Elasticsearch分词器基础安装
简介
Elasticsearch (ES) 是一个基于 Lucene 的搜索引擎,分词器是其核心组件之一,负责对文本数据进行分析和处理。
1. 文本分析
分词器将输入的文本拆分成一个个单独的词(tokens),以便后续的索引和搜索。例如,输入的文本 "Elasticsearch分词器" 可能会被分词器拆分为 ["Elasticsearch", "分词器"]。2. 索引优化
在将文档存储到 Elasticsearch 中之前,分词器可以去除一些不必要的字符和停用词(如“的”、“是”等),并将文本标准化(例如小写化)。这有助于减少索引的大小和提高搜索效率。3. 多语言支持
Elasticsearch 支持多种语言的分词器,例如中文分词器、英文分词器等。不同的分词器使用不同的规则和算法来处理特定语言的文本,以便提供更精确的搜索结果。4. 提升搜索质量
通过有效的分词,分词器可以提高搜索的相关性和准确性。分词器能够识别出用户查询中的关键词,并将其与索引中的词进行匹配,从而提高搜索结果的质量。5. 分析文本数据
分词器还可以用于分析文本数据的特点,比如词频统计、短语提取等。这对后续的数据挖掘和分析工作非常重要。6. 自定义分词
Elasticsearch 允许用户自定义分词器,开发者可以根据具体需求定义分词规则和过滤器,以满足特定场景的需求。7. 创建和配置索引
在创建索引时,可以指定使用的分词器。根据文档类型或应用场景的不同,可以选择不同的分词器来满足需求。
常见的分词器
Elasticsearch 提供了多种分词器(analyzers)以支持不同类型的文本分析和搜索需求。以下是一些常见的分词器:1. 标准分词器(Standard Analyzer)
这是 Elasticsearch 默认的分词器,适用于大多数语言。它会将文本分割为单词,并去除停用词(如“的”、“是”等)。2. 中文分词器
IK Analyzer:一个流行的中文分词插件,支持细粒度和粗粒度两种分词模式,适合处理中文文本。
HanLP:另一种中文分词器,支持多种自然语言处理功能,包括分词、词性标注等。3. Whitespace 分词器
将输入文本按空白字符进行分词,适合处理不需要复杂分析的情况。4. Keyword 分词器
将整个输入文本视为一个单一的词,适用于需要精确匹配的场景,如 ID 和特定标签。5. NGram 分词器
生成输入文本的 N-gram 形式,适合用于模糊搜索和自动补全功能。6. Path Hierarchy 分词器
适用于处理文件路径和层级结构数据,能够正确分词层级关系。7. Edge NGram 分词器
仅生成输入文本的前 N 个字符的 N-gram,适合用于前缀匹配的搜索场景。8. Stop Token 分词器
用于去除常见的停用词,这些词通常不会对搜索结果产生实质性影响。9. Custom Analyzer
用户可以根据需求自定义分词器,组合不同的分词和过滤器,以满足特定的分析需求。
中文分词器 ik
默认的分词器是标准分词器,它会将文本分割为单词,并去除停用词(如“的”、“是”等),在生产实际使用过程中,是不符合国内的业务的
所以我们需要引入中文分词器 ik
- IK Analyzer:一个流行的中文分词插件,支持细粒度和粗粒度两种分词模式,适合处理中文文本。
安装步骤
注意:安装的版本需要跟es的版本保持一致,我这里使用的7.3.2的
下载
- 方式一:如果需要的ik是7.3.2 ,否则可以选择其他的方式
- 公众号获取,回复
ik<font style="color:rgb(26, 27, 28);">分词器</font>

- 方式二:github下载
https://github.com/infinilabs/analysis-ik/tags
找到自己需要的版本
例如我需要下载v7.3.2

下载zip的方式
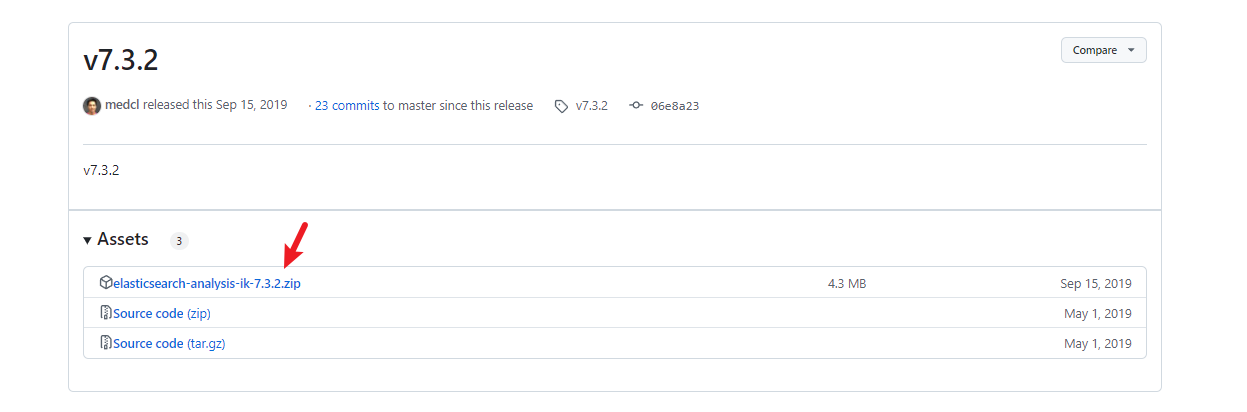
上传,解压
# 切换到es下的plugins 这里根据自己es的安装目录
cd elasticsearch-7.3.2/plugins
# 上传
rz
# 解压
unzip elasticsearch-analysis-ik-7.3.2.zip -d ik
# 删除压缩包,否则启动会报错
rm -rf elasticsearch-analysis-ik-7.3.2.zip
重启es
ps -ef|grep elasticsearch查看es的pid

- 杀死程序 kill -9 pid
- 进入es的bin目录,执行
./elasticsearch -d
分词测试
使用kibana进行查看
- 标准分词器测试
POST /_analyze
{"tokenizer": "standard", "text": "Elasticsearch分词器测试"
}
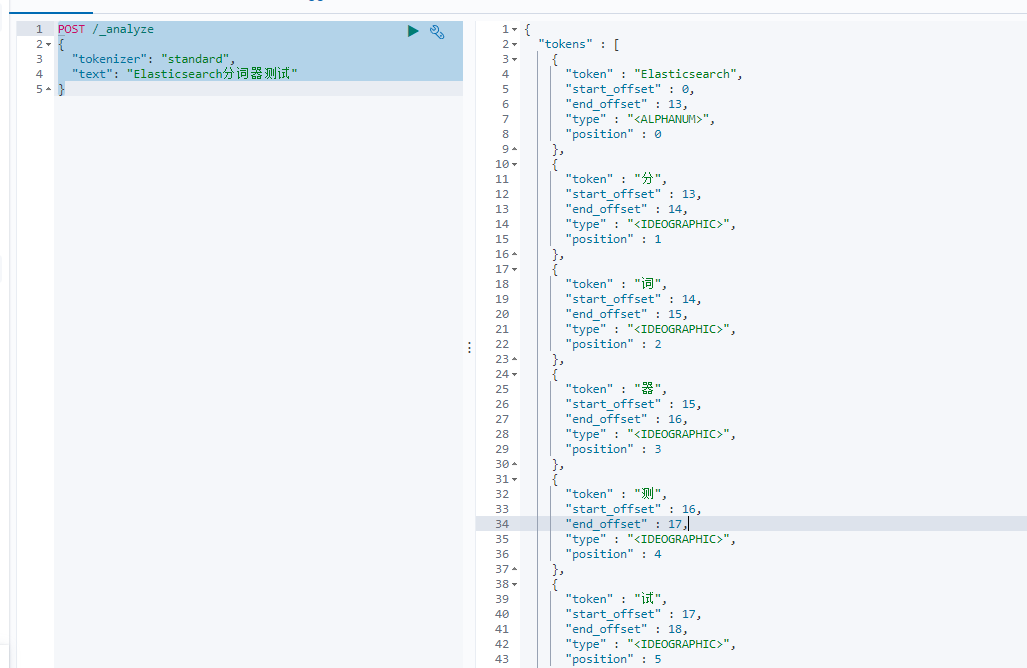
- ik分词器测试
POST /_analyze
{"tokenizer": "ik_max_word","text": "Elasticsearch分词器测试"
}
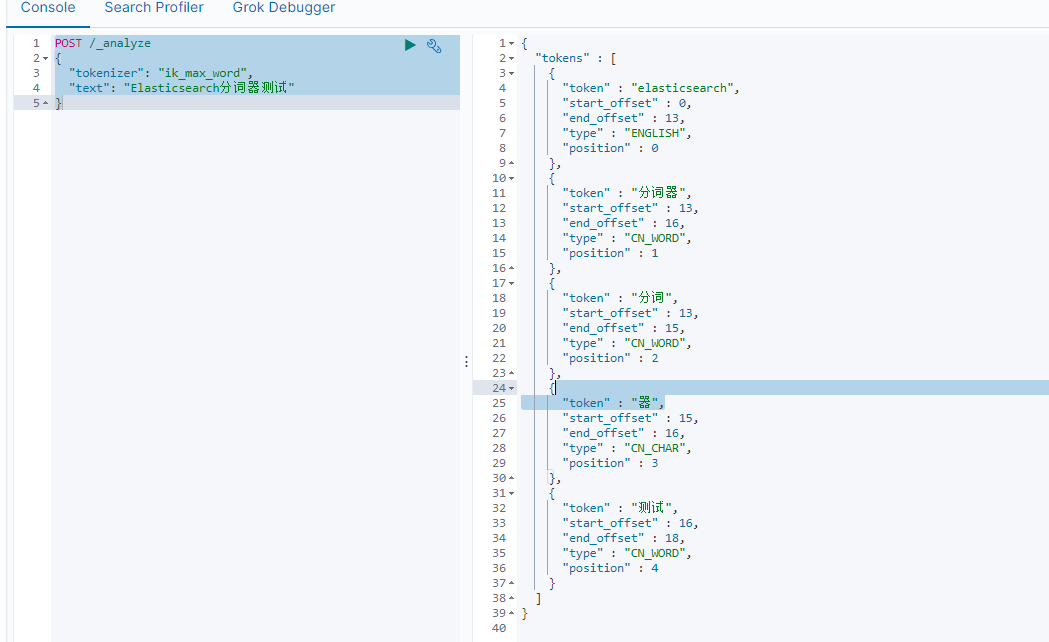
可以看出二者的区别
相关文章:
Elasticsearch分词器基础安装
简介 Elasticsearch (ES) 是一个基于 Lucene 的搜索引擎,分词器是其核心组件之一,负责对文本数据进行分析和处理。 1. 文本分析 分词器将输入的文本拆分成一个个单独的词(tokens),以便后续的索引和搜索。例如&#x…...

Django-邮件发送
邮件相关协议: SMTP(负责发送): IMAP(负责收邮件): POP3(负责收邮件): 两者区别: Django发邮件: 邮箱相关配置: settings中&…...

SchooWeb2--基于课堂学习到的知识点2
SchoolWeb2 form表单input控件中各type中value值含义 默认值 text password hidden 提交给服务器的值 select option radio属性的name含义 name值相同表示是同一组单选框中的内容 script的位置 head标签 在head中使用script可以保证在页面加载时进行加载ÿ…...

Android.mk 写法
目录放在odm/bundled_uninstall_back-app/VantronMdm/VantronMdm.apk LOCAL_PATH : $(my-dir) include $(CLEAR_VARS) LOCAL_MODULE : VantronMdm LOCAL_MODULE_CLASS : APPS LOCAL_MODULE_PATH : $(TARGET_OUT_ODM)/bundled_uninstall_back-app LOCAL_SRC_FILES : $(LOCAL_M…...

精通Javascript 函数式array.forEach的8个案例
JavaScript是当今流行语言中对函数式编程支持最好的编程语言。我们继续构建函数式编程的基础,在前文中分解介绍了帮助我们组织思维的四种方法,分别为: array.reduce方法 帮你精通JS:神奇的array.reduce方法的10个案例 array.map方…...

忘记无线网络密码的几种解决办法
排名由简单到复杂 1网线直连; 2查看密码备份文件; 3问人要密码; 4已连接无线设备生成二维码扫描即可上网; 5路由器有wps功能,设备输入pin码可上网; 6已连接电脑右键wifi名,选择属性,…...

git add你真的用明白了吗?你还在无脑git add .?进入暂存区啥意思?
git add 命令用于将文件的改动添加到暂存区(staging area),为下一次提交做好准备。简单来说,它标记了哪些文件或改动会被纳入下次 git commit 中。以下是 git add 的作用和使用场景: 1. 作用 git add 将指定文件或文…...

Vue-Route
一、相关理解 1. vue-router的理解 vue的一个插件库,专门用来实现SPA应用 2. 对SPA应用的理解 单页Web应用整个应用只有一个完整的页面点击页面中的导航链接不会刷新页面,只会做页面的局部更新数据需要通过ajax请求获取 3. 路由的理解 什么是路由 …...

字符串逆序(c语言)
错误代码 #include<stdio.h>//字符串逆序 void reverse(char arr[], int n) {int j 0;//采用中间值法//访问数组中第一个元素和最后一个元素//交换他们的值,从而完成了字符串逆序//所以这个需要临时变量for (j 0; j < n / 2; j){char temp arr[j];arr[…...
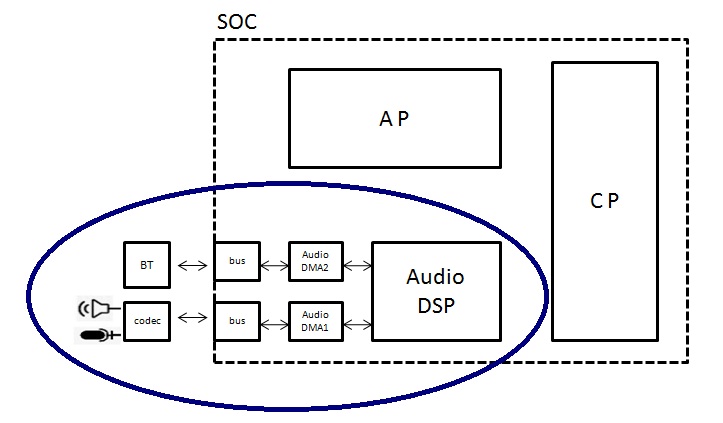
芯片上音频相关的验证
通常芯片设计公司(比如QUALCOMM)把芯片设计好后交由芯片制造商(比如台积电)去生产,俗称流片。芯片设计公司由ASIC部门负责设计芯片。ASIC设计的芯片只有经过充分的验证(这里说的验证是FPGA(现场…...
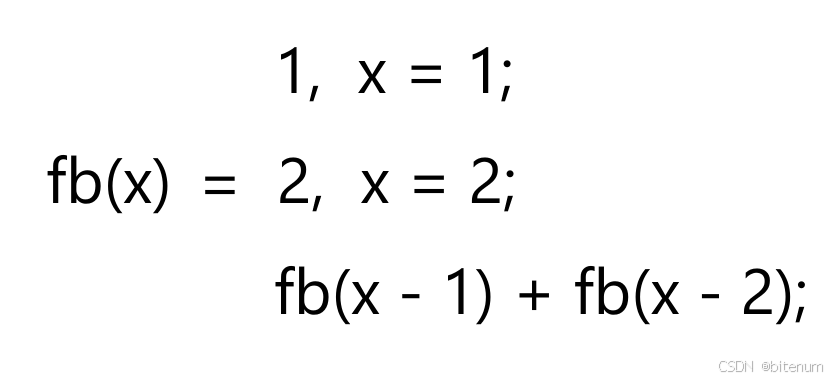
【C/C++】函数的递归
1.什么是递归? 递归就是递推和回归,以数学函数f(x) x为例: 递推:f(x) f(x - 1) 1 ; f(x - 1) f(x - 2) 1 ; f(x - 2) …… 回归:……; f(x - 2) f(x - 1) 1 ; f(x - 1) f(x) 1; 可以看出, 递推和…...

《链表篇》---两两交换链表中的节点(中等)
题目传送门 1.定义一个虚拟节点链接链表 2.定义一个当前节点指向虚拟节点 3.在当前节点的下一个节点和下下一个节点都不为null的情况下。 定义 node1和node2。保存当前节点后面两个节点的地址。cur.next node2;node1.next node2.next;node2.next node1;cur node1; 4.返回re…...

Fakelocation 步道乐跑(Root真机篇)
前言:需要 Fakelocation,真机Root,步道乐跑,Dia,MT管理器系统需求 Fakelocation | MT管理器 | Dia | 环境模块 任务一 真机Root(德尔塔,过momo,刷环境模块) 任务二 前往Dia查看包名(…...
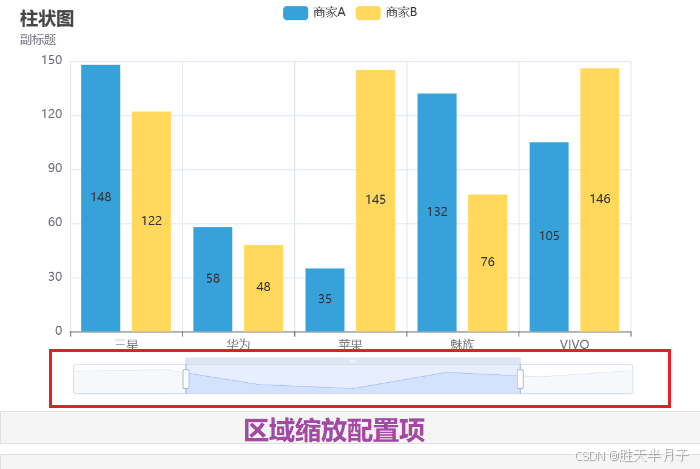
PyEcharts | 全局配置项中初始配置项和区域缩放配置项的使用
全局配置项可通过set_global_opts方法设置 一个图像主要的内容 引入包 from pyecharts.charts import Bar,Line from pyecharts import options as opts from pyecharts.faker import Faker from pyecharts.globals import ThemeType,RenderTypefrom pyecharts.globals imp…...

突破语言壁垒:Cohere 发布多语言大模型 Aya Expanse
前沿科技速递🚀 在多语言大模型领域,Cohere 再次迎来了突破!10月24日,Cohere的研究实验室 Cohere For AI 正式发布了最新的多语言AI模型家族 —— Aya Expanse。该系列模型开放了8B和32B参数两个版本,为全球AI爱好者带来了崭新的多…...

内容安全与系统构建加速,助力解决生成式AI时代的双重挑战
内容安全与系统构建加速,助力解决生成式AI时代的双重挑战 0. 前言1. PRCV 20241.1 大会简介1.2 生成式 Al 时代的内容安全与系统构建加速 2. 生成式 AI2.1 生成模型2.2 生成模型与判别模型的区别2.3 生成模型的发展 3. GAI 内容安全3.1 GAI 时代内容安全挑战3.2 图像…...

Scrapy源码解析:DownloadHandlers设计与解析
1、源码解析 代码路径:scrapy/core/downloader/__init__.py 详细代码解析,请看代码注释 """Download handlers for different schemes"""import logging from typing import TYPE_CHECKING, Any, Callable, Dict, Gener…...

shell基础-awk
awk 是一个强大的文本处理工具,广泛用于 Unix 和 Linux 系统中。它可以用来处理和分析文本文件,特别是那些包含结构化数据的文件。以下是 awk 的基础知识和一些常用示例。 基本概念 记录和字段: 记录:awk 处理的每一行文本称为一…...

@Controller 和 @RestController 区别
功能范畴: Controller:用于定义一个控制器类,主要用于处理用户请求并返回视图(通常是HTML页面)。常常与 Spring MVC 的视图解析器一起使用。RestController:是一个特殊类型的控制器,用于返回数据而不是视图…...

【数据库设计】规范设计理论之数据依赖的公理系统(1)
知道范式的几种分类之后还并不能帮助我们设计一款好的数据库,在对关系进行拆解(指模式分解)之前,我们需要引入一个理论基础让设计过程变得有迹可循和具备一定的严谨性以此来支撑数据库背后的可靠性。 Armstrong公理系统 所谓公理…...

网络出口IP管理工具ipman:原理、使用与实战指南
1. 项目概述与核心价值最近在折腾网络工具和代理配置时,发现了一个挺有意思的开源项目,叫twisker/ipman。乍一看这个名字,可能会联想到IP地址管理,但实际上,它的定位更偏向于一个轻量级的、用于在特定网络环境下管理和…...

面向对象_昂瑞微_作者观点仅供参考
C 语言面向对象编程实例解析 选自 OnMicro OM6626 BLE SDK 中的 DFU(Device Firmware Upgrade)模块。 适合有一定 C 基础、想理解"如何在 C 中实现面向对象"的初级工程师。 一、先看最终效果:调用方完全不关心底层实现 在 onmicro…...

AI编程助手My_CoPaw:从代码补全到智能协作者的架构演进
1. 项目概述:当你的代码有了“猫爪”伙伴最近在GitHub上闲逛,发现一个挺有意思的项目,叫haozhuoyuan/My_CoPaw。光看名字,CoPaw——协作的爪子,是不是立刻联想到“猫爪”(Cat‘s Paw)和“协作”…...

注意力机制新思路:拆解CoordAttention,看它如何用两个1D全局池搞定“位置+通道”信息
注意力机制新思路:拆解CoordAttention,看它如何用两个1D全局池搞定“位置通道”信息 在计算机视觉领域,注意力机制已经成为提升模型性能的关键组件。传统的通道注意力机制(如SE模块)虽然能有效建模通道间关系ÿ…...

二维码扫描模块价格解析:从几十元到上千元,如何根据应用场景选型?
1. 项目概述:解码二维码扫描模块的价格迷思每次和做硬件集成的朋友聊天,或者接到客户关于自助终端、智能门禁的咨询,总绕不开一个最实际的问题:“你们用的那个扫码模块,到底多少钱一个?” 这问题看似简单&a…...

AP的全称是什么?
AP 的全称是 Access Point。 中文常叫 无线接入点 或 无线 AP,一般指 Wi‑Fi 路由器 / 热点 里负责 让手机、笔记本、POS 等无线接入局域网 的那一部分(有时也整台设备被口语叫成 AP)。 在你们文档里 「Connect the LAN port … to an AP r…...

第11章:C++ PGO与LTO优化
第11章:C++ PGO与LTO优化 本章定位:第四卷《实战卷》第三篇"性能优化"第 11 章。 在第 10 章"找热点"和第 11 章"改代码"之后,本章讨论"什么也不改、只调编译选项"能再榨出 5%-30% 的性能:LTO 让编译器看到全程序,PGO 让它看到运…...

从设计到部署:一款面向轻量化产线的6轴关节机器人实战解析
1. 为什么轻量化产线需要6轴关节机器人 在小型工件装配场景中,传统机械臂常遇到两个致命问题:一是庞大的机身挤占产线空间,二是固定轨迹动作难以适应多变的工件姿态。去年我参与改造的一条散热器装配线就遇到过这种情况——原有直角坐标机器人…...

ARM Cortex-M0+极限性能优化:从超频到外设压榨的嵌入式实战
1. 项目概述:一次基于经典平台的极限性能探索“飞思卡尔Freedom打造新记录!”这个标题,对于很多嵌入式领域的老兵而言,瞬间就能勾起一段充满挑战与激情的回忆。飞思卡尔(Freescale,现为NXP的一部分…...

Keil MDK Debug 命令行常用命令
适用:Keil MDK-ARM (uVision5),进入 Debug 模式后,下方的 Command 窗口或 View → Command Window 打开。一、断点管理 (BKPT / BS / BL) 硬件断点 (Breakpoint Set) BS <func> ; 在函数入口设断点 BS <func&…...