FLINK 分流
在Apache Flink中,分流(Stream Splitting)是指将一条数据流拆分成完全独立的两条或多条流的过程。这通常基于一定的筛选条件,将符合条件的数据拣选出来并放入对应的流中。以下是关于Flink分流的详细解释:
一、分流方式

Flink提供了多种分流方式,以满足不同的数据处理需求:
- 基于filter的分流:
- 这是最直接的分流方式,通过多次调用.filter()方法,将符合不同条件的数据筛选出来,形成不同的流。
- 例如,可以将一个整数数据流拆分为奇数流和偶数流。
- 基于split的分流(已废弃):
- 在早期的Flink版本中,.split()方法允许用户根据条件将数据流拆分为多个流。
- 但由于该方法限制了数据类型转换,且随着Flink的发展,更灵活和高效的分流方式(如侧输出流)被引入,因此.split()方法已被废弃。
- 基于侧输出流(Side Output)的分流:
- 侧输出流是Flink提供的一种更灵活和高效的分流方式。
- 它允许用户在处理函数(如.process())中,根据条件将数据输出到不同的侧输出流中。
- 使用侧输出流时,需要先定义输出标签(OutputTag),然后在处理函数中通过ctx.output()方法将数据写入对应的侧输出流。
- 最后,可以通过getSideOutput()方法从侧输出流中获取数据。
三、内部机制
- 数据流的拆分:
- 当数据流通过分流操作时,Flink会根据用户定义的筛选条件或处理函数,将数据元素分发到不同的子流中。
- 这个过程通常是在Flink的算子(如filter算子、process算子)内部实现的,算子会根据输入数据的属性和条件来决定数据元素的去向。
- 子流的独立性:
- 一旦数据流被拆分成多个子流,这些子流在后续的处理中就是相互独立的。
- 用户可以对每个子流进行独立的操作和处理,如转换、聚合、窗口计算等。
- 资源的分配和调度:
- Flink会根据任务的并行度和资源情况,动态地分配和调度资源来处理这些子流。
- 这确保了每个子流都能得到足够的资源来处理数据,并且能够在满足性能要求的同时,尽可能地提高系统的吞吐量和效率。
四、应用场景
分流在Flink中有着广泛的应用场景,包括但不限于:
- 数据路由:根据数据的某些属性(如用户ID、地区等)将数据路由到不同的处理路径上。
- 异常检测:将正常数据和异常数据分开处理,以便对异常数据进行更详细的分析和处理。
- 数据过滤:从原始数据流中筛选出符合特定条件的数据进行进一步处理。
- 多版本处理:在处理数据升级或迁移时,将旧版本数据和新版本数据分开处理。
五、示例
1. filter分流
基于整数的奇偶性进行分流
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class FlinkFilterSplitExample { public static void main(String[] args) throws Exception { // 创建Flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从Socket接收数据流(这里假设Socket发送的是整数数据) DataStreamSource<String> socketStream = env.socketTextStream("localhost", 9999); // 将字符串数据流转换为整数数据流 SingleOutputStreamOperator<Integer> intStream = socketStream.map(Integer::valueOf); // 使用filter算子进行分流:偶数流和奇数流 SingleOutputStreamOperator<Integer> evenStream = intStream.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % 2 == 0; } }); SingleOutputStreamOperator<Integer> oddStream = intStream.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % 2 != 0; } }); // 打印偶数流和奇数流 evenStream.print("Even Stream: "); oddStream.print("Odd Stream: "); // 执行Flink程序 env.execute("Flink Filter Split Example"); }
}
说明:
- 创建执行环境:首先,我们创建了一个Flink的执行环境StreamExecutionEnvironment。
- 接收数据流:通过env.socketTextStream(“localhost”, 9999),我们从本地的9999端口接收一个文本数据流。这里假设发送的是整数数据的字符串表示。
- 数据类型转换:使用map算子,我们将接收到的字符串数据流转换为整数数据流。
- 分流操作:
- 使用filter算子,我们根据整数的奇偶性将数据流拆分为偶数流和奇数流。
- evenStream包含所有偶数,oddStream包含所有奇数。
- 打印结果:最后,我们使用print算子打印偶数流和奇数流的结果。
- 执行程序:通过调用env.execute(),我们启动了Flink程序。
2. split分流(已废弃)
基于传感器温度的split分流
import org.apache.flink.api.common.functions.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSplit;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; // 传感器数据类
class SensorReading { String deviceNo; long timestamp; double temperature; // 构造函数、getter和setter方法省略
} public class FlinkSplitExample { public static void main(String[] args) throws Exception { // 创建Flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 假设有一个数据源,这里使用一个简单的示例数据源 SingleOutputStreamOperator<SensorReading> sensorStream = env.fromElements( new SensorReading("device1", 1610035289736L, 84.3), new SensorReading("device2", 1610035371758L, 38.8), // ... 其他传感器数据 ); // 使用split算子进行分流 DataStreamSplit<SensorReading> splitStream = sensorStream.split(new OutputSelector<SensorReading>() { @Override public Iterable<String> select(SensorReading sensorReading) { ArrayList<String> output = new ArrayList<>(); if (sensorReading.temperature > 70.0) { output.add("high"); } else { output.add("low"); } return output; } }); // 从SplitStream中选择出高温流和低温流 DataStream<SensorReading> highTempStream = splitStream.select("high"); DataStream<SensorReading> lowTempStream = splitStream.select("low"); // 打印结果 highTempStream.print("High Temperature Stream: "); lowTempStream.print("Low Temperature Stream: "); // 执行Flink程序 env.execute("Flink Split Example"); }
}
3. 侧输出流(Side Output)分流
基于整数的奇偶性进行分流
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.apache.flink.api.common.functions.FilterFunction; public class SplitStreamByOutputTag { // 定义输出标签 private static final OutputTag<Integer> evenTag = new OutputTag<Integer>("even") {}; private static final OutputTag<Integer> oddTag = new OutputTag<Integer>("odd") {}; public static void main(String[] args) throws Exception { // 创建Flink上下文环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // Source DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888); // Transform SingleOutputStreamOperator<Integer> mapResult = dataStreamSource.map(input -> { int i = Integer.parseInt(input); return i; }); // Process and split SingleOutputStreamOperator<Integer> processedStream = mapResult.process(new ProcessFunction<Integer, Integer>() { @Override public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception { if (value % 2 == 0) { ctx.output(evenTag, value); } else { ctx.output(oddTag, value); } // 注意:这里不向主输出流输出任何数据,所有数据都通过侧输出流输出。 // 如果需要同时向主输出流输出数据,可以在else分支中添加 out.collect(value); } }); // 获取侧输出流并打印 DataStream<Integer> evenStream = processedStream.getSideOutput(evenTag); DataStream<Integer> oddStream = processedStream.getSideOutput(oddTag); evenStream.print("Even Stream: "); oddStream.print("Odd Stream: "); // 执行 env.execute(); }
}
相关文章:
FLINK 分流
在Apache Flink中,分流(Stream Splitting)是指将一条数据流拆分成完全独立的两条或多条流的过程。这通常基于一定的筛选条件,将符合条件的数据拣选出来并放入对应的流中。以下是关于Flink分流的详细解释: 一、分流方式…...

从零开始:构建一个高效的开源管理系统——使用 React 和 Ruoyi-Vue-Plus 的实战指南
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

windows下pycharm社区版2024下载与安装(包含新建第一个工程)
windows下pycharm社区版2024下载与安装 下载pycharm pycharm官网 安装pycharm 1.进入官网 pycharm官网 下载 点击Download–>右侧Other versions 下载对应的社区版(如下图):下载网址 2.点击运行下载好的安装包 点击下一步 3.更改pychar…...

重构案例:将纯HTML/JS项目迁移到Webpack
我们已经了解了许多关于 Webpack 的知识,但要完全熟练掌握它并非易事。一个很好的学习方法是通过实际项目练习。当我们对 Webpack 的配置有了足够的理解后,就可以尝试重构一些项目。本次我选择了一个纯HTML/JS的PC项目进行重构,项目位于 GitH…...

表格编辑demo
<el-form :model"form" :rules"status ? rules : {}" ref"form" class"form-container" :inline"true"><el-table :data"tableData"><el-table-column label"计算公式"><templat…...

企业自建邮件系统选U-Mail ,功能强大、安全稳定
在现代企业运营中,电子邮件扮演着至关重要的角色,随着企业规模的增长和业务的多样化,传统的租用第三方企业邮箱服务逐渐显现出其局限性。例如,存储空间受限、数据安全风险、缺乏灵活的管理和备份功能,以及无法与其他企…...
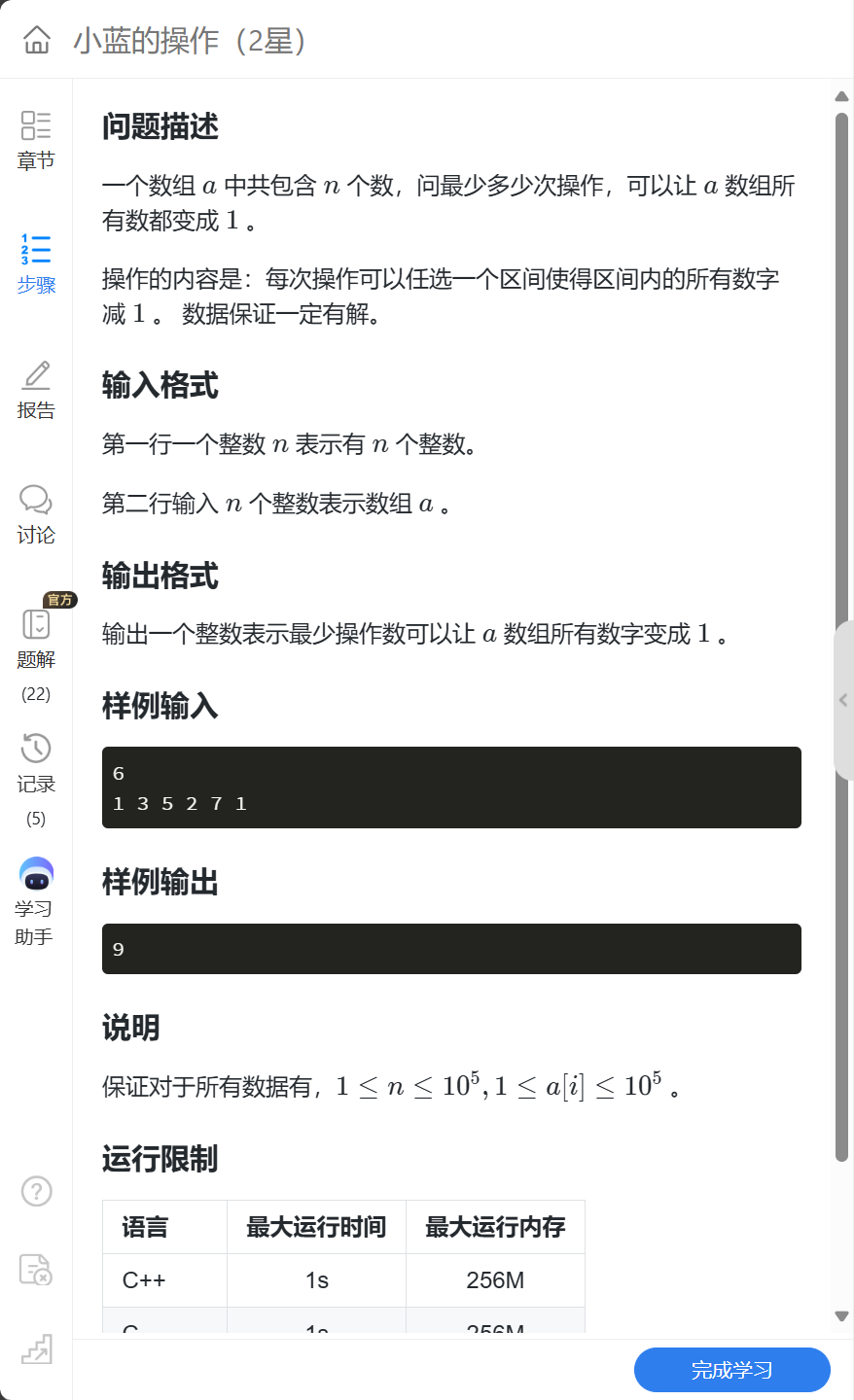
蓝桥杯题目理解
1. 一维差分 1.1. 小蓝的操作 1.1.1. 题目解析: 这道题提到了对于“区间”进行操作,而差分数列就是对于区间进行操作的好方法。 观察差分数列: 给定数列:1 3 5 2 7 1 差分数列:1 2 2 -3 5 6 题目要求把原数组全部…...

浪潮云启操作系统(InLinux)bcache缓存实践:理解OpenStack环境下虚拟机卷、Ceph OSD、bcache设备之间的映射关系
前言 在OpenStack平台上,采用bcache加速ceph分布式存储的方案被广泛用于企业和云环境。一方面,Ceph作为分布式存储系统,与虚拟机存储卷紧密结合,可以提供高可用和高性能的存储服务。另一方面,bcache作为混合存储方案&…...

通过ssh端口反向通道建立并实现linux系统的xrdp以及web访问
Content 1 问题描述2 原因分析3 解决办法3.1 安装x11以及gnome桌面环境查看是否安装x11否则使用下面指令安装x11组件查看是否安装gnome否则使用下面指令安装gnome桌面环境 3.2 安装xrdp使用下面指令安装xrdp(如果安装了则跳过)启动xrdp服务 3.3 远程服务…...

# 渗透测试#安全见闻8 量子物理面临的安全挑战
# 渗透测试#安全见闻8 量子物理面临的安全挑战 ##B站陇羽Sec## 量子计算原理与技术 量子计算是一种基于量子力学原理的计算方式,它利用量子位(qubits)来进行信息处理和计算…...

【rabbitmq】实现问答消息消费示例
目录 1. 说明2. 截图2.1 接口调用截图2.2 项目结构截图 3. 代码示例 1. 说明 1.实现的是一个简单的sse接口,单向的长连接,后端可以向前端不断输出数据。2.通过调用sse接口,触发rabbitmq向队列塞消息,向前端返回一个sseEmitter对象…...
单片机_RTOS__架构概念
经典单片机程序 void main() {while(1){函数1();函数2();}} 有无RTOS区别 裸机 RTOS RTOS程序 喂饭() {while(1){喂一口饭();} } …...
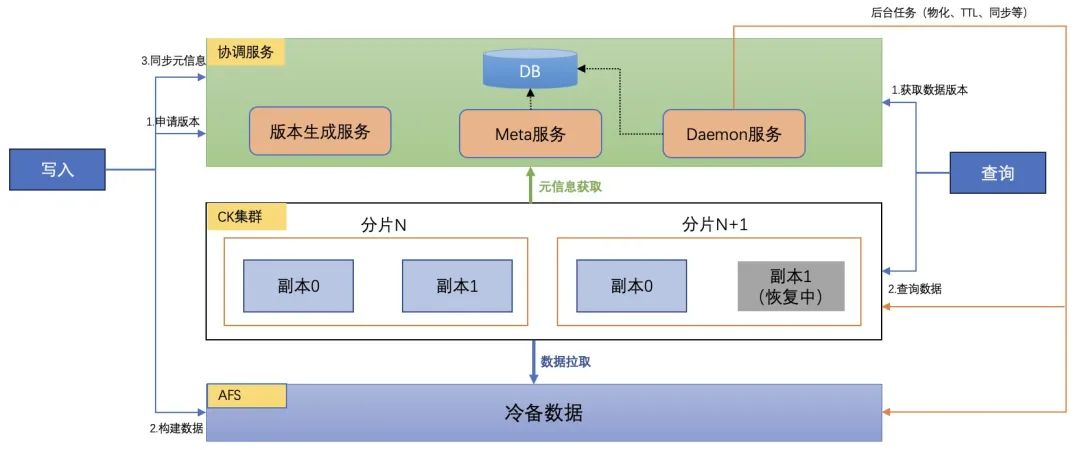
ClickHouse在百度MEG数据中台的落地和优化
导读 百度MEG上一代大数据产品存在平台分散、质量不均和易用性差等问题,导致开发效率低下、学习成本高,业务需求响应迟缓。为了解决这些问题,百度MEG内部开发了图灵3.0生态系统,包括Turing Data Engine(TDE)计算引擎、Turing Dat…...
与C/S架构(Client/Server))
B/S架构(Browser/Server)与C/S架构(Client/Server)
基本概念 B/S架构(Browser/Server):即浏览器/服务器架构。在这种架构中,用户通过浏览器(如Chrome、Firefox、Safari等)访问服务器上的应用程序。服务器端负责处理业务逻辑、存储数据等核心功能,…...

idea中自定义注释模板语法
文章目录 idea 自定义模板语法1.自定义模板语法是什么?2.如何在idea中设置呢? idea 自定义模板语法 1.自定义模板语法是什么? 打开我的idea,创建一个测试类: 这里看到我的 test 测试类里面会有注释,这是怎…...
基于SSM的儿童教育网站【附源码】
基于SpringBoot的课程作业管理系统(源码L文说明文档) 目录 4 系统设计 4.1 系统概述 4.2 系统模块设计 4.3.3 数据库表设计 5 系统实现 5.1 管理员功能模块的实现 5.1.1 视频列表 5.1.2 文章信息管理 5.1.3 文章类…...

深挖自闭症病因与孩子表现的关联
自闭症,亦称为孤独症,乃是一种对儿童发展有着严重影响的神经发育障碍性疾病。深入探寻自闭症的病因与孩子表现之间的联系,对于更深刻地理解并助力自闭症儿童而言,可谓至关重要。 当前,自闭症的病因尚未完全明晰&#x…...

[网络协议篇] UDP协议
文章目录 1. 简介2. 特点3. UDP数据报结构4. 基于UDP的应用层协议5. UDP安全性问题6. 使用udp传输数据的系统就一定不可靠吗?7. 基于UDP的主机探活 python实现 1. 简介 User Datagram Protocol,用户数据报协议,基于IP协议提供面向无连接的网…...
----MySQL(初阶))
关系型数据库(1)----MySQL(初阶)
目录 1.mysql 2.mysqld 3.mysql架构 1.连接层 2.核心服务层 3.存储引擎层 4.数据存储层 4.SQL分类 5.MySQL操作库 6.MySQL数据类型 1. 数值类型 2. 日期和时间类型 3. 字符串类型 4. 空间类型 5. JSON数据类型 7.MySQL表的约束 1. 主键约束(PRIMARY…...

计算机毕业设计Python+大模型租房推荐系统 租房大屏可视化 租房爬虫 hadoop spark 58同城租房爬虫 房源推荐系统
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 用到的技术: 1. python…...

开源停车查询工具技术解析:从数据抓取到API服务的完整架构实践
1. 项目概述:一个开源停车查询工具的诞生最近在GitHub上看到一个挺有意思的项目,叫Harperbot/openclaw-parking-query。光看名字,你大概能猜到它和停车查询有关。没错,这是一个开源的停车信息查询工具,或者说ÿ…...

超薄OLED字符显示屏技术解析与工业应用
1. 超薄OLED字符显示屏的技术革新 在工业控制和嵌入式系统领域,显示模块的选择往往需要在可视性、功耗和空间占用之间寻找平衡点。Newhaven Display最新推出的超薄OLED字符显示屏系列,通过突破性的结构设计将厚度压缩至5mm,同时实现了10,000:…...

Windows热键侦探:快速定位占用快捷键的终极解决方案
Windows热键侦探:快速定位占用快捷键的终极解决方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...

使用 SaySo 语音输入提升内容创作效率,从灵感到初稿的工作流实践
作为一个日更科技内容创作者,我每天都需要完成大量文字输出。包括工具测评、产品体验、干货笔记、技术趋势观察,以及一些观点类内容。长期写下来之后,我发现真正消耗时间的,不只是选题和思考,还有一个很容易被忽略的环…...

如何快速使用QVina:分子对接的终极完整指南
如何快速使用QVina:分子对接的终极完整指南 【免费下载链接】qvina Accurately speed up AutoDock Vina 项目地址: https://gitcode.com/gh_mirrors/qv/qvina QVina是一个高效准确的分子对接工具,专门用于加速AutoDock Vina的计算过程。如果你正在…...
)
Veo 2与Sora、Pika、Runway ML v4终极横评:18项指标实测(含时长支持、物理仿真、多主体追踪)
更多请点击: https://intelliparadigm.com 第一章:Veo 2视频生成技术全景概览 Veo 2 是 Google DeepMind 推出的下一代原生视频扩散模型,支持长达 60 秒、1080p 分辨率、24fps 的高质量视频生成,显著超越前代在时序一致性、物理…...

BUUCTF Web实战:从SQL注入到文件上传的CTF解题全解析
1. SQL注入漏洞实战解析 SQL注入是CTF中最常见的Web漏洞类型之一。记得我第一次参加BUUCTF比赛时,遇到的第一道Web题就是SQL注入。当时完全不知道什么是"万能密码",现在回头看才发现这其实是入门必学的知识点。 在BUUCTF的[极客大挑战 2019]Ea…...

为什么你的团队很忙,却没有结果
“团队忙得脚不沾地,季度业绩却只增长3%。”这是杭州一位制造业老板的真实困惑。如果你也有同感,不妨想一想:你的团队是在“有效增长”,还是“虚假忙碌”?虚假忙碌的三种表现作为扎根杭州的企业管理培训陪跑机构&#…...

Simulink-采样时间实战:从模型配置到模块级联的精准控制
1. Simulink采样时间基础概念 第一次接触Simulink建模时,很多人会被"采样时间"这个概念搞得一头雾水。我刚开始用Simulink做电机控制系统仿真时,就因为这个参数设置不当,导致仿真结果完全失真。简单来说,采样时间决定了…...
)
告别Hive慢查询:用Impala在CDH集群上实现秒级数据分析(实战避坑)
告别Hive慢查询:用Impala在CDH集群上实现秒级数据分析(实战避坑) 当你的Hive查询从30分钟降到3秒,数据工程师的幸福感会直接拉满。这不是理论上的性能优化,而是我们团队在CDH生产环境迁移Hive到Impala后的真实体验。如…...