基于卷积神经网络的大豆种子缺陷识别系统,resnet50,mobilenet模型【pytorch框架+python源码】
更多目标检测和图像分类识别项目可看我主页其他文章
功能演示:
大豆种子缺陷识别系统,卷积神经网络,resnet50,mobilenet【pytorch框架,python源码】_哔哩哔哩_bilibili
(一)简介
基于卷积神经网络的大豆种子缺陷识别系统是在pytorch框架下实现的,这是一个完整的项目,包括代码,数据集,训练好的模型权重,模型训练记录,ui界面和各种模型指标图表等。
该项目有两个可选模型:resnet50和mobilenet,两个模型都在项目中;GUI界面由pyqt5设计和实现。此项目的两个模型可做对比分析,增加工作量。
该项目是在pycharm和anaconda搭建的虚拟环境执行,pycharm和anaconda安装和配置可观看教程:
超详细的pycharm+anaconda搭建python虚拟环境_pycharm虚拟环境搭建-CSDN博客
(二)项目介绍
1. 项目结构

该项目可以使用已经训练好的模型权重,也可以自己重新训练,自己训练也比较简单
以训练resnet50模型为例:
第一步:修改model_resnet50.py的数据集路径,模型名称、模型训练的轮数

第二步:模型训练和验证,即直接运行model_resnet50.py文件
第三步:使用模型,即运行gui_chinese.py文件即可通过GUI界面来展示模型效果
2. 数据结构

部分数据展示:

3.GUI界面(技术栈:pyqt5+python+opencv)
1)gui初始界面

2)gui分类、识别界面



4.模型训练和验证的一些指标及效果
1)模型训练和验证的准确率曲线,损失曲线

2)热力图

3)准确率、精确率、召回率、F1值

4)模型训练和验证记录

(三)代码
由于篇幅有限,只展示核心代码
def main(self, epochs):# 记录训练过程log_file_name = './results/resnet50训练和验证过程.txt'# 记录正常的 print 信息sys.stdout = Logger(log_file_name)print("using {} device.".format(self.device))# 开始训练,记录开始时间begin_time = time()# 加载数据train_loader, validate_loader, class_names, train_num, val_num = self.data_load()print("class_names: ", class_names)train_steps = len(train_loader)val_steps = len(validate_loader)# 加载模型model = self.model_load() # 创建模型# 修改全连接层的输出维度in_channel = model.fc.in_featuresmodel.fc = nn.Linear(in_channel, len(class_names))# 模型结构可视化x = torch.randn(16, 3, 224, 224) # 随机生成一个输入# 模型结构保存路径model_visual_path = 'results/resnet50_visual.onnx'# 将 pytorch 模型以 onnx 格式导出并保存torch.onnx.export(model, x, model_visual_path) # netron.start(model_visual_path) # 浏览器会自动打开网络结构# 将模型放入GPU中model.to(self.device)# 定义损失函数loss_function = nn.CrossEntropyLoss()# 定义优化器params = [p for p in model.parameters() if p.requires_grad]optimizer = optim.Adam(params=params, lr=0.0001)train_loss_history, train_acc_history = [], []test_loss_history, test_acc_history = [], []best_acc = 0.0for epoch in range(0, epochs):# 下面是模型训练model.train()running_loss = 0.0train_acc = 0.0train_bar = tqdm(train_loader, file=sys.stdout)# 进来一个batch的数据,计算一次梯度,更新一次网络for step, data in enumerate(train_bar):# 获取图像及对应的真实标签images, labels = data# 清空过往梯度optimizer.zero_grad()# 得到预测的标签outputs = model(images.to(self.device))# 计算损失train_loss = loss_function(outputs, labels.to(self.device))# 反向传播,计算当前梯度train_loss.backward()# 根据梯度更新网络参数optimizer.step() # 累加损失running_loss += train_loss.item()# 每行最大值的索引predict_y = torch.max(outputs, dim=1)[1] # torch.eq()进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回Falsetrain_acc += torch.eq(predict_y, labels.to(self.device)).sum().item()# 更新进度条train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,train_loss)# 下面是模型验证# 不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化model.eval()# accumulate accurate number / epochval_acc = 0.0 testing_loss = 0.0# 张量的计算过程中无需计算梯度with torch.no_grad(): val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:# 获取图像及对应的真实标签val_images, val_labels = val_data# 得到预测的标签outputs = model(val_images.to(self.device))# 计算损失val_loss = loss_function(outputs, val_labels.to(self.device)) testing_loss += val_loss.item()# 每行最大值的索引predict_y = torch.max(outputs, dim=1)[1] # torch.eq()进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回Falseval_acc += torch.eq(predict_y, val_labels.to(self.device)).sum().item()train_loss = running_loss / train_stepstrain_accurate = train_acc / train_numtest_loss = testing_loss / val_stepsval_accurate = val_acc / val_numtrain_loss_history.append(train_loss)train_acc_history.append(train_accurate)test_loss_history.append(test_loss)test_acc_history.append(val_accurate)print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, train_loss, val_accurate))# 保存最佳模型if val_accurate > best_acc:best_acc = val_accuratetorch.save(model.state_dict(), self.model_name)# 记录结束时间end_time = time()run_time = end_time - begin_timeprint('该循环程序运行时间:', run_time, "s")# 绘制模型训练过程图self.show_loss_acc(train_loss_history, train_acc_history,test_loss_history, test_acc_history)# 画热力图test_real_labels, test_pre_labels = self.heatmaps(model, validate_loader, class_names)# 计算混淆矩阵self.calculate_confusion_matrix(test_real_labels, test_pre_labels, class_names)(四)总结
以上即为整个项目的介绍,整个项目主要包括以下内容:完整的程序代码文件、训练好的模型、数据集、UI界面和各种模型指标图表等。
项目运行过程如出现问题,请及时交流!
相关文章:
基于卷积神经网络的大豆种子缺陷识别系统,resnet50,mobilenet模型【pytorch框架+python源码】
更多目标检测和图像分类识别项目可看我主页其他文章 功能演示: 大豆种子缺陷识别系统,卷积神经网络,resnet50,mobilenet【pytorch框架,python源码】_哔哩哔哩_bilibili (一)简介 基于卷积神…...

HarmonyOS项目开发一多简介
目录 一、布局能力概述 二、自适应布局 三、响应式布局 四、典型布局场景 一、布局能力概述 布局决定页面元素排布及显示:在页面设计及开发中,布局能力至关重要,主要通过组件结构来确定使用何种布局。 自适应布局与响应式布局࿱…...

C++基础三
构造函数 构造函数(初始化类成员变量): 1、属于类的成员函数之一 2、构造函数没有返回类型 3、构造函数的函数名必须与类名相同 4、构造函数不允许手动调用(不能通过类对象调用) 5、构造函数在类对象创建时会被自动调用 6、如果没有显示声…...

利用ChatGPT完成2024年MathorCup大数据挑战赛-赛道A初赛:台风预测与分析
利用ChatGPT完成2024年MathorCup大数据挑战赛-赛道A初赛:台风预测与分析 引言 在2024年MathorCup大数据挑战赛中,赛道A聚焦于气象数据分析,特别是台风的生成、路径预测、和降水风速特性等内容。本次比赛的任务主要是建立一个分类评价模型&…...

Linux系统操作篇 one -文件指令及文件知识铺垫
Linux操作系统入门-系统篇 前言 Linux操作系统与Windows和MacOS这些系统不同,Linux是黑屏的操作系统,操作方式使用的是指令和代码行来进行,因此相对于Windows和MacOS这些带有图形化界面的系统,Linux的入门门槛和上手程度要更高&…...

隨筆20241028 ISR 的收缩与扩展及其机制解析
在 Kafka 中,ISR(In-Sync Replicas) 是一组副本,它们与 Leader 保持同步,确保数据一致性。然而,ISR 的大小会因多种因素而变化,包括收缩和扩展。以下是 ISR 收缩与扩展的详细解释及其背后的机制…...

linux-字符串相关命令
1、cut 提取文件每一行中的内容 下面是一些常用的 cut 命令选项的说明: -c, --characters列表:提取指定字符位置的数据。-d, --delimiter分界符:指定字段的分隔符,默认为制表符。-f, --fieldsLIST:提取指定字段的数据…...

ES6 函数的扩展
ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法 ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面 参数变量是默认声明的,所以不能用 let 或 const 再次声明 使用参数默认值时,函数不能有同名参…...

Mac 查看占用特定端口、终止占用端口的进程
在 macOS 上,可以使用以下命令来查看占用特定端口(例如 8080)的进程: lsof -i :8080命令说明 lsof:列出打开的文件和网络连接信息。-i :8080:筛选出正在监听 8080 端口的进程。 输出结果结构 执行上述命…...
C#入坑JAVA MyBatis入门 CURD 批量 联表分页查询
本文,分享 MyBatis 各种常用操作,不限于链表查询、分页查询等等。 1. 分页查询 在 下文的 的「3.4 selectPage」小节,我们使用 MyBatis Plus 实现了分页查询。除了这种方式,我们也可以使用 XML 实现分页查询。 这里,…...

RabbitMQ 安装(Windows版本)和使用
安装 安装包获取 可以自己找资源,我这里也有百度云的资源,如果没失效的话可以直接用。 通过百度网盘分享的文件:RabbitMQ 链接:https://pan.baidu.com/s/1rzcdeTIYQ4BqzHLDSwCgyw?pwdfj79 提取码:fj79 安装教程…...

Apache paimon表管理
表管理 2.9.4.1 管理快照 1)快照过期 Paimon Writer每次提交都会生成一个或两个快照。每个快照可能会添加一些新的数据文件或将一些旧的数据文件标记为已删除。然而,标记的数据文件并没有真正被删除,因为Paimon还支持时间旅行到更早的快照。它们仅在快照过期时被删除。 …...

java 第19天
一.Lambda表达式 前提是:参数是函数式接口才可以书写Lambda表达式 函数式接口条件: 1.接口 2.只有一个抽象方法 lambda表达式又称为匿名函数,允许匿名函数以参数的形式传入方法,简化代码 lambda表达式分为两部分()->{} …...

什么是服务器?服务器与客户端的关系?本地方访问不了网址与服务器访问不了是什么意思?有何区别
服务器是一种高性能的计算机,它通过网络为其他计算机(称为客户端)提供服务。这些服务可以包括文件存储、打印服务、数据库服务或运行应用程序等。服务器通常具有强大的处理器、大量的内存和大容量的存储空间,以便能够处理多个客户…...

Spring(1)—Spring 框架:Java 开发者的春天
一、关于Spring 1.1 简介 Spring 框架是一个功能强大的开源框架,主要用于简化 Java 企业级应用的开发,由被称为“Spring 之父”的 Rod Johnson 于 2002 年提出并创立,并由Pivotal团队维护。它提供了全面的基础设施支持,使开发者…...

MT1401-MT1410 码题集 (c 语言详解)
目录 MT1401归并排序 MT1402堆排序 MT1403后3位排序 MT1404小大大小排序 MT1405小大大小排序II MT1406数字重排 MT1407插入 MT1408插入 MT1409旋转数组 MT1410逆时针旋转数组 MT1401归并排序 c 语言实现代码 #include <stdio.h>// merge two subarrays void merge(int a…...
React基础语法
1.React介绍 React由Meta公司开发,是一个用于构建Web和原生交互界面的库 1.1 React优势 相较于传统基于DOM开发的优势 1.组件化的开发方式 2.不错的性能 相较于其他前端框架的优势 1.丰富的生态 2.跨平台支持 1.2React的时长情况 全球最流行,大厂…...

《Kadane‘s Algorithm专题:最大和连续子数组》
🚀 博主介绍:大家好,我是无休居士!一枚任职于一线Top3互联网大厂的Java开发工程师! 🚀 🌟 在这里,你将找到通往Java技术大门的钥匙。作为一个爱敲代码技术人,我不仅热衷…...
)
Vue基础(5)
ref属性 在 Vue2 中,ref是一个特殊的属性,用于在模板中获取对某个 DOM 元素或子组件的引用。通过 ref,我们可以在 JavaScript 代码中直接访问该 DOM 元素或组件实例。 示例: <template><div><input ref"inputField&quo…...
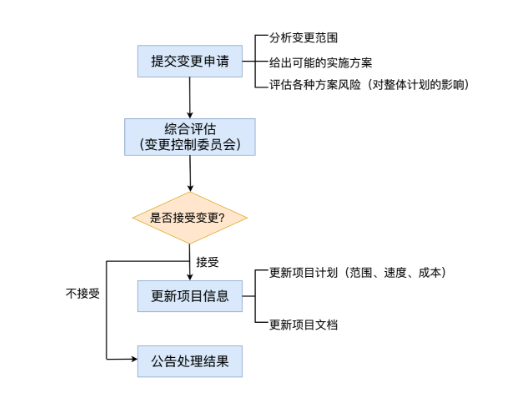
面对复杂的软件需求:5大关键策略!
面对软件需求来源和场景的复杂性,有效地管理和处理需求资料是确保项目成功的关键,能够提高需求理解的准确性,增强团队协作和沟通,降低项目风险,提高开发效率。反之,项目可能面临需求理解不准确、团队沟通不…...
)
面试记录 (2026/5/12)
问题一:java并发包下的AQS,了解多少? 这个真是没看过源码,就不班门弄斧了 直接学习下 大佬的经验 https://blog.csdn.net/qq_45772447/article/details/149126295?fromshareblogdetail&sharetypeblogdetail&sharerId149126295&…...

Vinkius Cloud扩展:在IDE中无缝管理MCP AI网关运行时
1. 项目概述:在IDE中管理你的AI网关运行时如果你正在开发或使用基于MCP(Model Context Protocol)的AI应用,那么你很可能已经体会过在多个AI客户端(比如Cursor、Claude Desktop、Windsurf)之间管理和维护后端…...

疫情如何重塑GPU市场:从游戏硬件到数字基础设施的演变
1. 市场预期的“扭曲”:疫情如何重塑GPU行业逻辑如果你在2020年初问任何一位半导体行业的分析师,他们对当年第二季度GPU(图形处理器)市场的预测,大概率会得到一个基于历史季节性规律的保守或平稳的答案。然而ÿ…...

Day3:拆箱ROS2|一起搭建机器人开发车间
Day1:一起学习了ros2是什么以及ros2为机器人开发提供了哪些核心功能. Day2一起安装了ros2。 接下来自然会想到如果现在要用ROS2开发一个机器人,应该怎样开始? 下面我们以雷达小车机器人举例说明: 1、需要为机器人创建一个【工作空间】作为顶层…...

从高通市值超越英特尔看半导体IP价值与Fabless模式
1. 从一则旧闻谈起:当高通市值超越英特尔2012年11月9日,对于全球半导体行业而言,是一个值得被记住的日子。那天,一则消息在业界引发了不小的震动:高通(Qualcomm)的市值首次超越了英特尔…...

常见404 500错误解析
一、常见404 500错误解析浏览器:用户发起请求的入口,地址栏输入 URL、AJAX 请求都从这里发。服务器:本质就是一台电脑,Tomcat 在这里负责接收请求、分发处理。前端层:存放静态页面,处理页面渲染、用户交互…...
)
Docker Compose 镜像检测脚本(支持自动扫描 + 手动输入 YAML)
在日常运维中,经常会遇到这样一个问题: docker-compose 文件里定义了很多镜像,但本地是否已经存在不清楚 如果一个个 docker pull 或 docker images 去对比,会非常低效。 因此我们可以写一个脚本,自动解析 docker-com…...

芯片晶圆平面度如何测量?半导体制造中的光学形貌检测方案
晶圆作为集成电路的核心承载基片,表面形貌的精度直接关系到光刻聚焦质量、芯片电学性能及最终良率。从8英寸到12英寸的大尺寸晶圆制造中,平面度、翘曲度(Warp)、总厚度变化(TTV)及局部平面度(SF…...

用PLC控制Labview自动运行
博图软件设置注意数据位正确下图为Labview读取CSV文件的位置测试数据如下图所示实现方法:在1分支内创建好条件,当PLC心跳为True那么就去跑True里面的流程(CSM框架)...

基于Helm与Kubernetes的以太坊节点自动化部署与运维实战
1. 项目概述:当以太坊遇见Kubernetes如果你和我一样,在区块链基础设施领域摸爬滚打多年,从早期手动编译客户端、配置systemd服务,到后来用Docker Compose编排节点,每一步都伴随着大量的重复劳动和运维痛点。当节点数量…...