Java Collection/Executor LinkedTransferQueue 总结
前言
相关系列
- 《Java & Collection & 目录》
- 《Java & Executor & 目录》
- 《Java & Collection/Executor & LinkedTransferQueue & 源码》
- 《Java & Collection/Executor & LinkedTransferQueue & 总结》
- 《Java & Collection/Executor & LinkedTransferQueue & 问题》
涉及内容
- 《Java & Collection & 总结》
- 《Java & Collection & Queue & 总结》
- 《Java & Collection/Executor & BlockingQueue & 总结》
- 《Java & Collection/Executor & SynchronousQueue & 总结》
- 《Java & Collection/Executor & TransferQueue & 总结》
- 《Java & Executor & 总结》
概述
简介
LinkedTransferQueue @ 链接迁移队列类是BlockingQueue @ 阻塞队列接口的实现类之一,也是TransferQueue @ 迁移队列接口的唯一实现类,基于链表实现。链接迁移队列类与其它阻塞队列接口实现类最大的不同在于其是阻塞队列接口的间接实现类/孙类,在原本的基础上额外实现了由迁移队列接口定义的迁移方法。迁移方法是与插入方法性质相似的操作,负责为移除方法提供可用的元素。不同的是插入方法需要剩余容量方可执行成功,而迁移方法则需要与之同步的移除方法方可执行成功,即迁移方法会同与之互补/实现的移除方法一同执行成功。因此插入方法实际直接保存的是元素(元素对应着容量,容器只有在直接保存元素时才有容量的概念),而迁移方法实际直接保存的是操作。虽然操作中会携带元素,但这属于间接保存而非直接保存。迁移方法被广泛应用于不允许元素过度生产的场景,因为在没有可用移除者的情况下,迁移者会进入等待状态。那么在线程数量有限的环境中,链接迁移队列最多只能保存与线程数量相同的迁移者,这变相等同于只能保存与线程数量相同的元素。这是一种元素的移除速率会影响元素插入速率的模型,该知识点的内容会在下文详述。
链接迁移队列类不允许存null,或者说阻塞队列接口的所有实现类都不允许存null。null被作为poll()及peek()方法表示链接迁移队列不存在元素的标记值,因此所有的阻塞队列接口实现类都不允许存null。
链接迁移队列类是真正意义上的无界队列,即容量理论上只受限于堆内存大小。链接迁移队列类在无界概念上的实现程度甚至超过了另一个真正意义上的无界队列PriorityBlockingQueue @ 优先级阻塞队列类,因为其没有[size @ 大小]来记录元素总数,这意味着其实际元素总数可以真正超过Integer.MAX_VALUE而无需像优先级阻塞队列类一样只能在元素总数触达上限时手动抛出内存溢出错误来掩盖实际实现上的限制。但这么做的代价是size()方法原本可以直接返回[大小],但如今却需要遍历整个链接迁移队列来获取元素总数。这不但使得方法的时间复杂度从O(1)变为了O(n),还导致获取的元素总数非常不准确。此外,由于size()方法的返回值依然是int类型,因此当元素总数大于Integer.MAX_VALUE时其最多也只能返回Integer.MAX_VALUE。事实上,链接迁移队列类会被设计为无界队列是为了兼容线程安全机制而做出的选择,该知识点的内容会在下文详述。
链接迁移队列类是线程安全的,或者说阻塞队列接口的所有实现类都是线程安全的,其接口定义中强制要求实现类必须线程安全。链接迁移队列类采用“无锁”线程安全机制,即使用CAS乐观锁来保证整体的线程安全。由于CAS乐观锁并不是真正意义上的锁,因此被称为“无锁”线程安全机制。由于无锁的原因,链接迁移队列类可以支持极高的并发,但也会因为CAS的高并发竞争失败而造成大量CPU资源的消耗。因此为了平衡性能与开销,链接迁移队列类采用了“懈怠”思想来辅助实现。所谓的“懈怠”思想可以理解为汇聚,即将本该每次执行的操作修改为只在达成指定条件的情况下执行,并且执行时操作范围要覆盖之前条件未达成的部分,从而减少高并发环境下的竞争问题。例如将3次加1操作汇聚为1次加3操作就是典型的懈怠场景,该知识点的内容会在下文详述。
链接迁移队列类的迭代器是弱一致性的,即可能迭代到已移除的元素或迭代不到新插入的元素。弱一致性迭代器可以有效兼容并发的使用环境,使得插入/移除方法的执行不会导致迭代的中断,该知识点的内容会在下文详述。
链接迁移队列类虽然与阻塞队列接口一样都被纳入Executor @ 执行器框架的范畴,但同时也是Collection @ 集框架的成员。
方法的不同形式
所谓方法的不同形式是指方法在保证自身核心操作不变的情况下实现多种不同的回应形式来应对不同场景下的使用要求。方法的不同形式实际上是Queue @ 队列接口的定义,阻塞队列接口拓展了该定义,而链接迁移队列类实现了该定义。例如对于插入,当容量不足时,有些场景希望在失败时抛出异常;而有些场景则希望能直接返回失败的标记值;而有些场景又希望可以等待至存在可用容量后成功新增为止…正是因为这些不同场景的存在,方法的不同形式才应运而生。方法最多可以拥有四种不同回应形式,这四种回应形式的具体设定如下:
异常 —— 队列接口定义 —— 当不满足操作条件时直接抛出异常;
特殊值 —— 队列接口定义 —— 当不满足操作条件时直接返回失败标记值。例如之所以不允许存null就是因为null被作为了操作失败时的标记值;
阻塞(无限等待) —— 阻塞队列接口定义 —— 当不满足操作条件时无限等待,直至满足操作条件后执行;
超时(有限等待) —— 阻塞队列接口定义 —— 当不满足操作条件时有限等待,如果在指定等待时间之前满足操作条件则执行;否则返回失败标记值。
与SynchronousQueue @ 同步队列类的对比
- 链接迁移队列类与同步队列类都存在迁移方法(同步队列类的迁移操作是自实现的,而不是实现自迁移队列接口),如果抛开各类方法在底层实现上的纠缠不谈,在链接迁移队列中迁移方法是一类独立于插入及移除方法的操作类型,因此其既直接保存元素也直接保存操作;而在同步队列类中迁移方法是插入方法的底层实现(实际上也是移除方法的),因此插入方法与迁移方法实际上是等价的,故而其只直接保存操作而不直接保存元素;
- 链接迁移队列类中有容量的说法,因为其即直接保存元素也直接保存操作,并且是真正意义上的无界队列;而同步队列类则没有容量的说法,因为其只直接保存操作;
- 链接迁移队列类与同步队列类都采用链表的方式实现,但链接迁移队列类只有队列一种结构的实现,而同步队列类则存在队列(公平)与堆栈(非公平)两种结构的实现;
- 链接迁移队列类与同步队列类都采用节点来保存操作,但链接迁移队列类支持数据与请求两种模式的节点共存(但实际只有一种可用),而同步队列类只能存在其中一种;
- 链接迁移队列类是非同步的,即支持多个互补/实现并发执行,并采用了懈怠机制来缓解线程间的CAS竞争;而同步队列类则是同步的,即同一时间最多只允许存在一个互补/实现。
使用
创建
-
public LinkedTransferQueue() —— 创建链接迁移队列;
-
public LinkedTransferQueue(Collection<? extends E> c) —— 创建按迭代器顺序包含指定集中所有元素的链接迁移队列。
插入
-
public boolean add(E e) —— 新增 —— 向当前链接迁移队列的尾部插入指定元素。该方法是插入方法尾部位置“异常”形式的实现,当当前链接迁移队列存在剩余容量时插入并返回true;否则抛出非法状态异常。虽说定义如此,但实际由于链接迁移队列类是真正的无界队列,最大容量只受限于堆内存的大小,故而永远不会抛出非法状态异常,而只会在堆内存不足时抛出内存溢出错误。
-
public boolean offer(E e) —— 提供 —— 向当前链接迁移队列的尾部插入指定元素。该方法是插入方法尾部位置“特殊值”形式的实现,当当前链接迁移队列存在剩余容量时插入并返回true;否则返回false。虽说定义如此,但实际由于链接迁移队列类是真正的无界队列,最大容量只受限于堆内存的大小,故而永远不会抛出非法状态异常,而只会在堆内存不足时抛出内存溢出错误。
-
public void put(E e) —— 放置 —— 向当前链接迁移队列的尾部插入指定元素。该方法是插入方法尾部位置“阻塞”形式的实现,当当前链接迁移队列存在剩余容量时插入;否则等待至存在剩余容量为止。虽说定义如此,但实际由于链接迁移队列类是真正的无界队列,最大容量只受限于堆内存的大小,故而永远不会抛出非法状态异常,而只会在堆内存不足时抛出内存溢出错误。
-
public boolean offer(E e, long timeout, TimeUnit unit) —— 提供 —— 向当前链接迁移队列的尾部插入指定元素。该方法是插入方法尾部位置“异常”形式的实现,当当前链接迁移队列存在剩余容量时插入并返回true;否则在指定等待时间内等待至存在剩余容量为止,超出指定等待时间则返回false。虽说定义如此,但实际由于链接迁移队列类是真正的无界队列,最大容量只受限于堆内存的大小,故而永远不会抛出非法状态异常,而只会在堆内存不足时抛出内存溢出错误。
迁移
-
public boolean tryTransfer(E e) —— 尝试迁移 —— 从当前链接迁移队列的头部同步移除者。该方法是迁移方法“特殊值”形式的实现,当当前链接迁移队列存在移除者时同步并返回true;否则返回false。
-
public void transfer(E e) throws InterruptedException —— 迁移 —— 从当前链接迁移队列的头部同步移除者。该方法是迁移方法“阻塞”形式的实现,当当前链接迁移队列存在移除者时同步;否则加入队尾等待至存在移除者为止。
-
public boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException —— 尝试迁移 —— 从当前链接迁移队列的头部同步移除者。该方法是迁移方法“超时”形式的实现,当当前链接迁移队列存在移除者时同步并返回true;否则加入队尾在指定等待时间内等待至存在移除者为止,超出指定等待时间则返回false。
移除
- public E remove() —— 移除 —— 从当前链接迁移队列的头部移除元素/同步迁移者并返回移除/携带元素。该方法是移除方法头部位置“异常”形式的实现,当当前链接迁移队列存在元素/迁移者时移除/同步并返回头元素;否则抛出无如此元素异常。
链接迁移队列并没有自实现remove()方法,而是直接使用了父类AbstractQueue @ 抽象队列抽象类的实现。在实现中其调用了头部移除方法“特殊值”形式的poll()方法来达成目的,使得所有抽象队列抽象类的子类只需实现poll()方法后就可以正常调用remove()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/*** Retrieves and removes the head of this queue. This method differs from {@link #poll poll} only in that it throws an exception if this queue is empty.* 检索并移除队列的头。该方法不同于poll()方法,如果队列为空时其会抛出一个异常。* <p>* This implementation returns the result of <tt>poll</tt> unless the queue is empty.* 除非队列为空,否则该实现返回poll()的结果。** @return the head of this queue 队列的头(元素)* @throws NoSuchElementException if this queue is empty* 无元素异常:如果队列为空*/
public E remove() {// 调用poll()方法获取元素。E x = poll();if (x != null)// 如果元素存在,直接返回。return x;else// 如果元素不存在,抛出无元素异常。throw new NoSuchElementException();
}
-
public E poll() —— 轮询 —— 从当前链接迁移队列的头部移除元素/同步迁移者并返回移除/携带元素。该方法是移除方法头部位置“特殊值”形式的实现,当当前链接迁移队列存在元素/迁移者时移除/同步并返回头元素;否则返回null。
-
public E take() throws InterruptedException —— 拿取 —— 从当前链接迁移队列的头部移除元素/同步迁移者并返回移除/携带元素。该方法是移除方法头部位置“阻塞”形式的实现,当当前链接迁移队列存在元素/迁移者时移除/同步并返回头元素;否则加入队尾等待至存在元素/迁移者为止。
-
public E poll(long timeout, TimeUnit unit) throws InterruptedException —— 轮询 —— 从当前链接迁移队列的头部移除元素/同步迁移者并返回移除/携带元素。该方法是移除方法头部位置“超时”形式的实现,当当前链接迁移队列存在元素/迁移者时移除/同步并返回头元素;否则加入队尾在指定等待时间内等待至存在元素/迁移者为止,超出指定等待时间则返回null。
-
public boolean remove(Object o) —— 移除 —— 从当前链接迁移队列的中按迭代器顺序移除首个指定元素(包括迁移者中携带的元素)。该方法是移除方法头内部位置的实现,成功则返回true;否则返回false。
由于指定元素可能处于任意位置(不一定是头/尾),因此被称为内部移除。内部移除并不是常用的方法:一是其不符合FIFO的数据操作方式;二是各类实现为了提高性能可能会使用各种优化策略,而remove(Object o)方法往往无法适配这些策略,导致性能较/极差。 -
public void clear() —— 清理 —— 从当前数组阻塞队列中移除所有元素(包括迁移者中携带的元素)。
检查
- public E element() —— 元素 —— 从当前链接迁移队列的头部获取元素(包括迁移者中携带的元素)。该方法是检查方法头部位置“异常”形式的实现,当当前链接迁移队列存在元素/迁移者时返回头元素;否则抛出无如此元素异常。
数组阻塞队列并没有自实现element()方法,而是直接使用了父类抽象队列抽象类的实现。在实现中其调用了头部检查方法“特殊值”形式的peek()方法来达成目的,使得所有抽象队列抽象类的子类只需实现peek()方法后就可以正常调用element()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/*** Retrieves, but does not remove, the head of this queue. This method differs from {@link #peek peek} only in that it throws an exception if this* queue is empty.* 检索,但不移除队列的头(元素)。该方法不同于peek()方法,如果队列为空时其会抛出一个异常。* <p>* This implementation returns the result of <tt>peek</tt> unless the queue is empty.* 除非队列为空,否则该实现返回peek()的结果。** @return the head of this queue 队列的头(元素)* @throws NoSuchElementException if this queue is empty* 无元素异常:如果队列为空* @Description: 元素:用于返回队列的头元素(但不移除)。当队列中不存在元素时抛出无元素异常。*/
public E element() {E x = peek();if (x != null)return x;elsethrow new NoSuchElementException();
}
- public E peek() —— 窥视 —— 从当前链接迁移队列的头部获取元素(包括迁移者中携带的元素)。该方法是检查方法头部位置“特殊值”形式的实现,当当前链接迁移队列存在元素/迁移者时返回头元素;否则返回null。
流失
-
public int drainTo(Collection<? super E> c) —— 流失 —— 将当前链接迁移队列中的所有元素(包括迁移者中携带的元素)流失到指定集中,并返回流失的元素总数。被流失的元素将不再存在于当前链接迁移队列中。
-
public int drainTo(Collection<? super E> c, int maxElements) —— 流失 —— 将当前链接迁移队列中最多指定数量的元素(包括迁移者中携带的元素)流失到指定集中,并返回流失的元素总数。被流失的元素不再存在于当前链接迁移队列中。
查询
-
public int size() —— 大小 —— 获取当前链接迁移队列的元素总数。如果超过Integer.MAX_VALUE则返回Integer.MAX_VALUE。
由于没有[大小],方法必须通过遍历整个链接迁移队列来统计元素总数,故而时间复杂度从O(1)变为了O(n),从性能的角度来说并不理想。最主要的是因为并发的原因,方法获取到的元素总数往往并不准确,因此不建议将该方法的调用结果作为判断依据使用。* -
public boolean isEmpty() —— 是否为空 —— 判断当前链接迁移队列是否为空,是则返回true;否则返回false。
-
public int remainingCapacity() —— 剩余容量 —— 获取当前链接迁移队列的剩余容量。由于链接迁移队列是无界队列,因此该方法会永远返回Integer.MAX_VALUE。
-
public Object[] toArray() —— 转化数组 —— 获取按迭代器顺序包含当前链接迁移队列中所有元素的新数组(包括迁移者中携带的元素)。
-
public <T> T[] toArray(T[] a) —— 转化数组 —— 获取按迭代器顺序包含当前链接迁移队列中所有元素(包括迁移者中携带的元素)的泛型数组。如果参数泛型数组长度足以容纳所有元素,则令之承载所有元素后返回。并且如果参数泛型数组的长度大于当前链接迁移队列的元素总数,则将已承载所有元素的参数泛型数组的size索引位置设置为null,表示从当前链接迁移队列中承载的元素到此为止。当然,该方案只对不允许保存null元素的集有效。如果参数泛型数组的长度不足以承载所有元素,则重分配一个相同泛型且长度与当前链接迁移队列元素总数相同的新泛型数组以承载所有元素后返回。
-
public boolean hasWaitingConsumer() —— 有等待中的消费者 —— 判断当前链接迁移队列中是否存在移除者,是则返回true;否则返回false;
-
public int getWaitingConsumerCount() —— 获取等待中的消费者总数 —— 获取当前链接迁移队列中的移除者总数。由于int类型最大值的限制,该方法最大返回Integer.MAX_VALUE,意味着当前链接迁移队列中至少存在Integer.MAX_VALUE个移除者。
迭代器
- public Iterator iterator() —— 迭代器 —— 创建可遍历当前链接迁移队列中元素的迭代器。
事实上,上文中只列举了大部分常用方法。由于链接迁移队列类是集接口的实现类,因此其也实现了其定义的所有方法,例如contains(Object o)、removeAll(Collection<?> c)、containsAll(Collection<?> c)等。但由于这些方法的执行效率不高,并且与链接迁移队列类的主流使用方式并不兼容/兼容性差,因此通常是不推荐使用的,有兴趣的童鞋可以去查看源码实现。
实现

元素的保存/移除
链接迁移队列类基于链表实现,而想要实现链接迁移队列类必须先明确元素的保存/移除方式。问题的产生源于链接迁移队列类是迁移队列接口的实现类,相比于普通阻塞队列接口实现类而言其多出了迁移这类元素来源。迁移方法虽说直接保存的是操作,但操作本身会间接携带元素。之前已经说过,迁移方法等待的是移除者而非剩余容量,那么这两类来源的元素该如何保存,保存后又该如何移除就成为必须要解决的首要问题。
链接迁移队列类使用单链表统一保存所有元素,该方案一次性解决了两个问题:元素被统一保存,亦可被统一移除。为了实现统一保存,链接迁移队列类的节点类被设计为可直接保存操作的形式,因为为了使迁移方法可以发现等待中的移除者(或使移除方法可以发现等待中的迁移者)必须将各类操作封装使之可视化。其次相比直接保存元素,操作需要保存的数据更多。除了必要的元素外,还需保存线程(线程是最重要的,是区别当前节点直接保存的是元素还是操作的标记,当然,实际情况会更复杂一些)、类型、是否互补/实现以及是否取消等等。简而言之,是直接保存元素数据的超集。因此被设计用来直接保存操作的节点类也可直接保存元素,即只为节点中与元素相关的字段赋值,这是链接迁移队列类专为迁移方法所做出的兼容性处理。
当链接迁移队列没有等待中的移除者/迁移者时,当前迁移者/移除者会被封装为节点加入链接迁移队列中,以供后续到达的移除者/迁移者发现。由于操作类型的不同,链接迁移队列的节点会被分为两种:一是DATA @ 数据节点,对应插入及迁移方法;二是REQUEST @ 请求节点,对应移除方法。
继元素的保存/移除问题后,链接迁移队列类还必须解决容量检测问题。链接迁移队列类支持直接保存元素,因此其存在容量概念,而所谓容量检测问题即是指如何获取准确的元素总数/剩余容量,并在后续流程中作为可靠的判断依据。事实上,该问题是无法解决的。因为在基于乐观锁的线程安全机制下,获取容量相关准确数据虽然可行,但想作为可靠判断依据却不现实。因为在缺少悲观锁提供稳定环境的情况下,容量相关数据每时每刻都可能变化,因此即使是准确数据也会在获取的瞬间变得不可靠,这也是链接迁移队列类没有大小字段的根本原因。因为即使将之设置为AtomicInteger @ 原子整数类型来保证准确性,也无法避免其后续变化,反而会影响执行性能。容量检测问题未解决的直接影响是插入方法无法实现,因为链接迁移队列在无法判定自身是否已满(即剩余容量是否为0)的情况下自然也无法执行插入、抛出异常、返回特殊值以及有限/无限等待等操作,因此将链接迁移队列类设计为无界队列实际上也是无奈之举。链接迁移队列类只有在成为无界队列的情况下才无需在意容量检测问题,因为其永远都会存在剩余容量,也就意味着插入方法永远都会成功,除非JVM抛出OOM。
懈怠
链接迁移队列类在实现中采用了“懈怠”思想,在不明白懈怠具体含义的情况下可能很难彻底理解链接迁移队列类的部分实现,因此此处进行详细说明。
采用“懈怠”思想的目的是为了缓解由于采用乐观锁而可能导致产生的高竞争平衡性能与开销。所谓的“懈怠”思想可以理解为汇聚,即将本该每次执行的操作修改为只在达成指定条件的情况下执行,并且执行时操作范围会覆盖之前条件未达成的部分,从而减少高并发环境下的竞争问题。例如将3次加1操作汇聚为1次加3操作就是典型的懈怠场景。
链接迁移队列类中主要有两处性质相似的操作采用了“懈怠”思想:一是只有当头部已实现节点积累到指定量后才会被以节点链的形式从链接迁移队列的头部批量移除,以避免[头节点]的频繁更新;二是只有当尾部追加节点积累到指定量后才会将最新追加的节点设置为新尾节点,以避免[尾节点]的频繁更新。这也是导致尾节点和最后节点概念不同的原因之一,但根本原因还是并发。
链接迁移队列类将目标懈怠值设置为2,意味着上述两种情况下只有当节点积累总数 >= 时才会触发更新头/尾节点。按源码中注释的说法:最佳目标懈怠值实际上是通过经验主义得来的,即虽然经过测试确定该值可在性能与开销之间达到最佳平衡,但无法阐明其具体缘由。大佬们发现,在一系列平台上,使用1 ~ 3范围内的常数效果最好。更大的值会增加缓存不命中的成本及长遍历(即需要遍历更多的懈怠节点才能找到目标节点)的开销,并且对GC也会造成一定阻碍,而更小的值会则增加CAS的竞争和开销。
互补/实现
在了解了基本存储结构与“懈怠”思想后,接下来讲述具体的方法实现。事实上,插入/移除/迁移三类方法的实现是通用的,即调用的是同一底层方法。该方法在运行流程上被分为互补/实现、节点追加及线程自旋/等待三个步骤。根据传参的不同,底层方法会执行部分或全部步骤,已达到不同方法不同形式的效果。
互补/实现步骤是三步骤中的第一步骤,也是必然会被执行的步骤,其核心是以链接迁移队列头节点为起点找到首个与当前操作相反模式的未实现节点并与之互补/实现。以移除者为例,其会从链接迁移队列头节点开始向后遍历,直至找到首个未实现数据节点。如果未实现数据节点不存在,其会将自身封装为请求节点加入链接迁移队列尾部以供后续到达的插入者/迁移者发现。这属于节点追加步骤的详细内容,此处暂且不谈;而如果未实现数据节点存在,则移除者会与之进行互补/实现。互补/实现的本质是将当前操作所携带的元素与未实现节点的元素进行互换,由于移除者不携带元素,因此其会从未实现数据节点获得元素以供返回。而未实现数据节点的元素则因为“移除”而为null,使得其变为已实现数据节点。链接迁移队列类并没有设计专有字段/标记位记录节点是否互补/实现,而是根据节点的元素与模式综合判断。如果数据节点的元素为null,则说明其已被互补/实现。同理:如果请求节点元素不为null,则说明其已被互补/实现。
已实现节点可能会被人为/非人为保留在链接迁移队列中,这也是寻找首个未实现节点需要从头节点向后遍历而非直接获取头节点的原因。互补/实现结束后,未实现节点虽然成为已实现节点,但还依然存在于链接迁移队列中,因此理论上应该将之头部移除以促使其被GC回收,但实际情况是已实现节点可能会被人为/非人为的保留。其中非人为是由于无锁并发的原因,无法保证互补/实现与头部移除的原子性;而人为原因则分为具体两种:一是由于“懈怠”思想,头部移除并不会次次执行,只会在已实现节点的保留数量满足目标懈怠值的情况下执行;二是如果已实现节点是最后节点的话,则即使满足目标懈怠值也会被强制保留。这是因为最后节点被作用于追加新节点,移除可能会因为并发导致新节点被一同移除的线程安全问题。
已实现节点会在其保留数量满足目标懈怠值的情况下以节点链的形式被批量移除。在满足目标懈怠值的情况下,节点被互补/实现后会触发头部移除,即通过CAS将当前已实现节点的后继节点(如果已实现节点是最后节点的话,会将自身设置为新头节点,即上文的强制保留)设置为新头节点。但是因为并发的原因,更新头节点的CAS可能失败,这意味着有其它线程成功将其已实现节点的后继节点(或自身)设置为了头节点。这种情况下会在当前最新头节点的基础上以2为单位距离前进来更新头节点,直至更新成功或已实现节点的保留数量少于目标懈怠值为止。头节点更新成功后,理论上还需要断开已实现节点与新头节点的链接,即将当前已实现节点的后继引用设置为自身。自引用是一步非常绝妙的操作,其不但相当于以节点链的形式批量移除包含当前已实现节点在内的之前所有未头部移除的已实现节点,还可以将头部移除的已实现节点与后继引用为null的最后节点区分开来,更可以作为避免迭代/遍历中断的标记。当在遍历中发现某节点为自引用时,说明其已被并发头部移除。此时为了避免中断,程序会跳转至链接迁移队列的头节点继续向后遍历,这是所有遍历的共性,后续将不再提及。
但令人奇怪的是,链接迁移队列类并没有按上文所说将当前触发头部移除的已实现节点断开链接,而是将旧头节点断开链接。该行为使得节点链被分割为了前/后两段,其中前段因为与链接迁移队列在物理层面上断开链接而被称为垃圾链;而后段由于依然与链接迁移队列相连,只是单纯在逻辑层面上断开链接而被称为外链。虽然外链/垃圾链本质上并不会对GC造成根本性影响,即相关节点最终都会被GC所回收,但外链的存在依然使得行为变得扑朔迷离起来…为何不直接将触发头部移除的已实现节点断开链接呢?这么做分明可以避免外链的产生…关于该问题个人有以下两个方面的猜想,希望知道具体答案的童鞋能够不吝赐教。
- 当触发头部移除的已实现节点为最后节点时会被强制保留,此时其不允许被断开链接。但如果为了避免外链而选择将之前驱节点断开链接的话则需要通过遍历进行定位,这会对性能造成影响,因此选择旧头节点断开链接是基于兼容与性能两方面考量后的选择;
- 越位于前方的节点意味着存活越久,即其存在于老年代的概率就越大,断开链接有助于避免其与新生代节点形成跨带引用。

无论已实现节点是否会触发头部移除,其内部线程都会被当前操作线程唤醒。该行为只对直接保存操作的节点执行,因为直接保存元素的节点不会保存线程,因此自然也就没有唤醒的说法。虽然已实现节点中的线程未必是等待状态,但唤醒一定会执行。执行后当前操作线程与被唤醒线程会各自返回,意味着两个操作都已彻底执行完毕。
节点追加
当当前操作在互补/实现步骤未找到相反模式未实现节点的情况下,会跳转至运行流程第二步骤:节点追加。节点追加步骤顾名思义,即将当前元素/操作封装为相应节点追加至链接迁移队列的尾部以供后续相反操作发现并互补/实现,是实现操作可视化的重要一步。节点追加步骤整体的流程并不复杂(实际上每个步骤都不复杂,只是并发实在是太烦人了…),但依然有值得讲解的点。
节点追加步骤并不是必定执行的步骤。以迁移/移除方法的“特殊值”形式为例,如果在互补/实现步骤未找到相反模式的未实现节点,则会直接返回而不是进行节点追加,这是其方法形式所规定的行为。但插入方法的“特殊值”形式实现则并非如此,在未找到相反模式未实现节点的情况下,其理论上还要判断是否存在剩余容量以决定是否进行节点追加。由于无界队列不可能出现没有剩余容量的情况,因此对于插入方法而言节点追加是必然会执行的步骤。
由于并发/懈怠的原因,尾节点与最后节点未必相同,因此为了找到真正的最后节点以追加新节点,需在尾节点的基础上向后遍历,直至找到后继引用为null的最后节点为止。最后节点找到之后并不能直接追加节点,由于并发原因我们需要判断最后节点是否是相反模式的未实现节点,是则说明有线程成功并发追加了相反模式的新节点,当前操作需跳转至互补/实现步骤重新执行;否则通过CAS将新节点追加为最后节点的后继节点。在这一步判断中,如果找到的最后节点是相反模式的已实现节点,也不会影响新节点的追加。因为这并不会导致链接迁移队列中存在两种模式的未实现节点,所以在链接迁移队列中同时存在两种模式的节点是可能的,这种节点模式的转变被称为“阶段性变化”。故而如果在遍历过程中发现某种模式的未实现节点,则必然不存在相反模式的未实现节点,可以视情况直接停止遍历。例如在互补/实现步骤中我们要寻找未实现的数据节点,如果在遍历过程中发现了未实现请求节点,则说明必然不存在未实现数据节点,可以直接停止遍历。
当追加节点数量满足目标懈怠值时会触发更新尾节点,即当尾节点后的节点数量大于等于2时会将最新追加的节点设置为尾节点。与更新头节点相似,如果由于并发的原因导致CAS失败,意味着有其它线程成功将其追加的节点设置为了尾节点。这种情况下会在当前最新尾节点的基础上以2为单位前进来更新尾节点,直至更新成功或尾节点后的节点数量少于2为止。
线程自旋/等待
节点追加步骤执行成功后会跳转至第三步骤,同时也是最后步骤:线程自旋/等待。该步骤的核心是令未实现节点的线程进入等待状态,直至未实现节点被互补/实现或取消(中断/超时)为止。
与节点追加步骤相同,线程自旋/等待步骤并不是必定执行的步骤。已知的是第三步骤是针对线程执行的操作,因此直接保存元素的插入方法不会执行该步骤。而对于直接保存操作的迁移/移除方法而言,则视具体的形式而定。例如“异常”与“特殊值”形式的实现是不会执行的,但“阻塞”与“超时”形式的实现则会执行。
令线程进入等待状态的目的是为了节省CPU资源。但需要知道的是,Java线程是1:1模型的实现,线程状态切换依赖底层操作系统完成,是成本非常高昂的操作。试想,如果线程进入等待状态没多久就因为未实现节点被互补/实现而唤醒,那此次线程等待/唤醒的性价比是非常低的,完全可以执行某些“无意义操作”消磨这段时间以避免这两次线程状态切换。虽然“无意义操作”可能会浪费少量CPU资源,但相比两次线程状态切换的开销就显得微不足道了,而自旋就是这样的“无意义操作”。
自旋的本质是循环,是在多核处理器下避免线程进入等待状态的一种手段。令线程陷入无限循环,直至达成条件后跳出,从而避免线程状态的改变,这就是自旋的本质。而之所以强调在多核处理器中,是因为单核处理器永远只有一条线程在工作,意味着线程永远都不可能跳出自旋循环,就例如移除者在自旋中永远无法等待到插入者/迁移者,因为整个物理机都没有第二条线程可以执行插入/迁移。因此自旋只可能发生在多核处理器中,包括其它采用了自旋的类、程序及计算机语言等。
在线程自旋/等待步骤中,如果当前是多核处理器,则链接迁移队列会令位于前部的未实现操作节点(即直接保存操作的节点)的线程在等待之前先自旋,因为位于前部的未实现操作节点有相当大的概率被快速互补/实现。为了实现这一点,链接迁移队列令节点线程循环判断未实现操作节点是否已被互补/实现或已取消(中断/超时),是则说明节点线程成功通过自旋避免了自身进入等待状态,并完成了相关操作。当然,自旋不可能永远持续下去,因为相反模式操作到来的时间无法预估,无限/过多的循环终究会使得自旋消耗的CPU资源超过线程等待/唤醒的消耗,因此自旋的次数会被限制,当次数耗尽后线程会进入等待状态。根据前部环境的不同,节点追加成功后设定自旋次数的具体规则如下:
- 节点与前驱节点的模式不同,即阶段性变化节点(前驱节点必然已互补/实现或取消) —— 节点是首个未实现节点 —— 128 + 64 = 192;
- 节点与前驱节点的模式相同,且前驱节点已互补/实现或取消 —— 节点是首个未实现节点 —— 128;
- 节点与前驱节点的模式相同,且前驱节点未互补/实现或取消,并正在自旋或是元素节点 —— 节点不是首个未实现节点,但大概率位于前部(因为前驱节点尚未自旋结束) —— 64。
线程在自旋期间,每次循环都会通过ThreadLocalRandom @ 线程本地随机类获取一个0 ~ 128随机数,当随机数为0时线程会短暂放弃CPU资源,个人猜测可能是为了避免线程饥饿(即部分线程长时间难以获取CPU资源)的情况。而当所有自旋次数耗尽,而未实现操作节点并没有被互补/实现或取消时,便会进入无限/有限的等待状态(阻塞/超时形式),直至因为信号/中断/超时而恢复运行。在进入等待状态之前,操作节点会将执行线程保存下来,用于在互补/实现中被相反模式操作唤醒使用(同时也是判断线程是否进入等待状态标记)。如果线程被唤醒而恢复运行,会主动遗忘节点中的元素及线程,有助于后续节点被GC回收;而如果线程因为超时/中断而恢复执行,则意味着节点被取消,需执行取消节点的内部移除,该知识点会在下文详解。
第三步骤的结束意味着整个运行流程的结束,也基本意味着整体操作执行结束。在最后,给出源码中操作对三步骤执行情况的标记位设定:
NOW @ 现在 @ 0:跳过节点追加与线程自旋/等待两个步骤,只执行互补/实现步骤;
SYNC @ 同步 @ 1 :跳过线程自旋/等待步骤,只执行互补/实现及节点追加两个步骤;
ASYNC @ 异步 @ 2:完整执行互补/实现、节点追加及线程自旋/等待三个步骤,且在线程自旋/等待步骤中当自旋结束后会无限等待;
TIMED @ 定时 @ 3:完整执行互补/实现、节点追加及线程自旋/等待三个步骤,且在线程自旋/等待步骤中当自旋结束后会有限等待。
取消节点与内部移除
取消节点是指线程等待超时或被中断的节点,因此取消节点必然是操作节点。节点取消的标记是元素自引用,即元素值为节点自身。
在线程自旋/等待步骤中,如果节点线程等待超时或被中断,则会将节点元素自引用以表示取消,并触发内部移除。从正常的流程来说,内部移除取消节点是非常简单的。首先将节点中保存的元素及线程都置null以辅助GC,随后调用与内部移除方法remove(Object o)相同的底层逻辑,即将取消节点的前驱节点与后继节点建立链接,这样就相当于将取消节点从链接迁移队列中内部移除了。并且内部移除并不会断开取消节点的后继引用(即会形成外链),这是为了实现迭代器的弱一致性。但事实是在并发环境下,一切简单的操作都变的不再简单。在上述操作中,有两种情况会导致取消节点遗留在链接迁移队列中:
- 取消节点是最后节点,为了避免并发导致新节点被一同移除,取消节点会被强制遗留在链接迁移队列中;
- 取消节点的前驱节点也被内部移除,这种情况下前前驱节点就会持有取消节点的后继引用。如此就导致前驱节点和前前驱节点同时持有取消节点的后继引用,虽然后续会将前驱节点链接节点的后继节点,但由于前前驱节点依然指向节点,因此取消节点会遗留在链接迁移队列中。

事实上,上述两种情况是比较少见的,很难造成大量的取消节点遗留,但也确实可能造成该情况。例如在相反模式操作迟迟不来而链接迁移队列中又存在大量短定时节点的情况下…
既然确实存在导致大量取消节点遗留的情况,则必须进行特别处理。最常规的做法是当可能发生节点遗留时遍历整个链接迁移队列进行清理(由于“懈怠”思想、并发安全等原因,清理范围不包含头/最后节点),但这么做的后果是性能的大量损失。为了避免/缓解这一点,链接迁移队列会在节点被取消时通过判断其前驱节点是否互补/实现及取消的方式判断取消节点是否可能被遗留。并在可能发生取消节点遗留的情况下积累[sweepVotes @ 清理选票],只有当[清理选票]的数量达到指定数量(32)时才会遍历清理,从而将“遗留”取消节点很好的控制在相对较低的数量。而实际情况则更加喜人,因为[清理选票]的积累只是意味着可能,并不代表取消节点一定被遗留了;其次由于链接迁移队列的不断运行,早期遗留的取消节点可能早已被头部移除了。因此实际遗留在链接迁移队列中的取消节点数量往往远远小于[清理选票]的数量。由于使用的是相同的清理逻辑,因此“节点遗留”问题在remove(Object o)方法中也会发生。remove(Object o)方法在内部移除指定元素前会先将相应节点强制互补/实现,以避免在内部移除的过程中受到相反模式操作的互补/实现并发影响。这也是为何在判断取消节点是否可能被遗留时需判断前驱节点是否被互补/实现的原因,因为这互补/实现可能是因为remove(Object o)方法而产生的。
除此以外,在判断可能发生取消节点遗留的前提下,有两种情况可以无需积累[清理选票]:一是前驱节点被断开链接,这意味着前驱节点已被头部移除而非内部移除,也意味着取消节点遗留的情况不会发生,因为发生场景已被破坏;二是取消节点被断开链接,该情况下无论取消节点是否曾经发生遗留,其也已经从链接迁移队列中脱离了,自然也就无需积累[清理选票]。
弱一致性迭代器
链接迁移队列类自身实现了弱一致性的迭代器。所谓弱一致性,即数据最终会达成一致,但可能存在延迟。具体表现为迭代器可能迭代到已移除的元素或迭代不到新插入的元素。大致表现如下:

迭代器之所以可以实现弱一致性有两个原因:一是迭代器提前保存了下个迭代节点/元素的快照,因此即使下次迭代时节点/元素已从链接迁移队列中移除,迭代器也依然可以返回元素,从而实现弱一致性。而如果迭代器已判断下个迭代节点/元素为null,则即使插入了新元素,也无法被迭代到。但这么做的影响是可能导致移除节点/元素在迭代器中长期保留,使得已移除节点/元素无法被GC回收。问题的关键在于这种保留在时间上是难以预测的,即可能是短期、长期、甚至是永久保存。这完全取决于迭代器的迭代频率,而频率又与具体的业务相关。频率高就是短期,低就是长期,不调用就是永久。事实上,该问题是所有弱一致性迭代器的共性。但所幸的是发生该问题的概率不高,并且也只会导致少许对象被延迟回收或浪费少量存储空间,因此并不会产生较大的负面影响。二是哪怕节点已从链接迁移队列中内部移除,也不会断开其后继引用。这就使得保存在迭代器中的节点快照无论是否内部移除都可以找到其在链接迁移队列中的后继节点(如果有多个连续的节点都被移除,则会一直向后遍历,直到找到首个处于链接迁移队列中的后继节点为止…或遍历结束)从而继续向后迭代。如此一来,弱一致性的迭代器便完成了。
频繁的老年代GC
关于头部移除,目的是为了辅助GC,那么是什么原因导致GC困难呢?答案是频繁的老年代GC。
如果头部移除不断开后继引用,则由于不断的头部移除,会在链接迁移队列外形成一条长长的外链,并与最终与头节点相连。示例如下:

这看起来似乎不是什么太大的事情…甚至可能算不上事情。不就是有一些没用的节点残留么?等着GC慢慢回收不就好了。事实上也确实如此,Java的GC太过智能,以至于我们往往/从来不会考虑这方面的执行过程。但实际上虽然无需亲自执行回收,但开发者仍有义务保证GC准确高效的执行。在上面的情况中存在这样一种场景:外链中存在部分节点存活于老年代,并与后继存活于新生代的节点相连,造成跨带引用的现象。示例如下:

跨带引用是非常难处理的。在跨带引用中,为了回收被引用的新生代对象,必须要先执行老年代对象的回收。老年代的Major GC本身就是不频繁的(因为老年代的对象存活周期一般都比较长),并且执行速度也远比新生代的Minor GC慢得多(有资料说至少有10倍以上的差距),因此在实际开发中要时刻注意避免。在当前场景中,为了回收外链中处于新生代的空节点,必须先触发老年代的Major GC。这本质上不算太过严重的问题,一次跨带引用并不会对程序带来多少影响…但问题的关键在于程序在不断的运行,每时每刻都有新元素被插入,同样也不断会有元素被移除。这就意味着外链会重复的形成,从而频繁地导致跨带引用及老年代GC。正是因为该原因,所以将头部移除节点设置为自引用是必须的。
自引用有两大作用:一是头部移除的节点链长度大幅缩短,并不再持有内链的引用,大幅降低了跨带引用出现的可能(毕竟头部移除还是节点链,因此依然存在跨带引用的可能,但概率会很小);二是其可以作为迭代器的标记使用。当迭代器迭代时发现保存在迭代器中的节点是自引用时,就说明该节点已被头部移除了,故而会直接跳跃至头节点继续向后遍历以找到首个未实现节点。
上述操作虽然精妙,但遗憾的是并不能对调用remove(Object o)方法移除的节点使用,即该类节点依然要保持原本的后继引用。这是因为该类移除可能在链接迁移队列的任意位置发生,其首个存在于链接迁移队列的后继节点并不一定是链接迁移队列的首个未实现节点,故而不可以采用该方案,也意味着remove(Object o)方法是存在引发跨带引用的隐患的…但由于remove(Object o)方法本身在开发中就较少且不推荐使用…并且想要连续的移除还是有一定难度的…因此总体来说并不会有太大影响。还有一点需要注意的是:由于迭代器的迭代移除方法remove()使用的也是内部移除,因此也可能发生“节点遗留”问题。
相关文章:
Java Collection/Executor LinkedTransferQueue 总结
前言 相关系列 《Java & Collection & 目录》《Java & Executor & 目录》《Java & Collection/Executor & LinkedTransferQueue & 源码》《Java & Collection/Executor & LinkedTransferQueue & 总结》《Java & Collection/Execu…...

阿拉伯国家本地化测试的特点
针对阿拉伯国家的应用程序的本地化测试需要详细了解语言、文化背景、地区规范和技术细节,以符合阿拉伯语用户的期望。这些国家包括沙特阿拉伯、阿拉伯联合酋长国、科威特、卡塔尔、巴林和阿曼,具有独特的语言和文化因素,成功地本地化测试解决…...

申请前必知!关于「美国绿卡」的28个常见问题汇总!
01 美国绿卡的类别 美国绿卡分为多个类别,如亲属移民、职业移民、投资移民等。每个类别有不同的申请要求和优先级。选择最适合自己的类别,并深入了解相关法律和政策,是成功申请的第一步。 02 移民路径选择 根据个人情况(如职业…...

2024年十款超好用的图纸防泄密软件精选,十款优秀的图纸防泄密软件推荐
在当今竞争激烈的商业环境中,图纸作为企业的核心资产和智慧结晶,其安全性至关重要。一旦图纸泄露,可能会给企业带来巨大的经济损失和竞争劣势。因此,选择一款可靠的图纸防泄密软件成为了企业保护知识产权的关键。下面为大家推荐十…...

数据库锁机制
数据库锁机制 数据库锁主要分为三大类 1.全局锁 2.表级锁 3.行级锁 全局锁 定义:全局锁是对整个数据库实例加锁,禁止所有对数据库的写操作。 用途:主要用于备份和维护操作。 示例 MySQL FLUSH TABLES WITH READ LOCK;这条命令会锁定所…...

呼叫中心系统如何选型?
呼叫中心系统如何选型? 作者:开源呼叫中心系统 FreeIPCC 采购一套呼叫中心系统是企业提升客户服务质量、优化运营流程、增强市场竞争力的关键步骤。一个合适的呼叫中心系统不仅能提升客户满意度,还能提高内部团队的工作效率,降低…...
Ubuntu 22.04安装部署
一、部署环境 表 1‑1 环境服务版本号系统Ubuntu22.04 server lts运行环境1JDK1.8前端WEBNginx1.8数据库postgresqlpostgresql13postgis3.1pgrouting3.1消息队列rabbitmq3.X(3.0以上)运行环境2erlang23.3.3.1 二、安装系统 2.1安装 1.安装方式,选第一条。 2.选择…...
KINGBASE部署
环境:x86_64 系统:centos7.9 数据库–版本:KingbaseES_V008R006C008B0014_Lin64_install 授权文件–版本:V008R006-license-企业版-90天 一 前置要求 1.1. 硬件环境要求 KingbaseES支持通用X86_64、龙芯、飞腾、鲲鹏等国产C…...

探索 ONLYOFFICE:开源办公套件的魅力
文章目录 引言一、ONLYOFFICE 产品介绍与历史1.1 ONLUOFFICE 介绍1.2 ONLYOFFICE发展历史 二、ONLYOFFICE 的核心功能2.1 文档处理2.2 演示文稿 三、ONLYOFFICE 部署与安装四、ONLYOFFICE 产品优势和挑战五、ONLYOFFICE 案例分析六、ONLYOFFICE 的未来发展七、全文总结 引言 在…...

如何保护网站安全
1. 使用 Web 应用防火墙(WAF) 功能:WAF 可以实时检测和阻止 SQL 注入、跨站脚本(XSS)、文件包含等常见攻击。它通过分析 HTTP 流量来过滤恶意请求。 推荐:可以使用像 雷池社区版这样的 WAF,它提…...
抖音矩阵系统开发的技术框架解析,支持OEM
一、引言 随着短视频平台的兴起,抖音已成为全球范围内极具影响力的社交娱乐应用。对于企业和创作者而言,构建抖音矩阵系统可以实现多账号管理、内容分发与优化、数据分析等功能,从而提升品牌影响力和内容传播效果。本文将详细探讨抖音矩阵系统…...

python偏相关分析
偏相关分析含义 偏相关分析是一种用于测量两个变量之间关系的统计方法,它可以控制(排除)其他变量的影响。与简单的相关分析不同,偏相关分析可以帮助我们了解在控制某些干扰因素后,两个变量之间的“净”关系。比如&…...

低代码用户中心:简化开发,提升效率的新时代
随着数字化转型的加速,企业对于快速交付高质量应用的需求日益增长。在这个背景下,低代码开发平台应运而生,成为越来越多企业和开发者的首选工具。今天,我们将聚焦于低代码用户中心,探讨其如何帮助开发者简化流程、提升…...

ThingsBoard规则链节点:Math Function节点详解
引言 1. Math Function 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 数据预处理 3.2 阈值判断 3.3 复杂计算 3.4 动态阈值 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台,…...

echarts地图,柱状图,折线图实战
1.地图 <template><div style"height: 100%;" class"cantainerBox"><div class"top"><div class"leftTop"><span class"firstSpan">推广进度</span><div>省份选择:&l…...

客服宝快捷回复软件:客服工作的得力助手
在从事客服工作的这段漫长时间里,响应率和满意度一直是我最为头疼的绩效指标。这两个指标就如同两座大山,压得我时常喘不过气来。 然而,幸运的是,最近我安装了客服宝这个快捷回复软件,这一举措如同为我打开了一扇新的…...
laravel: Breeze 和 Blade, 登录 注册等
composer require laravel/breeze --dev php artisan breeze:install php artisan migrate npm install npm run build php artisan route:clear http://laravel-dev.cn/ http://laravel-dev.cn/register http://laravel-dev.cn/login...
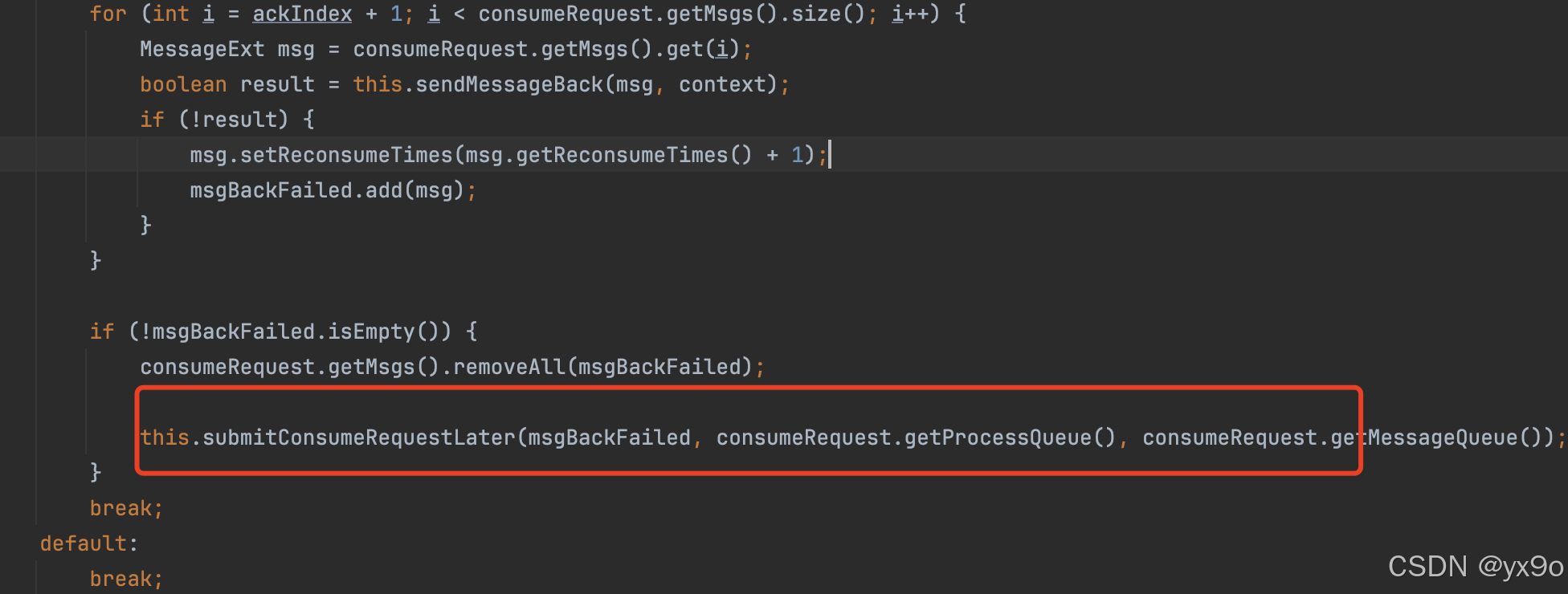
RocketMQ 消息消费失败的处理机制
在分布式消息系统中,处理消费失败的消息是非常关键的一环。 RocketMQ 提供了一套完整的消息消费失败处理机制,下面我将简要介绍一下其处理逻辑。 截图代码版本:4.9.8 步骤1 当消息消费失败时,RocketMQ会发送一个code为36的请求到…...
三、Java并发 Java 线程池 ( Thread Pool )
一、前言 本文我们将讲解 Java 中的线程池 ( Thread Pool ),从 Java 标准库中的线程池的不同实现开始,到 Google 开发的 Guava 库的前世今生 注:本章节涉及到很多前几个章节中阐述的知识点。我们希望你是按照顺序阅读下来的,不然…...
zabbix安装配置与使用
zabbix Zabbix的工作原理如下: 监控部分: Zabbix Agent安装在各个需要监控的主机上,它以主配置的时间间隔(默认60s)收集主机各项指标数据,如CPU占用率、内存使用情况等。 通讯部分: Agent会把收集的数据通过安全通道(默认10051端口)发送到Zabbix Server。Server会存储这些数…...

避坑指南:PyCharm 2023.3 + Anaconda 虚拟环境配置,绕开‘解释器路径选择界面消失’的陷阱
PyCharm 2023.3与Anaconda虚拟环境深度配置指南:从原理到实战避坑 在数据科学和机器学习项目的开发过程中,PyCharm与Anaconda的组合堪称黄金搭档。然而,当PyCharm 2023.3遇到Anaconda虚拟环境配置时,不少开发者会陷入"解释器…...

FPGA资源吃紧?看Artix7-35T如何“精打细算”实现MIPI视频解码与HDMI输出
Artix7-35T极限优化:在资源受限FPGA上实现MIPI-HDMI全流程处理 当医疗内窥镜或工业检测设备需要嵌入式图像处理时,工程师们常常面临一个残酷的现实:既要实现复杂的MIPI视频处理流水线,又不得不使用Artix7-35T这类入门级FPGA。这颗…...

OpenAnolis峰会技术干货:从内核优化到云原生实战与开源参与
1. 项目概述:一场不容错过的技术盛宴如果你是一名长期耕耘在操作系统、云计算或基础软件领域的开发者或技术决策者,那么“2022全球开源峰会OpenAnolis分论坛”这个标题,对你而言绝不仅仅是一场普通的线上或线下会议通知。它更像是一份来自技术…...

Microblaze软核处理器在SRAM型FPGA中的抗单粒子效应高可靠加固方案
1. 项目概述:为什么要在太空里“加固”一个软核处理器?在工业自动化、医疗影像或者汽车电子领域,你或许听说过Xilinx FPGA里的Microblaze软核处理器。它就像一个可以随心所欲“捏”出来的32位或64位CPU大脑,开发者能根据项目需求&…...
)
为什么92%的DeepSeek RAG Pipeline在迭代3轮后崩溃?真相藏在这份DRY反模式检查清单里(附Git Hooks自动拦截脚本)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG Pipeline崩溃现象与DRY原则失效全景图 DeepSeek RAG Pipeline在高并发检索与动态文档更新场景下频繁出现不可恢复的worker panic,典型表现为embedding向量化阶段goroutine泄漏、向量数…...

为什么你的DeepSeek在GCP延迟飙高2000ms?揭秘GPU实例选型、CUDA版本与A100/A100-80GB混部的底层冲突
更多请点击: https://codechina.net 第一章:DeepSeek GCP部署指南 在Google Cloud Platform上部署DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)需兼顾计算性能、存储效率与网络低延迟。本指南基于GCP最新稳定API&…...

AD画完板子别急着下单!5分钟搞定DRC规则检查,避开这些坑才能顺利发嘉立创
AD设计必看:DRC规则检查深度解析与实战避坑指南 在PCB设计领域,完成布线只是成功的一半。许多工程师在AD(Altium Designer)中精心设计完电路板后,常常因为忽略DRC(Design Rule Check)检查而遭遇生产返工、延迟甚至完全报废的惨痛经历。本文将…...

Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成
Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成 【免费下载链接】komanda The IRC Client For Developers 项目地址: https://gitcode.com/gh_mirrors/ko/komanda Komanda作为一款面向开发者的IRC客户端,提供了强大的代码嵌入功能&…...

G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器
G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expe…...

CXPatcher:让Mac上的CrossOver性能飞升的终极指南
CXPatcher:让Mac上的CrossOver性能飞升的终极指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾经在Mac上尝试运行Windows游戏时感到…...