spark读取parquet文件
源码
parquet文件读取的入口是FileSourceScanExec,用parquet文件生成对应的RDD
非bucket文件所以走createNonBucketedReadRDD方法。
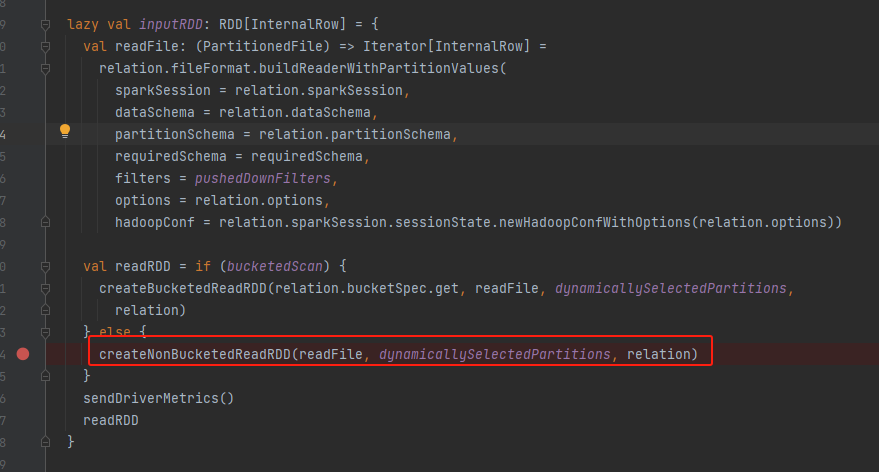
createNonBucketedReadRDD
过程:
- 确定文件分割参数
- openCostInBytes=4M 相关参数spark.sql.files.openCostInBytes=4M
- maxSplitBytes<=128M 相关参数spark.sql.files.maxPartitionBytes=128M,根据maxSplitBytes计算得来
- logInfo打印的日志可以用于排查参数
- 切分文件
- splitFiles进行文件切分,按照maxSplitBytes将大文件切分
- 切分后文件根据大小进行倒排,为了方便后面合并
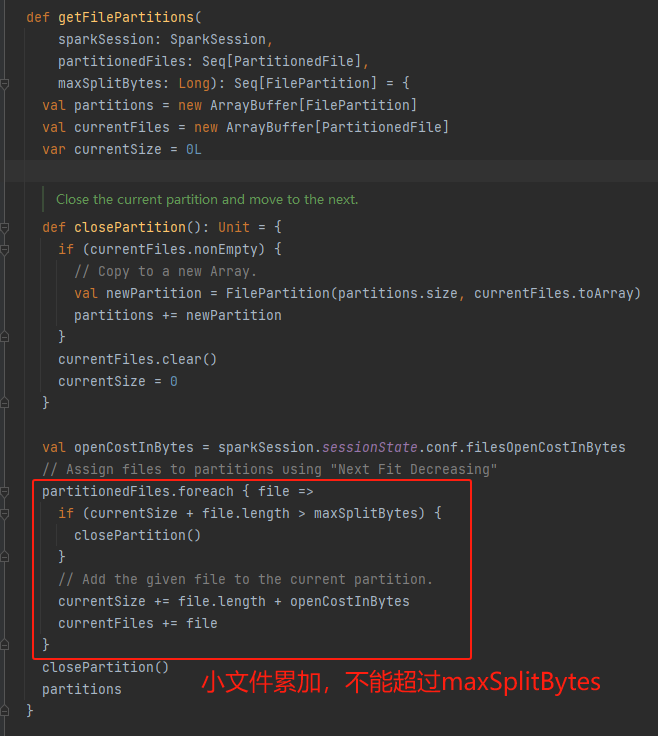
- 合并partition
- getFilePartitions 将小文件合并到一个partition
- 生成RDD
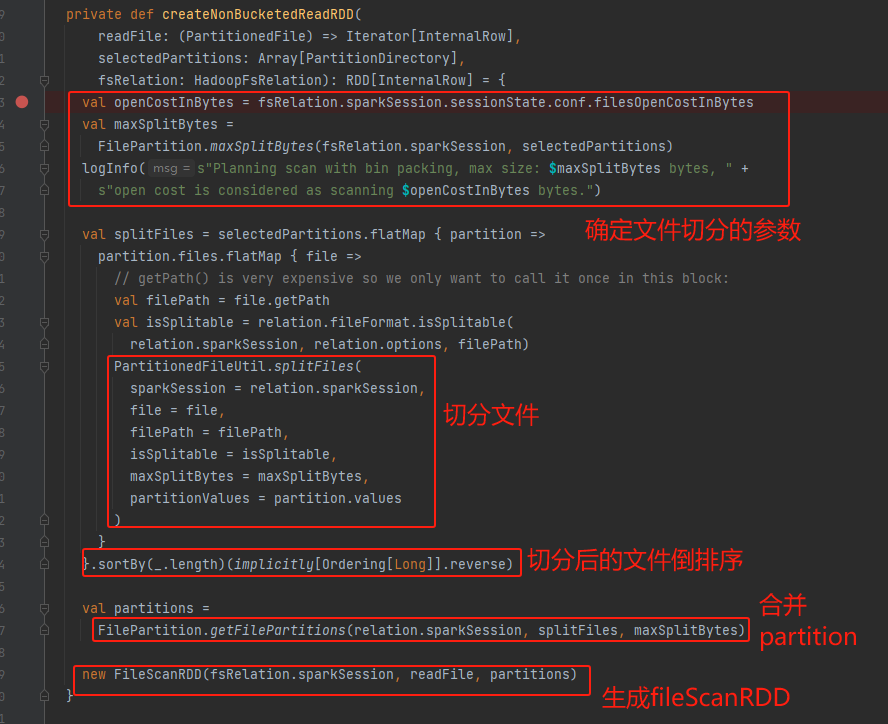
maxSplitBytes
- defaultMaxSplitBytes 最大分区大小=spark.sql.files.maxPartitionBytes=128M
- openCostInBytes 打开文件的代价 默认4M
- defaultParallelism 并行度
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))默认是core的总和,最小为2 - totalBytes 文件总大小(单个文件大小需要加上openCostInBytes)
- bytesPerCore 单个core分配的文件大小
最后Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
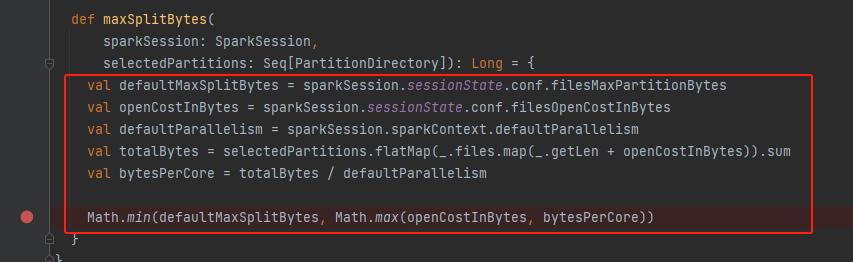
splitFiles
0L until file.getLen by maxSplitBytes按maxSplitBytes进行文件拆分
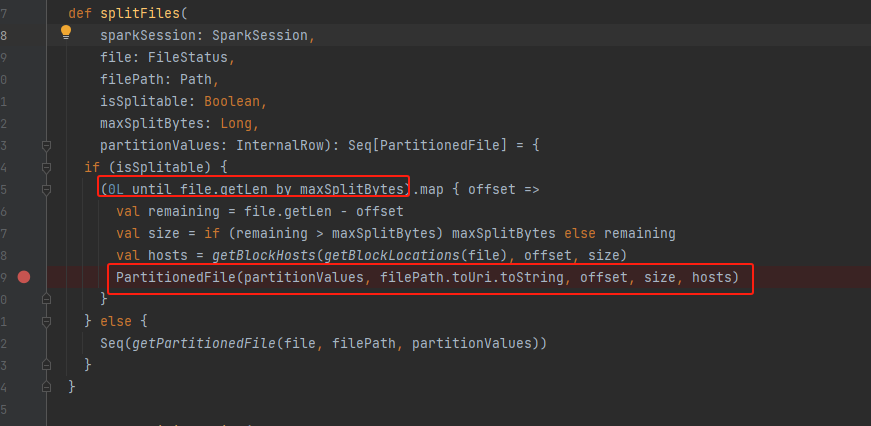
getFilePartitions
currentSize += file.length + openCostInBytes计算文件大小的时候需要加上openCostInBytes
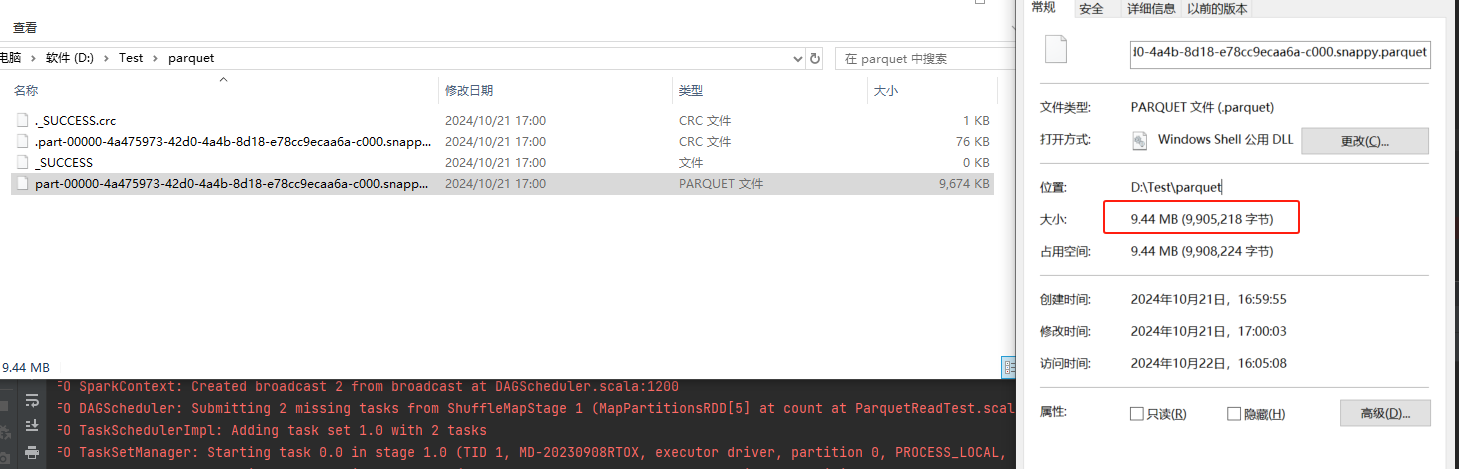
计算示例
parquet文件是9,905,218b,并行度是2
defaultMaxSplitBytes = 128MB
openCostInBytes = 4MB
defaultParallelism = max(2, 2) = 2
totalBytes = 9,905,218b+ 1 * 4MB = 14,099,522B
bytesPerCore = 14,099,522B / 2 = 7,049,761B
maxSplitBytes = 7,049,761B = Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
文件分成0-7049761 和 7049761-9905218两部分
从下面日志可以知道计算正确。


参考https://developer.aliyun.com/article/985412?utm_content=m_1000349867
相关文章:
spark读取parquet文件
源码 parquet文件读取的入口是FileSourceScanExec,用parquet文件生成对应的RDD 非bucket文件所以走createNonBucketedReadRDD方法。 createNonBucketedReadRDD 过程: 确定文件分割参数 openCostInBytes4M 相关参数spark.sql.files.openCostInBytes4M…...

redis详细教程(1.String类型)
Redis 的 String 类型内部使用了一种叫做 SDS(Simple Dynamic String)的结构。SDS 的设计比传统的 C 语言字符串更加高效和安全,主要特点如下: 头部信息:SDS 的头部包含了一些元数据,比如字符串的长度、剩…...

用友U8接口-库存管理(7)
概括 本文的操作需要正确部署U8API主要讲述库存管理接口的使用,以产成品入库单作为说明,其他单据接口都是大同小异的!许多时候先在ERP做个单,然后仿造ERP单据参数,构造接口JSON参数是不错的做法。 获取Token访问令牌…...

Spring Boot HikariCP数据库连接池入门
1. 概述 在我们的项目中,数据库连接池基本是必不可少的组件。在目前数据库连接池的选型中,主要是 Druid ,为监控而生的数据库连接池。HikariCP ,号称性能最好的数据库连接池。 至于怎么选择,两者都非常优秀&#x…...

Docker快速上手教程:MacOS系统【安装/配置/使用/原理】全链路速通
背景 最近换了个 Macbook Air M3, 写个人项目需要用到 Docker,配置过程有一点点坎坷,还是得记录下避免重蹈覆辙。 什么。为什么是买 Air 而不是 Pro Max? 因为码农的钱也是钱啊。 这里我不会先讲原理,我认为工程的事情都是先看到现象,有了概念的轮廓,才应该去研究原理,…...

【JavaSE】认识String类,了解,进阶到熟练掌握
#1024程序员节 | 征文# 下面就让博主带领大家一起解决心中关于String类的疑问吧~~~ 1.字符串构造: 第一种和第二种(有一定的区别,在常量池上) public static void main(String[] args) { // 使用常量串构造 String s1 "h…...
vue3 vben-admin 窗口大小更改后 echarts尺寸变为 100px的问题
问题描述: 当切换切换tab 并且窗口尺寸更改时, echarts的尺寸因为父元素为 0, 自动设置为 100px 网上查找资料的结果: 1,使用vue 中的 v-if 来重新设置dom树 缺点: 频繁操作dom树结构, 极其消耗性能 优点: 自适应展示 2,设置固定宽高 缺点: 不能自适应展示, 无需消耗额外…...

Web应用框架-Django应用基础(3)-Jinja2
1.创建姓名模板 username里的数据发生改变,页面中渲染的数据发生改变,该效果称为动态数据 #hello/views:def hello_user(request):username000html <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8&quo…...

js(深浅拷贝,节流防抖,this指向,改变this指向的方法)
一、深浅拷贝 1.基本数据类型和引用数据类型的区别: 1. 基本数据类型的变量存储的是值 引用数据类型的变量存储的是地址值 2. 基本数据类型的变量存储的值在栈内存 引用数据类型的变量存储的值在堆内存 3. 基本数据类型的变量存储的是值和值之间相互不影响 引用数据…...

香橙派5(RK3588)使用npu加速yolov5推理的部署过程
香橙派5使用npu加速yolov5推理的部署过程 硬件环境 部署过程 模型训练(x86主机) 在带nvidia显卡(最好)的主机上进行yolo的配置与训练, 获取最终的best.pt模型文件, 详见另一篇文档 模型转换(x86主机) 下载airockchip提供的yolov5(从pt到onnx) 一定要下这个版本的yolov5, …...

基于MWORKS的蓝桥杯「智能装备数字化建模大赛」正式发布,首期培训本周六开启
为强化装备数字化人才培养,推动装备数字化技术快速发展,第十六届蓝桥杯全国软件和信息技术专业人才大赛设置专项赛暨智能装备数字化建模大赛,使用MWORKS作为参赛软件。关于参赛软件授权、技术支持与培训、教材与案例开发支持、成果转化培训及…...

021、深入解析前端请求拦截器
目录 深入解析前端请求拦截器: 1. 引言 2. 核心实现与基础概念 2.1 基础拦截器实现 2.2 响应拦截器配置 3. 实际应用场景 3.1 完整的用户认证系统 3.2 文件上传系统 3.3 API请求缓存系统 3.4 请求重试机制 3.5 国际化处理 4. 性能优化实践 4.1 请求合并…...

windows中的tracert命令
在 Windows 操作系统中,tracert(全称 Trace Route)是一个用于确定 IP 数据包到达目标主机所经过的路径的命令行工具。它通过发送具有不同生存时间(TTL)的 ICMP(Internet Control Message Protocolÿ…...

【玩儿】Java 数字炸弹小游戏(控制台版)+ IO 数据存储
Java 数字炸弹小游戏(控制台版) IO 数据存储 数字炸弹小游戏概述功能实现实体类User.java 玩家信息实体类GameRecode.java 游戏记录实体类 自定义异常AccountLockedException.java 账号锁定异常PasswordErrorException.java 密码错误异常UnknowAccountEx…...

今日头条躺赚流量:自动化新闻爬取和改写脚本
构建一个自动化的新闻爬取和改写系统,实现热点新闻的自动整理和发布,需要分为以下几个模块:新闻爬取、信息解析与抽取、内容改写、自动发布。以下是每个模块的详细实现步骤和代码示例: 1. 新闻爬取模块 目标:从新闻网…...

日常实习与暑期实习详解
日常实习与暑期实习详解 问了下正在实习的同学,发现天要塌了–才知道日常实习是没有笔试的 1. 实习的定义 1.1 日常实习 日常实习是企业长期招聘的实习岗位,通常没有时间限制。企业会在需要时进行招聘,招聘对象包括在校大学生和大一、大二的…...
Git的原理和使用(六)
本文主要讲解企业级开发模型 1. 引入 交付软件的流程:开发->测试->发布上线 上面三个过程可以详细划分为一下过程:规划、编码、构建、测试、发 布、部署和维护 最初,程序⽐较简单,⼯作量不⼤,程序员⼀个⼈可以完…...

Elasticsearch 中的高效按位匹配
作者:来自 Elastic Alexander Marquardt 探索在 Elasticsearch 中编码和匹配二进制数据的六种方法,包括术语编码(我喜欢的方法)、布尔编码、稀疏位位置编码、具有精确匹配的整数编码、具有脚本按位匹配的整数编码以及使用 ESQL 进…...
,是一种特殊的循环神经网络(RNN)结构)
LSTM,全称长短期记忆网络(Long Short-Term Memory),是一种特殊的循环神经网络(RNN)结构
关于lstm超参数设置,每个参数都有合适的范围,超过这个范围则lstm训练不再有效,loss不变,acc也不变 LSTM,全称长短期记忆网络(Long Short-Term Memory),是一种特殊的循环神经网络&am…...
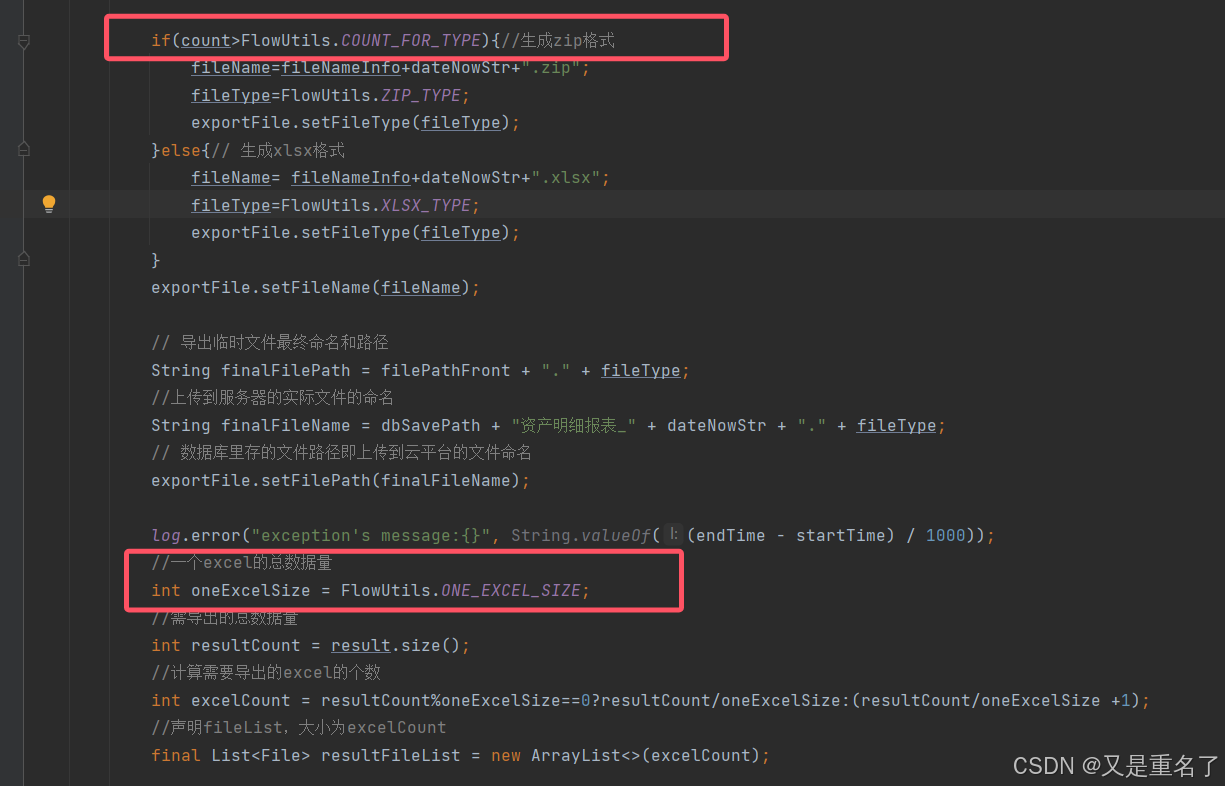
导出问题处理
问题描述 测试出来一个问题,使用地市的角色,导出数据然后超过了20w的数据,提示报错,我还以为是偶然的问题,然后是发现是普遍的问题,本地环境复现了,然后是,这个功能是三套角色&…...

3个核心模块揭秘:Python量化投资如何免费获取通达信专业数据
3个核心模块揭秘:Python量化投资如何免费获取通达信专业数据 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 你是否在量化投资中为数据获取而烦恼?商业接口太贵,…...

AI赋能软件测试:基于PyTorch视觉模型实现自动化GUI测试脚本生成效果演示
AI赋能软件测试:基于PyTorch视觉模型实现自动化GUI测试脚本生成效果演示 1. 效果亮点预览 想象一下这样的场景:一个AI系统正在自动测试你的软件界面,它能像人类测试工程师一样"看"懂屏幕上的每个元素,发现那些传统脚本…...

SM4算法在嵌入式平台的轻量化移植与优化实践
1. SM4算法与嵌入式平台适配挑战 SM4作为我国自主设计的商用分组密码标准,在物联网设备安全领域应用广泛。但直接将OpenSSL中的SM4实现移植到STM32等嵌入式平台时,开发者常会遇到三大难题: 代码体积膨胀:OpenSSL的SM4实现依赖大量…...

Serilog:从结构化日志认知到 .NET 工程落地
MySQL 中的 count 三兄弟:效率大比拼! 一、快速结论(先看结论再看分析) 方式 作用 效率 一句话总结 count(*) 统计所有行数 最高 我是专业的!我为统计而生 count(1) 统计所有行数 同样高效 我是 count(*) 的马甲兄弟…...
做特征重要性分析与亚组发现)
从预测到归因:手把手教你用因果森林(grf)做特征重要性分析与亚组发现
从预测到归因:手把手教你用因果森林(grf)做特征重要性分析与亚组发现 在金融风控、个性化营销和医疗疗效评估等领域,我们常常面临一个关键问题:干预措施的效果是否存在显著差异?传统分析方法如A/B测试能告诉…...
)
SENet实战:如何在PyTorch中实现Squeeze-and-Excitation模块(附完整代码)
PyTorch实战:手把手实现SENet中的SE模块 在计算机视觉领域,注意力机制已经成为提升模型性能的重要工具。今天我们将深入探讨如何在PyTorch中实现Squeeze-and-Excitation(SE)模块——这个让ResNet-50在ImageNet上表现接近ResNet-10…...
)
Nuxt3 + PM2 + Nginx:打造高可用前端部署方案(附常见问题排查指南)
Nuxt3 PM2 Nginx:打造高可用前端部署方案(附常见问题排查指南) 在当今快速迭代的Web开发领域,Nuxt3凭借其出色的服务端渲染能力和现代化的开发体验,正成为越来越多技术团队的首选框架。然而,将Nuxt3应用部…...
)
别再手动转格式了!用Python的docx2pdf库5行代码搞定Word转PDF(Windows/Mac通用教程)
5行代码终结格式转换焦虑:Python自动化Word转PDF全攻略 每次市场部门催着要电子合同时,你是不是还在手忙脚乱地点击"另存为PDF"?当运营团队需要批量生成上百份产品手册时,是否还在忍受重复机械的格式转换操作࿱…...

Ostrakon-VL-8B零售AI创新:用像素游戏化设计提升一线员工使用意愿
Ostrakon-VL-8B零售AI创新:用像素游戏化设计提升一线员工使用意愿 1. 项目背景与设计理念 在零售和餐饮行业,一线员工使用AI工具的意愿往往不高。传统工业级UI界面过于复杂,操作流程繁琐,导致员工抵触新技术。Ostrakon-VL-8B团队…...

Tomato Novel Downloader:智能搜索功能的技术突破
Tomato Novel Downloader:智能搜索功能的技术突破 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读工具领域,用户体验的每一个细节都可能决定…...