python实战(二)——房屋价格回归建模
一、任务背景
本章将使用一个经典的Kaggle数据集——House Prices - Advanced Regression Techniques进行回归建模的讲解。这是一个房价数据集,与我们熟知的波士顿房价数据集类似,但是特征数量要更多,数据也要更为复杂一些。下面,我们将使用这个房价数据进行机器学习中的回归建模,依次分解机器学习建模的各个步骤并给出详细的注解。
二、机器学习建模
1、数据获取
为了展示一个完整的机器学习建模流程,我们把数据集下载到了本地并使用python进行读取:
df = pd.read_csv('./data/housePrices.csv')
print('数据量:', len(df))
print(df.head())结果如下,数据总量是1460条,可以看到最后一列SalePrice就是我们要预测的标签了,此外除Id列之外还有80个特征列。

2、探索性数据分析
通过常规的探索性分析,大概看一下这个数据集长什么样子,比如有多少行、有多少列、每一列中是否有空值、哪些列是数值类型的、哪些列是文本类型的,以及最重要的——我们要预测的标签是哪一列。
(1)查看空值
由于特征列较多,所以全都打出来比较难阅读,这里通过筛选的方式,仅打印有空值的特征列:
for col in list(df.columns):sum_na = df[col].isna().sum()if sum_na > 0:print("{:<20} {}".format(col, sum_na))结果如下,有空值的列数为19列,其中一些列含有较多的空值,比如最后三列。

(2)查看特征取值类型
我们可以通过筛选数据字段类型的方式分别统计出有多少是数值型特征,有多少是文本特征:
# 选择数值型的列
numeric_df = df.select_dtypes(include=['int64', 'float64'])
# 选择文本型的列
text_df = df.select_dtypes(include=['object']) # 注意:这里可能包括了混合类型的列
# 打印结果
print("数值型列:")
print('数量:{}, 列名:{}'.format(len(numeric_df.columns), numeric_df.columns.tolist()))
print("文本型列:")
print('数量:{}, 列名:{}'.format(len(text_df.columns), text_df.columns.tolist()))结果如下:

或者,还有个一步到位的方式:
print(df.info())结果如下,可以看到,使用.info()方法既可以打印出数据量,也能显示每一列非空值的数量以及字段类型等信息。


(3)查看标签分布
通过可视化的方式把标签分布可视化出来
plt.figure(figsize=(9, 8))
sns.histplot(df['SalePrice'], color='b', bins=100)
plt.show() 可以看到标签取值范围集中在100K到250K的区间内。
3、数据预处理
在进行了初步的数据探索之后,我们可以开始数据的预处理了。首先,部分特征列存在大量的空值,虽然可以取当前列有效数据的平均值或者中值进行填充 ,但是由于空值列比例太大,笔者在这里直接去掉这些列。对于数据为文本类型的列,我们进行一个简单的转换,确保每一列的数据都是数值类型,以方面后续的相关性计算以及建模。由于文本列也可能存在空值,这里统一编码为“missing”。
# 去掉空值数量超过600的列,不同数据集相应空值数量临界值的界定视具体情况调整
df = df.drop(['Alley', 'MasVnrType', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1)
# 对于文本数据列首先填充空值,再进行数值化转换
label_encoder = LabelEncoder()
for col in text_df.columns:if col not in df:continuedf[col].fillna('missing', inplace=True)# 转换成数值类型的标号df[col] = label_encoder.fit_transform(df[col])其次,对于包含少量空值的数值类型列,我们使用中值进行填充。
# 计算每一列的中值
median_values = df.median()
# 使用中值填充空值
df = df.fillna(value=median_values)4、特征工程
由于总共有将近80列的特征,实际上我们可能不需要这么多特征,所以我们进行一个简单的相关性分析(这里使用Pearson相关系数,衡量线性相关度,也可以使用斯皮尔曼系数等来衡量非线性相关度),只保留跟标签列较相关的特征(相关性大于0.5)。在本文中,笔者只进行特征工程中的“特征选择方法”的展示,至于特征构造等内容,视建模结果而定,若建模结果不佳,则可能需要人工构造新特征了。
correlation_matrix = df.corr(method='pearson')
# 计算所有特征列与标签列之间的相关系数
correlations = df.drop('SalePrice', axis=1).corrwith(df['SalePrice'])
# 筛选出相关度大于0.5的特征列,实际取多少根据数据规律确定,例如这个数据集超过0.8的有0列,自然无法指定高于0.8的取值
highly_correlated_features = correlations[abs(correlations) > 0.5].index.tolist()
print("特征列与标签列相关度大于0.5的特征:", highly_correlated_features)5、训练集/测试集划分
在进行建模之前划分好训练集的测试集,训练集用于模型训练,测试集测试模型的效果。
# 选定训练特征和标签
X = df[highly_correlated_features].values.tolist()
y = df['SalePrice'].tolist()
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2024)
print('训练集数据量:', len(X_train))
print('测试集数据量:', len(X_test))这里讲一下几个比较重要的参数:
- test_size:指定训练集和测试集划分过程中的比例,0-1开区间之间的小数。
- random_state:指定随机数,以保证结果可复现。
6、模型训练
这里我们使用一个GBDT回归器作为当前任务的模型。我们使用R2作为评价模型的指标,R2显示了一个回归模型的可解释方差占总方差的比例,R2得分越接近1代表模型效果越好。此外,MSE和MAE是两个常见的指标,不赘述了。
gbr = GradientBoostingRegressor(loss="squared_error", n_estimators=100, criterion="friedman_mse", random_state=2024)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
# 评估模型表现
print('r2:', r2_score(y_test, y_pred))
print('mae:', mean_absolute_error(y_test, y_pred))
print('mse:', mean_squared_error(y_test, y_pred))
print('rmse:', mean_squared_error(y_test, y_pred)**0.5)这里同样有几个需要注意的参数:
- n_estimators:指定要构建的决策树的数量,默认值是100。更多的树可以提高模型的复杂度和拟合能力,但也会增加过拟合的风险及计算量。
- max_depth:指定每个决策树的最大深度,树的深度太浅会欠拟合,树的深度太深则会过拟合,需要凭经验调整,默认值是3。
- loss:指定优化目标函数,可选squared_error(默认)、absolute_error、huber、quantile。squared _ error是回归的平方误差;absolute_error是回归的绝对误差;huber是两者的结合;quantile允许使用分位数回归(使用alpha指定分位数)。
- criterion:指定衡量分裂质量的准则,可以选friedman_mse或mse。默认是friedman_mse,在某些情况下它可以得到更好的近似值。
- random_state:随机数种子,用于控制树的抽样和特征选择的随机性,默认是None,即不指定。
指标结果如下,由于我们并没有对标签进行归一化,所以MAE和MSE数值会非常大,但这是正常的,毕竟我们的标签房价基本都是10万元以上的:

可视化模型预测结果和真实值的差异,可以见到预测效果还不错(这里我们的数据并不是时序性的,但是为了观察预测值和真实值的拟合情况,可以把数据看作是时序的并使用曲线进行可视化, 这时候的X轴是标签对应的序号,Y轴是房价):
plt.plot(y_test, label='real')
plt.plot(y_pred, label='pred')
plt.legend()
plt.show()三、完整代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_errordf = pd.read_csv('./data/housePrices.csv')
print('数据量:', len(df))
print(df.head())# 查看包含空值的列
for col in list(df.columns):sum_na = df[col].isna().sum()if sum_na > 0:print("{:<20} {}".format(col, sum_na))# 选择数值型的列
numeric_df = df.select_dtypes(include=['int64', 'float64'])
# 选择文本型的列
text_df = df.select_dtypes(include=['object']) # 注意:这里可能包括了混合类型的列
# 打印结果
print("数值型列:")
print('数量:{}, 列名:{}'.format(len(numeric_df.columns), numeric_df.columns.tolist()))
print("文本型列:")
print('数量:{}, 列名:{}'.format(len(text_df.columns), text_df.columns.tolist()))
print(df.info())# 可视化标签分布
print(df['SalePrice'].describe())
plt.figure(figsize=(9, 8))
sns.histplot(df['SalePrice'], color='b', bins=100)
plt.show()# 去掉空值数量超过600的列,不同数据集相应空值数量临界值的界定视具体情况调整
df = df.drop(['Alley', 'MasVnrType', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1)
# 对于文本数据列首先填充空值,再进行数值化转换
label_encoder = LabelEncoder()
for col in text_df.columns:if col not in df:continuedf[col].fillna('missing', inplace=True)# 转换成数值类型的标号df[col] = label_encoder.fit_transform(df[col])# 计算每一列的中值
median_values = df.median()
# 使用中值填充空值
df = df.fillna(value=median_values)correlation_matrix = df.corr(method='pearson')
# 计算所有特征列与标签列之间的相关系数
correlations = df.drop('SalePrice', axis=1).corrwith(df['SalePrice'])
# 筛选出相关度大于0.5的特征列,实际取多少根据数据规律确定,例如这个数据集超过0.8的有0列,自然无法指定高于0.8的取值
highly_correlated_features = correlations[abs(correlations) > 0.5].index.tolist()
print("特征列与标签列相关度大于0.5的特征:", highly_correlated_features)# 选定训练特征和标签
X = df[highly_correlated_features].values.tolist()
y = df['SalePrice'].tolist()
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2024)
print('训练集数据量:', len(X_train))
print('测试集数据量:', len(X_test))gbr = GradientBoostingRegressor(loss="squared_error", n_estimators=100, criterion="friedman_mse", random_state=2024)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
# 评估模型表现
print('r2:', r2_score(y_test, y_pred))
print('mae:', mean_absolute_error(y_test, y_pred))
print('mse:', mean_squared_error(y_test, y_pred))# 预测效果可视化
plt.plot(y_test, label='real')
plt.plot(y_pred, label='pred')
plt.legend()
plt.show()四、总结
本文使用了开源数据集进行回归建模实践,遵循机器学习建模的几大流程注意展开讲解。分类和回归是机器学习的两大主要任务,也是业务过程中最常见的任务类型,因此有必要深入了解其中的建模流程及细节。
相关文章:

python实战(二)——房屋价格回归建模
一、任务背景 本章将使用一个经典的Kaggle数据集——House Prices - Advanced Regression Techniques进行回归建模的讲解。这是一个房价数据集,与我们熟知的波士顿房价数据集类似,但是特征数量要更多,数据也要更为复杂一些。下面,…...

UHF机械高频头的知识和待学习的疑问
电路图如上所示: 实物开盖清晰图如下: 待学习和弄懂的知识: 这是一个四腔的短路线谐振。分别是输入调谐,放大调谐,变频调谐和本振 第一个原理图输入为75欧(应该是面向有同轴线的天线了)如下图…...

深入理解 SQL 中的 WITH AS 语法
在日常数据库操作中,SQL 语句的复杂性往往会影响到查询的可读性和维护性。为了解决这个问题,Oracle 提供了 WITH AS 语法,这一功能可以极大地简化复杂查询,提升代码的清晰度。本文将详细介绍 WITH AS 的基本用法、优势以及一些实际…...

同三维T80005JEHA-4K60 4K60超高清HDMI/AV解码器
1路HDMI1路CVBS1路3.5音频输出,HDMI支持4K60,支持1路4K60解码,1路高清转码 产品简介: T80005JEHA-4K60是一款4K60超高清解码器,支持1路HDMI/CVBS解码输出,HDMI支持4K60,适用于各种音视频解决方…...

深信服秋季新品重磅发布:安全GPT4.0数据安全大模型与分布式存储EDS新版本520,助力数字化更简单、更安全
10月23日,深信服举办2024秋季新品发布会。发布会上,深信服正式推出了最新的创新成果:实现动静态数据分类分级和数据风险自动研判分析的安全GPT4.0、具备卓越可靠性和AI勒索防护能力的分布式存储EDS新版本520。通过这些新品和能力,…...

Flutter图片控件(七)
1、加载图片 import package:flutter/material.dart;void main() {runApp(const MaterialApp(home: MyHomePage(),)); }class MyHomePage extends StatelessWidget {const MyHomePage({super.key});overrideWidget build(BuildContext context) {return Scaffold(appBar: AppB…...
JavaEE初阶---文件IO总结
文章目录 1.文件初识2.java针对于文件的操作2.1文件系统的操作---file类2.2文件内容的操作---流对象的分类2.4字符流的操作》文本文件2.4.1异常的说明2.4.2第一种文件内容的读取方式2.4.3第二种读取方式2.4.4close的方法的介绍2.4.5close的使用优化操作2.4.6内容的写入 2.3字节…...

10.28Python_pandas_csv
三、读取CSV文件 CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本); CSV 是一…...

数据处理与可视化:pandas 和 matplotlib 初体验(9/10)
数据处理与可视化:pandas 和 matplotlib 初体验(9/10) 介绍 在如今的数据驱动时代,掌握数据处理与可视化是每个开发者和数据科学家不可或缺的技能。Python 拥有强大的数据处理库 pandas 和数据可视化库 matplotlib,它…...

鸿蒙学习总结
鸿蒙(HarmonyOS),做为国产自主研发设计的第一个操作系统,从开放测试以来一直备受关注。其纯血鸿蒙版(HarmonyOS NEXT)也于进日发布。过去的一段时间里,我站在一个移动开发者的角度对HarmonyOS进…...
如何修改文件创建时间?六个超简单修改方法介绍
怎么修改文件创建时间?在信息安全与隐私保护的领域里,每一个细节都可能成为泄露敏感信息的突破口。文件的创建时间,这个看似微不足道的数据点,实则可能蕴含着重要的时间线索,对于不希望被外界窥探其内容或来源的个人及…...

【MySQL 保姆级教学】内置函数(9)
内置函数 1. 日期函数1.1 日期函数的种类1.2 示例1.3 日期的转换 2. 字符串函数2.1 种类2.2 示例 3. 数学函数3.1 种类3.2 向上取整和向下取整3.3 示例 4. 其他函数4.1 查询当前用户/数据库4.2 ifnull(val1,val2)4.3 md5()函数4.4 password()函数 1. 日期函数 1.1 日期函数的种…...
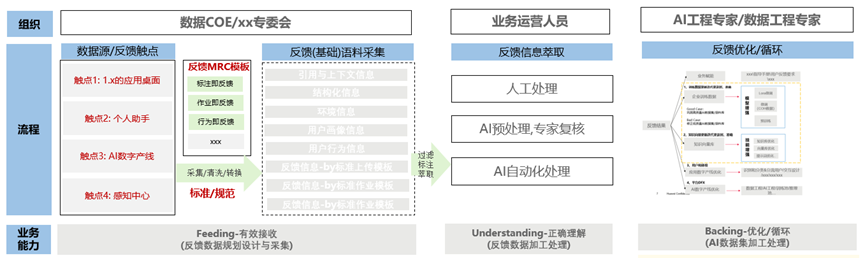
华为大咖说丨如何通过反馈机制来不断优化大模型应用?
本文分享自时习知 作者:袁泉(华为AI数据工程专家)全文约3015字,阅读约需8分钟 大模型应用正式投入使用后,存在一个较为普遍的情况:在利用“大模型提升业务运营效率”的过程中,业务部门和IT团队…...

上海亚商投顾:沪指缩量震荡 风电、传媒股集体走强
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 市场全天缩量震荡,三大指数集体收涨,北证50则跌超7%,超80只北交所个股跌逾…...
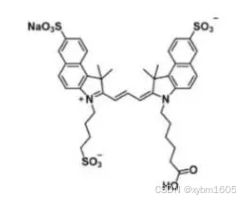
三磺酸-Cy3.5-羧酸在水相环境中表现良好,能够提高成像的清晰度和准确性
一、基本信息 中文名称:三磺酸-Cy3.5-羧酸,水溶性Cy3.5 羧基 英文名称:trisulfo-Cy3.5-carboxylic acid,trisulfo-Cy3.5-COOH,trisulfo-Cyanine3.5-COOH 分子式:C41H44N2NaO11S3- 分子量:85…...

国标GB28181视频平台EasyGBS国标GB28181软件实现无需插件的视频监控对讲和网页直播
在当今社会,视频监控已经成为公共安全、企业管理、智能城市建设等领域不可或缺的一部分。然而,由于不同厂家和平台之间的兼容性问题,视频监控系统的联网和整合面临巨大挑战。为了解决这个问题,国家制定了《公共安全视频监控联网系…...

mac nwjs程序签名公证(其他mac程序也一样适用)
为什么需要公证 mac os14.5之后的系统,如果不对应用进行公证,安装,打开,权限使用上都会存在问题,而且有些问题你强制开启(sudo spctl --master-disable)使用后可能会有另外的问题, …...

网络应用技术 实验一:路由器实现不同网络间通信(华为ensp)
目录 一、实验简介 二、实验目的 三、实验需求 四、实验拓扑 五、实验任务及要求 1、任务 1:完成网络部署 2、任务 2:设计全网IP 地址 3、任务 3:实现全网主机互通 六、实验步骤 1、在ensp中部署网络 2、配置各主机 IP地址、子网掩…...

使用 Qt GRPC 构建高效的 Trojan-Go 客户端:详细指南
使用 Qt GRPC 构建高效的 Trojan-Go 客户端:详细指南 初识 Qt 和 gRPC 什么是 Qt?什么是 gRPC? 项目结构概述创建 proto 文件定义 API 下载 api.proto 文件解析 proto 文件 1. package 与 option 语句2. 消息类型定义 TrafficSpeedUserUserSt…...
【mysql进阶】5-事务和锁
mysql 事务基础 1 什么是事务 事务是把⼀组SQL语句打包成为⼀个整体,在这组SQL的执⾏过程中,要么全部成功,要么全部失败,这组SQL语句可以是⼀条也可以是多条。再来看⼀下转账的例⼦,如图: 在这个例⼦中&a…...

AI编程助手实战指南:从GitHub Copilot到全流程开发效率提升
1. 项目概述:当AI遇见编码的“氛围感”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫Sunil6512/awesome-ai-vibe-coding。光看名字,awesome-ai-vibe-coding,就透着一股子新潮味儿。它不是一个具体的工具或者框架&am…...
)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析) 在通信系统设计中,下行同步是终端接入网络的第一步关键操作。5G新空口(NR)技术引入了更复杂的同步信号结构,这对算法工程师和研究人员提出了更高要…...

别再到处找DEM了!手把手教你用ArcGIS Pro + Python脚本,从NASA官网免费下载并拼接出完整的中国90米高程数据
从NASA获取中国90米高程数据的自动化解决方案 在GIS和遥感研究领域,获取高质量的数字高程模型(DEM)数据是许多项目的基础工作。然而,对于中国区域的完整覆盖、高精度且免费可用的DEM数据,研究者们常常面临获取困难。本文将介绍如何利用ArcGI…...

服务器运维与DevOps融合:迈向智能化运维的新纪元
在数字化浪潮席卷全球的今天,企业对IT基础设施的依赖程度日益加深,服务器运维作为支撑业务连续性和系统稳定性的核心环节,正面临前所未有的挑战与机遇。传统运维模式依赖人工干预、响应滞后、效率低下,已难以满足现代业务快速迭代…...

测水位·报雨情·预洪水:水文监测站
水文监测站采用先进平面阵列雷达微波探测技术,设备悬空架设、非接触式采集河道水体数据。通过高精度雷达天线持续发射微波信号,穿透空气介质触达水面后反射回波,系统精准测算信号传播时长与多普勒频移变化,结合设备自带角度校准功…...

QMCDecode:打破音乐枷锁,让QQ音乐文件在你的设备上自由呼吸
QMCDecode:打破音乐枷锁,让QQ音乐文件在你的设备上自由呼吸 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

截稿!NeurIPS 2026 投稿微信群成立
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信:CVer2233,助手会拉你进群!扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上…...

TTS-Backup:Tabletop Simulator数据备份与资源管理的技术解决方案
TTS-Backup:Tabletop Simulator数据备份与资源管理的技术解决方案 【免费下载链接】tts-backup Backup Tabletop Simulator saves and assets into comprehensive Zip files. 项目地址: https://gitcode.com/gh_mirrors/tt/tts-backup 在数字桌游时代&#x…...

JScope RTT模式实战:在GD32F303上实现1MB/s高速数据流录制与性能分析
JScope RTT模式实战:在GD32F303上实现1MB/s高速数据流录制与性能分析 在嵌入式系统开发中,实时数据采集与分析往往是调试过程中最具挑战性的环节之一。当工程师需要捕捉高速瞬态信号、分析多变量交互行为或进行故障诊断时,传统调试工具常常显…...

轻量级规则流引擎实践:基于DAG的业务流程编排与解耦
1. 项目概述与核心价值 最近在梳理一些遗留系统的业务流程时,我又一次被那些硬编码在代码里的“if-else”逻辑链折磨得够呛。一个简单的审批流,因为业务规则的细微调整,就需要在多个服务里翻找、修改、测试,牵一发而动全身。这让我…...