使用Flask构建RESTful API
💓 博客主页:瑕疵的CSDN主页
📝 Gitee主页:瑕疵的gitee主页
⏩ 文章专栏:《热点资讯》
使用Flask构建RESTful API
- Flask简介
- 环境搭建
- 安装Flask
- 项目结构
- 创建应用
- 路由定义
- 请求处理
- 获取查询参数
- 获取请求体
- 响应格式化
- JSON响应
- 错误处理
- 数据库集成
- 安装SQLAlchemy
- 配置数据库
- 定义模型
- 初始化数据库
- 测试
- 总结
Flask是一个轻量级的Web框架,适用于快速开发小型到中型的Web应用。本文将详细介绍如何使用Flask构建RESTful API,包括环境搭建、项目结构、路由定义、请求处理、响应格式化、错误处理、数据库集成、测试等内容。
Flask是一个用Python编写的轻量级Web应用框架。它没有固定的数据库抽象层、表单验证工具等,因此非常灵活,适合快速开发。 在开始之前,确保你的环境中已安装Python和pip。pip install Flask
my_flask_app/
├── app.py
├── config.py
├── models.py
├── routes.py
└── requirements.txt
from flask import Flask, jsonify, requestapp = Flask(__name__)@app.route('/hello', methods=['GET'])
def hello():return jsonify({'message': 'Hello, World!'}), 200if __name__ == '__main__':app.run(debug=True)
from flask import Blueprint, jsonify, requestapi_bp = Blueprint('api', __name__)@api_bp.route('/users', methods=['GET'])
def get_users():users = [{'id': 1, 'name': 'Alice'},{'id': 2, 'name': 'Bob'}]return jsonify(users), 200@api_bp.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):user = {'id': user_id, 'name': 'Unknown'}return jsonify(user), 200@api_bp.route('/users', methods=['POST'])
def create_user():data = request.jsonuser = {'id': 3, 'name': data['name']}return jsonify(user), 201# 导入蓝图
from app import app
app.register_blueprint(api_bp, url_prefix='/api')
@app.route('/search', methods=['GET'])
def search():query = request.args.get('q', '')results = []return jsonify(results), 200
@app.route('/submit', methods=['POST'])
def submit():data = request.jsonresult = process_data(data)return jsonify(result), 200
@app.route('/json', methods=['GET'])
def json_response():data = {'key': 'value'}return jsonify(data), 200
@app.errorhandler(404)
def not_found(error):return jsonify({'error': 'Not found'}), 404@app.errorhandler(500)
def internal_error(error):return jsonify({'error': 'Internal server error'}), 500
pip install SQLAlchemy
config.py中配置数据库。
import osbasedir = os.path.abspath(os.path.dirname(__file__))SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_TRACK_MODIFICATIONS = False
models.py中定义数据库模型。
from flask_sqlalchemy import SQLAlchemy
from config import SQLALCHEMY_DATABASE_URIapp.config['SQLALCHEMY_DATABASE_URI'] = SQLALCHEMY_DATABASE_URI
db = SQLAlchemy(app)class User(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(64), index=True, unique=True)def to_dict(self):return {'id': self.id,'name': self.name}
app.py中初始化数据库。
from models import dbdb.init_app(app)
with app.app_context():db.create_all()
import unittest
from app import app累加器 = 0class TestApp(unittest.TestCase):def setUp(self):self.app = app.test_client()self.ctx = app.app_context()self.ctx.push()def tearDown(self):self.ctx.pop()def test_hello(self):response = self.app.get('/hello')self.assertEqual(response.status_code, 200)self.assertEqual(response.json, {'message': 'Hello, World!'})def test_get_users(self):response = self.app.get('/api/users')self.assertEqual(response.status_code, 200)self.assertEqual(len(response.json), 2)if __name__ == '__main__':unittest.main()

使用Flask可以快速构建灵活且高效的RESTful API。

相关文章:
使用Flask构建RESTful API
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Flask构建RESTful API Flask简介 环境搭建 安装Flask 项目结构 创建应用 路由定义 请求处理 获取查询参数 获取请求体 响应…...

基于springboot的Java学习论坛平台
基于springboot的Java学习论坛平台 摘 要 在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括学习平台的网络应用,在外国学习平台已经是很普遍的方式,不过国内的管理平台可能还处于起步阶段。学习平台具…...

Python离线环境搭建
引言 在软件开发过程中,我们常常会遇到内网环境无法直接访问外网的情况,这就需要我们通过一些特殊手段来搭建Python开发环境。本文将详细介绍如何利用U盘在内网机与外网机之间迁移Python环境及其依赖包。 工具准备 1台内网机1台外网机1个U盘 操作步骤…...

windows下kafka使用出现的问题
kafka启动 启动kafka需要先启动zookeeper,在kafka根目录下先启动zookeeper .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties启动kafka 另开一个cmd命令行 .\bin\windows\kafka-server-start.bat .\config\server.propertieskafka与jdk版…...

ctfshow文件包含web78~81
目录 web78 方法一:filter伪协议 方法二:input协议 方法三:data协议 web79 方法一:input协议 方法二:data协议 web80 方法一:input协议 方法二:日志包含getshell web81 web78 if(isset($_GET[file]…...

鸿蒙生态认识
好的,让我们更深入地探讨鸿蒙生态的发展机遇、面临的挑战,以及未来的潜力。 对鸿蒙生态的认知与分析 鸿蒙系统作为一种新兴的操作系统,旨在打破设备之间的壁垒,打造一个更加连通的生态环境。以下是对其崛起的进一步分析…...

Hadoop-004-Big Data Tools插件的使用
一、Big Data Tools插件配置流程 1、安装Big Data Tools插件 以IntelliJ IDEA 2024.2.3为例打开setting, 搜索安装Big Data Tools插件后重启IDEA 2、Windows系统基础配置 Windows系统需要做一些基础设置,配合插件使用,将之前下载的hadoop-3.2.4.tar.gz 解压到D…...

linux8在线扩容/home目录
虚机新增1T磁盘 [rootrsb ~]# cat /etc/redhat-release Red Hat Enterprise Linux release 8.8 (Ootpa) [rootrsb ~]# vgs VG #PV #LV #SN Attr VSize VFree ol 2 3 0 wz--n- <2.00t 0 [rootrsb ~]# lvs LV VG Attr LSize Pool Origin Dat…...
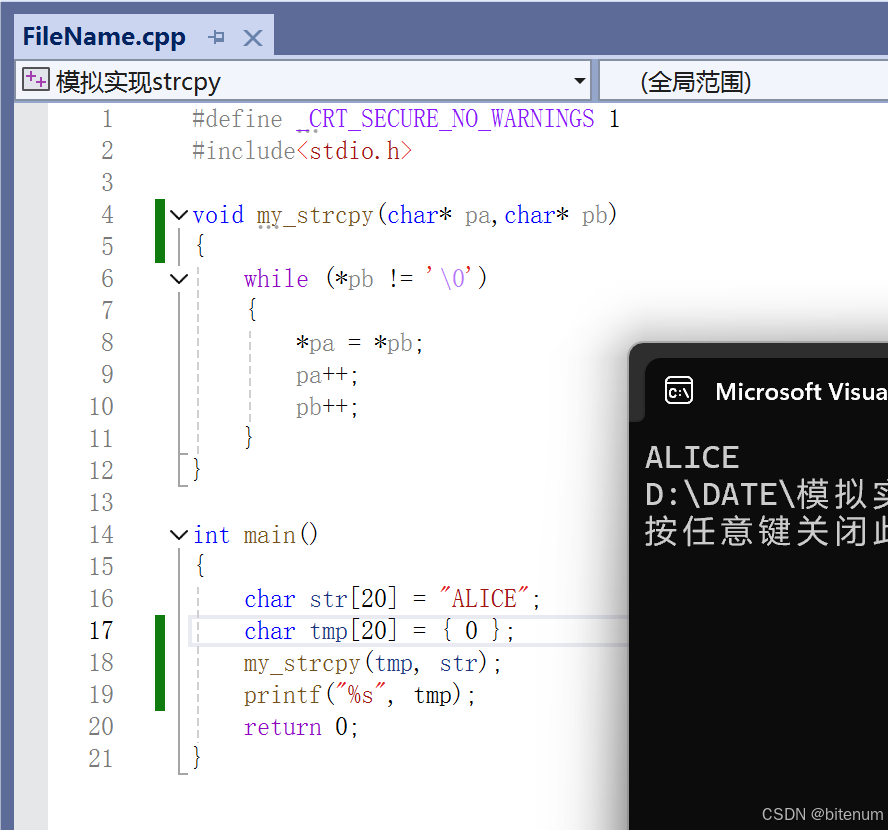
【C/C++】模拟实现strcpy
学习目标: 使用代码模拟实现strcpy。 逻辑: strcpy 函数的返回类型是 void 即不返回数据。strcpy 函数的参数类型是 char* ,用于接收数组。strcpy 函数要把一个数组复制到另一个数组。 代码: #define _CRT_SECURE_NO_WARNINGS …...

网络编程番外——IO多路复用的应用说明
一、IO多路复用与多线程 IO多路复用,IO Multiplexing,其实就是在IO上进行监听处理导致线程被阻塞(如果非阻塞就必须不断的轮询,仍然是占用此线程),如果一个IO对应一个线程是不是太浪费了。而且在诸如网络I…...

【Java爬虫的淘宝寻宝记】—— 淘宝商品类目的“藏宝图”
引言: 在淘宝这个广袤的“商品宇宙”中,每一件商品都是一颗璀璨的星球,而商品类目就是连接这些星球的星际航道。今天,我们将派遣一位勇敢的Java爬虫宇航员,去揭开这些星际航道背后的秘密——商品类目。准备好了吗&…...

探索Python文档自动化的奥秘:揭开docxtpl库的神秘面纱
文章目录 探索Python文档自动化的奥秘:揭开docxtpl库的神秘面纱1. 背景介绍2. 库简介3. 安装指南4. 基础函数介绍5. 实际应用场景6. 常见问题及解决方案7. 总结 探索Python文档自动化的奥秘:揭开docxtpl库的神秘面纱 1. 背景介绍 在日常工作中…...

RabbitMQ的解耦、异步、削峰是什么?
RabbitMQ在分布式系统和微服务架构中起到了重要的作用,其特性可以实现解耦、异步以及削峰,下面是对这三个概念的详细解释: 1. 解耦 解耦是指使系统的不同组件间的依赖关系减少或消失。在使用RabbitMQ时,生产者(发送消…...
4:arm汇编语言4:bits/byte的介绍(ASCII码)与二进制补位
4.2 bits/byte的介绍与ASCII码的引入 这个是详细介绍计算机内部原理的基础,bits与byte其实这两个是计算机中非常重要的单位。首先看一下bits,它是一个基础的计算机单位。计算机单位?像长度单位是米,体重的单位是kg,你…...

C++实现仿安卓线程Handler、Message、Looper的功能
在java开发中,习惯使用Handler、Message来处理同步,比如对相机的操作(open、setParamters、start、stop、clost)全部抛到同一个线程处理,防止并发操作导致异常,这样保留给外部的统一接口就是安全的,无论外部哪些线程来…...

构建安全的用户登录API:从请求验证到JWT令牌生成
构建安全的用户登录API:从请求验证到JWT令牌生成 为了实现这个后端POST /api/users/login端点,我们可以使用Node.js和Express框架,并结合一些常用的库如jsonwebtoken、bcrypt和express-validator来处理验证和密码校验。下面是一个完整的示例…...

状态模式:封装对象状态并改变行为的设计模式
1. 引言 在软件开发中,某些对象的行为会随着其内部状态的变化而变化。传统的实现方式可能需要使用大量的条件语句,导致代码复杂且难以维护。状态模式(State Pattern)提供了一种有效的方法,通过将状态行为封装在状态类…...
备战“双11”丨AI+物流:你的快递会有什么变化?
背景 在中国,每天有数以亿计的包裹在运输,尤其在电商促销季如“双十一”、“618”期间,快递量更是激增。快递物流行业面临人员短缺、配送效率低下和物流承载能力有限等问题。快瞳科技提供的AI识别解决方案通过智能化手段提高工作效率和配送准…...

理解为什么要有C++设计模式
什么时设计模式? 每一个模式描述了一个在我们周围不断重复的问题以及该问题的解决方案的核心,这样,就能一次有一次地使用该方案,而不必做重复劳动。 如何解决复杂性? 分解:人们面对复杂性有一个常见的做法…...

模式匹配类型
一、匹配常量 在scala中,模式匹配可以匹配所有的字面量,包括字符串,字符,数字,布尔值等等 def describeConst(x:Any):String x match {case "str" > "匹配字符串"case > "匹配字符&…...

Python随机密码生成器实战
求赞 求关注 当然写的不怎么好,因为我才刚初一,更新速度也慢。 如果想下载这里有链接 https://download.csdn.net/download/mc54321/91240180 正文开始 在编写这个程序我们需要导入random模块。 import random random 模块是 Python 标准库中的一个…...

Go语言事件驱动:CloudEvents
Go语言事件驱动:CloudEvents 1. CloudEvents实现 type Event struct {SpecVersion stringType stringSource stringID stringData []byte }2. 总结 CloudEvents是云原生事件的标准格式,促进跨服务的事件交互。...

一小时搞懂Python函数:原理+实践
目录 🙄什么是Python函数(了解函数的概念) 🤔为什么需要它?(背景和痛点) 😮函数的分类(函数有哪些?) 内置函数 标准库函数 第三方库函数 定…...

别再死记硬背Prompt了!用LangChain的ChatPromptTemplate,5分钟搞定角色扮演对话机器人
用LangChain的ChatPromptTemplate快速构建角色扮演对话机器人 你是否曾经为了设计一个能记住对话历史的客服机器人,不得不手动拼接几十行提示词?或者为了让AI扮演特定角色,反复调整系统消息却始终达不到理想效果?LangChain的Chat…...

为什么很多人学不会渗透?因为一开始就没学HTTP
最近刚开始系统学 Web 安全,发现很多人一上来就学 Kali、SQLMap、各种扫描器,但其实最应该先学的是 HTTP。因为后面很多 Web 漏洞,本质上都是在“修改 HTTP 请求”。比如:- SQL 注入 → 改参数 - XSS → 改输入内容 - 越权 → 改 …...

性能优化与profiling技术 - 打造极致性能
引言 性能优化是C语言编程的终极目标之一。作为最接近硬件的高级语言,C语言提供了丰富的优化手段。但盲目优化往往适得其反,科学的性能分析才是优化的前提。 本文将深入讲解性能分析方法、常见优化技巧、以及实用的profiling工具,帮助你写出高性能的C程序。 一、性能测量…...

3步掌握TEdit地图编辑器:泰拉瑞亚终极创作工具完全指南
3步掌握TEdit地图编辑器:泰拉瑞亚终极创作工具完全指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you c…...

2026 年 30 个 MCP Server 实测评:Claude Code 集成效果与响应延迟对比数据
1. 30个MCP Server实测评背后的真实问题:Claude Code不是“插上就快”,而是“配错就崩” 我上线第三个内部MCP Server时,CI流水线里一个原本2秒完成的代码补全请求,突然卡在waiting for MCP response状态长达17秒。日志里没有报错,只有反复重试的HTTP 504。排查了两天,最…...

别再手动调寄存器了!用Simulink给F28335 DSP配置ePWM,20kHz互补带死区输出一次搞定
告别寄存器调试:用Simulink图形化配置F28335 DSP的ePWM模块 在电机控制和电源逆变器开发中,PWM信号生成是核心环节。传统开发方式需要工程师反复查阅数百页的数据手册,手动计算并配置数十个寄存器参数,一个简单的死区时间设置就可…...

Perplexity实时新闻查询失效真相:Webhook劫持、缓存穿透与CDN时钟漂移三重陷阱
更多请点击: https://codechina.net 第一章:Perplexity实时新闻查询失效真相:Webhook劫持、缓存穿透与CDN时钟漂移三重陷阱 Perplexity 的实时新闻查询功能近期频繁返回陈旧或空结果,表面看是 API 延迟,实则深陷 Webh…...