数据库编程 SQLITE3 Linux环境
永久存储程序数据有两种方式:
- 用文件存储
- 用数据库存储
对于多条记录的存储而言,采用文件时,插入、删除、查找的效率都会很差,为了提高这些操作的效率,有计算机科学家设计出了数据库存储方式
一、数据库
数据库的基本组成:
用来管理数据库的软件被称数据库管理系统
一个数据库管理系统管理着多个数据库
一个数据库中可以包含很多张表
一张表中拥有很多记录(行)
一条记录拥有很多字段(列)
每条记录的每个字段存放不同类型的数据
因此,数据库本质上是表的集合

数据库按数据的组织形式分为:
- 关系型数据库 ----- 本章内容
- 非关系型数据库
数据库管理系统软件按是否支持远程分为:
- 网络版 ---- MySql Oracle SQlServer
- 单机版 ---- sqlite
网络版的数据管理系统的整体框架:

数据库管理系统发展初期,各家开发此类软件的公司采用的通信协议是不同的,这给应用客户端开发造成很大的麻烦
因此,经过一段时间的发展,全球几家著名的数据库管理系统开发公司制定了统一的通信协议,这个统一的通信协议被称为SQL(Structure Query Language)
随着关系型数据库的不断发展,SQL成为所有数据库管理系统的统一协议
每个数据库管理系统都会提供一个命令行界面的简易客户端,应用程序员可以使用这个简易客户端学习、练习SQL语句以及辅助开发
每一条SQL语句就是一个操作请求
二、SQLite
一个单机版的数据库管理系统
所有操作请求也遵循SQL标准
开源、精悍
SQLite安装:
1.安装SQLite3
命令行下输入:sudo apt-get install sqlite32.安装SQLite3编译需要的工具包
命令行下输入: sudo apt-get install libsqlite3-dev如出现问题尝试:
sudo dpkg --purge --force-depends libsqlite3-0
sudo apt-get install libsqlite3-0
sudo apt-get install -f
sudo apt-get install libsqlite3-dev
sudo apt-get install sqlite3支持三种字段数据类型:
INTEGER 或 INT 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。
REAL 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。
TEXT 值是一个文本字符串,单引号或双引号括起的字符串
使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储
三、sqlite3简易客户端的使用
1. 运行
Linux>sqlite3 ------ 只是进入sqlite3的命令行界面,不创建打开任何数据库
Linux>sqlite3 路径/数据库文件名 ----- 先创建打开指定的数据库,然后进入sqlite3的命令行界面
sqlite3管理的一个数据库,在Linux系统下用一个文件表示它,习惯上将这个文件命名为 xxx.db
2. 两种命令
- . 开头的命令:简易客户端的内部命令
- 以 ; 结尾的命令:; 前的内容为SQL语句,; 是简易客户端要求的结尾符
3. 常用内部命令
创建打开一个指定的数据库
sqlite> .open 路径/xxx.db
sqlite> .help查看正在使用的数据库
sqlite> .databasesSQL语句操作结果按列对齐 ----- 重要
sqlite> .mode column 显示某表时是否显示表头 ----- 重要
sqlite> .headers on/off显示数据中的表 ------ 重要
sqlite> .tables退出sqlite命令行 ---- 重要
sqlite> .quit
四、常用SQL语句
SQL语句组成:关键字 + 运算符 + 字段名或表名 + 常量
SQL语句的关键字可以全大写、也全小写、甚至可以大小混合,一般建议采用全大写
字段名或表名的大小是区分的,aaa、Aaa、AAA认为是不同的字段名或表名,自建表建议字段名或表名全小写
1. 建表
CREATE TABLE [IF NOT EXISTS] table_name(column_name1 datatype[(size)] [PRIMARY KEY] [AUTOINCREMENT] [NOT NULL],column_name2 datatype,column_name3 datatype,.....column_nameN datatype,
);
[]:表示可选,选用时不带[]
[AUTOINCREMENT]:只能用于INTEGER 表示如果插入新记录时没有指定该字段的值,则其值为前一条记录同字段值+1
[PRIMARY KEY]:主键,唯一标识表中的记录 主键:表中每条记录的该字段值不会重复,也即该字段值可以唯一标识一条记录
[IF NOT EXISTS]:如果表不存在则建表,如果存在则什么都不做
[NOT NULL]:表示字段内容不能为空示例:
sqlite> CREATE TABLE student(id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,...> name TEXT,sex TEXT(1),score REAL); 2. 删表
DROP TABLE 表名;示例:
sqlite> CREATE TABLE ttt(xxx TEXT,yyy TEXT);
sqlite> DROP TABLE ttt;3. 插入新记录
通用:
INSERT INTO table_name(column1, column2,...columnN) VALUES(value1, value2,...valueN);不缺字段时:
INSERT INTO table_name VALUES(value1,value2,...valueN); 4. 查询记录
SELECT column1, column2, columnN FROM table_name [WHERE condition];
SELECT * FROM table_name [WHERE condition];
*表示查询结果显示所有字段
无WHERE子句则查询所有记录5. where子句
所谓子句就是不能成为独立的SQL语句,只能成为一条SQL语句的一部分WHERE子句用来为一些操作指定条件
WHERE conditioncondition可以是单个条件或由AND、OR连接的多个条件比较运算符支持:
= != > < >= <= 用法:字段名 运算符 值IN()用法:字段名 IN(值1,值2,...,值n) 表示字段值为值1或值2或....NOT IN()用法:字段名 NOT IN(值1,值2,...,值n) 表示字段值不为值1也不为值2也不为....LIKE用法:字段名 LIKE 模式字串 模式字串中可以用%号表示任意多个字符,用_表示单个字符,默认不区分大小写GLOB用法:字段名 GLOB 模式字串 模式字串中可以用*号表示任意多个字符,用?表示单个字符,区分大小写IS NOT NULL用法:字段名 IS NOT NULL 判断字段值是否为空IS NULL用法:字段名 IS NULL 判断字段值是否为空BETWEEN AND用法:字段名 BETWEEN 值1 AND 值2 字段值>=值1 且 字段值<=值2NOT反条件用法:字段名 NOT 其它条件6. 修改记录
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
无WHERE子句则对所有记录进行修改7. 删除记录
DELETE FROM table_name WHERE [condition];
无WHERE子句则删除所有记录8. Sort子句
ORDER BY 字段名 ASC 或 DESC
ASC升序
DESC降序9. SQL语句中的函数
datetime('now','localtime') ---- 产生当前日期时间的字符串使用示例:
INSERT INTO Table_name VALUES(datetime('now','localtime'));count(*) 对查询结果求记录数
使用示例:
SELECT count(*) FROM student;

五、sqlite3函数库
SQL按执行完毕后是否有记录结果分为两种:
- 一种SQL语句的执行只论是否成功。例如:建表、删表、插入记录、修改记录、删除记录
- 另一种SQL语句执行完毕产生多条记录结果。例如:查询
sqlite3_open参照图:

sqlite3_exec及其回调函数的参考图:

sqlite3_get_table函数参考图1:


//头文件包含
#include <sqlite3.h>/*链接选项-lsqlite3
*///1、打开/创建一个数据库
int sqlite3_open(const char *filename, sqlite3 **ppDb );
/*
功能:打开指定的数据库,如果数据库并存在则创建并打开指定的数据库,并创建一个后续操作该数据库的引擎
参数:filename:带路径的数据库文件名ppdb:指向sqlite句柄的指针,调用前定义一个sqlite3 *指针变量,取该指针变量的地址
返回:成功 SQLITE_OK (值为0),否则返回其他值。
*///2、如果打开数据库失败,open函数只是返回错误码,如果想要错误原因的字符串描述则调用该函数
const char *sqlite3_errmsg(sqlite3 *db);
/* 返回值:返回错误信息
*///3、回调函数执行sql语句
//更加适用于sql语句执行没有记录结果的情况(此时第3、4参数填NULL)或对需要依次对每条操作结果记录进行处理的情况
int sqlite3_exec(sqlite3* pDB, const char *sql, sqlite_callback callback, void*para, char** errMsg);/*
功能:执行SQL语句,查询的结果返回给回调函数callback,多个结果的操作,每个结果都会调用一次callback
参数:pDB:数据库引擎的句柄。sql:待执行的SQL 语句字符串,以’\0’结尾,不以';'结尾。callback:回调函数,用来处理查询结果,如果不需要回调(比如做insert 或者delete 操作时),可以置NULL。para:要传入回调函数的指针参数,没有可以置为NULL。errMsg:一级指向空间存放着一个char *类型的元素,该元素指向空间(二级指向空间)存放着一个字符串,该字符串内容描述出错原因,因此:1. 调用前定义一个char *类型的指针变量,传该指针变量的地址给该形参。2. 由于其二级指向空间是动态分配的,因此使用完后需要调用sqlite3_free函数进行释放;
返回值:执行成功返回SQLITE_OK,否则返回其他值
*///4、回调函数
typedef int (*sqlite_callback)(void* para, int columnCount, char** columnValue,char** columnName);
/*
功能:由用户处理查询的结果,每找到一条记录自动执行一次回调函数
参数:para:从sqlite3_exec()传入的参数指针;columnCount:查询到的这一条记录有多少个字段(即这条记录有多少列);columnValue:查询出来的数据都保存在这里,它实际上是个1 维数组(不要以为是2 维数组),每一个元素都是一个char * 值,是一个字段内容(用字符串来表示,以‘\0’结尾)columnName:与columnValue 是对应的,表示这个字段的字段名称。
返回值:执行成功返回SQLITE_OK,否则返回其他值
*///5、关闭
int sqlite3_close(sqlite3 *ppDb);
/*
功能:关闭sqlite数据库。
参数:ppdb:数据库句柄。
返回值:成功返回0,失败返回错误码
*///6、释放
void sqlite3_free(void * errMsg );
/*
功能:释放存放错误信息的内存空间
参数:errMsg: 返回错误信息
*///7、非回调来执行sql语句
//更加适用于SQL语句执行后有一条或多条记录结果,且程序期望对所有记录结果的整体进行处理的情况
int sqlite3_get_table(sqlite3 *db, /* An open database */const char *zSql, /* SQL to be evaluated */char ***pazResult, /* Results of the query */int *pnRow, /* Number of result rows written here */int *pnColumn, /* Number of result columns written here */char **pzErrmsg /* Error msg written here */);/*
功能:非回调来执行sql语句
参数:db:数据库句柄zSql:要执行的SQL语句pazResult:查询结果,一维数组,定义一个char **的二级指针变量,调用函数时传该二级指针变量的地址,不使用应立即调用sqlite3_free_table(result)进行释放pnRow:查询出多少条记录(查出多少行) 不包括字段名所在行pnColumn:多少个字段(查出多少列)pzErrmsg:错误信息
返回值:执行成功返回SQLITE_OK,否则返回其他值
注:pazResult的字段值是连续的,是一维数组不是二维数组,从第0索引到第 pnColumn- 1索引都是字段名称,从第 pnColumn索引开始,后面都是字段值。
*///8、释放pazResult查询结果
void sqlite3_free_table(char **pazResult);
/*参数:pazResult:指向空间存放着查询结果,指向空间为元素类型是char *的一维数组
*/示例代码:
#include <stdio.h>
#include <sqlite3.h>int handle_a_record(void *para,int cols,char **ppval,char **ppname);int main(){sqlite3 *pdb = NULL;int ret = 0;ret = sqlite3_open("./test.db",&pdb); // openif(ret != SQLITE_OK){printf("sqlite3 not open,because %s\n",sqlite3_errmsg(pdb));sqlite3_close(pdb);pdb = NULL;return 1;}{char sql[80] = "";char *perr = NULL;sprintf(sql,"SELECT * FROM stu"); // write instructionret = sqlite3_exec(pdb,sql,handle_a_record,NULL,&perr); // exec()if(ret != SQLITE_OK){ // errorprintf("exec %s failed,because %s\n",sql,perr);sqlite3_free(perr); // sqlite3_free()perr = NULL;}}{char sql[80] = "";char *perr = NULL;char **ppret = NULL;int rows = 0;int cols = 0;int i = 0;int j = 0;sprintf(sql,"SELECT * FROM stu"); // write instructionret = sqlite3_get_table(pdb,sql,&ppret,&rows,&cols,&perr); // exec()if(ret != SQLITE_OK){ // errorprintf("exec %s failed,because %s\n",sql,perr);sqlite3_free(perr); // sqlite3_free()perr = NULL;}else{for(j = 0;j < cols;j++){printf("%-20s ",*(ppret + j));}printf("\n");}for(i = 1;i <= rows;i++){for(j = 0;j < cols;j++) printf("%-20s ",*(ppret + i * cols + j));printf("\n");}sqlite3_free_table(ppret);ppret = NULL;
}sqlite3_close(pdb); // sqlite3_close()pdb = NULL;return 0;}int handle_a_record(void *para,int cols,char **ppval,char **ppname){int i = 0;for(i = 0;i < cols;i++){printf("%s | ",*(ppval + i));}printf("\n");return SQLITE_OK;
}
输出:

六、sqlite3函数库的并发模式
- 单线程模式 ----- 无锁模式
- 串行模式 ------ 默认模式,非阻塞互斥锁实现
- 读者写者模式 ------ 读写锁实现
配置sqlite3函数库的并发模式可以通过:1. 重新编译sqlite3函数库的源码 2.调用相关的接口函数进行配置
实际项目中大部分情况采用其默认模式
串行模式时,需要对sqlite3_exec、sqlite3_get_table函数进行如下形式的二次封装:
int my_sqlite3_exec(sqlite3* pdb, const char *sql, sqlite_callback callback, void*para, char** errmsg){int ret = 0; do {ret = sqlite3_exec( pdb , sql, callback , para , errmsg ); if (ret == SQLITE_BUSY || ret == SQLITE_LOCKED){usleep(30 * 1000);continue;}else{break;}} while(1); return ret;
}int my_sqlite3_get_table(sqlite3 *db, /* An open database */const char *zSql, /* SQL to be evaluated */char ***pazResult, /* Results of the query */int *pnRow, /* Number of result rows written here */int *pnColumn, /* Number of result columns written here */char **pzErrmsg /* Error msg written here */){int ret = 0;do {ret = sqlite3_get_table(db,zSql,pazResult,pnRow,pnColumn,pzErrmsg); if (ret == SQLITE_BUSY || ret == SQLITE_LOCKED){usleep(30 * 1000);continue;}else{break;}} while(1); return ret;
}七、二次封装
实际项目代码中,直接调用sqlite3函数库中的函数实现相关功能,会很不方便,往往会将项目中可能用到的所有数据库操作代码单独作为一个模块,该模块又按表分为几个子模块(一般命名为xxxhelper),由这个模块及其子模块向其它项目代码提供需要的数据库操作接口。

public子模块:不隶属于任何一个helper子模块的操作函数,归于本子模块
一般项目中建议采用如下方案:
/*一、public子模块 -------- 项目名_db_public.c*/
/*1. 函数功能:创建打开数据库,然后带IF NOT EXISTS关键字去建表*/
sqlite3 *create_db_engine(const char *pdbfile)
{1. 调用sqlite3_open2. 建表13. 建表2。。。。n+1. 建表n成功返回引擎地址,失败返回NULL
}/*2. 对sqllite3_exec的二次封装 ------ 见上一节*//*3. 对sqllite3_get_table的二次封装 ------ 见上一节*//*4. destroy_db_engine*/
void destroy_db_engine(sqlite3 *pdb)
{sqlite3_close(pdb);
}/*二、对表1的各种操作函数封装 表1名helper.c*/
int insert_new_record_into_表名(sqlite3 *pdb,.........)
{组织sql语句调用my_sqlite3_exec 或 my_sqlite3_get_table函数执行sql语句。。。。。。
}......???? xxxxx(sqlite3 *pdb,.......)
{通过多次执行sql语句组合完成本函数功能
}/*三、对表2的各种操作函数封装 表2名helper.c*/。。。。。。。。。。。。。。。相关文章:
数据库编程 SQLITE3 Linux环境
永久存储程序数据有两种方式: 用文件存储用数据库存储 对于多条记录的存储而言,采用文件时,插入、删除、查找的效率都会很差,为了提高这些操作的效率,有计算机科学家设计出了数据库存储方式 一、数据库 数据库的基本…...

独孤思维:总有一双眼睛默默观察你做副业
01 独孤昨天在陪伴群,分享了近期小白做副业的一些困扰。 并且以自己经历作为案例,分享了一些经验和方法。 最后顺势推出xx博主的关于365条赚钱信息小报童专栏。 订阅后,可以开拓副业赚钱思路,避免走一些弯路。 甚至于&#x…...

医院信息化与智能化系统(10)
医院信息化与智能化系统(10) 这里只描述对应过程,和可能遇到的问题及解决办法以及对应的参考链接,并不会直接每一步详细配置 如果你想通过文字描述或代码画流程图,可以试试PlantUML,告诉GPT你的文件结构,让他给你对应…...

基于YOLO11/v10/v8/v5深度学习的危险驾驶行为检测识别系统设计与实现【python源码+Pyqt5界面+数据集+训练代码】
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

Flink CDC系列之:学习理解核心概念——Transform
Flink CDC系列之:学习理解核心概念——Transform Transform参数元数据字段函数比较函数逻辑函数字符串函数时间函数条件函数 示例添加计算列参考元数据列使用通配符投影所有字段添加过滤规则重新分配主键重新分配分区键指定表创建配置分类映射用户定义函数已知限制 …...
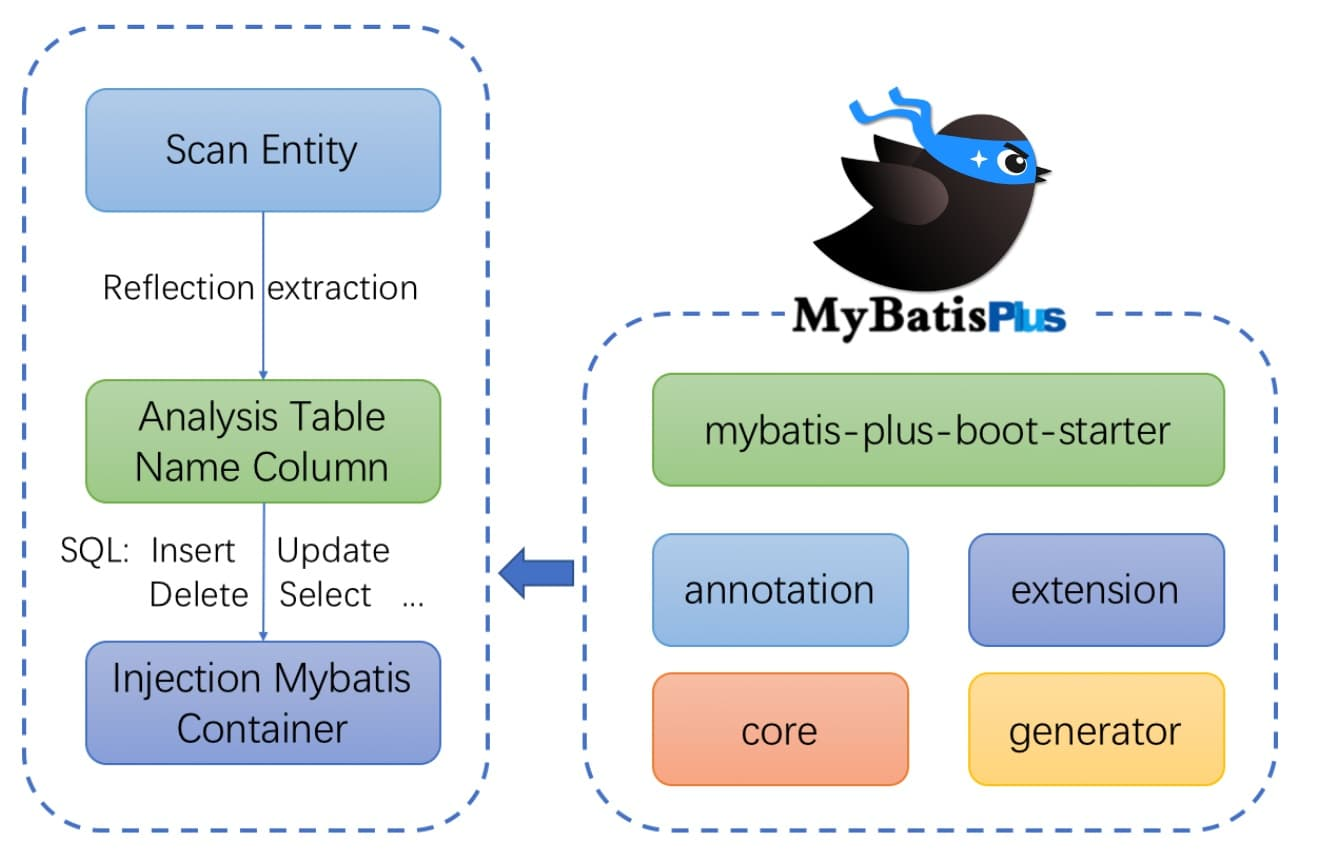
MyBatis-Plus:简化 CRUD 操作的艺术
一、关于MyBatis-Plus 1.1 简介 MyBatis-Plus 是一个基于 MyBatis 的增强工具,它旨在简化 MyBatis 的使用,提高开发效率。 关于Mybatis 简介 MyBatis 是一款流行的 Java 持久层框架,旨在简化 Java 应用程序与数…...

Windows on ARM编译安装openBLAS
Windows on ARM编译安装openBLAS 要求下载源码OpenBLAS可以使用LLVM工具链(clang-cl和flang)从源代码为Windows on ARM(WoA)进行构建。v0.3.24版本(预构建包)的构建和测试已通过。 要求 LLVM:版本需大于等于17.0.4 LLVM版本16及以下会生成冲突的符号(如_QQ*等)。 LL…...

FPGA编程语言VHDL与Verilog的比较分析!!!
VHDL(VHSIC硬件描述语言)和Verilog都是用于硬件描述和FPGA编程的工业标准语言。它们在语法和设计理念上存在一些差异,以下是两者的比较分析: 1. 历史背景 VHDL: 开发于1980年代初期,最初用于美国国防部的…...
)
C语言——八股文(笔试面试题)
1、 什么是数组指针,什么是指针数组? 数组指针:指向数组的指针 指针数组:数组中的元素都是指针 2、 什么是位段,什么是联合体 位段(Bit Field):在C语言中,允许在一个整数…...

解决 Oracle 数据库错误 ORA-12516:监听器无法找到匹配协议栈的处理程序
在使用 Oracle 数据库时,有时会遇到错误 ORA-12516,这个错误表明 Oracle 数据库的监听器无法为新的连接请求找到一个可用的处理程序,这通常是因为达到了连接数上限、配置问题或资源限制。本文将详细介绍如何解决这个问题。 一、错误描述 当…...

Flarum:简洁而强大的开源论坛软件
Flarum简介 Flarum是一款开源论坛软件,以其简洁、快速和易用性而闻名。它继承了esoTalk和FluxBB的优良传统,旨在提供一个不复杂、不臃肿的论坛体验。Flarum的核心优势在于: 快速、简单: Flarum使用PHP构建,易于部署&…...

方法+数组
1. 方法 1. 什么是方法 方法定义: // []表示可写可不写[public] [static] type name ( [type formal , type formal , ...]){方法体;[return value ;] }[修饰符] 返回值类型 方法名称([参数类型 形参 , 参数类型 形参 ...]){方法体代码;[return 返回值…...

驱动-----adc
在key1.c的基础上进行对adc1.c进行编写 首先将文件里面的key全部改为adc 再修改一下设备号 按键和adc的区别是什么,按键只需要按一下就触发了,并且不需要返回一个值出来, adc要初始化,启动,返回值 以下是裸机adc的代码: #include <s3c2440.h> #include "ad…...

js实现点击图片,使图片跟随鼠标移动(把注释打开是图片随机位置)
代码: <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Document</title>&l…...

MacOS的powermetrics命令查看macbook笔记本的耗能情况,附带查看ANE的工作情况
什么是 powermetrics? powermetrics 是 macOS 系统自带的一个命令行工具,用于收集和分析系统能源消耗数据。通过它,我们可以深入了解 Mac 的硬件性能、软件行为以及能源使用情况,从而优化系统配置,提高电池续航时间。…...

字符串函数
大家好,今天我们来了解几个字符串函数 1.strcpy函数 这个函数是一个字符串复制函数,其全称为string copy,它可以将一个源字符数组的内容复制到目标字符数组中,我们需要关注几个问题,首先源字符串必须以\0…...

Java数组的地址和元素访问 C语言空指针与野指针
1. public static void main(String[] args) {int []arr{1,2,3,4,5};int numarr[0];System.out.println(num);System.out.println(arr[1]);System.out.println(arr);//[I610f87f48//[表示地址 I表示数据类型 表示间隔符号(固定格式)//10f87f48表示地址…...

如何在Linux系统中使用SSH进行安全连接
如何在Linux系统中使用SSH进行安全连接 SSH简介 安装SSH 在Debian/Ubuntu系统中安装 在CentOS/RHEL系统中安装 启动SSH服务 验证SSH是否安装成功 SSH配置 配置监听端口 配置登录方式 SSH客户端 安装SSH客户端 使用SSH客户端 SSH密钥认证 生成SSH密钥对 复制公钥到远程服务器…...

Pandas 数据可视化指南:从散点图到面积图的全面展示
Pandas 数据可视化指南:从散点图到面积图的全面展示 本文介绍了使用 Pandas 进行数据可视化的多种方法,包括散点图、折线图、条形图、直方图、饼图和面积图等,涵盖了常见的图表类型及其实现方式。通过提供详细的代码示例,展示了如…...

Flink + Kafka 实现通用流式数据处理详解
Flink Kafka 实现通用流式数据处理详解 在大数据时代,实时数据处理和分析成为企业快速响应市场变化、提高业务效率和优化决策的关键技术。Apache Flink和Apache Kafka作为两个重要的开源项目,在数据流处理领域具有广泛的应用。本文将深入探讨Flink和Ka…...

GitHub加速终极指南:3步让你的下载速度提升10倍!
GitHub加速终极指南:3步让你的下载速度提升10倍! 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为Git…...

独立开发者如何借助taotoken模型广场低成本验证产品创意
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场低成本验证产品创意 对于资源有限的独立开发者或小型工作室而言,验证一个需要AI功…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

Taotoken官方价折扣活动对于高频用户的实际成本影响分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方价折扣活动对于高频用户的实际成本影响分析 1. 理解Taotoken的计费模式 Taotoken平台采用按Token消耗量计费的模式。…...

南京彩钢瓦屋面防水供应商
在南京,彩钢瓦屋面广泛应用于各类建筑,然而其防水问题一直是困扰众多业主的难题。选择一家靠谱的彩钢瓦屋面防水供应商至关重要。今天就为大家详细介绍雨中行修缮工程有限公司,同时也对比其他一些大厂,看看雨中行修缮为何能在市场…...
)
别再乱打包了!手把手教你用Kali Linux和Metasploit生成免杀后门(附实战演示)
Kali Linux高级免杀技术实战:从原理到绕过Windows Defender 在渗透测试和红队演练中,后门程序的免杀能力直接决定了行动的成败。许多初学者在使用Metasploit生成基础payload后,常常发现它们被主流杀毒软件轻易拦截。本文将深入探讨免杀技术的…...

C#元组类型简介
元组是 C# 7.0 引入的轻量级数据结构,用于临时组合多个值,无需定义专门的类或结构。 元组是有序的数据结构,成员按声明/创建时的顺序排列。(这里的元组只指值元组)元组类型在C#7.0前是有一个专门的内置类型,…...

AI智能体审批系统设计:从规则到价值网络的动态决策引擎
1. 项目概述:为什么AI需要“举手提问”?在AI智能体(Agent)日益深入业务流程自动化的今天,一个核心的、却常被忽视的问题浮出水面:这个拥有一定自主决策能力的“数字员工”,在什么情况下应该停下…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案
5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而头疼吗?复…...