点云聚类学习 KMeans/DBSCAN
点云聚类学习--KMeans/DBSCAN
- Overview
- KMeans
- DBSCAN
- 简单对比
Overview
最近做的东西会处理一些Lidar的点云数据,虽然之前在看Autoware的时候有了解一些聚类的基本原理和实现,但还是稍微再学习一下聚类方法吧,这里就简单记录一下(大部分都是参考wiki),然后做个简单实现看一下两种方法具体有什么区别
KMeans
参考wiki,k-means clustering源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。 其实简单来说在Lidar点云场景下,k-means就是把n个点云分成了k个聚类里去。其总体思路如下:

在具体的算法实践中,常见的k-means算法其实也是一种迭代的算法,还是参考wiki,其具体的算法流程为:

这个算法流程还是挺好理解的,其实就是根据距离把点分给最近的聚类中心,然后再更新聚类中心再分配再更新,最后达到收敛就是完成了。 那这里也就引出了另一个问题,其实我们是没有最初的初始聚类中心的,所以初始化步骤也是k-means聚类中的重要一步。通常使用的初始化方法有Forgy和随机划分(Random Partition)方法 。Forgy方法随机地从数据集中选择k个观测作为初始的均值点;而随机划分方法则随机地为每一观测指定聚类,然后运行“更新(Update)”步骤,即计算随机分配的各聚类的图心,作为初始的均值点。Forgy方法易于使得初始均值点散开,随机划分方法则把均值点都放到靠近数据集中心的地方。
最后来看一下简单实现,我这里实现的其实是一维的,也就是根据其中一个方向坐标进行的聚类,如果是3D的话其实就是初始化以及迭代的时候距离的更新需要改一下,还是很简单的,这里用到的就是随机划分的初始化方法
// Initialize centroidsdouble min_val = *std::min_element(data.begin(), data.end());double max_val = *std::max_element(data.begin(), data.end());for (int i = 0; i < k; ++i){centroids[i] = min_val + (max_val - min_val) * i / (k - 1);}
然后直接迭代就行了
for (int iter = 0; iter < max_iterations; ++iter){std::vector<std::vector<double>> clusters(k);// Assign points to the nearest centroidfor (const auto& point : data){int closest_centroid = 0;double min_distance = std::abs(point - centroids[0]);for (int j = 1; j < k; ++j){double distance = std::abs(point - centroids[j]);if (distance < min_distance){min_distance = distance;closest_centroid = j;}}clusters[closest_centroid].push_back(point);}// Update centroidsbool centroids_changed = false;for (int i = 0; i < k; ++i){if (!clusters[i].empty()){double new_centroid = std::accumulate(clusters[i].begin(), clusters[i].end(), 0.0) / clusters[i].size();if (std::abs(new_centroid - centroids[i]) > 1e-6){centroids[i] = new_centroid;centroids_changed = true;}}}if (!centroids_changed){break;}}
最后来看一下效果,可以看到整体效果还是不错的,把点云进一步地细分了,但是因为我这里用的是1D的聚类,所以在一些距离比较远当坐标有交集的时候不可避免地产生了误聚类的现象

DBSCAN
DBSCAN也是一种聚类方法,还是参考wiki,DBSCAN算法是以密度为本的:给定某空间里的一个点集合,这算法能把附近的点分成一组(有很多相邻点的点),并标记出位于低密度区域的局外点(最接近它的点也十分远)。 这个方法相比k-means算法复杂多了,首先所有的点被分成了三类:核心点可达点和局外点

如果 p 是核心点,则它与所有由它可达的点(包括核心点和非核心点)形成一个聚类,每个聚类拥有最少一个核心点,非核心点也可以是聚类的一部分,但它是在聚类的“边缘”位置,因为它不能达至更多的点。具体可以参考下面这个图

在这幅图里,minPts = 4,点 A 和其他红色点是核心点,因为它们的 ε-邻域(图中红色圆圈)里包含最少 4 个点(包括自己),由于它们之间相互相可达,它们形成了一个聚类。点 B 和点 C 不是核心点,但它们可由 A 经其他核心点可达,所以也属于同一个聚类。点 N 是局外点,它既不是核心点,又不由其他点可达。
所以DBSCAN算法的话,核心有两个参数,一个是选的范围的大小,另一个就是minPts这个值,它由一个任意未被访问的点开始,然后探索这个点的 ε-邻域,如果 ε-邻域里有足够的点,则建立一个新的聚类,否则这个点被标签为杂音。注意这个点之后可能被发现在其它点的 ε-邻域里,而该 ε-邻域可能有足够的点,届时这个点会被加入该聚类中。
如果一个点位于一个聚类的密集区域里,它的 ε-邻域里的点也属于该聚类,当这些新的点被加进聚类后,如果它(们)也在密集区域里,它(们)的 ε-邻域里的点也会被加进聚类里。这个过程将一直重复,直至不能再加进更多的点为止,这样,一个密度连结的聚类被完整地找出来。然后,一个未曾被访问的点将被探索,从而发现一个新的聚类或杂音。其伪代码流程如下:

当然DBSCAN由于相对复杂一些,所以我这里就没有自己去实现了,我是直接利用了PCL库来实现DBSCAN功能
std::vector<std::vector<Eigen::Vector3d>> LidarPreProcess::performDBSCANClustering(const std::vector<Eigen::Vector3d>& points, double clusterTolerance, int minClusterSize, int maxClusterSize)
{pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);cloud->points.reserve(points.size());for (const auto& point : points){cloud->points.emplace_back(point.x(), point.y(), point.z());}cloud->width = cloud->points.size();cloud->height = 1;cloud->is_dense = true;pcl::search::KdTree<pcl::PointXYZ>::Ptr tree(new pcl::search::KdTree<pcl::PointXYZ>);tree->setInputCloud(cloud);std::vector<pcl::PointIndices> cluster_indices;pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;ec.setClusterTolerance(clusterTolerance);ec.setMinClusterSize(minClusterSize);ec.setMaxClusterSize(maxClusterSize);ec.setSearchMethod(tree);ec.setInputCloud(cloud);ec.extract(cluster_indices);std::vector<std::vector<Eigen::Vector3d>> clusters;for (const auto& indices : cluster_indices){std::vector<Eigen::Vector3d> cluster;for (int index : indices.indices){cluster.push_back(points[index]);}clusters.push_back(cluster);}return clusters;
}
这里就不放这个效果图了,大概的对比在下一节用文字描述一下
简单对比
其实把两个流程大概梳理一下,能发现第一个不同就是:k-means在使用的时候是需要指定聚类数的,而DBSCAN是没有这个需求的, 而且理论上,DBSCAN对那种非线性的点云处理效果应该是更好一些的,不过我这里因为点云在其中一个轴有更好地一种分布特性,用了DBSCAN之后反而会把一整根线分成多段(大概率也是我参数设置的不好),在我的应用场景中,效果应该是单轴k-means > DBSCAN >>> k-means,所以最后实际的应用中,去结合点云的一些实际分布特性适当调整方法就可以了。
本文仅作个人简单学习记录,如有错误之处还烦请指正。
相关文章:
点云聚类学习 KMeans/DBSCAN
点云聚类学习--KMeans/DBSCAN OverviewKMeansDBSCAN简单对比 Overview 最近做的东西会处理一些Lidar的点云数据,虽然之前在看Autoware的时候有了解一些聚类的基本原理和实现,但还是稍微再学习一下聚类方法吧,这里就简单记录一下(…...

反悔贪心
Problem - C - Codeforces(初识反悔贪心) 题目: 思路: 代码: #include <bits/stdc.h> #define fi first #define se secondusing namespace std; typedef pair<int,int> PII;string a, b, ans; bool vis…...

汽车软件融合分析
随着汽车智能化、互联化的不断发展,软件在汽车中的重要性日益彰显。从硬件定义汽车,到软件定义汽车,再到AI定义汽车,汽车产业的变革正在加速进行。在这一变革中,软件融合成为了一个重要的趋势。本文将从多个角度对汽车…...

机器人和智能的进化速度远超预期-ROS-AI-
危机 通常,有危险也有机遇才称之为危机。 从2020年启动转型自救,到2021年发现危险迫在眉睫,直到2024年也没有找到自己满意的出路。 共识 中产阶级知识分子共有的特性和一致的推断。 200年前的推断,在如今得到了验证。 机器人…...

5天学习RAG路线图,你信吗?
RAG是"Retrieval Augmented Generation"的缩写,让我们来拆解这个术语,了解RAG的本质: R -> Retrieval(检索) A -> Augmented(增强) G -> Generation(生成&…...

JIME智创:抖音创作者的AI绘画与视频生成创作神器
在短视频和社交内容创作的时代,创意和速度成了成功的关键。无论是视频博主、图文创作者还是品牌推广人,他们都面临着如何快速生成高质量图片与视频素材的挑战。JIME智创正是针对这一需求推出的AI创作工具,专为抖音的图文和视频创作者设计&…...

基于SpringBoot和PostGIS的世界各国邻国可视化实践
目录 前言 一、空间数据查询基础 1、空间数据库基础 2、空间相邻查询 二、SpringBoot后台功能设计 1、后台查询接口的实现 2、业务接口设计 三、Leaflet进行WebGIS开发 1、整体结构介绍 2、相邻国家展示可视化 四、成果展示 1、印度及其邻国 2、乌克兰及其邻国 3、…...

Halcon相机外参自理解
外参描述了相机在世界坐标系中的位置和朝向,即它将世界坐标转换为相机坐标的几何变换。具体来说,外参包括一个 旋转矩阵 R R R 和一个 平移向量 t t t,它们共同构成了将世界坐标变换到相机坐标系的刚体变换 相机标定的Pose0代表了相机在外界…...

C#语言入门:从基础到进阶
C#(发音为"C sharp")是微软公司推出的一种面向对象的编程语言,它由Anders Hejlsberg和他的团队在.NET框架下开发。C#语言结合了C和Java的特性,并添加了新的功能,使其成为当今最流行的编程语言之一。 C#的特…...

网络爬虫的定义
网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页)开始,读取网页…...

一个月调研分析标的“英伟达”
放在现在依然成立 一、移动网兴起至今的最佳股票与人工智能时代的目标 9 年移动网兴起至今,若选一只股票长期持有,最佳解是 ARM(涨了 20 倍),因为无论系统层和应用层谁胜出,底层一定是芯片,而…...

Spring Boot 与 EasyExcel 携手:复杂 Excel 表格高效导入导出实战
数据的并行导出与压缩下载:EasyExcel:实现大规模数据的并行导出与压缩下载 构建高效排队导出:解决多人同时导出Excel导致的服务器崩溃 SpringBoot集成EasyExcel 3.x: 前言 在企业级应用开发中,常常需要处理复杂的 …...

什么是严肃游戏,严肃游戏本地化的特点是什么?
“严肃游戏”是一种交互式数字体验,不仅用于娱乐,还用于教育、培训或解决问题。与主要关注乐趣和参与度的传统游戏不同,严肃游戏的目标不仅仅是娱乐,比如教授特定技能、模拟现实生活场景或提高对重要问题的认识。它们用于医疗保健…...

ceph补充介绍
SDS-ceph ceph介绍 crushmap 1、crush算法通过计算数据存储位置来确定如何存储和检索,授权客户端直接连接osd 2、对象通过算法被切分成数据片,分布在不同的osd上 3、提供很多种的bucket,最小的节点是osd # 结构 osd (or device) host #主…...

2024/11/1 408 20题
b d c c a b d c c...
Python相关类库使用问题
文章目录 前言 一、pandas是什么? 二、使用步骤 1.引入库 2.读入数据 总结 前言 在工作中不时遇到新的需求,需要用到新的类库,以此篇专门记录Python类库使用过程中遇到的问题与解决 一、Python是什么? Python是一种高级编…...

ESP32/ESP8266开发板单向一对多ESP-NOW无线通信
ESP32/ESP8266开发板单向一对多ESP-NOW无线通信 简介读取ESP32/ESP8266接收方Receiver的MAC地址ESP32/ESP8266发送方Sender程序ESP32/ESP8266接收方Receiver程序ESP-NOW通信验证总结 简介 本实验通过ESP-NOW无线通信协议实现多个ESP32/ESP 8266开发板向ESP32开发板发送数据。例…...

动态规划-回文串问题——5.最长回文子串
1.题目解析 题目来源:5.最长回文子串——力扣 测试用例 2.算法原理 1.状态表示 判断回文子串需要知道该回文子串的首尾下标,所以需要一个二维数组且数据类型为bool类型来存储每个子字符串是否为回文子串, 即dp[i][j]:以第i个位置为起始&a…...
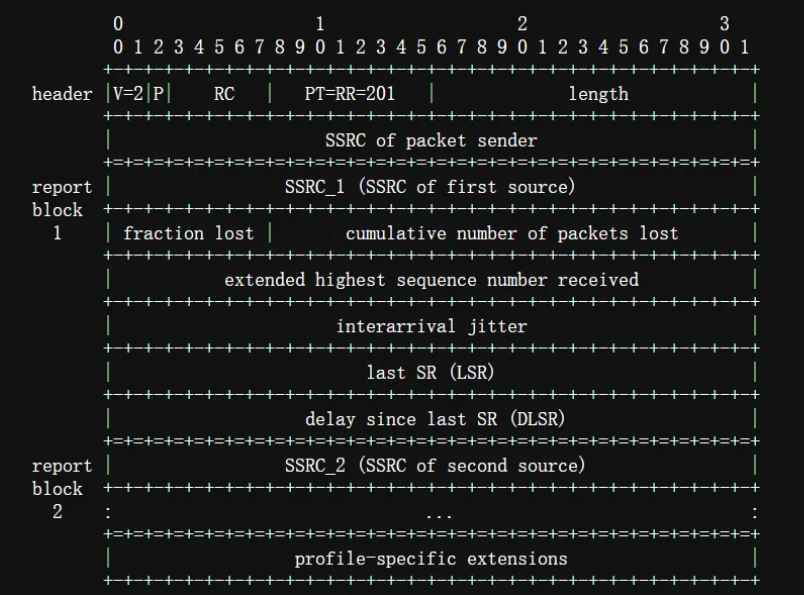
rtp协议:rtcp包发送和接收规则和报告!
RTCP Packet Send and Receive Rules: 发送和接收 RTCP 包的规则在此列出。允许在多播环境或多点单播环境中运行的实现必须满足第 6.2 节中的要求。这样的实现可以使用本节定义的算法来满足这些要求,或者可以使用其他算法,只要其性能等同或更…...
转imagenet(用于mmclassification))
label数据(或自定义数据集)转imagenet(用于mmclassification)
理论上用于分类的图像一般都不需要用labelme来标注的,笔者是因为刚好手上有这么一组数据,所以就顺带处理了。labelme标注完的数据每张还包含了一个json文件,这个在分类任务中用不上。具体的mmclassification使用方法在我的另一篇文章里有&…...
内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发—将 NXP 官方 Linux内核4.9.88 移植到韦东山IMX6ULLPro)
个人项目记录(二)内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发—将 NXP 官方 Linux内核4.9.88 移植到韦东山IMX6ULLPro
本文是个人项目记录(二)内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发,记录了将NXP官方Linux内核4.9.88移植到百问网(100ASK)IMX6ULL Pro开发板的完整过程,包括defc…...
别再死记硬背公式了!用大白话和动图拆解Transformer的注意力机制
用生活场景拆解Transformer:注意力机制就像一场高效会议 想象你正在主持一场跨国团队会议,成员们用不同语言讨论项目进展。作为主持人,你需要快速捕捉每个人的发言重点,判断谁的意见最关键,并协调不同观点之间的关系—…...

Kindle Comic Converter:漫画爱好者的终极电子阅读器优化工具
Kindle Comic Converter:漫画爱好者的终极电子阅读器优化工具 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc 你是否曾经尝试在Kindle或其…...

高级逆向工程分析:PC微信小程序wxapkg加密算法深度解析与实现
高级逆向工程分析:PC微信小程序wxapkg加密算法深度解析与实现 【免费下载链接】pc_wxapkg_decrypt_python PC微信小程序 wxapkg 解密 项目地址: https://gitcode.com/gh_mirrors/pc/pc_wxapkg_decrypt_python PC微信小程序逆向工程工具提供了精准的wxapkg加密…...

为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案
为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-po…...

视觉伺服visual servoing
模拟视觉反馈(图像 X/Y 偏差)自动控制机械臂末端向目标移动闭环控制,偏差越小速度越低无硬件相机也能运行(内置虚拟视觉信号)视觉伺服 Visual Servoing 示例代码cpp运行/********************************************…...

电池级硫酸锂粉碎工艺与设备选型全解析
一、硫酸锂粉碎核心需求与特性 1. 硫酸锂基础物性(决定粉碎工艺边界) 形态与硬度:白色结晶 / 颗粒(无水 / 一水),莫氏硬度约 2–3,质地脆、易结块、吸湿性强。 纯度要求:工业级≥99.…...

【Perplexity专利搜索黄金法则】:20年资深IP专家首度公开3大反直觉检索技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity专利搜索黄金法则的底层逻辑 Perplexity 作为基于语言模型的智能搜索工具,其在专利检索场景中的卓越表现并非源于简单关键词匹配,而是植根于对专利文本结构化语义、法…...
GNA稀疏注意力机制:视觉Transformer计算优化实践
1. GNA稀疏注意力机制解析在视觉Transformer领域,计算效率一直是制约模型规模和应用场景的关键瓶颈。传统自注意力机制需要计算所有查询(Query)和键(Key)之间的交互,导致计算复杂度随序列长度呈平方级增长&…...
)
别再硬编码了!用Unity动画事件实现音效与攻击判定的动态解耦(附完整C#脚本)
告别硬编码:Unity动画事件驱动的模块化开发实战 在游戏开发中,动画系统与游戏逻辑的耦合常常成为后期维护的噩梦。想象一下这样的场景:每次调整动画帧数都需要同步修改代码中的硬编码数值,或者音效资源路径被直接写在脚本里导致资…...