【mysql进阶】4-5. InnoDB 内存结构
InnoDB 内存结构
1 InnoDB存储引擎中内存结构的主要组成部分有哪些?
🔍 分析过程
-
从官⽹给出的InnoDB架构图中可以找到答案
-
InnoDB存储引擎架构链接:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
✅ 解答问题
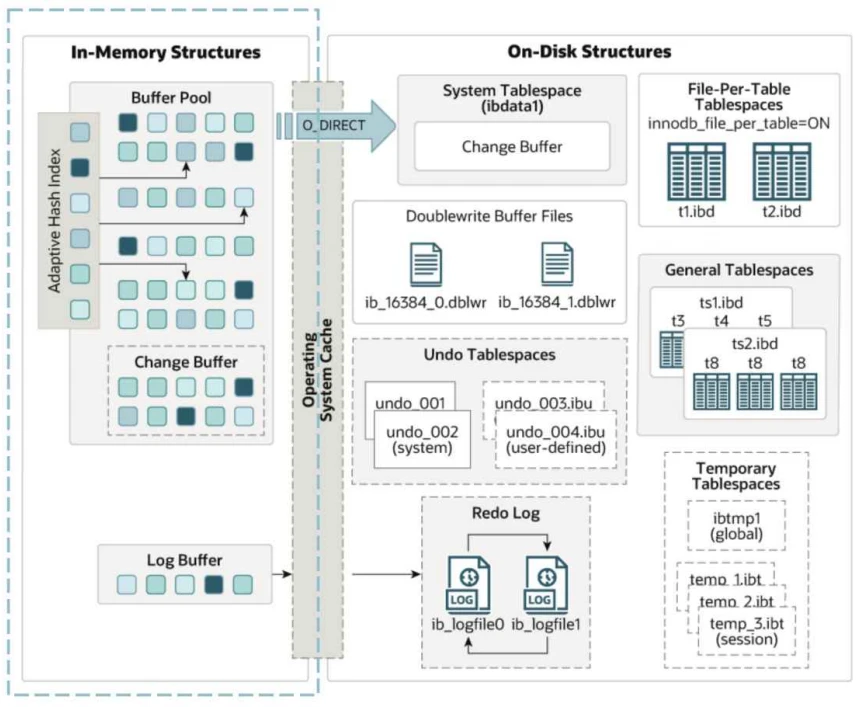
- InnoDB存储引擎中内存结构主要分为:
- Buffer Pool 缓冲池、
- Change Buffer 变更缓冲区
- adaptive_hash_index ⾃适应哈希索引
- Log Buffer ⽇志缓冲区
2 为什么需要内存结构?
✅ 解答问题
- 这个问题在InnoDB架构章节已经做了解释,再来回顾⼀下:
- 从MySQL实现的⻆度来思考这个问题,数据库的作⽤就是保存数据,⽤⼾的真实数据最终都会保存在磁盘上,在查询数据的过程中,如果每次都从磁盘上读取会严重影响效率,为了提⾼数据的访问效率,InnoDB会把查询到的数据缓存到内存中,当再次查询时,如果⽬标数据已经存在于内存中,就可以从内存中直接读取,从⽽⼤幅提升效率。
- 也就是说磁盘结构中的⽂件是⽤来保存数据实现数据持久化的,内存结构是⽤来缓存数据提升效率的。
3 缓冲池 - Buffer Pool
3.1 缓冲池的作⽤?
💡 前置知识
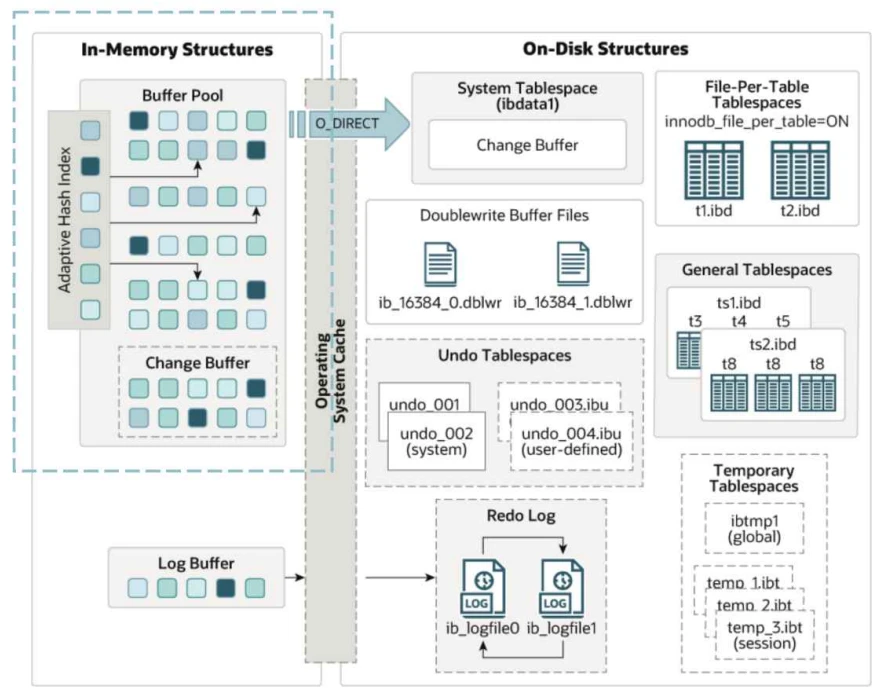
- 缓冲池在内存结构中的位置,如下图所⽰:
✅ 解答问题
- 缓冲池主要⽤来缓存被访问的InnoDB表和索引数据⻚,是主内存中的⼀⽚区域,允许直接从内存访问频繁使⽤的数据从⽽提⾼效率。在专⽤数据库服务器上,通常会将多达80%的物理内存分配给缓冲池。
- 其次缓冲池不仅缓存了磁盘的数据⻚,也存储了锁信息、Change Buffer信息、Adaptive hash index、Double write buffer等信息。如上图所⽰
3.2 缓冲池是如何组织数据的?
💡 前置知识
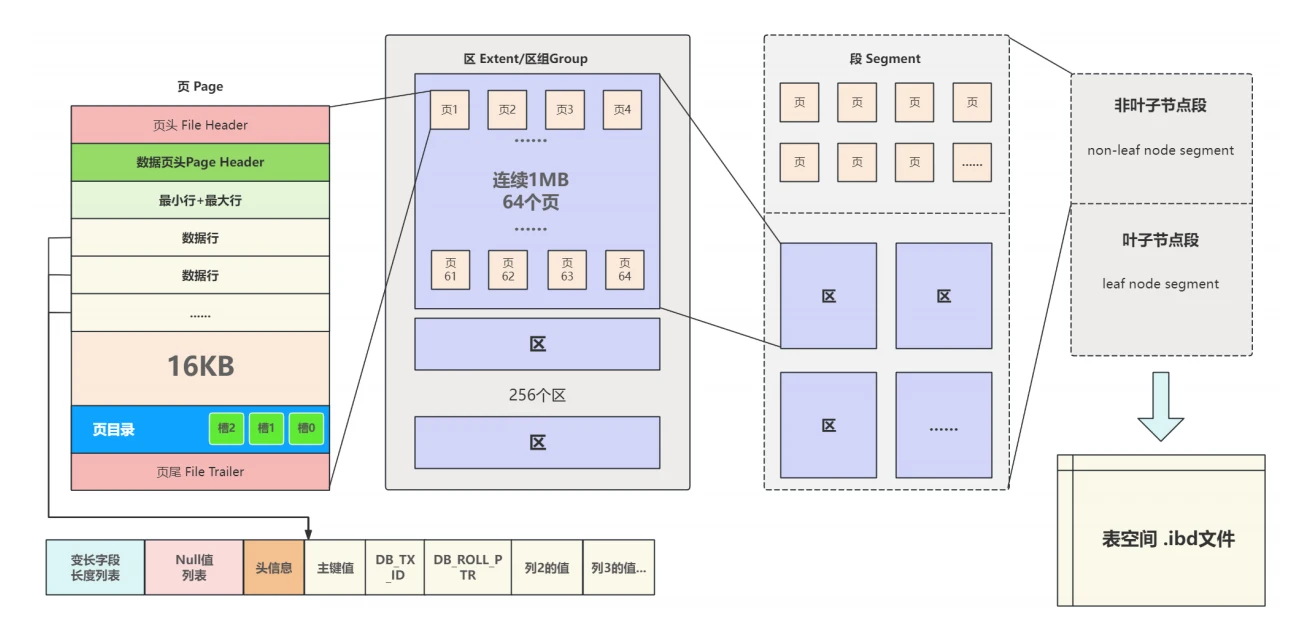
- 缓冲池组织数据的⽅式也可以说是缓冲池⽤到的数据结构,在这之前回顾⼀下InnoDB表空间的存储结构。
- 每个InnoDB表空间在磁盘上对应⼀个 .ibd ⽂件,其中包含了叶⼦节点段和⾮叶⼦节点段等逻辑段,段中包含了区组,区组中管理着区,区别包含数据⻚,数据⻚中包含数据⾏,每分别对着不同的数据结构⽬的就是便于数据的管理与⾼效访问
3.2.1 缓冲池的结构是怎样的?
-
从缓冲池的概念了解到它是主内存中的⼀⽚区域,在专⽤服务器上会将多达80%的物理内存分配给缓冲池,在这么⼤的内存空间中如何保证效率就是要解决的问题
-
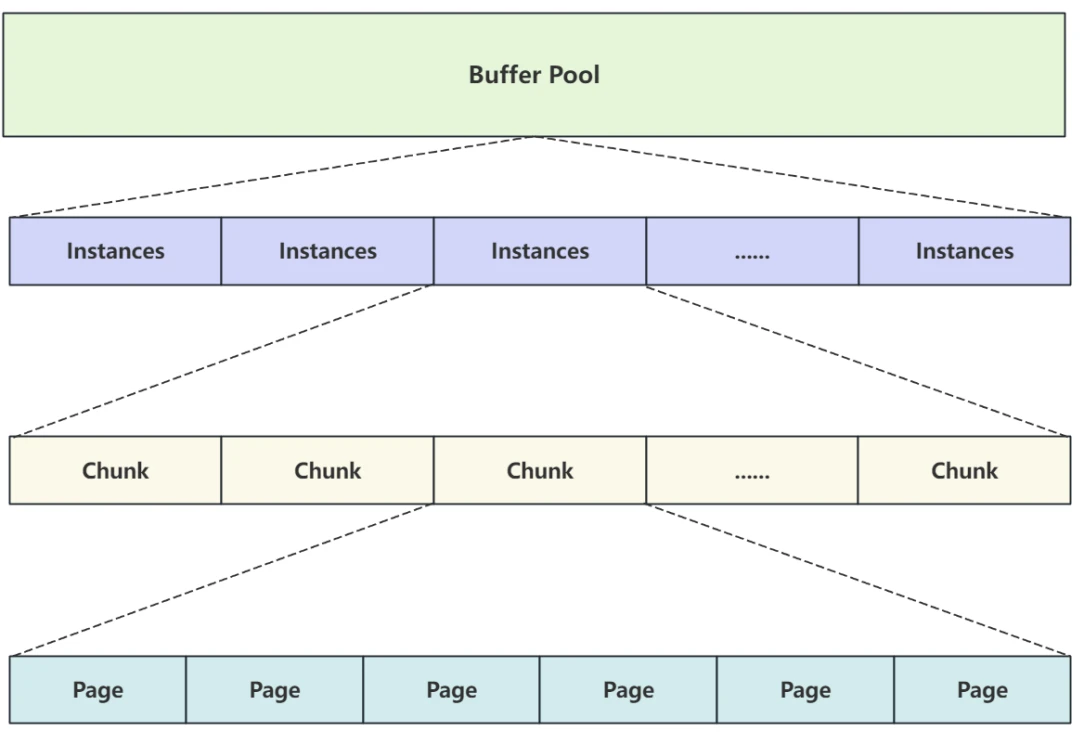
缓冲池也采⽤与表空间类似的⽅式对数据进⾏组织,如下图所⽰:
- 缓冲池中包含⾄少⼀个 Instances 实例, Instances 是真正的缓冲池的实例对象,内存操作都是在 Instances 中进⾏的;
- 每个 Instances 中包含⾄少⼀个 Chunk 块, Chunk 是在服务器运⾏状态下动态调缓冲池进⾏⼤⼩时操作的块⼤⼩;
- 每个块中包含和管理若⼲个从磁盘加载到内存的 Page 数据⻚
-
可以看出缓冲池通过定义不同的数据结构,但最终管理的是每个数据⻚,这些数据⻚是从磁盘中加载到内存的,也就是说磁盘中的数据⻚加载到内存中之后,对应的就是内存中的数据⻚,并且⻚与⻚之间⽤链表连接。
-
那么这时就有⼀个问题,我们知道磁盘中的数据⻚⼤⼩默认是16KB,并且通过头信息中的next_record 记录下⼀⾏地址偏移量,在⻚的结构定义中并没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,那么在内存中如何为每个⻚建⽴连接呢?
3.2.2 缓冲池中⻚与⻚之间是如何建⽴连接的?
- 由于数据⻚中没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,为了每个数据⻚在内存中实现链表连接,InnoDB定义了⼀个叫"控制块"的数据结构,"控制块"中有三个重要的信息分别是:
- 指向数据⻚的内存地址
- 前⼀个控制块的内存地址
- 后⼀下控制块的内存地址
- 之后再⽤⼀个双向链表管理每个控制块,如下图所⽰:
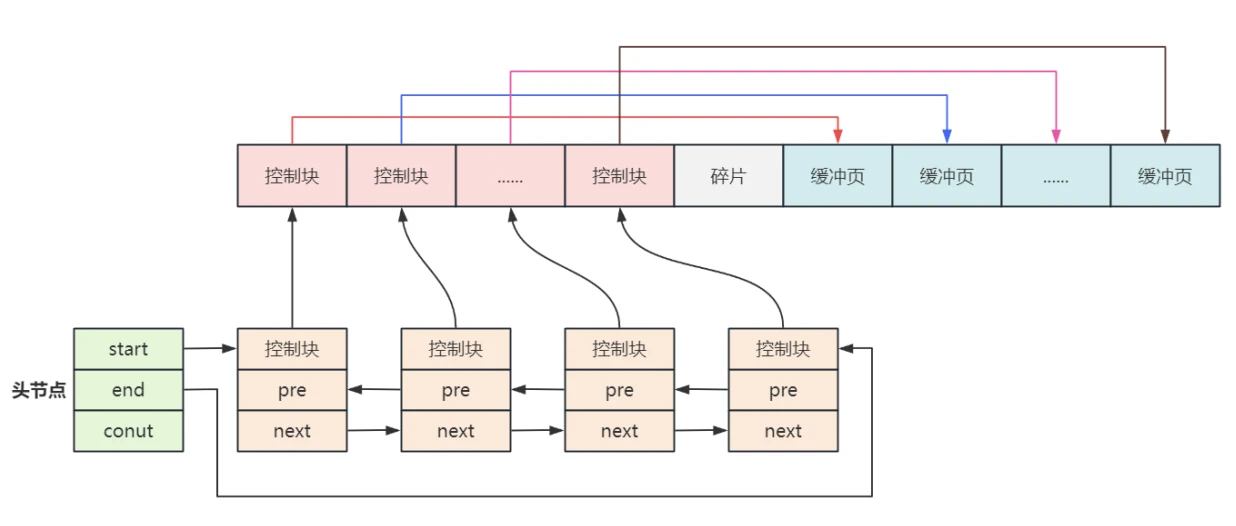
- 为了确定控制块链表的超始位置,专⻔定义了⼀个头节点,头节点中包含了三个主要的信息,如图中所⽰:
- 第⼀个控制块的内存地址
- 最后⼀个控制块的内存地址
- 链表中控制块的数量
- 通过遍历控制块链表就可以遍历内存中的数据⻚
✅ 解答问题
- 缓冲池中主要缓存的是磁盘中的数据⻚,由于数据⻚中没有⼀个字段⽤来表⽰内存中下⼀⻚的地址,InnoDB定义了"控制块"的数据结构,控制块中有⼀个指向数据⻚内存地址的指针,实现"控制块"与数据⻚的⼀⼀对应,并且把每个控制块连接成⼀个双向链表,⽤⼀个单独的头节点记录链表的第⼀个和最后⼀个节点,这样通过遍历控制块链表就可以遍历内存中的数据⻚。
3.2.3 内存中的数据⻚与磁盘上的数据⻚是什么关系?
磁盘上的数据⻚加载到内存中后,在缓冲池中都有⼀个内存⻚与它对应,只不过内存中管理的是控制块组成的链表,控制块有⼀个指针指向了内存中真实的数据⻚
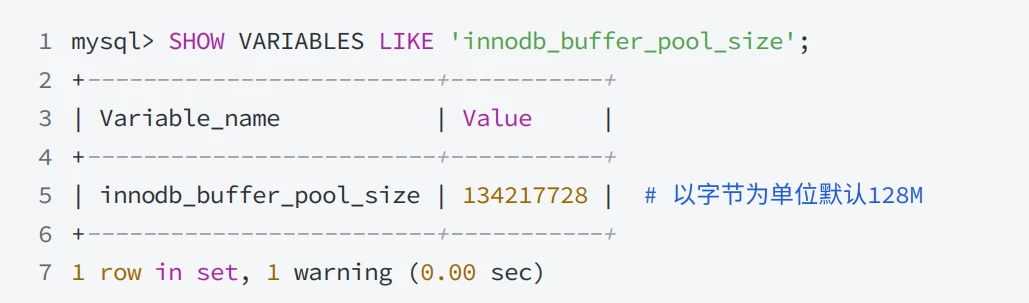
3.2.4 Buffer Pool的⼤⼩可以设置吗?
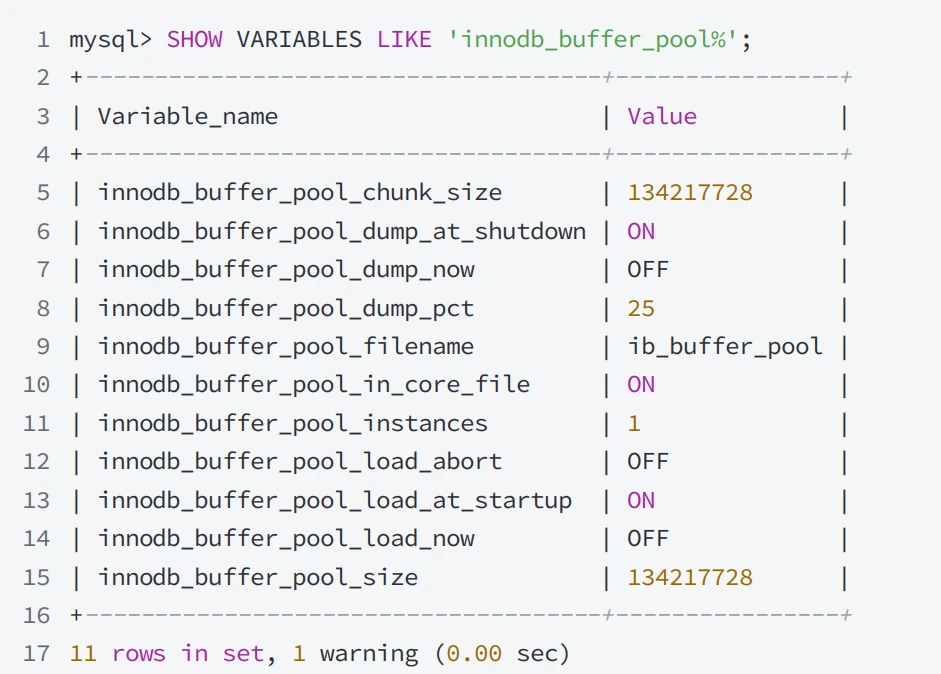
- 可以通过系统变量 innodb_buffer_pool_size 进⾏设置,设置时以字节为单位:默认值为134217728 字节,即 128MB ;最⼤值取决于CPU架构和操作系统,在 32 位系统上最⼤值为4294967295 (2^32 -1),在 64 位系统上最⼤值为 18446744073709551615 (2^64 -1)
- 这⾥需要注意的是, InnoDB 为"控制块"分配额外的内存空间,也就是说"控制块"并不会占⽤Buffer Pool的内存空间,所以实际分配的内存总空间⽐指定的缓冲池⼤⼩⼤ 10%左右。
- 缓冲池设置的值越⼤,在多次访问相同表数据时,磁盘I/O就会越少,因为数据都已经缓存在内存中,所以效率也就越⾼,但是服务器启动时初始化时间会⽐较⻓。
- 查看缓冲池⼤⼩可以使⽤下⾯的SQL语句
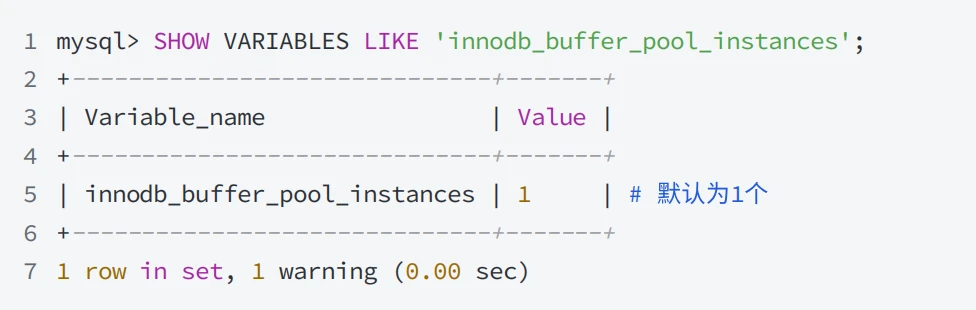
3.2.5 Buffer Pool中Instances的数量如何确定?
-
通过系统变量 innodb_buffer_pool_instances 可以设置缓冲池实例的个数,默认是 1 ,最⼤值 64 ;
-
当缓冲池的⼤⼩⼩于 1GB 时,⽆论指定 innodb_buffer_pool_instances 数是多少都会⾃动调整为 1 ;
-
当缓冲池的⼤⼩⼤于 1GB 时, innodb_buffer_pool_instances 默认值为 8 ,也可以指定⼤于 1 的值来设置 Instances 的数量,多个 Instances 可以提升服务器的并发性;
-
为了获得最佳的效率,通过指定 innodb_buffer_pool_instances 和 innodb_buffer_pool_size 为每个缓冲池实例设置⾄少为 1GB 的空间;
-
查看Instances的数量可以使⽤下⾯的SQL语句
3.2.6 Chunk的作⽤是什么?
- Chunk 是在服务器运⾏状态下动态调缓冲池进⾏⼤⼩时操作的块⼤⼩,为避免在调整⼤⼩操作期间复制所有缓冲池中的数据⻚,调整操作以 "块"为基本单位执⾏;
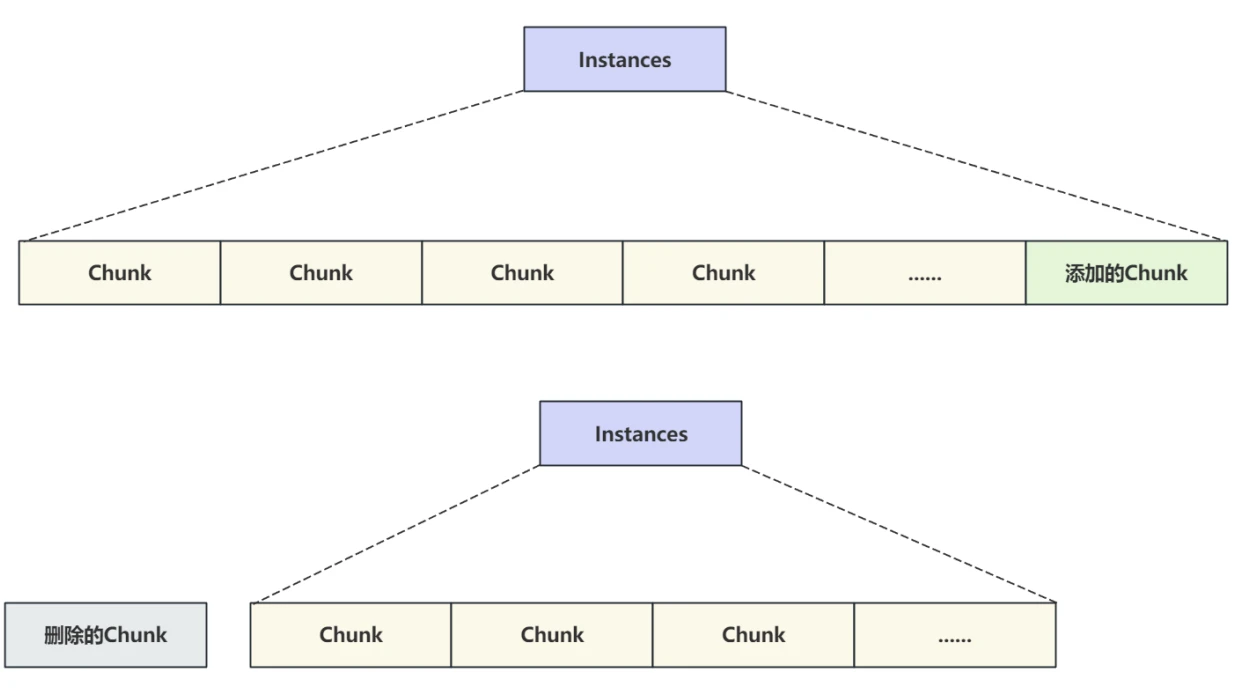
- ⽐如在服务器运⾏时想要调整缓冲池的⼤⼩可以通过以下SQL语句:

- 注意:启动调整⼤⼩操作时,在所有活动事务完成后操作才会开始。⼀旦调整⼤⼩操作开始,新的事务和操作必须等到调整⼤⼩操作完成才可以访问缓冲池。
3.2.7 Instances中Chunk的数量如何确定?
-
Chunk⼤⼩可以通过系统变量innodb_buffer_pool_chunk_size进⾏设置,默认为134217728 字节即 128MB ;在设置⼤⼩时可以以 1048576 字节即 1MB 为单位增加或减少;块中包含的数据⻚数取决于innodb_page_size; -
更改
innodb_buffer_pool_chunk_size的值时注意以下条件 :-
如果 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances ⼤于当前缓冲池⼤⼩, innodb_buffer_pool_chunk_size 将被截断为innodb_buffer_pool_size / innodb_buffer_pool_instances 。
-
缓冲池⼤⼩必须始终等于或倍数于
innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances。如果修改了innodb_buffer_pool_chunk_size的值,导致不符合这个规则,那么在缓冲池初始化时innodb_buffer_pool_size 会⾃动四舍五⼊为等于或者倍数于innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的值。
-
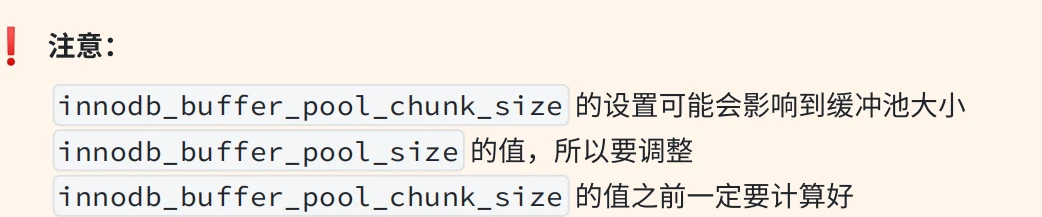
3.2.8 控制块与Page是如何初始化的?
- 前⾯介绍了 Chunk 中管理的是具体的数据⻚,当缓冲池初始化完成时会把每个数据⻚所占⽤的内存空间和对应的控制块分配好,只不是没有从磁盘加载数据时,内存中的数据⻚是空的⽽已。
- 当缓冲池初始化的过程中,会为 Chunk 分配置内存空间,此时"控制块"会从 Chunk 的内存空间从左向右进⾏初始化,数据⻚所占的内存会从 Chunk 的内存空间从右向左进⾏初始化,当所剩的内存空间不够⼀组"控制块" + 数据⻚所占的空间时,就会产⽣碎⽚空间,如果适好够⽤则不会出现碎⽚空间,如下图所⽰:
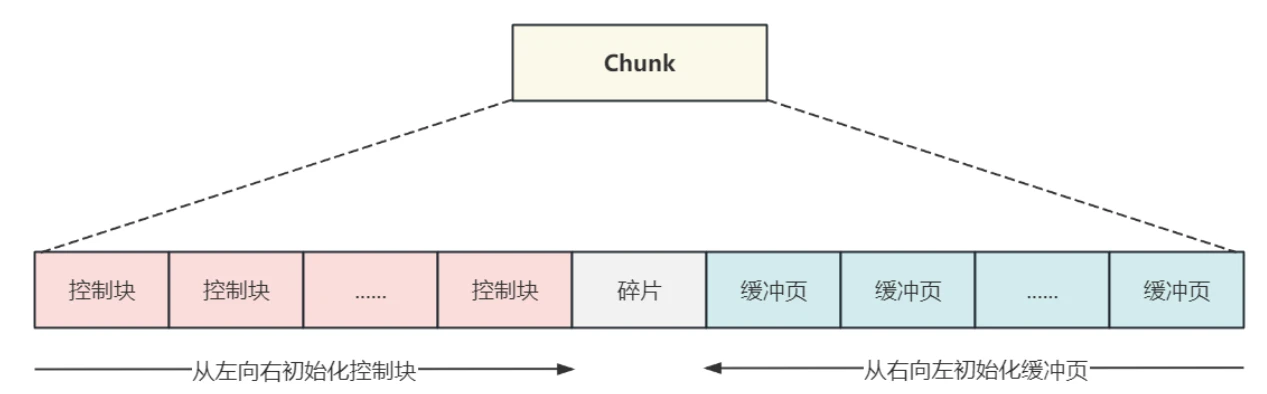
- 内存初始化完成之后,建⽴控制块与内存中缓冲数据⻚之间的关系,从左开始第⼀个控制块指向第⼀个缓冲数据⻚的内存地址
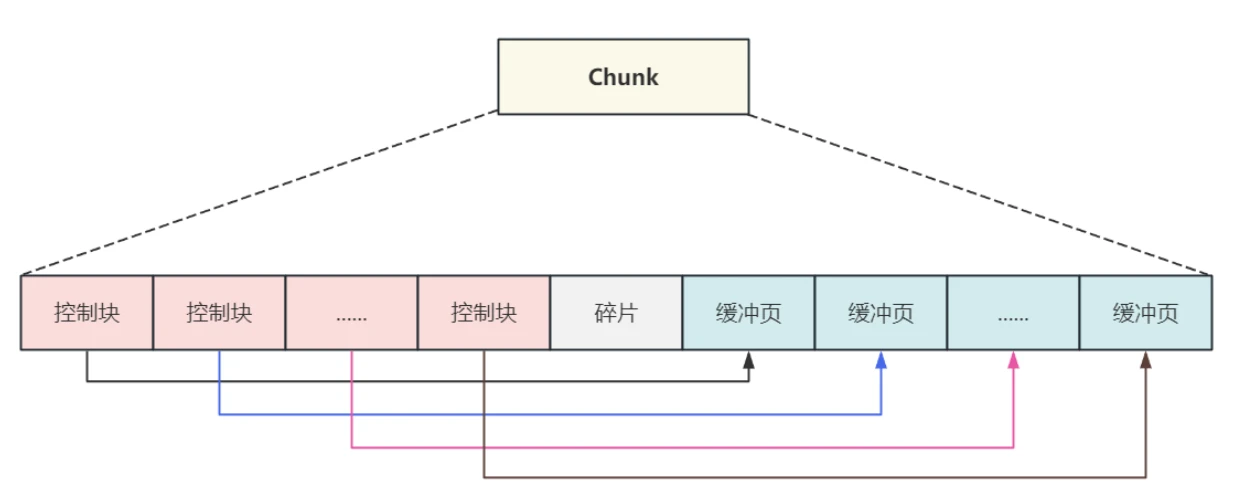
- 当前从磁盘中加载数据⻚时,就可以在把数据缓存在内存中的空闭数据⻚中
3.2.9 可以通过缓冲池配置来提升性能吗?
当然可以,通过配置以下关于缓冲池的系统变量来提⾼性能,其中包括:
- 配置缓冲池⼤⼩
- 配置多个缓冲池实例
- 防⽌缓冲池扫描
- 配置缓冲池预取(预读)
- 配置缓冲池刷新策略
- 保存和恢复缓冲池状态
- 从核⼼⽂件中排除缓冲池⻚
- 这些变量可以通过以下语句查看
3.3 缓冲池中的⻚是如何进⾏管理的?
分析过程
- 当缓冲池初始化完成后,缓冲池中的数据⻚只是被分配了内存空间,并没有真实的数据,当⽤⼾进⾏数据查询时真实的数据从磁盘加载到内存中并分配⼀个内存中的数据⻚,这时内存中数据⻚的状态从空间变成了有实际的数据;当⽤⼾修改数据时,并不是直接修改磁盘中的数据⻚,⽽是修改内存中数据⻚中的数据⻚,这时内存中数据⻚的状态从有实际数据变成了被修改。
- 在缓冲池中采⽤三个链表维护内存⻚,这三个链表也对应着内存中⻚的三种状态,分别是:
- Free 未使⽤的⻚,也可以称做空闲⻚;
- Clean 已使⽤但未修改的⻚,也可以称做⼲净⻚;
- Dirty 已修改的⻚,也可以称做脏⻚。
- 对应的三个链表分别是 Free List 、 LRU List 和 Flush List :
- Free List :只管理Free ⻚
- LRU List :管理 Clean⻚和Dirty⻚
- Flush List :只管理Dirty⻚
- 如下图所⽰
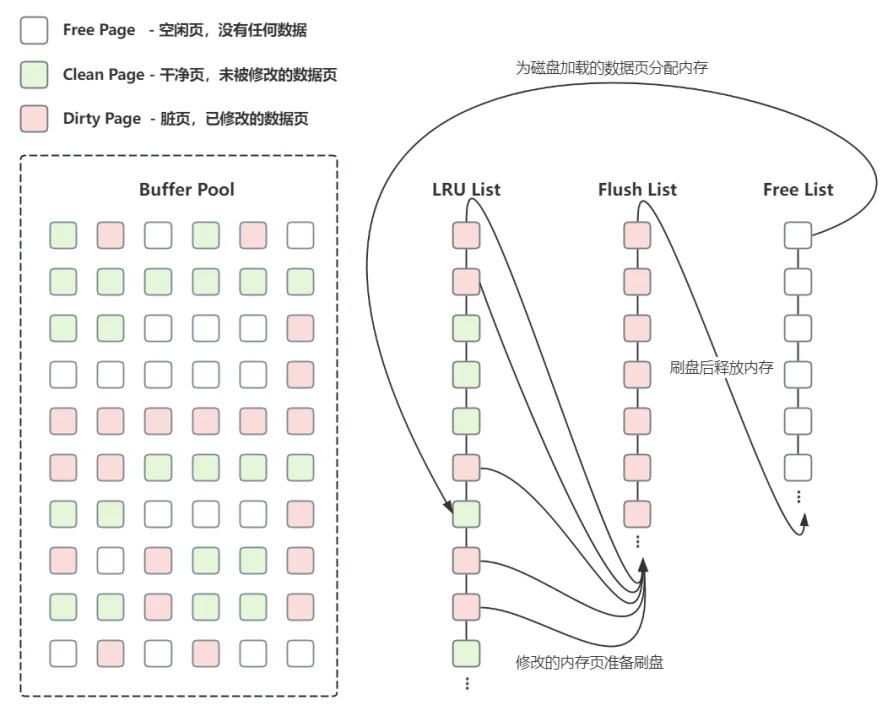
Free List:管理着空闲的也就是没有被使⽤的内存⻚,当执⾏查询操作时,如果对应的⻚已经在 buffer pool 中则直接返回数据,如果没有且 Free List 不为空,则从磁盘中查询对应的数据并存到 Free List 的某⼀⻚中,然后把这个⻚从 Free List 中移除并放⼊ LRU List中。LRU List:管理所有从磁盘中读取的数据⻚,包括未被修改的和已被修改的数据⻚,并根据LRU算法对链表中的⻚节点进⾏维护与淘汰。当数据库刚启动时 LRU List 是空的,这时从内存中申请到的⻚都存放在 Free List 中,当数据从磁盘读取到缓冲池时,⾸先从 Free List 中查找是否有可⽤的空闲⻚,如果有则把该⻚从 Free List 中删除并加⼊到 LRU List ;如果没有,则根据 LRU 算法淘汰 LRU List 末尾的⻚,并将该内存空间分配给新数据⻚;Flush List:当 LRU List 中的⻚被修改后会被标识为脏⻚(Dirty page),并把脏⻚加⼊到Flush List 中,在这种情况下,数据库会通过刷盘机制把 Flush List 中的脏⻚刷回磁盘; Flush List 是⼀个专⻔⽤来管理脏⻚的列表。脏⻚既存在于 LRU List 中,也存在于Flush List 中, LRU List ⽤来管理缓冲池中⻚的可⽤性,Flush List⽤来管理要被刷回磁盘的⻚,⼆者互不影响。 Flush List 中的脏⻚在执⾏了刷盘操作后会将空间还给FreeList。
✅ 解答问题
- 每个缓冲池都采⽤三个链表维护内存⻚,这三个链表也对应着内存中⻚的三种状态,分别是:
Free未使⽤的⻚,也可以称做空闲⻚;Clean已使⽤但未修改的⻚,也可以称做⼲净⻚;Dirty已修改的⻚,也可以称做脏⻚。
3.3.1 内存中有这么多数据⻚如何快速找到⽬标⻚?
- ⾸先第⼀种办法是通过遍历,这种做法显⽰不能满⾜性能要求
InnoDB采⽤的是Page Hash的⽅式,也就是每当把磁盘中数据⻚加载到内存时,⽤数据⻚的表空间Id和⻚号做为Key,当前⻚在内存中的地址做为Value保存起来,每次查询时就可以通过Key快速定位到⽬标⻚,如果内存中没有⽬标⻚,则从磁盘中获取。
3.3.2 缓冲池中的数据放不下了怎么办?
- nnoDB根据根据⾃⾝的实际场景,使⽤淘汰策略来淘汰相应的数据⻚,从⽽释放出内存空间,以便新的数据⻚加载到内存中。
3.4 缓冲池采⽤哪种淘汰策略?是如何实现的?
🔍 分析过程
- 缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法(在原来LRU算法的基础做了修改),以下出现的LRU算法指的是LRU变形算法。
- 缓冲池使⽤ LRU算法管理链表,当有新⻚⾯添加到缓冲池时,最近最少使⽤的⻚将被淘汰,并将新⻚添加到列表的中间,这种中点插⼊策略将列表视为两个⼦列表:
- 链表头部,是存放最近访问的新⻚(年轻⻚)⼦列表;
- 链表尾部,是存放最近较少访问的旧⻚⼦列表
- 如下图所⽰:
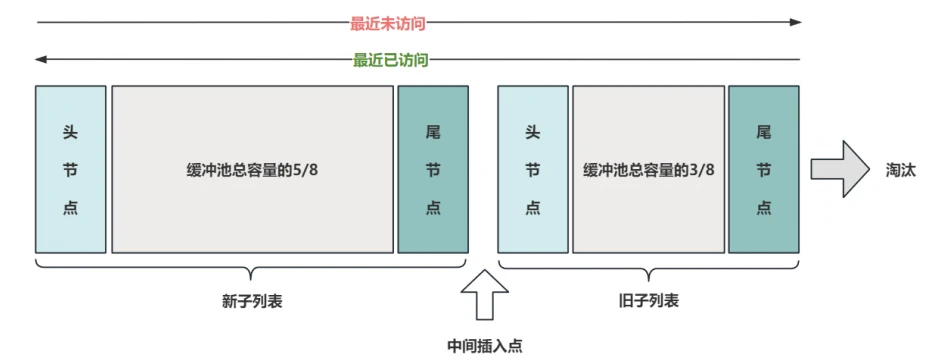
- 经常使⽤的⻚保存在新⼦列表中,较少使⽤的⻚保存在旧⼦列表中,随着时间的推移,旧⼦列表中的⻚将会逐渐被淘汰。默认情况下,算法的执⾏过程如下:
- 缓冲池总容量的 5/8 ⽤于新⼦列表,3/8⽤于旧⼦列表;
- 列表的中间插⼊点是新⼦列表的尾部与旧⼦列表头部的交界;
- 当⼀个⻚被读⼊缓冲池时,⾸先插⼊到中点做为旧⼦列表的头节点;
- 当访问的⻚在旧⼦列表中时,把被访问的⻚移动到新⼦列表的头部,使其成为 “新” ⻚;
- 数据库运⾏的过程中,缓冲池中被访问⻚⾯的位置不断更新,未访问的⻚⾯向列表的尾部移动,从⽽逐渐"变⽼" ,最终超出缓冲池容量的⻚从旧⼦列表的尾部被淘汰。
✅ 解答问题
- 缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法
3.4.1 为什么要把⻚插⼊到中间⽽不是直接插⼊到新⼦列表的头部?
- 因为InnoDB在读取⻚时,可能会发⽣"预读",预读的意思是InnoDB根据当前访问的记录⾃动推断后⾯可能会访问哪个⻚,并把他们提前加载到内存中,从⽽提⾼以后查询的效率,预读的⻚以并不⼀定会被真正的读取,从中间点插⼊可以使其尽快被淘汰。
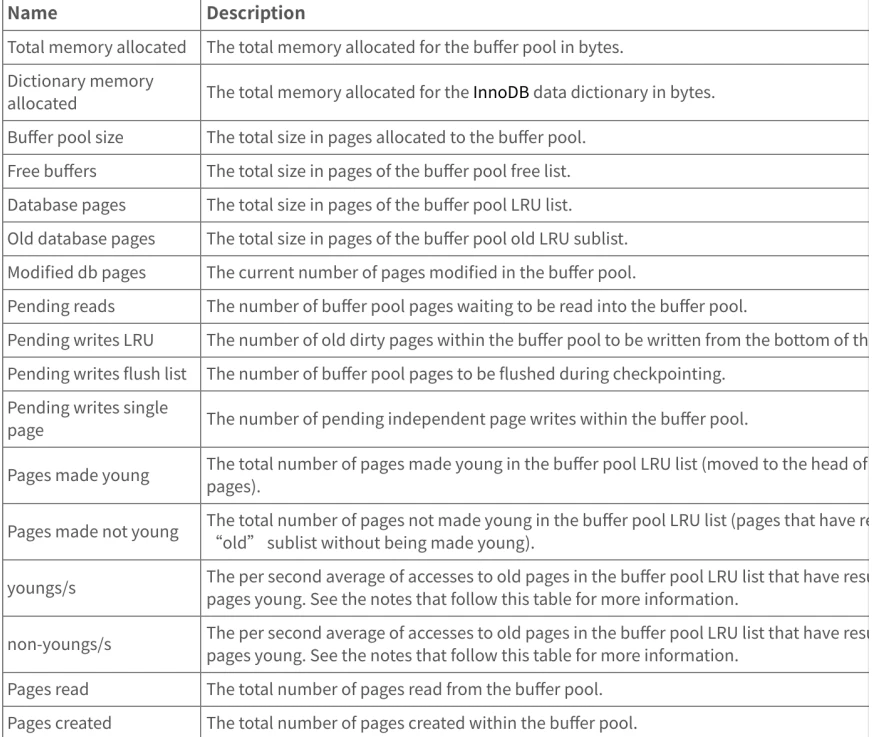
3.5 怎么查看当前缓冲池的信息?
✅ 解答问题
- 通过使⽤
SHOW ENGINE InnoDB STATUS访问InnoDB标准监视器输出中BUFFER POOL AND MEMORY部分查看有关缓冲池的指标。缓冲池指标位于InnoDB标准监视器输出的缓冲池和内存部分:
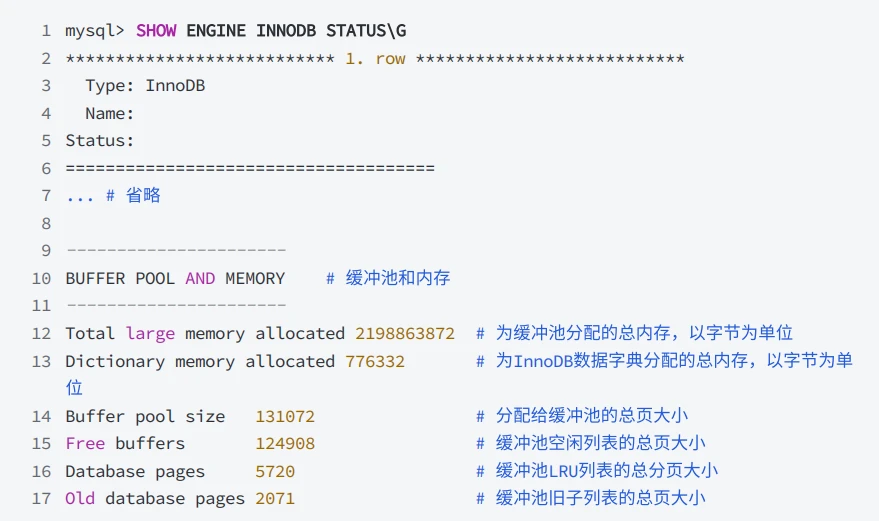
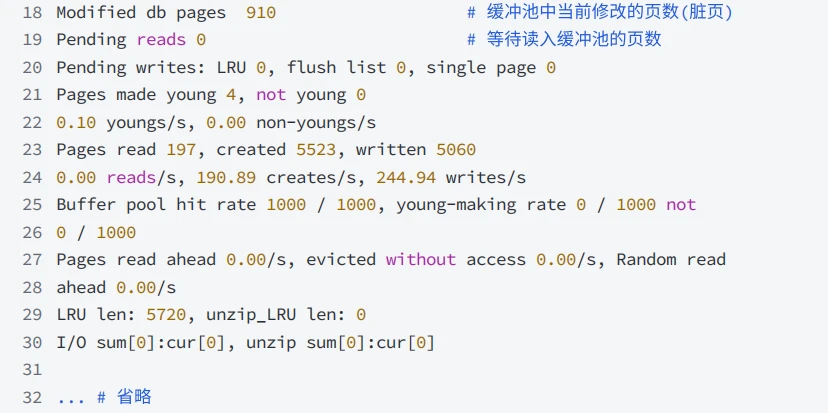
- InnoDB缓冲池指标如下,以供参考:
小结
❤ ⼩结
缓冲池是⽤来缓存各种数据,最主要的就是缓存从磁盘中加载的数据⻚,从⽽提升效率
缓冲池为了⽅便数据组织定义了不同的数据结构,包括 Instances 实例, Chunk块,其中 Buffer Pool 中包含⾄少⼀个 Instances , Instances 包含⾄少⼀个Chunk 块, Chunk 管理若⼲个从磁盘加载到内存的 Page 数据⻚
缓冲池能过三个链表管理内存中的数据⻚,分别是 Free List 、 LRU List 和 Flush List
缓冲池淘汰策略采⽤变形的最近最少使⽤(LRU)算法
4 变更缓冲区 - Change Buffer
- 变量缓冲区在内存中的位置
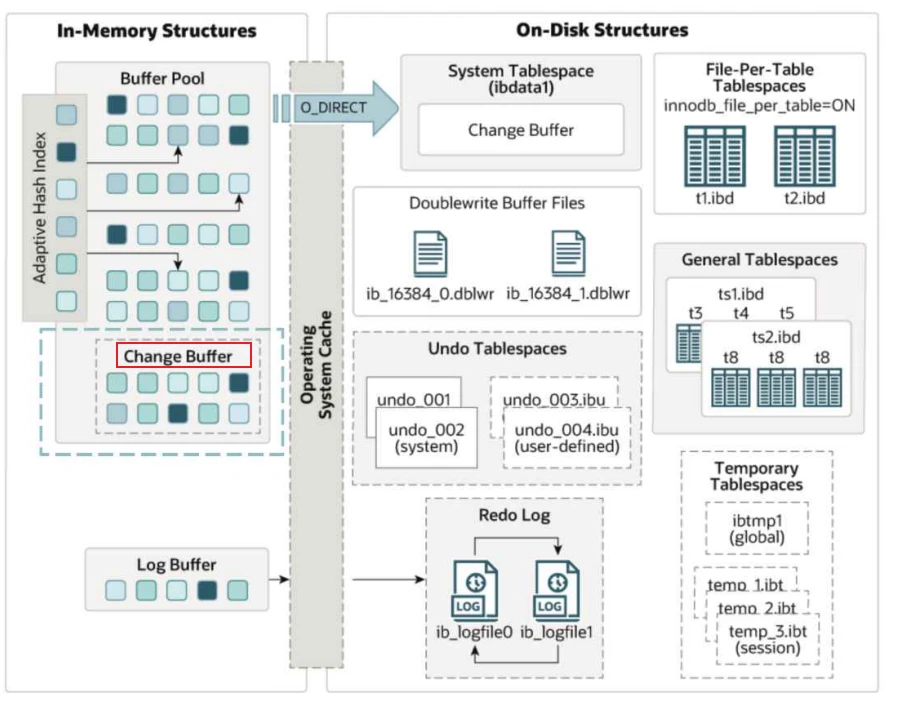
4.1 变更缓冲区的作⽤?
🔍 分析过程
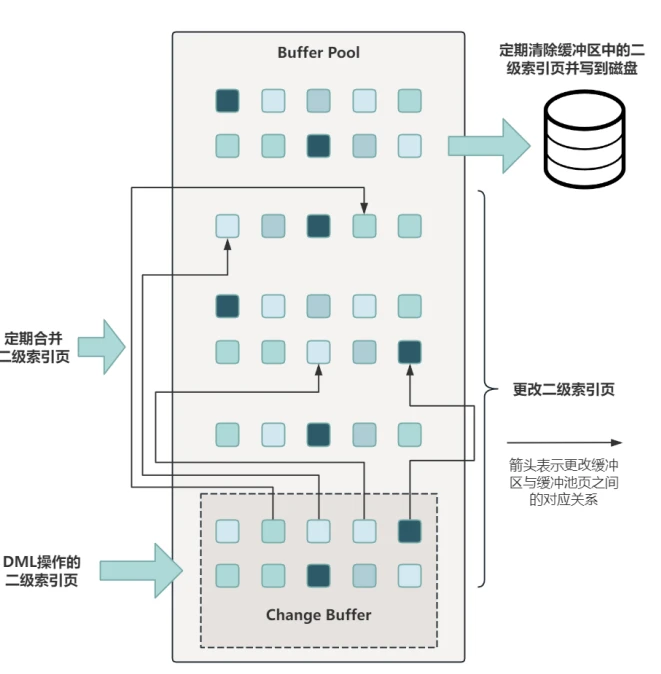
-
变更缓冲区占⽤Buffer Pool的⼀部分空间,具体如图所⽰:
-
变更缓冲区⽤来缓存对⼆级索引数据的修改,是⼀个特殊的数据结构,当使⽤ INSERT 、UPDATE 或 DELETE 语句修改⼆级索引对应的数据时,如果对应的数据⻚在缓冲池中则直接更新,如果不在缓冲池中,那么就把修改操作缓存到变更缓冲区,这样就不⽤⽴即从磁盘读取对应的数据⻚了,当之后的读操作将对应的数据⻚从磁盘加载到缓冲池中时,变更缓冲区中缓存的修改操作再批量合并到缓冲池,从⽽达到减少磁盘I/O的⽬的。执⾏流程如图所⽰:
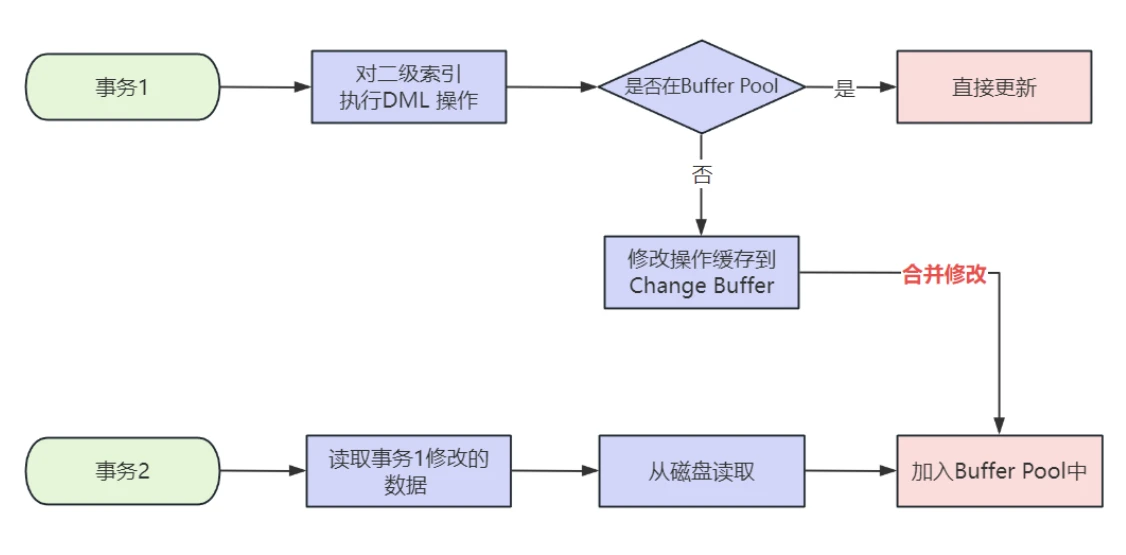
✅ 解答问题
- 变更缓冲区⽤来缓存对⼆级索引数据的修改,当数据⻚没有被回载到内存中时先把修改缓存起来,等到其他查询操作发⽣时数据⻚被加载到内存后,再直接修改内存中的数据⻚,从⽽达到减少磁盘I/O的⽬的。
👼 衍⽣问题
4.1.1 为什么是⼆级索引?
- 关于索引在数据库初阶已经做了介绍,我们知道索引分为聚集索引(主键)和⼆级索引(⾃定义)
- 由于聚集索引具有唯⼀性,我们分析⼀下聚集索引为什么不能被放⼊变更缓存,假设表中有⼀个主键( ID ),现在有两条 INSER 语句,都在插⼊数据时ID的值相同 (id=1) ,那么在变更缓冲区中就存在两个修改操作,如果以后要合并到缓冲池中,这时就会出现重复的主键值,所以聚集索引的修改不能被加⼊到变更缓冲区;
- 与聚集索引不同,⼆级索引通常是不唯⼀的,并且向⼆级索引中插⼊数据时由于数据列不同,所以位置相对随机,同样对于删除和更新操作可能会影响不相邻的⼆级索引⻚,如果每次都从磁盘读取数据就会发⽣⼤量的随机I/O,以变更缓冲区的⽅式先将修改缓存起来,当真正的读取数据时再把修改合并到缓冲池中可以提升效率。
4.1.2 Merge的触发时机有哪些?
- 读取对应的数据⻚时;
- 当系统空闲或者 Slow Shutdown 时,主线程发起 merge ;
- Change buffer 的内存空间即将耗尽时;
- Redo Log 写满时。
4.2 变更缓冲区的主要配置项都有哪些?
🔍 分析过程
- 主要的配置项有缓冲类型和更改缓冲区的最⼤⼤⼩
- 缓冲类型
在修改⼆级索引数据时变更缓冲区可以减少磁盘I/O从⽽提⾼效率,但是变更缓冲区占⽤了缓冲池的⼀部分空间,从⽽减少了可⽤于缓存数据⻚的内存,如果业务场景读多写少,或者表中的⼆级索引相对较少,那么可以考虑禁⽤更改缓冲从⽽提⾼缓冲池空间。
可以通过选项⽂件或 SET GLOBAL 语句对系统变量 innodb_change_buffering 进⾏设置,来控制变更缓冲区对于插⼊、删除操作(索引记录被标记为删除)和清除操作(当索引记录被物理删除时)的开启或禁⽤:
删除操作:索引记录被标记为删除
清除操作:索引记录被物理删除时
更新操作:是插⼊和删除操作的组合
- all : 默认值,缓存插⼊、删除标记操作和清除
- none :不缓存任何操作
- inserts :只缓存插⼊操作
- deletes :只缓存删除标记操作
- changes :缓存插⼊和删除标记操作
- purges :缓存发⽣在后台的物理删除操作
- 更改缓冲区的最⼤⼤⼩
- 通过
innodb_change_buffer_max_size系统变量可以设置更改缓冲区的最⼤⼤⼩,默认为25,最⼤为50,表⽰更改缓冲区占缓冲池内存总⼤⼩的百分⽐。 - 在有⼤量插⼊、更新和删除的业务场景中,可以考虑增加
innodb_change_buffer_max_size的值,在⼤部分是读多写少,⽐如⽤于报表的静态数据场景中考虑减⼩innodb_change_buffer_max_size的值 - 需要注意的是,如果更改缓冲区占了缓冲池太多的内存空间,会导致缓冲池中的数据⻚更快地淘汰。
✅ 解答问题
- 主要的配置项有缓冲类型和更改缓冲区的最⼤⼤⼩
4.3 怎么查看当前变更缓冲区的信息?
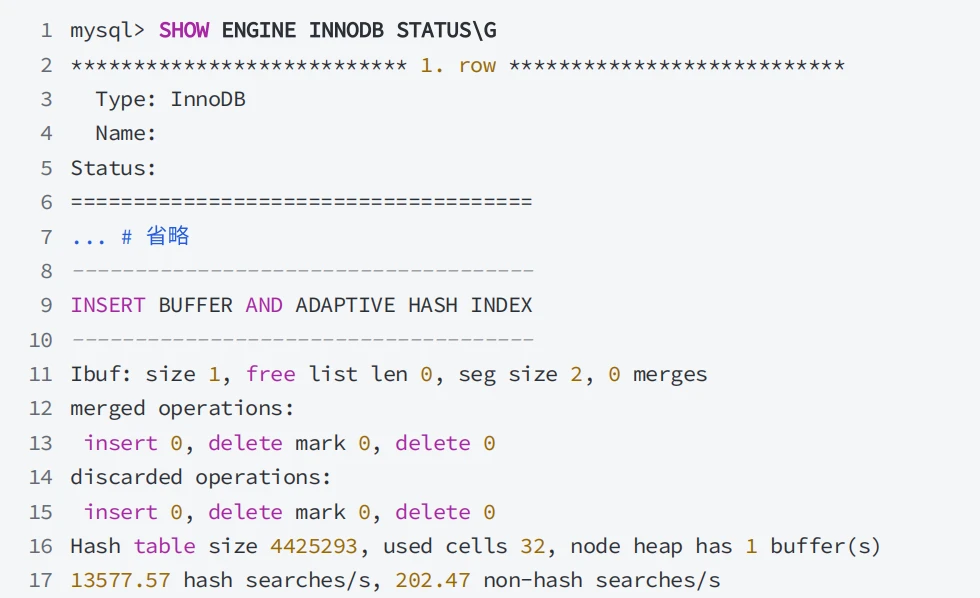
- 通过使⽤
SHOW ENGINE InnoDB STATUS访问InnoDB标准监视器输出中INSERTBUFFER AND ADAPTIVE HASH INDEX部分查看有关更改缓冲区状态的信息。
5 ⾃适应哈希索引
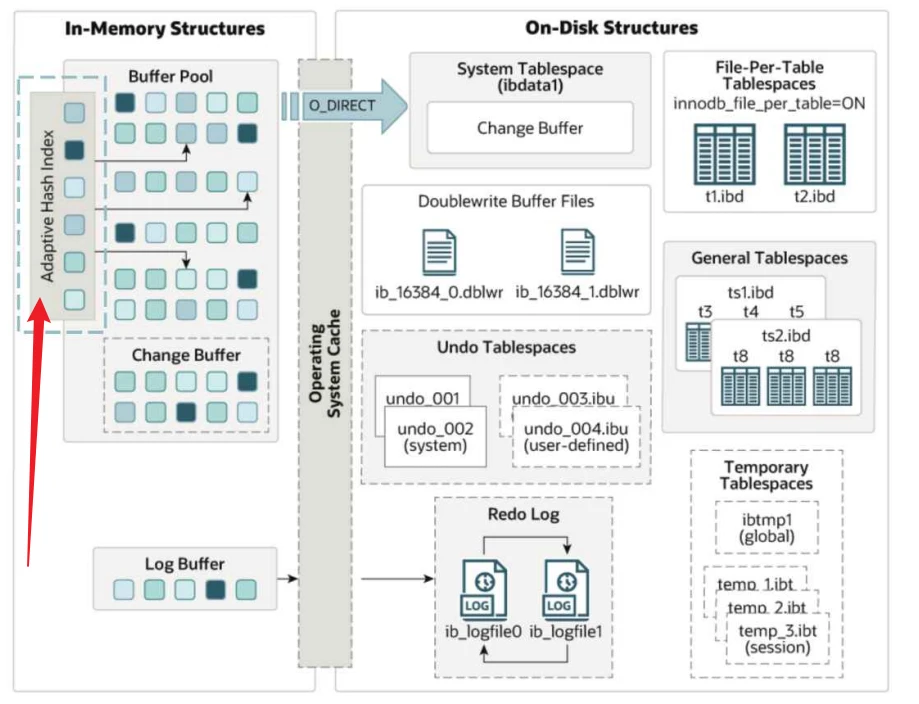
⾃适应哈希索引在内存中的位置
5.1 ⾃适应哈希索引的作⽤?
- ⾃适应哈希索引可以使InnoDB存储引擎在不牺牲事务特性和可靠性以及缓冲池空间⾜够的前提下提升效率,使⽤起来更像是⼀个内存数据库,哈希索引根据经常访问的索引⻚⾃动构建;
- 根据InnoDB内部的监控机制,如果监控到某些查询通过建⽴哈希索引可以提⾼性能,则⾃动对这个⻚创建哈希索引,这个过程称为⾃适应,所以叫⾃适应哈希索引;
- 如果表完全放在内存中,则哈希索引可以通过直接查找任何元素来加快查询速度
✅ 解答问题
- ⾃适应哈希索引的主要作⽤就是提升查询效率
5.1.1 为什么要创建⾃适应哈希索引?
- InnoDB存储引擎的数据存储于B+树中,B+树通常只有3到5层,但从根节点到叶节点的寻路涉及到多层⻚⾯内记录的⽐较,即使所有路径上的⻚⾯都在内存中,也⾮常消耗CPU的资源
- InnoDB对寻路的开销进⾏了优化,⽐如寻路结束后将cursor缓存起来⽅便下次查询复⽤;尽可能的避免单词寻路开销,Adaptive hash index(AHI)便是为此⽽设计,可以理解为B+树的索引
- 本质上是通过缩短寻路路径(Search Path)从⽽提升MySQ查询性能的⼀种⽅式
5.1.2 ⾃适应哈希索引的Key - Value如何设置?
以查询条件为key,B+树⻚的地址为value的Hash Index
5.1.3 ⾃适应哈希索引在保存在哪⾥?
- ⾃适应哈希索引会占⽤缓冲池⼀部分内存区域,在缓冲池初始化后被初始化,为了避免AHI的锁竞争压⼒,AHI⽀持分区,可以使⽤
innodb_adaptive_hash_index_parts参数配置分区个数,默认为 8 。
注意:⾃适应哈希索引是InnoDB内部的优化⽅式,外部不能⼲预
5.2 关于⾃适应哈希索引有哪些配置项?
✅ 解答问题
-
通过设置系统变量
innodb_adaptive_hash_index开启或关闭⾃适应哈希索引-
在选项⽂件中设置系统变量 innodb_adaptive_hash_index=[1|0] 实现开启与关闭
-
通过命令⾏选项 --skip-innodb-adaptive-hash-index 也可以关闭⾃适应哈希索引
-
-
每个⾃适应散列索引被绑定到不同的分区中,每个分区有不同的锁保护,分区数量由系统变量
innodb_adaptive_hash_index_parts控制,默认置为 8 ,最⼤值为 512 。
5.3 怎么查看⾃适应哈希索引的信息?
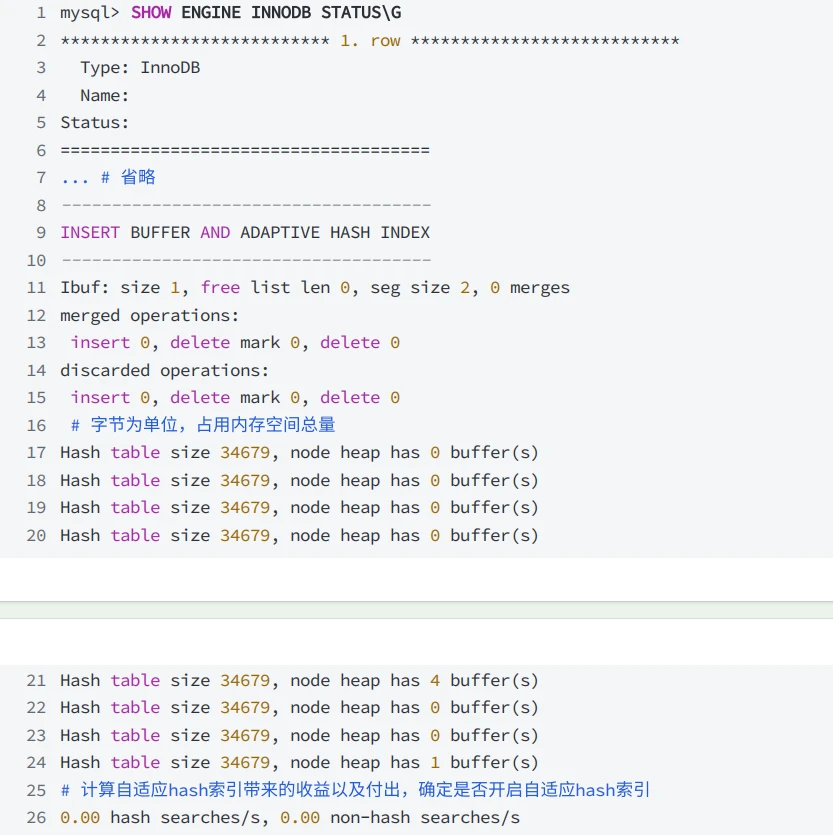
通过使⽤ SHOW ENGINE InnoDB STATUS 访问 InnoDB 标准监视器输出中 INSERT BUFFER AND ADAPTIVE HASH INDEX 部分查看⾃适应哈希索引使⽤信息,如果锁争抢过多,可以考虑增加⾃适应哈希索引分区数量或禁⽤⾃适应哈希索引。
6 ⽇志缓冲区
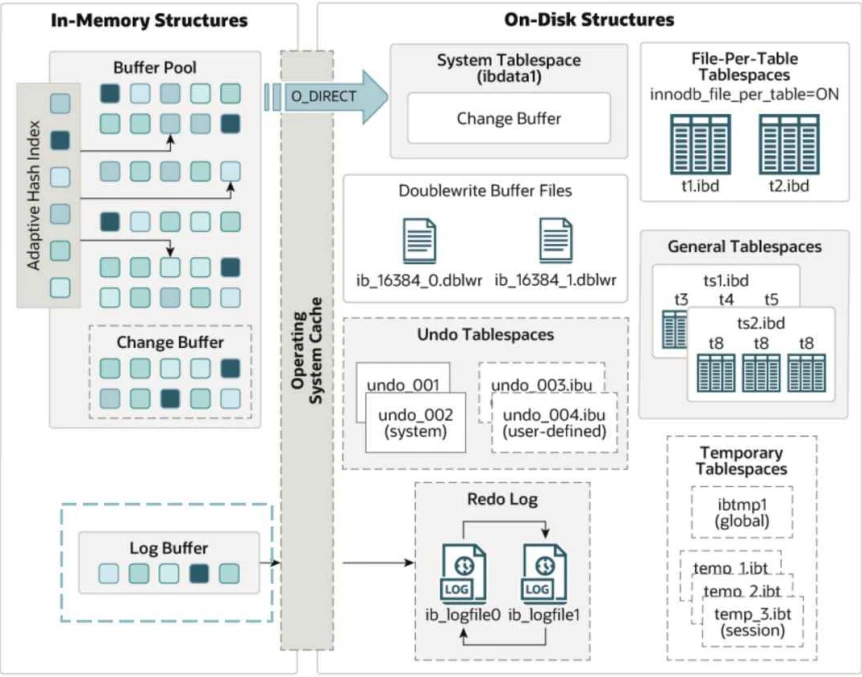
- ⽇志缓冲区在内存中的位置
6.1 ⽇志缓冲区的作⽤?
✅ 解答问题
-
⽇志缓冲区是服务器启动时向操作系统申请的⼀⽚连续的内存区域,存储即将要写⼊磁盘⽇志⽂件的数据。
-
在对数据库进⾏DML操作时,InnoDB会记录对应操作的⽇志,⽐如为保证数据完整性实现数据库崩溃恢复的Redo Log,这些⽇志会⾸先写⼊Log Buffer中,从⽽解决同步写磁盘导致的性能问题,然后根据不同落盘策略最终写⼊磁盘
6.2 ⽇志不通过Log Buffer直接写⼊磁盘不⾏吗?
- 如果⽇志不通过Log Buffer直接写⼊磁盘,那么每次进⾏DML操作都会进⾏⼀次磁盘I/O,这样会严重影响效率,所以把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,可以实现⼀次磁盘I/O写⼊多条⽇志,从⽽提升效率
小结
❤ ⼩结
-
InnoDB内存结构主要分为:
-
Buffer Pool 缓冲池、
-
Change Buffer 变更缓冲区
-
adaptive_hash_index ⾃适应哈希索引
-
Log Buffer ⽇志缓冲区
-
-
缓冲池
- 内存中的主要⼯作区域
- 缓冲池中包含⾄少⼀个 Instances ,每个 Instances 中包含⾄少⼀个Chunk , Chunk 管理着多个数据⻚
- 缓冲池中使⽤控制块与数据⻚建⽴对应关系,通过双向链表连接每个控制块,从⽽管理数据⻚
- 缓冲池中有三个链表分别是 Free List 、 LRU List 和 Flush List :
- Free List :只管理Free ⻚
- LRU List :管理 Clean⻚和Dirty⻚
- Flush List :只管理Dirty⻚
- 缓冲池淘汰策略采⽤变形的最近最少使⽤算法LRU
-
变更缓冲区
- ⽤来缓存对⼆级索引数据的修改,从⽽减少磁盘的IO次数以提升效率
-
⾃适应哈希索引
- 为频繁使⽤的查询条件和对应的数据⻚建⽴映射关系,从⽽提升内存级别的查询效率
-
⽇志缓冲区
- 把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,从⽽减少磁盘的IO次数以提升效率
个 Instances ,每个 Instances 中包含⾄少⼀个Chunk , Chunk 管理着多个数据⻚
-
缓冲池中使⽤控制块与数据⻚建⽴对应关系,通过双向链表连接每个控制块,从⽽管理数据⻚
-
缓冲池中有三个链表分别是 Free List 、 LRU List 和 Flush List :
- Free List :只管理Free ⻚
- LRU List :管理 Clean⻚和Dirty⻚
- Flush List :只管理Dirty⻚
-
缓冲池淘汰策略采⽤变形的最近最少使⽤算法LRU
-
变更缓冲区
- ⽤来缓存对⼆级索引数据的修改,从⽽减少磁盘的IO次数以提升效率
-
⾃适应哈希索引
- 为频繁使⽤的查询条件和对应的数据⻚建⽴映射关系,从⽽提升内存级别的查询效率
-
⽇志缓冲区
- 把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,从⽽减少磁盘的IO次数以提升效率
相关文章:
【mysql进阶】4-5. InnoDB 内存结构
InnoDB 内存结构 1 InnoDB存储引擎中内存结构的主要组成部分有哪些? 🔍 分析过程 从官⽹给出的InnoDB架构图中可以找到答案 InnoDB存储引擎架构链接:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html ✅ 解答问题 InnoD…...

从零入门扣子Bot开发
从零入门扣子Bot开发 工作流简单介绍问题思考工作流实例 图像流简单介绍瘦脸图像流的设计创建图像流设计流程 总结参考链接 工作流简单介绍 工作流起源于生产组织和办公自动化领域,是指在计算机应用环境下,对业务过程的部分或整体进行自动化处理。它通过…...

中药是怎么计价的 复制药方文本划价系统操作教程
一、概述 【软件资源文件下载可以点文章最后卡片】 通过复制药方文本,快速划价并计算出总金额。 可以保存记录,如日期,客户名称,药方名称,金额等,便于查询统计或导出表格。 中药划价系统怎么收费 中药是…...

怎么做网站?
现代网站建设涵盖了多个方面,远不仅仅是简单的网站制作。如果您有兴趣创建网站或者想了解如何建立一个成功的网站,那么您需要了解众多与之相关的关键要素。本文将为您详细介绍这些要素。 选域名:域名是您网站的标识,因此选择一个…...

Centos Stream 9部署Zabbix7.0LTS
目录 1. 系统环境1.1 编辑配置文件/etc/yum.repos.d/epel.repo1.2 安装Zabbix存储库1.3 安装Zabbix server,Web前端,agent 2. MySQL/MariaDB 数据库2.1安装和配置 MySQL/MariaDB 数据库2.2 创建初始数据库2.3 导入初始架构和数据,系统将提示您…...

深入理解Allan方差:用体重数据分析误差的时间尺度与稳定性
文章目录 1. 什么是Allan方差?Allan方差的特点 2. Allan方差与传统方差的区别3. 用体重数据举例分析波动性场景A:体重变化较平稳场景B:体重变化波动较大 4. Allan方差的计算公式与详细步骤5. 不同时间块长度下的Allan方差计算场景A的Allan方差…...

Elasticsearch 解析:倒排索引机制/字段类型/语法/常见问题
Elasticsearch 是一个分布式的开源搜索引擎,广泛用于全文搜索、分析和数据存储。它基于 Apache Lucene 构建,支持 RESTful 风格的 API,使得开发者能够高效地存储和检索数据。本文将详细讲解 Elasticsearch 的基本原理,特别是其倒排…...

数字后端零基础入门系列 | Innovus零基础LAB学习Day5
###Module 12 RC参数提取和时序分析 数字后端零基础入门系列 | Innovus零基础LAB学习Day4 数字后端零基础入门系列 | Innovus零基础LAB学习Day3 数字后端零基础入门系列 | Innovus零基础LAB学习Day2 数字后端零基础入门系列 | Innovus零基础LAB学习Day1 ###LAB12-1 这个章节…...

Redis 内存回收策略小结
Redis 内存回收策略 及时回收内存中不需要的数据,能有效地保持性能和防止内存溢出。Redis内存回收主要有两种场景 删除过期的键值对内存使用达到maxmemory时触发回收策略 删除过期的键值对 惰性删除: 在查询时如果发现 该键值对已经过期则执行删除操作…...

React常用前端框架合集
React 是 Facebook 开发的一款用于构建用户界面的 JavaScript 库。由于其高效、灵活的特性,React 成为了目前最流行的前端框架之一。为了帮助开发者更好地利用 React 构建应用,市场上涌现了许多优秀的辅助工具和框架。本文将详细介绍几个常用的 React 前…...

python对文件的读写操作
任务:读取文件夹下的批量txt数据,并将其写入到对应的word文档中。 txt文件中包含:编号、报告内容和表格数据。写入到word当中:编号、报告内容、表格数据、人格雷达图以及对应的详细说明(详细说明是根据表格中的标识那一列中的加号…...
)
Redis工具类(解决缓存穿透、缓存击穿)
文章目录 前言IBloomFilterObjectMapUtilsCacheClient使用示例具体业务的布隆过滤器控制层服务层 前言 该工具类包含以下功能: 1.将任意对象存储在 hash 类型的 key 中,并可以设置 TTL 2.将任意对象存储在 hash 类型的 key 中,并且可以设置…...

Air780E量产binpkg文件的获取方法
Air780E量产binpkg文件如何获取呢?操作方法如下。 一、背景 最近luatos开发客户增多,客户在量产烧录的时候需要binpkg文件,但是有些客户不知道binpkg文件是什么,在哪里获取,是否可以用soc文件提取出来,使…...

C++STL之stack
1.stack的使用 函数说明 接口说明 stack() 构造空的栈 empty() 检测 stack 是否为空 size() 返回 stack 中元素的个数 top() 返回栈顶元素的引用 push() 将元素 val 压入 stack 中 pop() 将 stack 中尾部的元素弹出 2.stack的模拟实现 #include<vector> namespace abc { …...

git的学习之远程进行操作
1.代码托管GitHub:充当中央服务器仓库的角色 2.git远程进行操作 3.配置本地服务器的公钥 4.推送 5.git远程操作 pull .gitignore 6.给命令配置别名 git config --global alias.st status 7.标签管理 git tag -a [name] -m "XXX" [commit_id] 操作标签…...

蓝桥杯普及题
[蓝桥杯 2024 省 B] 好数 题目描述 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位……)上的数字是奇数,偶数位(十位、千位、十万位……)上的数字是偶数,我们就称之为“好数”。 给定一个正整数 N N N,请计算从 1 1...

Spreadsheet导出excel
记录下常用的方法 数字转字符:Coordinate::stringFromColumnIndex(27); 输出 AA字符转数字:Coordinate::columnIndexFromString(AA); 输出27设置单元格式 eg:(设置为保留两位小数点) $sheet->getStyle($columnLetter)->getNumberFormat()->set…...

Leetcode|454.四数相加II ● 383. 赎金信 ● 15. 三数之和 ● 18. 四数之和
15.三数之和 哈希解法: 用俩个for循环求出,所需的a和b,再用哈希表,判断剩余的那个c是否在数组 class Solution { public:vector<vector<int>> threeSum(vector<int>& nums) {vector<vector<int>…...

使用ceph-csi把ceph-fs做为k8s的storageclass使用
背景 ceph三节点集群除了做为对象存储使用,计划使用cephfs替代掉k8s里面现有的nfs-storageclass。 思路 整体实现参考ceph官方的ceph csi实现,这套环境是arm架构的,即ceph和k8s都是在arm上实现。实测下来也兼容。 ceph-fs有两种两种挂载方…...
太速科技-212-RCP-601 CPCI刀片计算机
RCP-601 CPCI刀片计算机 一、产品简介 RCP-601是一款基于Intel i7双核四线程的高性能CPCI刀片式计算机,同时,将CPCI产品的欧卡结构及其可靠性、可维护性、可管理性与计算机的抗振动、抗冲击、抗宽温环境急剧变化等恶劣环境特性进行融合。产品特别…...

终端工作空间新选择:从 tmux 到 Zellij 的迁移与实战
1. 为什么需要从 tmux 迁移到 Zellij 作为一个用了五年 tmux 的老用户,我最初对 Zellij 这个"新玩具"是持怀疑态度的。直到有一次在远程服务器上调试时,tmux 的窗格突然卡死,所有工作进度瞬间归零,我才开始认真寻找替代…...
终极指南:从入门到实战的完整教程)
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr 面对复杂多变的空间数据,传统的地理加权回归(GWR)常…...

实测5款AI教材编写工具,低查重效果惊人,快速生成专业教材
许多教材编写者常常感到遗憾,他们费尽心思完善的正文内容,因为缺少配套资源而导致教学效果打折。设计课后练习题时,面对题型的多样化却缺乏创新的思路;制作可视化教学课件时,手头的技术能力又无法满足;深入…...
)
ubuntu linux虚拟机安装部署hermes详细教程(安装、问题处理)
文章目录 前言 一、Hermes 介绍 1. 什么是 Hermes Agent? 2. 核心特性 3. 为什么选择 Hermes Agent? 4. 适用场景 二、安装Hermes 1.安装 2.配置 3.开始对话 4.接入多平台(可选) 5.保持更新 三、Hermes接入微信 四、常见错误解决 1.Failed to connect to github.com port 4…...

开源AI应用构建平台Casibase:从架构设计到生产部署全解析
1. 项目概述:一个开源的AI应用构建平台最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:想法很多,但落地太难。从模型选型、API对接、到前端交互、数据管理,每一个环节都够喝一壶。特别是当你想把多个模型、多种…...

性价比高的AI应用厂家
核心结论: 当前市面上AI应用厂商众多,但真正能做到“高性价比”的,必须同时满足三个条件:功能覆盖企业核心痛点(管理、销售、运营)、落地效果可量化(降本增效有数据支撑)、成本可控&…...

小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 小微团队如何利用 Taotoken 统一管理多个 AI 模型密钥与用量 对于小型开发或产品团队而言,在项目开发中集成多个大语言…...

英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆
英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟…...

如何快速掌握音频频谱分析:Spek开源工具完整指南
如何快速掌握音频频谱分析:Spek开源工具完整指南 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 想要深入了解音频文件的内部结构吗?Spek音频频谱分析器是你的理想选择!这款免费…...

DeepSeek RAG pipeline重构实录,KISS检查挽救了87%的推理延迟——从2300ms到290ms的极简跃迁
更多请点击: https://intelliparadigm.com 第一章:DeepSeek RAG pipeline重构实录,KISS检查挽救了87%的推理延迟——从2300ms到290ms的极简跃迁 在一次线上 P99 延迟告警中,DeepSeek 的 RAG 服务平均响应时间飙升至 2300ms&#…...