python 爬虫 入门 四、线程,进程,协程
目录
一、进程
特征:
使用:
初始代码
进程改装代码
二、线程
特征:
使用:
三、协程
后续:五、抓取图片、视频
线程和进程大部分人估计都知道,但协程就不一定了。
一、进程
进程是操作系统分配资源和调度的基本单位,一个程序开始运行时,操作系统会给他分配一块独立的内存空间并分配一个PCB作为唯一标识。初始化内存空间后进程进入就绪态,PCB插入就绪队列。轮到该进程时,操作系统会给进程分配CPU时间片,让进程进入运行态。时间片用完后,重新返回就绪队列,等待下一次分配。如果运行途中,进程遇到了阻塞事件,就会让出CPU给其他就绪进程,自己则进入阻塞队列,待阻塞结束后,重新返回就绪队列。

特征:
- 动态性:进程是程序的一次执行过程,有生命期。
- 并发性:多个进程实体同存于内存中,能并发执行。
- 独立性:进程是资源分配的基本单位,拥有独立的内存空间和系统资源。
- 异步性:进程以各自独立、不可预知的速度向前推进。
- 结构特性:每个进程由程序段、数据段和一个进程控制块(PCB)三部分组成。
使用:
进程用的比较少,线程协程用的多,因为进程之间的切换需要的资源太多了,比较慢,而且因为内存独立而不好通信。
今天试试这个网站泰坦陨落2steam版新手常见问题解决方法汇总 新手入门指南_逗游网一个游戏攻略,我们要尝试获取每一页红框中的内容,总共9页。

先来看看数据在不在页面源代码中,使用 Ctrl+U进入页面源代码,再Ctrl+F查找文字内容。发现页面源代码里有,这表明内容非脚本生成的,少了一大截麻烦。
老样子,通过抓包找到请求,就知道了url和请求方法,根据p不同的取值(1~9)即可切换不同的页面。现在我们可以开始写代码了。

初始代码
先来个无并行的,只记录请求部分时间。最后结果存在word文档里面。之后只展示控制台输出,word输出没什么差别。
import time
from io import BytesIOimport requests
from bs4 import BeautifulSoup
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Inches, RGBColordef out_word(bs_datas, out_path): # 将bs_datas内容保存,out_path为保存文件名# 创建Word文档doc = Document()# 遍历HTML内容for bs_data in bs_datas:if bs_data is None:continuefor section in bs_data.find_all('p'):section_all = section.find_all() # 获取部分中所有元素section_all.insert(0, section) # 列表第一个插入section_text = section_all[-1].string # 最后一个应该是无嵌套的纯文本if section_text is None or section_text.strip() == "": # 空的看看是不是图片if section_all[-1].name == "img":paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run()# 下载图片img_url = section_all[-1]['src']img_response = requests.get(img_url) # 下载图片img_stream = BytesIO(img_response.content)# 将图片添加到Word文档中run.add_picture(img_stream, Inches(5)) # 调整图片宽度else:continueelse: # 有文本,写下来paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run('\t' + section_text.strip()) # 获取标签文本,前面空格for part in section_all: # 遍历每个部分,给段落添加属性if part.name == 'strong': # 粗体run.bold = True # 设置为粗体elif 'align' in part.attrs: # 有对齐方式,这估计只有图片有个居中对齐,不过都写上吧align = part['align'].upper()if align == 'LEFT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif align == 'RIGHT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTelif align == 'CENTER':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTERelif align == 'JUSTIFY':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFYelse:paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif part.name == 'span' and 'style' in part.attrs: # 有颜色style = part['style']if style.startswith('color:'):color_str = style.split(':')[1]# 将颜色字符串转换为 RGB 分量r, g, b = int(color_str[1:3], 16), int(color_str[3:5], 16), int(color_str[5:7], 16)# 创建一个 RGBColor 对象color = RGBColor(r, g, b)run.font.color.rgb = color # 上色# 保存Word文档doc.save(out_path + '.docx')def get_text(bs_datas, url, i): # 获取p=i页内容(bs4)存在bs_datas[i-1]params = {"p": str(i)}with requests.get(url=url, headers=headers, params=params) as resp:resp.encoding = "utf-8" # 当页面乱码改这里bs = BeautifulSoup(resp.text, "html.parser")data = bs.find("div", class_="CH396071PsfiiY01QjM3f")bs_datas[i - 1] = dataprint(f"页面{i}结束")url = "https://www.doyo.cn/article/396071"
headers = {# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 ""Safari/537.36 Edg/126.0.0.0",
}
bs_datas = [None] * 9
now_time = time.time() # 记录访问时间
for i in range(1, 10):get_text(bs_datas, url, i)
# get_text(bs_datas, url, 1)
print("用时:", time.time() - now_time)
print(bs_datas)
out_word(bs_datas, 'output')


进程改装代码
平常使用时,我们可以通过multiprocessing.Pool创建进程池或者multiprocessing.Process创建进程。先来两段代码展示一下进程池和进程的使用
进程池,进程池像是工具箱,会自动分配和回收进程。
import time
from multiprocessing import Pool
import osdef task(m,n):for i in range(m,n):print(f"进程: {os.getpid()} 输出:{i}")# time.sleep(0) # 睡一下,让出cpu(为了更好展示并发性)if __name__ == "__main__":ranges = [(10,100)]*10with Pool(processes=3) as pool: # 使用3个进程pool.starmap(task, ranges) # 有10个任务

进程,注意你启动进程后,只是把它放到了就绪队列,具体什么时候运行要看什么时候轮到它。
import time
from multiprocessing import Process
import osdef task(m,n):for i in range(m,n):print(f"进程: {os.getpid()} 输出:{i}")# time.sleep(0) # 睡一下,让出cpu(为了更好展示并发性)if __name__ == "__main__":processes = []for i in range(3):p = Process(target=task, args=(100,1000))processes.append(p)for p in processes: # 启动所有进程p.start()for p in processes: # join等待进程结束后才会继续运行。p.join()print("全部进程结束")
两种方式都会出现下面这种现象,进程a和进程有几率交叉输出,这就是并发的表现

下面是用进程改装的代码,(图片请求591了,可能是刷太多次不让看了?所以加了个200判断,不影响。)切实能快一点。
import time
from io import BytesIO
from multiprocessing import Poolimport requests
from bs4 import BeautifulSoup
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Inches, RGBColordef out_word(bs_datas, out_path): # 将bs_datas内容保存,out_path为保存文件名# 创建Word文档doc = Document()# 遍历HTML内容for bs_data in bs_datas:if bs_data is None:continuefor section in bs_data.find_all('p'):section_all = section.find_all() # 获取部分中所有元素section_all.insert(0, section) # 列表第一个插入section_text = section_all[-1].string # 最后一个应该是无嵌套的纯文本if section_text is None or section_text.strip() == "": # 空的看看是不是图片if section_all[-1].name == "img":paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run()# 下载图片img_url = section_all[-1]['src']img_response = requests.get(img_url)if not img_response ==200:continue# 下载图片img_stream = BytesIO(img_response.content)# 将图片添加到Word文档中run.add_picture(img_stream, Inches(5)) # 调整图片宽度else:continueelse: # 有文本,写下来paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run('\t' + section_text.strip()) # 获取标签文本,前面空格for part in section_all: # 遍历每个部分,给段落添加属性if part.name == 'strong': # 粗体run.bold = True # 设置为粗体elif 'align' in part.attrs: # 有对齐方式,这估计只有图片有个居中对齐,不过都写上吧align = part['align'].upper()if align == 'LEFT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif align == 'RIGHT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTelif align == 'CENTER':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTERelif align == 'JUSTIFY':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFYelse:paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif part.name == 'span' and 'style' in part.attrs: # 有颜色style = part['style']if style.startswith('color:'):color_str = style.split(':')[1]# 将颜色字符串转换为 RGB 分量r, g, b = int(color_str[1:3], 16), int(color_str[3:5], 16), int(color_str[5:7], 16)# 创建一个 RGBColor 对象color = RGBColor(r, g, b)run.font.color.rgb = color # 上色# 保存Word文档doc.save(out_path + '.docx')def get_text(bs_datas, headers, url, i): # 获取p=i页内容(bs4)存在bs_datas[i-1]params = {"p": str(i)}with requests.get(url=url, headers=headers, params=params) as resp:resp.encoding = "utf-8" # 当页面乱码改这里bs = BeautifulSoup(resp.text, "html.parser")data = bs.find("div", class_="CH396071PsfiiY01QjM3f")print(f"页面{i}结束")return str(data),iif __name__ == "__main__":url = "https://www.doyo.cn/article/396071"headers = {# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 ""Safari/537.36 Edg/126.0.0.0",}bs_datas = [None] * 9data_chunks = [(bs_datas,headers, url, i) for i in range(1,10)]now_time = time.time() # 记录访问时间with Pool(processes=4) as pool: # 使用4个进程datas = pool.starmap(get_text, data_chunks)print("用时:", time.time() - now_time)for data in datas:bs_datas[data[1]-1]=BeautifulSoup(data[0], "html.parser")print(bs_datas)out_word(bs_datas, 'output')

二、线程
线程是cpu调度的基本单位,一个进程能有很多个线程(至少一个),进程是线程的容器。他的状态、特性、使用都和进程相似,有时候也成为轻量级进程。
与进程相比,线程的资源分配、调度、切换的花销都更少。而线程因为没有自己独立的内存空间,在通信上更灵活。
特征:
- 轻量级:相对于进程而言,线程是轻量级的执行单元,它只拥有一点必不可少的资源,如程序计数器、一组寄存器和栈。
- 共享资源:线程属于同一进程,它们共享进程的内存空间和资源,这使得线程之间的通信更加方便。
- 独立执行流:每个线程都有自己的执行路径,线程在执行过程中独立运行,互不干扰。
- 上下文切换快:线程间的上下文切换相对较快,因为线程共享了大部分上下文信息。
使用:
在python中,进程和线程的创建、使用的代码十分相似,这里只展示concurrent库线程池的使用:
import threading
from concurrent.futures import ThreadPoolExecutor
import timedef task(m, n):for i in range(m, n):print(f"线程: {threading.get_ident()} 输出:{i}")# time.sleep(0) # 睡一下,让出cpu(为了更好展示并发性)if __name__ == "__main__":with ThreadPoolExecutor(3) as t: # 使用3个线程for i in range(10):t.submit(task,m=10,n=100)print("end")
使用线程修改代码: 线程因为切换消耗少,自然速度能更快一些。
import time
from io import BytesIO
from concurrent.futures import ThreadPoolExecutor
import requests
from bs4 import BeautifulSoup
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Inches, RGBColordef out_word(bs_datas, out_path): # 将bs_datas内容保存,out_path为保存文件名# 创建Word文档doc = Document()# 遍历HTML内容for bs_data in bs_datas:if bs_data is None:continuefor section in bs_data.find_all('p'):section_all = section.find_all() # 获取部分中所有元素section_all.insert(0, section) # 列表第一个插入section_text = section_all[-1].string # 最后一个应该是无嵌套的纯文本if section_text is None or section_text.strip() == "": # 空的看看是不是图片if section_all[-1].name == "img":paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run()# 下载图片img_url = section_all[-1]['src']img_response = requests.get(img_url)if not img_response ==200:continue# 下载图片img_stream = BytesIO(img_response.content)# 将图片添加到Word文档中run.add_picture(img_stream, Inches(5)) # 调整图片宽度else:continueelse: # 有文本,写下来paragraph = doc.add_paragraph() # 添加一个新的段落run = paragraph.add_run('\t' + section_text.strip()) # 获取标签文本,前面空格for part in section_all: # 遍历每个部分,给段落添加属性if part.name == 'strong': # 粗体run.bold = True # 设置为粗体elif 'align' in part.attrs: # 有对齐方式,这估计只有图片有个居中对齐,不过都写上吧align = part['align'].upper()if align == 'LEFT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif align == 'RIGHT':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTelif align == 'CENTER':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTERelif align == 'JUSTIFY':paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFYelse:paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFTelif part.name == 'span' and 'style' in part.attrs: # 有颜色style = part['style']if style.startswith('color:'):color_str = style.split(':')[1]# 将颜色字符串转换为 RGB 分量r, g, b = int(color_str[1:3], 16), int(color_str[3:5], 16), int(color_str[5:7], 16)# 创建一个 RGBColor 对象color = RGBColor(r, g, b)run.font.color.rgb = color # 上色# 保存Word文档doc.save(out_path + '.docx')def get_text(bs_datas, headers, url, i): # 获取p=i页内容(bs4)存在bs_datas[i-1]params = {"p": str(i)}with requests.get(url=url, headers=headers, params=params) as resp:resp.encoding = "utf-8" # 当页面乱码改这里bs = BeautifulSoup(resp.text, "html.parser")data = bs.find("div", class_="CH396071PsfiiY01QjM3f")bs_datas[i - 1] = dataprint(f"页面{i}结束")if __name__ == "__main__":url = "https://www.doyo.cn/article/396071"headers = {# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 ""Safari/537.36 Edg/126.0.0.0",}bs_datas = [None] * 9data_chunks = [(bs_datas,headers, url, i) for i in range(1,10)]now_time = time.time() # 记录访问时间with ThreadPoolExecutor(4) as t: # 使用4个线程for i in range(1,10):t.submit(get_text,bs_datas=bs_datas,headers=headers,url=url,i=i)print("用时:", time.time() - now_time)print(bs_datas)out_word(bs_datas, 'output')

三、协程
协程比线程更小,它完全是在程序中切换代码的执行,而不需要操作系统的参与,具体来说,它可以在程序阻塞时去执行其他的代码段,而不需要白白让出cpu,不必切换线程也意味着没有切换消耗。下面来一段程序来表现协程:
import asyncio
import timedef f1s():print("f1s-in")time.sleep(1)print("f1s-out")def f3s():print("f3s-in")time.sleep(3)print("f3s-out")def f5s():print("f5s-in")time.sleep(5)print("f5s-out")async def af1s():print("f1s-in")# time.sleep(1) # time.sleep是同步操作,会终止异步await asyncio.sleep(1) # 挂起代码,异步操作print("f1s-out")async def af3s():print("f3s-in")# time.sleep(3)await asyncio.sleep(3)print("f3s-out")async def af5s():print("f5s-in")# time.sleep(5)await asyncio.sleep(5)print("f5s-out")async def main():now_time = time.time()tasks = [asyncio.create_task(af1s()),asyncio.create_task(af3s()),asyncio.create_task(af5s())]await asyncio.wait(tasks) # 一次启动多个任务print("启动协程:", time.time() - now_time)if __name__ == '__main__':now_time = time.time()f1s()f3s()f5s()print("正常:", time.time() - now_time)asyncio.run(main())

可以看出协程能够在阻塞时执行其他函数,节约寿命。在爬虫中,请求服务器的过程中有大量等待操作,协程能尽可能利用这段等待时间。

如果要在爬虫中使用协程,我们需要将会产生阻塞的函数换成协程异步函数,比如文件读写用aiofiles库,网络请求用aiohttp库。
下面是用协程的代码,只需0.25s更快了。(没加后面保存部分,之前也一直没计算保存部分时间。)
import asyncio
import timeimport aiohttp
from bs4 import BeautifulSoupasync def get_text(bs_datas, headers, url, i): # 获取p=i页内容(bs4)存在bs_datas[i-1]params = {"p": str(i)}async with aiohttp.ClientSession() as session: # aiohttp.ClientSession()相当于requestsasync with session.get(url=url, headers=headers, params=params)as resp:bs = BeautifulSoup(await resp.text(), "html.parser") # 图片换.content.red()data = bs.find("div", class_="CH396071PsfiiY01QjM3f")bs_datas[i - 1] = dataprint(f"页面{i}结束")async def main(bs_datas, headers, url):now_time = time.time() # 记录访问时间tasks = []for i in range(1, 10):tasks.append(asyncio.create_task(get_text(bs_datas=bs_datas, headers=headers, url=url, i=i)))await asyncio.wait(tasks) # 一次启动多个任务print("启动协程:", time.time() - now_time)if __name__ == "__main__":url = "https://www.doyo.cn/article/396071"headers = {# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 ""Safari/537.36 Edg/126.0.0.0",}bs_datas = [None] * 9# asyncio.run(main(bs_datas, headers, url))loop = asyncio.get_event_loop()loop.run_until_complete(main(bs_datas, headers, url))print(bs_datas)

在大量请求下,协程能够节省大量时间,请求数目越多越明显
后续:五、抓取图片、视频
会有大量请求,正是协程展示的好时机
相关文章:
python 爬虫 入门 四、线程,进程,协程
目录 一、进程 特征: 使用: 初始代码 进程改装代码 二、线程 特征: 使用: 三、协程 后续:五、抓取图片、视频 线程和进程大部分人估计都知道,但协程就不一定了。 一、进程 进程是操作系统分配资…...

cloak斗篷伪装下的独立站
随着互联网的不断进步,越来越多的跨境电商卖家开始认识到独立站的重要性,并纷纷建立自己的独立站点。对于那些有志于进入这一领域的卖家来说,独立站是什么呢?独立站是指个人或小型团队自行搭建和运营的网站。 独立站能够帮助跨境…...

【Nas】X-DOC:在Mac OS X 中使用 WOL 命令唤醒局域网内 PVE 主机
【Nas】X-DOC:在Mac OS X 中使用 WOL 命令唤醒局域网内 PVE 主机 1、Mac OS X 端2、PVE 端(Debian Linux) 1、Mac OS X 端 (1)安装 wakeonlan 工具 brew install wakeonlan(2)唤醒 PVE 命令 …...

u盘装win10系统提示“windows无法安装到这个磁盘,选中的磁盘采用GPT分区形式”解决方法
我们在u盘安装原版win10 iso镜像时,发现在选择硬盘时提示了“windows无法安装到这个磁盘,选中的磁盘采用GPT分区形式”,直接导致了无法继续安装下去。出现这种情况要怎么解决呢?下面小编分享u盘安装win10系统提示“windows无法安装到这个磁盘…...

Linux系统之dc计算器工具的基本使用
Linux系统之dc计算器工具的基本使用 一、DC工具介绍二、dc命令的基本用法2.1 dc命令的help帮助信息2.2 dc命令基本用法2.3 dc命令常用操作符 三、dc命令的基本使用3.1dc命令的用法步骤3.2 简单数学计算3.3 通过文件来计算3.4 使用--expression计算3.5 使用dc命令进行高精度计算…...

使用Python计算相对强弱指数(RSI)进阶
使用Python计算相对强弱指数(RSI)进阶 废话不多说,直接上主题:> 代码实现 以下是实现RSI计算的完整代码: # 创建一个DataFramedata {DATE: date_list, # 日期CLOSE: close_px_list, # 收盘价格 }df pd.DataF…...

vue 解决:npm ERR! code ERESOLVE 及 npm ERR! ERESOLVE could not resolve 的方案
1、问题描述: 其一、需求为: 想要安装项目所需依赖,成功运行 vue 项目,想要在浏览器中能成功访问项目地址 其二、问题描述为: 在 package.json 文件打开终端平台,通过执行 npm install 命令,…...

Android 原生开发与Harmony原生开发浅析
Android系统 基于Linux ,架构如下 底层 (Linux )> Native ( C层) > FrameWork层 (SystemService) > 系统应用 (闹钟/日历等) 从Android发版1.0开始到现在15,经历了大大小小的变革 从Android6.0以下是个分水岭,6.0之前权限都是直接卸载Manifest中配置 6.0开始 则分普…...
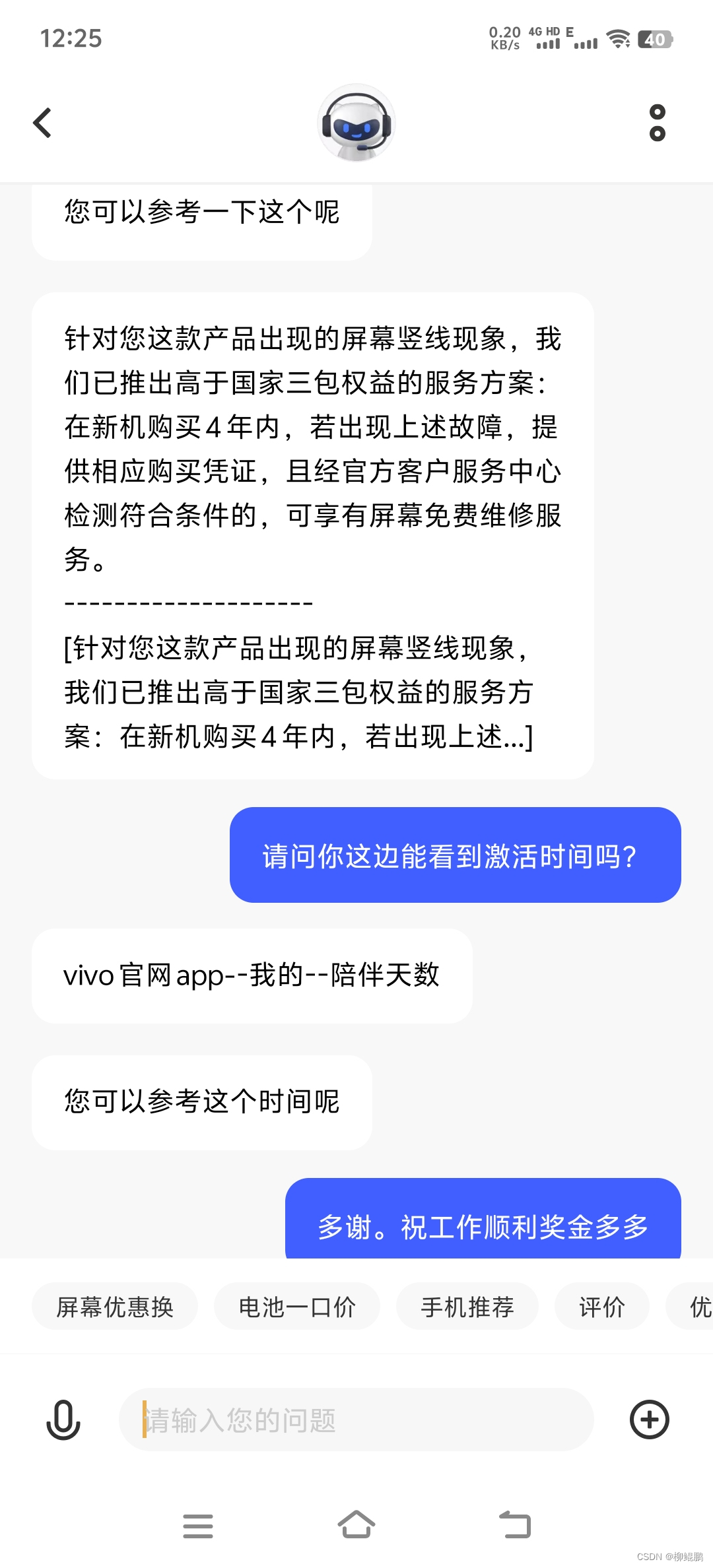
VIVO售后真好:屏幕绿线,4年免费换屏
只要亮屏就有。这也太影响使用了。 本来想换趁机换手机,看了VIVO发布的X200,决定等明年的X200 ULTRA。手头这个就准备修。 查了一下价格,换屏1600,优惠1100。咸鱼上X70 PRO也就800。能不能简单维修就解决呢?于是联系…...

数据类型【MySQL】
文章目录 建立表查看表删除表数据类型floatcharvarcharchar&&varchar 时间日期类型enum和setenum和set查找 建立表 mysql> create table if not exists user1(-> id int ,-> name varchar (20) comment 用户名 ,-> password char (32) comment 用户名的…...

流媒体协议.之(RTP,RTCP,RTSP,RTMP,HTTP)(二)
继续上篇介绍,本篇介绍一下封装RTP的数据格式,如何将摄像头采集的码流,音频的码流,封装到rtp里,传输。 有自己私有协议例子,有rtp协议,参考代码。注意不是rtsp协议。 一、私有协议 玩过tcp协议…...
在 Kakarot ZkEVM 上使用 Starknet Scaffold 构建应用
Starknet 和 EVM 我们所知的智能合约世界一直围绕着以太坊虚拟机(EVM),其主要语言是 Solidity。 尽管 Starknet 通过 STARKs 为以太坊开辟了新的可能性,但其缺点是它有一个不同的虚拟机 (CairoVM),这要求开发者学习 …...
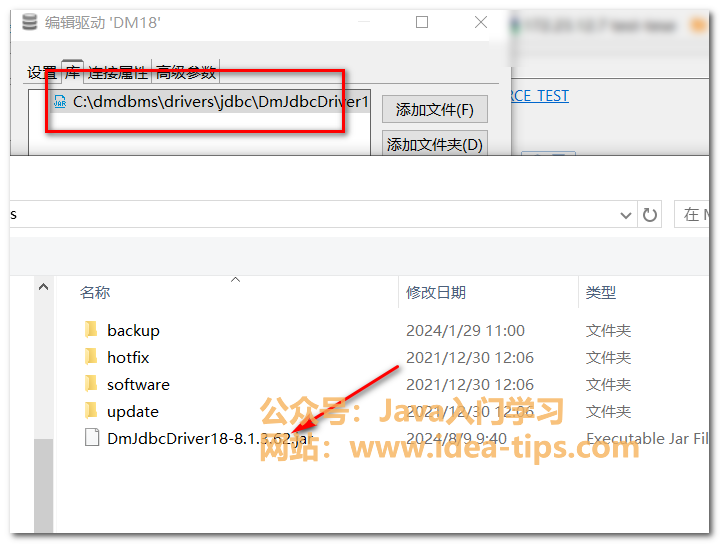
DBeave如何连接达梦数据库,设置达梦驱动,真酷
前言 我们在使用DBeaver连接数据库时,默认可以连接常用的数据库,如mysql数据库,postgresql数据库,oracle数据库。但是,我们的国产数据库达梦数据库,默认在IDEA里面没有驱动,所以还得配置一下才…...

2024年全球 MoonBit 编程创新赛-零基础早鸟教程-使用wasm4八小时开发井子棋小游戏
前言 本篇文章主要分享 “2024年全球 MoonBit 编程创新赛 游戏赛道”参赛过程中九宫棋游戏的开发技巧和心得。以此抛砖引玉。首先介绍下 MoonBit。 月兔语言 MoonBit 是一个用于云计算和边缘计算的 WebAssembly 端到端的编程语言工具链。 您可以访问 https://try.moonbitlang.…...

机器学习4
第3章 线性模型 3.1 线性模型的基本形式 3.1.1 线性模型的核心公式 线性模型通过属性的线性组合进行预测,其核心公式为: [ f(x) \omega_1 X_1 \omega_2 X_2 … \omega_d X_d b ] 其中: ω 1 , ω 2 , . . . , ω d \omega_1, \omega_…...

Python数值计算(33)——simpson 3/8积分公式
1. 背景知识 既然前的Simpson可以通过使用三个点构造二次曲线近似积分,那么,如果点数增加到了4个,然后不就可以构造三次多项式的曲线,实现对目标值的积分吗? 如果采用和上一节介绍的同样的方法,我们可以推…...

<项目代码>YOLOv8路面垃圾识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...
)
Java中的注解(白金版)
Spring中常用注解 Springboot中@Validated注解的使用 Swagger中常用注解 @Validate...

actor模型
Actor模型(Actor Model)是一种用于并发计算的数学模型和编程概念,它最早由计算机科学家 Carl Hewitt 等人提出,用于简化对多线程或并发系统的设计和实现。Actor模型在并发编程、分布式系统、消息传递系统等领域具有广泛应用。 核…...

合约门合同全生命周期管理系统:企业智能合同管理的新时代
合约门合同全生命周期管理系统:企业智能合同管理的新时代 1. 引言 随着现代企业的快速发展,合同管理的复杂性日益增加。无论是采购合同、销售合同还是合作协议,合同管理已成为企业运营中至关重要的一环。传统的手工合同管理方式往往效率低下…...

避开这些坑:ADSP-SC589开发中JTAG连接、驱动安装与调试的常见问题解决
ADSP-SC589开发实战:JTAG连接与调试避坑指南 当ADSP-SC589开发板与AD-HP530ICE仿真器首次相遇时,许多开发者会陷入连接失败的困境。不同于普通MCU开发,SHARC系列DSP的JTAG调试存在诸多技术细节,稍有不慎就会导致数小时的无效排查。…...

学习如何用CC-Switch + Claude Code 接入 DeepSeek-V4-Pro
1.概述 1.1.关键词 Claude Code:Anthropic 出品的 AI 编程命令行工具。在终端里让 AI 帮你写代码、改 Bug、分析项目。 CC-Switch:开源的图形化配置管理工具。一键切换 Claude Code 背后使用的模型,不用手动改配置文件。 1.2.目的 使用C…...

如何用wxlivespy实现微信视频号直播数据实时抓取与分析
如何用wxlivespy实现微信视频号直播数据实时抓取与分析 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy wxlivespy是一款专业级的微信视频号直播间弹幕信息抓取工具,能够实时捕获弹幕、…...

3大技术创新:重新定义Windows Android生态的工具体验
3大技术创新:重新定义Windows Android生态的工具体验 【免费下载链接】wsa-toolbox A Windows 11 application to easily install and use the Windows Subsystem For Android™ package on your computer. 项目地址: https://gitcode.com/gh_mirrors/ws/wsa-tool…...

[技术解析] 边缘结构模型MSM:破解时依性混杂的因果推断利器
1. 边缘结构模型MSM:因果推断的"时光机" 想象你是一名医生,正在研究某种降压药的长期疗效。患者A连续服药3个月后血压稳定,患者B服药1个月后自行停药导致血压反弹。传统统计方法会简单对比两组结果,但忽略了一个关键问…...

基于Python与yfinance构建本地化股票量化筛选器:以PKScreener为例
1. 项目概述与核心价值 最近在和一些做量化交易的朋友交流时,发现大家普遍面临一个痛点:虽然市面上有各种股票数据接口和量化平台,但真正能快速、灵活地根据自定义条件进行股票筛选,并且能本地化部署、深度定制的工具却不多。要么…...

36种阀体混线全自动智能分拣方案|3D视觉+机器人柔性制造实践
一、项目背景与行业痛点在高端流体控制设备制造领域,阀体、阀盖的精密分拣是保障产品质量的核心环节。随着工业设备向小型化、高精度方向发展,客户对阀体组件加工误差的控制要求持续提升,传统生产模式面临显著瓶颈:1. 人工分拣效率…...

MediaCreationTool.bat:革命性的Windows自动化部署解决方案
MediaCreationTool.bat:革命性的Windows自动化部署解决方案 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

HoRain云--PHP安全插入MySQL数据指南
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

从Siri上车看车载语音交互:技术演进、产业融合与安全设计
1. 项目概述:当Siri首次驶入驾驶舱2012年洛杉矶国际车展上的一则新闻,在当时的汽车与科技圈激起了不小的涟漪。通用汽车宣布,其旗下的雪佛兰品牌将成为首批将苹果Siri语音助手集成到车载信息娱乐系统中的汽车制造商,首发车型包括雪…...