Java 分布式缓存
在当今的大规模分布式系统中,缓存技术扮演着至关重要的角色。Java 作为一种广泛应用的编程语言,拥有丰富的工具和框架来实现分布式缓存。本文将深入探讨 Java 分布式缓存的概念、优势、常见技术以及实际应用案例,帮助读者更好地理解和应用这一关键技术。
一、引言
随着互联网的快速发展,软件系统的规模和复杂性不断增加。为了满足高并发、低延迟的需求,分布式系统架构成为了主流选择。在分布式系统中,数据的存储和访问面临着诸多挑战,如数据一致性、性能瓶颈等。分布式缓存作为一种有效的解决方案,可以显著提高系统的性能和响应速度,减轻数据库的负担,提升用户体验。
二、分布式缓存的概念与优势
(一)分布式缓存的定义
分布式缓存是将数据存储在多个节点上的缓存系统。它通过将数据分散到不同的服务器上,实现了数据的分布式存储和访问。分布式缓存可以在内存中存储经常访问的数据,以便快速响应客户端的请求,减少对数据库的访问次数,从而提高系统的性能和吞吐量。
(二)分布式缓存的优势
- 提高系统性能
- 分布式缓存将数据存储在内存中,使得数据的访问速度远远快于从数据库中读取数据。通过减少对数据库的访问次数,可以显著提高系统的响应速度和吞吐量,降低系统的延迟。
- 减轻数据库负担
- 在高并发的情况下,数据库往往成为系统的性能瓶颈。分布式缓存可以将经常访问的数据缓存起来,减少对数据库的访问压力,从而提高数据库的性能和稳定性。
- 提高数据可用性
- 分布式缓存通常采用多副本机制,将数据存储在多个节点上。即使某个节点出现故障,其他节点仍然可以提供数据服务,从而提高了数据的可用性和系统的可靠性。
- 便于扩展
- 分布式缓存可以很容易地进行扩展,通过增加节点数量来提高缓存的容量和性能。这种扩展性使得分布式缓存能够适应不断增长的业务需求和数据量。
三、Java 分布式缓存的常见技术
(一)Ehcache
- 简介
- Ehcache 是一个广泛使用的 Java 缓存框架,它提供了内存缓存和磁盘缓存两种存储方式。Ehcache 支持多种缓存策略,如 LRU(Least Recently Used)、LFU(Least Frequently Used)等,可以根据实际需求进行选择。
- 特点
- 简单易用:Ehcache 的 API 简单直观,易于使用和集成到 Java 应用程序中。
- 高性能:Ehcache 在内存中存储数据,具有非常高的访问速度。同时,它还支持磁盘缓存,可以在内存不足时将数据存储到磁盘上。
- 多种缓存策略:Ehcache 支持多种缓存策略,可以根据实际需求进行选择,提高缓存的命中率和性能。
- 分布式支持:Ehcache 可以通过扩展实现分布式缓存,支持多个节点之间的数据同步和共享。
- 示例代码
- 以下是一个使用 Ehcache 的简单示例:
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager;
import net.sf.ehcache.Element;public class EhcacheExample {public static void main(String[] args) {// 创建缓存管理器CacheManager cacheManager = CacheManager.create();// 获取缓存对象Cache cache = cacheManager.getCache("myCache");// 将数据放入缓存cache.put(new Element("key1", "value1"));// 从缓存中获取数据Element element = cache.get("key1");if (element!= null) {System.out.println("Value from cache: " + element.getValue());}// 关闭缓存管理器cacheManager.shutdown();}
}
(二)Guava Cache
- 简介
- Guava Cache 是 Google 开发的一个 Java 缓存库,它提供了一种简单而强大的方式来缓存数据。Guava Cache 支持多种缓存策略,如基于时间的过期、基于容量的淘汰等,可以根据实际需求进行选择。
- 特点
- 简单易用:Guava Cache 的 API 非常简单,易于使用和集成到 Java 应用程序中。
- 高性能:Guava Cache 在内存中存储数据,具有非常高的访问速度。同时,它还支持自动加载数据,可以在数据不存在时自动从数据源加载数据。
- 多种缓存策略:Guava Cache 支持多种缓存策略,可以根据实际需求进行选择,提高缓存的命中率和性能。
- 监控和统计:Guava Cache 提供了丰富的监控和统计功能,可以方便地了解缓存的使用情况和性能指标。
- 示例代码
- 以下是一个使用 Guava Cache 的简单示例:
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;import java.util.concurrent.ExecutionException;public class GuavaCacheExample {public static void main(String[] args) {// 创建缓存LoadingCache<String, String> cache = CacheBuilder.newBuilder().maximumSize(100).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {// 当缓存中不存在数据时,从数据源加载数据return loadDataFromDatabase(key);}});// 将数据放入缓存cache.put("key1", "value1");// 从缓存中获取数据try {String value = cache.get("key1");System.out.println("Value from cache: " + value);} catch (ExecutionException e) {e.printStackTrace();}}private static String loadDataFromDatabase(String key) {// 模拟从数据库加载数据return "Value from database for key: " + key;}
}
(三)Redis
- 简介
- Redis 是一个开源的内存数据结构存储系统,它可以用作数据库、缓存和消息中间件。Redis 支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,可以满足不同的应用需求。
- 特点
- 高性能:Redis 将数据存储在内存中,具有非常高的访问速度。同时,它还支持持久化,可以将数据存储到磁盘上,保证数据的安全性。
- 丰富的数据结构:Redis 支持多种数据结构,可以满足不同的应用需求。例如,可以使用字符串存储简单的键值对,使用哈希表存储对象,使用列表实现队列等。
- 分布式支持:Redis 可以很容易地进行扩展,通过增加节点数量来提高缓存的容量和性能。同时,Redis 还支持主从复制和哨兵模式,可以提高系统的可用性和可靠性。
- 示例代码
- 以下是一个使用 Redis 的简单示例:
import redis.clients.jedis.Jedis;public class RedisExample {public static void main(String[] args) {// 连接到 Redis 服务器Jedis jedis = new Jedis("localhost", 6379);// 将数据放入缓存jedis.set("key1", "value1");// 从缓存中获取数据String value = jedis.get("key1");System.out.println("Value from cache: " + value);// 关闭连接jedis.close();}
}
四、Java 分布式缓存的设计与实现
(一)缓存策略的选择
- 基于时间的过期
- 基于时间的过期策略是指在缓存中存储数据时,设置一个过期时间。当数据超过过期时间时,自动从缓存中删除。这种策略适用于数据的时效性要求较高的场景,如缓存用户的登录状态、验证码等。
- 基于容量的淘汰
- 基于容量的淘汰策略是指在缓存中存储数据时,设置一个最大容量。当缓存中的数据量超过最大容量时,自动淘汰一些数据。这种策略适用于数据量较大的场景,如缓存商品列表、文章列表等。
- 基于访问频率的淘汰
- 基于访问频率的淘汰策略是指在缓存中存储数据时,记录数据的访问频率。当缓存中的数据量超过最大容量时,自动淘汰访问频率较低的数据。这种策略适用于数据的访问频率差异较大的场景,如缓存热门文章、热门商品等。
(二)缓存数据的存储结构
- 键值对存储
- 键值对存储是最常见的缓存数据存储结构。在这种结构中,每个数据都有一个唯一的键和一个对应的值。通过键可以快速地访问到对应的值。这种存储结构适用于存储简单的数据,如字符串、数字、对象等。
- 哈希表存储
- 哈希表存储是一种将数据存储在哈希表中的结构。在这种结构中,每个数据都有一个唯一的键和一个对应的值。通过键可以快速地访问到对应的值。哈希表存储适用于存储复杂的数据结构,如对象、列表、集合等。
- 列表存储
- 列表存储是一种将数据存储在列表中的结构。在这种结构中,数据按照插入的顺序存储在列表中。可以通过索引快速地访问到列表中的某个元素。列表存储适用于存储有序的数据,如文章列表、商品列表等。
- 集合存储
- 集合存储是一种将数据存储在集合中的结构。在这种结构中,数据是无序的,并且不允许重复。可以通过元素快速地访问到集合中的某个元素。集合存储适用于存储不重复的数据,如用户列表、商品分类列表等。
(三)分布式缓存的一致性问题
- 缓存与数据库的一致性
- 在分布式系统中,缓存与数据库之间的数据一致性是一个重要的问题。当数据库中的数据发生变化时,需要及时更新缓存中的数据,以保证缓存中的数据与数据库中的数据一致。可以通过监听数据库的变化、使用消息队列等方式来实现缓存与数据库的一致性。
- 分布式缓存节点之间的一致性
- 在分布式缓存中,多个节点之间的数据一致性也是一个重要的问题。当某个节点中的数据发生变化时,需要及时将变化同步到其他节点,以保证所有节点中的数据一致。可以通过使用分布式锁、一致性哈希等方式来实现分布式缓存节点之间的一致性。
五、Java 分布式缓存的性能优化
(一)缓存预热
- 简介
- 缓存预热是指在系统启动时,将一些经常访问的数据预先加载到缓存中,以减少系统启动后的首次访问时的缓存 miss,提高系统的响应速度。
- 实现方式
- 可以在系统启动时,通过查询数据库或其他数据源,将一些经常访问的数据加载到缓存中。也可以在系统运行过程中,通过定时任务或其他方式,将一些热点数据预先加载到缓存中。
(二)缓存淘汰策略的优化
- 基于访问时间的淘汰策略
- 基于访问时间的淘汰策略是指在缓存中存储数据时,记录数据的最后访问时间。当缓存中的数据量超过最大容量时,自动淘汰那些最后访问时间最早的数据。这种策略适用于数据的访问频率差异较大的场景,如缓存热门文章、热门商品等。
- 基于访问频率的淘汰策略
- 基于访问频率的淘汰策略是指在缓存中存储数据时,记录数据的访问频率。当缓存中的数据量超过最大容量时,自动淘汰那些访问频率较低的数据。这种策略适用于数据的访问频率差异较大的场景,如缓存热门文章、热门商品等。
- 基于数据大小的淘汰策略
- 基于数据大小的淘汰策略是指在缓存中存储数据时,记录数据的大小。当缓存中的数据量超过最大容量时,自动淘汰那些数据大小较大的数据。这种策略适用于数据大小差异较大的场景,如缓存图片、视频等大文件。
(三)缓存的分布式存储与访问优化
- 分布式缓存的一致性哈希算法
- 一致性哈希算法是一种用于分布式缓存的哈希算法。它可以将数据均匀地分布到多个节点上,并且在节点增加或减少时,只需要重新映射部分数据,而不是全部数据。这种算法可以提高分布式缓存的可扩展性和性能。
- 分布式缓存的读写分离
- 分布式缓存的读写分离是指将缓存的读操作和写操作分别分配到不同的节点上。读操作可以从多个节点上读取数据,提高读操作的性能;写操作可以只在一个节点上进行,保证数据的一致性。这种方式可以提高分布式缓存的性能和可扩展性。
六、Java 分布式缓存的实际应用案例
(一)电商系统中的商品缓存
- 问题描述
- 在电商系统中,商品信息的查询是一个非常频繁的操作。如果每次查询都从数据库中读取数据,会给数据库带来很大的压力,影响系统的性能。因此,需要使用分布式缓存来缓存商品信息,提高系统的性能。
- 解决方案
- 可以使用 Redis 或 Ehcache 等分布式缓存框架来缓存商品信息。在商品信息发生变化时,及时更新缓存中的数据,以保证缓存中的数据与数据库中的数据一致。同时,可以使用缓存预热技术,在系统启动时将一些热门商品的信息预先加载到缓存中,提高系统的响应速度。
(二)社交系统中的用户状态缓存
- 问题描述
- 在社交系统中,用户的状态信息(如在线状态、离线状态等)是一个非常频繁的查询操作。如果每次查询都从数据库中读取数据,会给数据库带来很大的压力,影响系统的性能。因此,需要使用分布式缓存来缓存用户状态信息,提高系统的性能。
- 解决方案
- 可以使用 Redis 或 Ehcache 等分布式缓存框架来缓存用户状态信息。在用户状态发生变化时,及时更新缓存中的数据,以保证缓存中的数据与数据库中的数据一致。同时,可以使用缓存预热技术,在系统启动时将一些热门用户的状态信息预先加载到缓存中,提高系统的响应速度。
(三)金融系统中的交易数据缓存
- 问题描述
- 在金融系统中,交易数据的查询是一个非常频繁的操作。如果每次查询都从数据库中读取数据,会给数据库带来很大的压力,影响系统的性能。因此,需要使用分布式缓存来缓存交易数据,提高系统的性能。
- 解决方案
- 可以使用 Redis 或 Ehcache 等分布式缓存框架来缓存交易数据。在交易数据发生变化时,及时更新缓存中的数据,以保证缓存中的数据与数据库中的数据一致。同时,可以使用缓存预热技术,在系统启动时将一些热门交易数据预先加载到缓存中,提高系统的响应速度。
七、结论
Java 分布式缓存是提高系统性能和可扩展性的重要技术。通过选择合适的分布式缓存框架、设计合理的缓存策略和存储结构、解决缓存一致性问题以及进行性能优化,可以有效地提高系统的性能和响应速度,减轻数据库的负担,提升用户体验。在实际应用中,需要根据具体的业务需求和系统架构选择合适的分布式缓存方案,并不断进行优化和改进,以满足不断增长的业务需求。
相关文章:

Java 分布式缓存
在当今的大规模分布式系统中,缓存技术扮演着至关重要的角色。Java 作为一种广泛应用的编程语言,拥有丰富的工具和框架来实现分布式缓存。本文将深入探讨 Java 分布式缓存的概念、优势、常见技术以及实际应用案例,帮助读者更好地理解和应用这一…...

【MySQL】MySQL 使用全教程
MySQL 使用全教程 介绍 MySQL 是一种广泛使用的开源关系型数据库管理系统(Relational Database Management System),它基于 Structured Query Language(SQL)进行数据管理,允许用户存储、检索、更新和删除数据库中的数据。通过提供…...

油猴脚本-GPT问题导航侧边栏增强版
为 GPT官网和相关网站提供了一个便捷的侧边栏目录,能够自动搜集当前会话页面的问题,展示在侧边栏上,可快速导航到问题的位置。 安装使用地址:https://scriptcat.org/zh-CN/script-show-page/1972 安装前请确保浏览器有油猴,没有…...

Java Lock ConditionObject 总结
前言 相关系列 《Java & Lock & 目录》(持续更新)《Java & Lock & ConditionObject & 源码》(学习过程/多有漏误/仅作参考/不再更新)《Java & Lock & ConditionObject & 总结》(学习…...
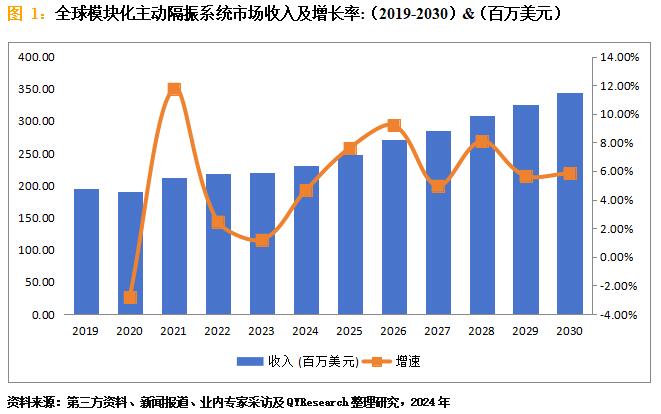
模块化主动隔振系统市场规模:2023年全球市场规模大约为220.54百万美元
模块化主动隔振系统是一种用于精密设备和实验装置的隔振解决方案,通过主动控制技术消除振动干扰,提供稳定的环境。目前,随着微纳制造和精密测量技术的发展,对隔振系统的要求越来越高。模块化设计使得系统能够灵活适应不同负载和工…...

SpringAOP:对于同一个切入点,不同切面不同通知的执行顺序
目录 1. 问题描述2. 结论结论1:"对于同一个切入点,同一个切面不同类型的通知的执行顺序"结论2:"对于同一个切入点,不同切面不同类型通知的执行顺序" 3. 测试环境:SpringBoot 2.3.4.RELEASE测试集合…...

unique_ptr初始化
std::unique_ptr 是 C11 引入的智能指针,用于管理动态分配的对象的生命周期。unique_ptr 确保每个动态分配的对象有且仅有一个所有者,当 unique_ptr 超出作用域时,它会自动释放其管理的对象。以下是 std::unique_ptr 的一些常见初始化方法。 …...

HelloCTF [RCE-labs] Level 8 - 文件描述和重定向
开启靶场,打开链接: GET传参cmd system($cmd.">/dev/null 2>&1"); 这行代码将执行命令 $cmd,并且将其标准输出和标准错误输出都重定向到 /dev/null,这意味着无论命令的输出还是可能产生的错误信息都不会显示…...

DEVOPS: 集群伸缩原理
概述 阿里云 K8S 集群的一个重要特性,是集群的节点可以动态的增加或减少有了这个特性,集群才能在计算资源不足的情况下扩容新的节点,同时也可以在资源利用 率降低的时候,释放节点以节省费用理解实现原理,在遇到问题的…...

什么是SMO算法
SMO算法(Sequential Minimal Optimization) 是一种用于求解 支持向量机(SVM) 二次规划对偶问题的优化算法。它由 John Platt 在 1998 年提出,目的是快速解决 SVM 的优化问题,特别是当数据集较大时ÿ…...

MySQL根据.idb数据恢复脚本,做成了EXE可执行文件
文章目录 1.代码2.Main方法打包3.Jar包打成exe可执行文件4.使用(1.)准备一个表结构一样得数据库(2.)打开软件(3.)输入路径 5.恢复成功 本文档只是为了留档方便以后工作运维,或者给同事分享文档内…...

Spring Boot面试题
1.什么是SpringBoot?它的主要特点是什么? Spring Boot 是一个基于 Spring 框架的开发和构建应用程序的工具,它旨在简化 Spring 应用的初始搭建和开发过程。Spring Boot 提供了一种约定优于配置的方式,通过自动配置和默认值&#…...

原生页面引入Webpack打包JS
Webpack简介 概述: Webpack是一个现代JavaScript应用程序的静态模块打包器。它将应用程序中的每个文件视为一个模块,并通过配置规则来解析这些模块之间的依赖关系,最终将其打包成一个或多个浏览器可以执行的文件。动态加载(Code …...

健康之路押注医药零售:毛利率下滑亏损扩大,医疗咨询人次大幅减少
《港湾商业观察》黄懿 2024年9月13日,健康之路股份有限公司(下称“健康之路”)再次递表港交所,建银国际为独家保荐人。健康之路国内运营主体为健康之路(中国)信息技术有限公司和福建健康之路信息技术有限公…...

【人工智能-初级】第7章 聚类算法K-Means:理论讲解与代码示例
文章目录 一、K-Means聚类简介二、K-Means 聚类的工作原理2.1 初始化簇中心2.2 分配簇标签2.3 更新簇中心2.4 迭代重复2.5 K-Means 算法的目标三、K-Means 聚类的优缺点3.1 优点3.2 缺点四、K 值的选择五、Python 实现 K-Means 聚类5.1 导入必要的库5.2 生成数据集并进行可视化…...

HOT 100 技巧题(136/169/75/31/287)
136. 只出现一次的数字 技巧类型题目,通过异或运算实现 169. 多数元素 三种常见解法:1. 哈希2. 排序3. 投票法 75. 颜色分类 单指针 两次遍历:第一次遍历把所有0都交换到前面,记录最后一个0的位置index,第二次遍…...

什么是时间戳?怎么获取?有什么用?
在 JavaScript 中,时间戳通常表示为自 1970 年 1 月 1 日 00:00:00 UTC 以来的毫秒数。我们可以使用 Date 对象来获取当前时间的时间戳,或者将特定的日期转换为时间戳。在JavaScript中,时间戳通常以毫秒为单位表示。 如何获取时间戳 在Java…...

LeetCode:459重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。 示例 1: 输入: s "abab" 输出: true 解释: 可由子串 "ab" 重复两次构成。示例 2: 输入: s "aba" 输出: false示例 3: 输入: s "abcabcabcabc" 输…...
【含开题报告+文档+PPT+源码】基于SSM的旅游与自然保护平台开发与实现
开题报告 围场县拥有丰富的自然景观和野生动植物资源,同时面临着旅游业发展和自然保护之间的平衡问题,通过强调自然保护,这个平台可以教育游客如何尊重和保护当地的生态环境。同时,平台还可以提供关于生态保护的信息,…...

【ANTs】医疗影像工具ANTs多种安装方式教程
介绍ANTs的几种简单的安装教程 基于Releases的安装 Github上选择适配自己操作系统的安装包,链接: link 一般使用最新版本。这里官方操作说明,支持Ubuntu、MacOS、CentOS,但是windows有安装包,不知道怎么用。。。 下载后有两个文件夹,bin和lib,bin里面长这样(图示wind…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

为VS Code集成GPT-4V视觉能力:VisualChatGPTStudio实战指南
1. 项目概述:当ChatGPT“睁开双眼”如果你和我一样,是个重度依赖ChatGPT进行编程、文档撰写和头脑风暴的开发者,那你一定体验过它的强大与局限。它能写出漂亮的代码片段,解释复杂的概念,但当你指着屏幕上的一个错误说“…...

VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得
VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得 当第一次在无人机上部署VINS-Mono时,我盯着实时轨迹和地面真值之间逐渐拉大的偏差,意识到论文里的漂亮曲线背后藏着太多未言明的细节。这次评测源于一个实…...

AI编程助手配置统一管理:code-agnostic实现多编辑器配置同步
1. 项目概述:告别配置碎片化,一个中心管理所有AI编辑器如果你和我一样,同时在使用Cursor、OpenCode、Codex甚至Claude Code这些AI编程助手,那你一定对配置管理的混乱深有体会。每个编辑器都有一套自己的配置格式和存放位置&#x…...

超长上下文处理能力翻倍,响应速度提升47%,API成本下降22%:Claude 3.5 Sonnet新功能落地实战手册,仅限本周内有效
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet新功能概览与核心突破 Anthropic 正式发布的 Claude 3.5 Sonnet 在推理效率、多模态理解边界与开发者集成体验上实现了显著跃迁。相比前代,其上下文窗口稳定支持 200K tok…...
)
从pip._vendor.urllib3报错到apt-get失败:一次搞定Ubuntu网络DNS配置(附阿里云镜像加速)
从pip报错到apt-get失败:Ubuntu网络DNS配置全攻略 最近在Ubuntu 16.04上配置Python开发环境时,遇到了一个看似简单却令人头疼的问题——pip安装包时频繁报错pip._vendor.urllib3.connection.HTTPSConnection,紧接着发现连apt-get update也失败…...

外汇延迟套利检测系统演进:从规则到AI的行为博弈
1. 项目概述:当速度优势不再是护城河 在电子外汇交易的世界里,速度套利一直是一个古老而又充满技术魅力的游戏。它的核心逻辑简单到近乎纯粹:如果你能比你的交易对手更快地获取到市场价格变动的信息,你就能在对手更新其报价之前&a…...

从零打造蒸汽朋克辉光管时钟:驱动方案、定制管与系统集成实战
1. 项目概述:从零开始的蒸汽朋克辉光管时钟作为一个在电子制作和复古硬件领域折腾了十多年的老玩家,我始终对那些散发着温暖橘红色光芒的辉光管(Nixie Tube)情有独钟。它们不仅仅是时间的显示器,更像是一件连接过去与未…...

nimbus-router:声明式路由增强框架,解决SPA复杂路由管理痛点
1. 项目概述:一个为现代前端应用量身定制的路由解决方案 如果你和我一样,在过去几年里深度参与过大型前端项目的开发,那你一定对路由管理这个“甜蜜的负担”深有体会。一方面,像 React Router、Vue Router 这样的库已经非常成熟&a…...

AI写测试靠谱吗?深度体验Diffblue Cover后,我总结了这3个真实使用场景和2个坑
AI写测试靠谱吗?深度体验Diffblue Cover后的实战思考 第一次在IntelliJ的插件市场看到Diffblue Cover时,我的反应和大多数Java开发者一样——"这玩意儿真能自动写测试?"作为在金融行业摸爬滚打八年的老码农,我见过太多号…...