Milvus 到 TiDB 向量迁移实践
作者: caiyfc 原文来源: https://tidb.net/blog/e0035e5e
一、背景
我最近在研究使用向量数据库搭建RAG应用,并且已经使用 Milvus、Llama 3、Ollama、LangChain 搭建完成。最近通过活动获取了 TiDB Cloud Serverless 使用配额,于是打算把 Milvus 已完成的向量数据给迁移到 TiDB Cloud Serverless 中。
经过查阅相关资料,我发现向量数据迁移的工具还不支持从 Milvus 迁移到 TiDB。那就无法迁移了吗?不,虽然现有的工具不能迁移,但是我可以手动迁移。于是就有了这篇文章。
TiDB Cloud Serverless 活动地址: 【TiDB 社区福利】贡献开源代码的开发者看过来!最高可获得超 14,000 元的 TiDB Cloud Serverless 云资源额度
搭建RAG应用方法: 手把手系列 | 使用Milvus、Llama 3、Ollama、LangChain本地设置RAG应用
二、迁移方案
要做数据迁移,首先需要确定迁移方案。最简单的迁移就两个步骤:数据从源库导出、数据导入到目标库,这样就完成了数据迁移。
但是这次就不同了。RAG应用使用了 LangChain,根据调研,LangChain 在 Milvus 和在 TiDB 中创建的结构是不同的。
在 Milvus 中的 collection 名称是:LangChainCollection,结构是: 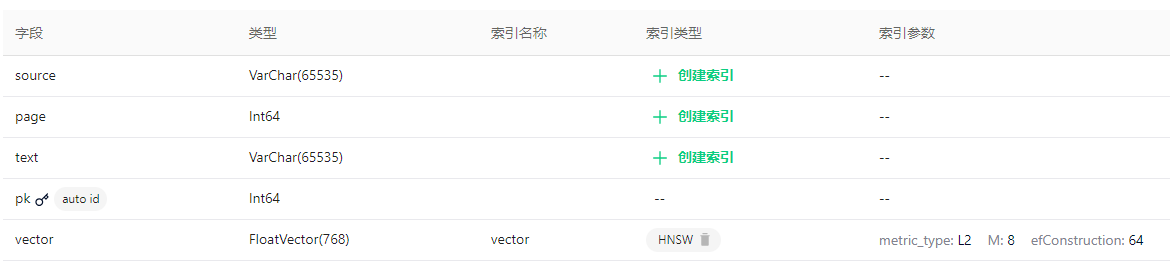
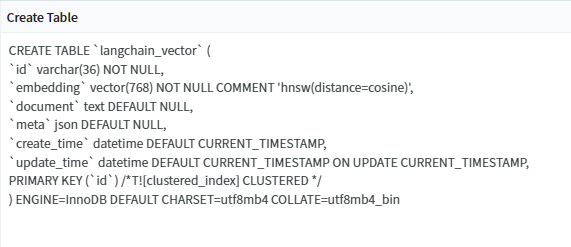
但是在 TiDB 中的table 名称是:langchain_vector,结构是:
在 LangChain 的文档中也有说明: 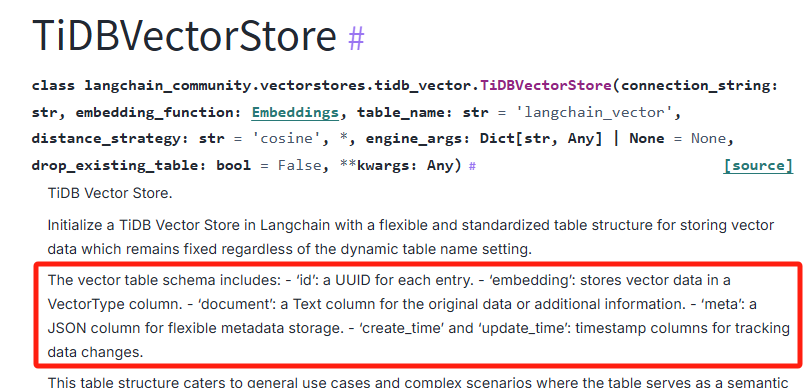
那么这次数据迁移就需要多增加两个步骤了:数据整理、表结构调整。而这两个又是异构数据库,所以导出的数据格式选择较为通用的csv。
整体方案如下:

三、Milvus 数据导出
根据 Milvus 的官方文档,没找到能直接把数据导出成 csv 文件的工具,但是我可以用 python 的 SDK 来把数据读取出来,然后存成 csv 文件。
import csv
from pymilvus import connections, Collection
# 连接到 Milvus
connections.connect("default", host="10.3.xx.xx", port="19530")
# 获取 Collection
collection = Collection("LangChainCollection")
# 分页查询所有数据
limit = 1000
offset = 0
all_results = []
while True:# 传递 expr 参数,使用一个简单的条件查询所有数据results = collection.query(expr="", output_fields=["pk", "source", "page", "text", "vector"], limit=limit, offset=offset)if not results:breakall_results.extend(results)offset += limit
# 打开 CSV 文件,准备写入数据
with open("milvus_data.csv", "w", newline="", encoding='utf-8') as csvfile:# 定义 CSV 列名fieldnames = ["pk", "source", "page", "text", "vector"]writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入表头writer.writeheader()
# 写入每一条记录for result in all_results:# 解析 JSON 数据,提取字段vector_str = ','.join(map(str, result.get("vector", []))) # 将向量数组转换为字符串writer.writerow({"pk": result.get("pk"), # 获取主键"source": result.get("source"), # 获取源文件"page": result.get("page"), # 获取页码"text": result.get("text"), # 获取文本"vector": vector_str # 写入向量数据})
print(f"Total records written to CSV: {len(all_results)}")
导出的 csv 文件数据的格式为:

四、数据整理、表结构整理
我用少量测试数据转换成向量,使用 LangChain 加载到 TiDB Cloud 中了。这样就得到了 TiDB Cloud 中的数据结构及数据格式了。
表结构为:
CREATE TABLE `langchain_vector` (
`id` varchar(36) NOT NULL,
`embedding` vector(768) NOT NULL COMMENT 'hnsw(distance=cosine)',
`document` text DEFAULT NULL,
`meta` json DEFAULT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
可以在 TiDB Cloud 中直接创建该表。
导出成 csv 的数据格式为(省略部分内容):
"id","embedding","document","meta","create_time","update_time"
"00a2ad02-eff5-4649-947f-820db0d24afa","[-0.08534411,0.048610855,0.018906716,0.023978366,***********-0.023846595,0.06352842,0.07482053]","— 22 — (七)移交利用共用部位、共用设施设备经营的相关资料、\n物业服务费用和公共水电分摊费用交纳记录等资料; (八)法律、法规员会和物业服务企业。","{\"page\": 21, \"source\": \"./湖北省物业服务和管理条例.pdf\"}","2024-10-15 08:18:16","2024-10-15 08:18:16"
已知 Milvus 导出的 csv 的数文件,根据对应关系,其实就是embedding 对应 vector,document 对应 text,meta 对应 page加source。这样逻辑就清晰了。根据对应关系编写数据整理的脚本:
import pandas as pd
import json
from uuid import uuid4
from datetime import datetime
# 读取CSV文件
input_csv = 'milvus_data.csv' # 替换为你的CSV文件名
df = pd.read_csv(input_csv)
# 创建新的DataFrame
output_data = []
for _, row in df.iterrows():# 提取需要的字段id_value = str(uuid4()) # 生成唯一IDembedding = f"[{','.join(row['vector'].split(','))}]" # 将vector转换为嵌入格式document = row['text']# 生成meta信息meta_dict = {"page": row['page'], "source": row['source']}meta = json.dumps(meta_dict, ensure_ascii=False) # 首先生成正常的JSON# meta = meta.replace('"', '\\"') # 转义双引号
create_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")update_time = create_time # 更新时同样的时间
# 添加到输出数据output_data.append({"id": id_value,"embedding": embedding,"document": document,"meta": meta,"create_time": create_time,"update_time": update_time})
# 转换为DataFrame
output_df = pd.DataFrame(output_data)
# 保存为CSV文件
output_csv = 'output.csv' # 输出文件名
output_df.to_csv(output_csv, index=False, quoting=1) # quoting=1用于确保字符串加引号
print(f"转换完成,已保存为 {output_csv}")
数据整理完成后,就可以导入数据到 TiDB Cloud 中了。
五、导入数据到 TiDB Cloud
TiDB Cloud 提供三种导入方式:

本次使用本地上传的方式。
小于 50MiB 的 csv文件可以使用第一种上传本地文件的方式,如果文件大于 50 MiB,可以使用脚本将文件拆分为多个较小的文件再上传:
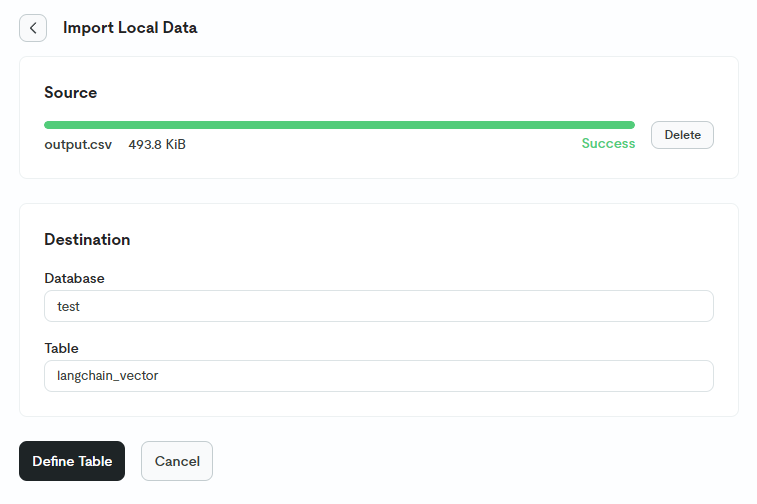
上传文件后,选择已经创建好的库和表,点击 define table :
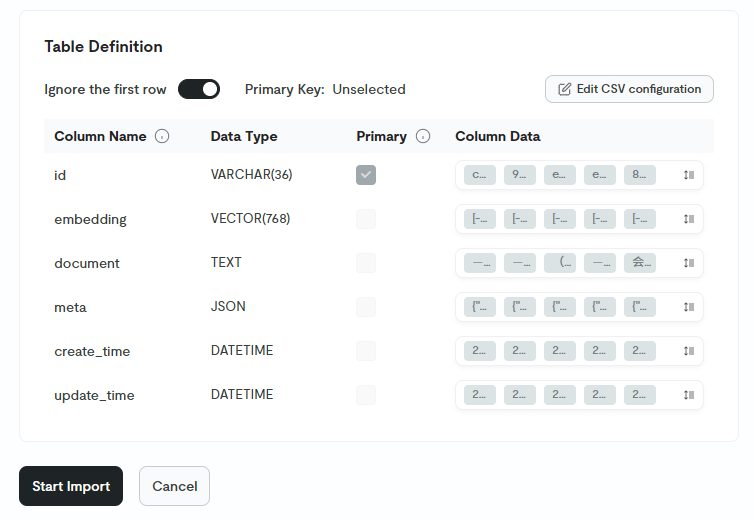
调整好对应关系,点击 start import 即可

更多的导入方式可以查看文档: Migration and Import Overview
六、验证结果
数据成功导入之后,就需要开始验证数据了。于是我修改了 RAG应用的代码,分别从 Milvus 和 TiDB 中读取向量数据,使用同一个问题,来让大模型返回答案,查看答案是否类似。
from langchain_community.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain import hub
from langchain.chains import RetrievalQA
from langchain.vectorstores.milvus import Milvus
from langchain_community.embeddings.jina import JinaEmbeddings
from langchain_community.vectorstores import TiDBVectorStore
import os
llm = Ollama(
model="llama3",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]
),
stop=["<|eot_id|>"],
)
embeddings = JinaEmbeddings(jina_api_key="xxxx", model_name="jina-embeddings-v2-base-zh")
vector_store_milvus = Milvus(embedding_function=embeddings,connection_args={"uri": "http://10.3.xx.xx:19530"},
)
TIDB_CONN_STR="mysql+pymysql://xxxx.root:password@host:4000/test?ssl_ca=/Downloads/isrgrootx1.pem&ssl_verify_cert=true&ssl_verify_identity=true"
vector_store_tidb = TiDBVectorStore(connection_string=TIDB_CONN_STR,embedding_function=embeddings,table_name="langchain_vector",
)
os.environ["LANGCHAIN_API_KEY"] = "xxxx"
query = input("\nQuery: ")
prompt = hub.pull("rlm/rag-prompt")
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vector_store_milvus.as_retriever(), chain_type_kwargs={"prompt": prompt}
)
print("milvus")
result = qa_chain({"query": query})
print("\n--------------------------------------")
print("tidb")
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vector_store_tidb.as_retriever(), chain_type_kwargs={"prompt": prompt}
)
result = qa_chain({"query": query})
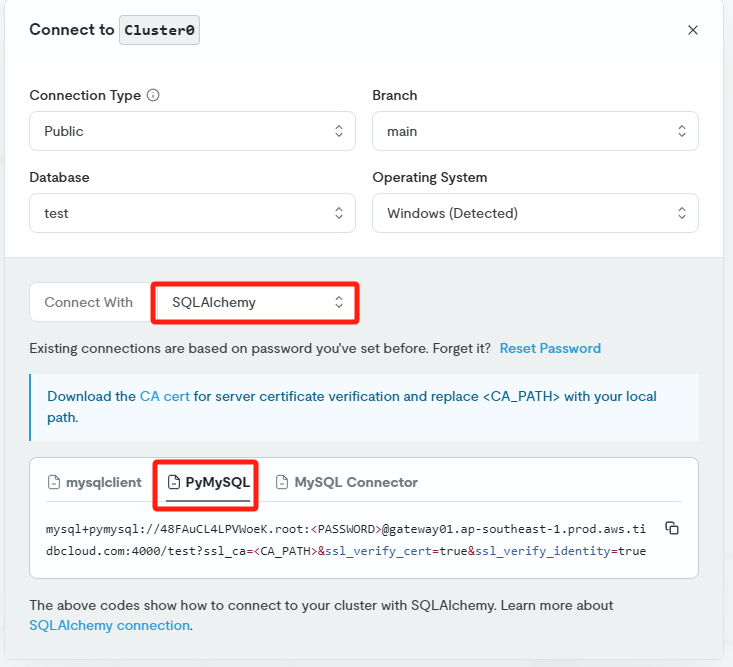
其中 TiDB 的连接串可以直接从 TiDB Cloud 中获取:
向 RAG 应用提问之后,查看回答,发现 Milvus 和 TiDB 的回答基本一致,说明向量迁移是成功的。还可以更进一步,比对数据条数,如果一致,那么迁移应该已经成功,没有丢失数据。
RAG 应用的执行结果如下图:

七、总结
不同数据库之间的数据迁移,本质上是将数据转换为所有数据库都能识别的通用格式,向量数据也不例外。本次迁移与传统的关系型数据库迁移有所不同,尽管 RAG 应用使用了 LangChain,但 LangChain 针对不同的数据库,创建的表结构和数据格式是不同的,因此需要对数据和表结构进行额外的整理,才能顺利将数据迁移至目标数据库。值得庆幸的是,TiDB Cloud 提供了多种便捷的数据导入方式,使迁移过程相对简单。
相关文章:
Milvus 到 TiDB 向量迁移实践
作者: caiyfc 原文来源: https://tidb.net/blog/e0035e5e 一、背景 我最近在研究使用向量数据库搭建RAG应用,并且已经使用 Milvus、Llama 3、Ollama、LangChain 搭建完成。最近通过活动获取了 TiDB Cloud Serverless 使用配额ÿ…...

springboot集成jsoup解析xml文件
springboot集成jsoup解析xml文件 1、引入依赖2、xml转成需要的map结构3、测试数据 1、引入依赖 <dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.16.2</version></dependency>2、xml转成需…...

基于Springboot相亲网站系统的设计与实现
基于 Springboot相亲网站系统的设计与实现 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:idea 源码获取:https…...

解决提示”warning C317 attempt to redefine macro ‘XX‘“问题
今天来分享一个之前在开发时候遇到的一个告警,是一个关于不正当使用宏定义产生的告警。 先看告警提示:warning C317: attempt to redefine macro ‘WIFI_UART_SEND_BUF’; 意思是该宏定义存在重新定义; 而为什么编译器会这样提示…...

3D图片动画效果组件封装
1.效果 3D图片动画效果 2.组件部分 import "./index.less"/*** 3D图片动画效果* pictures: 图片数组[封面,英雄,标题]*/ export const Picture3D (props: any) > {console.log("3D图片动画效果", props)return <divclassNamepicture3DonClick{prop…...

高级优化算法之 fminunc函数 实践
说明 在本专栏机器学习_墨#≯的博客-CSDN博客前面几篇文章中,大多采用梯度下降法来求解。其实还有很多的高级优化算法可以用来求解回归和分类问题,本文就是在吴恩达机器学习视频课程[1]的启示下,想要简单尝试一下Matlab自带的无约束多变量函数…...

1.5 ROS架构
到目前为止,我们已经安装了ROS,运行了ROS中内置的小乌龟案例,并且也编写了ROS小程序,对ROS也有了一个大概的认知,当然这个认知可能还是比较模糊并不清晰的,接下来,我们要从宏观上来介绍一下ROS的…...

Redis Search系列 - 第四讲 支持中文
目录 一、支持中文二、自定义中文词典2.1 Redis Search设置FRISOINI参数2.2 friso.ini文件相关配置1)自定义friso UTF-8字典2)修改friso.ini配置文件 三、实测中文分词效果 一、支持中文 Redis Stack 从版本 0.99.0 开始支持中文文档的添加和分词。中文…...

架构师备考-架构图设计案列
本文中所涉及的架构图主要参考软考-架构设计师历年Web 架构设计案例真题,在其基础上进行补充说明。 历年软考架构师案例题-Web架构设计考点 2014 MVC 架构2015、2016 J2EE 架构2017 经典网络架构2018 SOA 架构2019 分布式架构2020 SSM 架构2021 云平台架构2022 物…...

专业级Facebook直播工具推荐:提升你的直播体验
随着社交媒体的迅速发展,直播已成为现代内容传播的重要方式。Facebook作为全球最大的社交平台之一,为用户和企业提供了丰富的直播功能,吸引了众多观众和参与者。在这个竞争激烈的环境中,如何打造高质量的直播内容显得尤为重要。本…...
:Cors的设置及.env文件的设置)
【NodeJS】NodeJS+mongoDB在线版开发简单RestfulAPI (三):Cors的设置及.env文件的设置
本项目旨在学习如何快速使用 nodejs 开发后端api,并为以后开展其他项目的开启提供简易的后端模版。(非后端工程师) 由于文档是代码写完之后,为了记录项目中需要注意的技术点,因此文档的叙述方式并非开发顺序࿰…...

[python flask 数据库ORM操作]
一、链接数据库 我们选择的框架是flask-sqlAlchemy 这个框架是对pymysql的封装。 连接数据库 #导入包 from flask_sqlalchemy import SQLAlchemy #创建flask app对象 app Flask(__name__) #设置配置信息 HOSTNAME "localhost" PORT 3306; USERNAME "root&…...

【JavaScript】如何优雅的编码if判断中的一个变量多个或条件
前言 你是否写过这样代码: ...if (status 1 || status 4 || status 6)...代码场景是这样的,记录有多个状态,当状态等于1,4,6时要做相同的逻辑。今天我们就分享一下如何简化写法,让代码更好看,更优雅。 使用 switch 语句 ...…...

SaaS云诊所系统源码,基于云计算技术的SAAS模式诊所管理系统,适用于诊所、门诊、卫生服务站、卫生站
SaaS云诊所管理系统源码,门诊管理系统源码,诊所药店云平台源码 云诊所管理系统是基于云计算的SAAS模式诊所管理系统,全面适用于诊所、门诊、卫生服务站、卫生站、卫生所、中医馆、药店、私人个体诊所、中小型门诊、乡村卫生室、医务室以及社…...

字节,AI产品经理面试,拿下offer!
如果大家最近打算找ai产品经理这方面的工作,可以对照着脑图准备起来啦。 这篇文章给大家讲解两道高频问题: 1)AI产品经理和传统产品经理有什么区别 2)AI 产品经理的工作职责和能力要求是什么? 这两个问题看似简单&a…...

Postgresql pgsql 插件之postgis 安装配置
相关链接: pgsql编译安装 一、说明 postgis是pgsql最强大的几个插件之一,可以用于地理信息系统(gis)的搭建 二、插件安装启动 由于我的pgsql是编译安装的,所以插件也是编译安装,更加灵活。 1.进入到源…...

单片机STC8H8K64U开发板_RA6809开发板 驱动彩屏显示
单片机STC8H8K64U开发板,型号RT8H8K001 预留Type C接口,可供电SWD下载: RA6809开发板,型号RT6809CNN01 预留Type C接口供电,预留MCU接口、电容触摸屏接口、液晶屏接口: 双臂合一,驱动和控…...

Redis底层和缓存雪崩,击穿,穿透
一、Redis的数据结构 1.动态字符串 我们知道Redis中保存的Key是字符串,value往往hi字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。不过,Redis 没有直接使用c语言的字符串,因为c语言字符串存在许多问题: …...

[Java基础] 集合框架
往期回顾 [Java基础] 基本数据类型 [Java基础] 运算符 [Java基础] 流程控制 [Java基础] 面向对象编程 [Java基础] 集合框架 [Java基础] 输入输出流 [Java基础] 异常处理机制 [Java基础] Lambda 表达式 目录 List 接口 数据结构 最佳实践 实战代码 Set 接口 数据…...

机器学习基础:算法如何让 AI 自我学习
大家好,我是Shelly,一个专注于输出AI工具和科技前沿内容的AI应用教练,体验过300款以上的AI应用工具。关注科技及大模型领域对社会的影响10年。关注我一起驾驭AI工具,拥抱AI时代的到来。 AI工具集1:大厂AI工具【共23款…...

开源项目metabase-mcp-server:用MCP协议连接Metabase与AI智能体,实现对话式数据分析
1. 项目概述:当开源BI工具遇上AI智能体如果你和我一样,在日常工作中既要用Metabase做数据可视化看板,又要和Claude、Cursor这类AI助手打交道,那你肯定也遇到过这样的痛点:想问问AI“上个月华东区的销售额趋势”&#x…...

Drogon框架数据库连接监控终极指南:性能指标与智能告警机制
Drogon框架数据库连接监控终极指南:性能指标与智能告警机制 【免费下载链接】drogon Drogon: A C14/17/20 based HTTP web application framework running on Linux/macOS/Unix/Windows 项目地址: https://gitcode.com/gh_mirrors/dr/drogon Drogon是一个基于…...

iOS设备支持文件管理解决方案:如何解决Xcode开发环境兼容性问题
iOS设备支持文件管理解决方案:如何解决Xcode开发环境兼容性问题 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport iOSDeviceSupport项目为iOS开发者提供了全面的设备支…...

网络安全事件报告:从SolarWinds事件看全球合规挑战与应对策略
1. 事件回顾:SolarWinds事件为何成为安全领域的“分水岭”如果你在网络安全或IT运维领域工作,2020年底曝光的SolarWinds供应链攻击事件,绝对是一个绕不开的里程碑。它不像一次简单的数据泄露,更像是一场精心策划、潜伏已久的“数字…...

离散流匹配与MaskFlow框架:视频生成技术解析
1. 离散流匹配在视频生成中的技术演进 视频生成技术近年来取得了显著进展,但长视频生成仍然面临两大核心挑战:一是如何有效建模视频中复杂的时空动态关系,二是如何在有限的计算资源下实现高效生成。传统方法通常采用固定长度的训练序列&…...

冻|结D球 2026
通过网盘分享的文件:冻|结D球 2026 链接: https://pan.baidu.com/s/1-bhxibfD69ahEoufeQFRRQ?pwdhygv 提取码: hygv...

WP Pinch:通过MCP协议为WordPress站点集成AI助手管理能力
1. 项目概述:当你的WordPress站点“长出”AI的爪子 如果你和我一样,每天大部分时间都泡在Slack、Telegram或者WhatsApp里,和团队沟通、处理信息,那么你肯定也烦透了那种“这个内容不错,等我回到电脑前再发到网站上”的…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

SLV:用AI对话驱动Solana节点部署与运维的革命性工具
1. 项目概述:SLV,一个为Solana节点管理注入AI灵魂的工具如果你在Solana生态里跑过验证器节点或者搭建过RPC服务,那你一定对下面这套流程不陌生:找一台靠谱的服务器,手动SSH连上去,一行行敲命令安装依赖、编…...

3步精通MOOTDX:量化投资数据接口实战指南
3步精通MOOTDX:量化投资数据接口实战指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专为量化投资和数据分析设计的Python库,它提供了高效、便捷的通达信数…...