卡方检验方法概述与类型——四格表和R*C表卡方检验案例
卡方检验是以卡方分布为基础,针对定类数据资料的常用假设检验方法。其理论思想是判断实际观测到的频数与有关总体的理论频数是否一致。
卡方统计量是实际频数与理论频数吻合程度的指标。卡方值越小,表明实际观察频数与理论频数越接近,反之卡方值越大则表示两者相差越大。卡方检验原假设实际频数与理论频数相同,依据卡方分布计算显著性p值进行统计结论的推断。取显著性水平α=0.05,当p值小于0.05时说明观察频数与理论频数差异有统计学意义,反之若p值大于0.05则说明观察频数与理论频数无差异。
一、方法概述
1. 应用方向
实际研究分析中,卡方检验有独立性/差异性检验和卡方拟合优度检验这两个重要的应用方向。
(1) 独立性/差异性检验
独立性检验可理解为判断两组或多组计数资料是相互关联还是彼此独立,如是否患病与是否吸烟的关联关系。根据研究侧重点的不同,也可用于两组或多组样本的总体率(或构成比)之间的差别是否具有统计学意义,如某疾病联合化疗和单纯化疗两种治疗方式的存活率有无差异,吸烟与不吸烟两组人群患病率有无差异。
(2) 拟合优度检验
检验实际观察的类别频数分布比例与已知类别频数分布比例是否符合的分析方法,通俗讲即检验验总体是否服从某个指定分布。比如在研究牛的相对性状分离现象时,用黑色无角牛和红色有角牛杂交,子二代出现黑色无角牛192头,黑色有角牛78头,红色无角牛72头,红色有角牛18头。这两对性状是否符合孟德尔遗传规律中9:3:3:1的遗传比例。
2. 数据要求
用于卡方检验的数据录入格式有两种。第一种是列联表频数资料,即加权数据格式,在分析时需要提前用频数进行加权。第二种是原始数据记录,即普通数据格式,在分析时软件工具会自动汇总频数结果。
实践中,列联表频数数据较为常见。列联表也叫交叉表,是两个分类变量各水平两两交叉组合后的频数汇总表。
如果两个分类变量均为2水平,那么二者构成2×2交叉表,交叉组合频数所在的位置也叫做单元格,因此2×2交叉表共有4个单元格,也就是常说的四格表。除四格表之外的列联表,我们可以统称为R×C列联表,其中R代表行个数,C代表列个数。
3. 卡方检验的类型
按列联表的形式,卡方检验可以简单划分为2×2四格表卡方检验、R×C列联表卡方检验;按研究设计不同,包括成组设计的独立性卡方检验和配对卡方检验;按研究目的,可以分为卡方拟合优度检验及独立性卡方检验。此外根据是否有分层变量,还包括分层卡方检验。各种类型卡方检验的应用目的、方法选择见表 4-23。
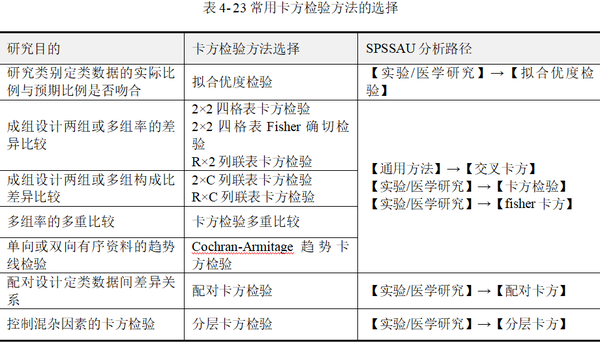
一般说卡方检验时,默认计算的是Pearson卡方统计量,而实际分析时,在2×2四格表卡方检验、R×C列联表卡方检验中通常会计算多个卡方统计量,包括Pearson卡方、Yates校正卡方(连续校正卡方)、趋势卡方,以及Fisher卡方检验(Fisher确切概率)等,应注意区分不同卡方统计量及其检验的适用条件,根据条件选择恰当的结果进行解释和分析。
使用SPSSAU进行卡方检验时,应注意【通用方法】→【交叉(卡方)】模块只提供较大样本时最常用的Pearson卡方检验,而【实验/医学研究】→【卡方检验】,模块可提供Pearson卡方、Yates校正卡方,以及Fisher卡方检验,适合小样本数据。
二、2×2四格表卡方检验
四格表是最基础的列联表,四格表卡方检验也是最常见的一种。本节介绍的是成组设计的四格表卡方检验,具体分析时需区分Pearson卡方、Yates校正卡方(连续校正卡方),以及Fisher卡方检验(Fisher确切概率)。其适用条件如表 4-24所示。
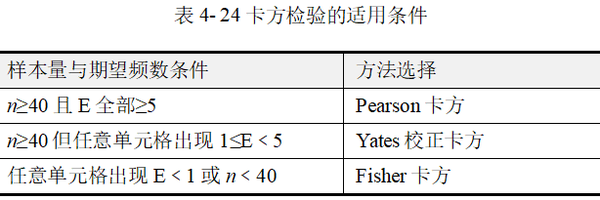
上表中n为样本量,E为理论频数。在四格表资料中,Pearson卡方适用于n≥40 且全部单元格 E≥5的情况。如果四格表 n≥40但任意单元格出现1≤E﹤5,则一般考虑采用Yates校正卡方,它是对Pearson卡方的校正结果。如果四格表中任意单元格出现E﹤1或n﹤40,则应当采用Fisher卡方(方积乾,2012)。
一般建议采用【实验/医学研究】→【卡方检验】模块来实现成组设计的四格表卡方检验。
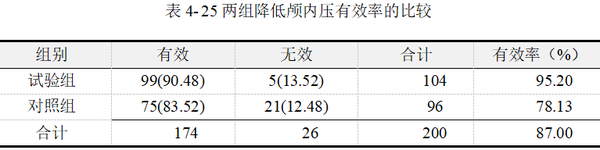
【例4-9】某医院欲比较异梨醇口服液(试验组)和氢氯噻嗪+地塞米松(对照组)降低颅内压的疗效。将200例颅内压增高症患者随机分为两组,结果见表 425。问两组降低颅内压的总体有效率有无差别?数据来源于孙振球,徐勇勇(2014),数据文档见“例4-9.xls”
1) 数据与案例分析
本例为频数资料,使用SPSSAU进行分析时,应按照加权数据格式录入数据。“组别”、“疗效”为均有2个水平的分类变量,“频数”为定量数据。在具体分析时需要将“频数”作为权重进行加权。本例加权数据格式见表 4-26。
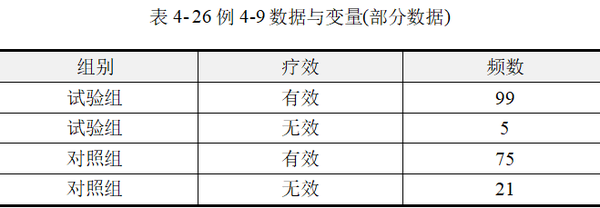
本例目的在于比较试验组与对照的治疗有效率,是典型的两组率的差异检验。数据资料为四格表频数资料,采用四格表卡方检验进行分析。
2) 卡方检验
读入数据后,仪表盘中依次选择【实验/医学研究】→【卡方检验】模块,将“组别”拖拽至【X(定类)】,“疗效”拖拽至【Y(定类)】。本例需加权处理,故再把“频数”拖拽至【加权项(可选)】。选项框内模型选择【百分数(按列)】,操作界面如图 414所示,最后单击【开始分析】。
图 4-14 卡方检验操作界面
3) 结果解读
为方便理解不同卡方统计量及其检验的适用条件,可先对卡方检验卡方统计量、期望频数E,样本容量n进行统计汇总,其结果见表 4-27,最后按表 4-27的常见三线表格式对结果进行报告。
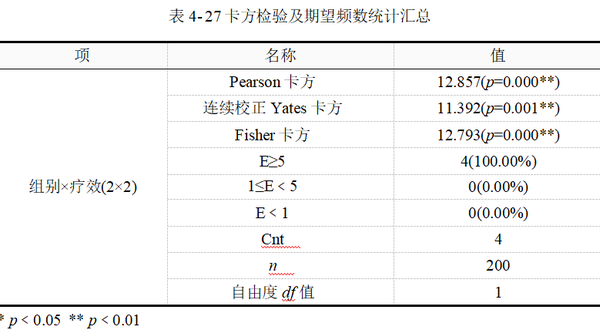
上表中包括了Pearson卡方、连续校正Yates卡方和Fisher卡方统计量及显著性p值,以及期望频数等基本信息的汇总结果。E为列联表单元格期望频数,n为样本量。本例中,样本量为200例,所有单元格的期望频数均大于5。根据卡方检验适用条件,应选择读取Pearson卡方检验结果。即卡方值12.857,p值﹤0.01,认为试验组与对照组两组人群的治疗有效率差异有统计学意义。
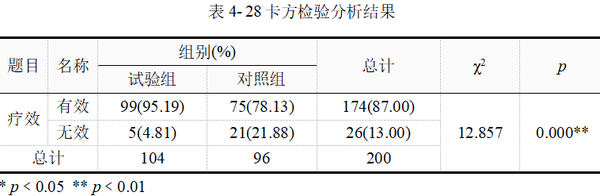
表 4-28最后两列给出的卡方统计量和p值,χ2=12.857,p值﹤0.01,其结果为平台自动匹配选择输出的Pearson卡方检验。
结合以上分析,可知试验组和对照组在降低颅内压的疗效并不相同。试验组有效率95.19%,对照组有效率78.13%。经Pearson卡方检验,按α=0.05水平,认为两组降低颅内压总体有效率不相等,具体表现为异梨醇口服液的有效率高于和氢氯噻嗪+地塞米松的有效率。
本例样本量和期望频数条件满足Pearson卡方检验的适用性,如果在四格表中有单元格出现期望频数在1~5之间的情况,则表 4-27会自动选择输出Yates校正卡方(连续性校正卡方检验)结果。一般建议读者直接读取和使用表 4-27的结果进行报告。
三、R×C表卡方检验与多重比较
R×C列联表卡方检验,包括常见的2×C两组构成比的差异比较;R×2两组或多组率的差异比较,还有多行多列即R×C列联表卡方检验。
本节内容介绍列联表中行与列两个变量均为无序多分类变量的情况,常见R×C卡方的应用场景见表 4-29。
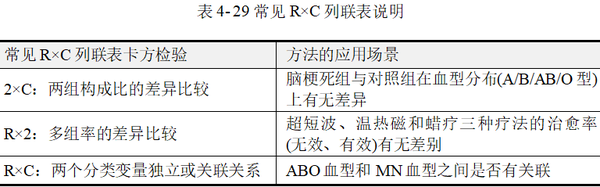
R×C列联表卡方检验时仍然采用的是Pearson卡方,其适用条件要求列联表中所有的单元格理论频数不应小于1,并且1≤E﹤5的单元格数量不宜超过总数的1/5。如果出现不符合该条件的情况,研究者可能要考虑采用Fisher确切概率法(方积乾,2012)。
R×C表卡方检验的结论是总体上差异是否显著,如果还想进一步判断两两总体率的差异,应继续做卡方结果的多重比较。在进行卡方检验时,【实验/医学研究】→【卡方检验】功能模块会根据分组情况自动实现卡方分割法多重比较。
以R×2列联表为例,卡方分割的基本思想是将R×2拆分为多个2×2四格表资料从而实现两两比较。例如3×2列联表检验3组总体率的差异,假设3个组名称分别为A/B/C,可拆分出AB(A、B两组率的比较)、AC、BC共3个2×2四格表卡方检验。
多重比较时,检验次数增多会增加Ⅰ类错误的概率,此过程应当对卡方检验p值进行校正,建议使用校正显著性水平(Bonferroni校正),假设显著性水平为0.05,当两两比较次数为3次时,那么Bonferroni校正显著性水平为0.05/3次=0.0167,即p值需要与0.0167进行对比,从而作出统计推断,而不是与0.05比较。
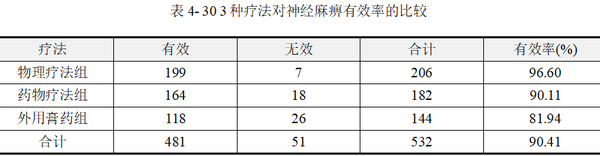
【例4-10】某医师研究物理疗法、药物治疗和外用膏药3种疗法治疗周围性面神经麻痹的疗效,数据资料见表 430。问3种疗法的有效率有无差别。数据来源于孙振球,徐勇勇(2014),本例数据文档见“例4-10.xls”。
1) 数据与案例分析
数据包括“组别”、“疗效”、“频数”3个变量,为加权数据格式。在表 430最后一列已经计算各组疗法的疗效有效率,依次为96.6%、90.11%、81.94%,本例目的比较3种不同治疗方法的疗效差异,为多组率的差异比较,接下来进行R×2卡方检验。
2) 卡方检验
读入数据后,依次选择【实验/医学研究】→【卡方检验】模块,将“组别”拖拽至【X(定类)】,“疗效”拖拽至【Y(定类)】。本例需加权处理,故再把“频数”拖拽至【加权项(可选)】。选项框内模型选择【百分数(按列)】,最后单击【开始分析】。
和上一例一样,表 4-31用于根据期望频数、样本量等适用条件选择正确的统计量和检验结果,表 4-32用于科研写作结果报告,也可以直接解释和分析表 4-32的结果。
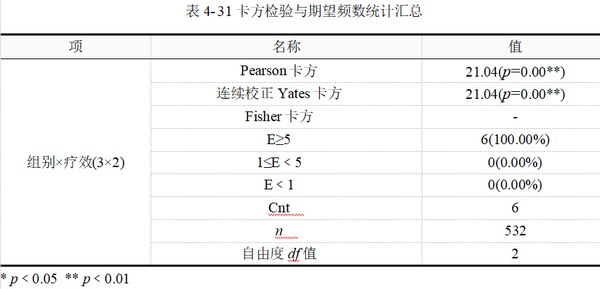
本例所有单元格E≥5,样本量532,依据卡方检验的适用条件,本例选择Pearson卡方检验结果,即卡方=21.04,p﹤0.01。
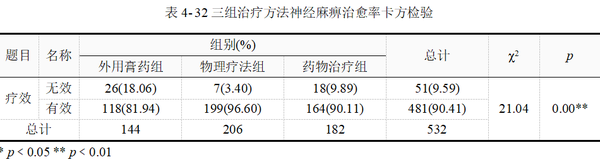
上表结果可直接用于报告,χ²=21.04,p值﹤0.01,说明3种疗法治疗周围性面神经麻痹的有效率有差别。
卡方检验时常使用相关性指标作为效应量的估计,如果研究上需要报告组别的效应量,可结合数据类型及交叉表格类型综合选择。如表 4-33所示,本例选择Cramer v效应量,此处Cramer v为0.2,说明存在弱相关。

综合以上信息,本例比较3组治疗方法的疗效。结果显示,χ²=21.04,p值﹤0.01,提示不同治疗方法其疗效不同,三组治疗有效率差异具有统计学意义。Cramer v = 0.20,疗法与治疗效果之间存在弱相关性。
3) 卡方分割多重比较
当卡方检验整体有显著性后,【实验/医学研究】→【卡方检验】模块会根据分组情况自动实现卡方分割法多重比较,本例结果如表 4-34示。
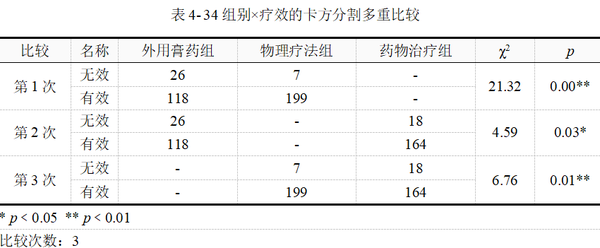
由上表可知,共进行3次拆分。第一次是外用膏药组与物理疗法组之间的治疗有效率差异比较;第2次是外用膏药组与药物治疗组之间的比较;第3次是物理疗法组与药物治疗组之间的比较。每一次拆分,都是一个独立的四格表卡方检验,输出对应的卡方统计量与显著性p值。
此处要注意到,表中最后一列的p值需要与校正后的显著性水平进行比较。本例进行3次两两比较,因此校正的显著性水平为α=0.05/3=0.0167,p值需与0.0167进行比较,从而推断检验的结果。
物理疗法组与外用膏药组p值﹤0.0167;物理疗法组与药物治疗组p值=0.01﹤0.0167。可以认为物理疗法与药物治疗、外用膏药的有效率均有统计学差异,具体来说是物理疗法的有效率高于其他两种疗法,但我们尚不能认为药物治疗与外用膏药的有效率有差异(p =0.03﹥0.0167)。
以上内容摘自《SPSSAU科研数据分析方法与应用》第4章——差异关系研究,书中不仅涵盖了数据清理、统计分析和模型构建等内容,还提供了丰富的案例,以便于读者在实际研究中应用。

相关文章:
卡方检验方法概述与类型——四格表和R*C表卡方检验案例
卡方检验是以卡方分布为基础,针对定类数据资料的常用假设检验方法。其理论思想是判断实际观测到的频数与有关总体的理论频数是否一致。 卡方统计量是实际频数与理论频数吻合程度的指标。卡方值越小,表明实际观察频数与理论频数越接近,反之卡…...

在浏览器和Node.js环境中使用Puppeteer的Rollup与Webpack打包指南
Puppeteer是一个Node.js库,它提供了一套高级API来通过DevTools协议控制Chrome或Chromium。虽然Puppeteer通常在服务器端使用,但有时你可能需要在浏览器环境中使用它的某些功能。本文将介绍如何使用Rollup和Webpack来打包包含Puppeteer或其轻量级版本Pupp…...

GPT论文整理提示词
论文阅读 指令1:粗读论文 请你阅读并理解这篇文献,然后将该篇文章的标题作为一级标题,将摘要和各个大标题作为二级标题,将小标题作为三级标题,将小标题下每一部分内容作为四级标题,给我以markdown的语言输出中文的翻…...

在培训班学网络安全有用吗
在当今数字化时代,网络安全问题日益凸显,成为了企业和个人关注的焦点。随着对网络安全人才需求的不断增长,各种网络安全培训班也如雨后春笋般涌现。然而,在培训班学网络安全真的有用吗? 一、网络安全的重要性与挑战 1. 信息时代的…...

Flink CDC系列之:理解学习YARN模式
Flink CDC系列之:理解学习YARN模式 准备会话模式在 YARN 上启动 Flink 会话设置 Flink CDC提交 Flink CDC Job Apache Hadoop YARN 是许多数据处理框架中流行的资源提供者。Flink 服务提交给 YARN 的 ResourceManager,后者在由 YARN NodeManagers 管理的…...

langgraph入门
使用langgraph框架搭建一个简易agent。 最近想学习一下agent相关知识,langgraph似乎挺好的,于是就来试一试。langgraph。看了官网,起核心思想是将agent中的角色和工具都当作是图的Node,整个agent流程通过增加Node之间的边来设定。…...

【Python】爬虫程序打包成exe
上一篇写了爬虫获取汽车之家配置表,师父要更方便使用甚至推广(?),反正就是他们没有环境也能用嘛,我就直接打包了,界面不会做也懒得学了、、 1、下载pyinstaller(清华镜像)…...

【力扣专题栏】两两交换链表中的节点,如何实现链表中两两相邻节点的交换?
这里写目录标题 1、题目描述解释2、算法原理解析3、代码编写 1、题目描述解释 2、算法原理解析 3、代码编写 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int…...

埋点采集的日志数据常见的格式简介
埋点采集的日志数据通常以结构化或半结构化的格式进行记录,以便于分析和处理。常见的格式包括: 1. JSON(JavaScript Object Notation) 特点:JSON 格式是一种轻量级的数据交换格式,具有良好的可读性和兼容…...

基于SSM高考志愿辅助填报系统设计与实现
前言 近年来,由于计算机技术和互联网技术的飞速发展,所以各企事业单位内部的发展趋势是数字化、信息化、无纸化,随着这一趋势,而各种决策系统、辅助系统也就应运而生了,其中,信息管理系统是其中重要的组成…...
elasticsearch 8.x 插件安装(六)之Hanlp插件
elasticsearch 8.x 插件安装(六)之Hanlp插件 elasticsearch插件安装合集 elasticsearch插件安装(一)之ik分词器安装(含MySQL更新) elasticsearch 8.x插件(二)之同义词安装如何解决…...

排序算法简记
列举几种基本的排序算法和排序思想 排序就是将一组对象按照某种逻辑顺序重新排列的过程。 一、选择排序 1、基本原理 最基本的排序,每次都从原有数据中选择最小或最大的数组放入新数据集中 2、步骤(以从小到大为例) 首先, 找到数组中最小的那个元素…...

Stable diffusion inference 多卡并行
stable diffusion 推理过程 多卡并行 注意事项 以SDXL为例,指定GPU,添加device_map参数信息 device_map {add_embedding: 1,decoder: 1,encoder: 1,conv_in: 1,conv_out: 1,post_quant_conv: 1,text_model: 6,conv_norm_out: 1,quant_conv: 1,time_em…...

Docker:namespace环境隔离 CGroup资源控制
Docker:namespace环境隔离 & CGroup资源控制 Docker虚拟机容器 namespace相关命令ddmkfsdfmountunshare 进程隔离文件隔离 CGroup相关命令pidstatstresscgroup控制 内存控制CPU控制 Docker 在开发中,经常会遇到环境问题,比如程序依赖某个…...
鼠标增强工具 MousePlus v5.3.9.0 中文绿色版
MousePlus 是一款功能强大的鼠标增强工具,它可以帮助用户提高鼠标操作效率和精准度。该软件可以自定义鼠标的各种功能和行为,让用户根据自己的习惯和需求来调整鼠标的表现。 详细功能 自定义鼠标按钮功能:可以为鼠标的各个按钮设置不同的功能…...

Android 圆形进度条CircleProgressView 基础版
一个最基础的自定义View 圆形进度条,可设置背景色、进度条颜色(渐变色)下载进度控制;可二次定制度高; 核心代码: Overrideprotected void onDraw(NonNull Canvas canvas) {super.onDraw(canvas);int mW g…...

理解磁盘结构---CHS---LAB---文件系统
1,初步了解磁盘 机械磁盘是计算机中唯的一个机械设备, 特点是慢,容量大,价格便宜。 磁盘上面的光面,由数不清的小磁铁构成,我们知道磁铁是有n/s极的,这刚好与二进制的&…...

我在1024谈华为
华为的发展历程与技术创新 华为自成立以来,一直是通信技术领域的重要参与者。让我们回顾一下华为的一些关键发展里程碑: 1987年,华为在深圳成立,起初专注于电话交换网络的研发和销售。 进入1990年代,华为转型为通信…...

NVR小程序接入平台/设备EasyNVR多品牌NVR管理工具/设备视频监控解决方案
随着科技的飞速发展,安防视频监控已成为维护公共安全、提升管理效率的重要手段。在这一领域中,NVR小程序接入平台/设备EasyNVR凭借其灵活的部署方式、强大的功能以及卓越的性能表现,脱颖而出,引领着安防视频监控的新纪元。 NVR小程…...

二叉树前序遍历的 Java 实现,包括递归和非递归两种方式
二叉树前序遍历是一种遍历树节点的方式,遵循特定的顺序。其基本过程可以总结为以下几个步骤: 前序遍历的顺序 访问根节点:首先处理当前节点。 递归遍历左子树:然后依次访问左子树。 递归遍历右子树:最后访问右子树。 …...

终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统
终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers…...

Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门
更多请点击: https://intelliparadigm.com 第一章:Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门 在对 Starter 计划的 API 调用行为进行深度监控时,我们观察到配额耗尽告警频…...
)
ComfyUI全面掌握-知识点详解——自定义节点安装与首次 AI 绘图(实操+排错)
本文为系列第 6 篇(第一章第 5 个知识点),讲解自定义节点的作用与安装方式,手把手教读者加载默认工作流、完成首次 AI 绘图,解读核心参数并排查常见问题。 目录 一、引言:自定义节点是什么?为什…...

如何构建高效的个人游戏串流服务器:Sunshine完整部署指南
如何构建高效的个人游戏串流服务器:Sunshine完整部署指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在当今数字娱乐时代,游戏玩家面临着设备限制与体验…...

不止于Java:在Termux的Ubuntu子系统里,我这样配置Python/Node.js多语言开发环境
不止于Java:在Termux的Ubuntu子系统里配置Python/Node.js多语言开发环境 将手机变成便携式开发工作站早已不是天方夜谭。通过Termux和proot-distro搭建的Ubuntu子系统,开发者可以在Android设备上构建完整的Linux开发环境。与局限于单一语言的解决方案不同…...

利用ODX实现整车诊断数据库管理
一:背景与挑战| 背景:在全球汽车行业快速发展的背景下,对车辆诊断技术的要求也在不断提升。ODX(Open Diagnostic data eXchange)作为行业标准的诊断数据库,已被各大汽车制造商广泛采用,并贯穿于ECU的整个生…...

016、气压计原理与高度测量
飞控算法从入门到精通 016 气压计原理与高度测量 一、一次炸机带来的教训 去年夏天,我在一个四轴飞行器上调试定高悬停。气压计用的是MS5611,数据手册翻烂了,滤波算法也上了,地面站里高度曲线看着挺平滑。结果一上天,飞机像喝醉了酒——先是莫名其妙往下掉半米,然后猛…...
)
VSCode调试C++项目全攻略:从CMake工程配置到Native Debug实战(含传参技巧)
VSCode调试C项目全攻略:从CMake工程配置到Native Debug实战(含传参技巧) 在当今的C开发环境中,高效调试已成为提升生产力的关键环节。对于使用CMake管理的中大型项目,如何在VSCode中实现无缝调试体验,是许多…...

观察taotoken在ubuntu高峰期调用时的稳定性与自动路由效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在 Ubuntu 高峰期调用时的稳定性与自动路由效果 1. 背景与测试环境 在日常的开发与调试工作中,我们经常…...

STM32+原理图+PCB程序直流充电桩主控方案源
💥💥💞💞欢迎来到本博客❤️❤️💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭:行百…...