AI大法之C语言哈希表算法比较两个文件去重
最近朋友在工作上遇到了一个问题,经常需要比对两个文件,筛选出文件中不同的订单号。比如有两个文件:计费.txt 和 受理.txt,文件中每一行都是一个订单号,需要找出计费.txt文件中有而受理.txt文件中没有的单号和计费.txt文件中没有而受理.txt文件中有的单号。
虽然有点绕,但仔细一看不就是简单的去重问题吗。于是我就说,这都2024年了,你把这两个文件上传给豆包、文心一言、kimi这些AI模型,直接让AI帮你找出来不就完事了么。结果并没有想象的那么顺利,由于文件行数不确定,大致在1W-20W行不等,上传给AI时,只给你加载一半数据,也不知道是不是没开会员的原因,想白嫖AI这条路算是行不通了。
于是我提出,干脆写个shell脚本去做这个操作呗。但朋友嫌弃shell脚本太慢了,想让我用C语言帮忙写一个,并请我喝奶茶。我心想这事情简单,有奶茶喝我就给你干了。
刚开始思路是,打开一个文件读一行,跟另一个文件每一行比,比完发现没有重复就存到一个新文件。后面一想,这样做文件行数一多,效率肯定极慢。于是问了问豆包,有什么好办法,豆包给出了个哈希表算法的建议。当了这么久牛马了,现在有了AI这个牛马,我肯定是不会自己从零开始撸代码的了,先让AI帮我写一段。
我copy过来,果然不出所料,编译都编不过。返回来质问AI,AI又老老实实给我整了一段,我找朋友要了两个测试数据,一测试发现不行,然后又让它改,然后给他提了一系列要求、比如哈希碰撞处理什么的,就这么一步步在我的调教下,终于写出了一段能用的代码。大家如果用得上可自取:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h> // 用于isspace函数#define MAX_LINE_LENGTH 1024
#define HASH_TABLE_SIZE 100000typedef struct Node {char *singleNumber;struct Node *next;
} Node;Node *hashTable[HASH_TABLE_SIZE];// 函数声明
unsigned int hashFunction(const char *str);
void insertHash(Node **hashTable, const char *singleNumber);
int containsHash(Node **hashTable, const char *singleNumber);
void freeHashTable(Node *hashTable[]);
int isNotBlankLine(const char *line);
char* trim(const char *str);int generaFile(const char *filename1, const char *filename2)
{FILE *file1, *file2, *outputfd;char output_filename[1024] = {0};strncpy(output_filename, filename2, strlen(filename2) - 4);strcat(output_filename, "_去重后.txt");char line[MAX_LINE_LENGTH];// 初始化哈希表for (int i = 0; i < HASH_TABLE_SIZE; i++) {hashTable[i] = NULL;}// 读取第一个文件并构建哈希表file1 = fopen(filename1, "r");if (!file1) {perror("Error opening file1");return EXIT_FAILURE;}while (fgets(line, MAX_LINE_LENGTH, file1)) {char *trimmedLine = trim(line);if (isNotBlankLine(trimmedLine)) {insertHash(hashTable, trimmedLine);}free(trimmedLine);}fclose(file1);printf("load %s hash finish!\n", filename1);// 读取第二个文件并删除共同的单号file2 = fopen(filename2, "r");outputfd = fopen(output_filename, "w+");if (!file2 || !outputfd) {perror("Error opening file2 or outputfd");return EXIT_FAILURE;}while (fgets(line, MAX_LINE_LENGTH, file2)) {char *trimmedLine = trim(line);line[strcspn(line, "\n")] = 0; // 移除换行符if (isNotBlankLine(trimmedLine) && !containsHash(hashTable, trimmedLine)) { // 没有找到相同的且不是空行fputs(trimmedLine, outputfd);fputc('\n', outputfd); // 使用fputc确保只写入一个换行符}free(trimmedLine);}fclose(file2);fclose(outputfd);// 释放哈希表freeHashTable(hashTable);return EXIT_SUCCESS;
}int isNotBlankLine(const char *line) {// 检查每一字符是否都是空白字符,如果是,则返回0,否则返回1while (*line) {if (!isspace((unsigned char)*line)) {return 1;}line++;}return 0;
}char* trim(const char *str) {if (str == NULL) return NULL;const char *end;size_t len = strlen(str);// Trim leading spacewhile (isspace((unsigned char)*str)) str++;if (*str == 0) // All spaces?return strdup("");// Trim trailing spaceend = str + len - 1;while (end > str && isspace((unsigned char)*end)) end--;// The len is the number of non-space charslen = (end - str + 1);char *trimmed = (char *)malloc(len + 1);if (trimmed) {snprintf(trimmed, len + 1, "%s", str);trimmed[len] = '\0';}return trimmed;
}int main(int argc, char *argv[])
{char *filename1 = argv[1];char *filename2 = argv[2];if (argc != 3) {printf("请指定要去重的两个文件!\n");printf("用法: ./quchong 文件1 文件2\n");printf("示例:./quchong 受理.txt 计费.txt\n");return 0;}if (generaFile(filename1, filename2) != EXIT_SUCCESS) {printf("%s 去重失败!", filename2);return EXIT_FAILURE;}// 注意:这里应该重新初始化哈希表for (int i = 0; i < HASH_TABLE_SIZE; i++) {hashTable[i] = NULL;}if (generaFile(filename2, filename1) != EXIT_SUCCESS) {printf("%s 去重失败!", filename1);return EXIT_FAILURE;}printf("数据去重完成!\n");return EXIT_SUCCESS;
}// 哈希函数
unsigned int hashFunction(const char *str)
{unsigned int hash = 5381;int c;while ((c = *str++)) {hash = ((hash << 5) + hash) + c; /* hash * 33 + c */}return hash % HASH_TABLE_SIZE;
}// 插入哈希表
void insertHash(Node **hashTable, const char *singleNumber)
{unsigned int index = hashFunction(singleNumber);Node *newNode = (Node *)malloc(sizeof(Node));if (!newNode) {perror("Memory allocation failed");exit(EXIT_FAILURE);}newNode->singleNumber = strdup(singleNumber);if (!newNode->singleNumber) {free(newNode);perror("Memory allocation failed");exit(EXIT_FAILURE);}newNode->next = hashTable[index];hashTable[index] = newNode;
}// 检查哈希表中是否包含某个单号
int containsHash(Node **hashTable, const char *singleNumber)
{unsigned int index = hashFunction(singleNumber);Node *current = hashTable[index];while (current) {if (strcmp(current->singleNumber, singleNumber) == 0) {return 1;}current = current->next;}return 0;
}// 释放哈希表内存
void freeHashTable(Node *hashTable[])
{for (int i = 0; i < HASH_TABLE_SIZE; i++) {Node *current = hashTable[i];while (current) {Node *temp = current;current = current->next;free(temp->singleNumber);free(temp);}}
}
不得不感叹现在AI的强大啊,就几轮对话的功夫就给我写出了一个基本能用的代码,大大提高了我们的工作效率。
相关文章:

AI大法之C语言哈希表算法比较两个文件去重
最近朋友在工作上遇到了一个问题,经常需要比对两个文件,筛选出文件中不同的订单号。比如有两个文件:计费.txt 和 受理.txt,文件中每一行都是一个订单号,需要找出计费.txt文件中有而受理.txt文件中没有的单号和计费.txt…...
)
Scala 提取器(Extractor)
Scala 提取器(Extractor) Scala 提取器(Extractor)是一个非常有用的特性,它允许你为任何类型定义自定义的解构赋值语法。在Scala中,提取器是一种用于从对象中提取值的工具,它可以帮助你以一种更直观和声明式的方式处理数据。本文将详细介绍Scala提取器的工作原理、使用场景…...

【主机漏洞扫描常见修复方案】:Tomcat安全(机房对外Web服务扫描)
文章目录 引言I SSL/TLS Not ImplementedTomcat 服务器 SSL 证书安装部署(JKS 格式)Tomcat 服务器 SSL 证书安装部署(PFX 格式)HTTP 自动跳转 HTTPS 的安全配置(可选)修复SSL证书版本低II 主机漏洞扫描常见修复方案Apache JServ protocol serviceSlow HTTP DEnial of Ser…...

MySQL数据库之——事务(Transaction)详解
一、MySQL 事务定义 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在银行管理系统中,用户张三向李四账户转账的操作,账户转账是一个完整的业务,最小的单元,不可再分,这样,…...
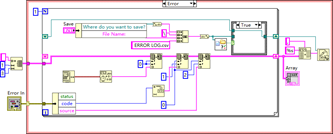
LabVIEW提高开发效率技巧----事件日志记录
在LabVIEW开发中,集成事件日志记录系统是提升程序调试效率和确保系统运行稳定的关键步骤。通过记录关键操作和异常事件,开发人员可以快速定位问题、优化程序性能,并确保系统的稳定性和可靠性。 1. 事件日志的作用 事件日志是指在程序运行过…...
整合XXL-Job任务调度平台
创建数据库 tables_xxl_job.sql 引入依赖 <dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.4.0</version> </dependency>编写配置文件 server:port: 8081xxl:job:admin:# 这…...

hi3536上ffmpeg带rtmp移植
1.下载ffmpeg-4.1.3版本源码包 用下面的脚本进行configure: ./configure \--target-oslinux \--prefix./libs/ \--enable-cross-compile \--archarm \--ccarm-hisiv500-linux-gcc \--cross-prefixarm-hisiv500-linux- \--nmarm-hisiv500-linux-nm \--enable-share…...

在PHP中,读取大文件
在PHP中,读取大文件可以采用以下几种方法: 1. 使用fopen和fread函数:这是最基本的文件读取方法,可以逐行读取大文件。首先使用fopen函数打开文件,然后使用fread函数指定读取的字节数,逐行读取文件内容并进…...

N-gram详解
文章目录 一、什么是N-gram?二、N-gram的种类三、优缺点PS:补充 一、什么是N-gram? 在自然语言处理中,n-gram是一种重要的文本表示方法。n-gram是指给定文本中连续的n个项目,这些项目可以是声音、单词、字符或者像素等。n-gram模型常常用于…...

电路中的电源轨及地的区别和处理
电源轨 VCC 通常代指正电源供电轨。在大多数数字和模拟电路中,VCC代表电路中的正电源端。VCC提供电路所需的正电压,通常是用来驱动晶体管、集成电路。 VDD 相对与VCC的正电源供应,VDD更常用于表示数字电路中的正电源引脚。VDD常见于集成电…...

k8s可以部署私有云吗?私有云部署全攻略
k8s可以部署私有云吗?K8S可以部署私有云。Kubernetes是一个开源的容器编排引擎,能够自动化容器的部署、扩展和管理,使得应用可以在各种环境中高效运行。通过使用Kubernetes,企业可以在自己的数据中心或私有云环境中搭建和管理容器…...

编辑器资源管理器
解释 EditorResMgr 是一个用于在 Unity 编辑器中加载资源的管理器。它通过 Unity 编辑器的 API (AssetDatabase) 进行资源加载,但仅在开发和编辑模式下可用,不能在最终发布的游戏中使用。这种工具通常用来在开发过程中快速加载编辑器中的资源࿰…...

高性能数据分析利器DuckDB在Python中的使用
DuckDB具有极强的单机数据分析性能表现,功能丰富,具有诸多拓展插件,且除了默认的SQL查询方式外,还非常友好地支持在Python、R、Java、Node.js等语言环境下使用,特别是在Python中使用非常的灵活方便。 安装 pip insta…...

IAR全面支持旗芯微车规级MCU,打造智能安全的未来汽车
中国上海,2024年10月18日 — 在全球汽车电子快速发展的今天,IAR与苏州旗芯微半导体有限公司(以下简称“旗芯微”)联合宣布了一项激动人心的合作——IAR Embedded Workbench for Arm 9.60.2版本现已全面支持旗芯微车规级MCU&#x…...

**深入浅出:TOGAF中的应用架构**
摘要: 在企业架构(EA)领域,TOGAF(The Open Group Architecture Framework)是一个广泛应用的框架。本文将带你深入了解TOGAF中的应用架构,帮助你理解其核心概念和实际应用。无论你是初学者还是有…...

Pytorch学习--DataLoader的使用
一、DataLoader简介 DataLoader官网 重要参数:画红框的参数 dataset: 作用:表示要加载的数据集。DataLoader通过该参数从数据集中读取数据。类型:Dataset,即PyTorch定义的Dataset类,用于封装数据并提供数据索引的功…...

代购系统界的“数据大厨”:定制API数据处理,烹饪出美味佳肴
在这个代购的盛宴中,每一位代购者都是一位大厨,他们用数据作为食材,用代码作为烹饪技巧,烹饪出一道道令人垂涎的美味佳肴。今天,就让我们走进代购界“数据大厨”的厨房,看看他们是如何定制API数据处理&…...

二十、Innodb底层原理与Mysql日志机制深入剖析
文章目录 一、MySQL的内部组件结构1、Server层1.1、连接器1.2、查询缓存1.3、分析器1.4、优化器1.5、执行器 2、存储引擎层 二、Innodb底层原理与Mysql日志机制1、redo log重做日志关键参数2、binlog二进制归档日志2.1、binlog日志文件恢复数据 3、undo log回滚日志4、错误日志…...

数据库设计与管理的要点详解
目录 前言1 数据库设计的基础:清晰的事实表1.1 确保数据的一致性和完整性1.2 优化查询性能 2 权限问题与数据问题的区分2.1 确认权限问题2.2 确认数据问题 3 视图与存储过程的合理使用3.1 视图的作用与应用3.2 存储过程的应用与优化 4 数据库操作日志的设计4.1 确保…...

国家科技创新2030重大项目
国家科技创新2030重大项目涵盖多个领域,例如:量子信息、人工智能、深海空间站、天地一体化信息网络、大飞机、载人航天与月球探测、脑科学与类脑研究、健康保障等,这些项目旨在解决制约我国经济社会发展的重大科技瓶颈问题,提升国…...

独立开发者如何借助Taotoken应对大模型API调用波动
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken应对大模型API调用波动 对于独立开发者而言,项目的稳定性和可控成本是生存与发展的关键。在…...

告别手动拖拽!用ENVI的Crosshairs和Cursor Value功能,精准搞定无坐标影像拼接
告别手动拖拽!用ENVI的Crosshairs和Cursor Value功能,精准搞定无坐标影像拼接 在遥感影像处理中,遇到没有地理参考信息的影像拼接任务时,很多用户的第一反应是手动拖拽对齐——这种看似直观的方法实际上效率低下且精度堪忧。想象一…...

ExifToolGUI:如何轻松批量管理照片元数据的完整指南
ExifToolGUI:如何轻松批量管理照片元数据的完整指南 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾经面对成百上千张照片,想要批量修改拍摄时间、添加版权信息或调整GPS坐标…...

性价比高可代理的油烟分离油烟机的厂家
最近跟10多个开厨电店的老板喝茶,一半人唉声叹气:去年赚的钱全压库存里了,3个做了十几年的老老板说,再找不到好产品,今年打算把店转了。为啥好好的店做成这样?说白了就是选品选错了,风口变了&am…...

技术创始人如何选择CEO:谦逊、互补与权力交接的艺术
1. 从技术专家到掌舵者:CEO角色转变的深层逻辑 在EDA(电子设计自动化)和半导体设计这个高度技术驱动的领域里,创业公司的故事每天都在上演。你可能会在DAC(设计自动化大会)上看到上百家初创公司,…...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...

Godot弹幕游戏开发利器:BulletUpHell插件核心功能与实战指南
1. 项目概述:一个为弹幕地狱游戏而生的强大引擎如果你正在用Godot引擎开发一款弹幕射击游戏(也就是我们常说的“弹幕地狱”或“STG”),并且正在为如何高效、灵活地生成成千上万颗轨迹各异的子弹而头疼,那么你很可能需要…...

Cursor编辑器Markdown实时预览插件CursorMD深度解析与实战指南
1. 项目概述:当代码编辑器遇上Markdown预览如果你和我一样,日常开发的主力工具是Cursor,同时又经常需要撰写技术文档、项目README或者个人博客,那你一定体会过那种在编辑器、浏览器和笔记软件之间反复横跳的割裂感。Cursor作为一款…...

OSINT自动化框架openeir:模块化设计与情报收集流水线构建
1. 项目概述:一个面向开源情报的现代化工具箱最近在整理自己的技术栈时,发现一个挺有意思的项目,叫heyeir/openeir。乍一看这个名字,可能会有点摸不着头脑,但如果你对开源情报(OSINT)领域有所涉…...

保姆级排错:Keil里J-Link选项神秘消失?手把手教你定位GD32E23等ARM-M23内核芯片的调试器兼容问题
当Keil调试器选项消失时:深度解析ARM-M23内核芯片的调试兼容性问题 第一次在Keil的Debug配置界面发现J-Link选项神秘消失时,我盯着屏幕愣了几秒钟——前一天明明还能正常使用的工具链,怎么突然就"罢工"了?这种看似"…...