MySQL—CRUD—进阶—(二) (ಥ_ಥ)
文本目录:
❄️一、新增:
❄️二、查询:
1、聚合查询:
1)、聚合函数:
2)、GROUP BY子句:
3)、HAVING 子句:
2、联合查询:
1)、内连接:
2)、外连接:
3)、自连接:
4)、子查询:
5)、合并查询:
❄️总结:
❄️一、新增:
插入查询结果
也就是创建一个新表,把原来旧表中指定的列插入到新表中。
语法:
INSERT INTO 新的表名 [(column [, column ...])](指定的新表的列) SELECT ...(这里是旧表的列)
我们先来创建两个表来进行演示一下对于这个方法如何使用:
我们先来创建一个 stu 这个表:有 id sn name

我们创建了 stu 这个表,并且往里面放入了 4条数据。
接下来我们再创建一个表:stu1 里面的列为 id name

我们可以看到这个表里面没有任何的数据,接下来我想要把 stu 里面的数据放入到 stu1中,那么要如何才能做到呢?
这个时候就可以使用上面那个新增的语法来达到这个目的:

这样呢,我们就可以实现把 stu 中的 id,name 都复制到 stu1中。
这个就是我们新增的一个语法。
❄️二、查询:
1、聚合查询:
1)、聚合函数:
常见的统计总数、计算平均值等操作呢,可以使用聚合函数来实现,常见的聚合函数:
| 函数 | 说明 |
| COUNT ([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM ([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG ([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MIN ([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
| MAX ([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
上面的这些操作呢都是对 列的操作。
我们先来创建一个 exam 表:

我们一个一个的演示一遍:
1、COUNT ([DISTINCT] expr):
语法:
select count(列) from 表名;
统计表中的行数

这里注意,当我们去指定列查询的时候呢,如果这个列中存在 NULL 的话呢,我们这个 count 方法呢是不会统计 NULL 这一行的,演示一遍看看:

这个就是不会 统计 NULL 值 。
2、SUM ([DISTINCT] expr):
作用:
把查询结果中所有行中的指定的列进行相加
语法:
select sum(列) from 表名;

对于求和的时候呢,我们的中的 NULL 同样不参与运算。
这里要注意我们计算出来的结果并不是存在在表中的,其存在在一个临时表中,并且不受表中字段的长度的约束。
当然在我们计算的时候呢,我们可以在其后面添加一些限制条件,比如:

3、AVG ([DISTINCT] expr):
作用:
对所有行的指定列进行求平均值
语法:
select avg(列) from 表名;
我们直接来演示一遍如何使用的:
1、对数学成绩进行平均值查询

这个同样不受表中字段长度的约束。
2、对表达式进行求平均值,我们这里同样可以使用别名来代替:

这个呢就是 AVG 的用法了,我们继续往下看
4、MIN ([DISTINCT] expr)、MAX ([DISTINCT] expr):
作用:
求所有行中指定列的最小值和最大值
语法:
这个呢,我们可以单独使用,也可以一起使用:
select min(列),max(列) from exam;

这个也可以使用别名:
 这个呢就是我们的 max 和 min 的使用方法了。
这个呢就是我们的 max 和 min 的使用方法了。
这里我们要注意:
对于使用聚合函数的时候呢,我们可以 多个聚合函数一起进行使用,而非是一个一个的进行运算。
当然了,聚合函数不单单只有这几个,还有很多,可以去官网去了解一下:
MySQL官网
2)、GROUP BY子句:
定义:
SELECT 中使用 GROUP BY 子句可以对 指定列进行分组查询。
需要满足:GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在 SELECT 中则必须包含在聚合函数中。
这样说的话,就不是很好理解,我们来对其进行演示一遍是什么意思,并且对其进行解释:
我们先来创建一个表:

我们来看 这个表中的字段哪个才能作为 分组字段,id 呢是不会重复的,对于name 呢也不存在相同的,还有工资也不适合分组,所以我们的只能由 role 角色进行分组,所以这里我们的 分组依据字段是 —— role。
语法:
select column1, sum(column2), .. from table group by column1,column3;

1、比如:计算不同角色的平均值

这个呢就是我们的对于 分组查询的使用。
我们在 group by 之后呢还可以添加 order by 语句进行排序规则:

3)、HAVING 子句:
定义:
在 GROUP BY 子句进行分组之后呢,需要对分组结果进行再进行过滤,不能使用 WHERE 语句,而是需要使用 HAVING 子句。
因为这些的到的查询结果不是表中真实的数据,都是由聚合函数查询出来的。
我们来使用看看这个 HAVING子句如何使用的:

having 使用在 group by 之后,而 where 是在 from 表名之后,也就是分组之前,这里要进行区分
如果需要对于 表中真实存在的数据进行过滤,并且也需要对分组的结果进行过滤,那么这时候可以在合适的位置写 where 和 having 即可。
2、联合查询:
联合查询也叫表连接查询:
1、首先确定哪几张表要参与查询
2、根据表与表之间的主外键关系,确定过滤条件
3、精准查询字段,得到想要的结果
我们先来看对于上次博客所说的 复合主键:
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积。
那么什么是笛卡尔积呢?我们来看:

我们可以的出对于生成笛卡尔积的过程是:
1、先从第一张表中取出一条记录,然后再与第二张表中的第一条记录进行组合,生成第一条新的记录
2、先从第一张表中取出一条记录,然后再与第二张表中的第二条记录进行组合,生成第一条新的记录
...................
最后的到的结果就是 一个全排列的结果集。
1)、内连接:
连接查询方法:
1:select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
2:select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
我们详细演示一下对于 内连接的第二种方式:
我们来创建两个表来进行基础的联合查询:
联合查询的语法:
select * from 表名,表名;

1、对这两个表进行联合查询:

这个两张表中呢,在取笛卡尔积之后呢,是存在有效数据和无效数据的,我们可以看到在class_id和 class表中的 id 相等的情况下呢,就是有效的数据,那么我们要如何过滤掉这些无效的数据呢?
2、通过连接条件过滤掉无效数据
连个表中是存在主外键关系的,只需要判断两个表中的主卧阿健字段是否相等就可以过滤掉无效数据。
我们可以通过 :表名.列名的方式来解决问题:

这样的得到的结果就是 表连接的查询,但是我们是不是不想要 class_id 和 id 这两个列啊,所以接下来我们对其进行简化: 
这样呢,我们就可以的到 内连接的联合查询的结果了。
我们来看看第一种 内连接的查询方式:

这些就是 内连接的联合查询的方式了。
2)、外连接:
定义:
外连接分为 左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
那么这个是什么意思呢?我们这样直接看定义不是很理解,我们呢来演示一遍来理解一下:

我们可以看到,对于 class 表中的 四班是没有被使用的,那么当我们在对这两个表进行 内连接的查询的时候呢,我们是查询不到 class 中这个 四班的,那如果我们要是想要显示出这个 四班的话呢,我们这里就需要使用到 —— 外连接。
1、右外连接:

这个就是我们的 右外连接了,左边的表没有与之匹配的会 赋值为 NULL 。
2、左外连接:

这个呢就是我们的 右外链接了。
3)、自连接:
自连接是指在同一张表连接自身进行查询。
我们的 where 都是对列与列之间的比较,如果我们要是想要对其进行 行与行 之间的比较的话呢,我们就需要先把其行与行变成 列与列,这样之后呢,我们才能就进行比较,这个时候呢就需要用到——自连接。
我们来演示一遍这个 自连接 要如何使用:
我们来查找 “计算机组成原理” 成绩比 “Java” 成绩高的信息:

这个就是我们的 自连接查询的示例了。
4)、子查询:
子查询是指嵌入在其他 sql 语句中的 select 语句,也叫嵌套查询。
单行子列查询:
语法:
select * from 表名 where 列名 = (select 列名 from 表名 where ...);
我们来演示一遍:
我们来看一个学生表:
我们来查找对于和 ‘许仙’ 一个班的同学信息:
1、查询 ‘许仙’ 同学的班级编号:

2、由查询的班级编号查询其余的同学:
 这几步骤可以有 子查询的一步直接完成,我们来看:
这几步骤可以有 子查询的一步直接完成,我们来看:

这个就是我们的 单行子查询。
多行子查询:返回多行记录的子查询
关键字1:
[NOT] IN 关键字:
语法:
select * from 表名1 where 表名1.列名 [not] in (select 列名 from 表名2 where 表名2.列名....);
查询 英语 或者 语文 的成绩(查询不包括 语文 或者 英文的成绩):

这个呢就是对于 多行子查询 的使用方法了。
关键词2:
[NOT] EXISTS
EXISTS 后面的括号中查询有结果返回则执行外层的查询
反之则不执行外层查询
当存在 NOT 的时候就是上面的结果反过来。
演示:

在from子句中使用子查询:
子查询语句出现在 from 子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用
查询比 “ 中文系2019级3班” 的平均成绩高的学生信息:
1、先计算出平均分:
我们这里使用 3 张表,因为成绩表和班级表之间没有关系,所以要添加一个表:
1)、从班级表中找到对应的编号
2)、根据班级编号从学生表中找到对应的学生
3)、根据学生编号在成绩表中计算平均分

这个是存放在 临时表中的。
接下来是在 from 中的 临时表的子查询:

5)、合并查询:
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION 和 UNION ALL 时,前后查询的结果集中,字段需要一致。
UNION :
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
假如我们想要对两个表进行查询的话,就可以使用这个方法:

UNION ALL :
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。

❄️总结:
OK,我们对于 MySQL 中的 CRUD的增删改查呢,到这里就都结束了,对于这个 知识点呢,我们要多的进行练习,这是非常重要的知识。到这里就结束了,拜拜~~~

相关文章:
MySQL—CRUD—进阶—(二) (ಥ_ಥ)
文本目录: ❄️一、新增: ❄️二、查询: 1、聚合查询: 1)、聚合函数: 2)、GROUP BY子句: 3)、HAVING 子句: 2、联合查询: 1)、内连接…...

时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解
时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解 目录 时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 (创新独家)TTNRBO-VMD改进牛顿-拉夫逊优化算优化变分模态分解TTNRBO–VMD 优化VMD分解层数K和…...

2024“源鲁杯“高校网络安全技能大赛-Misc-WP
Round 1 hide_png 题目给了一张图片,flag就在图片上,不过不太明显,写个python脚本处理一下 from PIL import Image # 打开图像并转换为RGB模式 img Image.open("./attachments.png").convert("RGB") # 获取图像…...

CSS行块标签的显示方式
块级元素 标签:h1-h6,p,div,ul,ol,li,dd,dt 特点: (1)如果块级元素不设置默认宽度,那么该元素的宽度等于其父元素的宽度。 (2)所有的块级元素独占一行显示. (3ÿ…...

Go 语言中的 for range 循环教程
在 Go 语言中,for range 循环是一个方便的语法结构,用于遍历数组、切片、映射和字符串。本教程将通过示例代码来帮助理解如何在 Go 中使用 for range 循环。 package mainimport "fmt"func main() {// 遍历切片并计算和nums : []int{2, 3, 4}…...

青训营 X 豆包MarsCode 技术训练营--小M的比赛胜场计算
问题描述 小M参加了一场n个人的比赛,比赛规则是所有选手两两对决。每个人有一个能力值,对应着他们的序号。参赛者同时被分为黄色或蓝色两种颜色。比赛胜负的规则如下: 当比赛双方颜色不同时,能力值大的选手获胜; 当比…...

海王3纯源码
海王3是一款热门的捕鱼类游戏,其纯源码为开发者提供了一个完整的游戏开发基础。该源码包括客户端和服务端的完整架构,支持多人在线竞技模式和丰富的游戏玩法。服务端采用C语言编写,并使用MySQL数据库来存储玩家数据,确保数据处理的…...

【ShuQiHere】Linux 系统中的硬盘管理详解:命令与技巧
【ShuQiHere】 💽 在 Linux 系统中,硬盘管理不仅仅是存储数据的操作,更涉及系统性能、数据安全和稳定性的优化。无论你是系统管理员、开发者还是 Linux 爱好者,掌握硬盘管理的基础操作都非常有用。本文将从硬盘健康检查、分区管理…...

数据结构之堆和二叉树的简介
1.树 1.1 树的概念与结构 如图所示,树是⼀种非线性的数据结构,它是由 n (n>0) 个有限结点组成⼀个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 …...

微信小程序上传图片添加水印
微信小程序使用wx.chooseMedia拍摄或从手机相册中选择图片并添加水印, 代码如下: // WXML代码:<canvas canvas-id"watermarkCanvas" style"width: {{canvasWidth}}px; height: {{canvasHeight}}px;"></canvas&…...

xshell5找不到匹配的host key算法
xshell5找不到匹配的host key算法,是因为电脑客户端不支持服务器的算法,因此需要再服务器增加算法。 下面以Ubuntu系统为例,修改下面的文件 sudo vim /etc/ssh/sshd_config 增加下面算法 KexAlgorithms diffie-hellman-group-exchange-…...

Linux中安装Tomcat
文章目录 一、Tomcat介绍1.1、Tomcat是什么1.2、Tomcat的工作原理1.3、Tomcat适用的场景1.4、Tomcat与Nginx、Apache比较1.4.1、优势1.4.2、劣势1.4.3、定位功能 1.5、Tomcat 的主要组件1.6、Tomcat 的主要配置文件 二、Tomcat安装2.1、查看可用的JDK2.2、安装OpenJDK 112.3、配…...

RV1126音视频学习(二)-----VI模块
文章目录 前言2.RV1126的视频输入vi模块2.1什么是VI模块2.3RV1126VI模块主要APIRK_MPI_SYS_Init()RK_MPI_VI_SetChnAttrRK_MPI_VI_EnableChnRK_S32 RK_MPI_VI_DisableChnRK_MPI_VI_StartStreamRK_MPI_SYS_GetMediaBufferRK_MPI_MB_GetPtrRK_MPI_MB_GetSizeRK_MPI_MB_ReleaseBuf…...

「C/C++」C++17 之 std::string_view 轻量级字符串视图
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...
Linux内核-内核模块内核参数
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注作者,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 我们的Linux进阶部分,到目前为止,已经讲过:硬件,日常运维,基础软…...
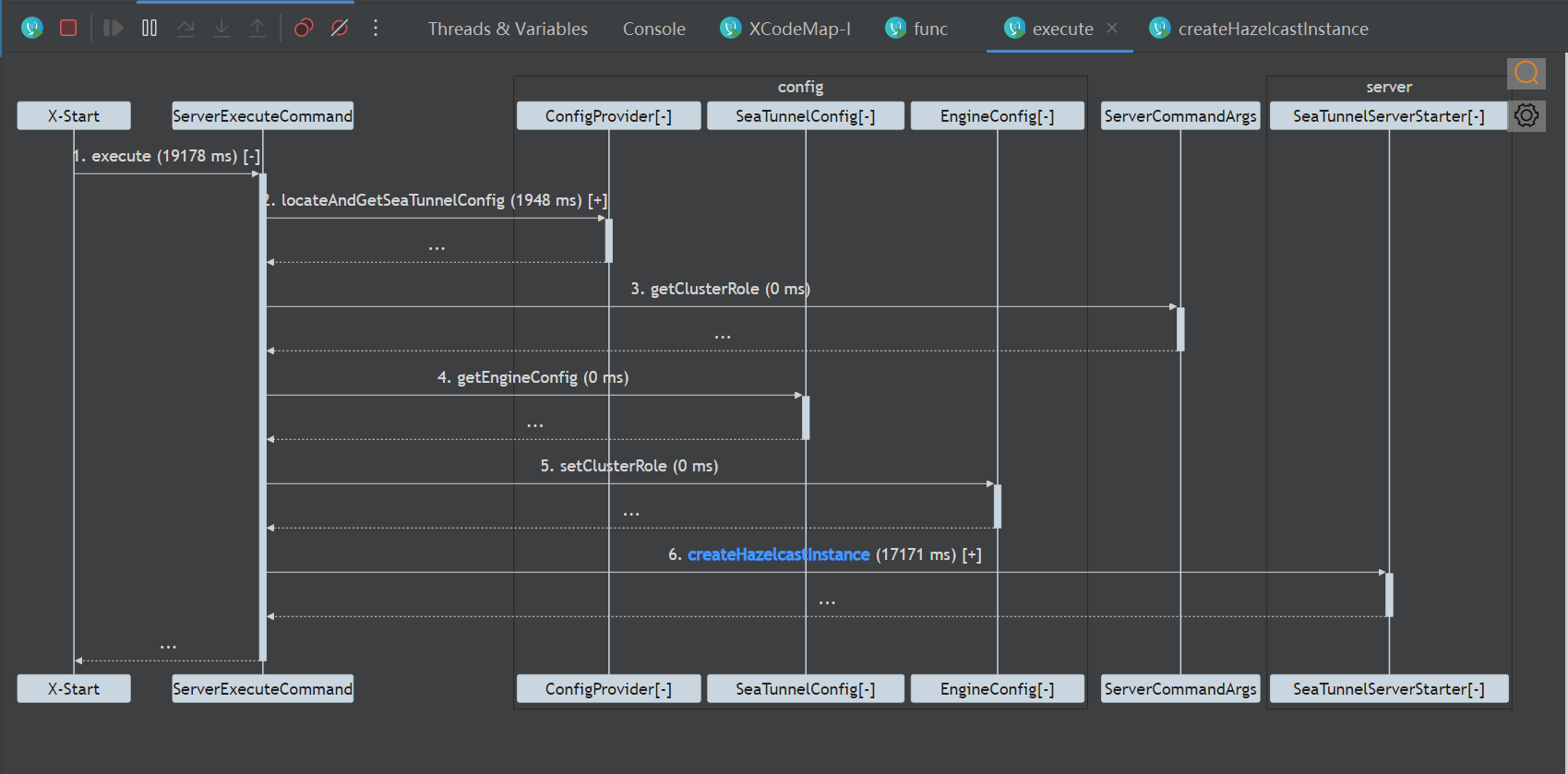
中电信翼康工程师:我在 Apache SeaTunnel 社区的贡献之旅
贡献者Github ID:luckyLJY 文章整理:曾辉 Apache SeaTunnel 作为一款强大的数据同步和转换工具,凭借其部署易用性、容错机制、数据源支持、性能优势、功能丰富性以及活跃的社区支持,成为了数据工程师们不可或缺的利器。 因其具有的…...

【ESP32S3】VSCode 开发环境搭建
ESP32S3 有多种开发方式,主流的有 Eclipse 和 VSCode 两种。本文来介绍一下基于 VSCode 的开发环境搭建。 VSCode 环境需要依赖于 ESP-IDF 插件,因此需要在 VSCode 插件市场中搜索并安装 ESP-IDF 插件: 安装完成后侧边栏会多出一个 ESP-IDF …...

大模型,多模态大模型面试问题基础记录24/10/24
大模型,多模态大模型面试问题基础记录24/10/24 问题一:LoRA是用在节省资源的场景下,那么LoRA具体是节省了内存带宽还是显存呢?问题二:假如用pytorch完成一个分类任务,那么具体的流程是怎么样的?…...

使用TimeShift备份和恢复Ubuntu Linux
您是否曾经想过如何备份和恢复您的Ubuntu或Debian系统?TimeShift是一个强大的备份和还原工具。TimeShift允许您创建系统快照,提供了一种在出现意外问题或系统故障时恢复到先前状态的简便方式。您可以使用RSYNC或BTRFS创建快照。 有了这个介绍࿰…...
win7现在还能用吗_哪些配置的电脑还可以安装win7系统
2024年了都,win7现在还能用吗?答案是肯定的。那么哪些配置的电脑还可以安装win7系统呢?下面就针对这两个问题详细分区。 win7现在还能用吗? Windows 7系统虽然已经停止官方支持,但仍然可以使用。以下是关于Windows 7系…...

2026毕业季必看!告别求职死循环,这两个高薪赛道让你稳上岸!
家人们谁都没想到,2026年毕业季求职难度直接拉满,堪称历年最难就业季!全国1270万高校毕业生扎堆涌入求职市场,岗位僧多粥少、竞争内卷到极致,无数应届生陷入一模一样的求职困境:精心打磨的简历海投出去&…...
切换场景及鼠标相关)
Unity(十六)切换场景及鼠标相关
场景切换空间命名:using UnityEngine.SceneManagement;直接用代码切换场景有问题要把场景加入到场景列表之中SceneList哪个场景在前面,谁在运行时就会首先进入过时方法Application.LoadLevel()if (Input.GetKeyDown(KeyCode.Space)) {SceneManager.LoadS…...

Windows下Python包管理权限踩坑实录:从WinError 5到WinError 32的完整解决流程
Windows下Python包管理权限问题深度解析:从WinError 5到WinError 32的实战指南 作为一名长期在Windows平台进行Python开发的工程师,我深刻理解文件权限问题带来的困扰。特别是当你在紧急项目交付前夜,突然遭遇PermissionError: [WinError 5]或…...

法律AI助手weclaw:基于RAG与领域大模型的智能法律应用实践
1. 项目概述:一个面向法律领域的智能助手 最近在关注一些开源项目,发现了一个挺有意思的,叫 shp-ai/weclaw 。光看这个名字,就能猜个八九不离十——“weclaw”,听起来像是“we”和“law”的结合,指向性非…...

ThunderAI:开源本地AI助手桌面应用部署与核心架构解析
1. 项目概述:一个开源的AI助手桌面应用 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“ThunderAI”。这名字听起来就挺带劲,对吧?点进去一看,是个用Python写的桌面应用程序,核心功能是把几个…...

DDR内存接口测试:从信号完整性到电源噪声的工程实践指南
1. DDR内存测试的核心挑战与价值在任何一个涉及高速数字信号的设计项目中,内存接口的验证都是决定系统稳定性的关键一环。从早期的SDRAM到如今主流的DDR4、DDR5乃至LPDDR系列,双倍数据速率(DDR)技术通过在每个时钟周期的上升沿和下…...

大模型评测实战指南:从基准测试到技术选型的全流程解析
1. 项目概述:为什么我们需要一个“大模型评测”清单?如果你在过去一年里深度参与过大语言模型(LLM)的应用开发、技术选型或者仅仅是技术追踪,你大概率会和我有同样的感受:“评测”这件事,变得越…...

如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍
如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为音乐配上精准的LRC歌词而烦恼吗?歌词…...

63岁黄仁勋再添博士头衔、英特尔CEO为其披袍,最新演讲刷屏:人类编写软件、计算机执行指令的范式已终结!
整理 | 苏宓 出品 | CSDN(ID:CSDNnews) 日前,在卡内基梅隆大学(CMU)的 2026 届毕业典礼上,英伟达 CEO 黄仁勋的头衔再加一,最新获得 CMU 科学与技术荣誉博士学位,而这也是…...

基于FastAPI与Flutter的LLM全栈聊天应用:私有化部署与架构解析
1. 项目概述与核心价值最近在折腾一个全栈的AI聊天应用,把后端、前端、数据库和缓存都整合到了一起。这个项目叫LLMChat,它不是一个简单的API包装器,而是一个功能完备、可以私有化部署的聊天平台。核心是用Python的FastAPI构建高性能后端&…...