv11模型的空间和通道维度上的冗余,我们引入空间和通道重构卷积。首先,…...

记录一次从nacos配置信息泄露到redis写计划任务接管主机
经典c段打点开局。使用dddd做快速的打点发现某系统存在nacos权限绕过 有点怀疑是蜜罐,毕竟nacos这实在是有点经典 nacos利用 老规矩见面先上nacos利用工具打一波看看什么情况 弱口令nacos以及未授权访问,看这记录估计被光顾挺多次了啊 手动利用Nacos-…...

Unity加载界面制作
效果 UI部分 结构 说下思路: 因为是加载界面,所以最上层是一个Panel阻止所有的UI交互,这个Panel如果有图片就加一个图片,如果没有可以把透明度调到最大,颜色设为黑色. 下面最核心的就是一个进度条了,有图片的话,将进度条的底放进来,将进度条锚点设为下中,将滑动块的尺寸设为0.…...

最好的ppt模板网站是哪个?做PPT不可错过的18个网站!
现在有很多PPT模板网站,但真正免费且高质量的不多,今天我就分享主流的国内外PPT模板下载网站,并且会详细分析这些网站的优缺点,这些网站都是基于个人实际使用经验的,免费站点会特别标注,让你可以放心下载&a…...

煤矿安全监测监控作业题库
第一部分 安全法律法规知识子题库 单选题 1.《安全生产法》规定,生产经营单位应当向从业人员如实告知作业场所和工作岗位存在的(A)、防范措施以及事故应急措施。 A. 危险因素 B. 人员状况 C. 设备状况 D. 环境状况 2.《安全生产法》规定&…...

【记录】Django数据库的基础操作
数据库连接 在Django中使用 mysqlclient 这个包用于数据库的连接,切换至 Django环境中直接 pip install mysqlclient 安装此包 1 数据库连接配置 在项目目录下的setting.py中配置 DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: mini,#数据库名US…...

XHCI 1.2b 规范摘要(五)
系列文章目录 XHCI 1.2b 规范摘要(一) XHCI 1.2b 规范摘要(二) XHCI 1.2b 规范摘要(三) XHCI 1.2b 规范摘要(四) XHCI 1.2b 规范摘要(五) 文章目录 系列文章目…...

小程序短链接生成教程
文章目录 一、小程序短链接(必须发布正式的小程序才能生成短链接!!!)二、使用步骤1.获取token信息2.获取短链接 总结 一、小程序短链接(必须发布正式的小程序才能生成短链接!!&#…...

C++进阶之路:再谈构造函数、static成员、友元(类与对象_下篇)
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

C 函数指针与回调函数
C 函数指针与回调函数 在C语言中,函数指针和回调函数是两个非常强大的概念,它们在提高代码的灵活性和模块化方面发挥着重要作用。本文将详细介绍C语言中的函数指针和回调函数,包括它们的定义、用法和实际应用场景。 函数指针 定义 函数指…...

CTF(九)
导言: 本文主要讲述在CTF竞赛网鼎杯中,web类题目AreUSerialz。 靶场链接:BUUCTF在线评测 一,分析代码。 看到了一大段php代码。 <?php// 引入flag.php文件 include("flag.php");// 高亮显示当前文件 highlight…...

三种单例实现
1、不继承Mono的单例 实现 使用 注: 使用需要继承BaseManager 泛型填写自己本身 需要实现无参构造函数 2、挂载式的Mono单例 实现 使用 注: 使用需要继承SingletonMono 泛型填写自己本身 需要挂载在unity引擎面板 3、不用挂载式的单例 实现 使…...

Spring XML配置方式和Spring Boot注解方式的详细对照关系
功能/配置项Spring XML配置方式Spring Boot注解方式定义Beanxml <bean id"myBean" class"com.example.MyBean"/>javaBeanpublic MyBean myBean() { return new MyBean(); }注入Beanxml <bean id"myBean" class"com.example.MyBea…...

VirtualRouter:3分钟将Windows电脑变身为免费WiFi热点
VirtualRouter:3分钟将Windows电脑变身为免费WiFi热点 【免费下载链接】VirtualRouter Wifi Hotspot for Windows computers (Windows 7, 8.x, Server 2012 and newer!) 项目地址: https://gitcode.com/gh_mirrors/vi/VirtualRouter 你是否曾遇到这样的情况&…...

OAI 5G核心网搭建后,如何用Docker命令进行日常运维和故障排查?
OAI 5G核心网Docker运维实战:从日志分析到故障排查 当OAI 5G核心网完成基础部署后,真正的挑战才刚刚开始。面对由多个容器组成的复杂系统,如何快速定位AMF拒绝注册的原因?SMF的PDU会话建立失败该如何排查?本文将分享一…...

use Hyperf\View\View;的生命周期的庖丁解牛
它的本质是:Hyperf\View\View 不是一个简单的工具类,而是一个由 Hyperf DI 容器管理的 服务实例 (Service Instance)。它的生命周期始于 容器启动时的元数据注册,经历 请求触发时的懒加载/实例化,执行 模板解析与渲染,…...

如何彻底解决JavaScript浮点数精度问题:decimal.js完整指南
如何彻底解决JavaScript浮点数精度问题:decimal.js完整指南 【免费下载链接】decimal.js An arbitrary-precision Decimal type for JavaScript 项目地址: https://gitcode.com/gh_mirrors/de/decimal.js 你是否曾经遇到过JavaScript中0.1 0.2 ≠ 0.3的尴尬…...

深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术
深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术 【免费下载链接】battery-charging-data-of-on-road-electric-vehicles This repository is transfered from the personal account of Dr. Zhognwei Deng (Michael Teng) 项目地址: …...

保姆级教程:手把手教你用MuJoCo和Spinning Up让UR5机械臂学会‘指哪打哪’
从零实现UR5机械臂强化学习控制:MuJoCo与Spinning Up实战指南 看着实验室里崭新的UR5机械臂,你是否想过让它像人类手臂一样灵活地指向任意位置?传统控制方法需要复杂的运动学计算,而强化学习能让机械臂通过"试错"自主掌…...

UWB车内目标探测技术【附仿真】
✨ 长期致力于UWB雷达、活体、目标检测、生命体征、信号模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)UWB雷达生命体征信号建模与自适应杂波抑制…...
深度集成:让 AI 安全执行企业 API)
函数调用(Function Calling)深度集成:让 AI 安全执行企业 API
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 5/10 篇,当前这篇会重点解决:展示如何让 AI 安全可控地操作企业后端服务,实现真正的智能体能力。 上一篇回顾:第 4 篇《检索增强生成(RAG)实战:Spring AI 集成向量数据库实现知识问…...

构建可靠AI编码代理:OpenClaw-Build工作流详解与实战
1. 项目概述:一个能“闭环”的AI编码代理工作流如果你用过市面上那些号称能自动编程的AI代理,大概率经历过这样的挫败感:你满怀期待地丢给它一个需求,它吭哧吭哧干了两三个任务,然后要么开始“神游”,写出来…...
)
告别手动建模!用ArcGIS+SWMM+慧天平台,5步搞定城市内涝模拟(附实战数据)
城市内涝模拟实战:ArcGISSWMM慧天平台高效协同工作流 暴雨过后街道成河、地下车库变泳池的场景,已成为许多城市规划者和工程师的噩梦。传统的内涝模拟方法需要手动处理海量管网数据,不仅耗时费力,还容易在数据转换过程中丢失关键信…...