使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML
使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML:详解与示例
在 Web 开发和数据分析中,解析 HTML 是一个常见的任务,尤其是当你需要从网页中提取数据时。Python 提供了多个库来处理 HTML,其中最受欢迎的就是 BeautifulSoup,它属于 bs4 模块。无论 HTML 结构是简单的还是复杂的,BeautifulSoup 都可以帮你轻松地从中提取出所需的数据。
本文将介绍如何使用 bs4 的 BeautifulSoup 库来解析复杂的 HTML 内容。我们将一步步讲解 BeautifulSoup 的基础知识、使用方法,并通过示例展示如何处理复杂的 HTML 结构。

一、什么是 BeautifulSoup?
BeautifulSoup 是一个用于解析 HTML 和 XML 的 Python 库,它将网页解析为一个易于遍历的树状结构,并提供了丰富的方法来查找和提取其中的元素。通常,我们将 BeautifulSoup 与 requests 库结合使用,用于获取和解析网页内容。
主要功能包括:
- HTML 解析:支持 HTML 和 XML 格式的文档。
- 数据提取:从复杂的 HTML 结构中提取所需数据。
- 标签处理:允许你通过标签名称、属性、文本内容等进行元素查找。
二、安装 BeautifulSoup
在使用 BeautifulSoup 之前,你需要先安装它以及用于进行网络请求的 requests 库。使用以下命令来安装:
pip install beautifulsoup4 requests
安装完成后,就可以开始解析 HTML 文档了。
三、BeautifulSoup 的基本用法
1. 加载 HTML 内容
首先,我们需要通过 requests 库获取网页的 HTML 内容,然后将其传递给 BeautifulSoup 进行解析。以下是一个简单的示例:
import requests
from bs4 import BeautifulSoup# 获取网页内容
url = "https://example.com"
response = requests.get(url)# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, "html.parser")
在这个例子中,我们首先使用 requests.get() 从指定网址获取网页内容,然后使用 BeautifulSoup 的 html.parser 解析器将 HTML 文档解析为一个可遍历的树结构。
2. 提取标签内容
使用 BeautifulSoup,你可以轻松提取特定的标签内容。例如,假设我们想提取页面中的所有 <a> 标签(超链接):
# 查找所有的 <a> 标签
links = soup.find_all('a')# 遍历并打印每个链接的 href 属性
for link in links:print(link.get('href'))
find_all() 是 BeautifulSoup 中最常用的方法之一,它可以返回文档中所有匹配的标签列表。在这个例子中,link.get('href') 提取了每个超链接的 URL。
3. 提取特定属性的标签
有时你可能只想查找带有特定属性的标签,例如带有 class="example" 的 div 标签:
divs = soup.find_all('div', class_='example')for div in divs:print(div.text)
find_all() 可以根据标签名称以及属性进行查找。在这个例子中,我们查找所有带有 class="example" 属性的 div 标签,并提取其中的文本内容。
四、解析复杂的 HTML
当我们面对复杂的 HTML 结构时,单靠简单的查找可能不足以提取所需的信息。BeautifulSoup 提供了多种灵活的方式来处理嵌套标签和复杂结构。下面我们将逐步展示如何解析复杂 HTML。
1. 处理嵌套标签
当 HTML 结构存在大量嵌套时,我们可以通过 BeautifulSoup 的 find() 和 find_all() 方法结合来逐步查找所需的内容。例如,假设我们想从以下 HTML 中提取嵌套的 <span> 标签的内容:
<div class="container"><div class="content"><span class="title">Title 1</span><span class="description">Description 1</span></div><div class="content"><span class="title">Title 2</span><span class="description">Description 2</span></div>
</div>
我们可以按以下方式逐步查找:
# 查找所有的 .content 容器
contents = soup.find_all('div', class_='content')for content in contents:# 查找每个 .content 中的标题和描述title = content.find('span', class_='title').textdescription = content.find('span', class_='description').textprint(f"Title: {title}, Description: {description}")
在这个例子中,我们首先查找所有的 div 容器,然后在每个容器中分别查找 span 标签,提取它们的文本内容。通过这种方法,你可以轻松解析具有多层嵌套结构的 HTML。
2. 使用 CSS 选择器查找元素
BeautifulSoup 还支持使用 CSS 选择器来查找元素,这在处理复杂 HTML 时非常有用。例如,假设我们想查找所有带有类名 .content .title 的标签,可以使用以下方法:
# 使用 select() 方法查找所有符合 CSS 选择器的标签
titles = soup.select('.content .title')for title in titles:print(title.text)
select() 方法允许你像在 CSS 中一样使用选择器查找元素。它比 find() 和 find_all() 更加灵活和强大,尤其适用于复杂的嵌套结构。
3. 处理动态内容
有时,网页内容是通过 JavaScript 动态生成的,这使得 BeautifulSoup 无法直接解析网页内容。在这种情况下,我们可以借助 Selenium 或其他工具来模拟浏览器环境并加载动态内容。
以下是一个使用 Selenium 和 BeautifulSoup 的简单示例,展示如何处理动态内容:
from selenium import webdriver
from bs4 import BeautifulSoup# 使用 Selenium 获取动态生成的 HTML
driver = webdriver.Chrome()
driver.get("https://example.com")# 获取页面源码
html = driver.page_source# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html, "html.parser")# 查找所需的内容
titles = soup.find_all('h1')for title in titles:print(title.text)# 关闭浏览器
driver.quit()
通过这种方式,你可以抓取并解析动态生成的网页内容。
4. 提取表格数据
在处理 HTML 数据时,表格是非常常见的结构之一。BeautifulSoup 可以方便地解析表格并提取其中的数据。假设我们有以下 HTML 表格:
<table><thead><tr><th>Product</th><th>Price</th></tr></thead><tbody><tr><td>Apple</td><td>$1</td></tr><tr><td>Banana</td><td>$0.5</td></tr></tbody>
</table>
我们可以通过以下方式提取表格数据:
# 查找表格
table = soup.find('table')# 查找表格中的所有行
rows = table.find_all('tr')# 遍历每一行,提取单元格数据
for row in rows:cells = row.find_all(['th', 'td'])for cell in cells:print(cell.text)
通过这种方式,你可以轻松提取表格中的内容,并根据需求进行处理。
五、数据清洗与处理
解析 HTML 数据后,通常我们还需要对数据进行清洗和处理。以下是一些常见的数据清洗操作:
1. 去除空白字符
HTML 内容中可能包含许多不必要的空白字符,可以使用 strip() 方法去除多余的空格、换行符等。
text = element.text.strip()
2. 替换或移除不需要的标签
如果你只想保留文本内容,可以使用 decompose() 方法移除不需要的标签。例如,假设我们要移除某个段落中的所有 <a> 标签:
# 查找段落
paragraph = soup.find('p')# 移除段落中的所有 <a> 标签
for a_tag in paragraph.find_all('a'):a_tag.decompose()print(paragraph.text)
六、总结
本文介绍了如何使用 Python 的 BeautifulSoup 库解析复杂的 HTML 内容,并通过多个实例展示了如何提取网页中的数据。通过 BeautifulSoup,你可以轻松地处理嵌套结构、动态内容、表格等复杂的 HTML 结构。无论是简单的网页抓取还是复杂的数据提取任务,BeautifulSoup 都提供了灵活且强大的工具。
在实际项目中,你可以将 BeautifulSoup 与其他库(如 requests、Selenium)
结合使用,构建强大的网页抓取和数据处理工具。随着你的熟练度增加,你会发现 BeautifulSoup 能够帮助你快速、高效地处理各种 HTML 和 XML 文档。
相关文章:
使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML
使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML:详解与示例 在 Web 开发和数据分析中,解析 HTML 是一个常见的任务,尤其是当你需要从网页中提取数据时。Python 提供了多个库来处理 HTML,其中最受欢迎的就…...

Spring Cache Caffeine 高性能缓存库
Caffeine 背景 Caffeine是一个高性能的Java缓存库,它基于Guava Cache进行了增强,提供了更加出色的缓存体验。Caffeine的主要特点包括: 高性能:Caffeine使用了Java 8最新的StampedLock乐观锁技术,极大地提高了缓存…...

Python3入门--数据类型
文章目录 一、基础语法编码标识符注释单行注释以 # 开头多行注释用多个 # 号,还有 和 """ 空行行与缩进同一行显示多条语句多行语句 二、数据类型Number(数字)type和isinstance查询变量类型数值运算 String(字符串…...

开发运维警示录-20241024
开发警示录 1、作为开发,不要私自修改业务人员给的SQL语句,虽然个人感觉SQL很冗余,效率低等。 2、开发前,要明确需求,必要时通过图和文字形成文档与需求方确认、留痕。 3、开发复杂的业务逻辑代码前,先疏通…...

Linux运维_搭建smb服务
Samba(SMB)是一个开源软件,允许Linux和Unix系统与Windows系统共享文件和打印机。以下是一些关于Samba和SMB的基本信息和操作步骤: Samba 和 SMB 基本概念 Samba:实现了SMB(Server Message Blockÿ…...
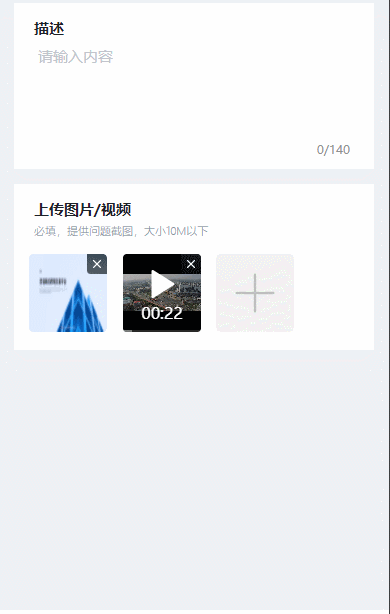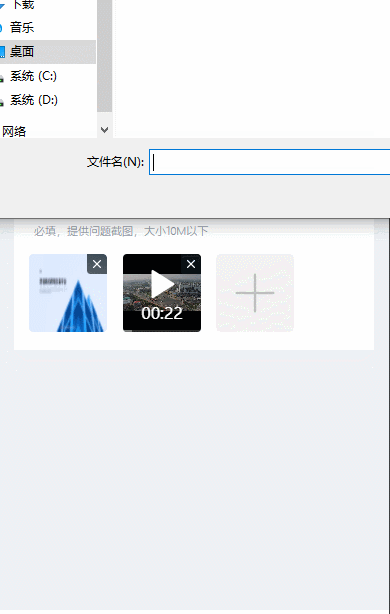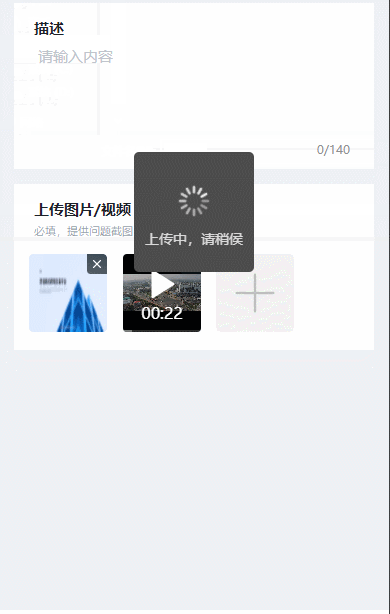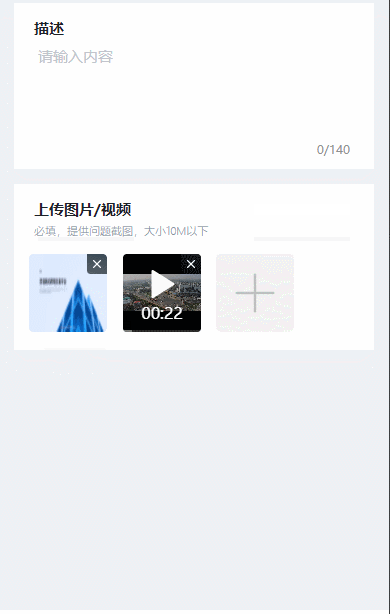
vue3移动端可同时上传照片和视频的组件
uni-app中的uni-file-picker可单独上传照片或视频,但不支持同时上传照片和视频。本篇博客使用image标签和video标签实现移动端(H5app小程序)中照片和视频的同时上传。 本篇博客采用的是照片和视频的单独上传,但可同时展示…...

PyQt入门指南二十七 QTableView表格视图组件
# 创建一个QStandardItemModel实例,用于存储表格数据model QStandardItemModel(4, 2) # 4行2列# 填充模型数据for row in range(4):for column in range(2):item QStandardItem(fRow {row}, Column {column})model.setItem(row, column, item)# 创建一个QTableVi…...
)
AI学习指南深度学习篇-自注意力机制(Self-Attention Mechanism)
AI学习指南深度学习篇—自注意力机制(Self-Attention Mechanism) 在深度学习的研究领域,自注意力机制(Self-Attention Mechanism)作为一种创新的模型结构,已成为了神经网络领域的一个重要组成部分…...

【JAVA毕业设计】基于Vue和SpringBoot的校园管理系统
本文项目编号 T 026 ,文末自助获取源码 \color{red}{T026,文末自助获取源码} T026,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 管…...

你对MySQL的having关键字了解多少?
在MySQL中,HAVING子句用于在数据分组并计算聚合函数之后,对结果进行进一步的过滤。它通常与GROUP BY子句一起使用,以根据指定的条件过滤分组。HAVING子句的作用类似于WHERE子句,但WHERE子句是在数据被聚合之前进行过滤,…...

【STM32编码器】【STM32】
提示:一般情况下我们会设计一个硬件电路模块来自动完成简单重复而高频的计算 文章目录 一、为什么通常情况下不使用外部中断来对编码器的脉冲进行计数?二、编码器速度测量程序设计思路三、正交编码器四、初始化流程五、STM32正交编码器输入捕获模式配置示…...

Python轴承故障诊断 (13)基于故障信号特征提取的超强机器学习识别模型
往期精彩内容: Python-凯斯西储大学(CWRU)轴承数据解读与分类处理 Pytorch-LSTM轴承故障一维信号分类(一)-CSDN博客 Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客 Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客 三十多个开源…...

VScode分文件编写C++报错 | 如何进行VScode分文件编写C++ | 不懂也能轻松解决版
分文件编写遇到的问题 分文件编写例子如下所示: 但是直接使用 Run Code 或者 调试C/C文件 会报错如下: 正在执行任务: C/C: g.exe 生成活动文件 正在启动生成… cmd /c chcp 65001>nul && D:\Librarys\mingw64\bin\g.exe -fdiagnostics-col…...

洞察前沿趋势!2024深圳国际金融科技大赛——西丽湖金融科技大学生挑战赛技术公开课指南
在当前信息技术与“互联网”深度融合的背景下,金融行业的转型升级是热门话题,创新与发展成为金融科技主旋律。随着区块链技术、人工智能技术、5G通信技术、大数据技术等前沿科技的飞速发展,它们与金融领域的深度融合,正引领着新型…...

Unity3D学习FPS游戏(4)重力模拟和角色跳跃
前言:前面两篇文章,已经实现了角色的移动和视角转动,但是角色并没有办法跳跃,有时候还会随着视角移动跑到天上。这是因为缺少重力系统,本篇将实现重力和角色跳跃功能。觉得有帮助的话可以点赞收藏支持一下!…...

C#基础知识-枚举
目录 枚举 1.分类 1.1普通枚举 1)默认情况 2)指定起始值 1.2标志枚举(Flag Enum) 位运算符与标志枚举 1)组合标志 2)检查标志 2.枚举与不同类型之间的转换 1)枚举->整型 2&#…...

系统架构设计师教程 第2章 2.1-2计算机系统及硬件 笔记
2.1计算机系统概述 ★☆☆☆☆ 计算机系统 (Computer System) 是指用于数据管理的计算机硬件、软件及网络组成的系统。 一般指由硬件子系统和软件子系统组成的系统,简称为计算机。 将连接多个计算机以实现计算机间数据交换能力的网络设备,称为计算机网…...

通过使用Visual Studio将你的程序一键发布到Docker
通过使用Visual Studio将你的程序一键发布到Docker 代码 阿里云容器镜像服务 https://www.aliyun.com/product/acr 添加Docker CE阿里云镜像仓库 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 安装Docker CE、Doc…...

vue2和vue3动态引入路由,权限控制
后端返回的路由结构(具体路由可以本地模拟) // 此路由自己本地模拟即可 const menus [{"title": "动态路由","meta": "{\"title\":\"动态路由\",\"noCache\":true}","component": "/t…...

Spring Boot:植物健康的智能守护者
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

Firefly开源中文大模型:指令微调、部署与领域适配实战
1. 项目概述:一个专为中文优化的开源大语言模型最近在开源社区里,Firefly(流萤)这个项目引起了我的注意。它不是一个通用框架,而是一个经过精心指令微调的大语言模型系列。简单来说,你可以把它理解为一个“…...
为你的五子棋项目加个‘智能大脑’)
从AlphaGo到你的小游戏:如何用MCTS(蒙特卡洛树搜索)为你的五子棋项目加个‘智能大脑’
从AlphaGo到你的小游戏:如何用MCTS为五子棋项目构建智能决策引擎 当你在手机上下棋输给AI时,是否好奇过这些"电子大脑"如何思考?2016年AlphaGo击败李世石的关键技术之一——蒙特卡洛树搜索(MCTS),…...

3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器
3分钟掌握SRWE:打破屏幕分辨率限制的终极窗口编辑神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE SRWE(Simple Runtime Window Editor)是一款革命性的实时窗口编辑器&…...

终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流
终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾梦想过让静态图片“活”起来,或者让文字描述直接变成生动…...

Linux小白避坑指南:Resilio Sync安装后权限配置与Web界面访问失败的常见问题解决
Linux权限迷宫:Resilio Sync安装后的深度避坑实战 当8888端口沉默时:一次真实的故障排查记录 上周五晚上11点,我正准备将团队的设计素材库同步到本地开发环境。按照官方文档,我在Ubuntu 22.04上顺利安装了Resilio Sync,…...

为什么设计师集体弃用Sora 2改投Veo?——从渲染延迟、长时序连贯性到版权水印支持的6维生产力对比
更多请点击: https://intelliparadigm.com 第一章:Veo vs Sora 2视频质量对比测试全景概览 为客观评估当前主流生成式视频模型的视觉保真度与时空一致性,我们构建了统一测试基准,涵盖运动连贯性、纹理细节还原、文本-视频对齐精度…...

Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南
Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南 当你面对一个加密的网络流量时,是否曾感到无从下手?无论是调试HTTPS API调用、分析SSH连接问题,还是研究QUIC协议的行为,加密流量总是像一…...

哔哩下载姬完全指南:从入门到精通的全能B站视频下载方案
哔哩下载姬完全指南:从入门到精通的全能B站视频下载方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

Armv8-A原子操作指令解析与应用优化
1. A64原子操作指令概述在Armv8-A架构中,A64指令集提供了一组强大的原子操作指令,这些指令在多核处理器环境下对实现线程安全的并发操作至关重要。原子操作的核心特性是保证特定内存操作的不可分割性——即这些操作要么完全执行,要么完全不执…...

直播人力成本居高不下?2026十大AI数字人直播平台推荐实现长效运营
引文: 2026年,直播电商的竞争早已从“拼人设”转向了“拼夜间值守效率”。据公开数据显示,AI数字人核心市场规模预计在2026年逼近千亿大关,其中“降本”和“长效运营”是众多商家投身高频无人直播的核心诉求。事实上,…...