(蓝桥杯C/C++)——常用库函数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、 二分查找
1.二分查找的前提
2.binary_ search函数
3.lower_bound和upper_bound
二、排序
1.sort概念
2.sort的用法
3.自定义比较函数
三、全排列
1.next permutation函数
2.prev_permutation()函数
四、最值查找
1.min和max函数
2.min element和max element
3.nth_element函数
五、大小写转换
1.islower/isupper函数
2.tolower/toupper函数
3.ascii码
六、其他库函数
1.memset()
2.swap()
3.reverse()
4.unique()
一、 二分查找
1.二分查找的前提
库函数只能对数组进行二分查找,
对一个数组进行二分查找的前提是这个数组中的元素是单调的,一般为单调不减,当然如果是单调不增也可以(需要修改比较函数)
例如:
[1,5,5.9,18]是单调的
[1,9,9,7,15]不是单调的
[9,8,8.7,7,1]是单调的
2.binary_ search函数
binary_ search是C++标准库中的一个算法函数,用于在已排序的序列(例如数组或容器中查找特定元素。
容器:C++标准模板库(STL)提供了一系列预定义的容器类,这些容器类是用来存储和管理对象的集合。
它通过二分查找算法来确定序列中是否存在目标元素。
函数返回一个bool值,表示目标元素是否存在于席列中。
如果需要获取找到的元素的位置,可以使用
lower_ bound函数或upper_ bound函数
代码如下(示例):
vector<int> numbers = {1, 3, 5, 7};
int a = 5;
//使用binary_ search查找目标元素
bool found = binary_ search(numbers.begin(), numbers.end(),a);
if (found)
{
cout << "a element " << a << "found." << endl;
}
else
{
cout << "a element "<< a << " not found." << endl;
}
3.lower_bound和upper_bound
前提:数组必须为非降序。
如果要在非升序的数组中使用,可以通过修改比较函数实现(方法与sort自定义比较函数似)
lower_ bound(st,ed,x)返回地址[st,ed)中第一个大于等于x的元素的地址。
//st(起始地址)/ed(结束地址)
upper_ bound(st,ed,x)返回地址[st,ed)中第一个大于x的元素的地址。
//地址-首地址=下标
如果不存在则返回最后一个元素的下一个位置,在vector中即end()。
代码如下(示例):
//初始化v
vector<int> v = {5, 1, 3, 7, 9};
sort ( v.begin(), v.end () );
for (auto &i : v)
cout << i << ' ' :
cout << '\n' ;
//找到数组中第一个大于等于5的元素位置
cout << (lower_bound(v.begin(), v.end(), 5) - v.begin()) << '\n';
二、排序
1.sort概念
sort函数包含在头文件<algorithm>中:在使用前需要#include<algorithm>或使用万能头文件。sort是C++标准库中的一个函数模板,用于对指定范围内的元素进行排序。
sort算法使用的是快速排序(QuickSort)或者类似快速排序的改进算法,具有较好的平均时间复杂度,一般为O(nlogn)。
2.sort的用法
sort(起始地址, 结束地址的下一位, *比较函数);
代码如下(示例):
int a[100];
int n;
//读取数组大小
cin >> n;
//读取元素
for(int i = 1;i <= n; ++i)
cin >> a[i];
//对数组进行排序
sort(a + 1, a + n + 1);
//输出
for(int i = 1;i <= n; ++i)
//可以替换成 for(auto i : v)
cout << a[i] << ' ';
3.自定义比较函数
sort默认使用小于号进行排序,如果想要自定义比较规则,
可以传入第三个参数,可以是函数或lambda表达式。
代码如下(示例):
bool cmp(const int &u, const int &v)
{
return u > v;
}
int main()
{
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
//初始化v
vector<int> v = {5, 1, 3, 9};
//对数组进行排序,降序排列
sort(v.begin(), v.end(), cmp);
//输出
for(int i = 0,i < v.size(); ++ i)
cout << v[i] <<' ';
输出: 9 5 3 1
结构体可以将小于号重载后进行排序,当然用前面的方法
也是可行的。
代码如下(示例):
struct NO
{
int u, v;
bool operator < (const No &m)const
{
//以u为第一关键字,v为第二关键字排序
return u == m.u ? v < m.v : u < m.u;
}
三、全排列
1.next permutation函数
next permutation函数用于生成当前序列的下一个排列。它按照字典序对序列进行重新排列,如果存在下一个排列,则将当前序列更改为下一个排列,并返回true;如果当前序列已经是最后一个排列,则将序列更改为第一个排列,并返回false。
代码如下(示例):
vector<int> nums = {1, 2, 3};
cout << "initial permutation: ";
for (int num : nums)
{
cout << num << " ";
}
cout << endl;
//生成下一个排列
while(next_permutation(nums.begin(), nums.end())
{
cout << "next_permutation: ";
for (int num :nums)
cout << num << " ";
{
cout << endl;
}
输出:
| 1 | 2 | 3 |
| 1 | 3 | 2 |
| 2 | 1 | 3 |
| 2 | 3 | 1 |
| 3 | 1 | 2 |
| 3 | 2 | 1 |
2.prev_permutation()函数
prev_permutation函数与next permutation 函数相反,它用于生成当前序列的上一个排列。它按照字典序对序列进行重新排列,如果存在上一个排列,则将当前序列更改为上一个排列,并返回true;如果当前序列已经是第一个排列,则将序列更改为最后一个排列,并返回false。
代码如下(示例):
vector<int> nums2 = {3, 2, 1};
cout << "initial permutation: ";
for (int num : nums2)
{
cout << num << " ";
}
cout << endl;
//生成上一个排列
while(prev_permutation(nums2.begin(), nums2.end())
{
cout << "prev_permutation: ";
for (int num : nums2)
cout << num << " ";
{
cout << endl;
}
输出:
| 3 | 2 | 1 |
| 3 | 1 | 2 |
| 2 | 1 | 3 |
| 2 | 1 | 3 |
| 1 | 3 | 2 |
| 1 | 2 | 3 |
四、最值查找
1.min和max函数
min(a,b)返回a和b中较小的那个值,只能传入两个值,或传入一个列表。例如:
min(3, 5)=3
min({1,2,3,4})=1
max(a,b)返回a和b中较大的那个值,只能传入两个值,或传入一个列表。例如:
max(7,5)=7
min({1,2, 3,4})=4
时间复杂度为O(1),传入参数为数组时时间复杂度为0(n),n为数组大小。
min,max函数是在取最值操作时最常用的操作。
2.min element和max element
min_element(st,ed)返回地址[st,ed)中最小的那个值的地址(迭代器),传入参数为两个地址或迭代器。
max_element(st,ed)返回地址[st,ed)中最大的那个值的地址(迭代器),传入参数为两个地址或迭代器。
时间复杂度均为O(n),n为数组大小(由传入的参数决定)
代码如下(示例):
//初始化v
vector <int> v = (5,1,3,9,11};
//输出最大的元素,*表示解引用,即通过地址(迭代器)得到值
cout << ( *max_element(v. begin, v.end()) << '/n';
输出:11
3.nth_element函数
nth element(st, k, ed)
进行部分排序,返回值为void()
传入参数为三个地址或迭代器。其中第二个参数位置的元素将处于正确位置,其他位置元素的顺序可能是任意的,但前面的都比它小,后面的都比它大。时间复杂度O(n)。
代码如下(示例):
//初始化
vector<int>v={5,1,7,3, 10,18, 9};
//输出最大的元素,*表示解引用,即通过地址(达代器)得到值
nth_ element(v.begin(),v.begin()+ 3,v.end());
//这里v[3]的位置将会位于排序后的位置,其他的任意
for(auto &i :v)
cout << i << " ";、
输出:3 1 5 7 9 18 10
五、大小写转换
1.islower/isupper函数
islower和isupper是C++标准库中的字符分类函数,用于检查一个字符是否为小写字母或大写字母islower和isupper函数需要包含头文件<cctype>,也可用方能头包含。函数返回值为bool类型。
代码如下(示例):
char ch1='A ';
char ch2 ='b';
//使用 islower 函数判断字符是否为小写字母
if(islower(ch1))
{
cout << ch1 << " is a lowercase letter." << endl;
}
else
{
cout << ch1 << "is not a lowercase letter." << endl;
}
//使用 isupper 函数判断字符是否为大写字母
if (isupper(ch2))
{
cout << ch2 << " is an uppercase letter."<< endl;
}
else
{
cout << ch2 << "is not an uppercase letter." << endl;
}
2.tolower/toupper函数
tolower(charch)可以将ch转换为小写字母,如果ch不是大写字母则不进
行操作。toupper()同理。
代码如下(示例):
char ch1 ='A';
char ch2= 'b';
//使用tolower 函数将字符转换为小写字母
char lowercaseCh1 = tolower(ch1);
cout << "Lowercase of " << ch1 << " is " << lowercasech1 << endl;
//使用toupper 所数将字符转换为大写字母
char uppercasech2 = toupper(ch2);
cout <<"Uppercase of "<< ch2 <<" is " << uppercasech2 << endl;
3.ascii码

在了解了ascii码后,我们可以通过直接对英文字母进行加减运算计算出其大小写的字符。
在ASCI码表中,大写字母的编码范围是65(A)到90(Z),而小写字母的编码范围是97(a”)到122(z)。根据这个规则,可以使用ASCII码表进行大小写转换。
代码如下(示例):
char ch='A';//大写字母
char convertedch;
if (ch >= 'A’ && ch <= 'z')
{
//大写字母转换为小写字母
convertedch =ch+32;
cout << "converted character: " << convertedch << endl;
}
else if (ch>='a'88 ch<= 'z')
{
// 小写字母转换为大写字母
convertedch=ch-32;
cout << "converted character: " << convertedch << endl;
}
else
{
cout << "Invalid character!" << endl;
}
六、其他库函数
1.memset()
memset()是一个用于设置内存块值的函数它的原型定义在<cstring>头文件中,
函数的声明如下:
void* memset(void* ptr,int value, size t num);
memset0)函数接受三个参数:
1.ptr:指向要设置值的内存块的指针。
2.value:要设置的值,通常是一个整数。
3.num:要设置的字节数。
memset0函数将ptr指向的内存块的前num个字节设置为value的值。它返回一个指向ptr的指针。memset0函数通常用于初始化内存块,将其设置为特定的值。例如,如果要将一个整型数组的所有元素设置为0,可以使用memset0)函数如下
int arr[10];emset(arr,0,sizeof(arr));
在上述示例中,,memset(arr,0.sizeof(arr))将数组arr的所有元素设置为0,需要注意的是,memset()函数对于非字符类型的数组可能会产生未定义行为。在处理非字符类型的数组时,更好使用C++中的其他方法,如循环遍历来视memset会将每个byte设置为value。
2.swap()
swap(T&a,T&b)函数接受两个参数:
1.a:要交换值的第一个变量的引用
2.b:要交换值的第二个变量的引用
swap()函数通过将第一个变量的值存储到临时变量中,然后将第二个变量的值赋给第一个变量,最后将临时变量的值赋给第二个变量,实现两个变量值的交换。
swap()函数可以用于交换任意类型的变量,包括基本类型(如整数、浮点数等)和自定义类型(如结构体、类对象等)。
以下是一个示例,展示如何使用swap()函数交换两个整数的值:
int a= 10;int b= 20;std::swap(a, b);
3.reverse()
reverse()是一个用于反转容器中元素顺序的函数。它的原型定义在<algorithm>头文件中,函数的声明如下
template<class BidirIt>
void reverse(BidirIt first, BidirIt last);
reverse()函数接受两个参数:
1.first:指向容器中要反转的第一个元素的迭代器。
2.last:指向容器中要反转的最后一个元素的下一个位置的迭代器
reverse()函数将[first,last)范围内的元素顺序进行反转。也就是说,它会将[first,last)范围内的元素按相反的顺序重新排列。
reverse()函数可用于反转各种类型的容器,包括数组、向量、链表等。
以下是一个示例,展示如何使用reverse()函数反转一个整型向量的元素顺序:
代码如下(示例):
#include <iostream>
#include <vectar>
#include <algorith>
int main()
{
std::vector<int> vec = {1, 2, 3, 4, 5};
std::reverse(vec.begin(), vec .end( ));
for (int num : vec)
{
std::cout << num <<" ";
}
std::cout << std::endl;
return 0;
}
在上述示例中,std::reverse(vec.begin()vec.end())将整型向量vec中的元素顺序进行反转。最终输出的结果是54321。需要注意的是,reverse()函数只能用于一"向迭代器的容器,因为它需要能够向"后遍历容器中的元素。对于只支持单器的容器(如前向链表),无法使用rev函数进行反转。
4.unique()
unique()是一个用于去除容器中相邻重复元素的函数,它的原型定义在<algorithm>头文件中,
函数的声明如下
template<class ForwardIt>
ForwardIt unique(ForwardIt first, ForwardIt last);
unique(first, last)函数接受两个参数:
1.first:指向容器中要去重的第一个元素的迭代器,
2.last:指向容器中要去重的最后元素的下一个位置的迭代器
unique()函数将[first, last)范围内的相邻重复元素去除,并返回一指向去重后范围的尾后迭代器去重后的范围中只保留了第一个出现的元素,后续重复的元素都被移除。
unique()函数可用于去除各种类型的容器中的相邻重复元素,包括数组、向量、链表等。
以下是一个示例,展示如何使用unique()函数去除一个整型向量中的相邻重复元素:
int main()
{
std::vector<int> vec = {1, 1, 2, 2, 3, 3, 3.4, 4, 5)
auto it = std::unique(vec.begin(), vec.end( ));
vec.erase(it, vec.end());
for (int num : vec)
{
std: :cout << num << " ";
std::cout << std::endl;
return 0
}
相关文章:
(蓝桥杯C/C++)——常用库函数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、 二分查找 1.二分查找的前提 2.binary_ search函数 3.lower_bound和upper_bound 二、排序 1.sort概念 2.sort的用法 3.自定义比较函数 三、全排列 1.next p…...

GPT-Sovits-2-微调模型
1. 大致步骤 上一步整理完数据集后,此步输入数据, 微调2个模型VITS和GPT,位置在 <<1-GPT-SoVITS-tts>>下的<<1B-微调训练>> 页面的两个按钮分别执行两个文件: <./GPT_SoVITS/s2_train.py> 这一步微调VITS的预训练模型…...

【数据结构 | PTA】懂蛇语
懂蛇语 在《一年一度喜剧大赛》第二季中有一部作品叫《警察和我之蛇我其谁》,其中“毒蛇帮”内部用了一种加密语言,称为“蛇语”。蛇语的规则是,在说一句话 A 时,首先提取 A 的每个字的首字母,然后把整句话替换为另一…...
Python——自动化发送邮件
在数字化时代,电子邮件是商务沟通和个人联络的重要工具。自动化邮件发送可以节省时间,提高效率。Python,作为一种强大且灵活的编程语言,提供了多种库来支持邮件的自动化发送。本文将详细介绍如何使用Python的smtplib和email库来编…...

MTKLauncher_布局页面分析
文章目录 前言遇到的困难点针对性解决困难 需求相关资料Launcher3 源码 目录简单介绍Launcher3 简介及页面布局分析UI整体架构数据加载布局加载布局加载核心思想device_profiles.xml 加载InvariantDeviceProfileinitGrid(context, gridName)getPredefinedDeviceProfilesinvDist…...
C#实现隐藏和显示任务栏
实现步骤 为了能够控制Windows任务栏,我们需要利用Windows API提供的功能。具体来说,我们会使用到user32.dll中的两个函数:FindWindow和ShowWindow。这两个函数可以帮助我们找到任务栏窗口,并对其执行显示或隐藏的操作 引入命名空…...

基于springboot+vue实现的公司财务管理系统(源码+L文+ppt)4-102
基于springbootvue实现的公司财务管理系统(源码L文ppt)4-102 摘要 本系统是基于SpringBoot框架开发的公司财务管理系统,该系统包含固定资产管理、资产申领管理、资产采购管理、员工工资管理等功能。公司财务管理系统是一种帮助公司进行有效资金管理、会…...

rnn/lstm
tip:本人比较小白,看到july大佬的文章受益匪浅,现在其文章基础上加上自己的归纳、理解,以及gpt的答疑,如果有侵权会删。 july大佬文章来源:如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博…...
袋鼠云产品功能更新报告12期|让数据资产管理更高效
本期,我们更新和优化了数据资产平台相关功能,为您提供更高效的产品能力。以下为第12期袋鼠云产品功能更新报告,请继续阅读。 一、【元数据】重点更新 |01 元数据管理优化,支持配置表生命周期 之前系统中缺少一个可以…...

MATLAB——入门知识
内容源于b站清风数学建模 目录 1.帮助文档 2.注释 3.特殊字符 4.设置MATLAB数值显示格式 4.1.临时更改 4.2.永久改 5.常用函数 6.易错点 1.帮助文档 doc sum help sum edit sum 2.注释 ctrl R/T 3.特殊字符 4.设置MATLAB数值显示格式 4.1.临时更改 format lon…...

C#从零开始学习(用户界面)(unity Lab4)
这是书本中第四个unity Lab 在这次实验中,将学习如何搭建一个开始界面 分数系统 点击球,会增加分数 public void ClickOnBall(){Score;}在OneBallBehaviour类添加下列方法 void OnMouseDown(){GameController controller Camera.main.GetComponent<GameController>();…...

Axure PR 9 多级下拉清除选择器 设计交互
大家好,我是大明同学。 Axure选择器是一种在交互设计中常用的组件,这期内容,我们来探讨Axure中选择器设计与交互技巧。 OK,这期内容正式开始 下拉列表选择输入框元件 创建选择输入框所需的元件 1.在元件库中拖出一个矩形元件。…...

分布式项目pom配置
1. 父项目打包方式为 pom <packaging>pom</packaging> 2. 父项目版本配置 <properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncod…...

2. Flink快速上手
文章目录 1. 环境准备1.1 系统环境1.2 安装配置Java 8和Scala 2.121.3 使用集成开发环境IntelliJ IDEA1.4 安装插件2. 创建项目2.1 创建工程2.1.1 创建Maven项目2.1.2 设置项目基本信息2.1.3 生成项目基本框架2.2 添加项目依赖2.2.1 添加Flink相关依赖2.2.2 添加slf4j-nop依赖2…...
Java-I/O框架06:常见字符编码、字符流抽象类
视频链接:16.16 字符流抽象类_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Tz4y1X7H7?spm_id_from333.788.videopod.episodes&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5&p16 1.常见字符编码 IOS-8859-1收录了除ASCII外,还包括西欧…...
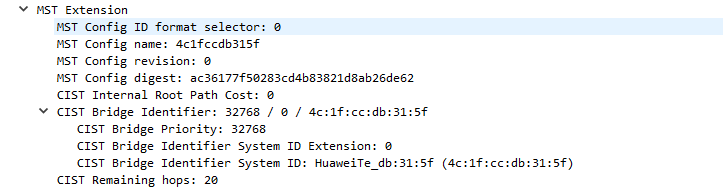
计算机网络-MSTP的基础概念
前面我们大致了解了MSTP的由来,是为了解决STP/RSTP只有一根生成树导致的VLAN流量负载分担与次优路径问题,了解MSTP采用实例映射VLAN的方式实现多实例生成树,MSTP有很多的理论概念需要知道,其实与其它的知识一样理论复杂配置还好的…...

P1037 [NOIP2002 普及组] 产生数
[NOIP2002 普及组] 产生数 题目描述 给出一个整数 n n n 和 k k k 个变换规则。 规则: 一位数可变换成另一个一位数。规则的右部不能为零。 例如: n 234 , k 2 n234,k2 n234,k2。有以下两个规则: 2 ⟶ 5 2\longrightarrow 5 2⟶5。 …...

【分布式知识】分布式对象存储组件-Minio
文章目录 什么是minio核心特点:使用场景:开发者工具:社区和支持: 核心概念什么是对象存储?MinIO 如何确定对对象的访问权限?我可以在存储桶内按文件夹结构组织对象吗?如何备份和恢复 MinIO 上的…...

跨平台开发支付组件,实现支付宝支付
效果图: custom-payment : 在生成预付订单之后页面中需要弹出一个弹层,弹层中展示的内容为支付方式(渠道),由用户选择一种支付方式进行支付。 该弹层组件是以扩展组件 uni-popup 为核心的,关于…...

API 接口:为电商行业高效发展注入强劲动力
一、动力之源:API 接口在电商中的角色剖析 在电商行业的广袤版图中,API 接口宛如一台强劲的发动机,是推动其高效发展的核心动力来源。它不再仅仅是一个技术工具,而是成为了连接电商各个环节的 “神经系统”,使得信息、…...

机器学习知识产权保护:从数据到模型的立体防御策略
1. 机器学习投资保护的核心挑战与思路 在上一篇文章中,我们探讨了机器学习(ML)项目从构思到部署过程中,知识产权(IP)保护的基本框架和初步策略。今天,我们深入到更具体、也更棘手的层面…...

基于MCP协议构建地方财政智能体:开源项目实践与开发指南
1. 项目概述:当MCP遇上地方财政,一个开源智能体的诞生最近在开源社区里,一个名为apifyforge/municipal-fiscal-intelligence-mcp的项目引起了我的注意。这个项目名听起来有点“学术”,但拆解开来,其实指向了一个非常具…...

OpenClaw Gateway智能守护者:双触发自愈与AI诊断实践
1. 项目概述:一个为OpenClaw Gateway设计的智能守护者如果你在运维一个基于OpenClaw Gateway的服务,大概率经历过这样的深夜惊魂:手机突然收到告警,提示网关服务挂了,然后你不得不从床上爬起来,摸黑打开电脑…...

手机跑多模态也能快到飞起!面壁MiniCPM-V 4.6开源
大模型技术正快步从云端机房走入普通人的智能手机,让移动设备直接处理复杂的图文与视频任务成为现实。面壁智能最新开源的一款多模态模型,以极低的算力成本,超低的首Token延迟,成功打通当前三大主流手机操作系统。MiniCPM-V 4.6专…...

基于Python的自动化数据简报生成:从模板驱动到部署实践
1. 项目概述:数据简报的自动化生成利器如果你也和我一样,每天需要从一堆数据库、日志文件和API接口里捞出数据,然后吭哧吭哧地整理成PPT或者Word报告,那你一定懂这种重复劳动的痛苦。数据本身就在那里,但把它们变成老板…...

从零构建:深入理解自治系统与BGP协议的核心机制
1. 自治系统与BGP协议的前世今生 第一次听说"自治系统"这个词时,我脑海中浮现的是科幻电影里的智能机器人。实际上,它指的是互联网中由单一组织管理的网络区域。想象一下,每个自治系统就像城市里的一个独立社区,有自己的…...

工业小白也能懂:5分钟上手Modbus Poll,像聊天一样调试你的设备
工业小白也能懂:5分钟上手Modbus Poll,像聊天一样调试你的设备 想象一下,你刚拿到一台环境监测设备,厂商告诉你它支持Modbus协议。作为软件开发者,你可能对"寄存器地址"、"功能码"这些工业术语一头…...

靠谱的工程防火门公司推荐
在工程行业摸爬滚打十几年,我见过太多因防火门翻车的项目:验收反复返工、产品用了两三年就变形卡死、超大门洞找不到厂家定制…… 这些看似鸡毛蒜皮的小事,一旦卡到消防验收节点上,轻则赔钱延期,重则被责令停工整改。今…...

DownKyi终极指南:简单快速获取B站8K超高清视频的完整解决方案
DownKyi终极指南:简单快速获取B站8K超高清视频的完整解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...

我跟踪了100位测试工程师的5年成长轨迹,发现成功者都踩准了这三个节点
五年,对于软件测试工程师而言,是一道清晰的分水岭。有人依然困在重复的手工用例里,薪资徘徊在行业均线以下;有人却完成了从执行者到架构者、从成本中心到价值中心的跃迁,成为团队里不可替代的角色。过去五年࿰…...